OpenAI’s o1 line created a split in the AI community.
On benchmarks it looks like a leap forward, especially for math and code. In daily use many developers report frustration, inconsistent instruction following, and awkward refusals. The gap is rarely “model quality”, it is a broken mental model.
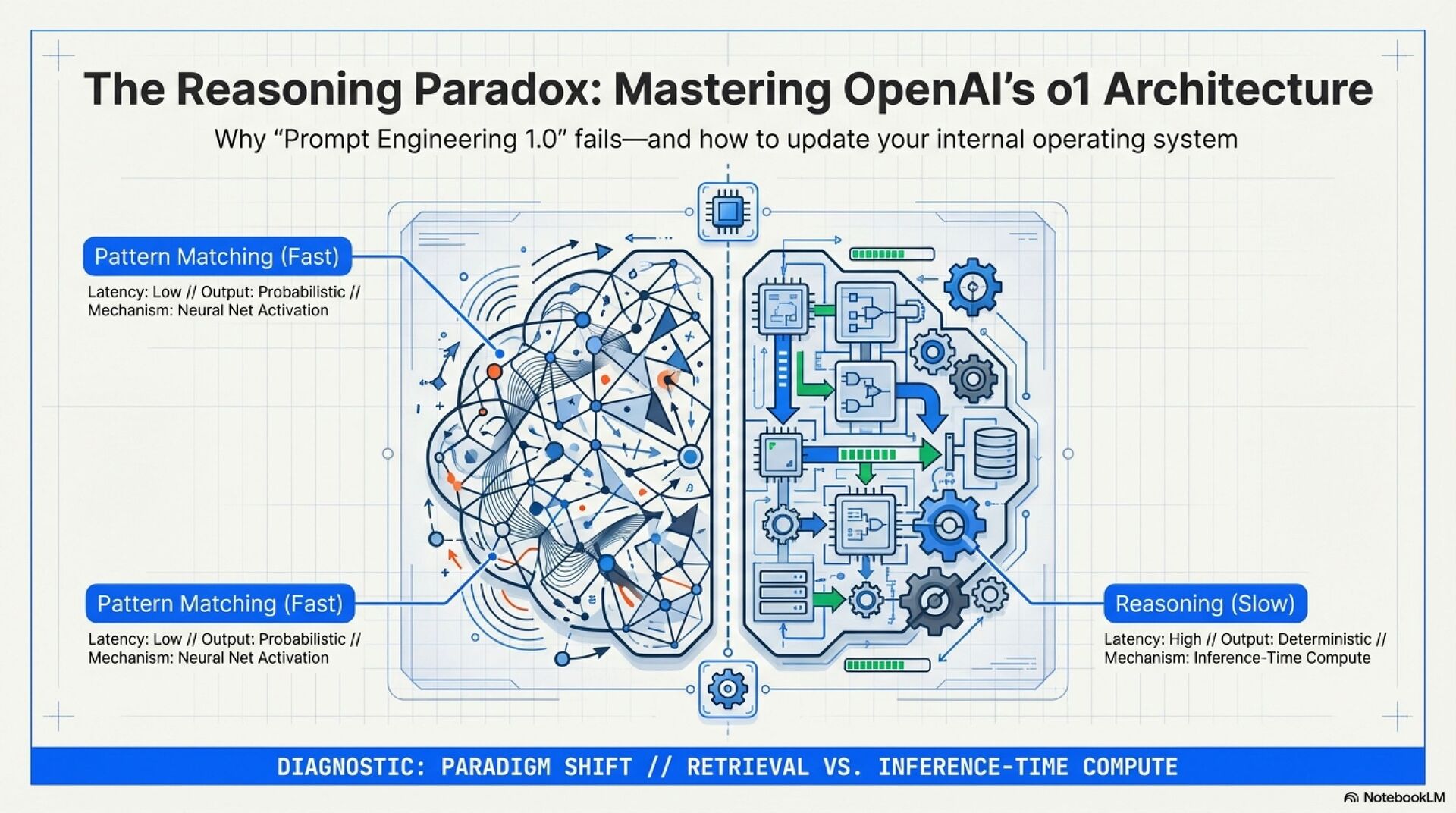
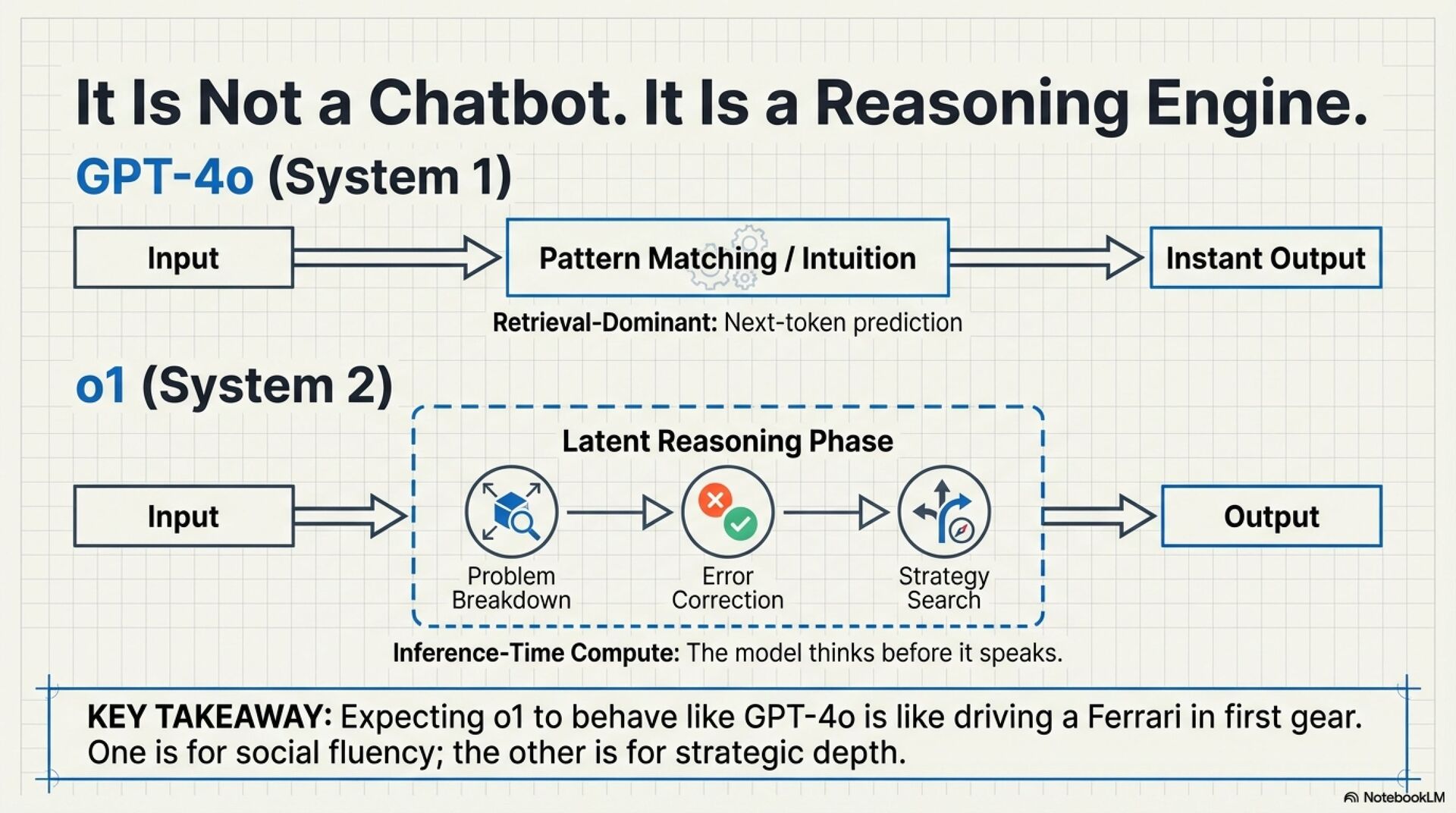
You are not talking to a faster chatbot. You are driving a reasoning engine.
Reasoning Paradox, benchmark excellence vs daily UX friction
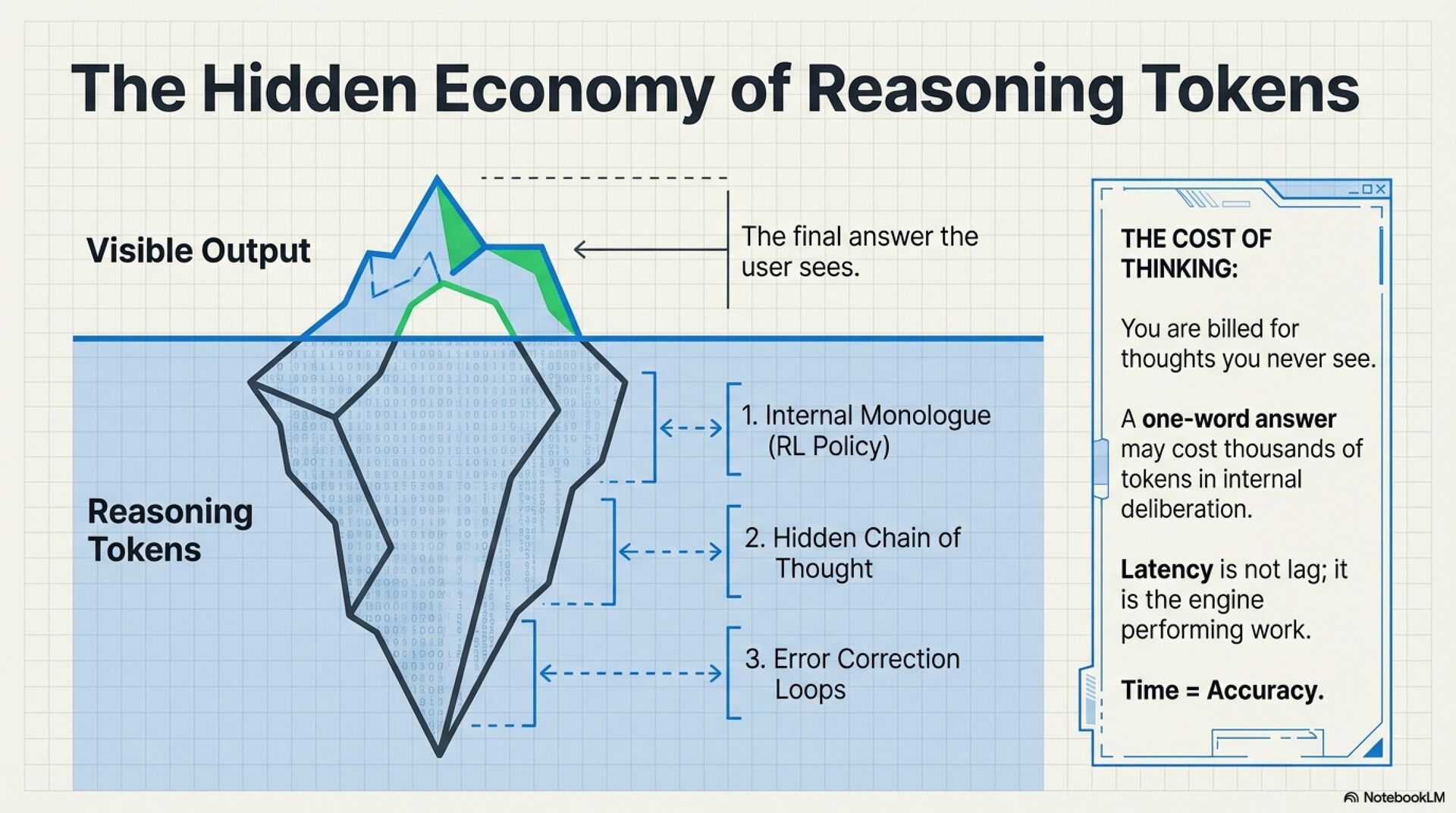
o1 is optimized to “think first, answer later” using internal reasoning tokens you do not see. That improves accuracy on hard problems, but it changes the experience:
• Latency feels higher because compute shifts to inference time
• Opacity increases because the real work happens off screen
• Cost feels unpredictable because hidden tokens still count
The real failure mode, Prompt Engineering 1.0 fights the optimizer
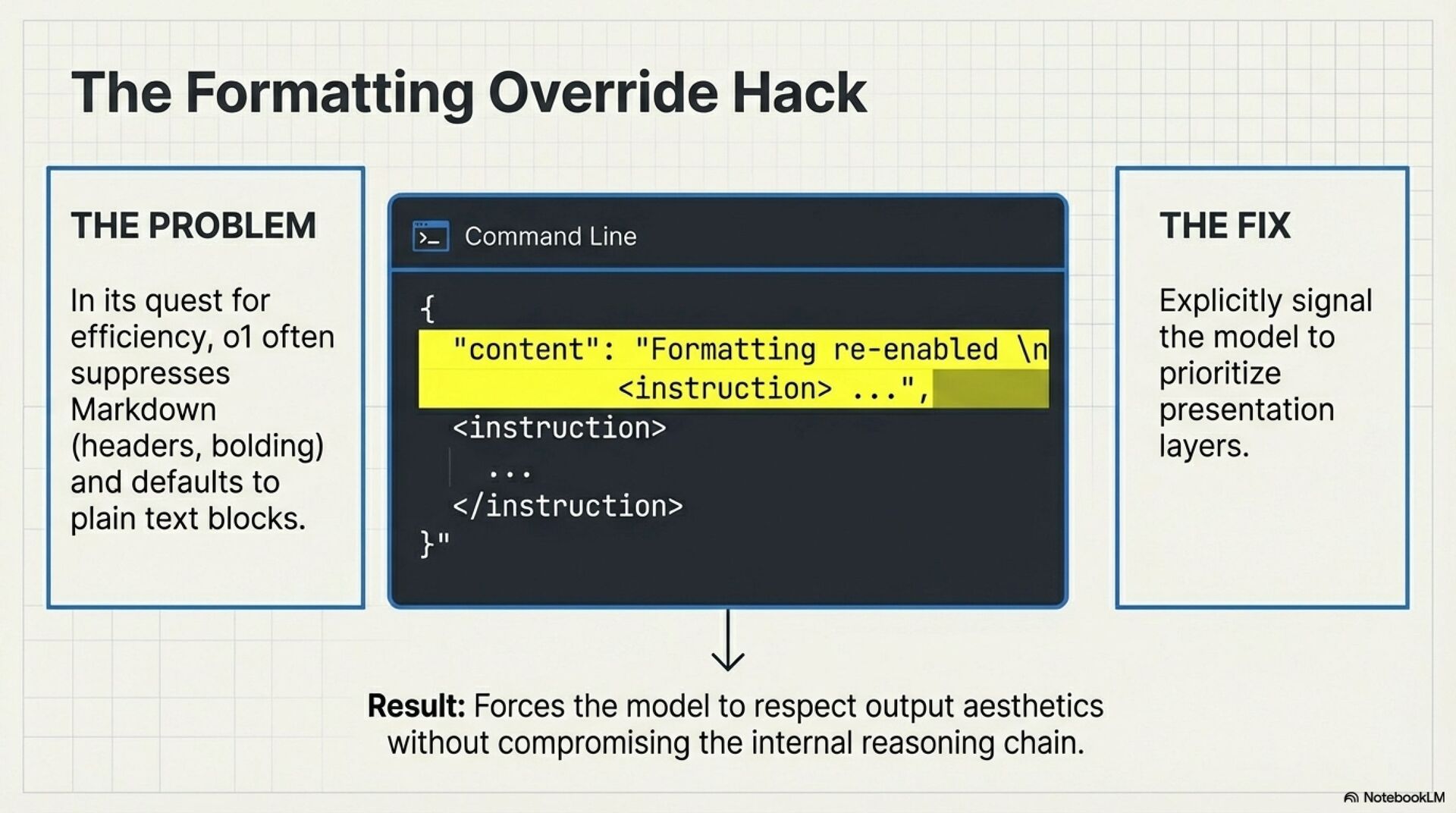
Old best practices assumed pattern matching models needed help “thinking”. o1 already reasons by default. Legacy techniques often add waste, increase latency, and reduce instruction fidelity.
Three mistakes that trigger poor outcomes
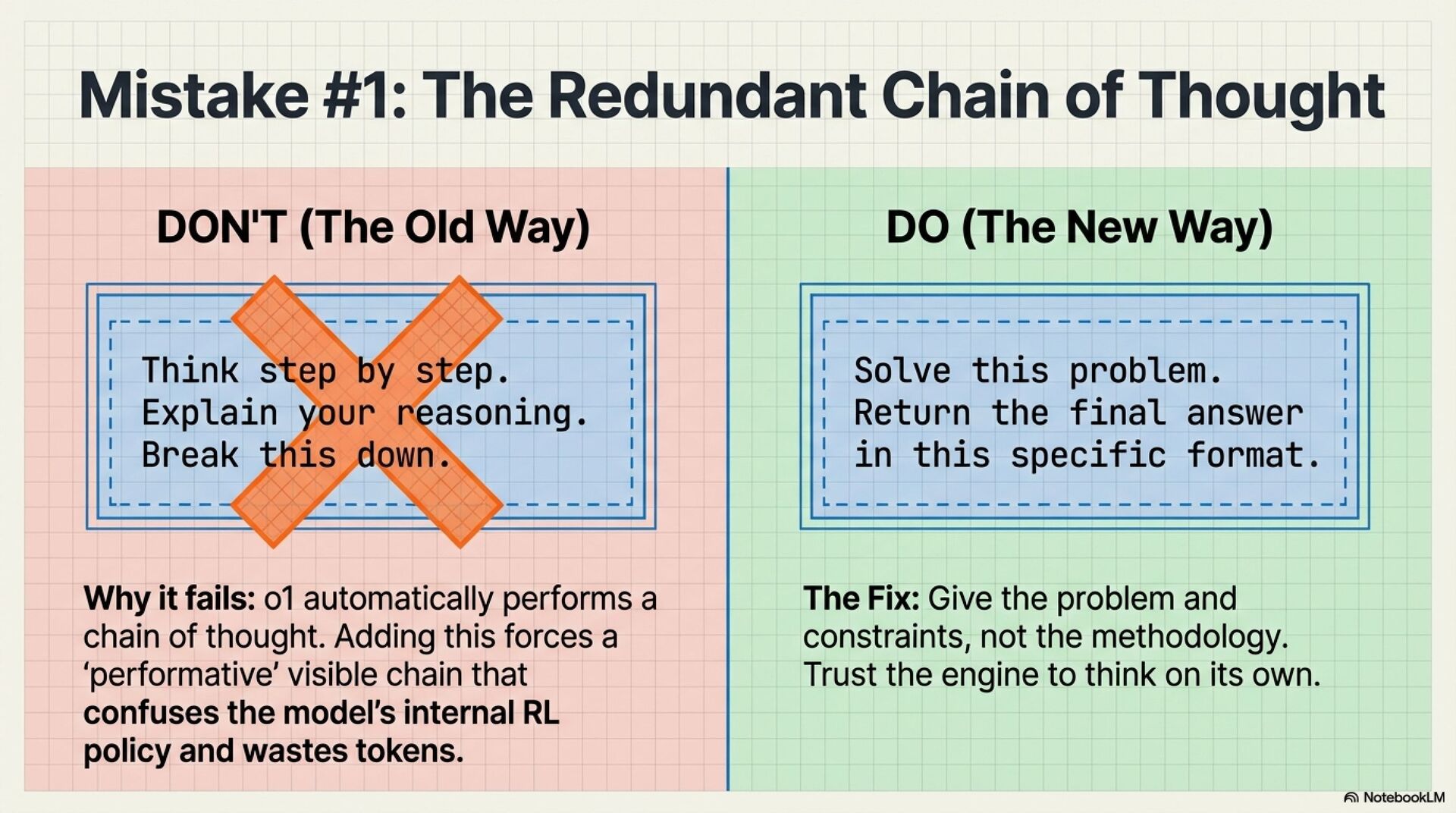
1. Redundant chain of thought prompting
“Think step by step” forces visible reasoning on top of hidden reasoning, you pay twice and often get worse formatting and compliance.
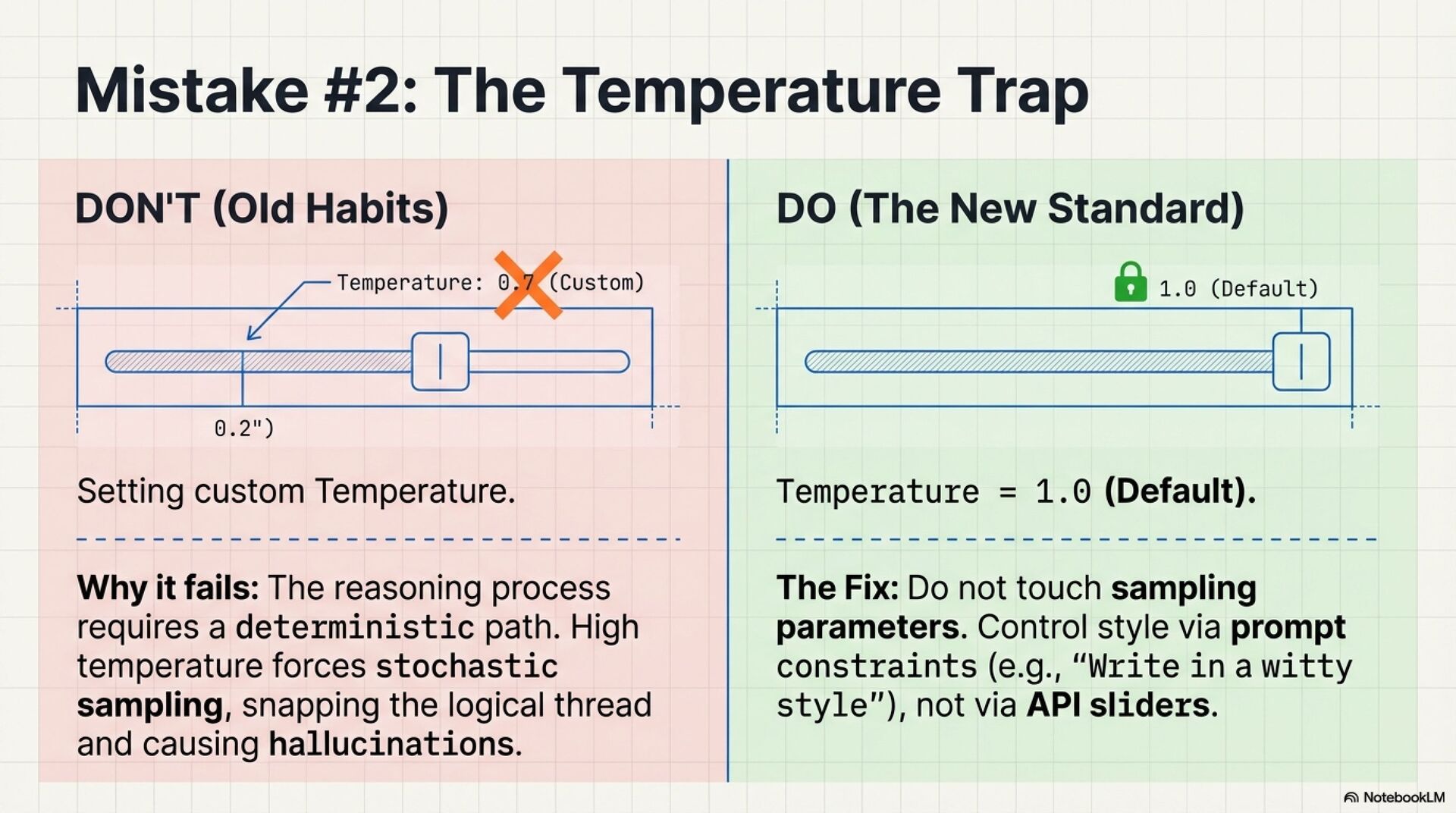
2. Temperature trap
Many o1 workflows only support the default temperature. Tooling that silently sets temperature can cause API errors or degraded reasoning.
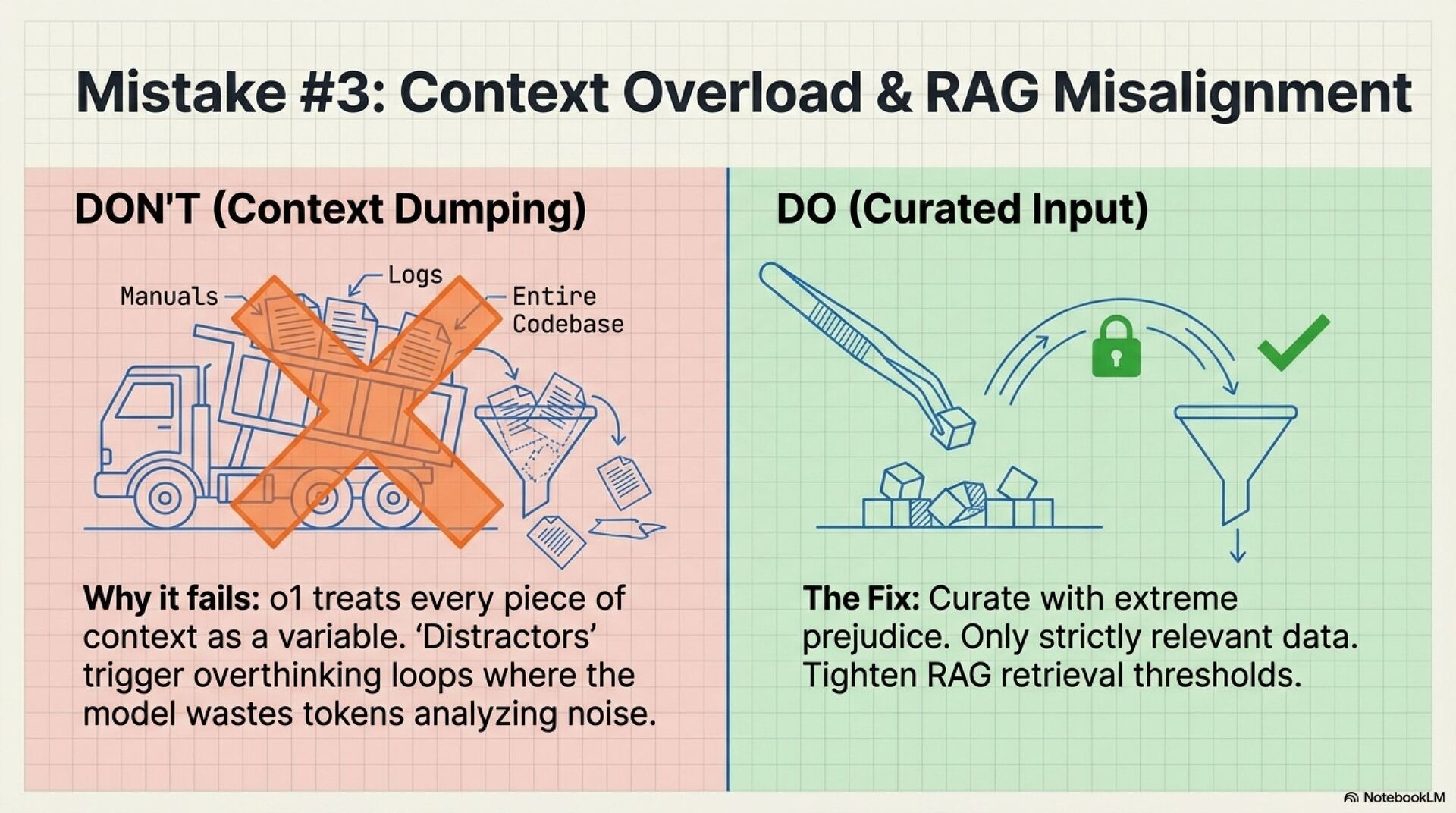
3. Context overload, RAG misalignment
Dumping large, noisy context makes o1 reason over distractors. Costs spike, instruction following drops. Fix with strict retrieval, smaller chunks, tighter thresholds, clear delimiters.
The new playbook, structured prompting
Treat prompts like constraints, not conversation:
• Put durable rules in developer style instructions, keep user input task only
• Use XML style blocks to separate context, rules, and task
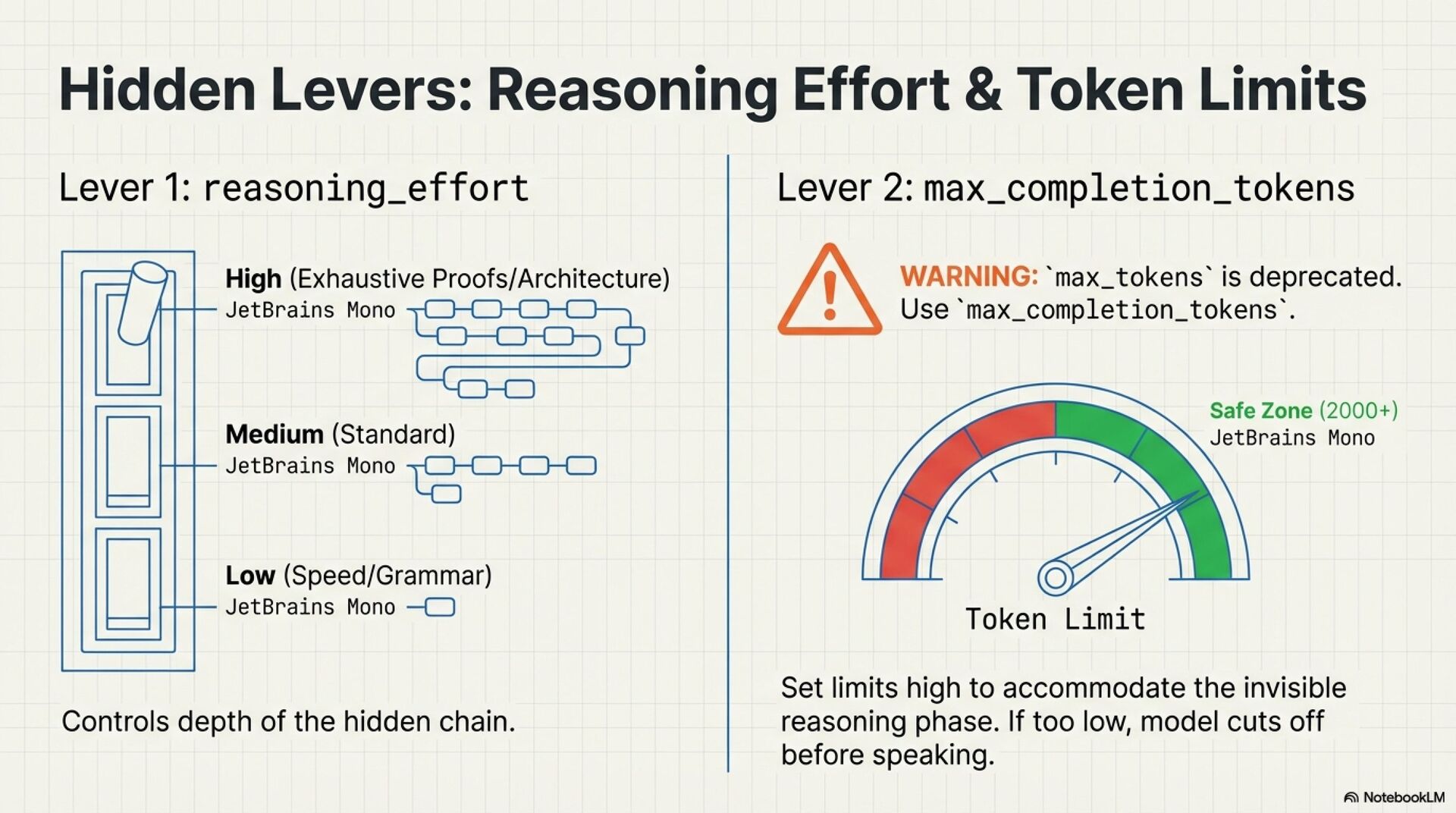
• Use reasoning effort to trade speed for depth
• Budget for hidden reasoning with max_completion_tokens, leave headroom
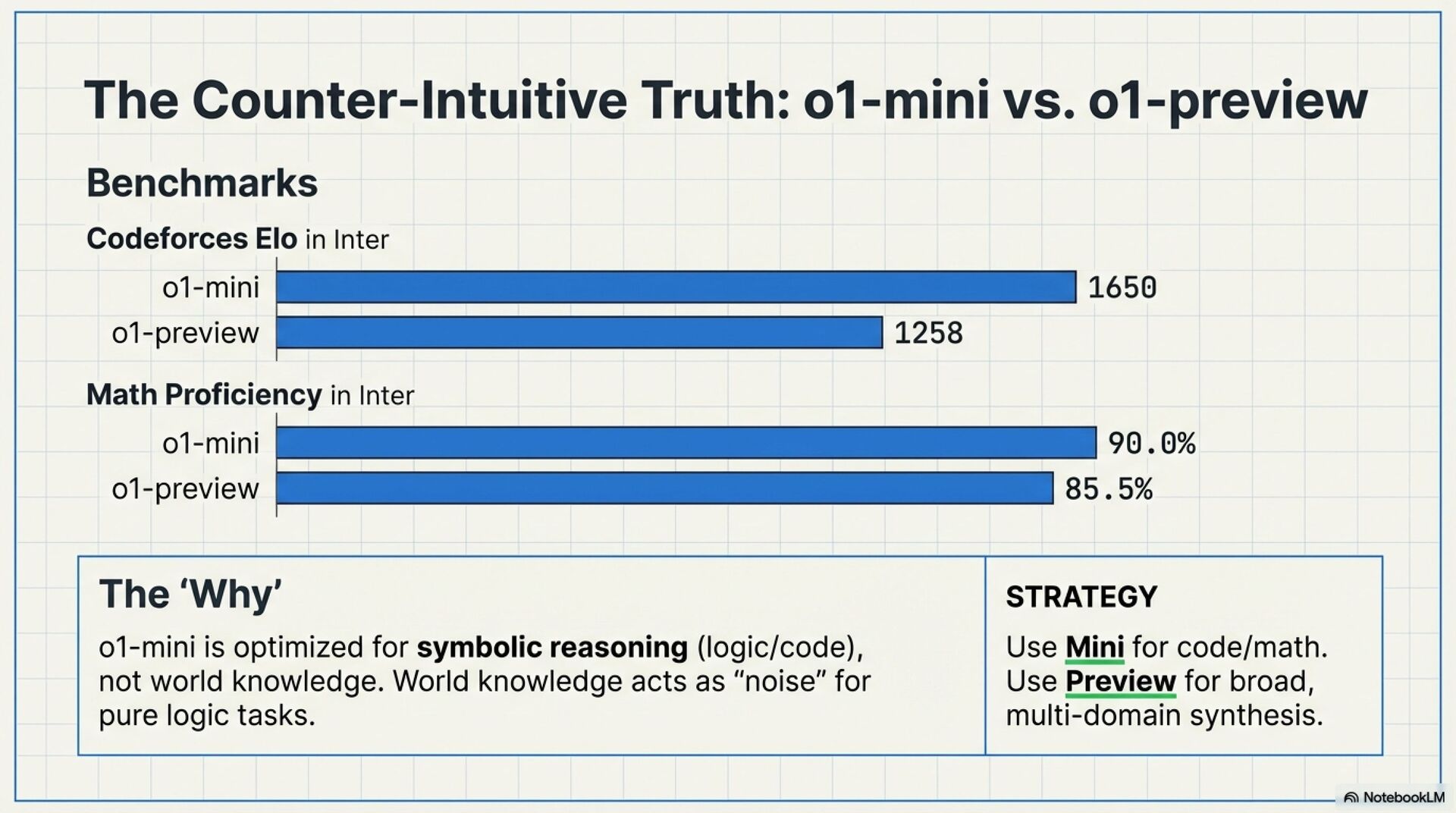
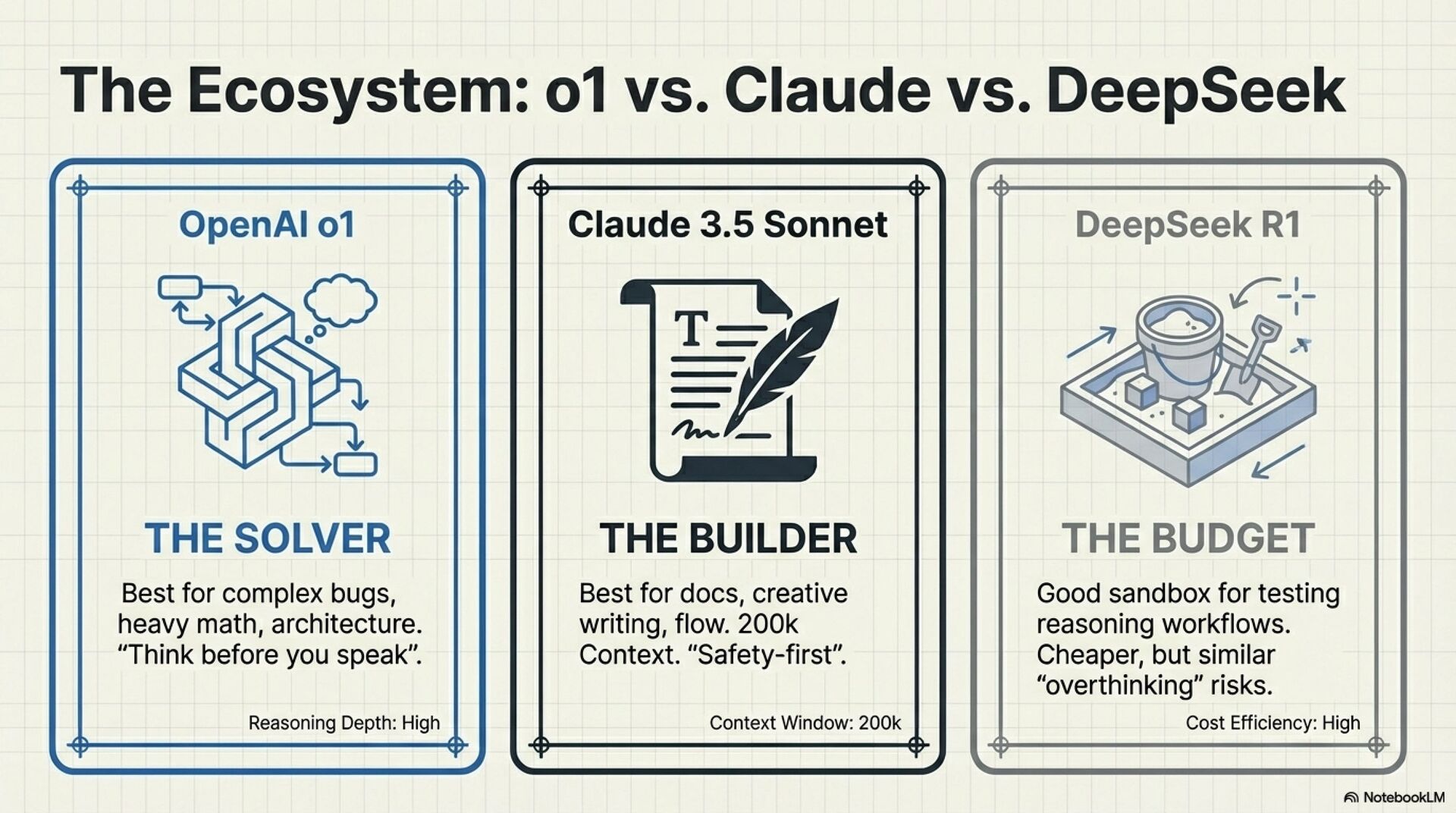
Counterintuitive reality, o1-mini can beat o1-preview for code
For code, debugging, and math heavy tasks, o1-mini is often the better default. Use larger variants when you need broader domain knowledge and synthesis.
Production optimization
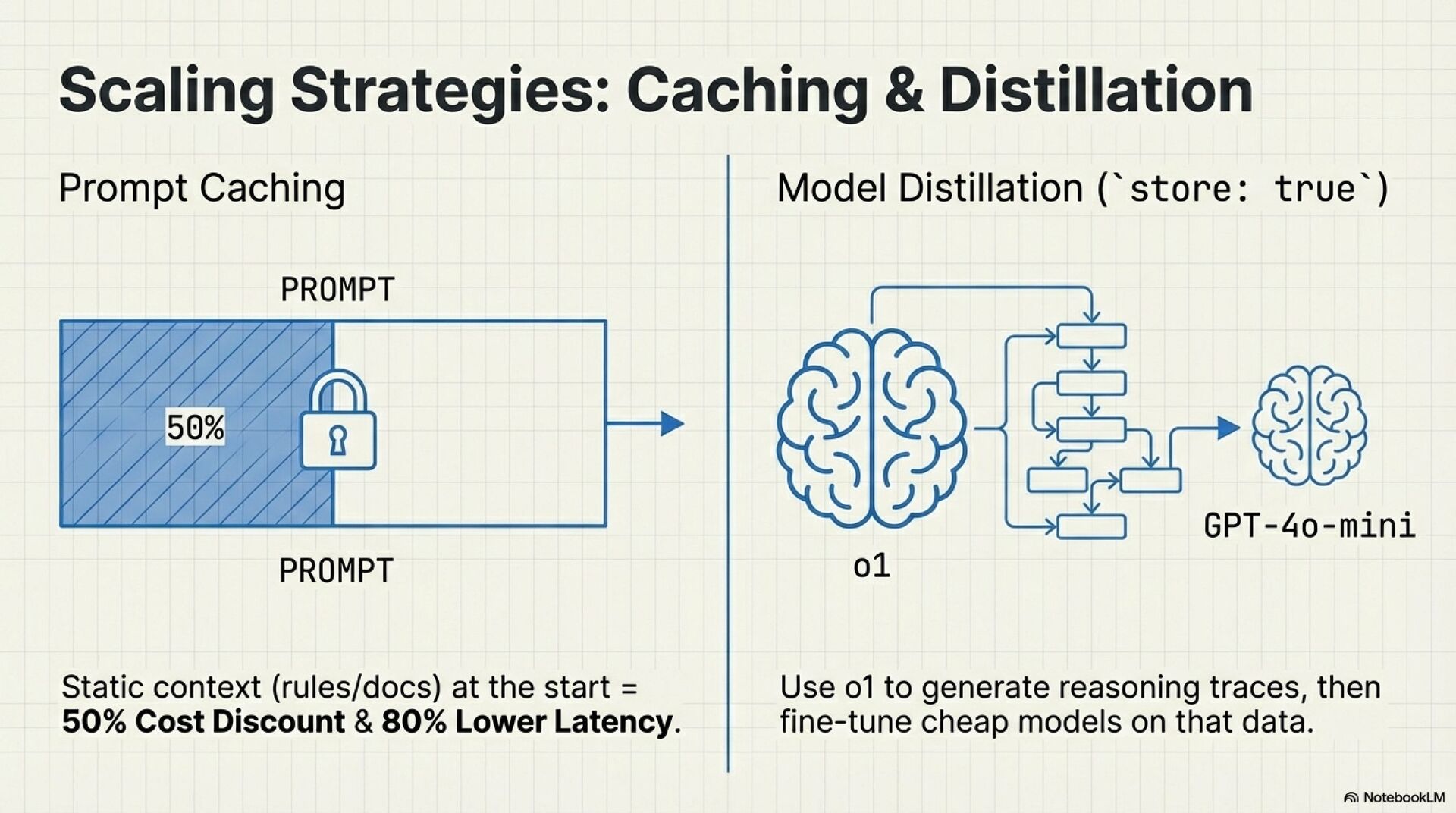
• Use prompt caching for repeated rulebooks and static prefixes
• Store high quality outputs and distill into cheaper models for recurring tasks
The paradox disappears once you stop “prompting a chatbot” and start engineering constraints for a reasoning system.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}