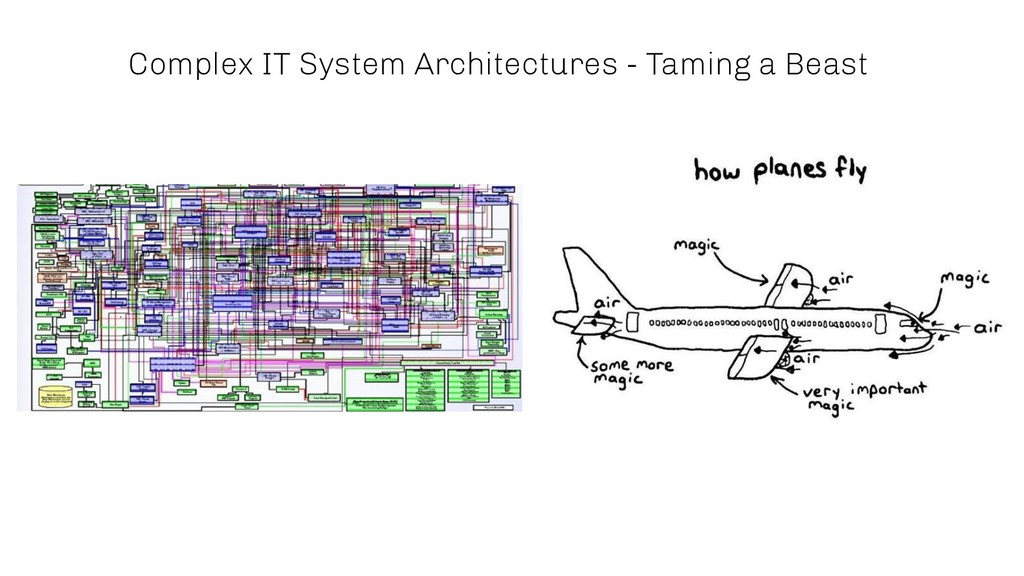
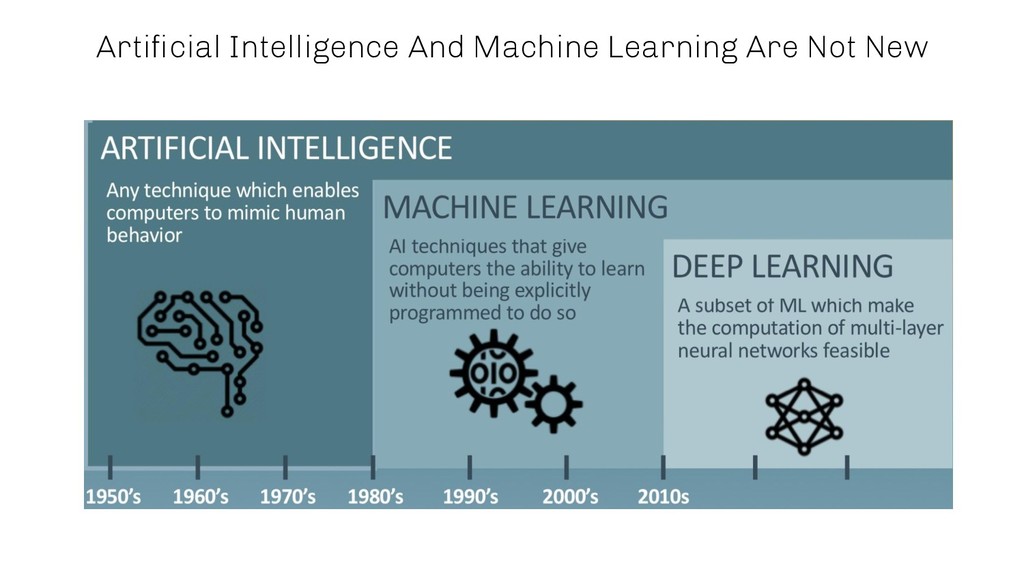
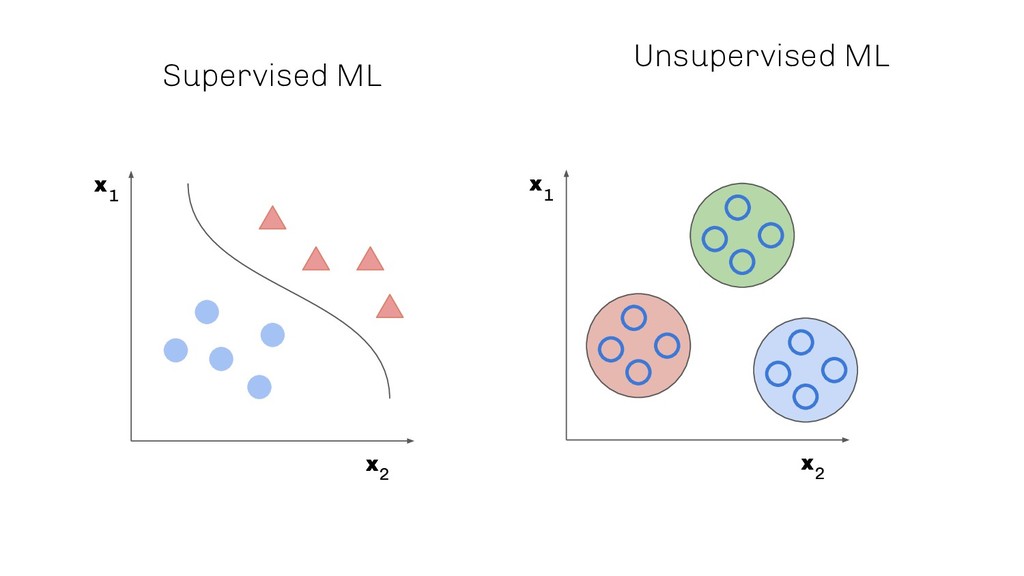
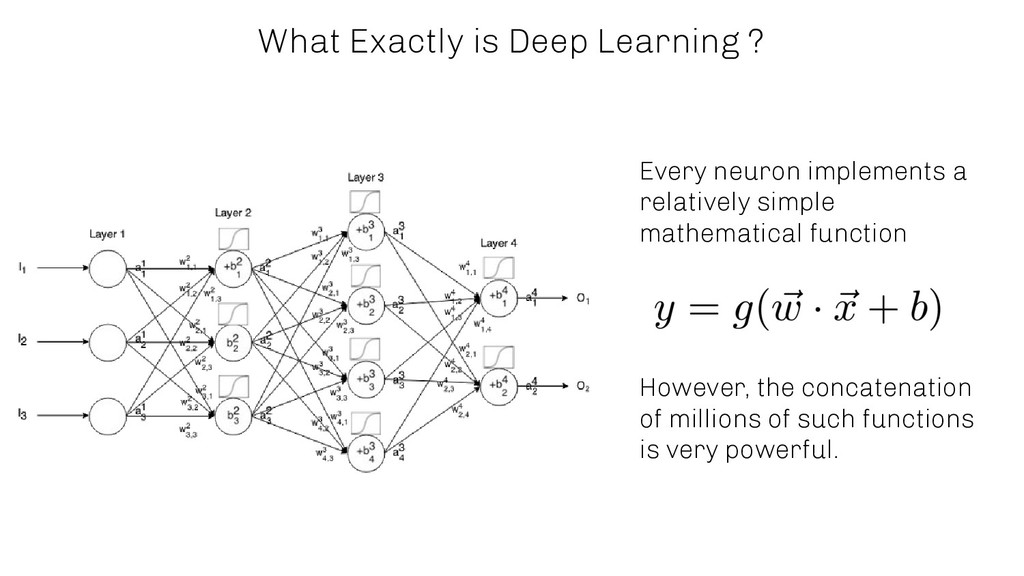
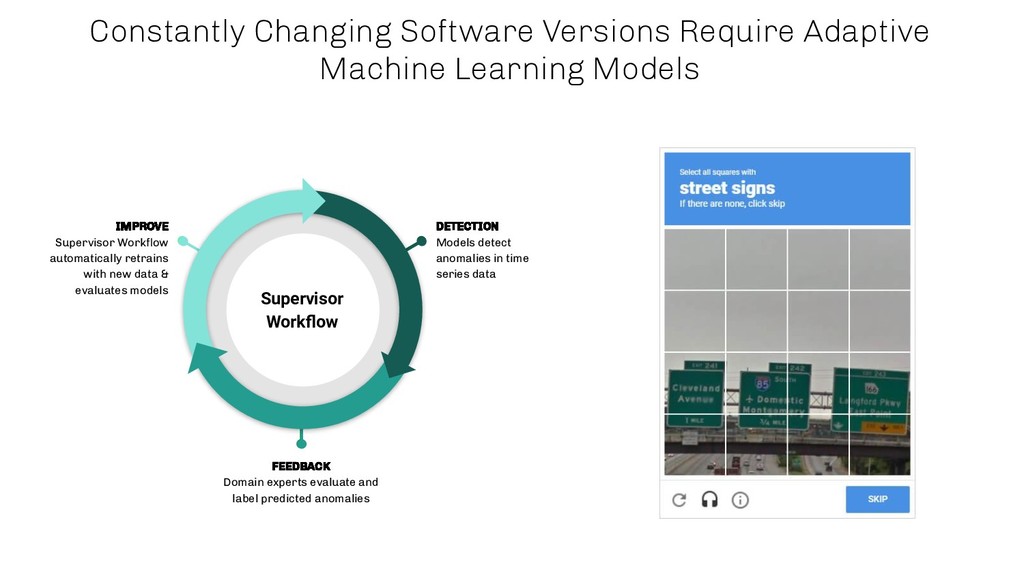
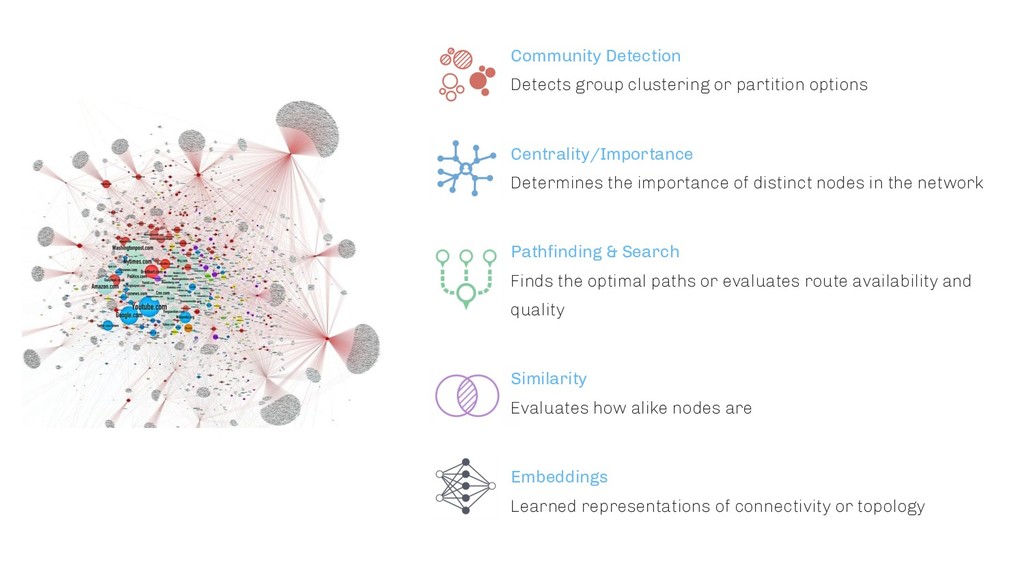
AIOps is one of the most promising fields where machine learning and in particular deep learning is starting to play an increasingly dominant role. Besides streamlining different tasks, machine learning algorithms are able to give additional insights into complex business processes, which most often cannot be maintained anymore by a human being without automation. One of the reasons is the number of interdependent system components which interact with each other in order to fulfil a certain task.
In this talk, I will show how a specific data representation, namely Knowledge Graphs, can help in order to speed up and optimise different areas within the field of AIOps. Several hands-on examples will be shown and an outlook will be given what other impacts will be generated by AI research in the AIOps community.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Thank you for your attention! Contact: fl[email protected]](https://files.speakerdeck.com/presentations/4973900f376c4054bf1b089bae19f7b5/slide_24.jpg){kind=link}