The days of trying to prevent failures are gone. In today’s high-volume, cloud-based systems, anything that can go wrong will eventually go wrong. It is far better to spend our time engineering fault tolerance than pursuing the impossible goal of fault prevention. Not only is reliability engineering one of the highest paying jobs in software engineering today, it is also a job full of unique challenges that demand creative thinking and problem solving.
This talk is about the multiple aspects of reliability engineering that have become critically important as our world has become increasingly dependent on software systems.
![www.poppendieck.com [email protected] Mary Poppendieck Photo © Tom Poppendieck Copyright©2019 Poppendieck.LLC](https://files.speakerdeck.com/presentations/c7059fcd6d0e4d9db0eb99a1c98047d5/slide_0.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
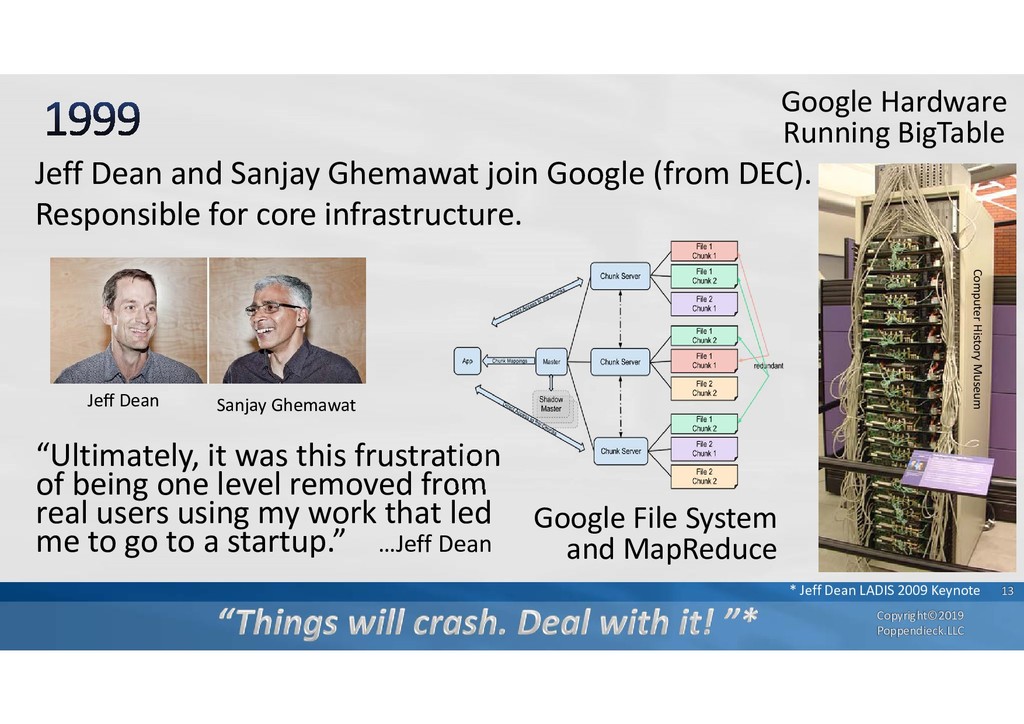{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Photo © Tom Poppendieck [email protected] www.poppendieck.com Mary Poppendieck 25](https://files.speakerdeck.com/presentations/c7059fcd6d0e4d9db0eb99a1c98047d5/slide_24.jpg){kind=link}