Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Rで始める正規表現入門
Search
Sponsored
·
SiteGround - Reliable hosting with speed, security, and support you can count on.
→
NobuakiOshiro
PRO
August 31, 2019
Technology
610
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
Rで始める正規表現入門
NobuakiOshiro
PRO
August 31, 2019
More Decks by NobuakiOshiro
See All by NobuakiOshiro
20260610_中東情勢_物流資源ショック_統合分析19枚_v3
doradora09
PRO
0
1
20260604_福岡女子大_講義後小レポート分析スライド_NOBDATA
doradora09
PRO
0
20
20260601_中東情勢1週間差分update
doradora09
PRO
0
33
20260602_中東情勢と物流_3か月振り返り_10枚圧縮版_最新版
doradora09
PRO
0
40
伊藤さん_発表スライド_全業種x各国_20260602
doradora09
PRO
1
34
20260528_生成AIを専属DSに_Howの次にすべきことを考える
doradora09
PRO
0
290
20260527_準悲観シナリオ_v2_価格高騰見込み
doradora09
PRO
0
59
20260527_ホルムズ制約長期化シナリオ(準悲観シナリオ)
doradora09
PRO
0
60
20260527_先週差分_今後調査予定_サマリ
doradora09
PRO
0
52
Other Decks in Technology
See All in Technology
JEP 522 Deep Dive - G1 GC同期コスト削減によるスループット向上を徹底検証&解説
tabatad
1
860
価格.comをAI駆動で全面刷新する ー 30年分の技術的負債を返し、次の30年の土台をつくる ー / AI Engineering Summit Tokyo 2026
tkyowa
49
52k
Databricks における 生成AIガバナンスの実践
taka_aki
1
310
TypeScript Compiler APIとPHP-Parserを活用し、TypeScriptとPHPで型を共有する
shuta13
0
360
Databricks 月刊サービスアップデート 2026年05月号
tyosi1212
0
210
EventBridge Connection
_kensh
4
530
運用を見据えたAIエージェント設計実践
amacbee
1
2.9k
速さだけじゃない! VoidZero ツールが移行先に選ばれる理由
mizdra
PRO
6
750
[モダンアプリ勉強会]今更聞けないGit/GitHub入門
tsukuboshi
0
270
GoとSIMDとWasmの今。
askua
3
510
10倍の生産性を実現するAI駆動並列エージェントのすべて
kumaiu
3
340
ITエンジニアを取り巻く環境とキャリアパス / A career path for Japanese IT engineers
takatama
4
1.8k
Featured
See All Featured
How to make the Groovebox
asonas
2
2.2k
More Than Pixels: Becoming A User Experience Designer
marktimemedia
3
430
How STYLIGHT went responsive
nonsquared
100
6.2k
Organizational Design Perspectives: An Ontology of Organizational Design Elements
kimpetersen
PRO
1
720
Exploring anti-patterns in Rails
aemeredith
3
390
The Mindset for Success: Future Career Progression
greggifford
PRO
0
350
We Are The Robots
honzajavorek
0
240
How to build an LLM SEO readiness audit: a practical framework
nmsamuel
1
770
A brief & incomplete history of UX Design for the World Wide Web: 1989–2019
jct
2
390
Designing for Timeless Needs
cassininazir
1
250
Docker and Python
trallard
47
3.9k
Typedesign – Prime Four
hannesfritz
42
3.1k
Transcript
LT Rで始める 正規表現⼊⾨ fukuoka.R #15 2019/08/31 @doradora09
⾃⼰紹介 • NOB DATA株式会社 代表取締役 • ⼤城 信晃 (@doradora09) •
データサイエンティスト • 沖縄 -> 東京 -> 福岡(3年⽬) • ヤフー -> DATUM STUDIO -> LINE Fukuoka -> NOB DATA(株) 設⽴ • DS協会九州⽀部 発起⼈ • コミュニティ運営 • Tokyo.R, fukuoka.R, 意思決定のための データ分析勉強会, PyData.Fukuoka、等 https://nobdata.co.jp/ 2
None
[RP] DS協会九州⽀部設⽴ • 次回は9/20のセミナーを調整中 • 個⼈・法⼈会員も募集中です・・!
モチベーション • たまにWebクロール & スクレイピン グのハンズオンなどをやっているが その後のデータ加⼯で皆苦戦してい る節がある • 「正規表現」という便利なものがあ
るよ、という紹介
こういうケースとか • Xpathで住所データをスクレイピングしたものの、 前後に改⾏とスペースが⼤量にある、など str_replace_all(pattern = "[\n ]+", replacement =
'') => 改⾏と半⾓スペースを除去し、データを綺麗に。
正規表現とは • 正規表現(せいきひょうげん、英: regular expression)とは、 ⽂字列の集合を⼀つの⽂字列で表現する⽅法の⼀つである。正 則表現(せいそくひょうげん)とも呼ばれ、形式⾔語理論の分 野では⽐較的こちらの訳語の⽅が使われる。まれに正規式と呼 ばれることもある。(wikipediaより) •
正規表現の起源の⼀つとして、数学者のスティーヴン・クリー ネは1950年代に正規集合と呼ばれる独⾃の数学的表記法を⽤い、 これらの分野のモデルを記述した。 • (その後Unix系のツールへ広がり今に⾄る)
正規表現のメリット • テキスト処理で本領を発揮。スクレイピングにも使える • XML(HTML含む)の構造が崩れているデータにも適⽤出来る • さらに他の⾔語でも使えるので汎⽤的 • ed、 grep、expr、awk、Emacs、vi、lex、Perl、PHP、Python等
• windowsやmacで動くテキストエディタにも実装されてるものも。 ※注 • いくつか⽅⾔はあるので注意。共通して使えるものを覚えておくと吉。 • 基本正規表現、拡張正規表現、Perl⾵正規表現など
正規表現で出来ること(⼀例) プログラムのif⽂や専⽤関数を使わずに以下のようなことが可能 1. 区切り⽂字変更(タブ -> カンマ) 2. HTMLタグの除去(簡易版) 3. 都道府県の抽出(簡易版)
4. 郵便番号の抽出(7桁) 5. URL解体(簡易版) 6. Emailアドレス形式チェック(⼀致するか否か) その他にも、⽂字列のルールに基づくマッチングや置換全般
Rで正規表現使うなら{stringr}パッケージ • {stringi}パッケージのラッパーパッケージ • 関数名とか引数のルールが統⼀されていて使いやすい • 対象⽂字列が⼀貫して第⼀引数で、パターンが⼆番⽬ • 今回は以下のような関数を利⽤ •
str_replace_all : ⼀致したパターンを置換 • str_extract : ⼀致したパターンを抽出 • str_match : ⼀致したパターンをグループで分割 • str_detect : ⼀致するかどうかをTRUE / FALSEで返却
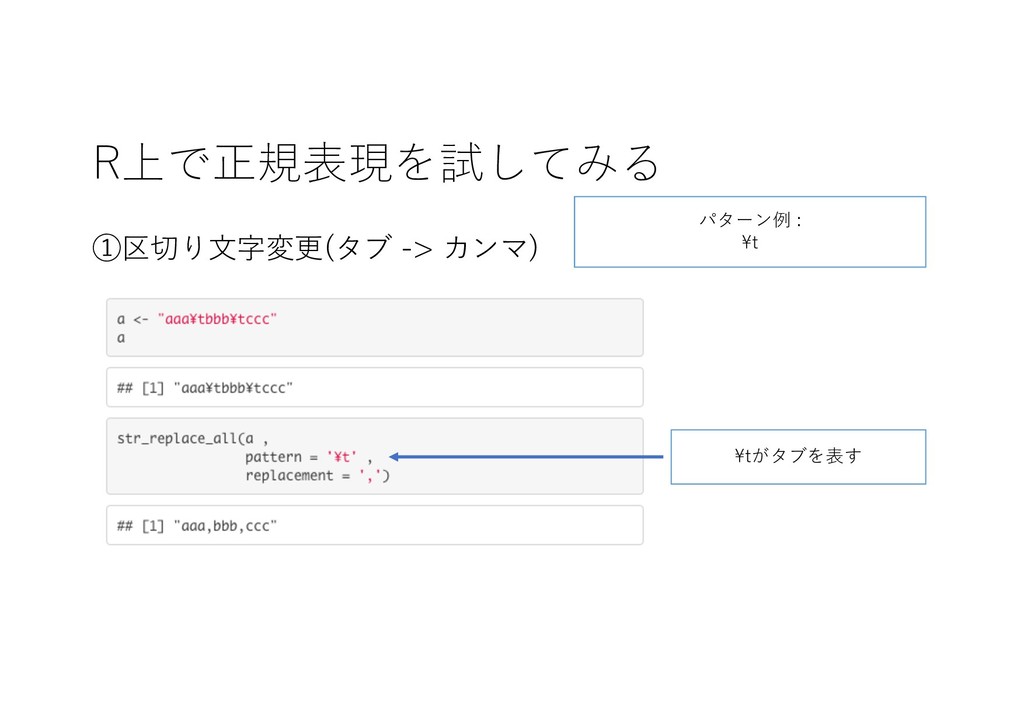
R上で正規表現を試してみる ①区切り⽂字変更(タブ -> カンマ) \tがタブを表す パターン例 : \t
ご参考 : 正規表現で定義されているもの(抜粋) https://murashun.jp/blog/20190215-01.html
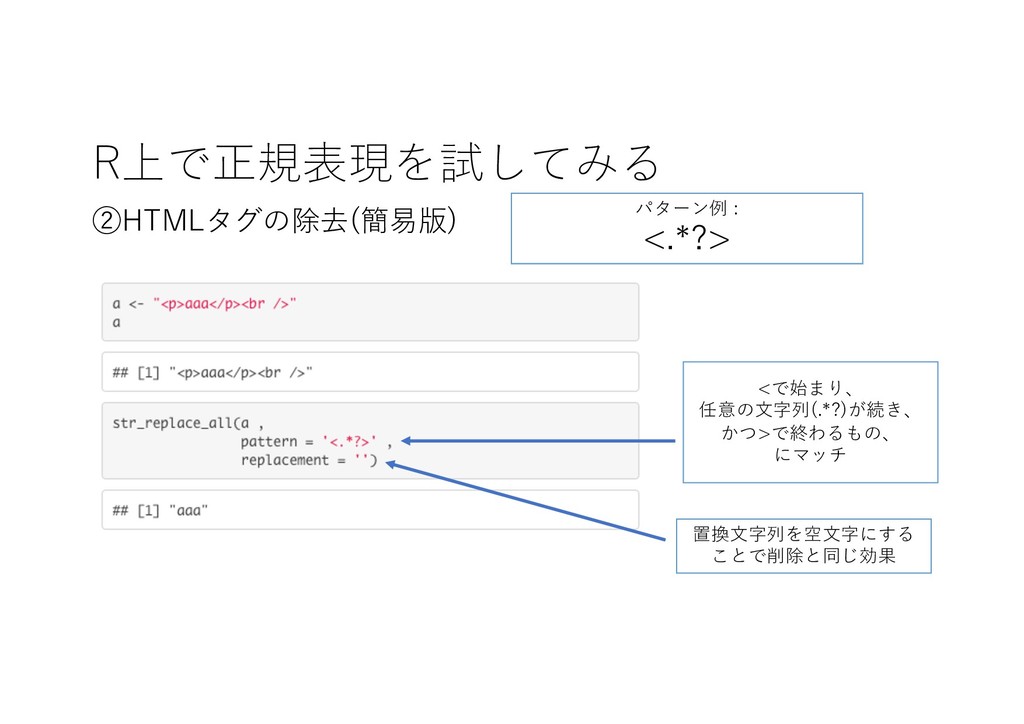
R上で正規表現を試してみる ②HTMLタグの除去(簡易版) <で始まり、 任意の⽂字列(.*?)が続き、 かつ>で終わるもの、 にマッチ 置換⽂字列を空⽂字にする ことで削除と同じ効果 パターン例 :
<.*?>
ご参考 : ⽂字列系のメタ⽂字(抜粋) https://murashun.jp/blog/20190215-01.html
R上で正規表現を試してみる ③都道府県の抽出(簡易版) スペース以外の⽂字([^ ])が、 2⽂字から3⽂字続き{2,3}?、 かつ都道府県のいずれかが続く パターンにマッチ ※[]の中の^は否定を表す。 ⾏頭を⽰す^とは別の意味な ので注意
パターン例 : ([^ ]{2,3}?[都道府県])
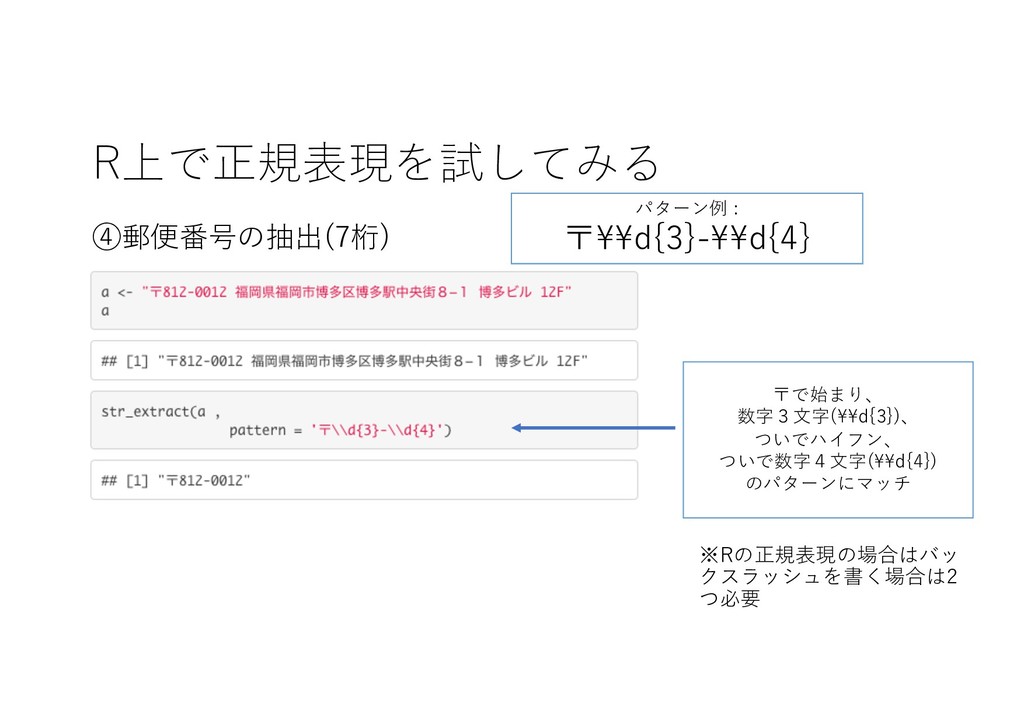
R上で正規表現を試してみる ④郵便番号の抽出(7桁) 〒で始まり、 数字3⽂字(\\d{3})、 ついでハイフン、 ついで数字4⽂字(\\d{4}) のパターンにマッチ ※Rの正規表現の場合はバッ クスラッシュを書く場合は2 つ必要
パターン例 : 〒\\d{3}-\\d{4}
ご参考 : 繰り返しや否定のメタ⽂字 https://murashun.jp/blog/20190215-01.html
R上で正規表現を試してみる ⑤URL解体(簡易版) ()でそれぞれグループ化したもの が分割されて後から取り出せる (後⽅参照) パターン例 : ^(.+?)://(.+?):?(\\d+)?(/.*)?$
R上で正規表現を試してみる ⑥Emailアドレス形式チェック(⼀致するか否か) パターンに⼀致する場合は TRUEを返却 不⼀致の場合は FALSEを返却 @マークが2ある変 なアドレスを指定し た場合 パターン例
: ^[A-Za-z0-9._+]+@[A-Za-z]+.[A-Za-z]+$
ご参考 : 連続した⽂字の省略記法(抜粋) https://murashun.jp/blog/20190215-01.html
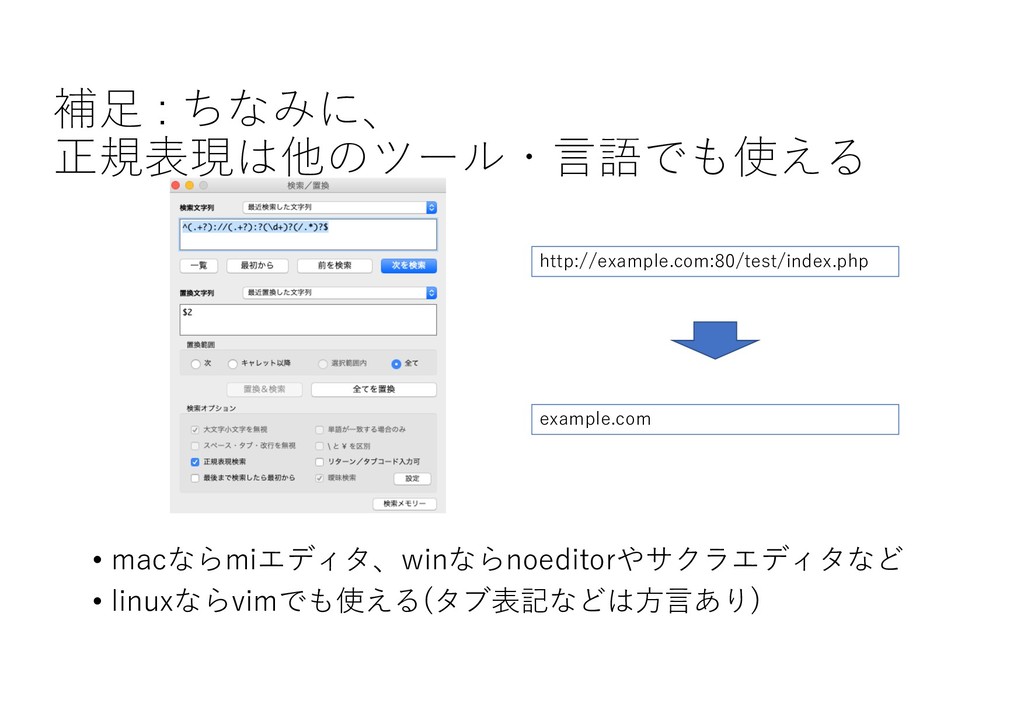
補⾜ : ちなみに、 正規表現は他のツール・⾔語でも使える • macならmiエディタ、winならnoeditorやサクラエディタなど • linuxならvimでも使える(タブ表記などは⽅⾔あり) http://example.com:80/test/index.php example.com
まとめ • テキスト処理を⾏うなら正規表現が便利 • Rで使うなら{stringr}パッケージなど • 他のエディタや⾔語でも使えるので拡張正規表現あたりは覚え ておくと役に⽴つかも
Enjoy !
{kind=link}
{kind=link}
{kind=link}
![[RP] DS協会九州⽀部設⽴ • 次回は9/20のセミナーを調整中 • 個⼈・法⼈会員も募集中です・・!](https://files.speakerdeck.com/presentations/3982d4af61844bd787f2592b529b5330/slide_3.jpg){kind=link}
{kind=link}
![こういうケースとか • Xpathで住所データをスクレイピングしたものの、 前後に改⾏とスペースが⼤量にある、など str_replace_all(pattern = "[\n ]+", replacement =](https://files.speakerdeck.com/presentations/3982d4af61844bd787f2592b529b5330/slide_5.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![R上で正規表現を試してみる ③都道府県の抽出(簡易版) スペース以外の⽂字([^ ])が、 2⽂字から3⽂字続き{2,3}?、 かつ都道府県のいずれかが続く パターンにマッチ ※[]の中の^は否定を表す。 ⾏頭を⽰す^とは別の意味な ので注意](https://files.speakerdeck.com/presentations/3982d4af61844bd787f2592b529b5330/slide_14.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}