Каждый разработчик ежедневно работает с коллекциями, структурами данных и алгоритмами в том или ином виде. Часто складывается ситуация, даже в самом обыкновенном энтерпрайзе, когда необходимо обработать тем или иным образом большие массивы данных. Чтобы не проседать в перформансе, необходимо понимать, какие структуры данных и коллекции использовать в том или ином случае. Соответственно, необходимо точно понимать, какие структуры данных лежат под различными коллекциями. Любой API - это кроличья нора, и некоторые норы довольно глубоки. В любом случае, желательно понимать инфраструктуру хотя бы на один уровень, глубже самого поверхностного. Доклад будет о практическом применении алгоритмов и структур данных.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
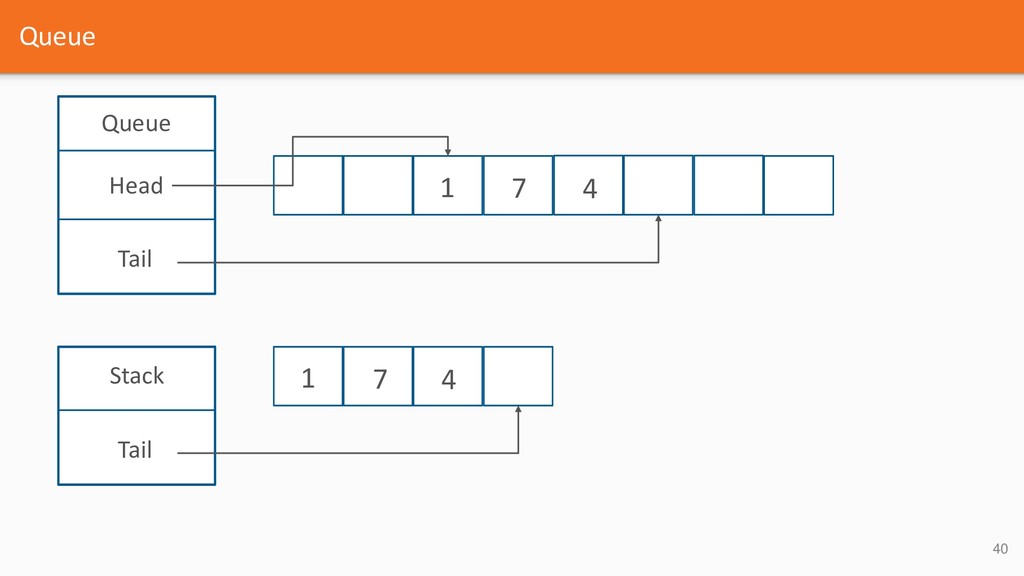{kind=link}
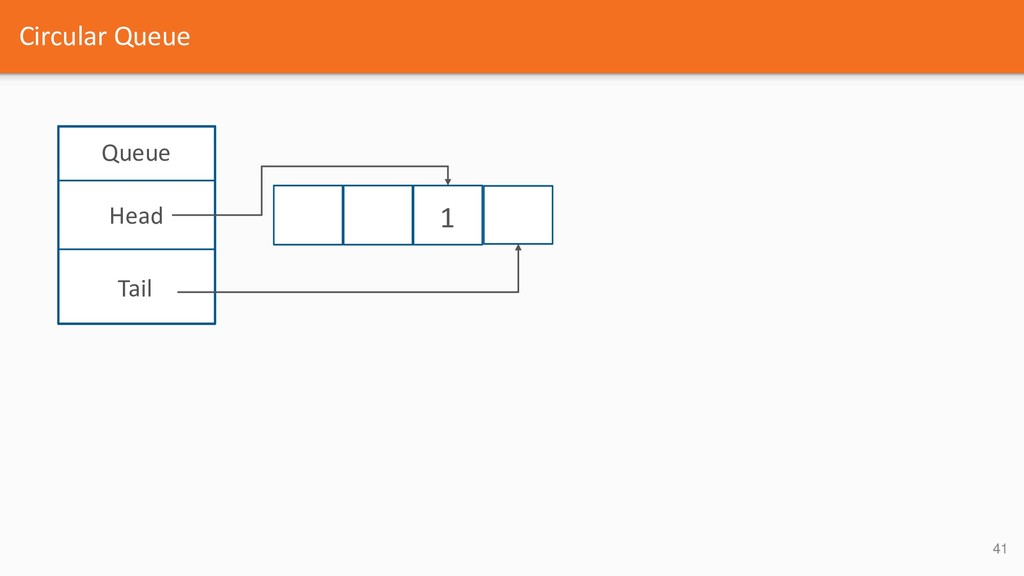{kind=link}
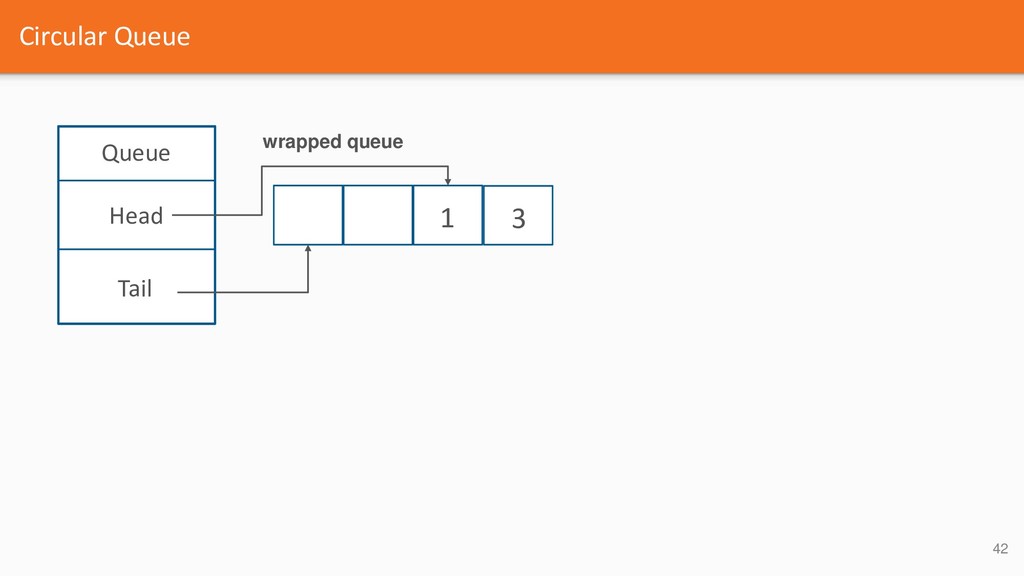{kind=link}
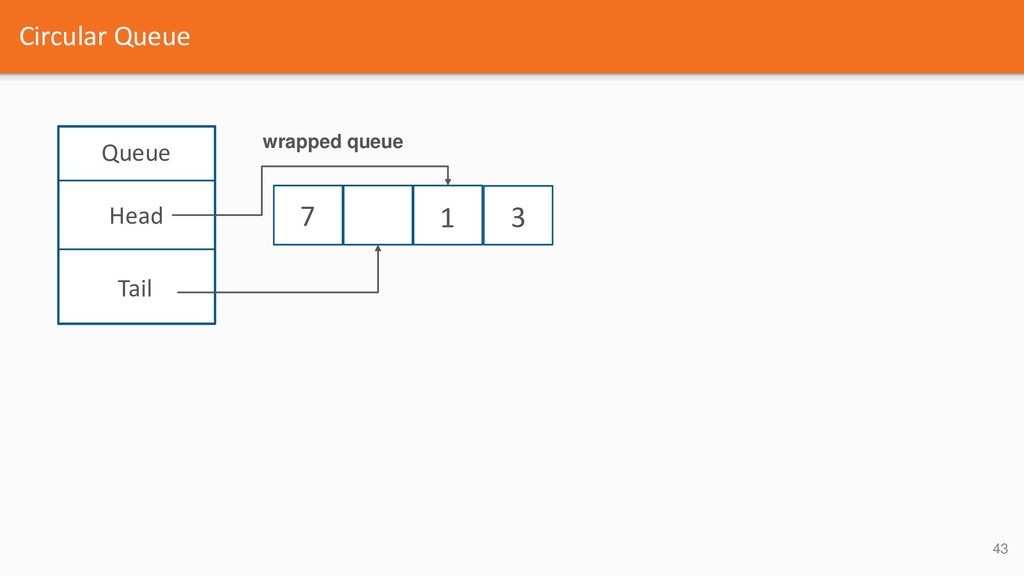{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
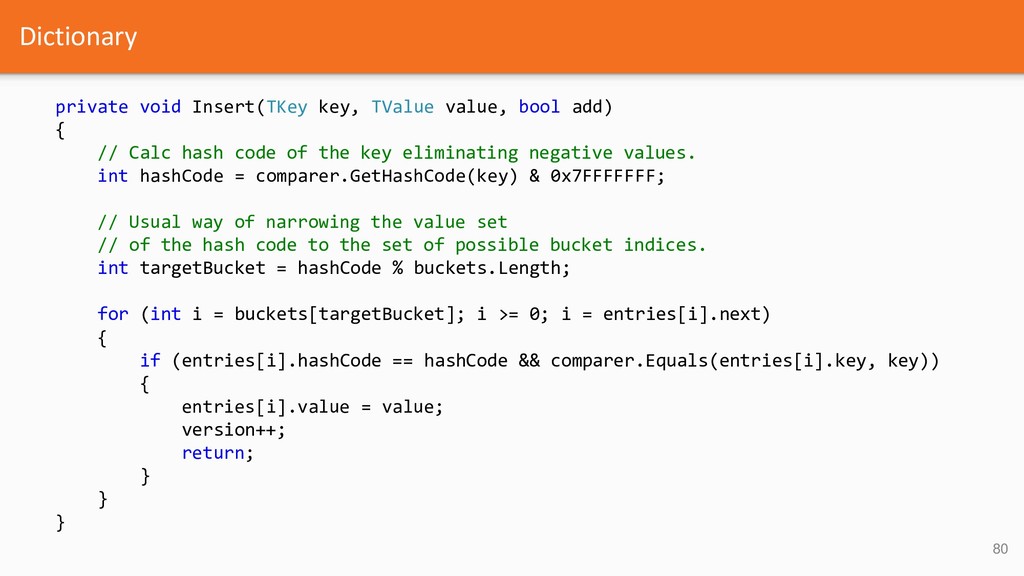{kind=link}
![Dictionary internal static class HashHelpers { public static readonly int[]](https://files.speakerdeck.com/presentations/57d40abe61b8407492e837190246d933/slide_70.jpg){kind=link}
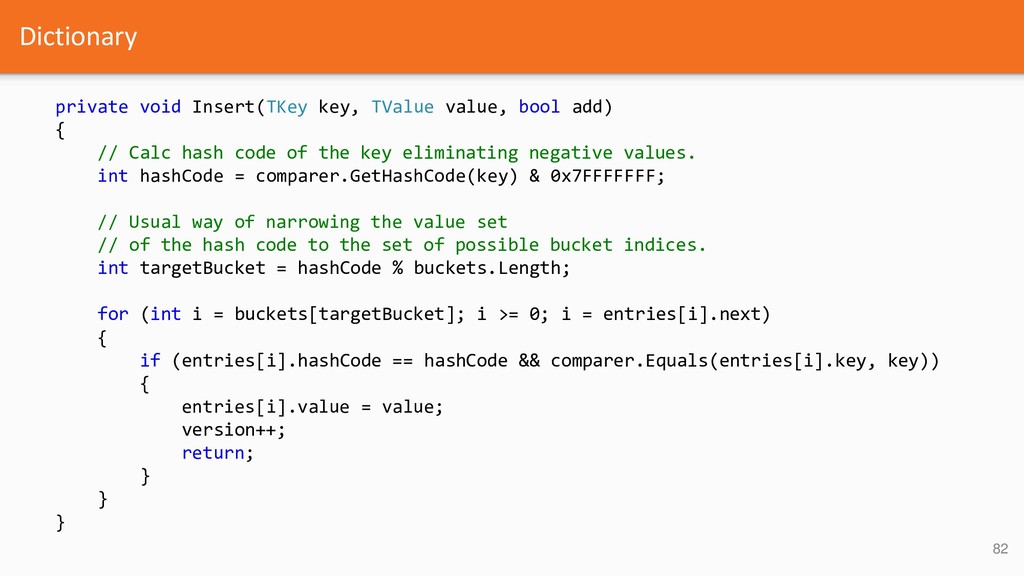{kind=link}
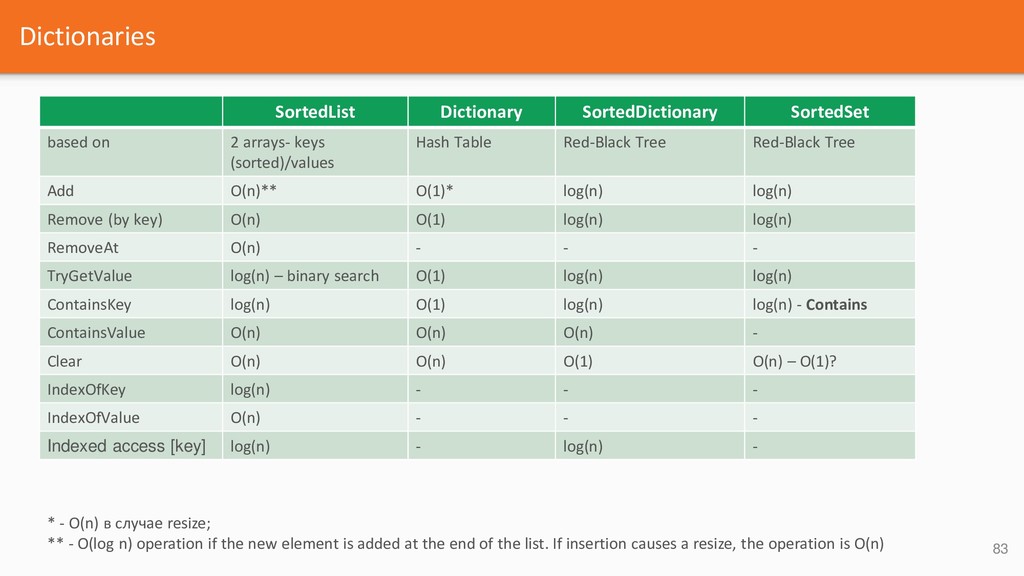{kind=link}
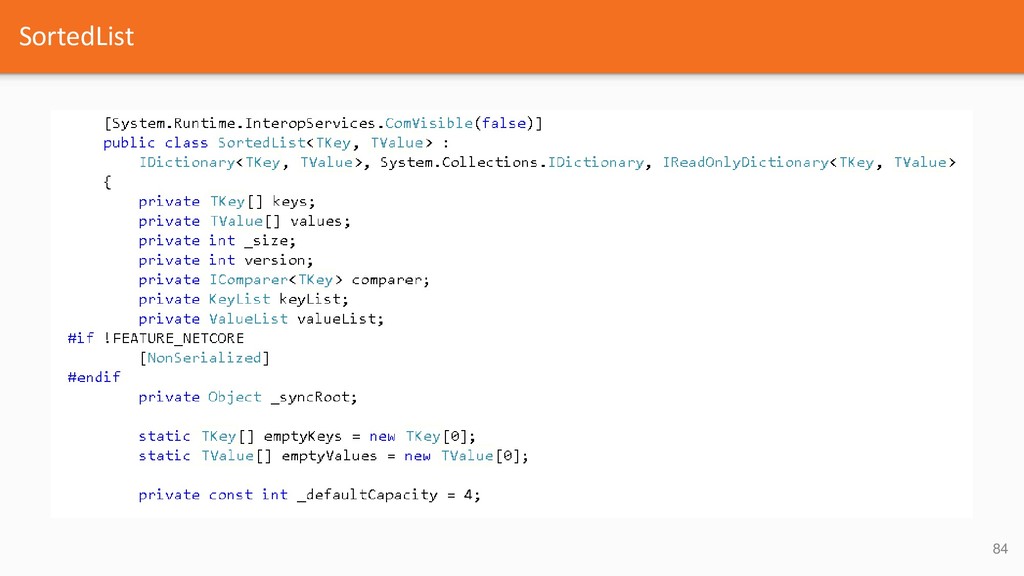{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
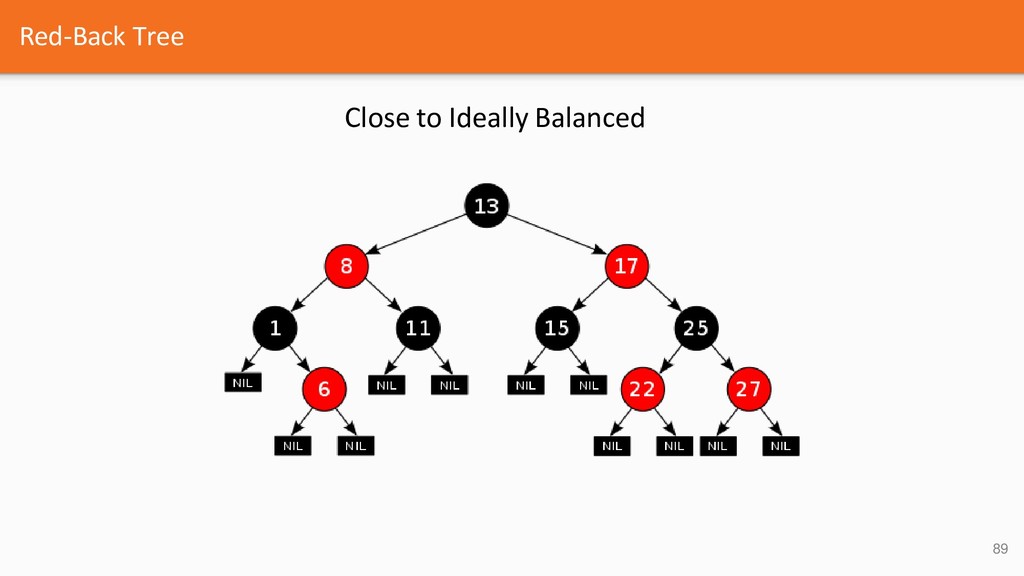{kind=link}
{kind=link}
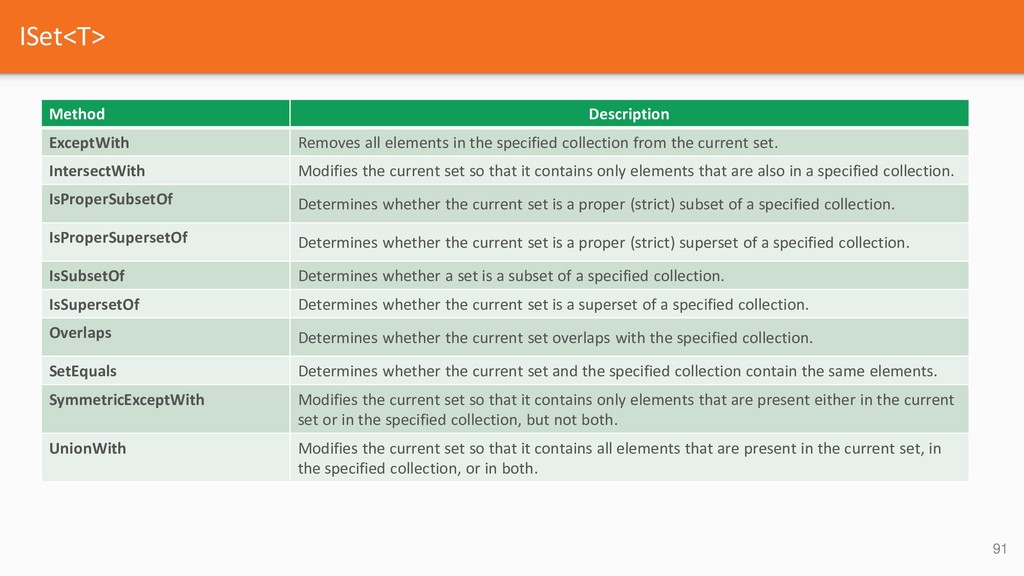{kind=link}
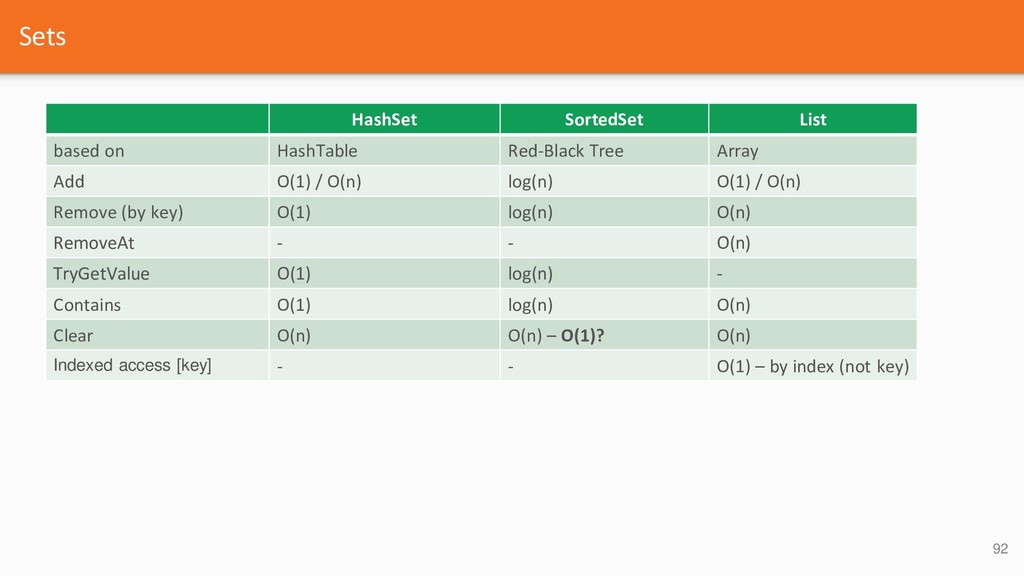{kind=link}
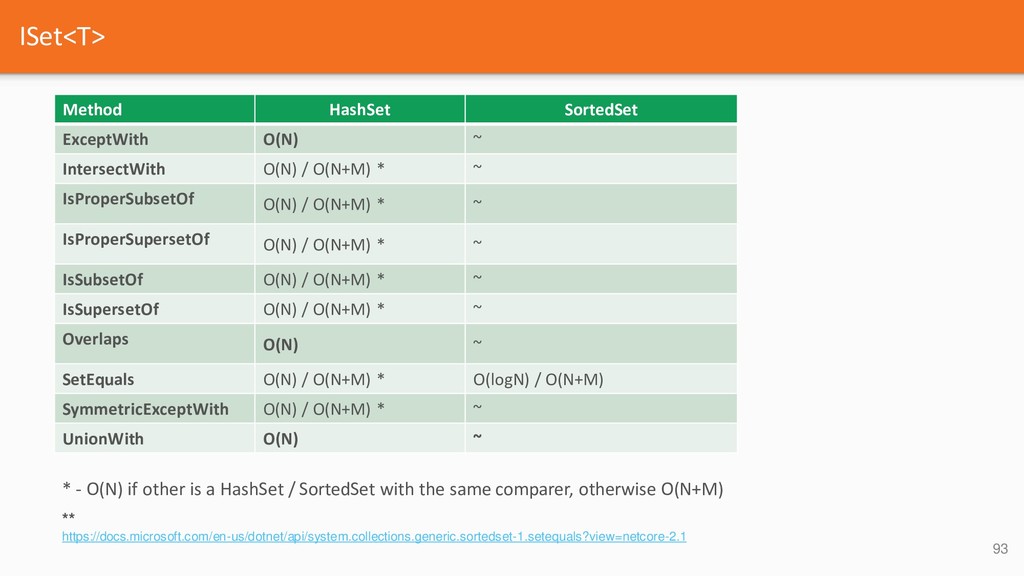{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}