Qian, Hang Li, Daxin Jiang, Jian Pei, and Qinghua Zheng http://research.microsoft.com/apps/pubs/default.aspx?id=168006 International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR) 2012 2013-04-24 輪講資料
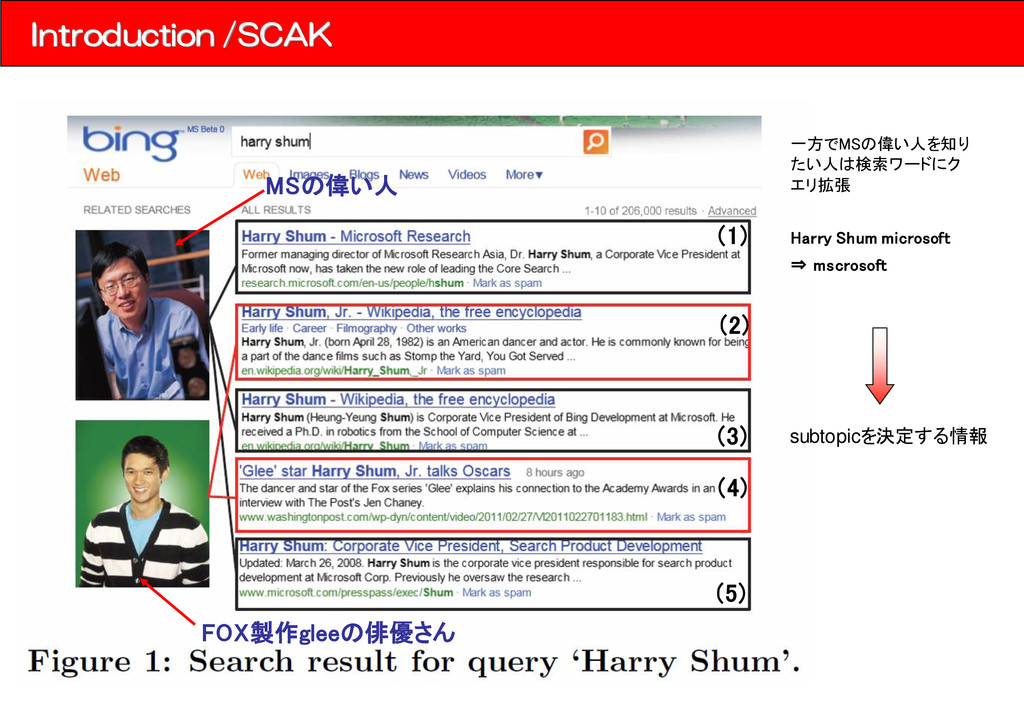
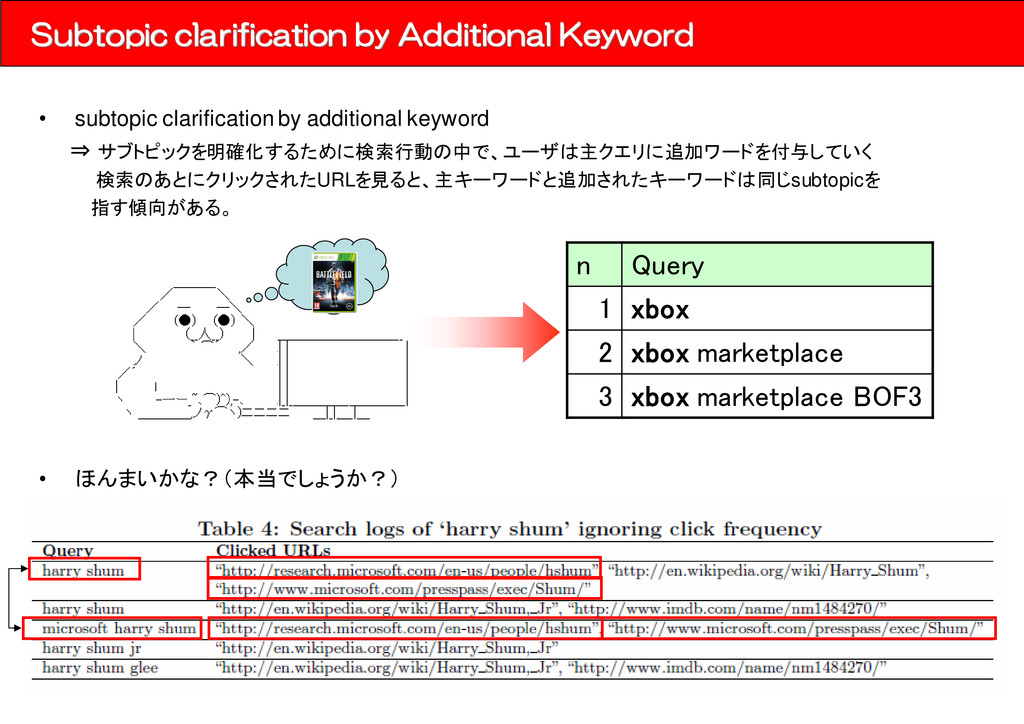
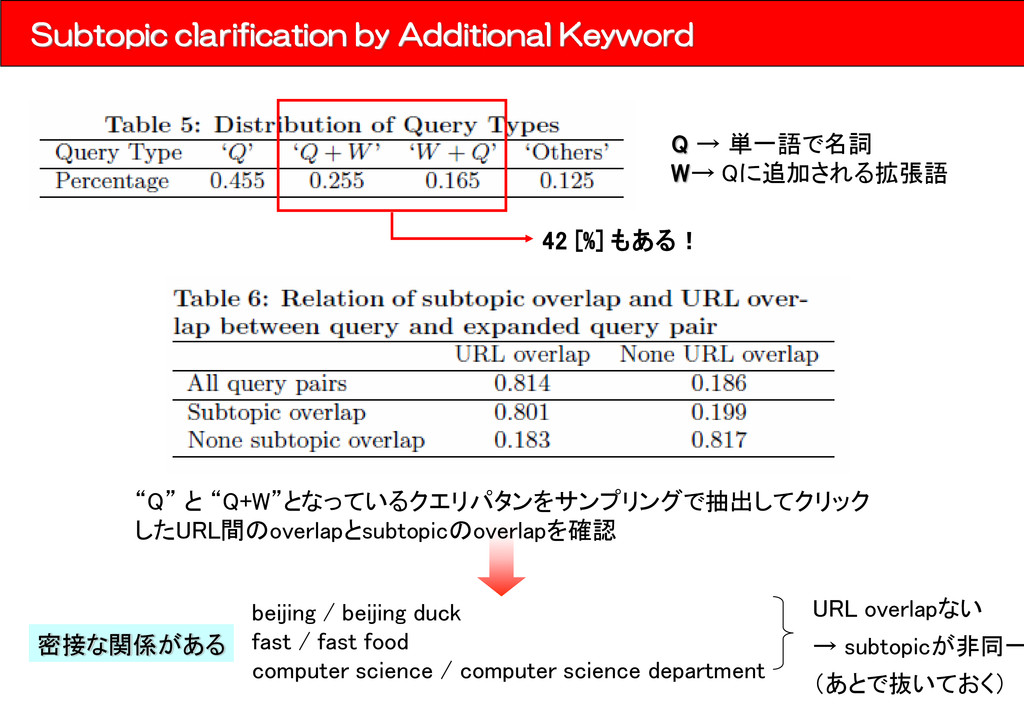
keyword ⇒ サブトピックを明確化するために検索行動の中で、ユーザは主クエリに追加ワードを付与していく 検索のあとにクリックされたURLを見ると、主キーワードと追加されたキーワードは同じsubtopicを 指す傾向がある。 n Query 1 xbox 2 xbox marketplace 3 xbox marketplace BOF3 • ほんまいかな?(本当でしょうか?)
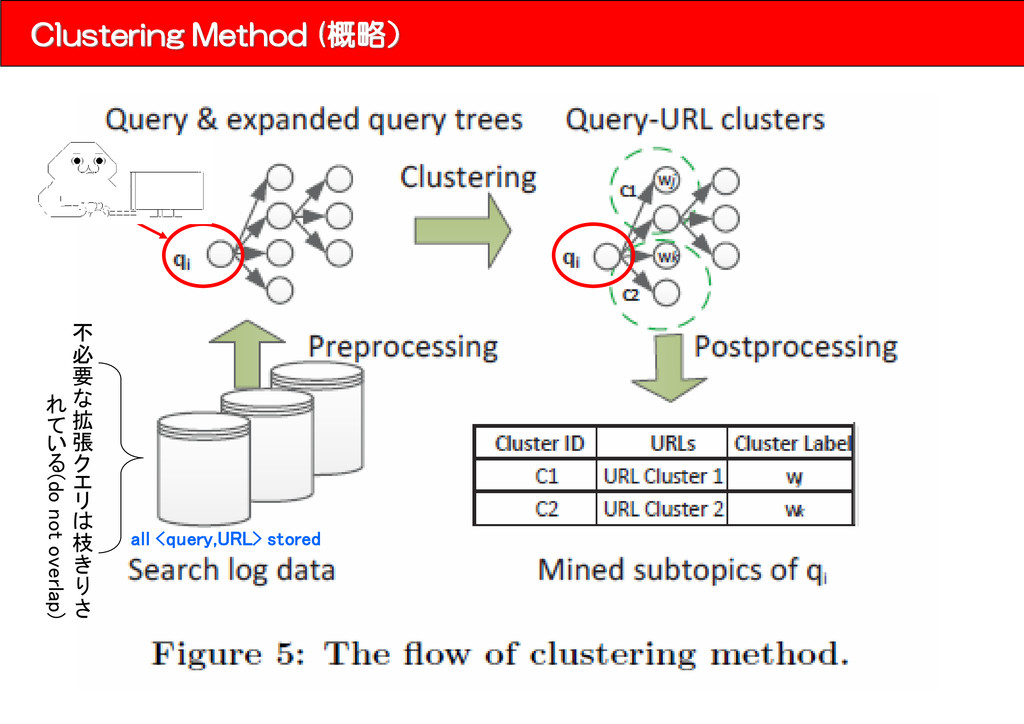
each query and its expanded queries. ▪Similarity Function S1 is a similarity function based on the OSS phenomenon, S2 is based on the SCAK phenomenon, S3 is based on string similarities, with α, β, and γ as weights. OSS term SCAK term string sim term ▪S1(OSS) term ui: http://www.a.com/ http://www.b.com/: 2 http://www.c.com/: 23 http://www.d.com/: 10 http://www.e.com/: 20 ユーザ検索にてある検索ワードで共起したURL集合(mui)
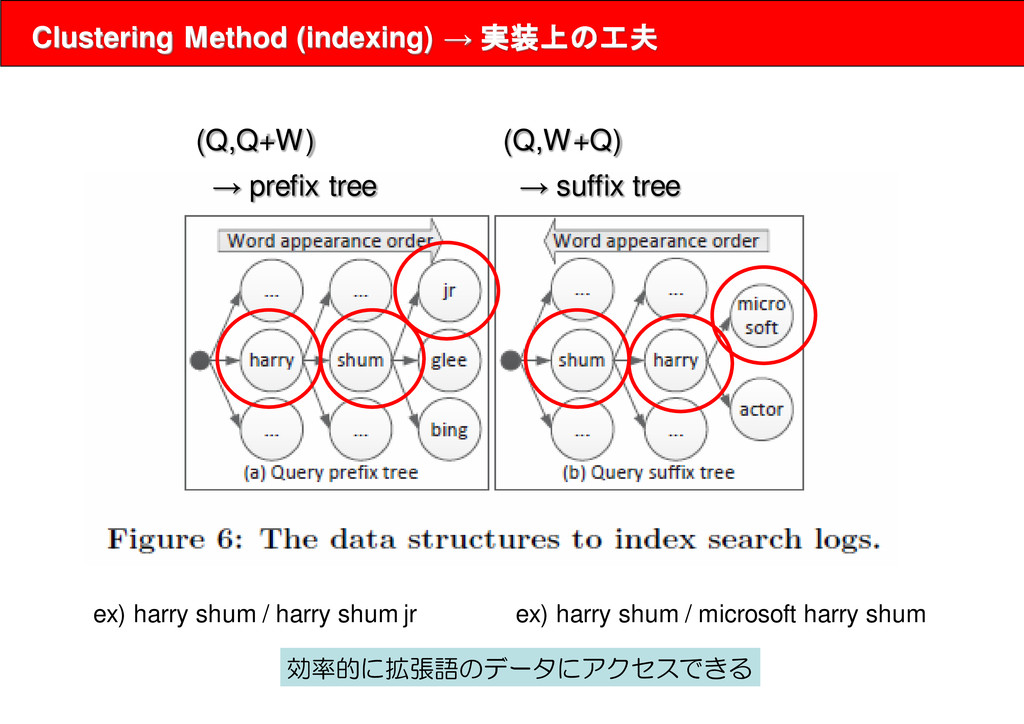
the vectors of keywords associated with ui and uj. u1 keywords vector given by this value u1 = {q=>1.0,q+w1=>1.0,w2+q=>1.0} ▪S3(string) term ui,ujの文字列としての類似度を計量しているが、 少しややこしいことをしているようだ。 ↓ M. Kan and H. Thi. Fast webpage classification using url features. In Proceedings of the 14th ACM ※ URLの表記情報からURLのrelevancyを推定する。 feature -> URLの長さや、URIのcomponent ※ 詳しく読めてない、興味ある人読んだら教えて。 ▪クラスタリングのアルゴリズム 階層的クラスタリング(凝集型)でやる。
を考慮して検索された結果(URL)をグルーピングし提示する。 ※この研究は先行研究が沢山なされており、Wang and Zhai’s[1] の研究を baselineとして比較する。 [1] X. Wang and C. Zhai. Learn from web search logs to organize search results. In Proceedings SIGIR'07,pages 87–94, 2007. 5.4% interms of B-cubed precision, 6.1% in terms of B-cubed recall, 5.9% in terms of B-cubed F1
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
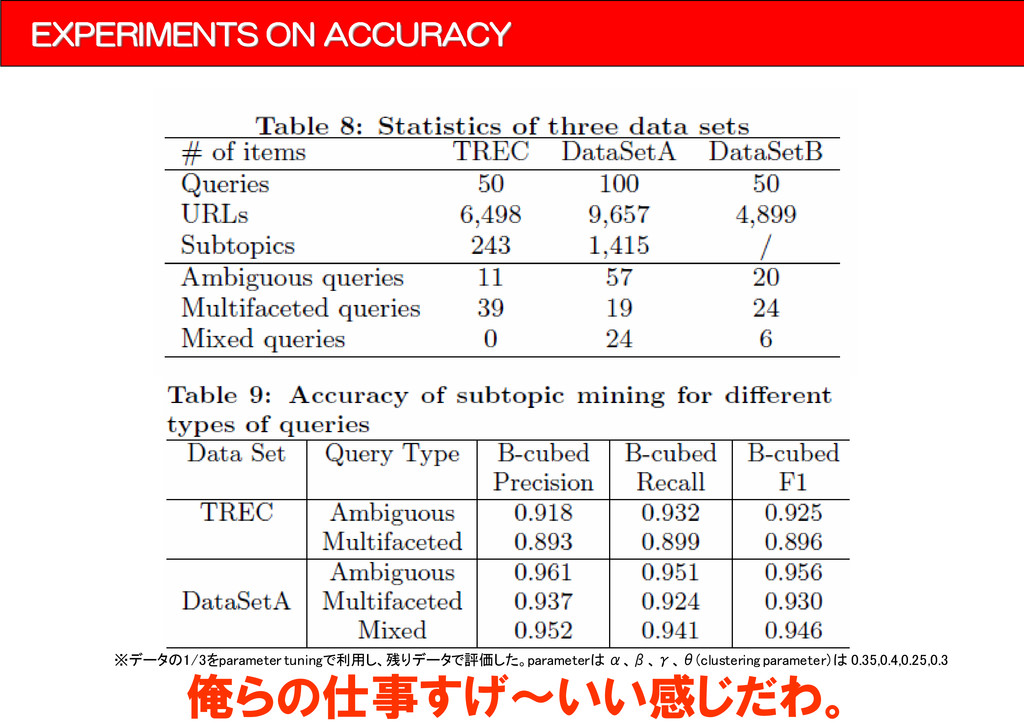{kind=link}
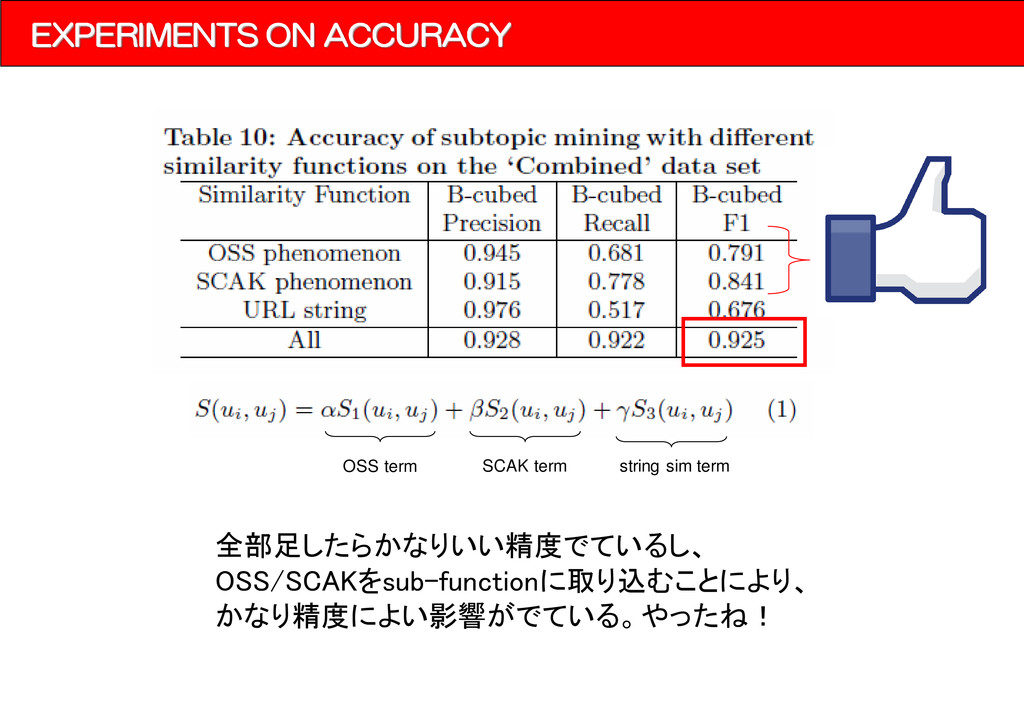{kind=link}
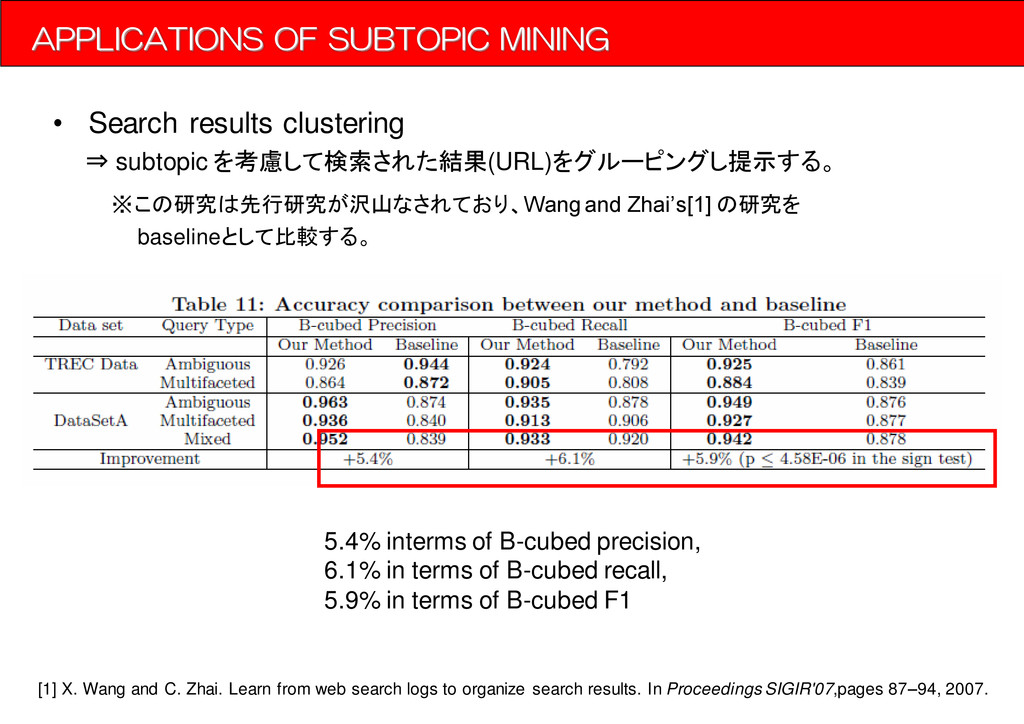{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}