(всего пользователей — 𝑁, 𝑖 = 1 … 𝑁). • 𝑎 — предметы (сайты, товары, фильмы...), которые рекомендуются (всего — 𝑀, 𝑎 = 1 … 𝑀). • Пользователь 𝑖 оценивает предмет 𝑎, он производит отклик 𝑟𝑖,𝑎 [отклик = случайная величина]. • Задача — предсказывать оценки 𝑟𝑖,𝑎 , зная признаки 𝑥𝑖 и 𝑥𝑎 для всех элементов базы и зная некоторые уже расставленные в базе 𝑟𝑖′,𝑎′ . Предсказание будем обозначать через Ƹ 𝑟𝑖,𝑎 .
Для каждого 𝑐 выделяется тот контекст, который он будет учитывать для вынесения оценок. Например, в Adamic/Adar это будет просто список друзей. • Map. «Спрашиваем» у каждого 𝑐, что он думает про возможность дружбы в каждой паре его друзей. По сути, вычисляем 𝑒𝑧𝑐 (𝑢, 𝑣) и сохраняем в виде (𝑢, 𝑣) → 𝑒𝑧𝑐 (𝑢, 𝑣) для всех 𝑢, 𝑣 𝑖𝑛 𝑁(𝑐). В случае Adamic/Adar: (𝑢, 𝑣) → 1/log |𝑁(𝑐)|. • Reduce. Для каждой пары (𝑢, 𝑣) суммируем все соответствующие ей значения. Их будет ровно столько, сколько общих друзей у 𝑢 и 𝑣.
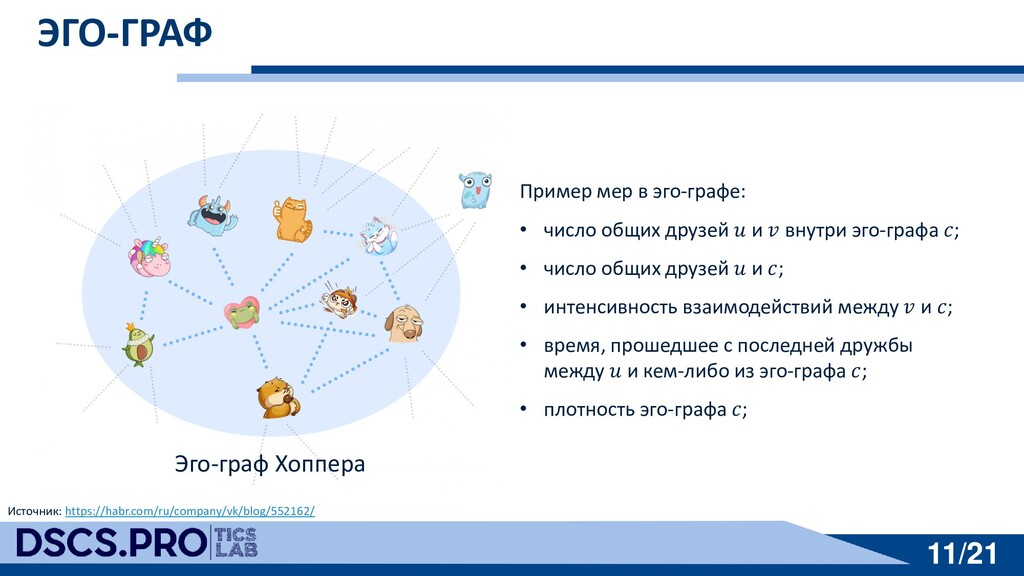
друзей 𝑢 и 𝑣 внутри эго-графа 𝑐; • число общих друзей 𝑢 и 𝑐; • интенсивность взаимодействий между 𝑣 и 𝑐; • время, прошедшее с последней дружбы между 𝑢 и кем-либо из эго-графа 𝑐; • плотность эго-графа 𝑐; Эго-граф Хоппера Источник: https://habr.com/ru/company/vk/blog/552162/
пары пользователей 𝑢 и 𝑣, а также их общего друга 𝑐, посчитаны меры(признаки) по эго-графу 𝑐; • пара пользователей 𝑢 и 𝑣 встречается в наборе данных ровно столько раз, сколько у них общих друзей; • все пары пользователей в наборе данных не являются друзьями на момент времени 𝑇; • для каждой пары 𝑢 и 𝑣 проставлена метка — подружились ли они в течение определённого промежутка времени начиная с 𝑇. Источник: https://habr.com/ru/company/vk/blog/552162/
все открытия окон, просмотры видео в группах, клики в ленте и просмотры постов в ленте (число и длительность просмотра). • Собираем явный фидбек: классы, решары, комменты. • С негативным весом добавляем скрытия контента, выход из групп, отписки от групповых оповещений. • Нормализуем взаимодействия на количество показов контента (исключаем перекос активно постящих групп). • Взвешиваем по типу контента, учитывая то, насколько давно пользователь ознакомился с группой (уменьшаем вес случайным действиям). • Нормализуем веса групп во вкусах пользователей. Эти веса и будут весами ребер графа на первом шаге обхода графа.
мощности и качества групп при формировании графа по сравнению с оригинальным подходом дали: •x4 к числу групп в рекомендациях; •x13 вступлений в группы численностью менее 1к пользователей; •+30% к общим вступлениям в групп
![17 сентября 2021 [email protected], [email protected] Олисеенко Валерий Дмитриевич Ассистент кафедры](https://files.speakerdeck.com/presentations/72a1cc9347f34686bc237d1c6f2a4691/slide_0.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
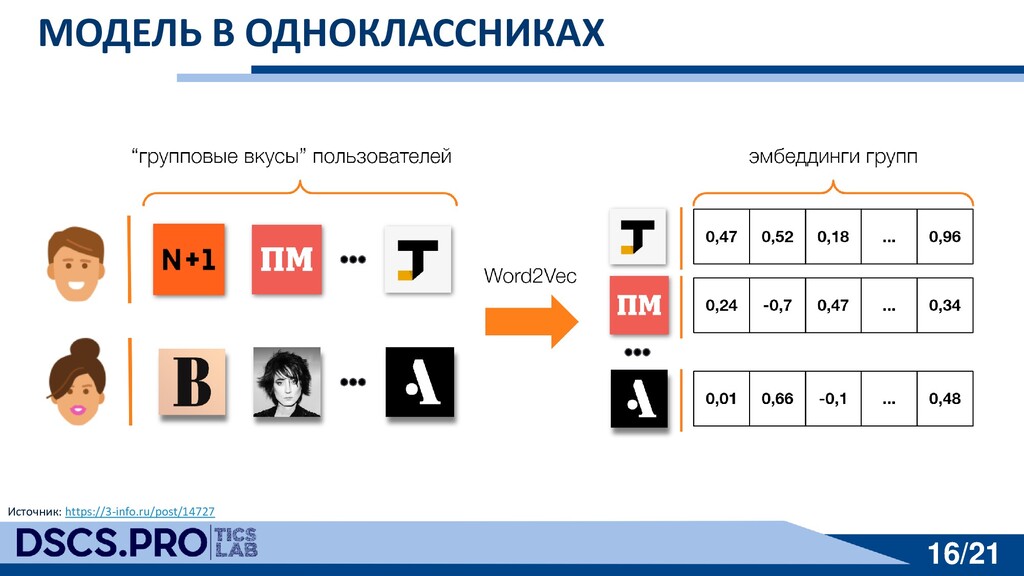{kind=link}
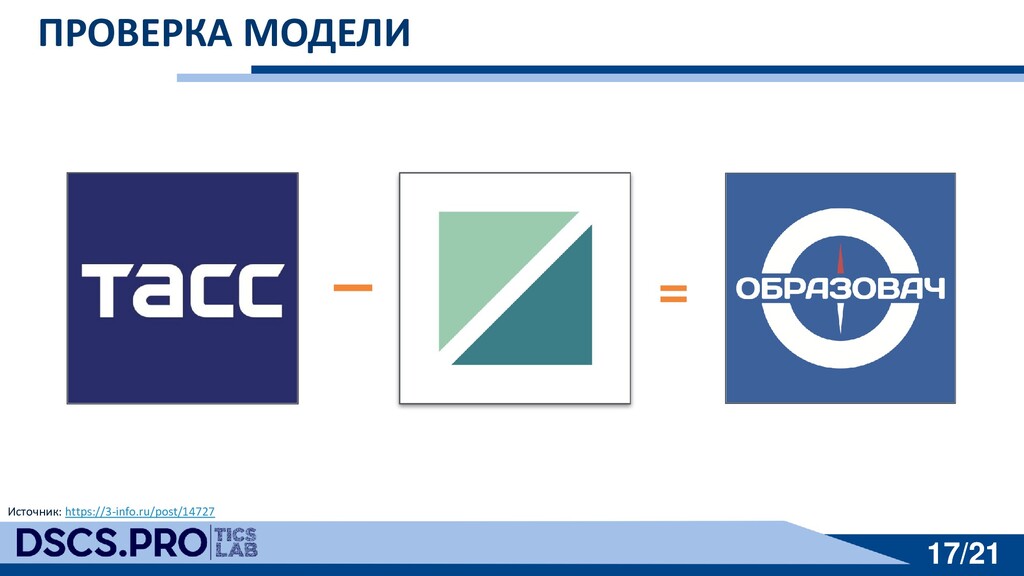{kind=link}
{kind=link}
{kind=link}
{kind=link}
![17 сентября 2021 [email protected], [email protected] Олисеенко Валерий Дмитриевич Ассистент кафедры](https://files.speakerdeck.com/presentations/72a1cc9347f34686bc237d1c6f2a4691/slide_20.jpg){kind=link}