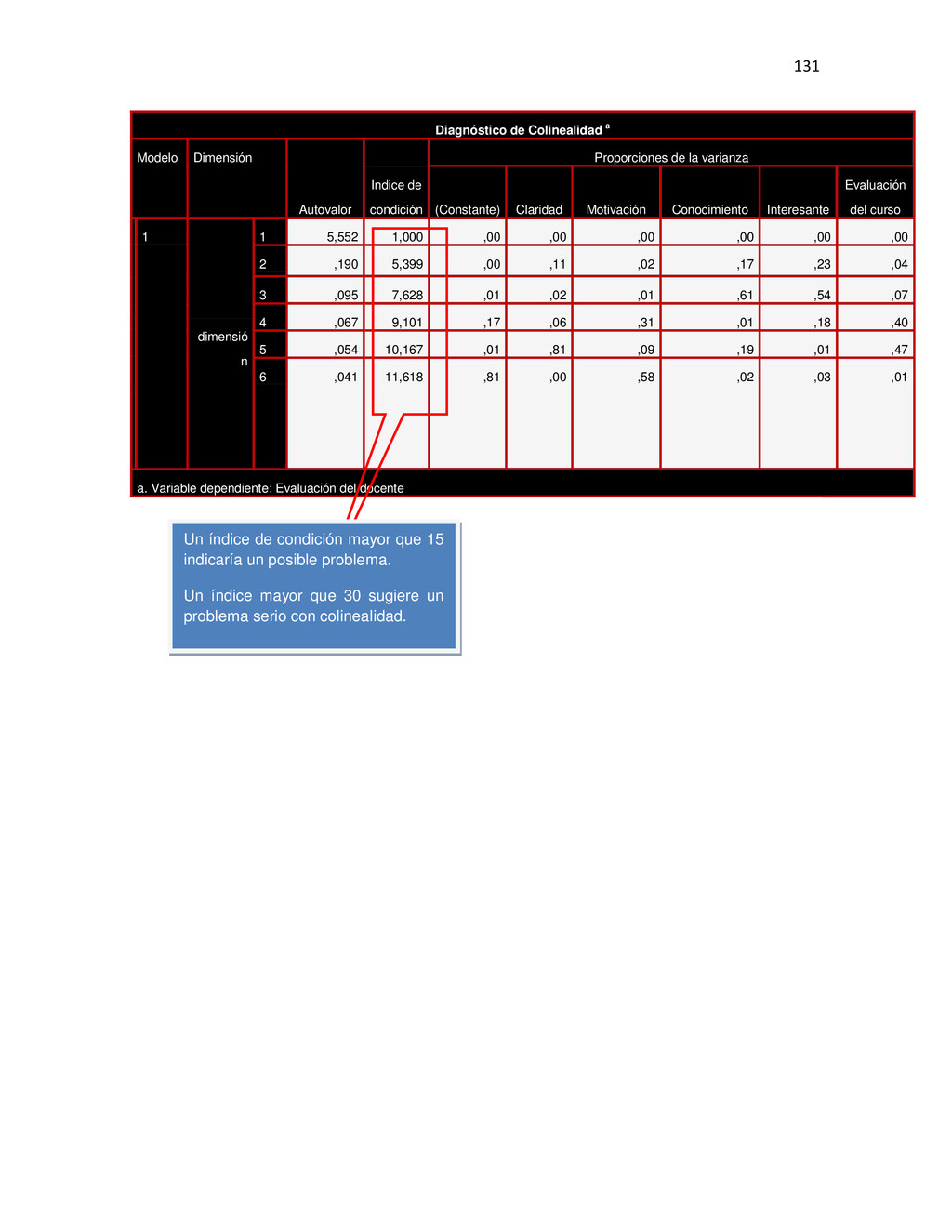
Estadísticos colinealidad B Error típ. Beta Tolerancia FIV 1 (Constant) -,182 ,281 -,649 ,522 Claridad ,495 ,075 ,689 6,582 ,000 ,651 1,536 Motivación ,076 ,076 ,099 1,007 ,323 ,744 1,345 Conocimiento ,169 ,105 ,158 1,617 ,118 ,744 1,344 Interesante ,272 ,098 ,263 2,779 ,010 ,798 1,254 Evaluación del curso ,074 ,089 ,088 ,827 ,416 ,638 1,569 Diagnóstico de Colinealidad a Modelo Dimensión Autovalor Indice de condición Proporciones de la varianza (Constante) Claridad Motivación Conocimiento Interesante Evaluación del curso d i m e n s i o n 0 1 dimensió n 1 5,552 1,000 ,00 ,00 ,00 ,00 ,00 ,00 2 ,190 5,399 ,00 ,11 ,02 ,17 ,23 ,04 3 ,095 7,628 ,01 ,02 ,01 ,61 ,54 ,07 4 ,067 9,101 ,17 ,06 ,31 ,01 ,18 ,40 5 ,054 10,167 ,01 ,81 ,09 ,19 ,01 ,47 6 ,041 11,618 ,81 ,00 ,58 ,02 ,03 ,01 Los coeficientes estandarizados se usan para comparar los efectos de las variables independientes Se comparar la Sig. Con alfa 0,05. Si Sig < 0,05 el coeficiente es estadísticamente significativo
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
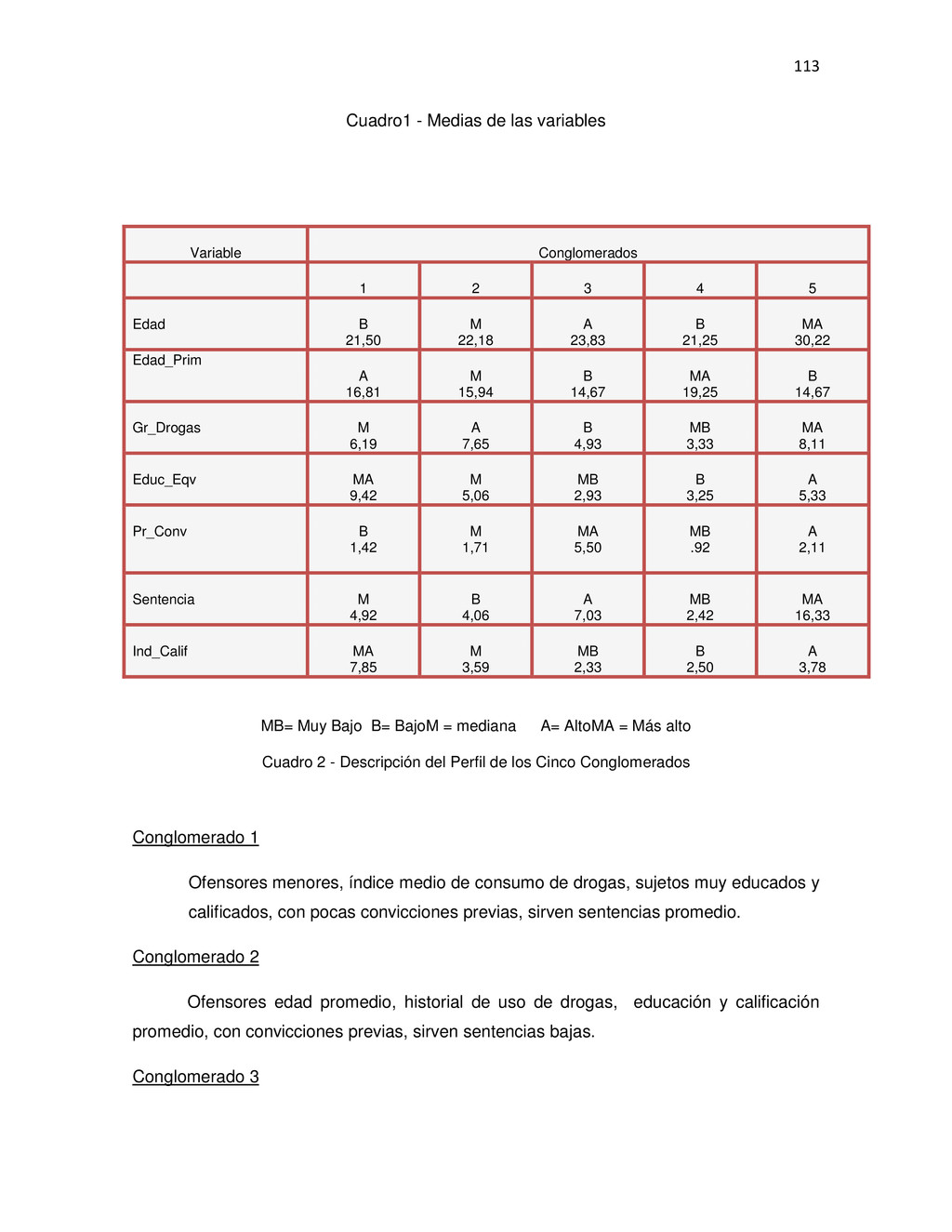{kind=link}
{kind=link}
{kind=link}
{kind=link}
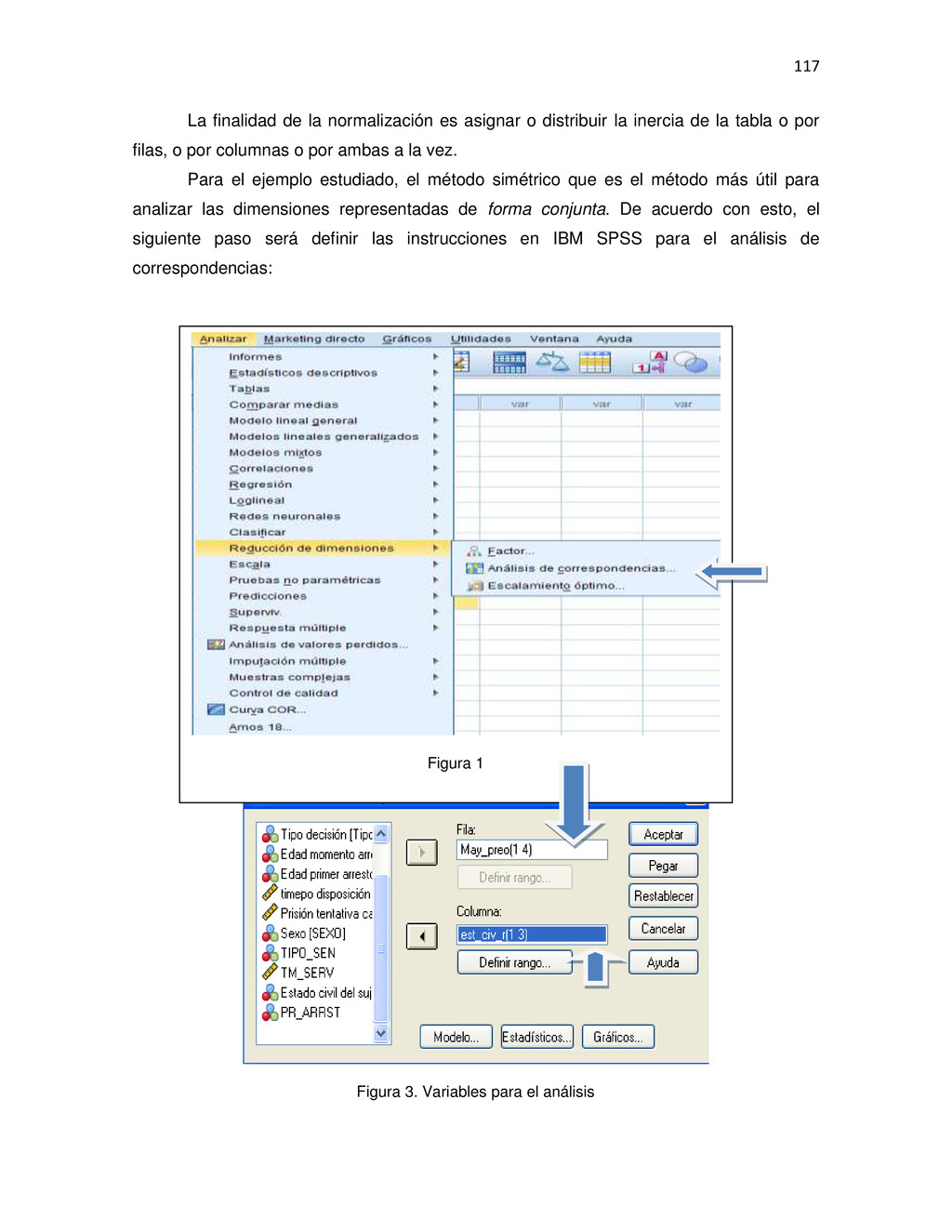{kind=link}
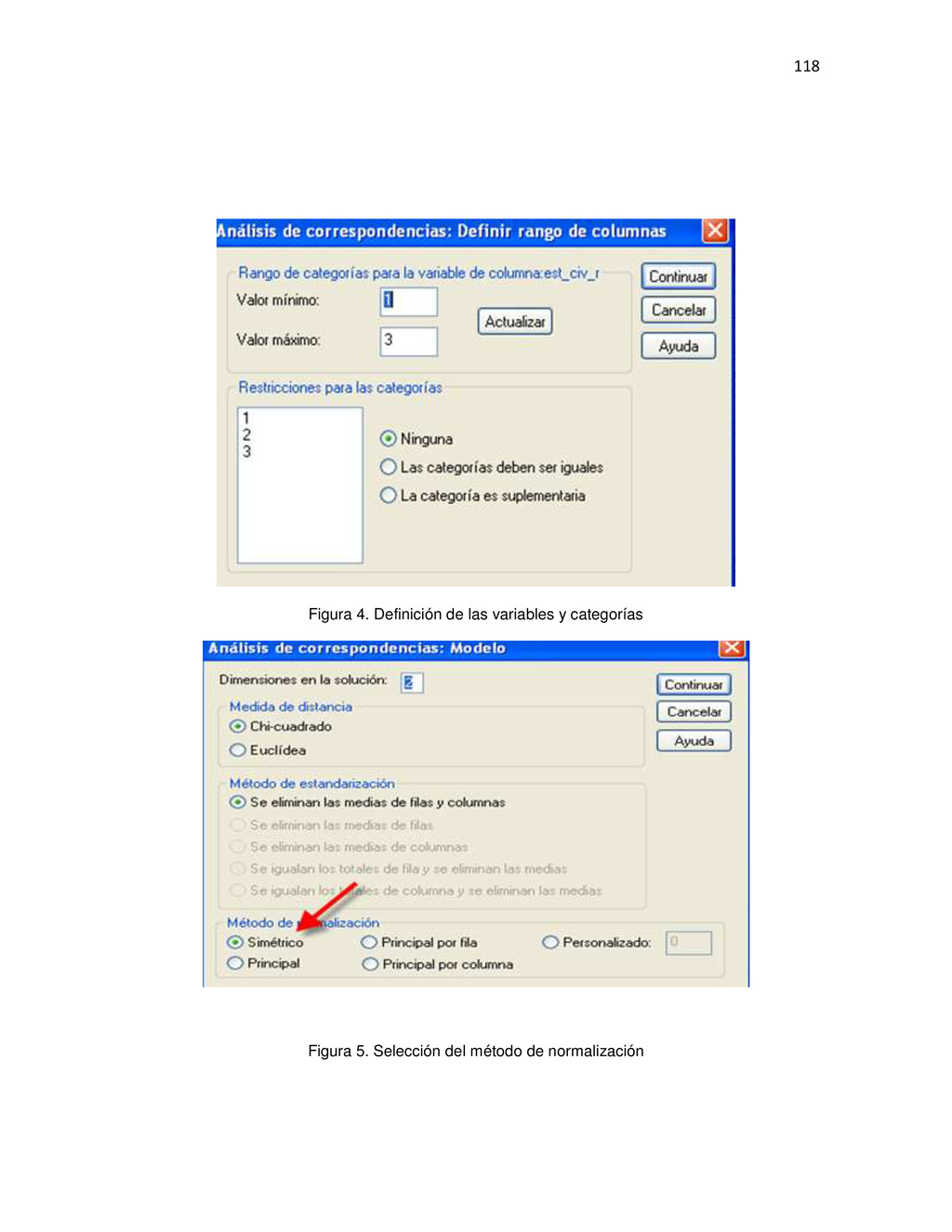{kind=link}
{kind=link}
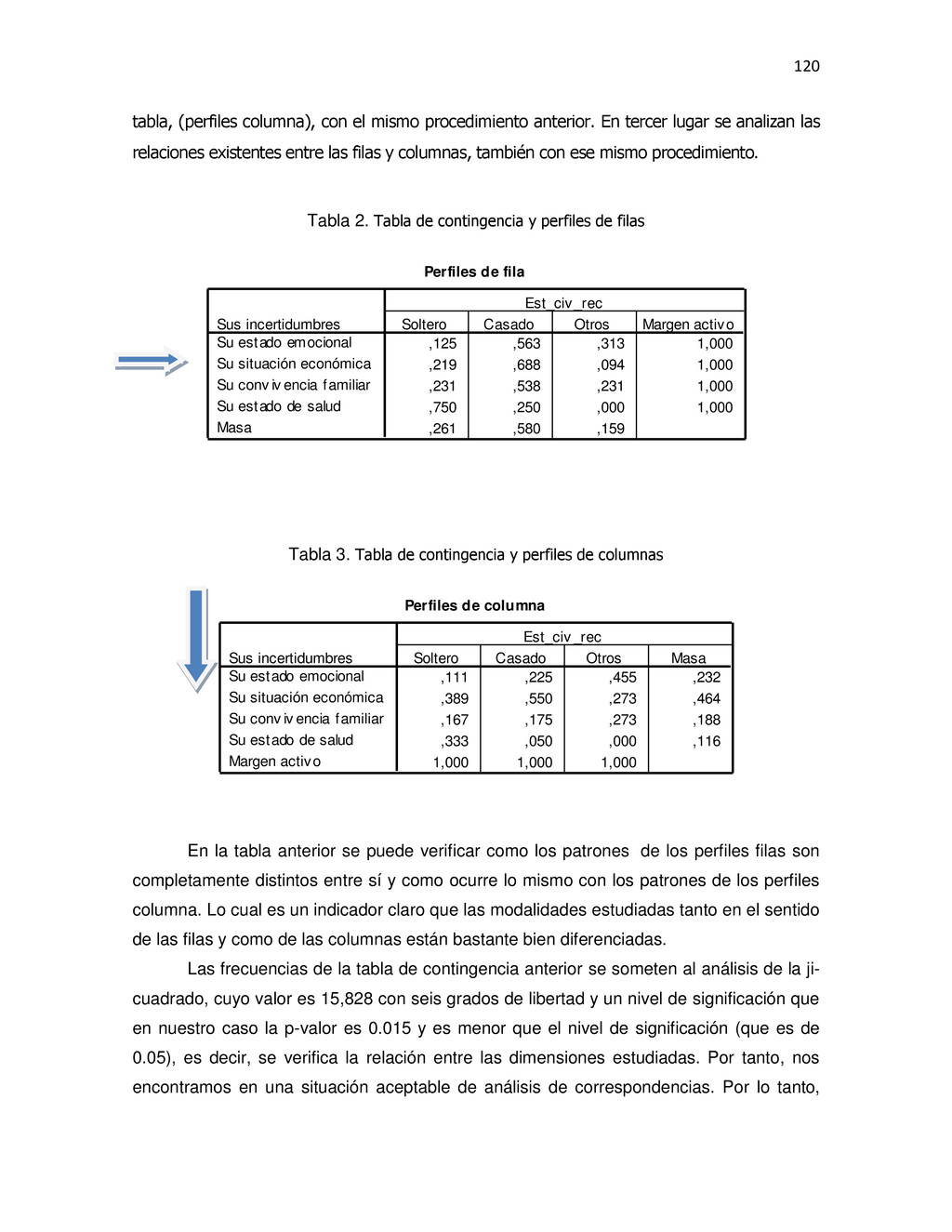{kind=link}
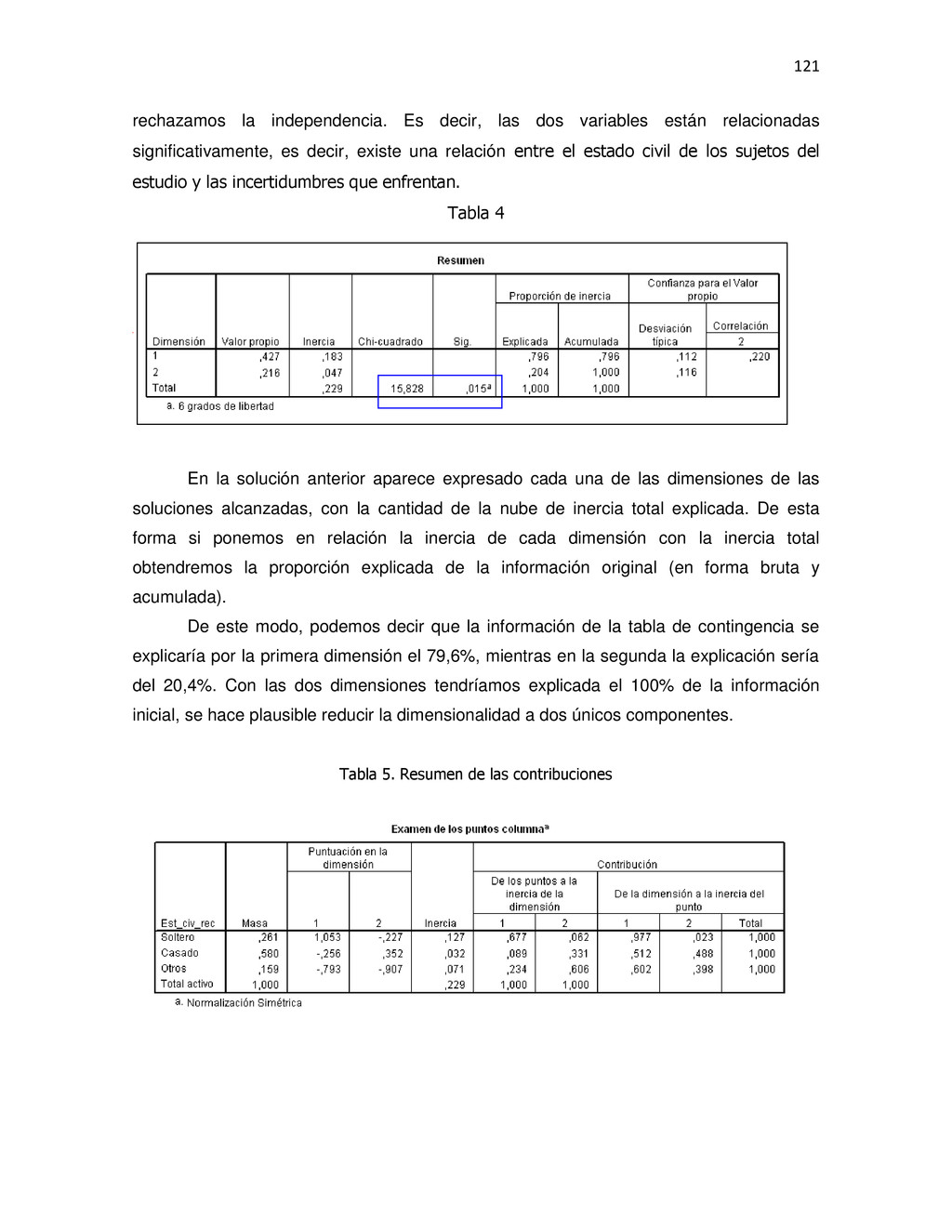{kind=link}
{kind=link}
{kind=link}
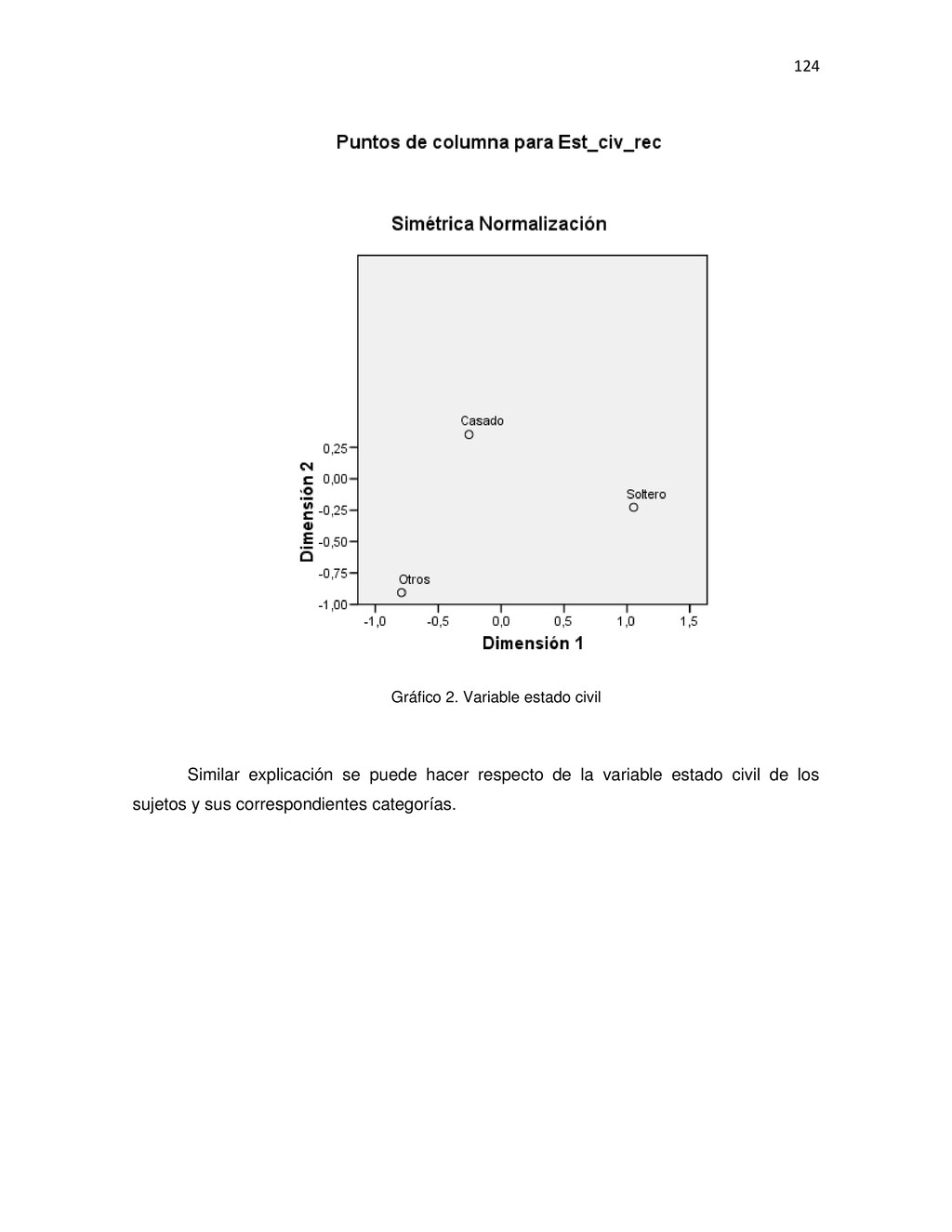{kind=link}
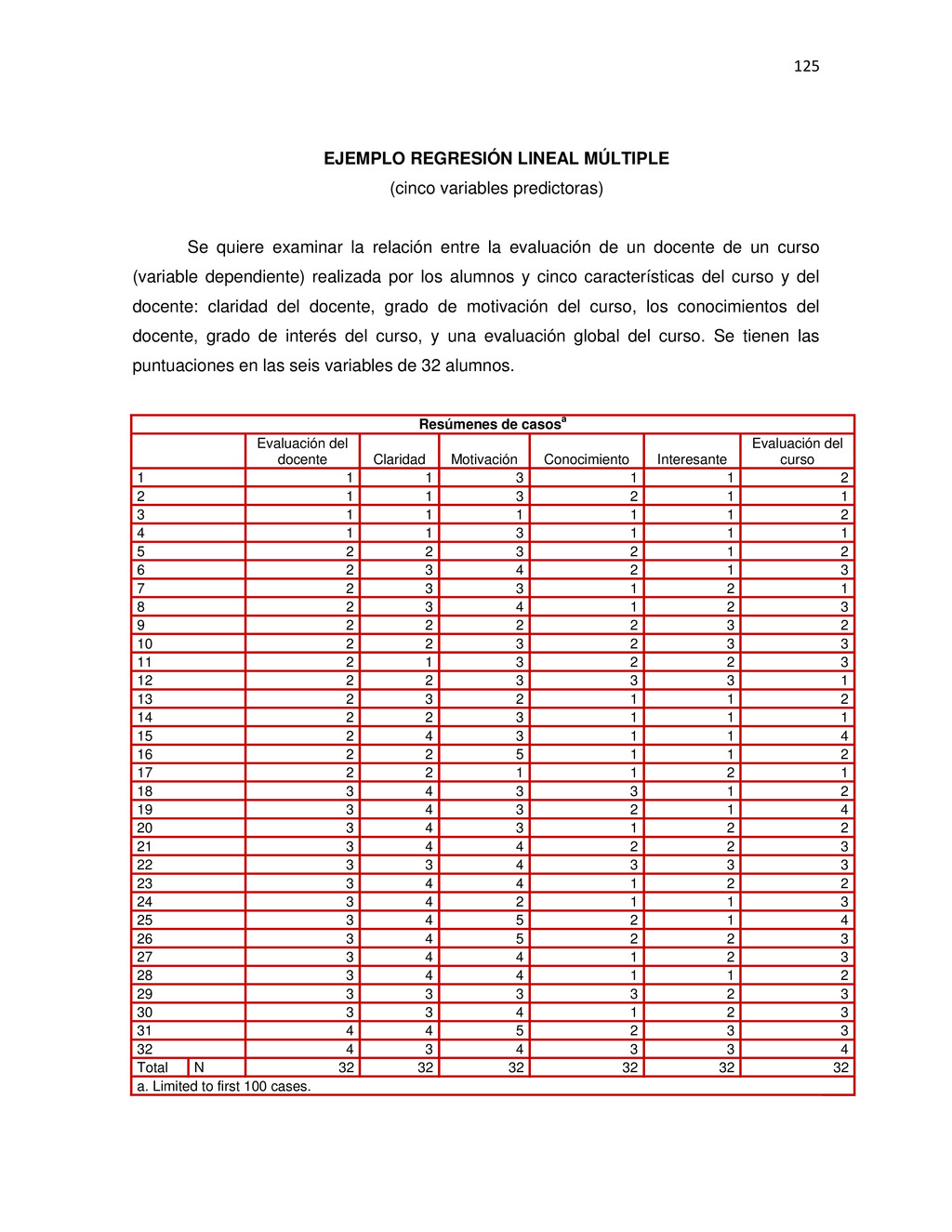{kind=link}
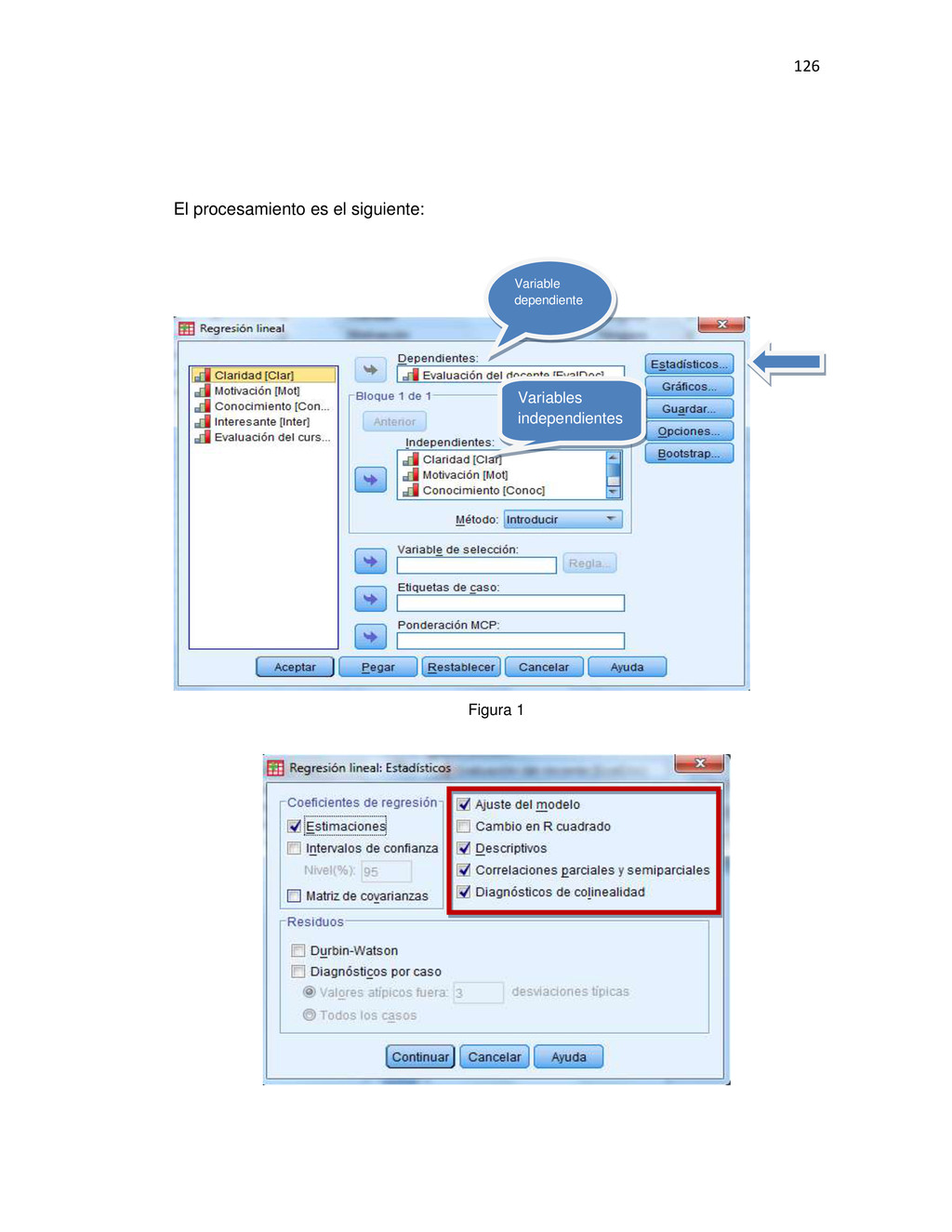{kind=link}
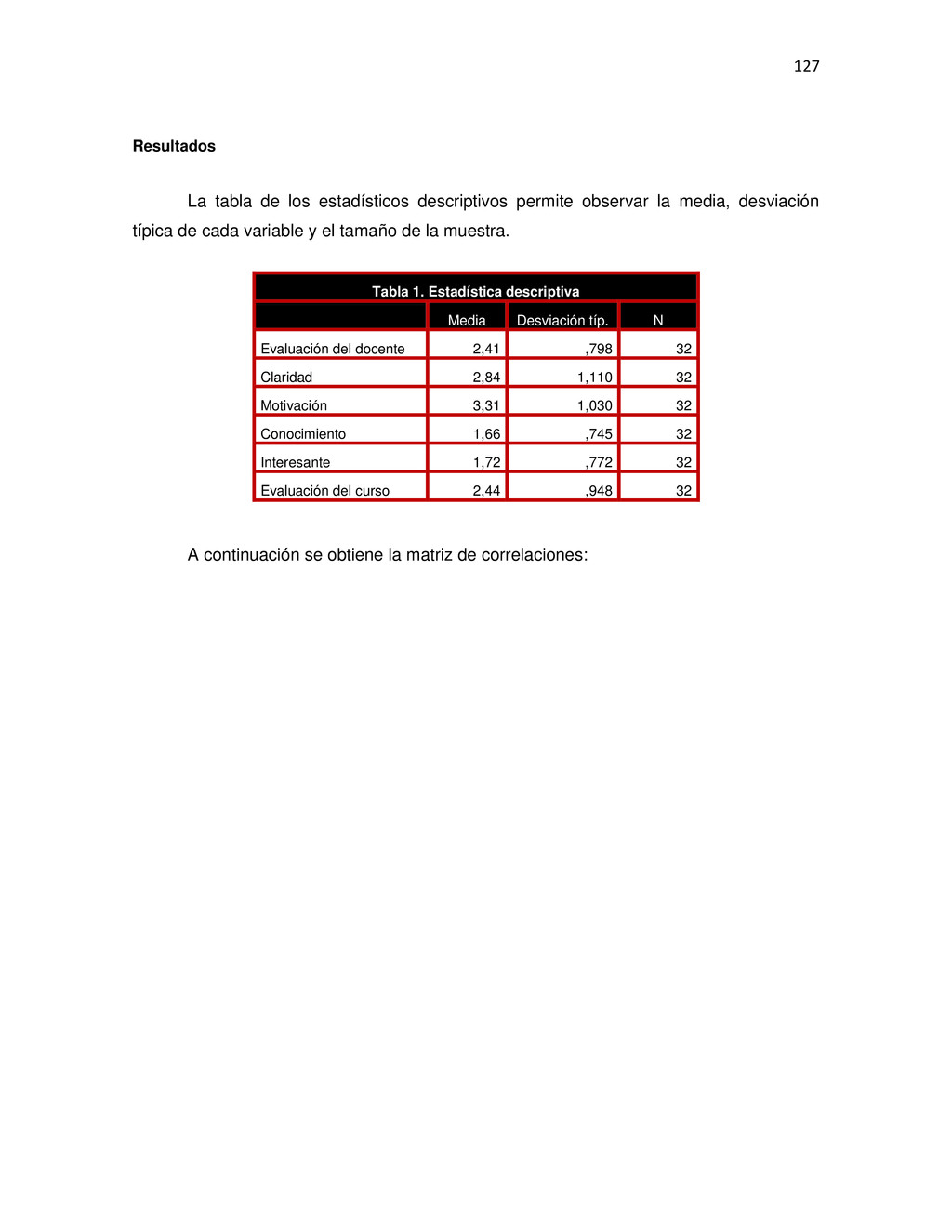{kind=link}
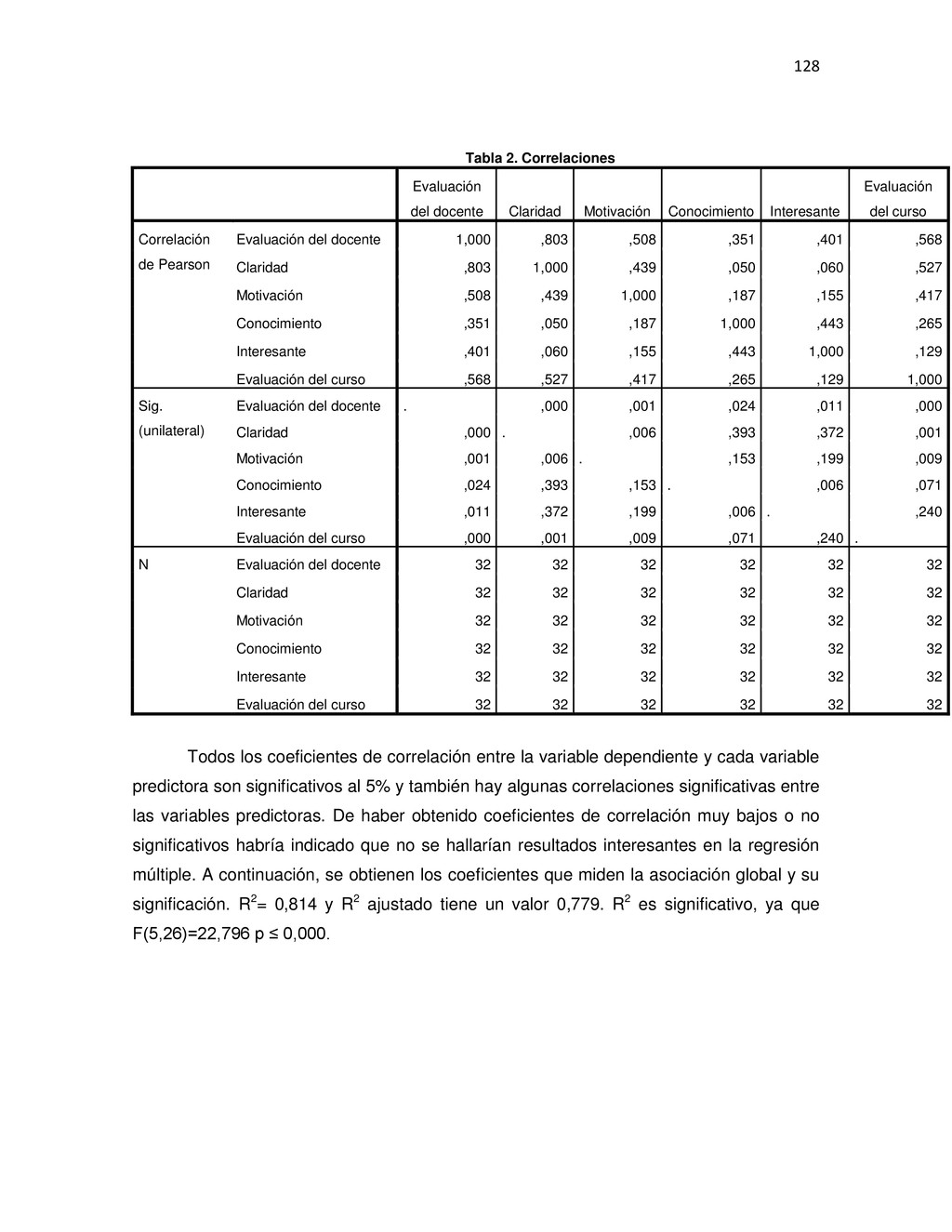{kind=link}
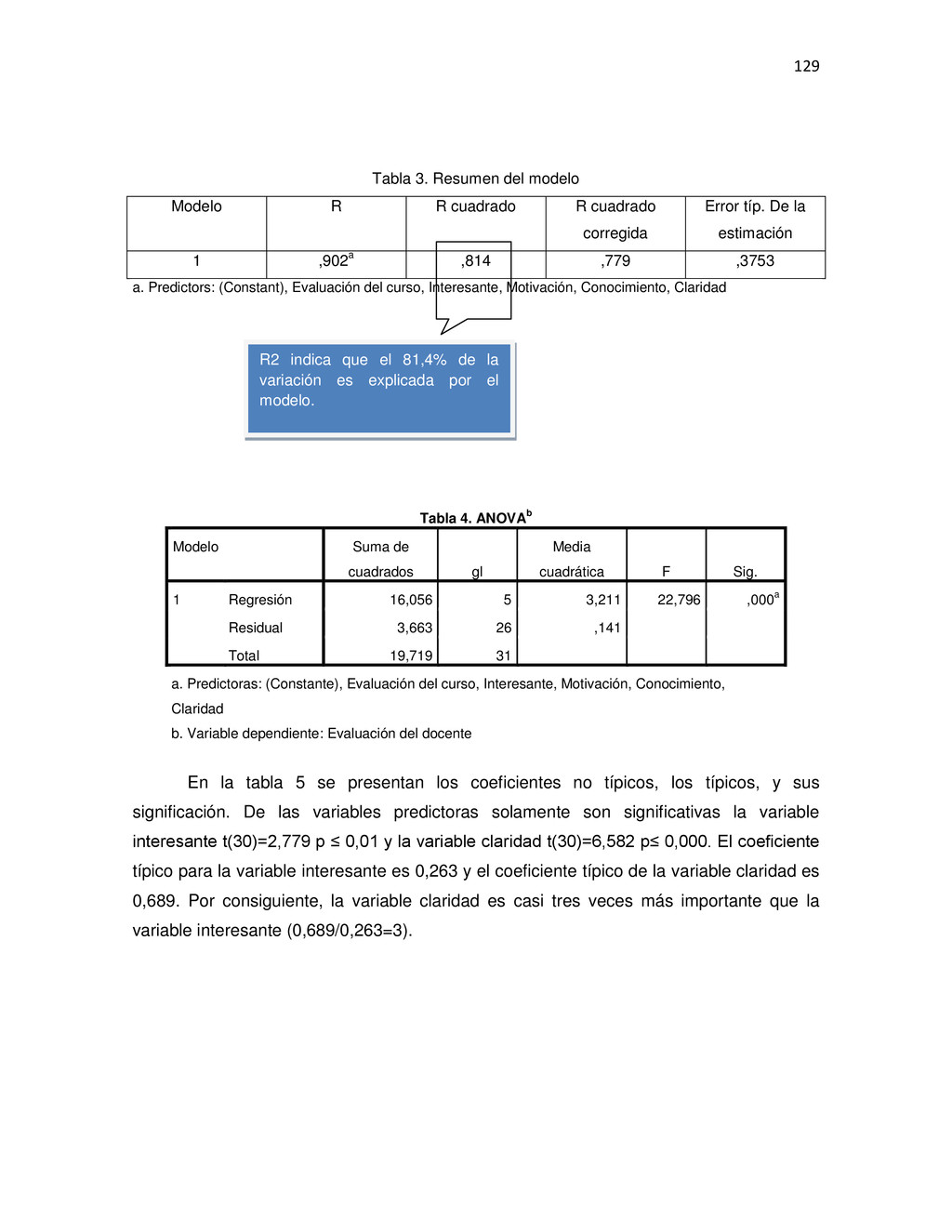{kind=link}
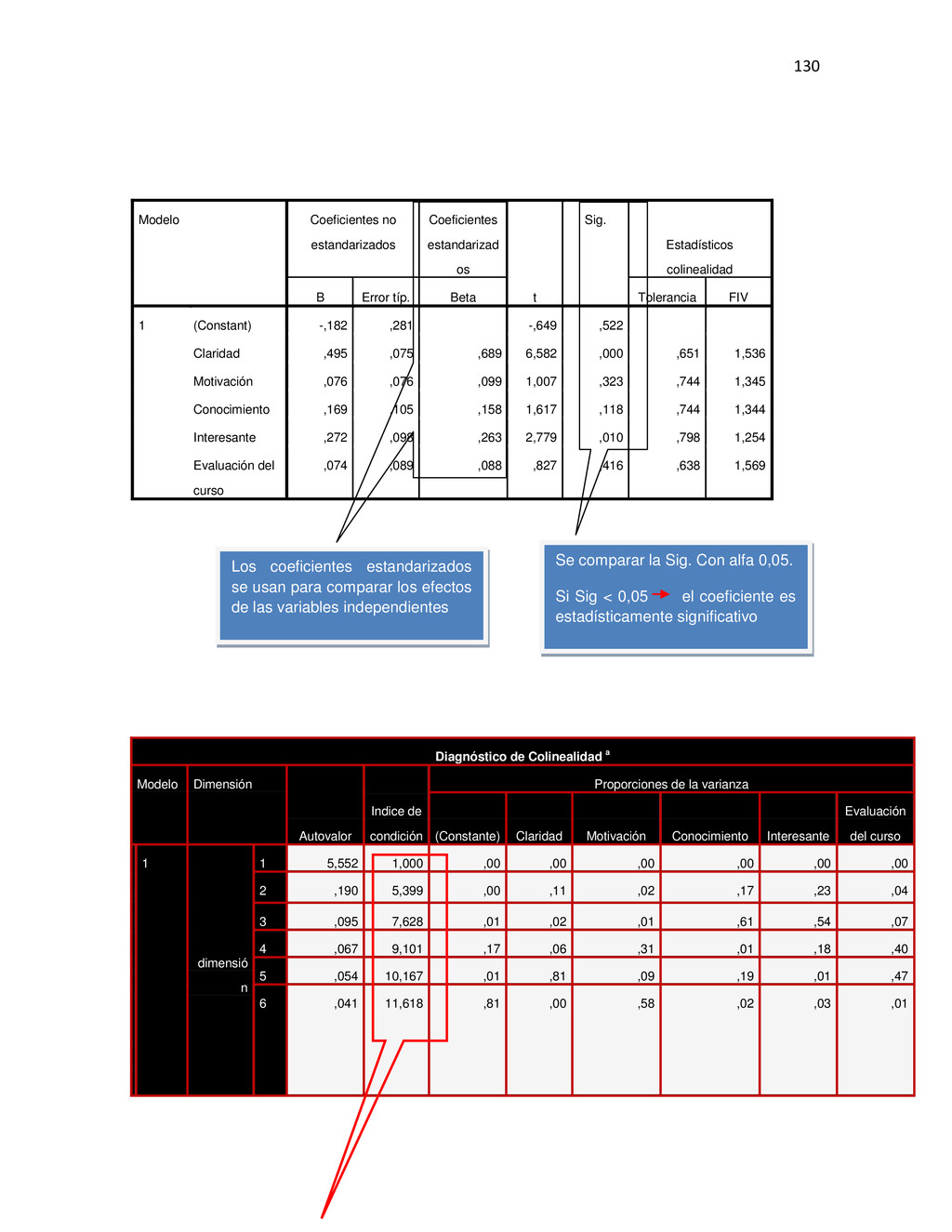{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}