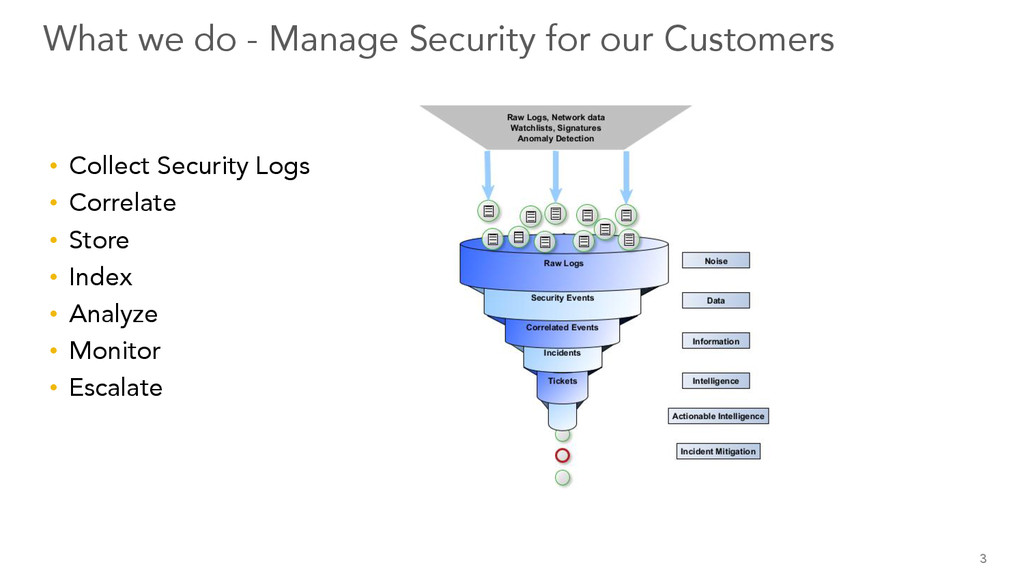
Verizon Managed Security Services (MSS) manages security for our customers dealing with security data collected from firewalls, ids/ips, proxy, and network/backbone. This presentation focuses on lessons learned, problems solved, and solutions implemented while running one of largest Elasticsearch clusters out there. Topics include architecture, investigation of various use cases, and best practices while dealing with 1M events per second and 20B events a day.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}