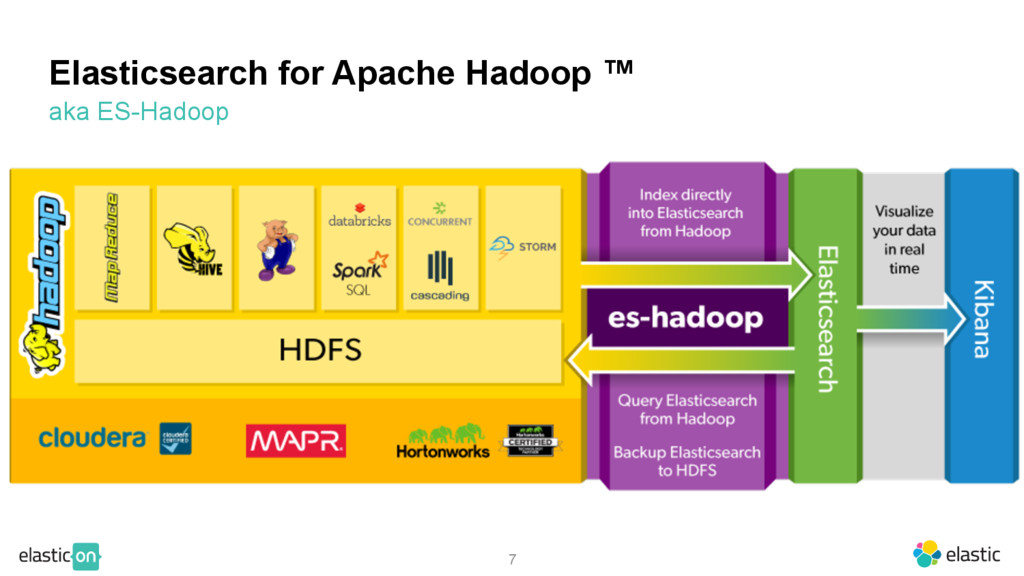
An overview of the Elastic Hadoop ecosystem with a focus on what has happened over the last year with Elasticsearch for Apache Hadoop. You can expect to hear about Apache Storm, Apache Spark, DataFrames, and other Hadoop goodies.
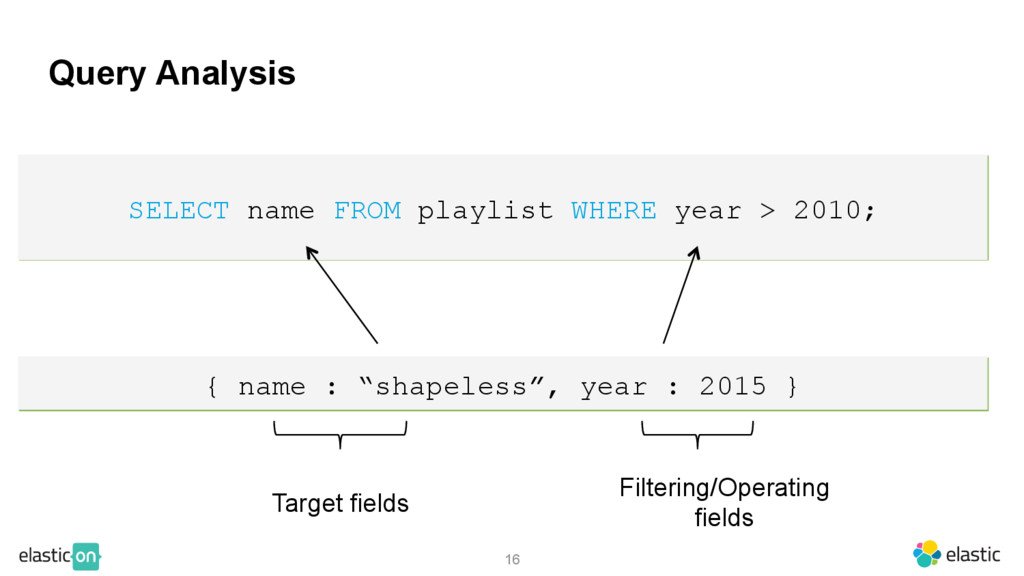
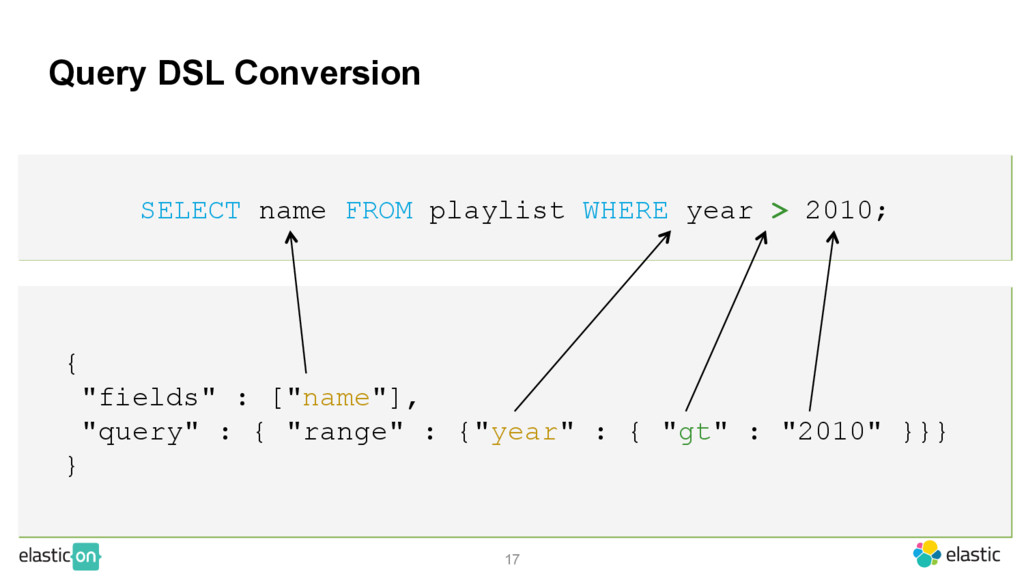
STORED BY 'org.elasticsearch.hadoop.hive.EsStorageHandler' TBLPROPERTIES('es.resource'='buckethead/albums','es.query'='?q=pikes'); SELECT name FROM playlist WHERE year > 2010; CREATE EXTERNAL TABLE playlist(name STRING, year:long) STORED BY 'org.elasticsearch.hadoop.hive.EsStorageHandler' TBLPROPERTIES('es.resource'='buckethead/albums'); INSERT INTO TABLE playlist VALUES ('Buildor', 2016), ('Florrmat', 2016);
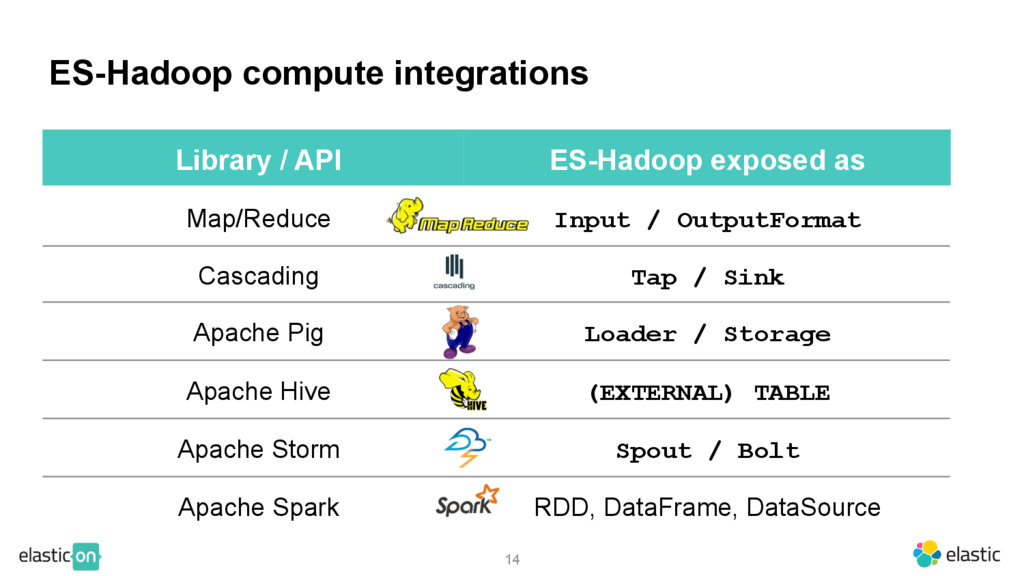
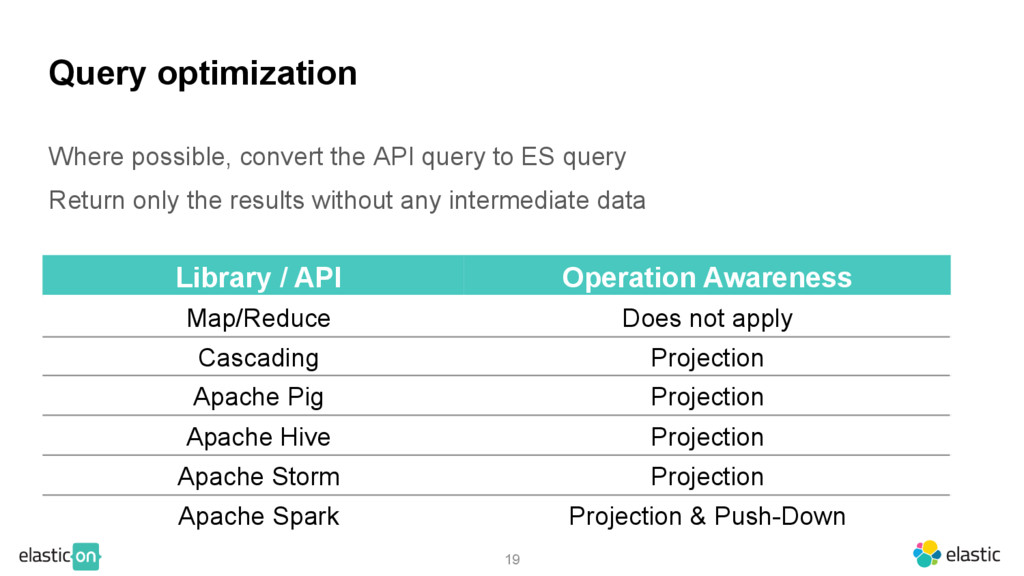
ES query Return only the results without any intermediate data Library / API Operation Awareness Map/Reduce Does not apply Cascading Projection Apache Pig Projection Apache Hive Projection Apache Storm Projection Apache Spark Projection & Push-Down
• 0.13 broke bwc (HiveOutputFormat) • 0.14 broke bwc (removed interface SerDe) ‒ Also released with SNAPSHOT deps (HIVE-8857/8906) • 1.0-1.2 required a rewrite of the testing infrastructure Apache Tez • Not 100% compatible with M/R jobs • ES-Hadoop fall backs / mimics the environment
API Understand Scala & Java types ‒ Case classes ‒ Java Beans Available as Spark package Supports Spark Core & SQL all 1.x version (1.0-1.6) Available for Scala 2.10 and 2.11 spark-‐packages.org/package/elas3c/elas3csearch-‐hadoop
module for working with structured data” RDD + schema = DataFrame (inspired by Python Pandas) Allows usage of SQL Integrates with Hive* * trivia – the project was initially based on Hive (Shark)
sqlCtx.read.format("es").load("buckethead/albums") df.filter(df("category").equalTo("pikes").and(df("year").gt(2015))) CREATE TEMPORARY TABLE dfAsTable USING org.elasticsearch.spark.sql OPTIONS (‘path’ = ‘buckethead/albums’); SELECT name FROM dfAsTable WHERE year > 2015 and category = “pikes”; val df = sqlContext.read.json("buckethead/2015/albums.json") df.saveToES("buckethead/albums")
DataSource Reader (Spark 1.4) DataSourceRegister (Spark 1.5) DataSource.unhandledFilters (Spark 1.6) - Tell Spark that a certain Filter is already handled (by ES/ES-Hadoop) val df = sql.load("spark/index", "org.elasticsearch.spark.sql") val df = sql.read.format("org.elasticsearch.spark.sql").load(“spark/index”) val df = sql.read.format(“es").load(“spark/index”)
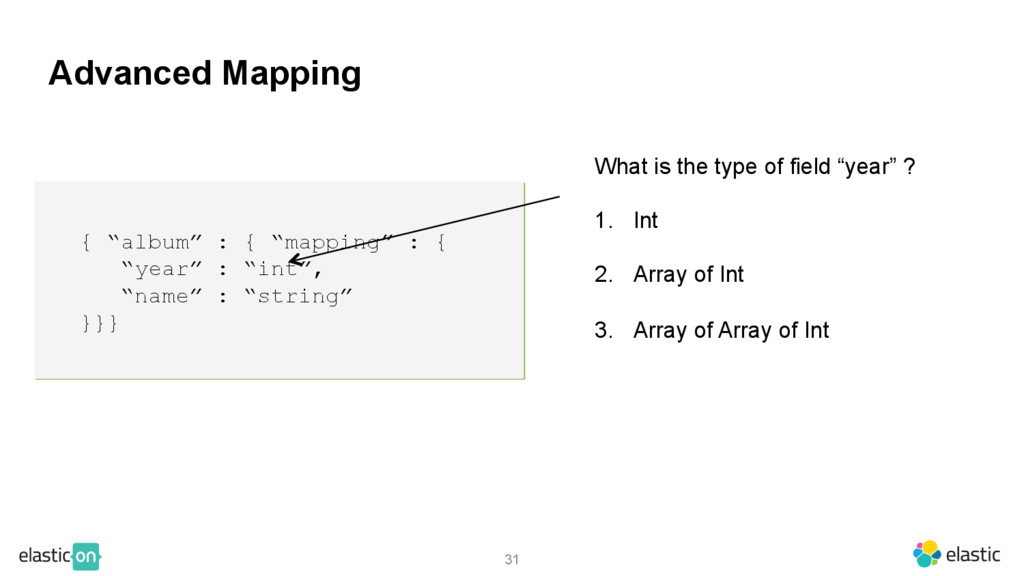
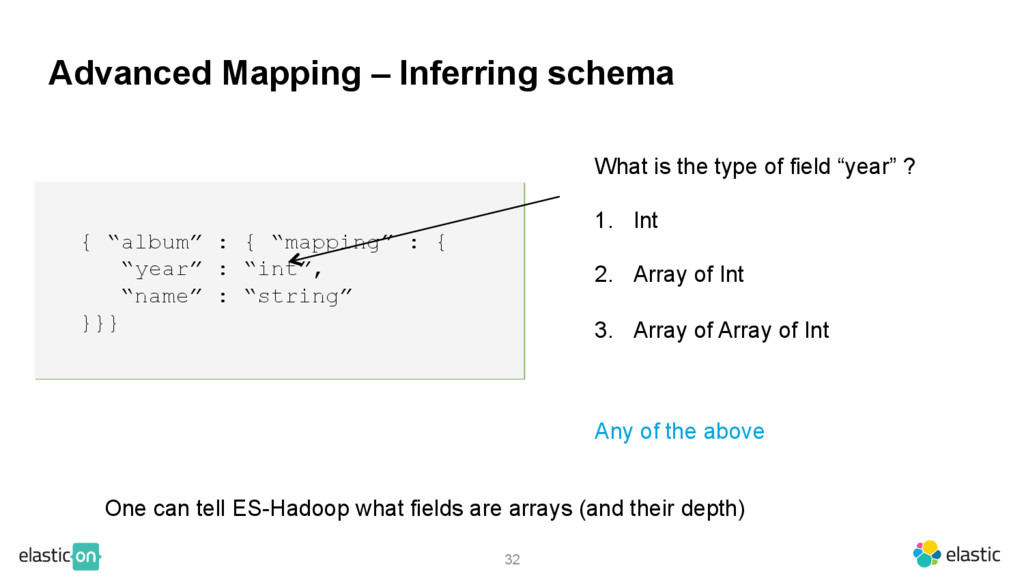
“mapping” : { “year” : “int”, “name” : “string” }}} What is the type of field “year” ? 1. Int 2. Array of Int 3. Array of Array of Int Any of the above One can tell ES-Hadoop what fields are arrays (and their depth)
storage Backup and recover data Issues: FileSystem API – not a file system Incomplete semantics (last-delete-on-close, fsync, atomic operations) NFSv3 bridge (not v4, metadata issues) https://github.com/elastic/elasticsearch/issues/9072
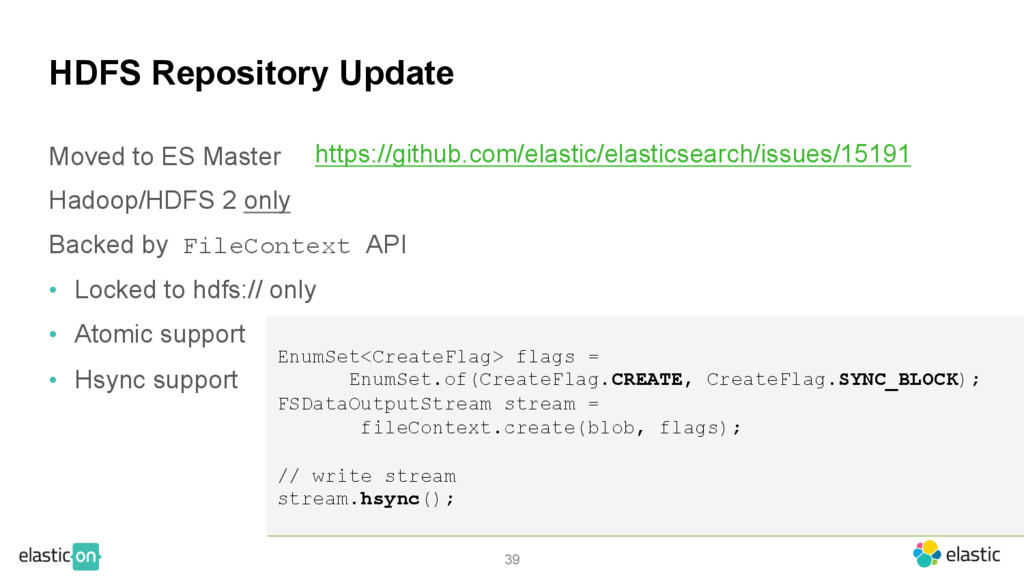
only Backed by FileContext API • Locked to hdfs:// only • Atomic support • Hsync support EnumSet<CreateFlag> flags = EnumSet.of(CreateFlag.CREATE, CreateFlag.SYNC_BLOCK); FSDataOutputStream stream = fileContext.create(blob, flags); // write stream stream.hsync(); https://github.com/elastic/elasticsearch/issues/15191
containers=2 Launched a 2 nodes Elasticsearch-YARN cluster [application_1415921358606_0006@http://hadoop:8088/proxy/ application_1415921358606_0006/] at Sun Feb 14 02:23:21 EET 2016 Run Elasticsearch on YARN* * YARN still doesn’t support long-lived services: • No provisioning • No ip/network guarantees • Data/node affinity Next YARN releases plan to address this
where otherwise noted, this work is licensed under http://creativecommons.org/licenses/by-nd/4.0/ Creative Commons and the double C in a circle are registered trademarks of Creative Commons in the United States and other countries. Third party marks and brands are the property of their respective holders.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![25 Apache Spark – JSON RDDs jsonRDD : RDD[(String, String)]](https://files.speakerdeck.com/presentations/11680214d2a649f2aea088ca12f81b5c/slide_24.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}