Elasticsearch is an industry-leading solution for search and real-time analytics at scale. Apache Spark has shaped into a powerhouse for processing massive data, both in batch and streaming contexts. Elasticsearch for Apache Hadoop (ES-Hadoop) is a two-way connector that provides the tools needed to marry these two together in perfect data harmony.
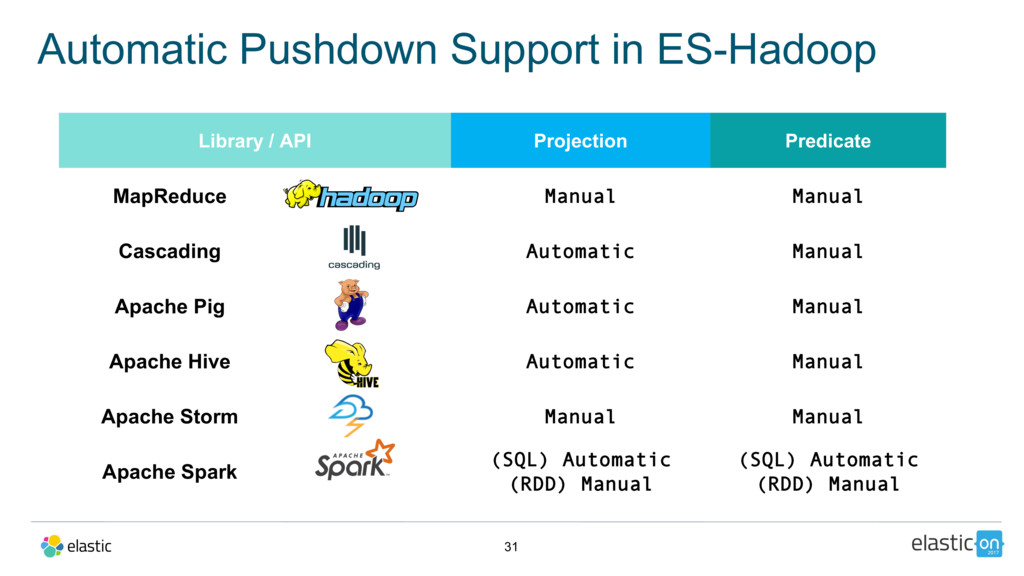
This talk aims to introduce the audience to the basics of ES-Hadoop’s native Spark Integration, touch upon the other features that the connector brings to the table (including native integrations with Hive, Storm, Pig, Cascading, and MapReduce), shed some light on the internals of how it works, as well as highlight what’s to come.
James Baiera l Software Engineer l Elastic
Anoop Sunke l Solutions Architect l Elastic
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
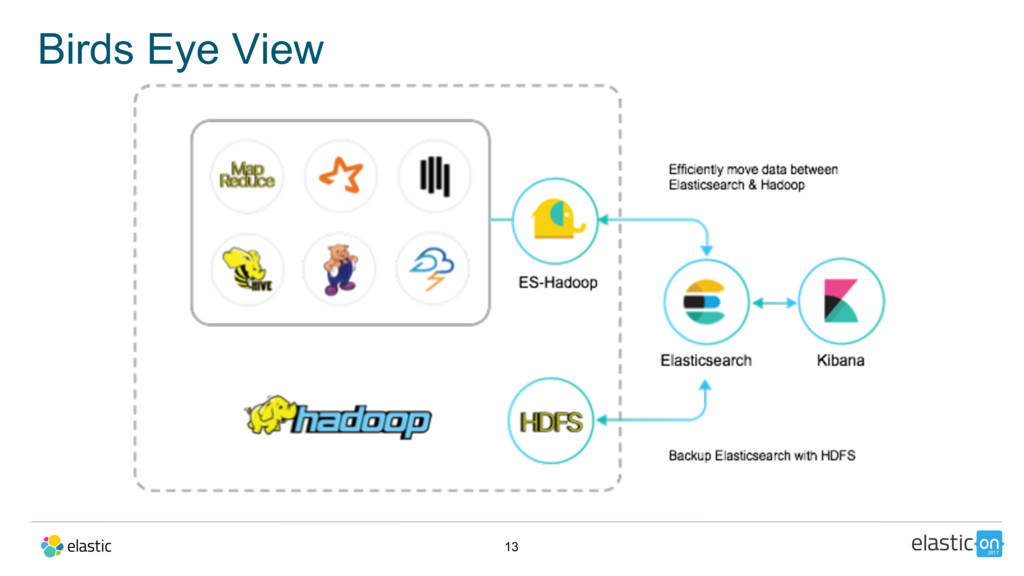{kind=link}
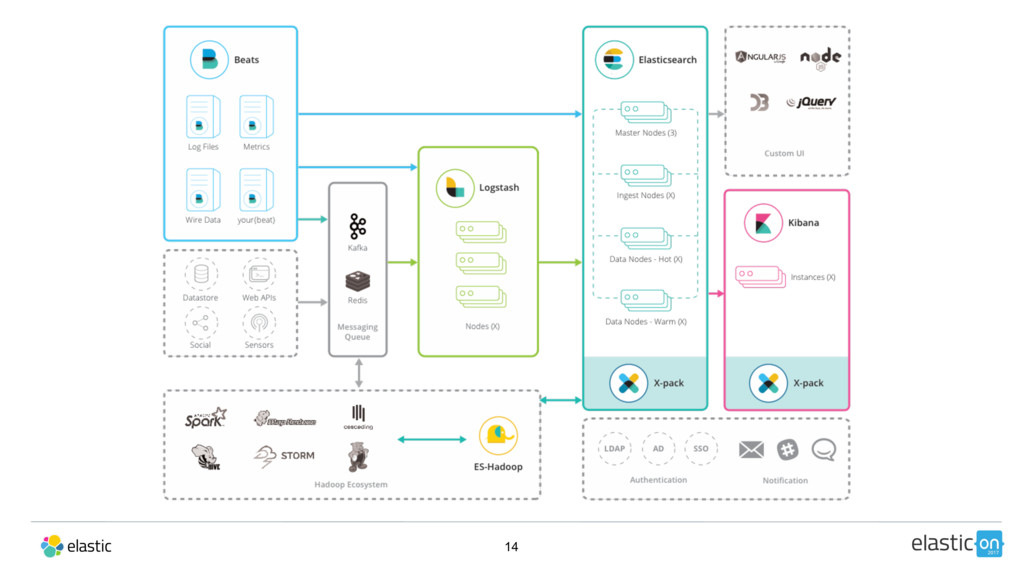{kind=link}
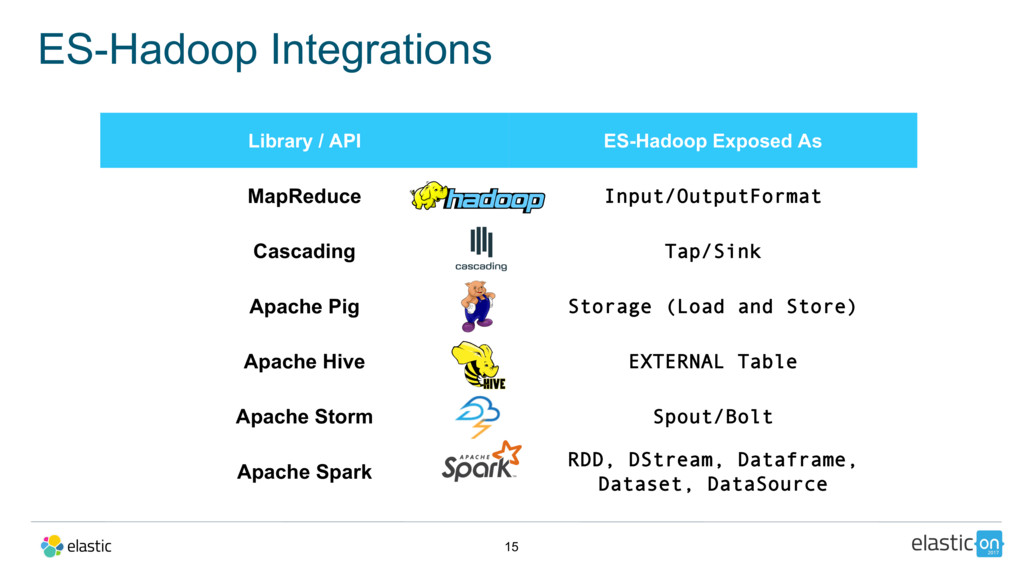{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
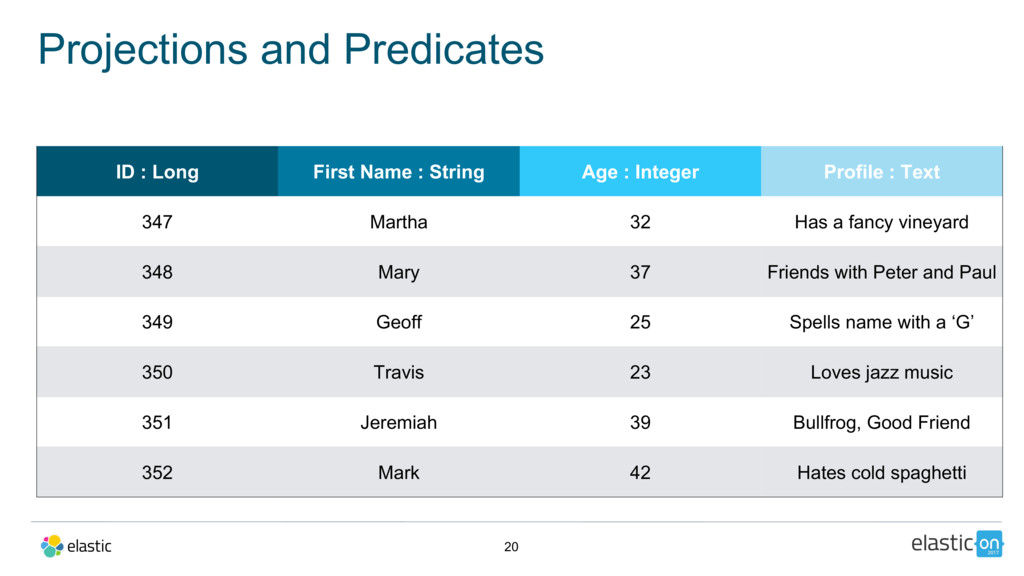{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![{ "_source": [ "name", "id" ], "query" : { "bool":{](https://files.speakerdeck.com/presentations/47f331225cf04db1a3b48da5ac5f79fb/slide_27.jpg){kind=link}
{kind=link}
![{ "_source": [ "name", "id" ], "query" : { "bool":{](https://files.speakerdeck.com/presentations/47f331225cf04db1a3b48da5ac5f79fb/slide_29.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
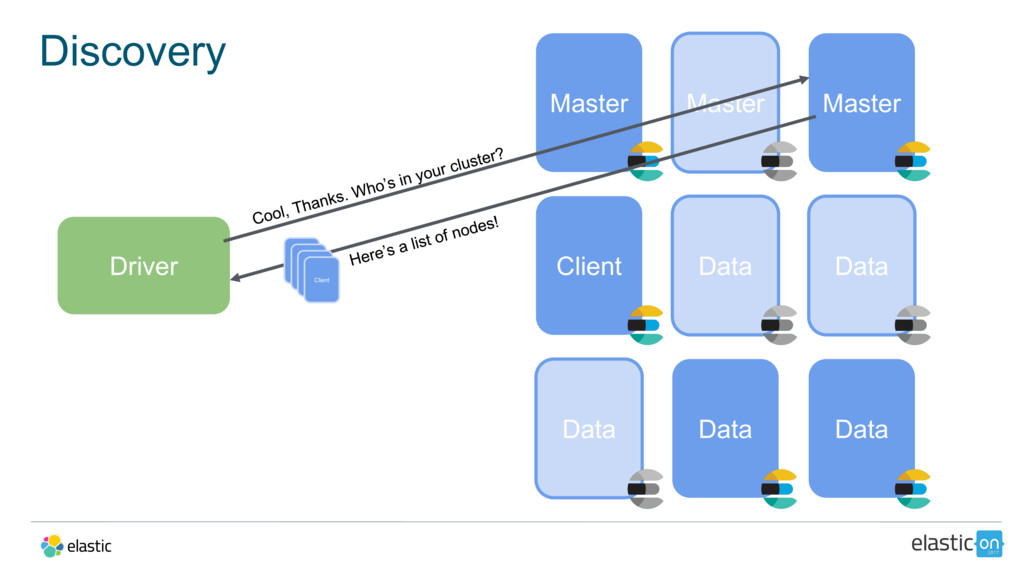{kind=link}
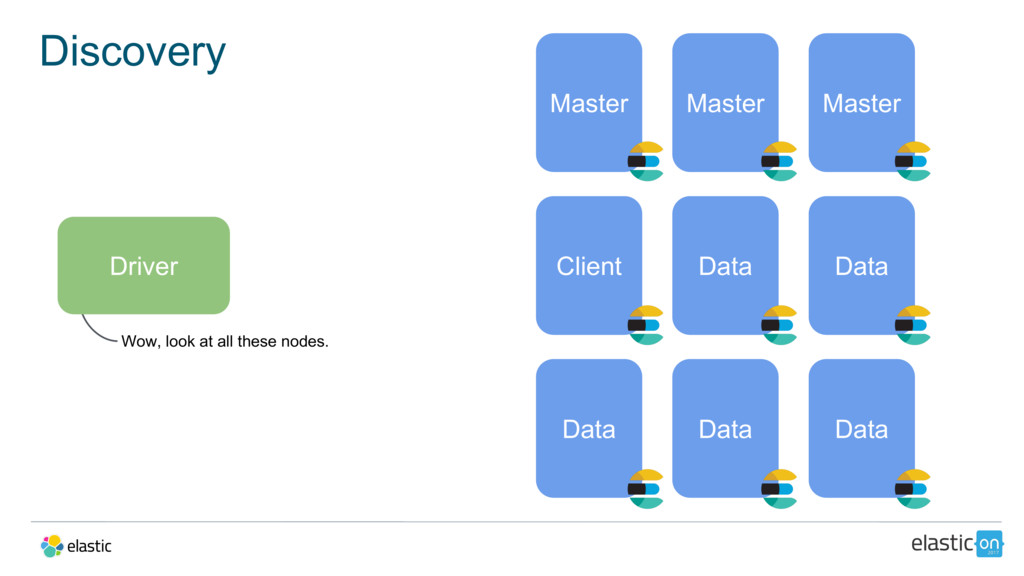{kind=link}
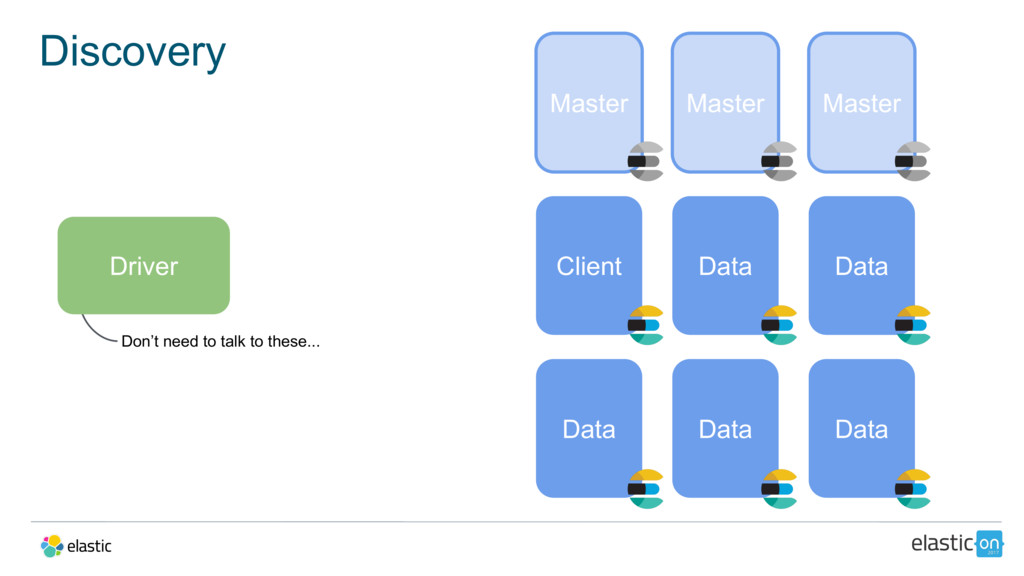{kind=link}
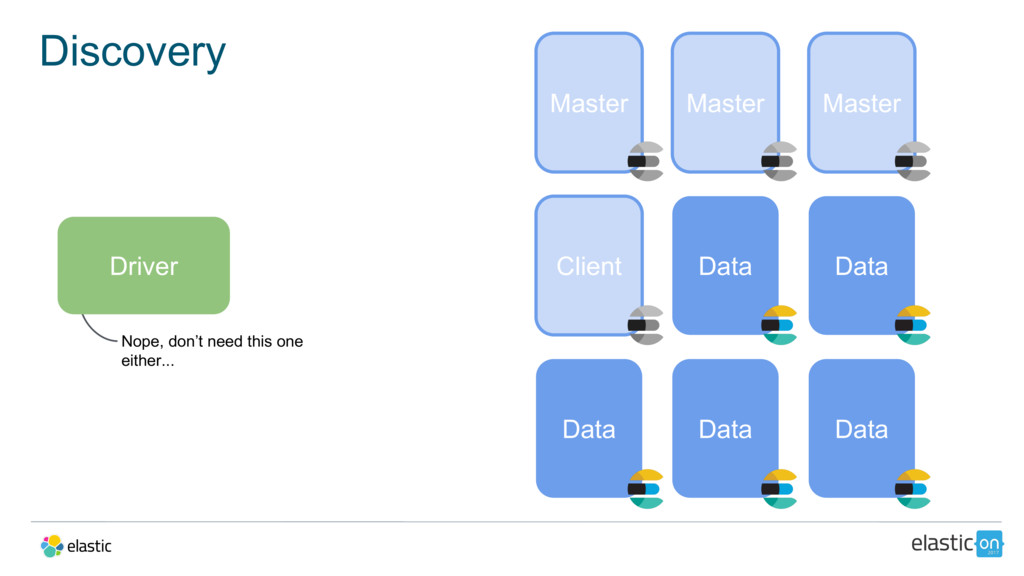{kind=link}
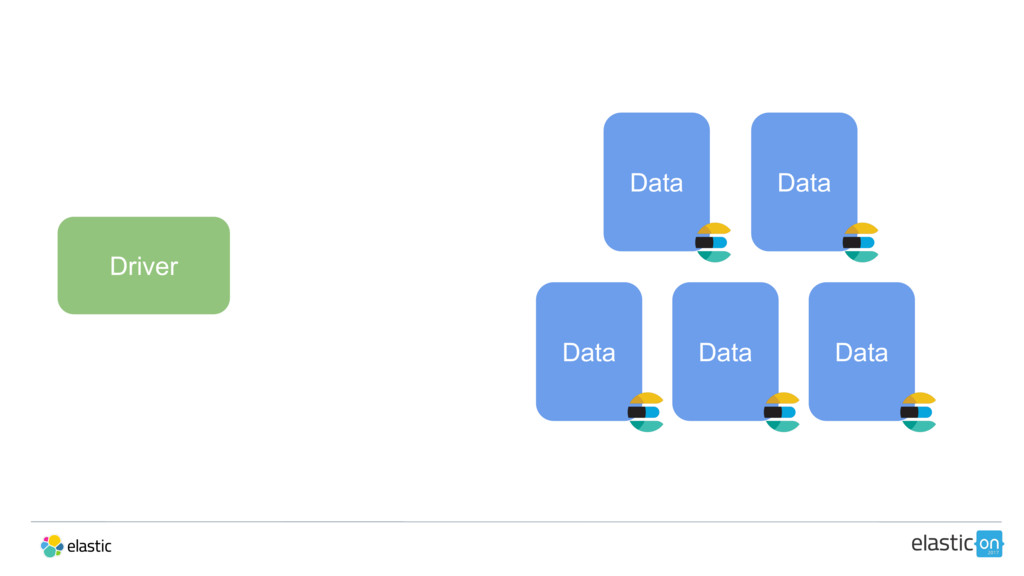{kind=link}
{kind=link}
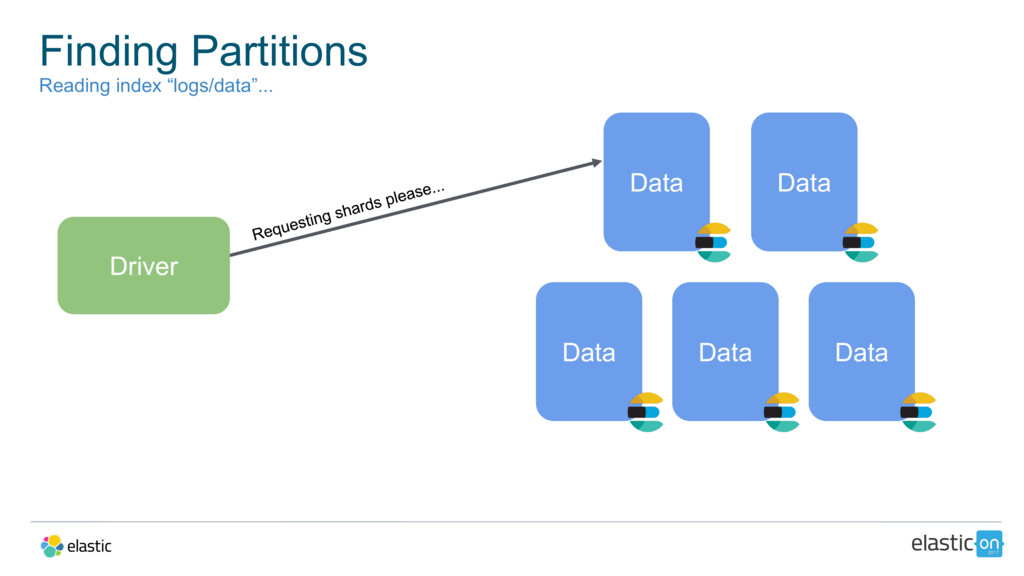{kind=link}
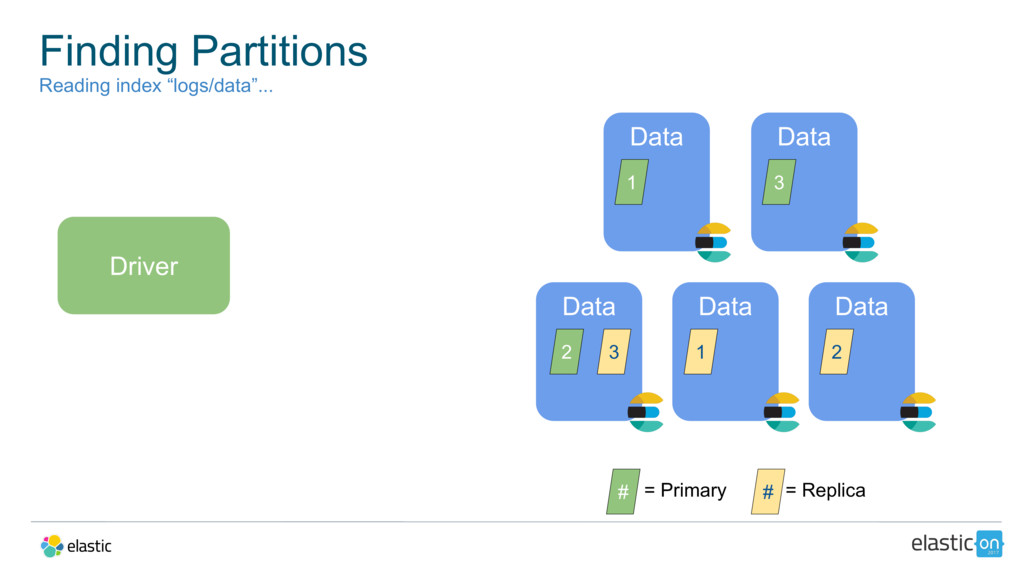{kind=link}
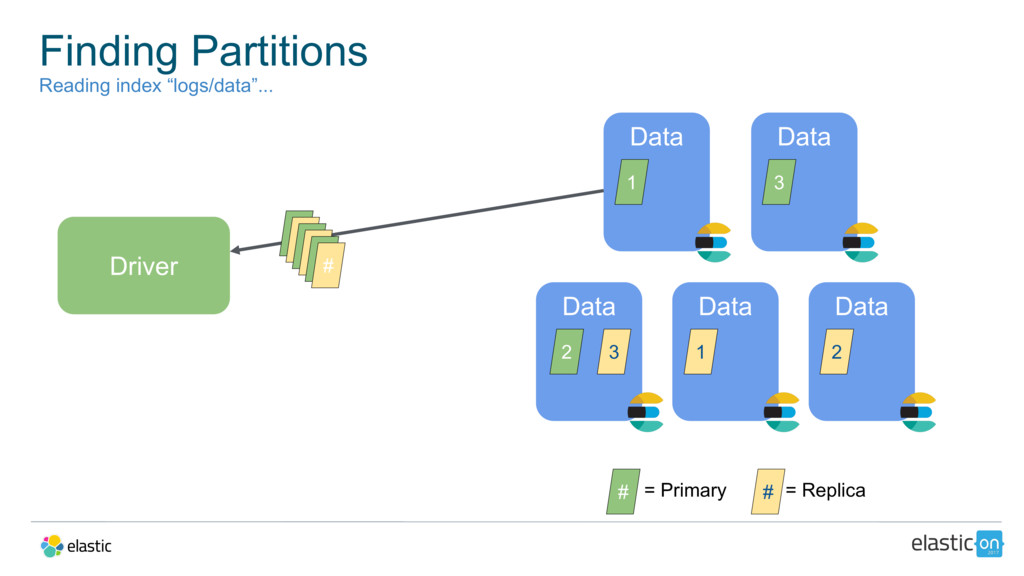{kind=link}
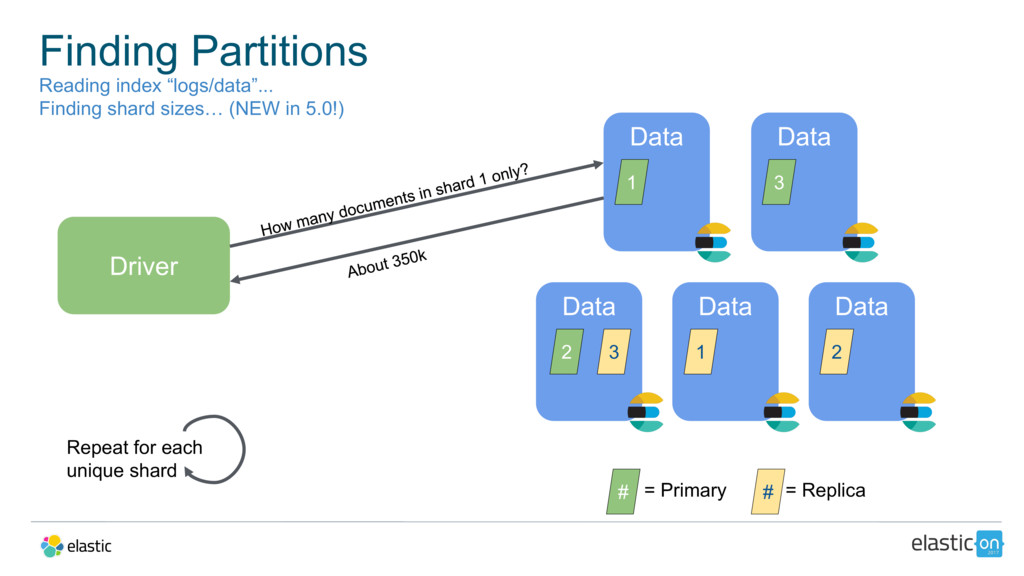{kind=link}
{kind=link}
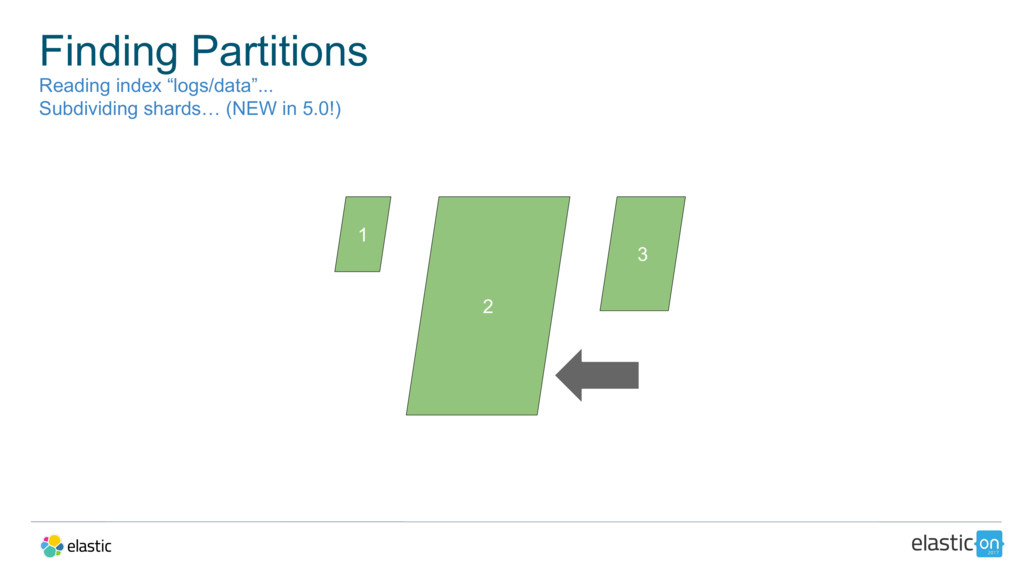{kind=link}
{kind=link}
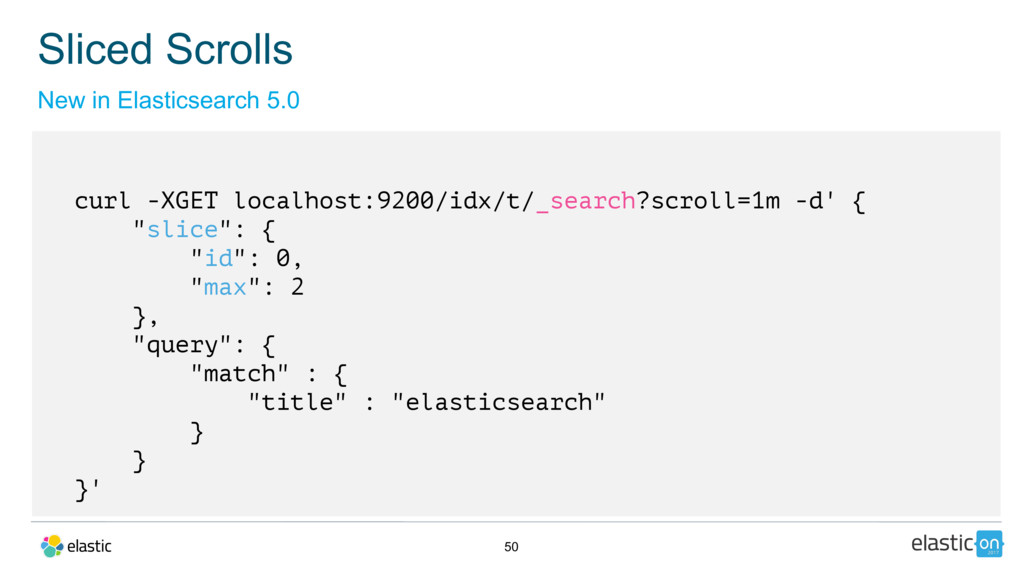{kind=link}
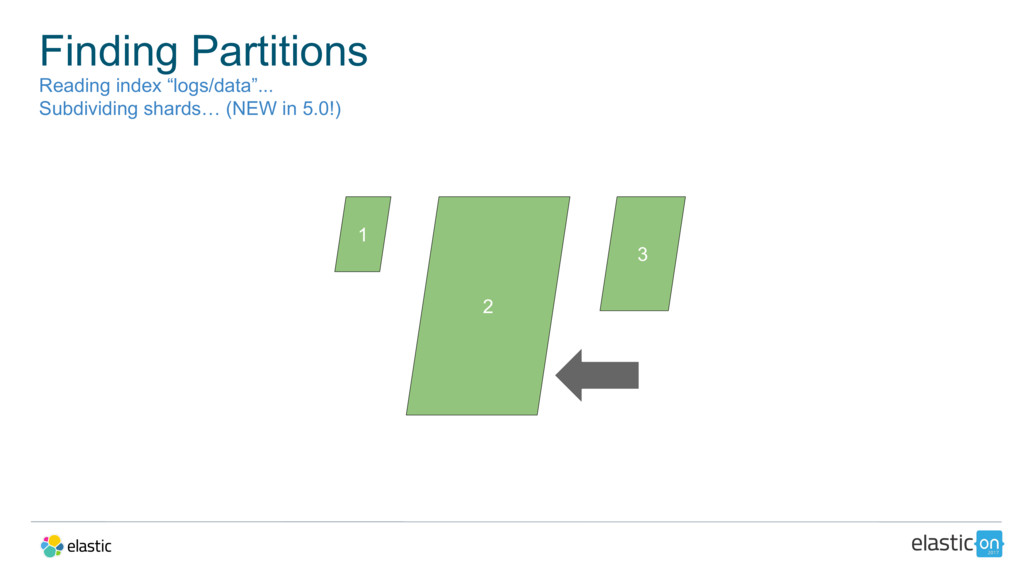{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
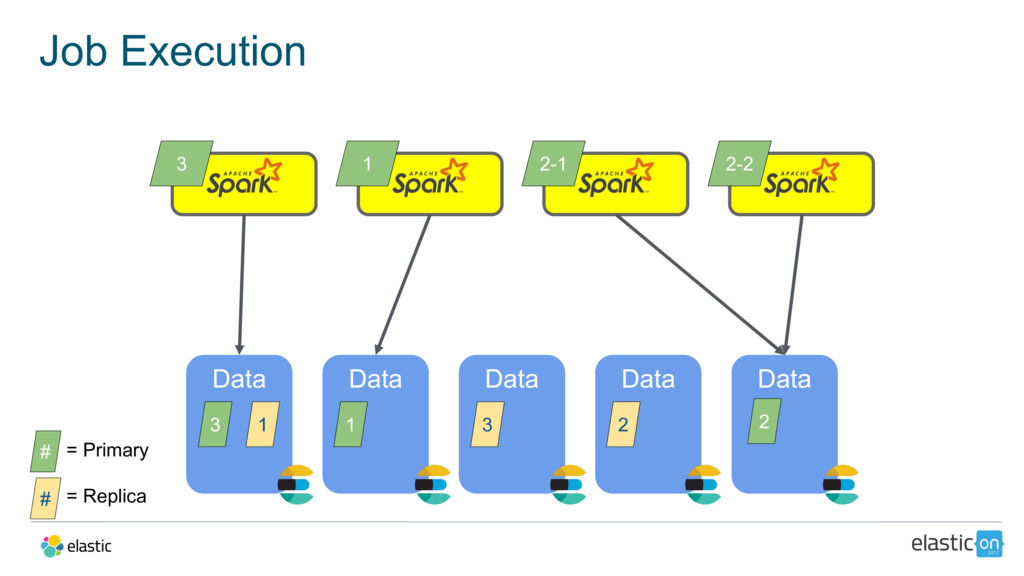{kind=link}
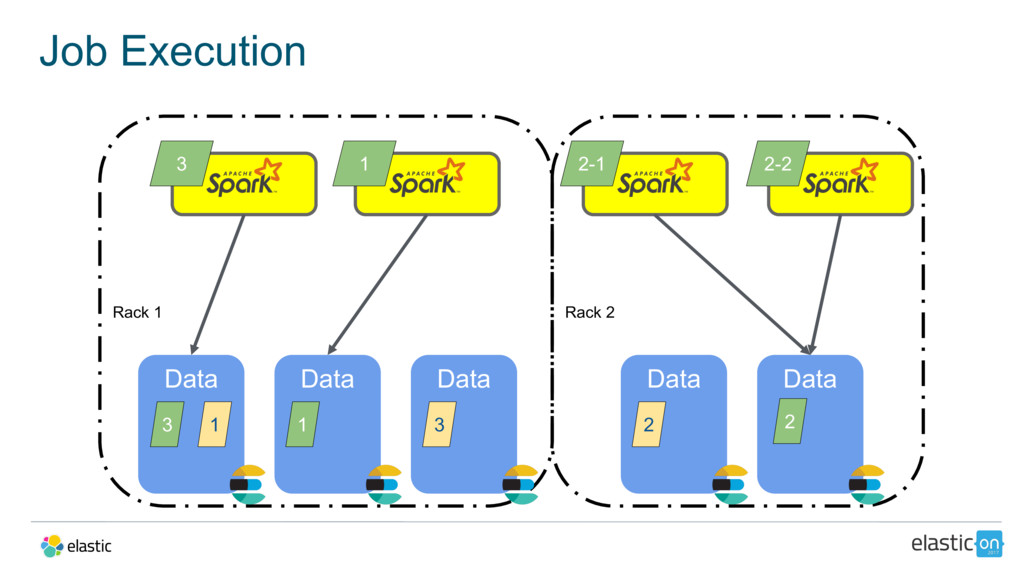{kind=link}
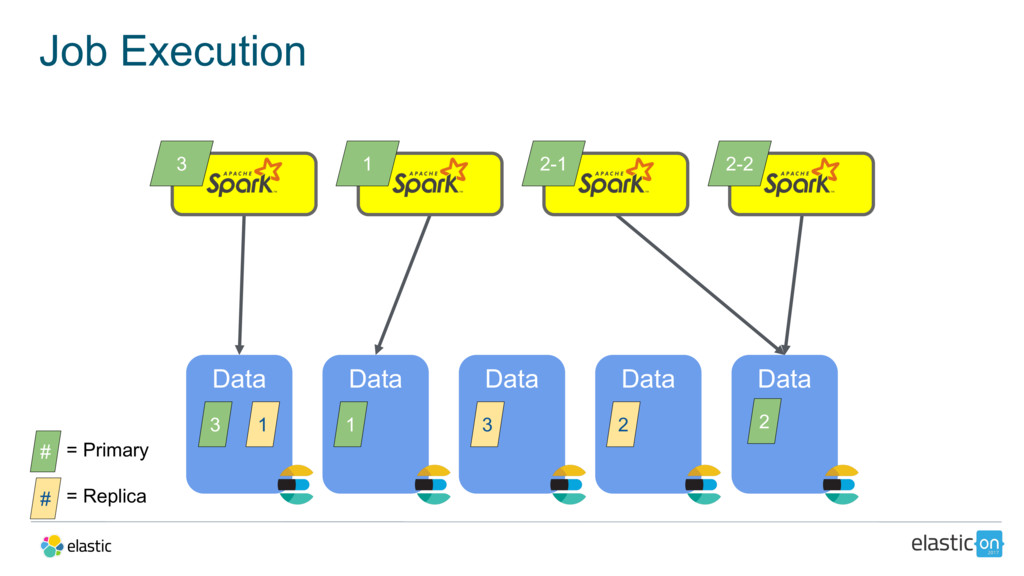{kind=link}
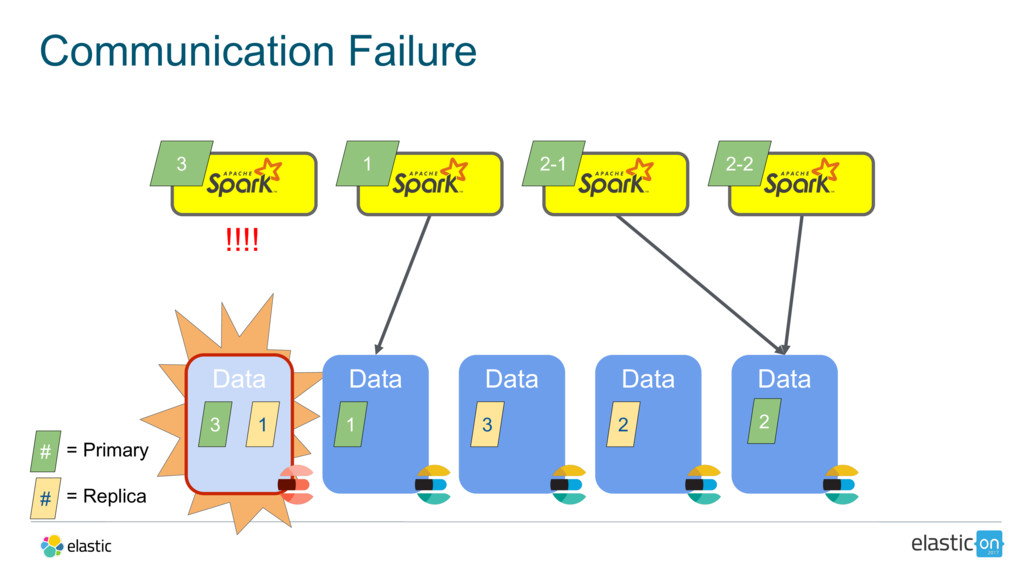{kind=link}
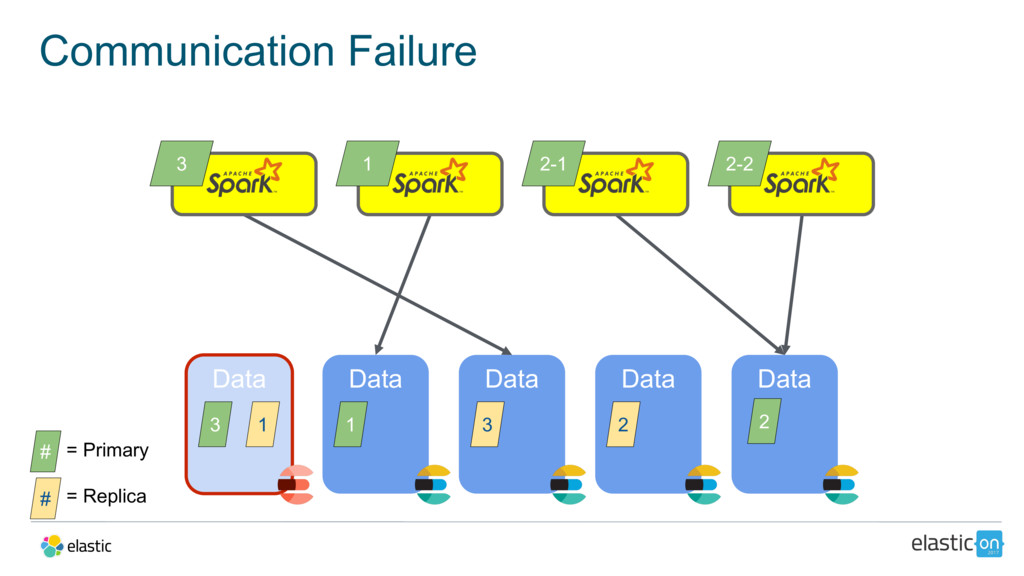{kind=link}
{kind=link}
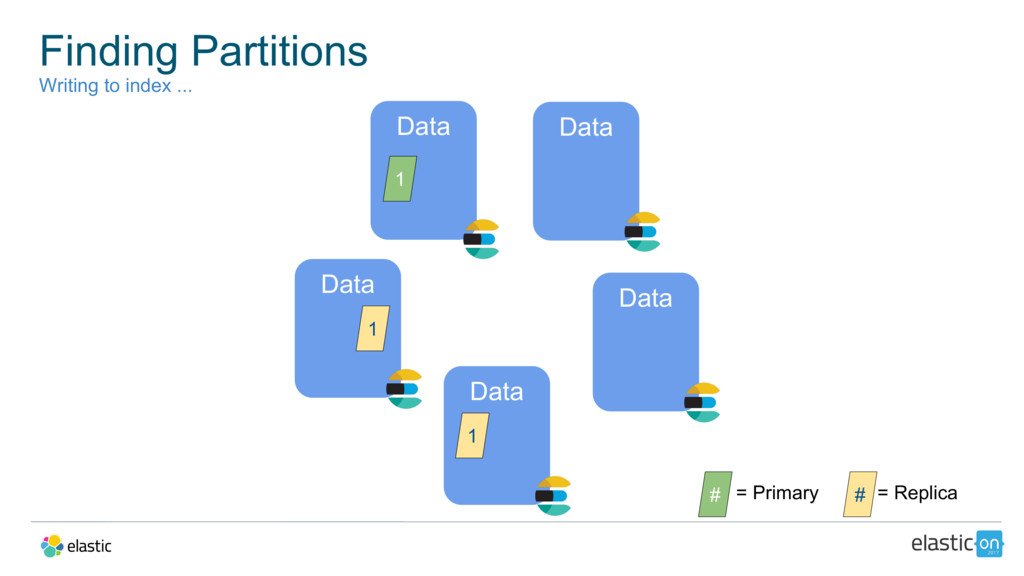{kind=link}
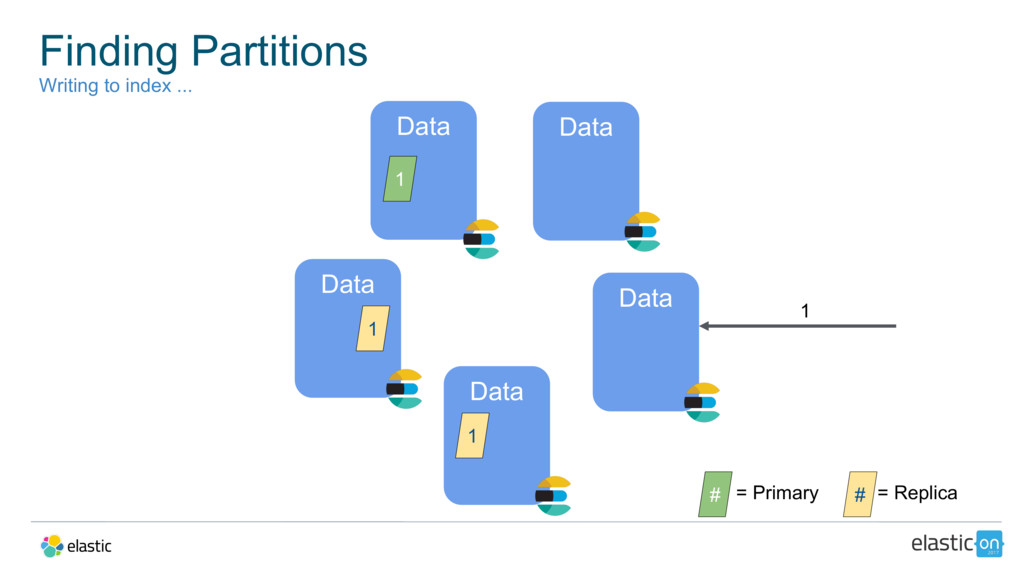{kind=link}
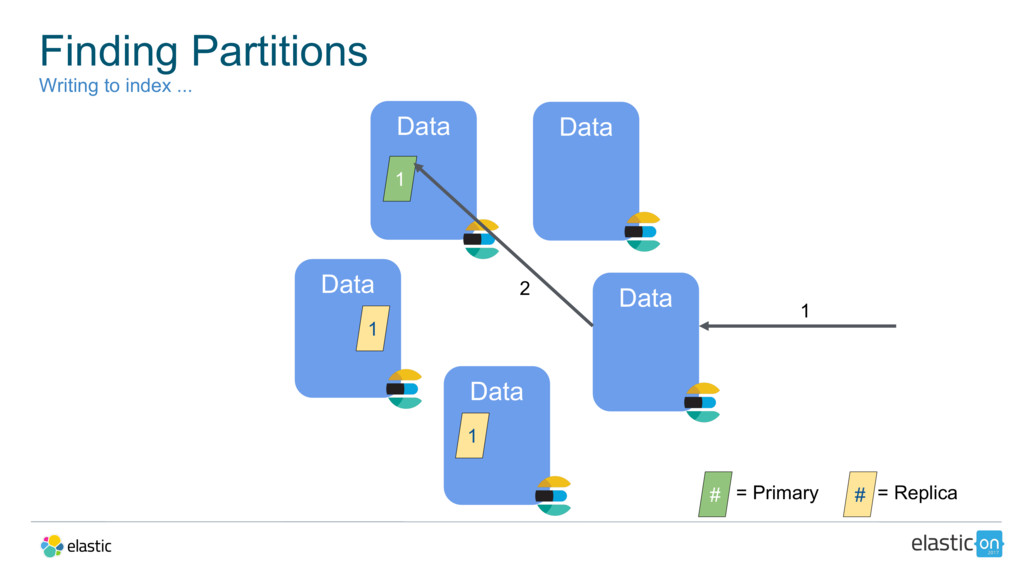{kind=link}
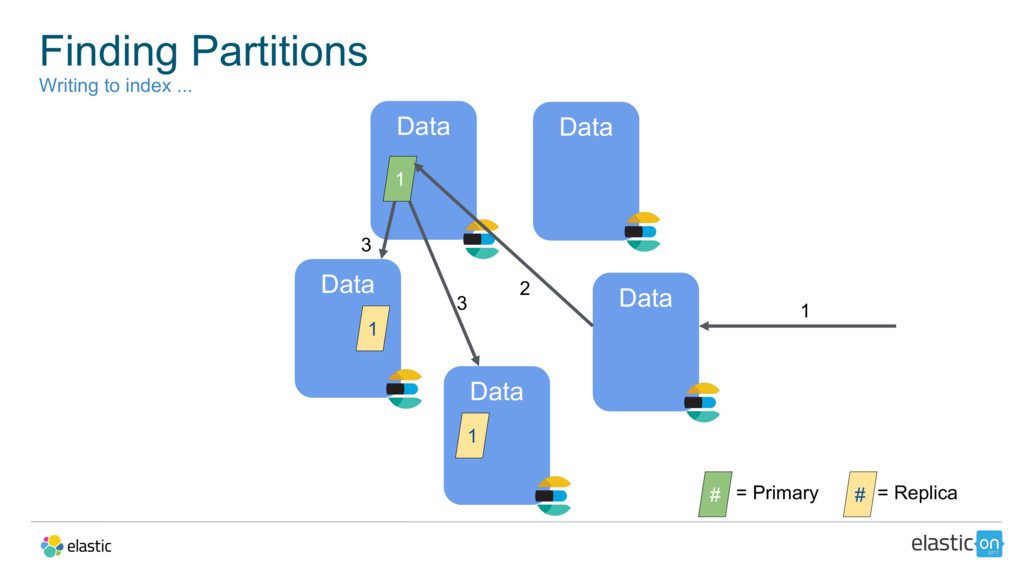{kind=link}
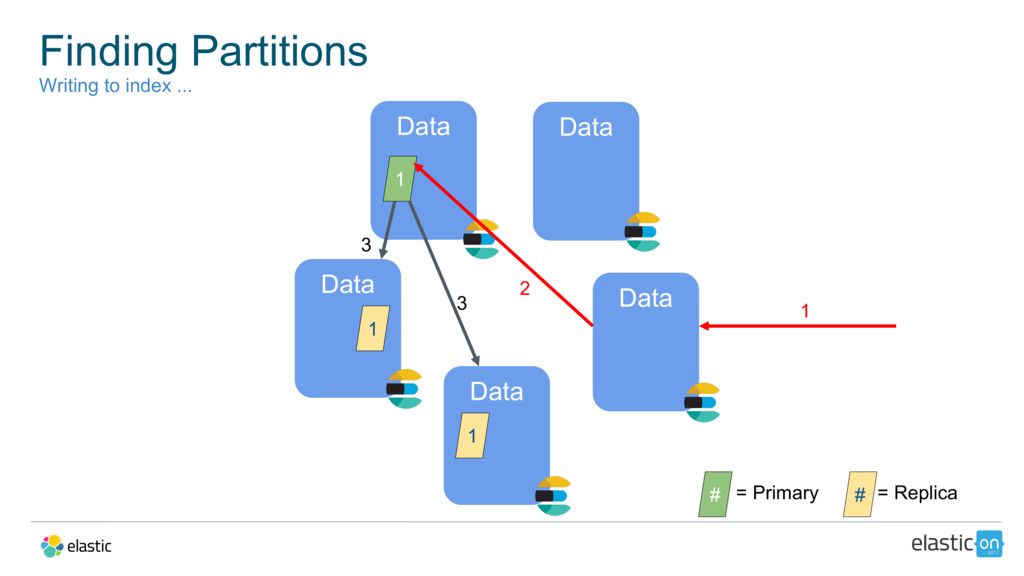{kind=link}
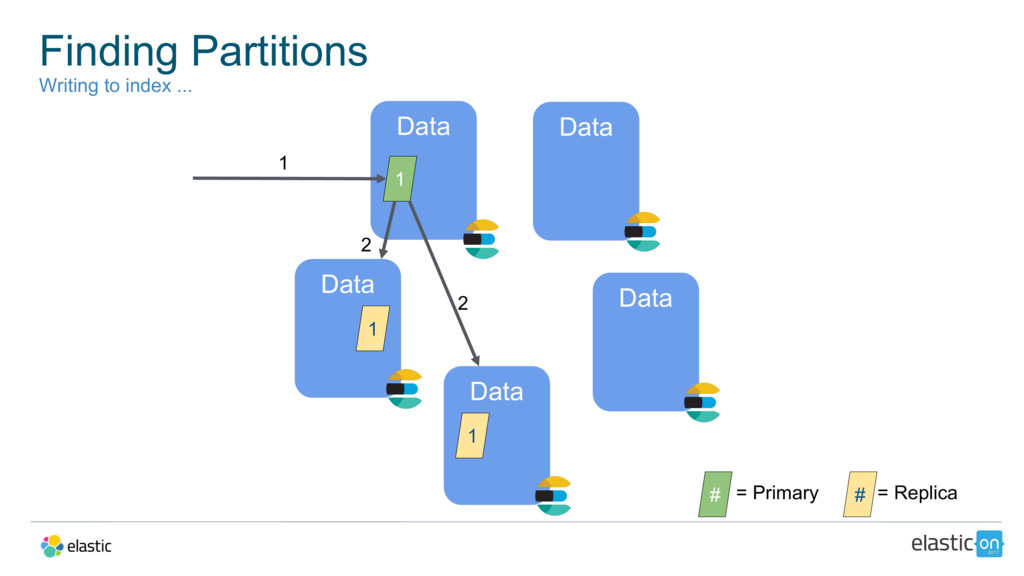{kind=link}
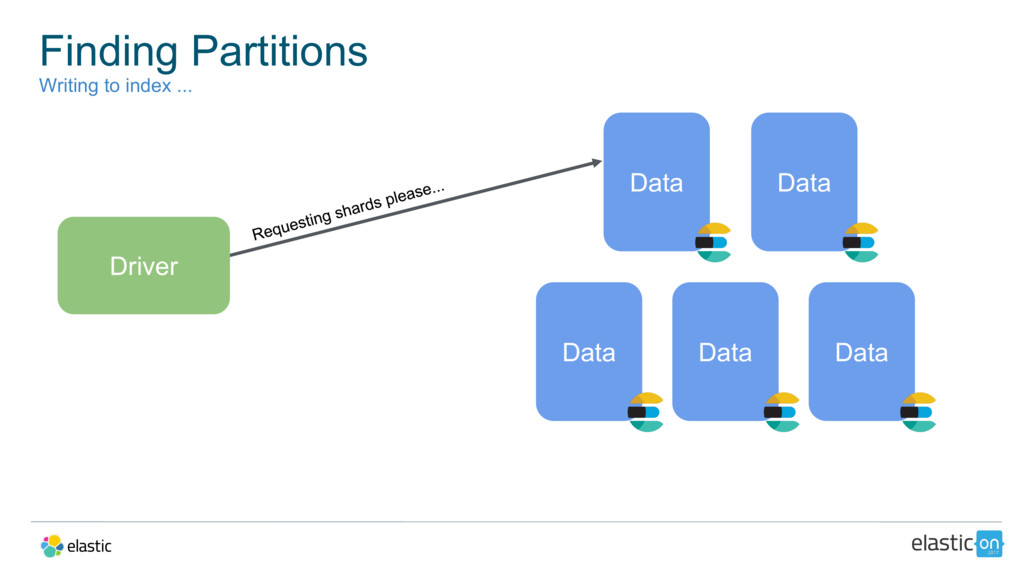{kind=link}
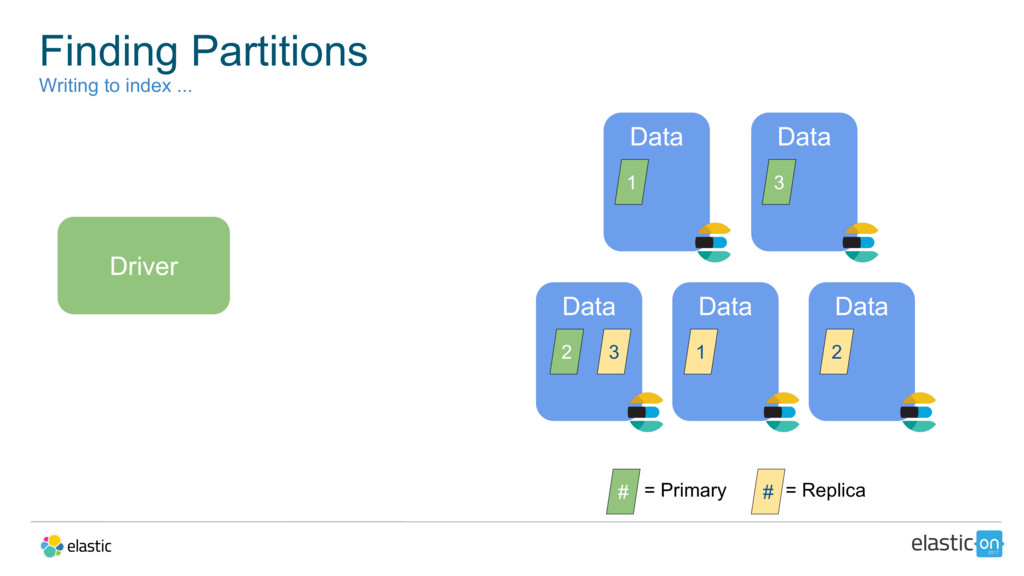{kind=link}
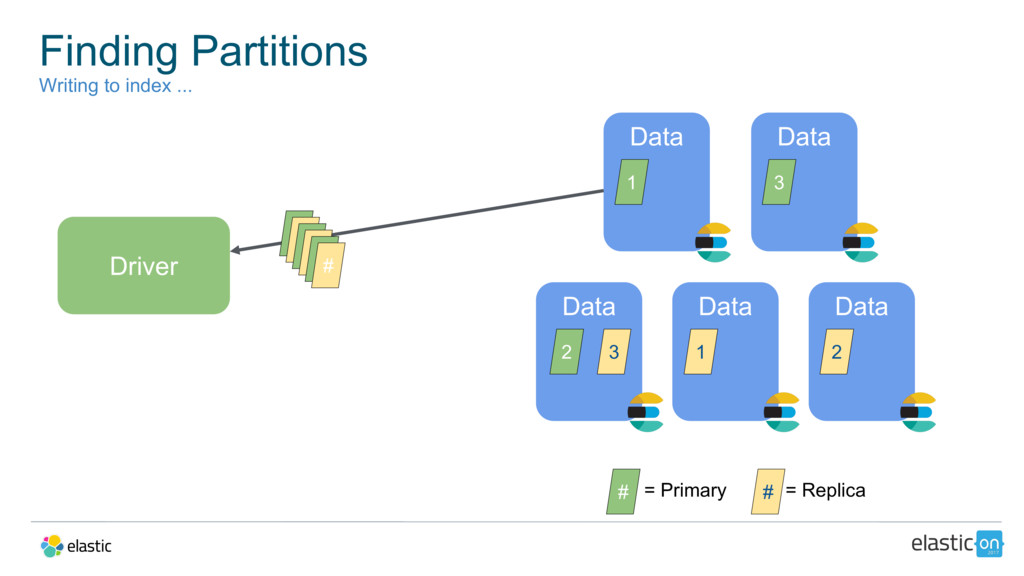{kind=link}
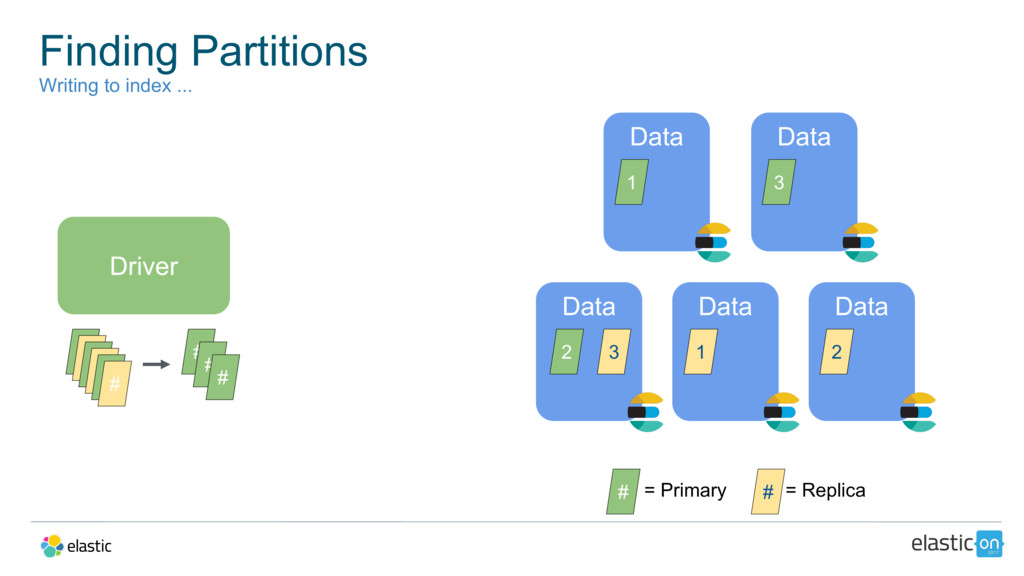{kind=link}
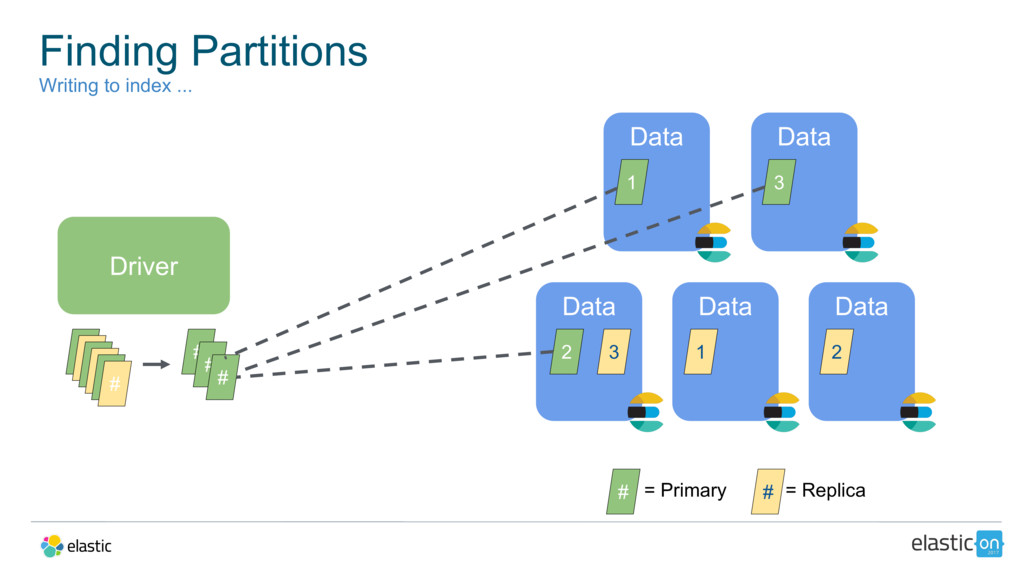{kind=link}
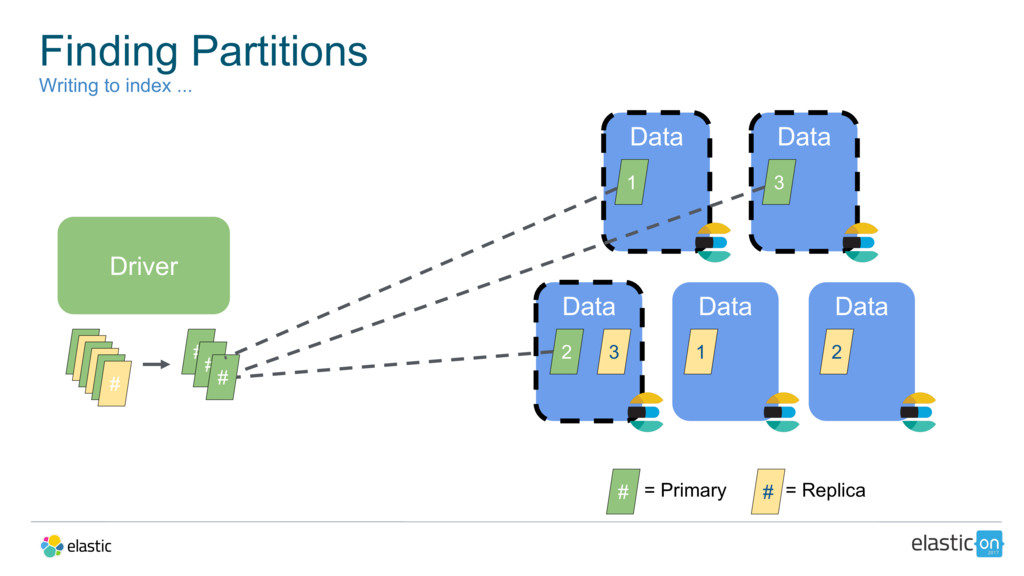{kind=link}
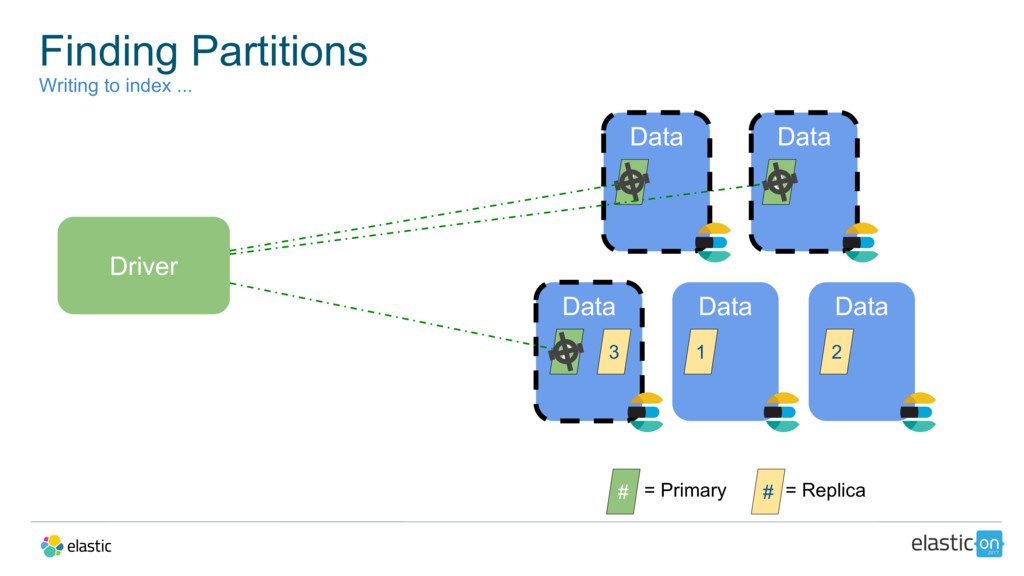{kind=link}
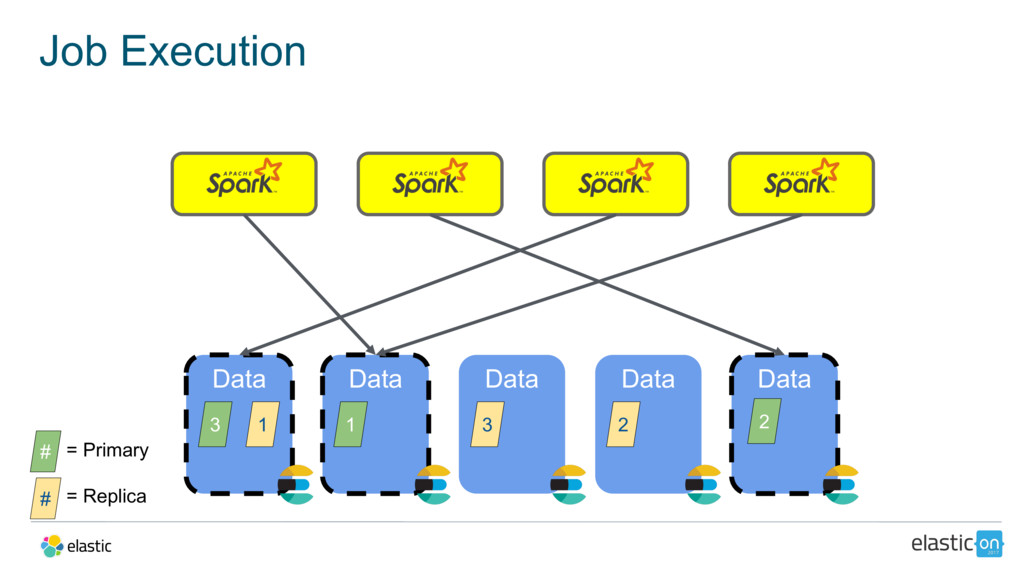{kind=link}
{kind=link}
{kind=link}
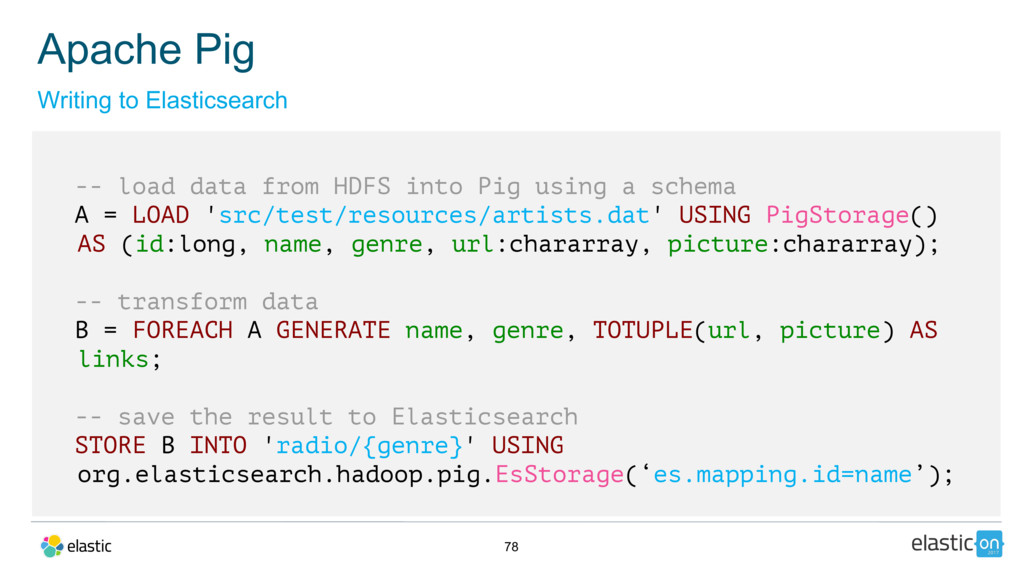{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
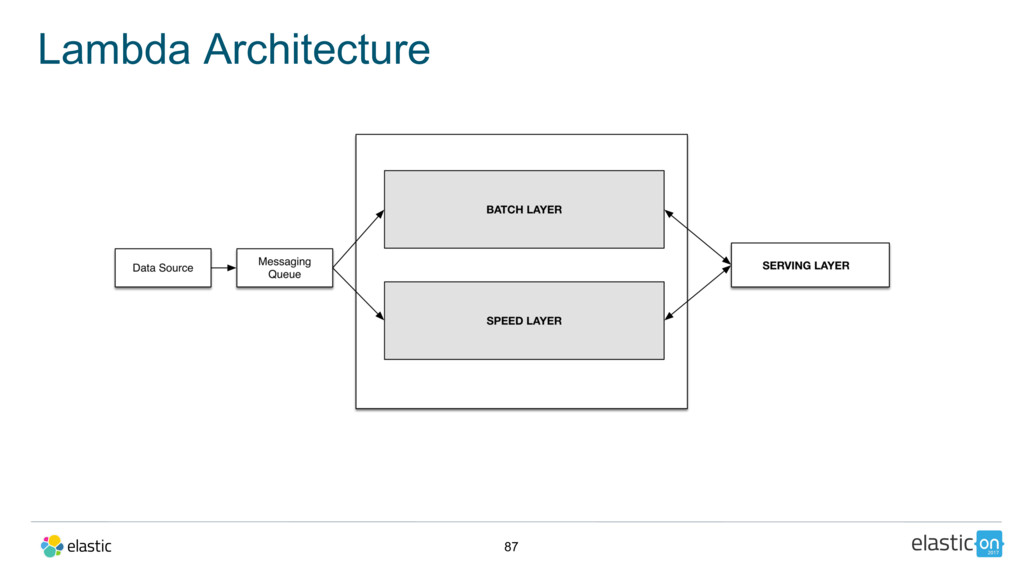{kind=link}
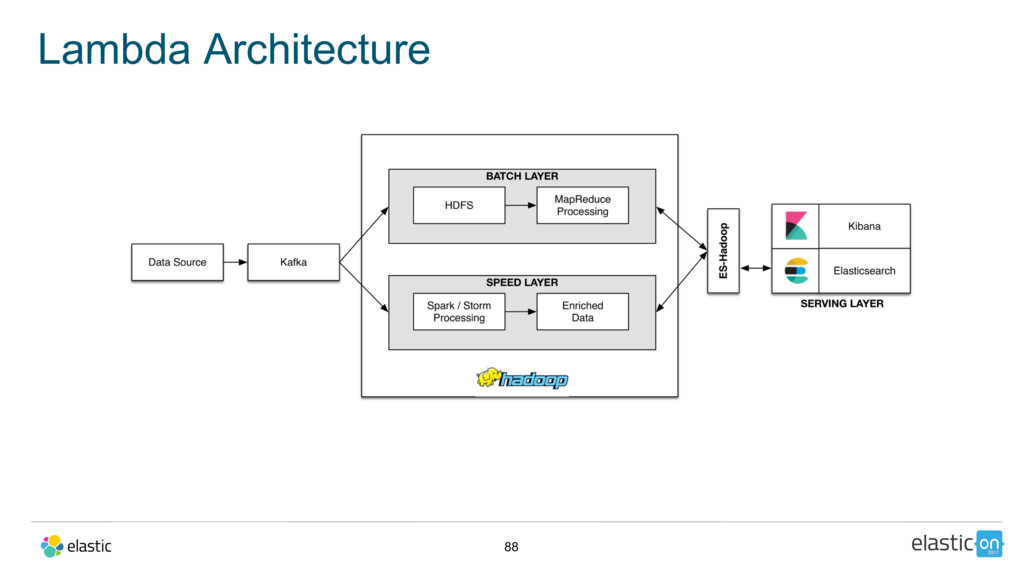{kind=link}
{kind=link}
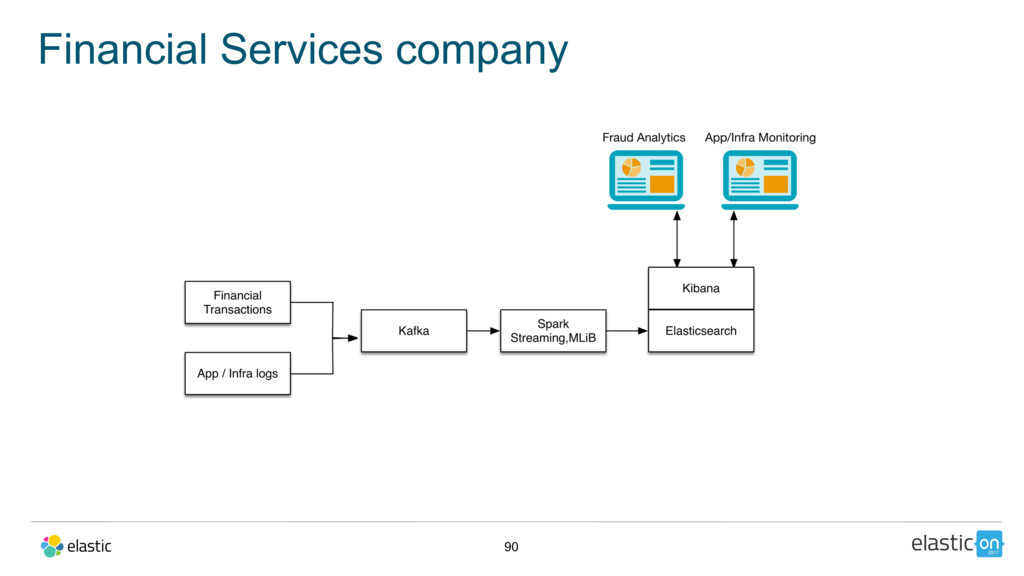{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}