Apresentação na XX Semana de Informática da Universidade Federal de Viçosa (http://semanainfo.nobugs.com.br/).
Descrição
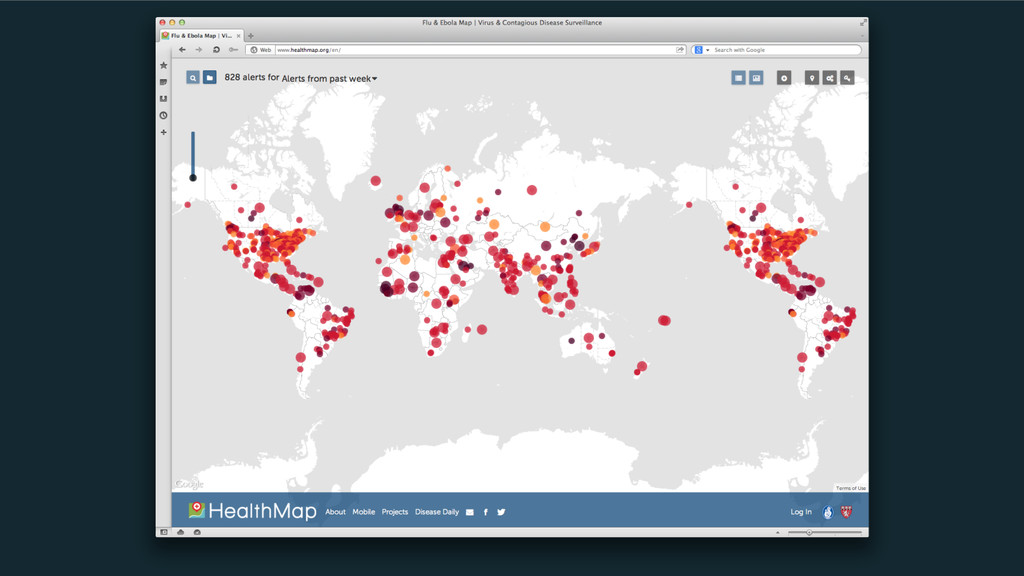
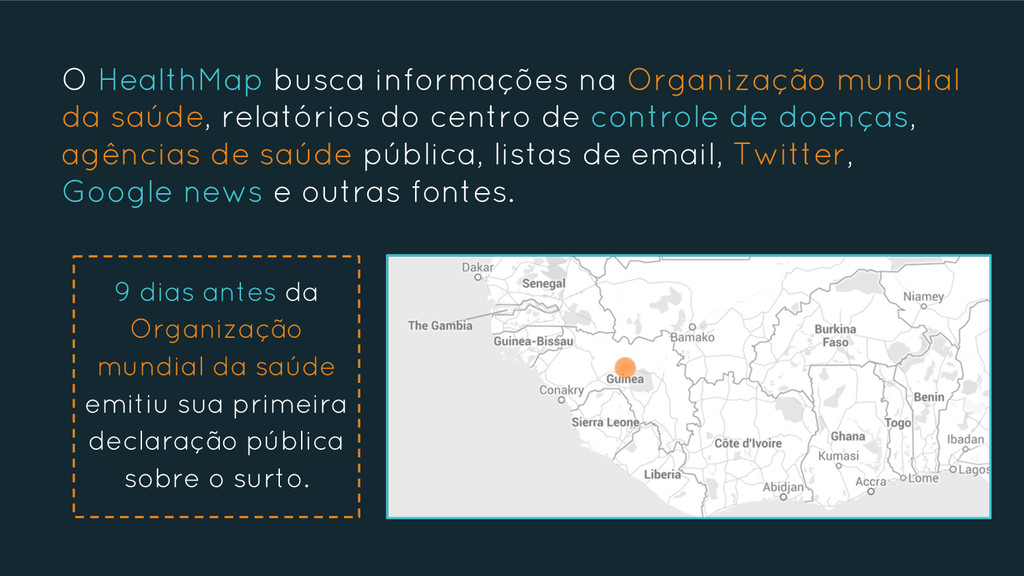
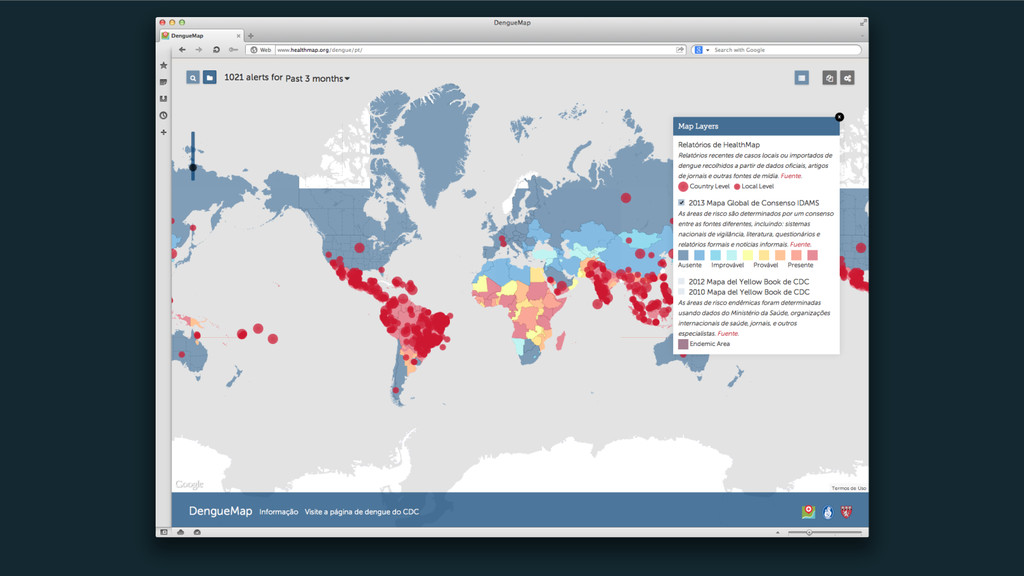
Big Data é o termo utilizado para definir dados que não podem ser processados usando os bancos de dados tradicionais, pois são muitos dados, se movendo muito rápido, ou são demasiadamente complexos para as ferramentas de processamento de dados convencionais. Mas agora podemos coletar, integrar e analisar dados de uma forma que não era possível até poucos anos atrás. Encontrar valor em todos estes dados é uma tarefa que demanda técnicas analíticas, além de armazenamento, processamento e tecnologias de integração.
Um estudo feito pela EMC em conjunto com a International Data Corporation (IDC) diz que a quantidade de dados existentes vai saltar de 130 exabytes em 2005 para 40 mil exabytes em 2020. Em valores estimados, 40 mil exabytes é o equivalente a 100 milhões de vezes todos os livros já escritos ou 8 mil vezes a transcrição de todas as palavras já pronunciadas pela raça humana. Dados de 2014 apontam que a cada minuto enviamos mais de 130 milhões de emails, curtimos mais de 1,8 milhões de posts no Facebook e mais de 430 mil tweets são realizados. O Google realiza mais de 1,5 milhões de buscas e o Walmart efetua mais de 16 mil transações a cada minuto.
Além disso, pense em todos os dados de sensores coletados diariamente, em todas as transações de cartão de créditos e nos dados de localização de todos os celulares em uso atualmente. Big Data está começando a transformar a maioria das áreas de negócio, a indústria, a investigação e muitas outras partes de nossas vidas.
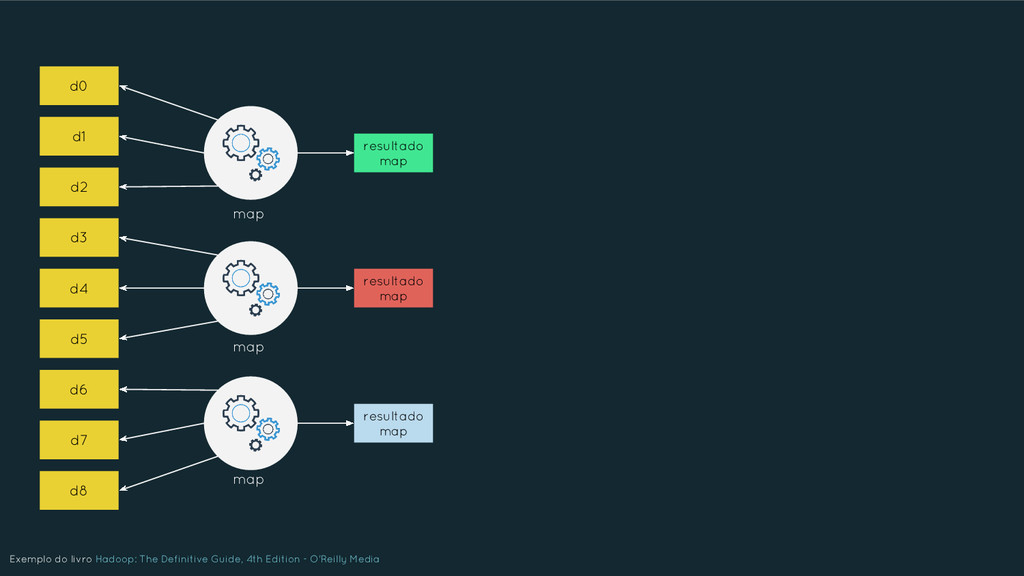
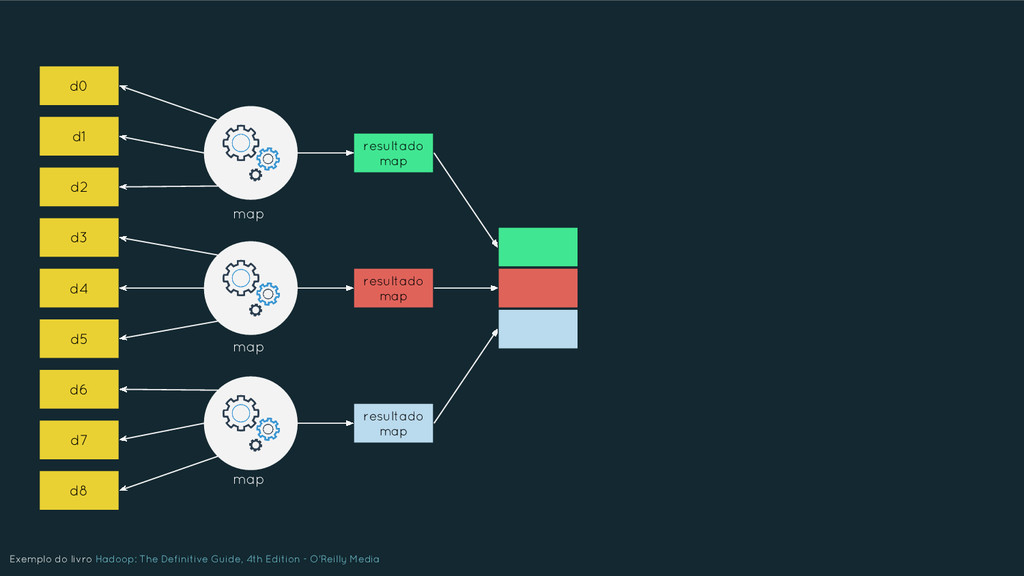
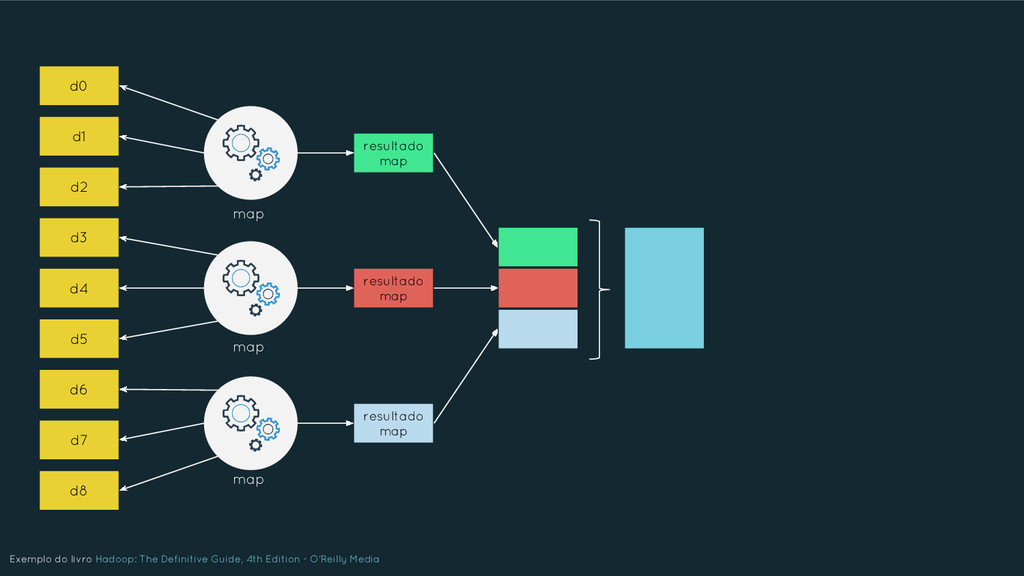
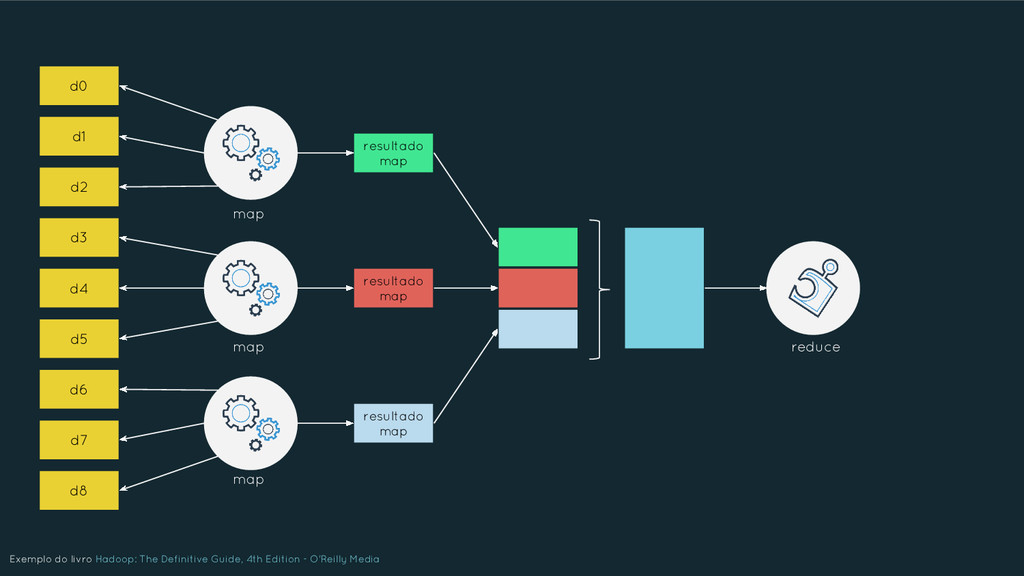
Nesta apresentação serão abordados os principais elementos que caracterizam o Big Data, buscando oferecer uma compreensão ampla das tecnologias em uso. Os tópicos serão tratados de forma inter-relacionada e abrangem: NoSQL, Hadoop, MapReduce, Machine Learning, Data Science, Internet of Things, etc. Além disso, será discutido como o Big Data está afetando as nossas vidas, as perspectivas futuras e quais os setores que o estão utilizando. Por fim, será dada uma visão de mercado sobre a crescente demanda de profissionais para trabalharem na área.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
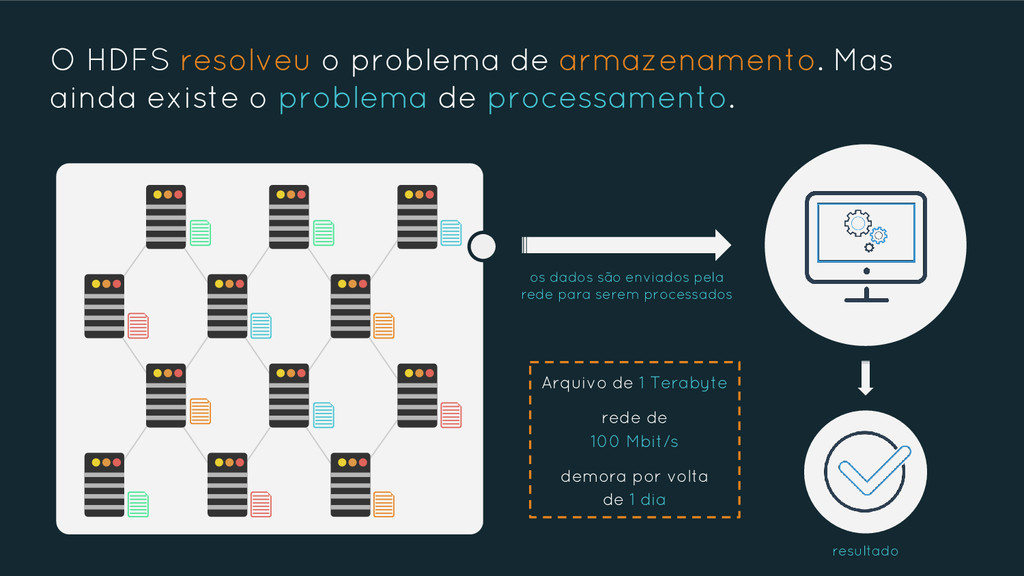{kind=link}
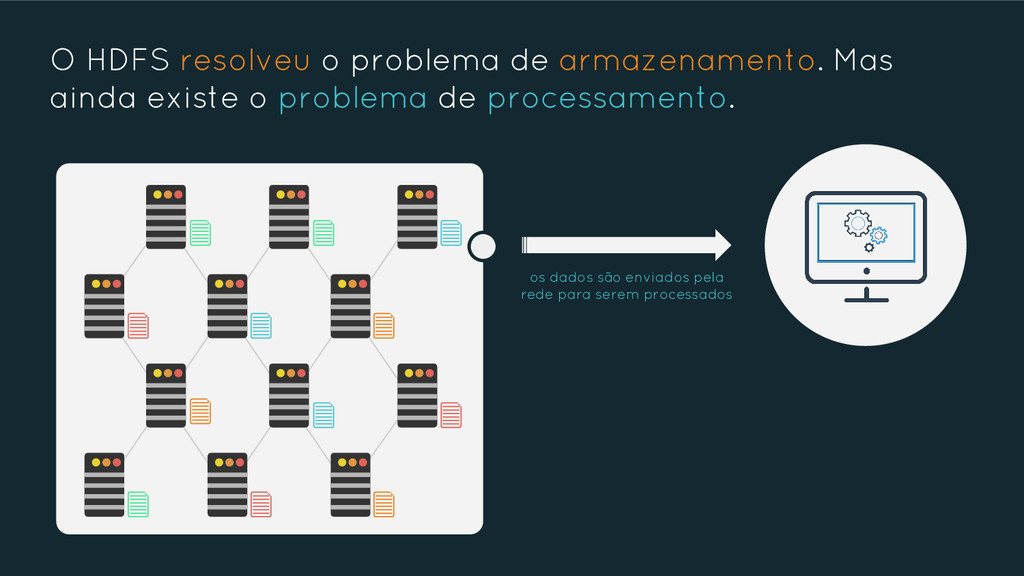{kind=link}
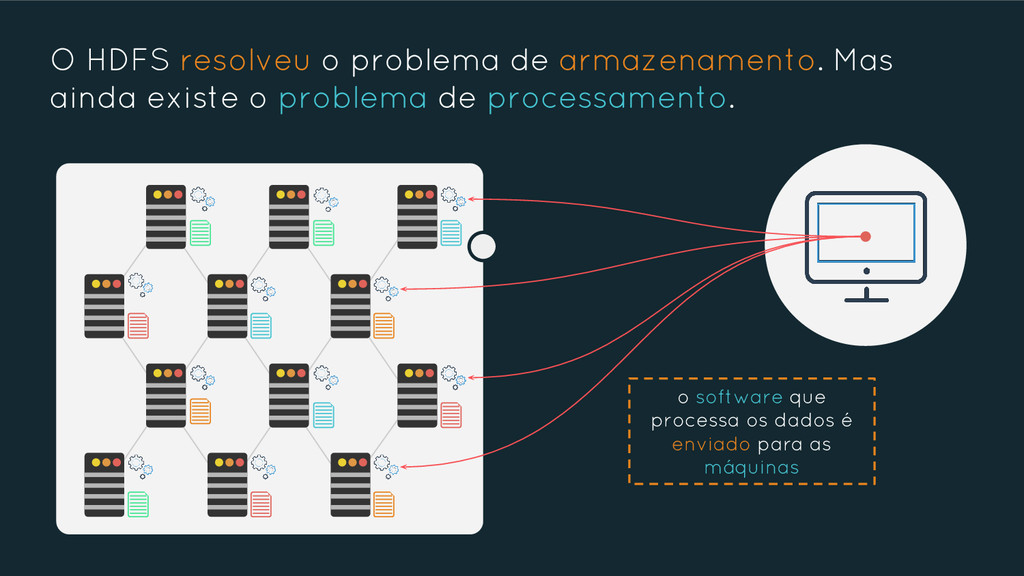{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
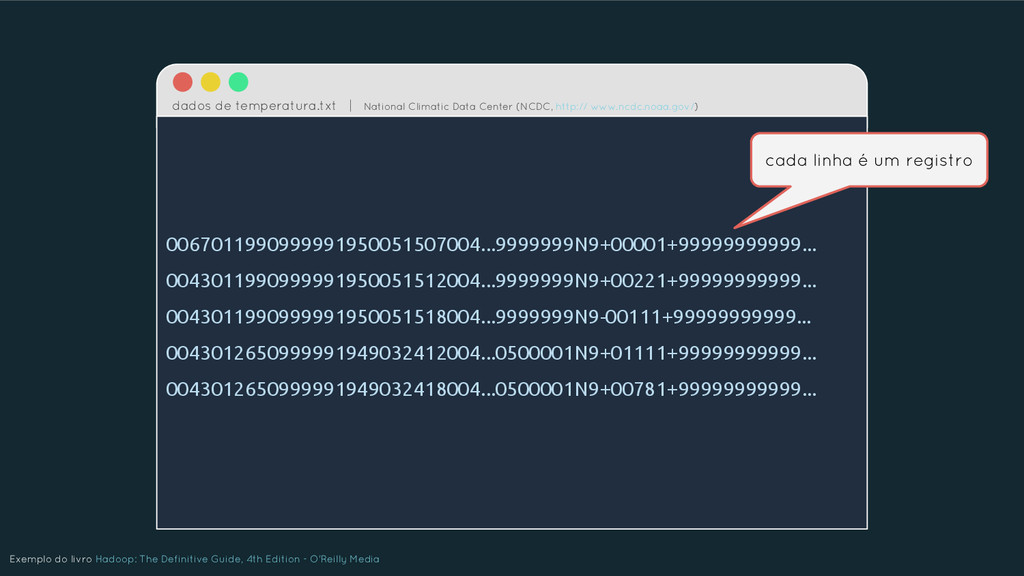{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}