Data Processing on Large Clusters. MapReduce é um modelo de programação para processamento de grandes volumes de dados. Esta abstração foi inspirada nas primitivas map e reduce do Lisp e outras linguagens funcionais.
e uma lista, onde este operador será chamada para cada elemento da lista (map f list [list2 list3 …]) (map square ‘(1 2 3 4)) ;Resultado: (1 4 9 16) ;;; A primitiva reduce recebe como parâmetros um operador binário e uma lista, onde os elementos da lista serão combinados utilizando este operador (reduce + ‘(1 4 9 16)) ;Resultado: 30 Map e Reduce no Lisp Lisp é uma linguagem funcional, projetada por John McCarthy que apareceu pela primeira vez em 1958.
value: Conteúdo do documento for each word w in value: EmitIntermediate(w, "1"); reduce(String key, Iterator values): // key: Uma palavra // values: Uma lista de contagens int result = 0; for each v in values: result += ParseInt(v); Emit(AsString(result)); Pseudocódigo para contagem de palavras Fonte: MapReduce: Simplified Data Processing on Large Clusters <http://static.googleusercontent.com/media/research.google.com/en//archive/mapreduce-osdi04.pdf>
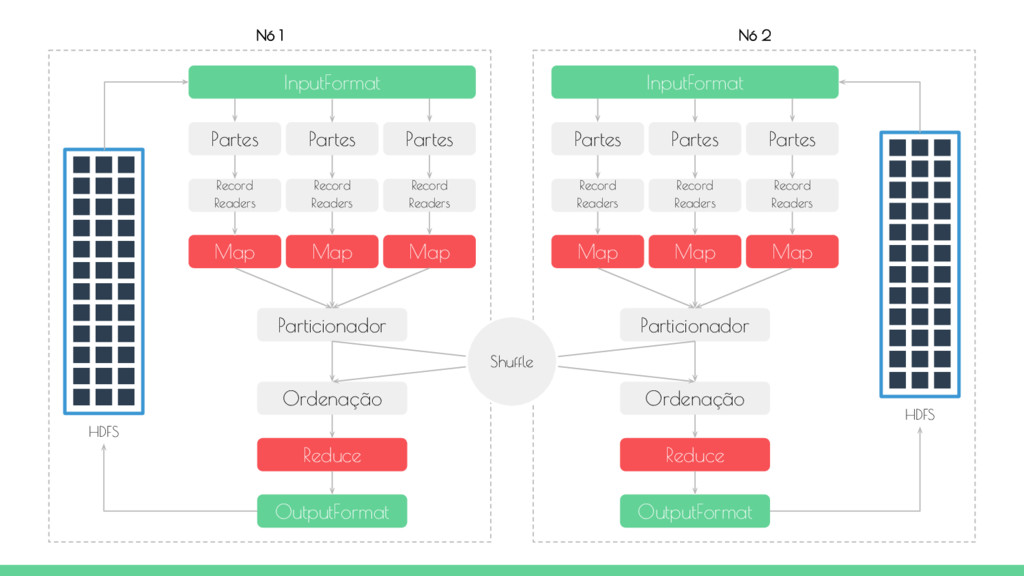
fase map são divididos entre os nós task tracker onde os dados estão localizados. Cada nó na fase map emite pares chave-valor com base no registro de entrada, um registro por vez. A fase shuffle é tratada pela estrutura Hadoop. Ela transfere os resultados dos dos mappers para os reducers juntando os resultados por meio chave. A saída dos mappers é enviado para os reducers. Os dados na fase reduce são divididos em partições onde cada reducer lê uma chave e uma lista de valores associados a essa chave. Os reducers emitem zero ou mais pares chave-valor com base na lógica utilizada.
1 jovem 1 saiu 1 com 1 um 1 belo 1 rapaz 1 para 1 um 1 belo 1 passeio 1 no 1 belo 1 parque 1 desta 1 bela 1 cidade 1 Chave Valor A 1 bela 1 bela 1 belo 1 belo 1 belo 1 cidade 1 com 1 desta 1 jovem 1 no 1 para 1 parque 1 passeio 1 rapaz 1 saiu 1 um 1 um 1 Chave Valor A 1 bela 1, 1 belo 1, 1, 1 cidade 1 com 1 desta 1 jovem 1 no 1 para 1 parque 1 passeio 1 rapaz 1 saiu 1 um 1, 1 Chave Valor A 1 bela 2 belo 3 cidade 1 com 1 desta 1 jovem 1 no 1 para 1 parque 1 passeio 1 rapaz 1 saiu 1 um 2 A bela jovem saiu com um belo rapaz para um belo passeio no belo parque desta bela cidade “ ”
na no map são divididos entre as task trackers onde os dados estão localizados. 2. A fase shuffle é implementada pelo próprio Hadoop. 3. Saída dos mappers são enviadas para os reducers como partições. 4. Reducers emitem zero ou mais chaves-valores baseado na lógica da aplicação. 5. Todas as anteriores. Exercícios
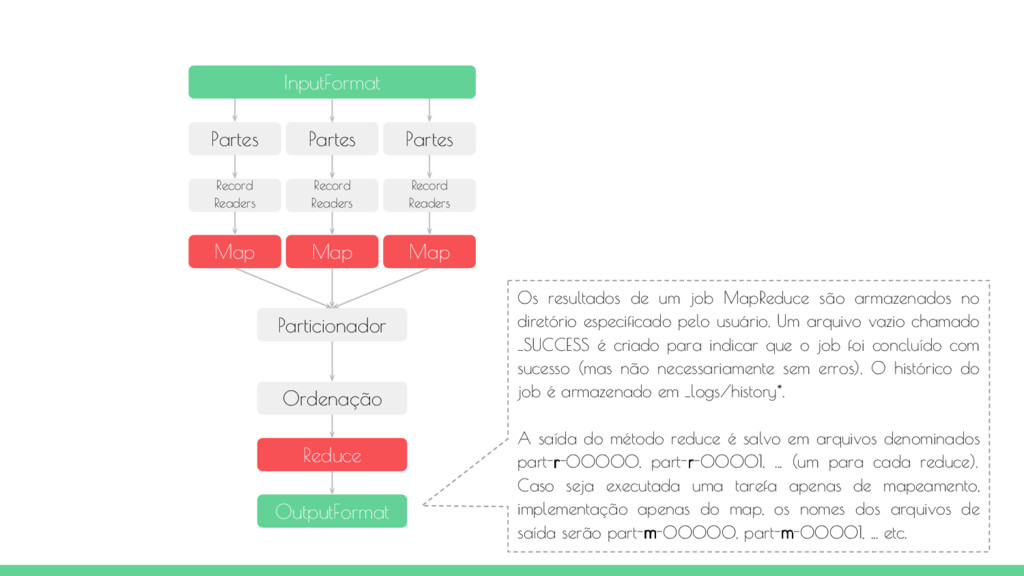
Readers Map Map Map Particionador Ordenação Reduce OutputFormat Nó 1 HDFS InputFormat Partes Partes Partes Record Readers Record Readers Record Readers Map Map Map Particionador Ordenação Reduce OutputFormat Nó 2 Shuffle
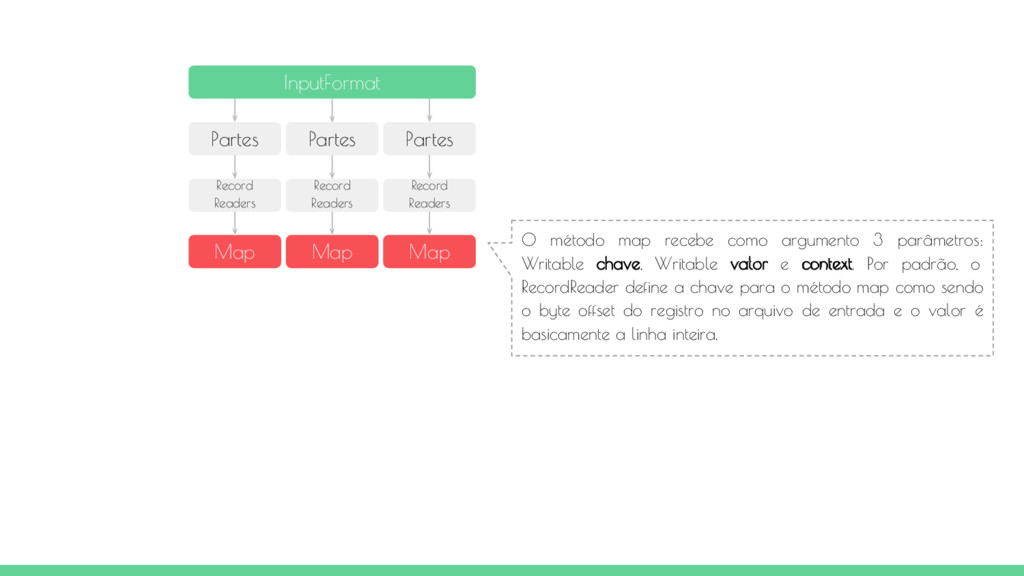
O objeto InputFormat é responsável por validar a entrada, dividindo os arquivos entre os mappers e instanciando os objetos RecordReaders. Por padrão, o tamanho de uma parte é igual ao tamanho de um bloco que no Hadoop o padrão é 64 Mb. As partão possuem um conjunto de registros onde cada um deles será quebrado em pares chave-valor para o map. A separação dos registros é feita antes mesmo da instanciação do do processo map. O job que está executando a tarefa MapReduce tentará colocar a tarefa map o mais próximo dos dados possível, ou seja, executar o processo map no mesmo nó do cluster onde o dados está armazenado.
Map Map Map O método map recebe como argumento 3 parâmetros: Writable chave, Writable valor e context. Por padrão, o RecordReader define a chave para o método map como sendo o byte offset do registro no arquivo de entrada e o valor é basicamente a linha inteira.
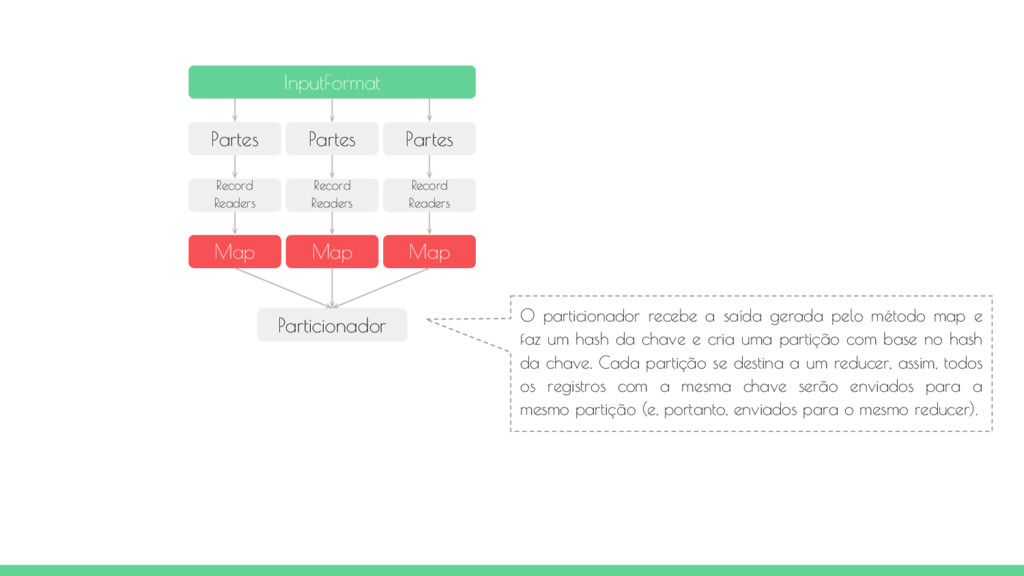
Map Map Map O particionador recebe a saída gerada pelo método map e faz um hash da chave e cria uma partição com base no hash da chave. Cada partição se destina a um reducer, assim, todos os registros com a mesma chave serão enviados para a mesmo partição (e, portanto, enviados para o mesmo reducer). Particionador
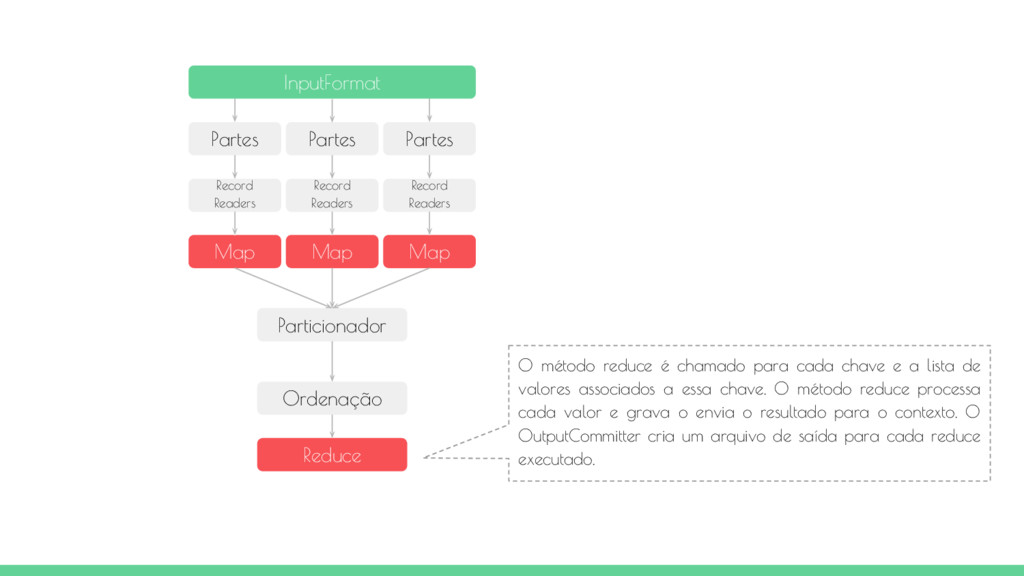
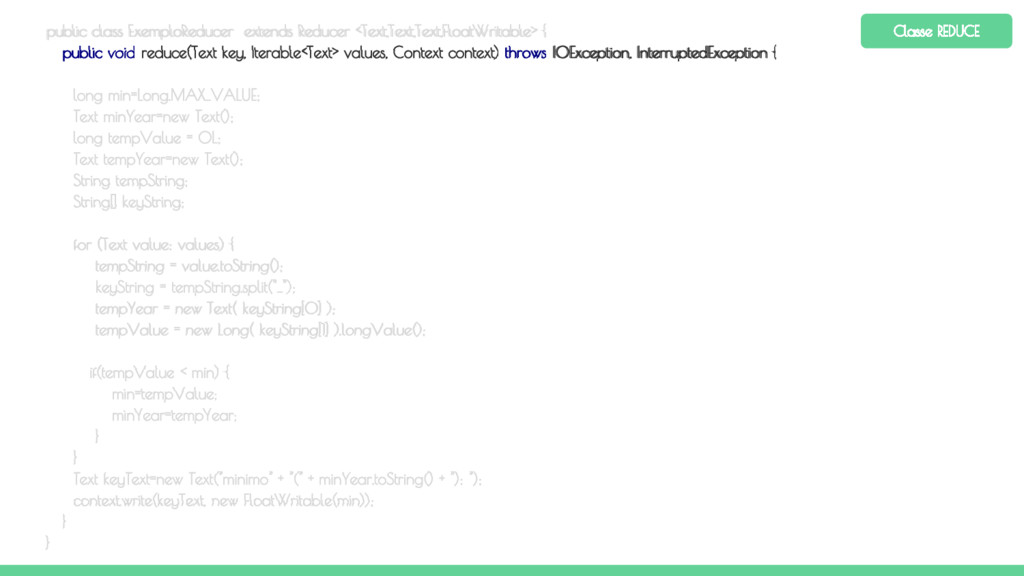
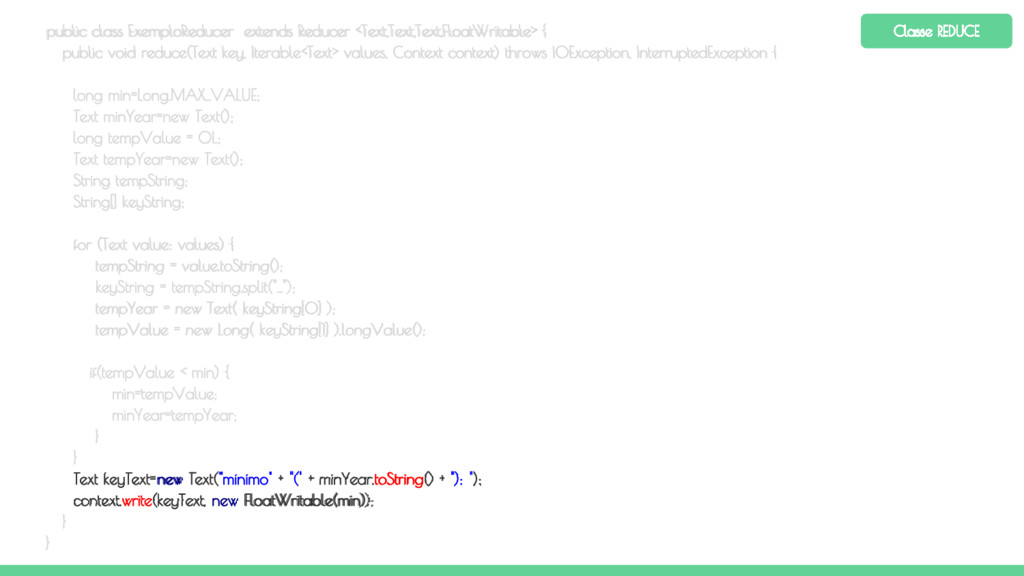
Map Map Map O método reduce é chamado para cada chave e a lista de valores associados a essa chave. O método reduce processa cada valor e grava o envia o resultado para o contexto. O OutputCommitter cria um arquivo de saída para cada reduce executado. Particionador Ordenação Reduce
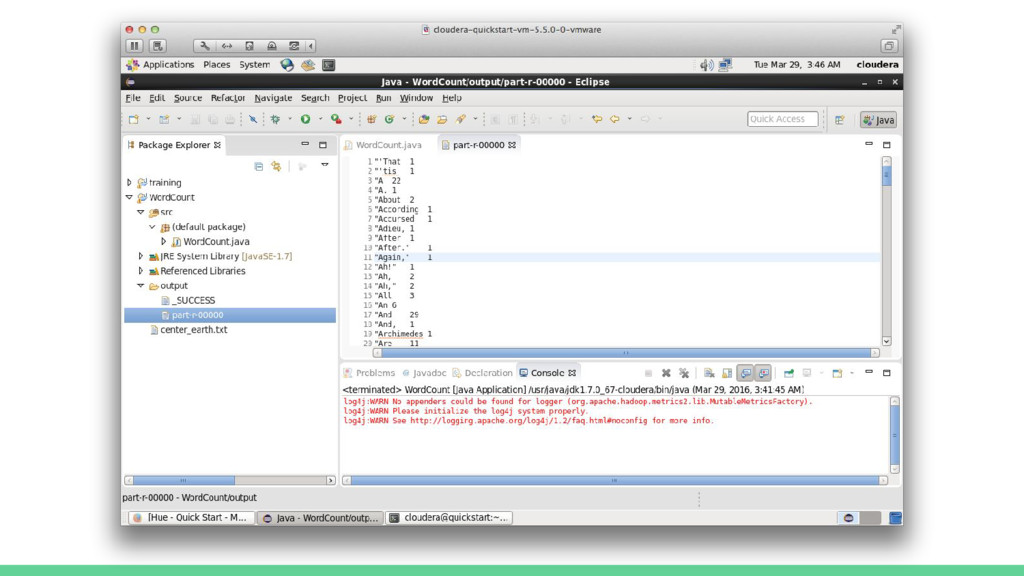
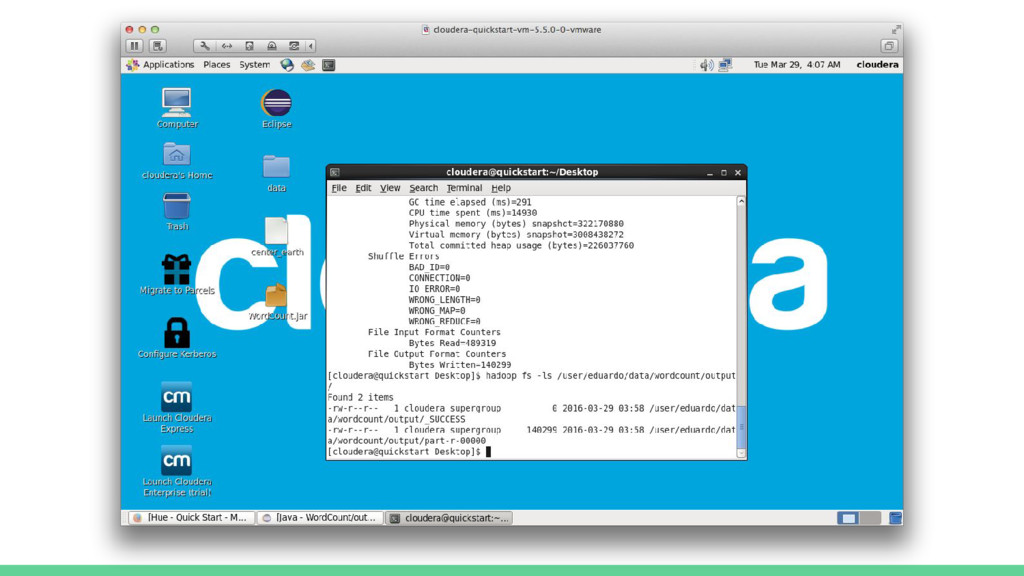
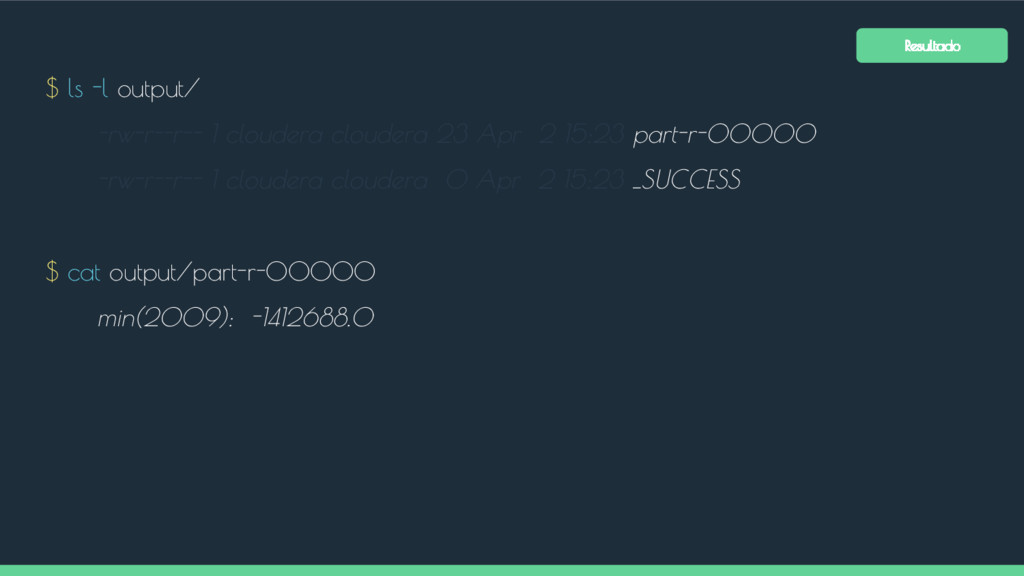
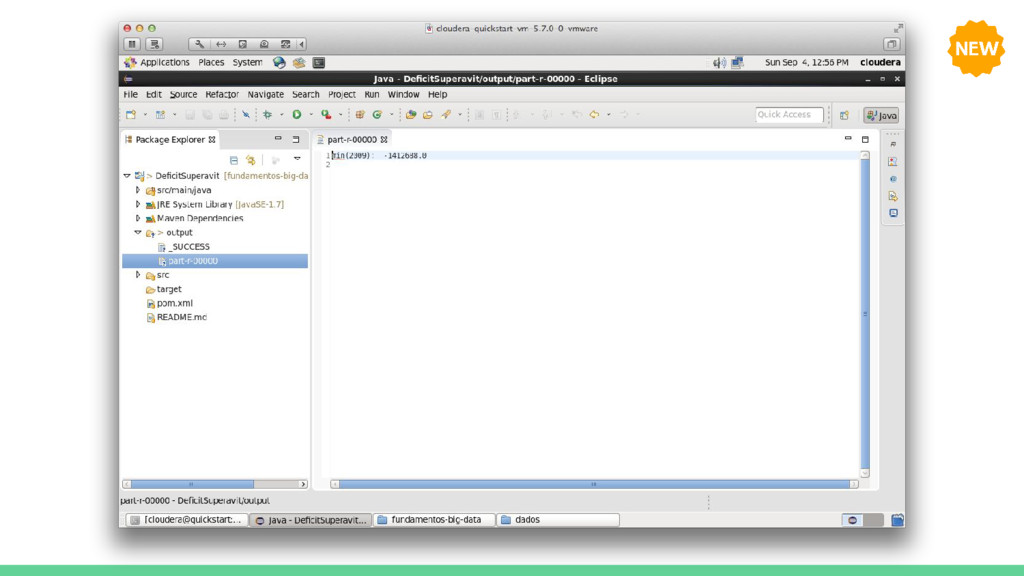
Map Map Map Os resultados de um job MapReduce são armazenados no diretório especificado pelo usuário. Um arquivo vazio chamado _SUCCESS é criado para indicar que o job foi concluído com sucesso (mas não necessariamente sem erros). O histórico do job é armazenado em _logs/history*. A saída do método reduce é salvo em arquivos denominados part-r-00000, part-r-00001, ... (um para cada reduce). Caso seja executada uma tarefa apenas de mapeamento, implementação apenas do map, os nomes dos arquivos de saída serão part-m-00000, part-m-00001, ... etc. Particionador Ordenação Reduce OutputFormat
cada chave é lido e processado. 2. Pares chave-valor são emitidos com base na entrada, sendo um registro por vez. 3. Os resultados são transferidos para os reducers. 4. Os valores são salvos em um arquivo de saida. Exercícios
etapa de reduce, fazer um hash do registro e criar uma partição com base no hash da chave. 2. Classificar e agrupar os dados a serem enviados para os reducers 3. Obter o resultado do map, fazer um hash do registro e criar uma partição com base no hash da chave. 4. Obter o resultado do TaskTracker a partir do reduce, fazer um hash do registro e criar uma partição com base no hash da chave. Exercícios
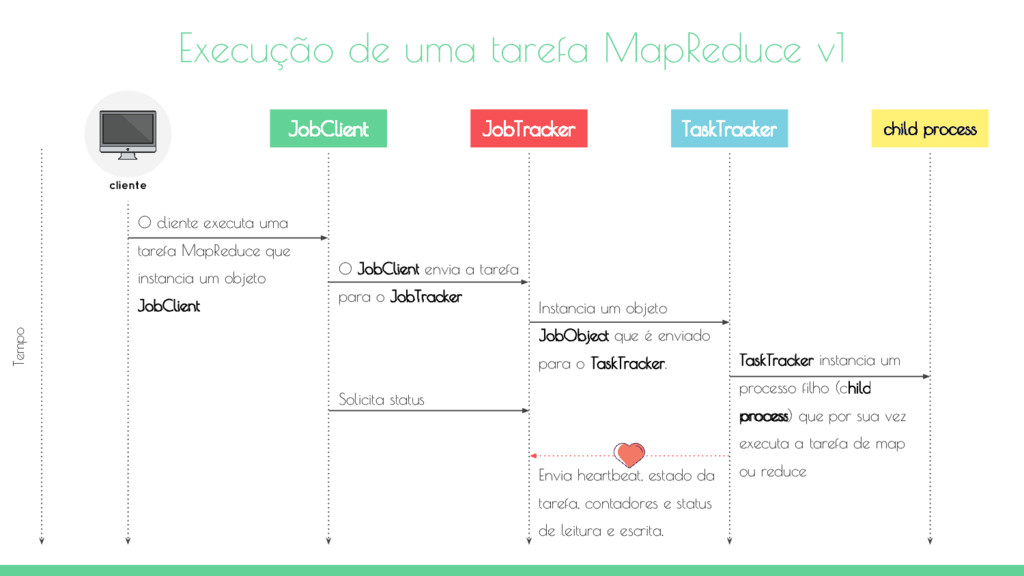
JobClient Execução de uma tarefa MapReduce v1 child process TaskTracker JobTracker JobClient cliente Tempo O JobClient envia a tarefa para o JobTracker Instancia um objeto JobObject que é enviado para o TaskTracker. TaskTracker instancia um processo filho (child process) que por sua vez executa a tarefa de map ou reduce Solicita status Envia heartbeat, estado da tarefa, contadores e status de leitura e escrita.
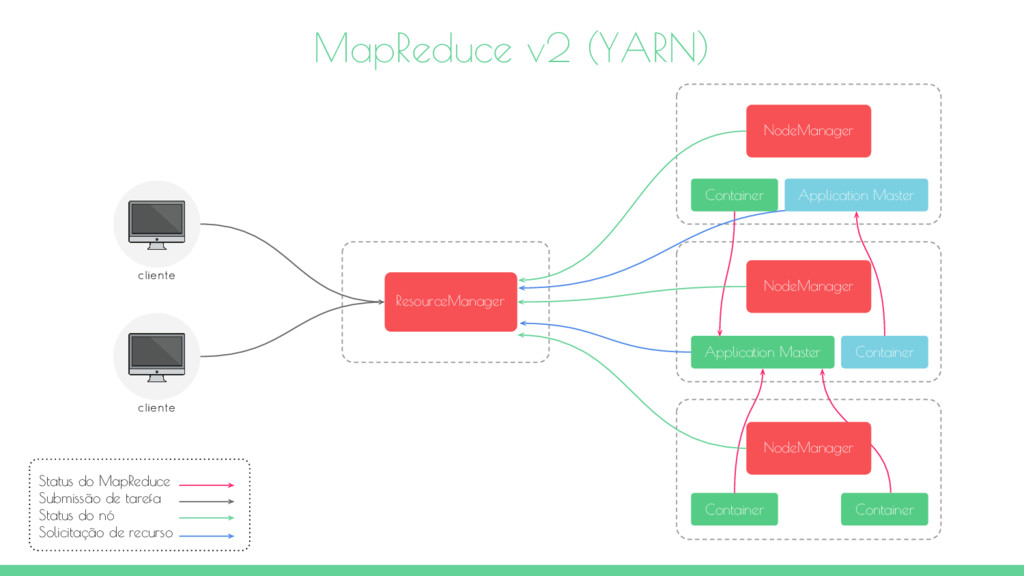
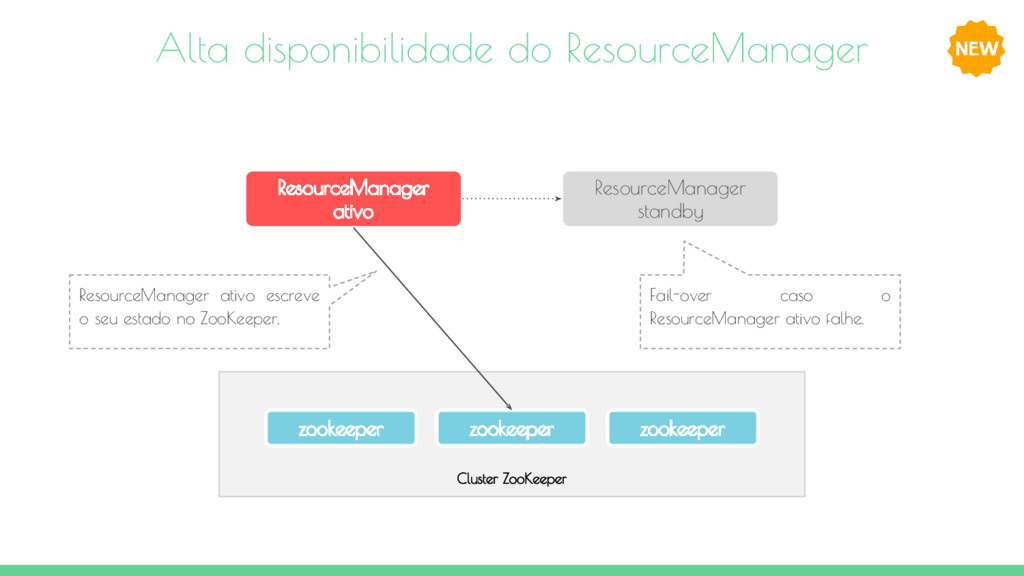
limite de 4000 nós o que limita a escalabilidade. Disponbilidade Um único JobTracker e namenode são pontos únicos de falha (Single point of failure - SPOF). Flexibilidade Slots de map e reduce não são configuráveis dinâmicamente. Existem duas propriedades mapred.tasktracker.map.tasks.maximum e mapred.tasktracker.reduce.tasks.maximum que limitam o número máximo possível de mappers e reducers sendo executados simultâneamente. Isso pode causar desperdício de recursos. Otimizador do agendador O framewrok não otimiza o agendamento de tarefas. Suporte O framework é restrito a tarefas apenas de map e reduce.
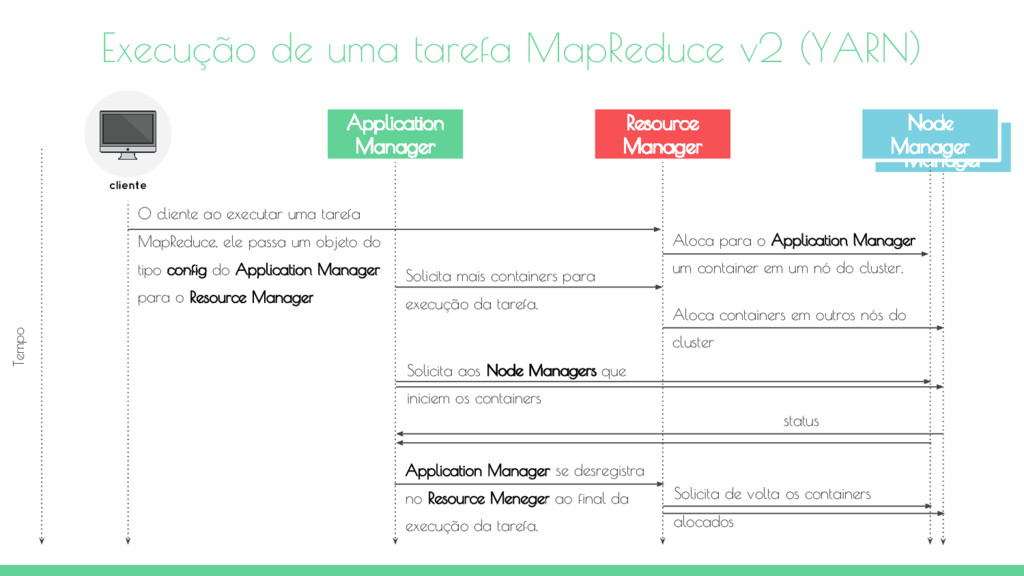
cliente ao executar uma tarefa MapReduce, ele passa um objeto do tipo config do Application Manager para o Resource Manager Execução de uma tarefa MapReduce v2 (YARN) Node Manager Resource Manager Application Manager cliente Tempo Aloca para o Application Manager um container em um nó do cluster. Solicita mais containers para execução da tarefa. Solicita aos Node Managers que iniciem os containers status Application Manager se desregistra no Resource Meneger ao final da execução da tarefa. Solicita de volta os containers alocados
partir de falhas das máquinas. 2. Shuffle dos dados entre as funções de Map e Reduce. 3. Executar funções Map Reduce em múltiplas máquinas. 4. Automaticamente paraliza um algoritmo. 5. Recuperação a partir de máquinas lentas. Exercícios
meio da abordagem por divisão e conquista? 1. Mover dados é computacionalmente "caro". 2. Usar uma única máquina é mais rápido que várias máquinas. 3. Utilizar muitas máquinas significa ter que le dar com muitas falhas. 4. Utilizar muitas máquinas significa ter que le dar com máquinas lentas. 5. Utilizar tabelas hash para documentos grandes funciona bem. Exercícios
Não existe configuração de slot no YARN. 2. O Job Tracker equivalente no YARN suporta multiplas instancias por cluster para escalar. 3. YARN suporta tarefas MapReduce e não MapReduce. 4. Todas as opções acima. Exercícios
YARN suporta apenas tarefas MapReduce. 2. A arquitetura do YARN limita o número de nós do cluster. 3. YARN utiliza uma API e um CLI (command line interface) diferente da versão MRv1. 4. A arquitetura YARN implementa separadamente o gerente de recursos (resource manager) do gerente de tarefas (job management). Exercícios
Tracker, o Job Tracker: 1. Acusa o erro e para a execução. 2. Reinicia a Task Tracker que falhou. 3. Reagenda a tarefa para 5 segundos depois no mesmo Task Tracker. 4. Reagenda a tarefa que falhou em um outro Task Tracker. Exercícios
Text, Text, IntWritable> { private final static IntWritable one = new IntWritable(1); private Text word = new Text(); public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { String line = value.toString(); StringTokenizer tokenizer = new StringTokenizer(line); while (tokenizer.hasMoreTokens()) { word.set(tokenizer.nextToken()); context.write(word, one); } } } WordCount.java
public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException { int sum = 0; for (IntWritable val : values) { sum += val.get(); } context.write(key, new IntWritable(sum)); } } WordCount.java
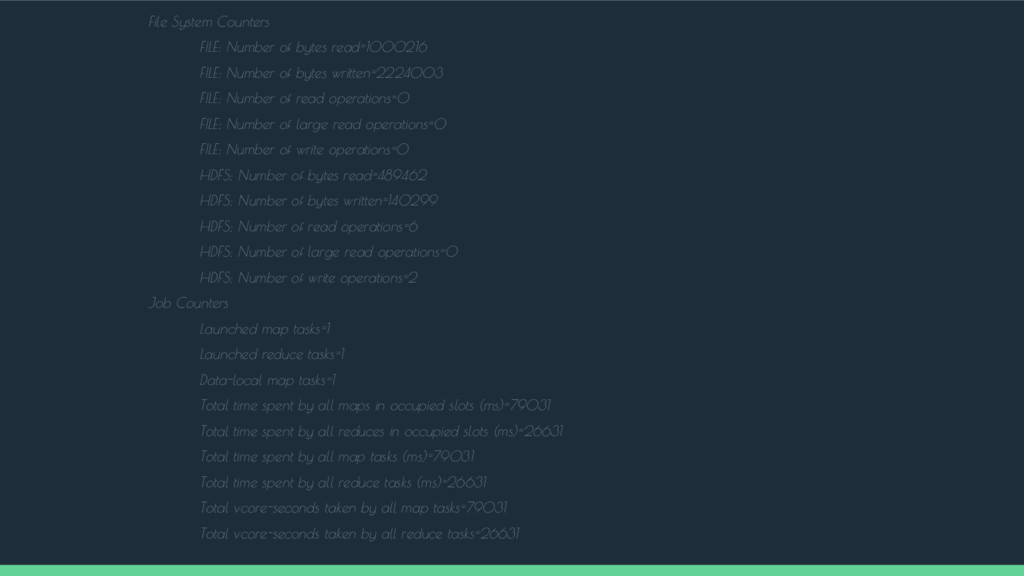
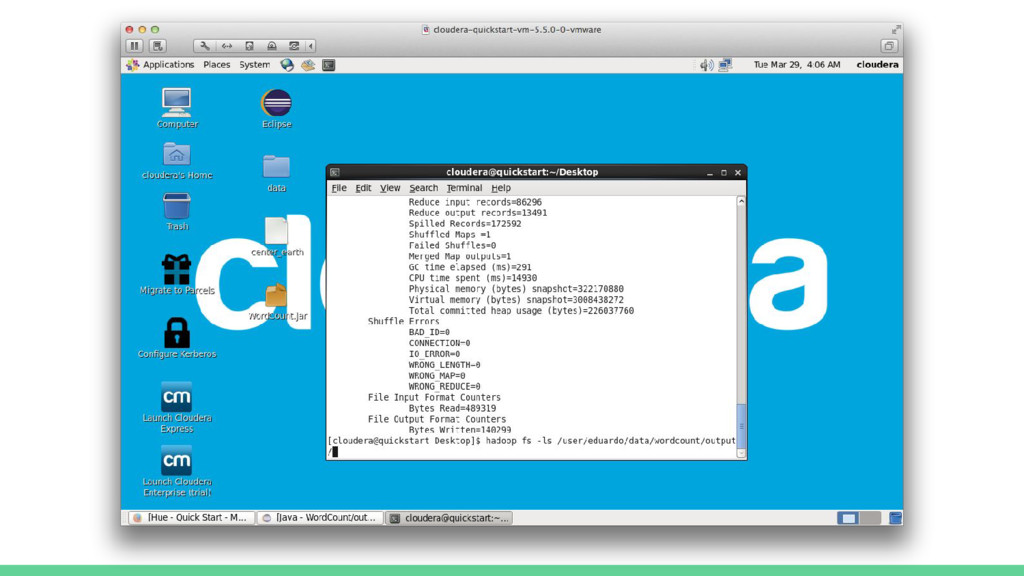
INFO client.RMProxy: Connecting to ResourceManager at /0.0.0.0:8032 16/03/29 03:56:02 WARN mapreduce.JobResourceUploader: Hadoop command-line option parsing not performed. Implement the Tool interface and execute your application with ToolRunner to remedy this. 16/03/29 03:56:03 INFO input.FileInputFormat: Total input paths to process : 1 16/03/29 03:56:04 INFO mapreduce.JobSubmitter: number of splits:1 16/03/29 03:56:04 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1458437037802_0001 16/03/29 03:56:08 INFO impl.YarnClientImpl: Submitted application application_1458437037802_0001 16/03/29 03:56:08 INFO mapreduce.Job: The url to track the job: http://quickstart.cloudera:8088/proxy/application_1458437037802_0001/ 16/03/29 03:56:08 INFO mapreduce.Job: Running job: job_1458437037802_0001 16/03/29 03:56:41 INFO mapreduce.Job: Job job_1458437037802_0001 running in uber mode : false 16/03/29 03:56:41 INFO mapreduce.Job: map 0% reduce 0% 16/03/29 03:58:02 INFO mapreduce.Job: map 100% reduce 0% 16/03/29 03:58:32 INFO mapreduce.Job: map 100% reduce 100% 16/03/29 03:58:33 INFO mapreduce.Job: Job job_1458437037802_0001 completed successfully 16/03/29 03:58:33 INFO mapreduce.Job: Counters: 49
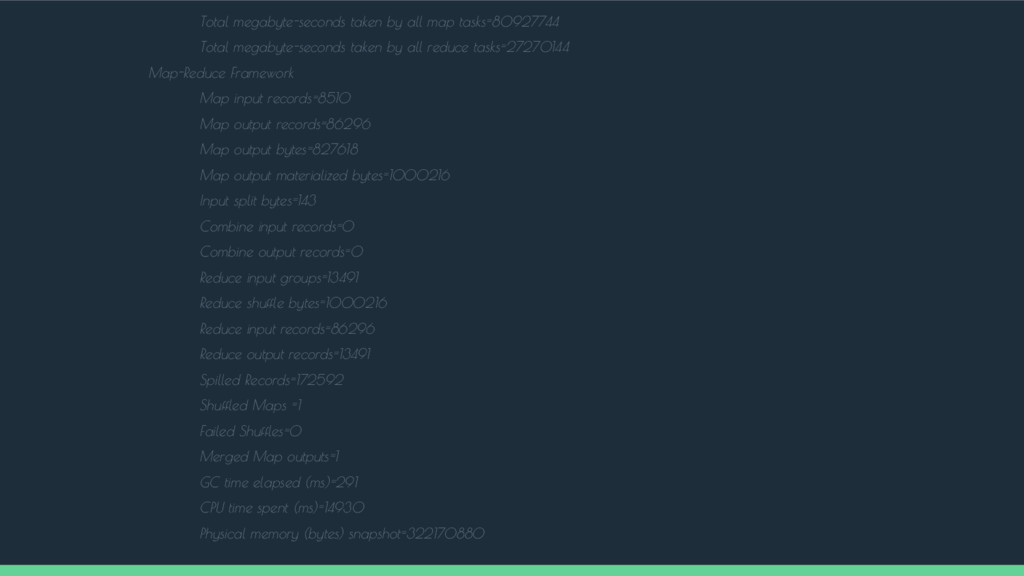
of bytes written=2224003 FILE: Number of read operations=0 FILE: Number of large read operations=0 FILE: Number of write operations=0 HDFS: Number of bytes read=489462 HDFS: Number of bytes written=140299 HDFS: Number of read operations=6 HDFS: Number of large read operations=0 HDFS: Number of write operations=2 Job Counters Launched map tasks=1 Launched reduce tasks=1 Data-local map tasks=1 Total time spent by all maps in occupied slots (ms)=79031 Total time spent by all reduces in occupied slots (ms)=26631 Total time spent by all map tasks (ms)=79031 Total time spent by all reduce tasks (ms)=26631 Total vcore-seconds taken by all map tasks=79031 Total vcore-seconds taken by all reduce tasks=26631
mapper e reducer A maior parte não-lógica de um código MapReduce é o mesmo em todas as aplicações. Isto inclui declarações de importação, definições de classe e assinaturas de método. 2. Modificar o template de acordo com as necessidades 3. Entender o fluxo de transformação dos dados O aspecto mais importante das aplicações MapReduce é entender como os dados são transformados a medida que são executado no framework MapReduce. Existem essencialmente quatro transformações do início ao fim • Como os dados são transformados a partir dos arquivos de entrada e alimentados nos mappers. • Como os dados são transformados pelos mapeadores. • Como os dados são ordenados, mesclados, e apresentado ao reducer. • Como os reducers transformam os dados e gravam os arquivos de saída. 4. Identificar os tipos adequados para as chaves e valores Construção de uma tarefa MapReduce
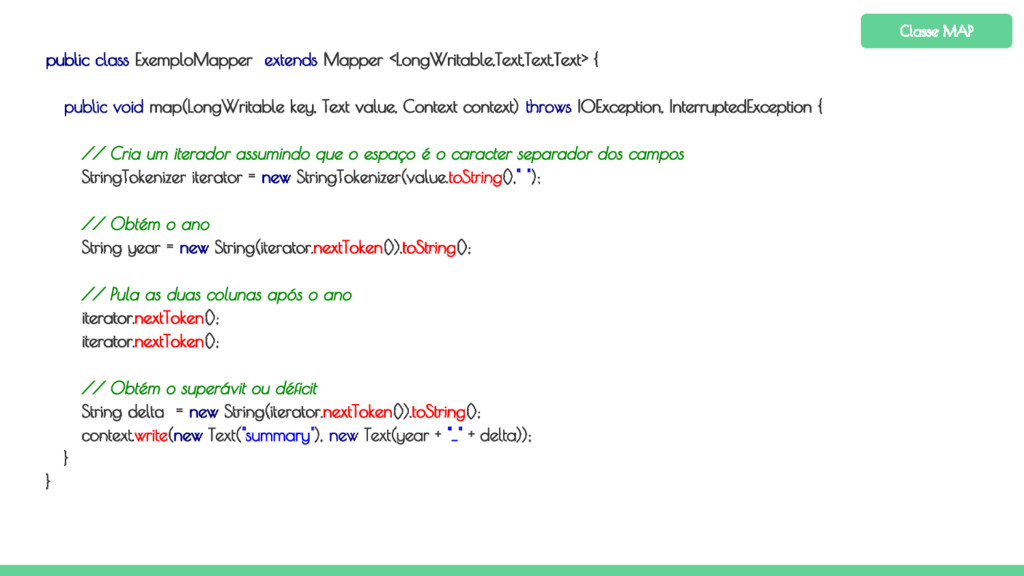
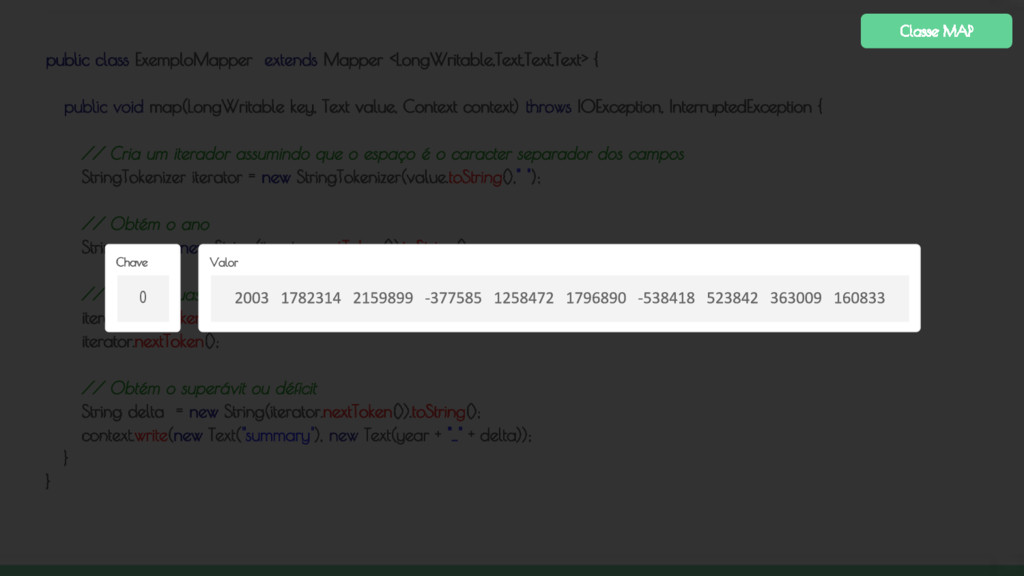
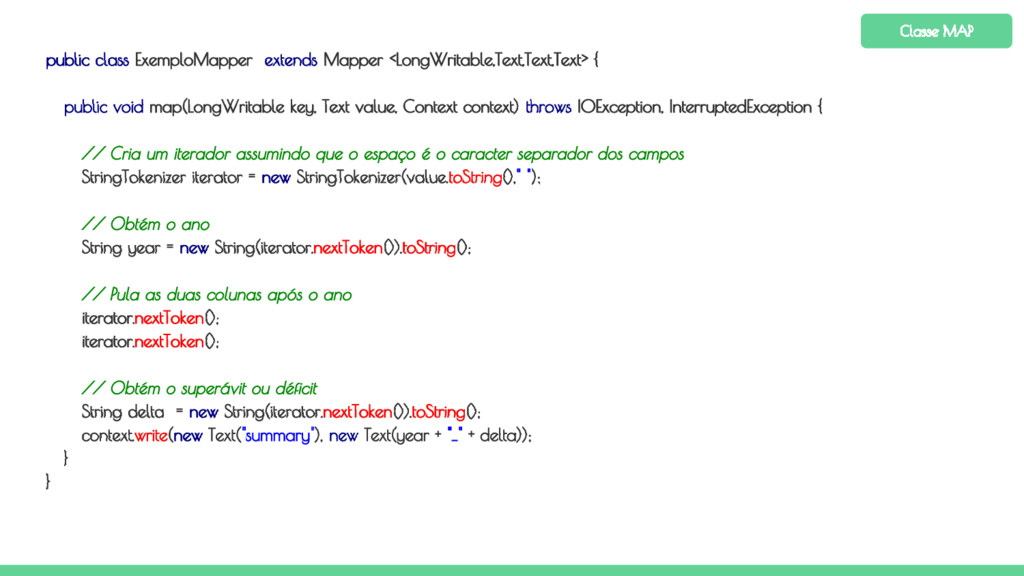
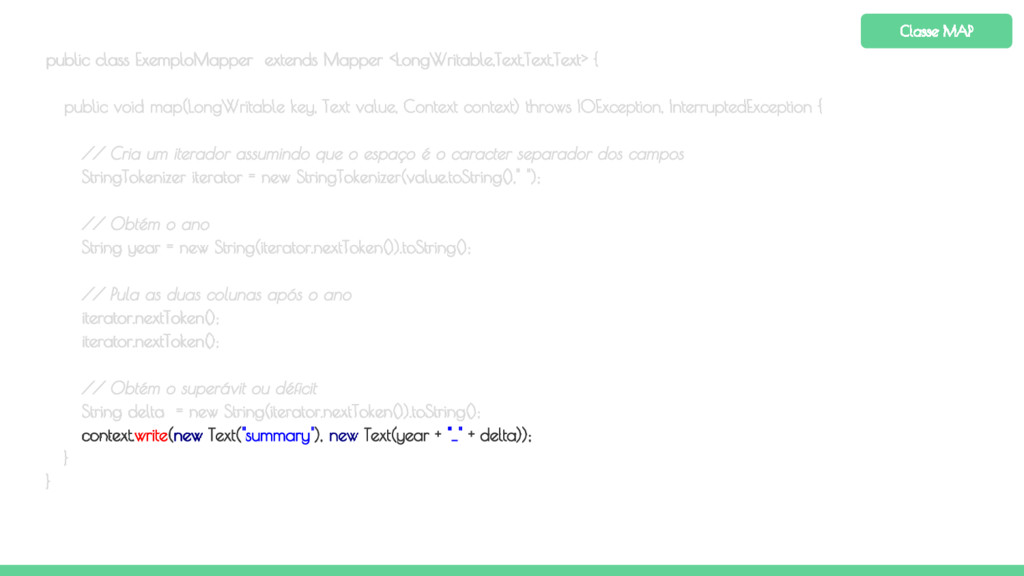
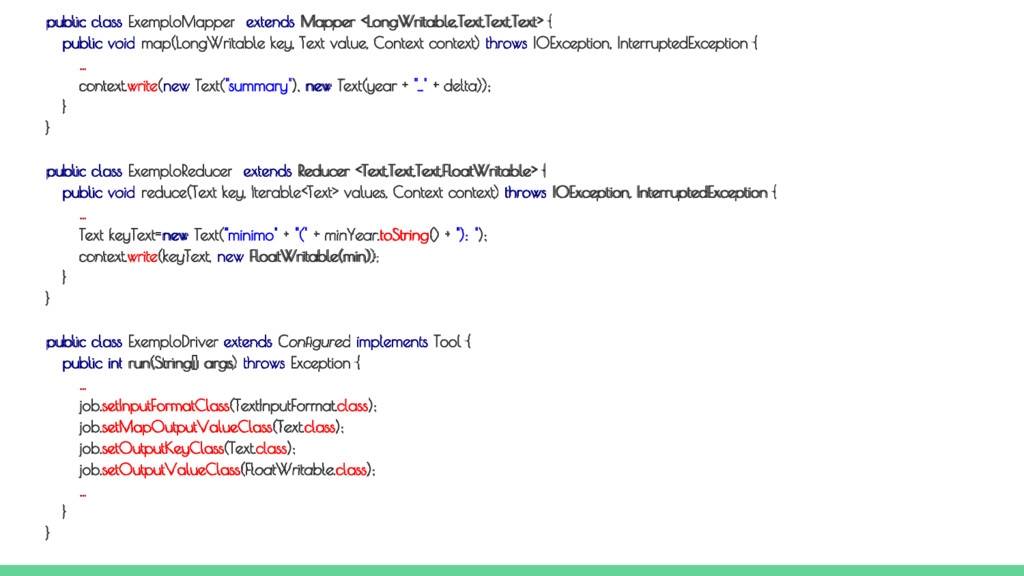
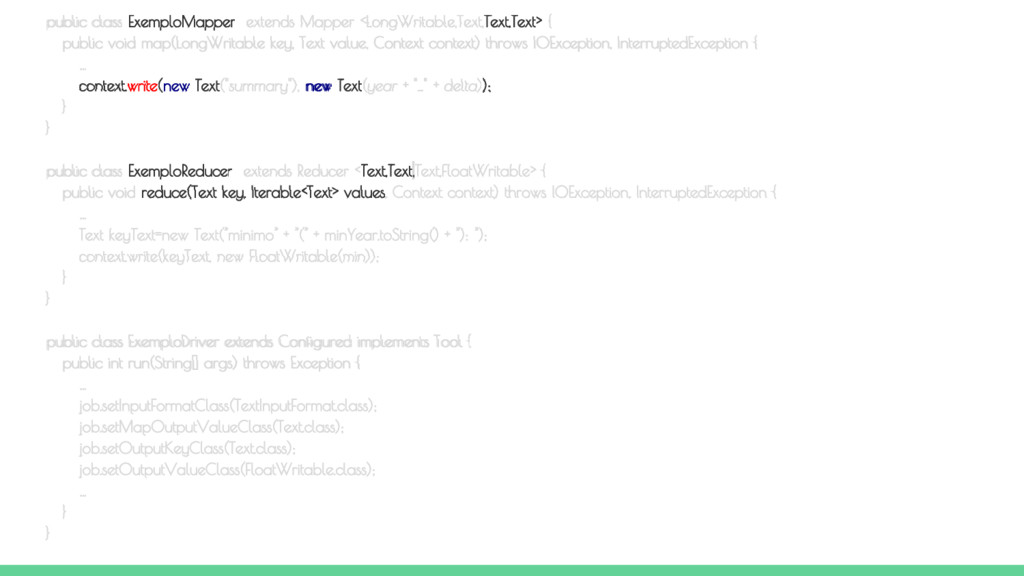
key, Text value, Context context) throws IOException, InterruptedException { // Cria um iterador assumindo que o espaço é o caracter separador dos campos StringTokenizer iterator = new StringTokenizer(value.toString()," "); // Obtém o ano String year = new String(iterator.nextToken()).toString(); // Pula as duas colunas após o ano iterator.nextToken(); iterator.nextToken(); // Obtém o superávit ou déficit String delta = new String(iterator.nextToken()).toString(); context.write(new Text("summary"), new Text(year + "_" + delta)); } } Classe MAP
key, Text value, Context context) throws IOException, InterruptedException { // Cria um iterador assumindo que o espaço é o caracter separador dos campos StringTokenizer iterator = new StringTokenizer(value.toString()," "); // Obtém o ano String year = new String(iterator.nextToken()).toString(); // Pula as duas colunas após o ano iterator.nextToken(); iterator.nextToken(); // Obtém o superávit ou déficit String delta = new String(iterator.nextToken()).toString(); context.write(new Text("summary"), new Text(year + "_" + delta)); } } Chave 0 Valor Classe MAP
key, Text value, Context context) throws IOException, InterruptedException { // Cria um iterador assumindo que o espaço é o caracter separador dos campos StringTokenizer iterator = new StringTokenizer(value.toString()," "); // Obtém o ano String year = new String(iterator.nextToken()).toString(); // Pula as duas colunas após o ano iterator.nextToken(); iterator.nextToken(); // Obtém o superávit ou déficit String delta = new String(iterator.nextToken()).toString(); context.write(new Text("summary"), new Text(year + "_" + delta)); } } Classe MAP
key, Text value, Context context) throws IOException, InterruptedException { // Cria um iterador assumindo que o espaço é o caracter separador dos campos StringTokenizer iterator = new StringTokenizer(value.toString()," "); // Obtém o ano String year = new String(iterator.nextToken()).toString(); // Pula as duas colunas após o ano iterator.nextToken(); iterator.nextToken(); // Obtém o superávit ou déficit String delta = new String(iterator.nextToken()).toString(); context.write(new Text("summary"), new Text(year + "_" + delta)); } } Classe MAP
key, Text value, Context context) throws IOException, InterruptedException { // Cria um iterador assumindo que o espaço é o caracter separador dos campos StringTokenizer iterator = new StringTokenizer(value.toString()," "); // Obtém o ano String year = new String(iterator.nextToken()).toString(); // Pula as duas colunas após o ano iterator.nextToken(); iterator.nextToken(); // Obtém o superávit ou déficit String delta = new String(iterator.nextToken()).toString(); context.write(new Text("summary"), new Text(year + "_" + delta)); } } Classe MAP
key, Text value, Context context) throws IOException, InterruptedException { // Cria um iterador assumindo que o espaço é o caracter separador dos campos StringTokenizer iterator = new StringTokenizer(value.toString()," "); // Obtém o ano String year = new String(iterator.nextToken()).toString(); // Pula as duas colunas após o ano iterator.nextToken(); iterator.nextToken(); // Obtém o superávit ou déficit String delta = new String(iterator.nextToken()).toString(); context.write(new Text("summary"), new Text(year + "_" + delta)); } } Classe MAP
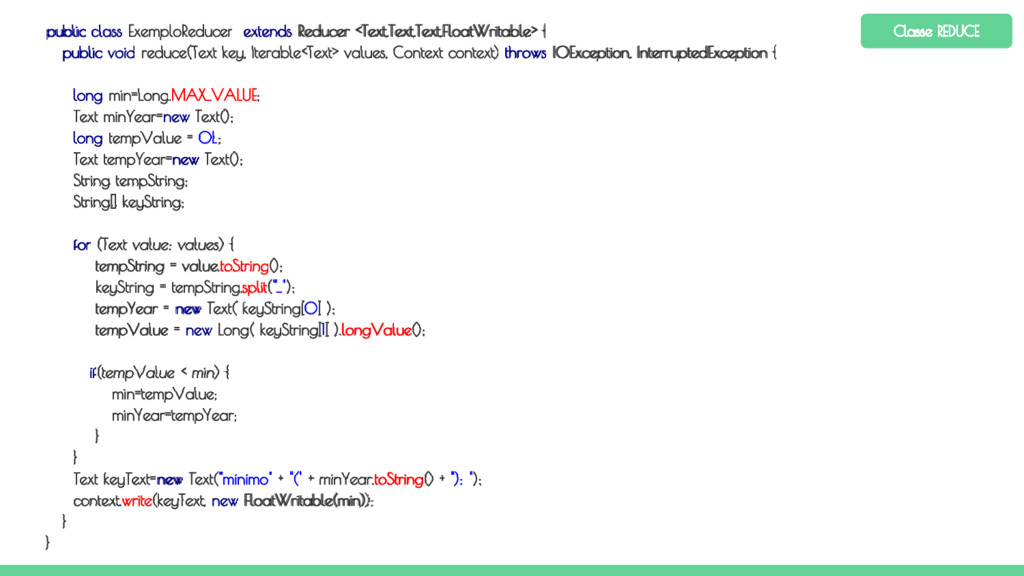
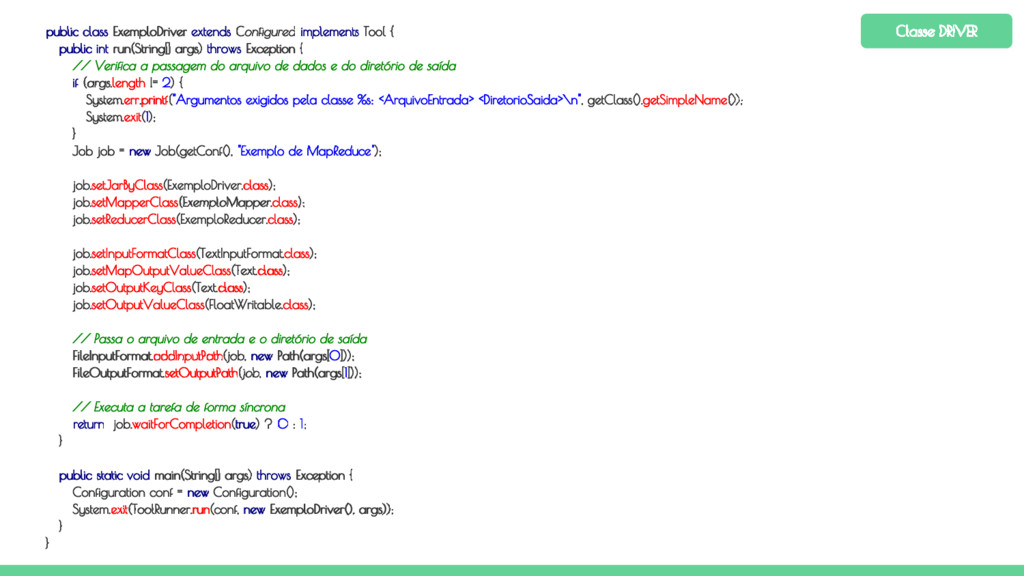
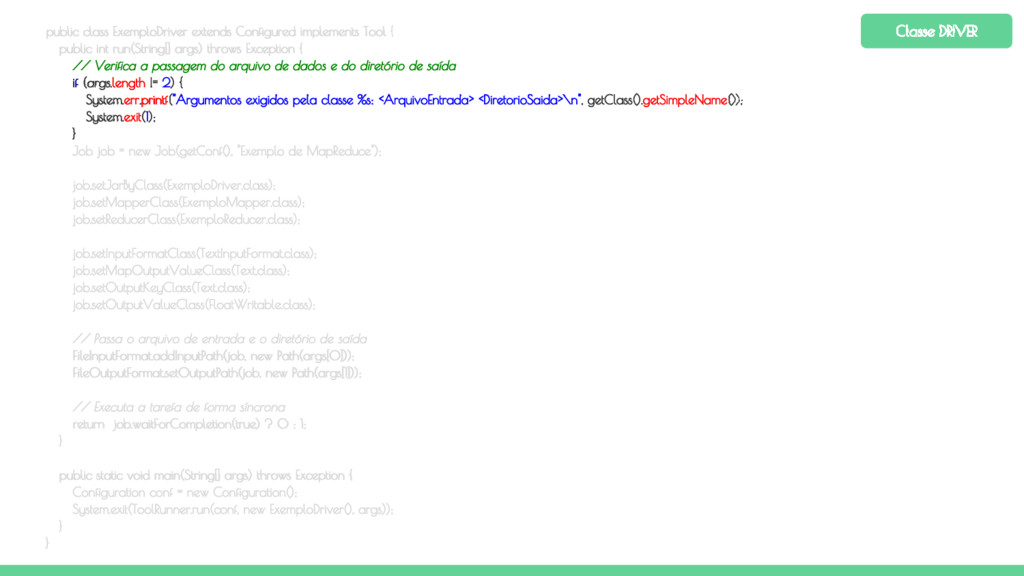
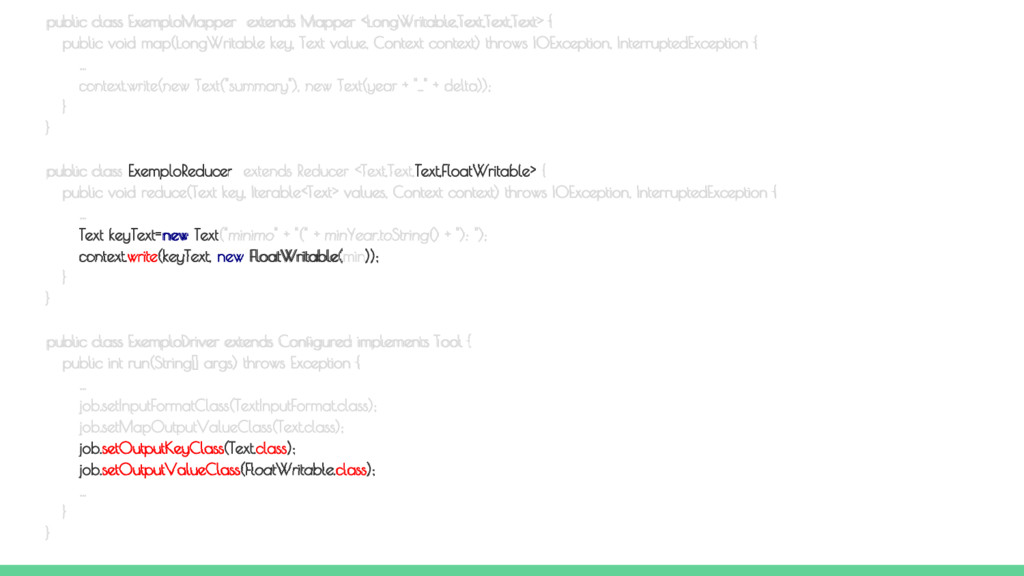
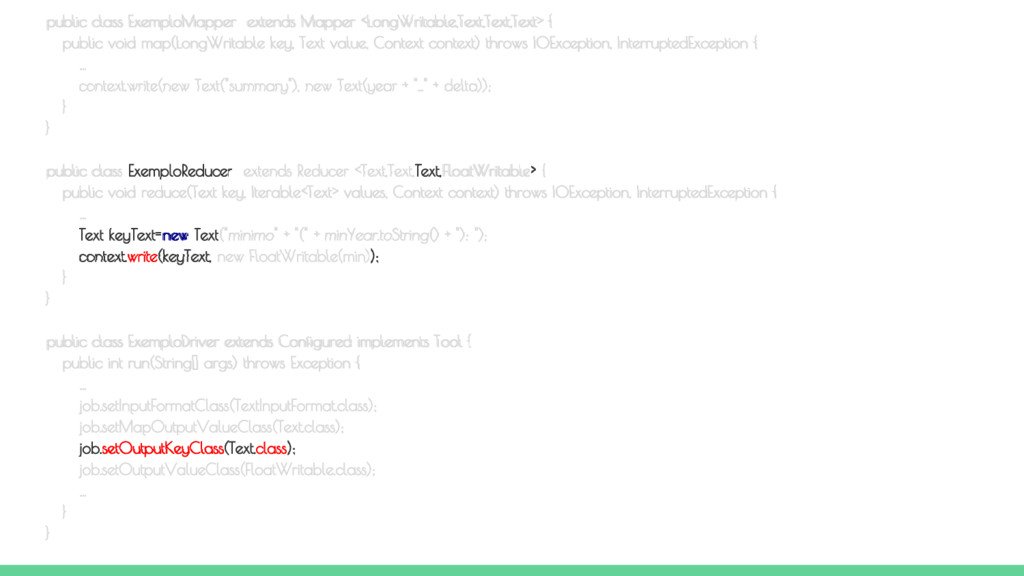
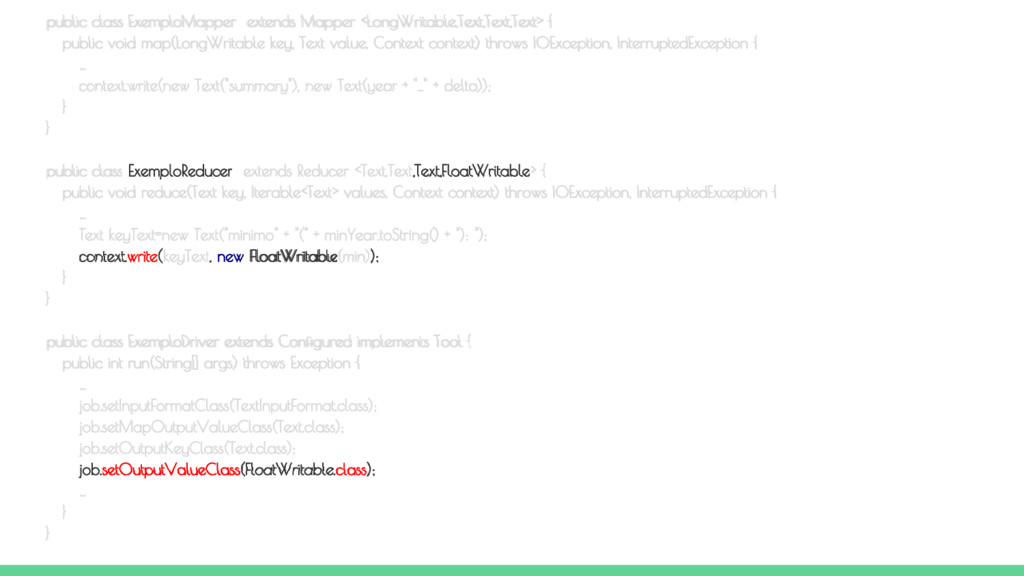
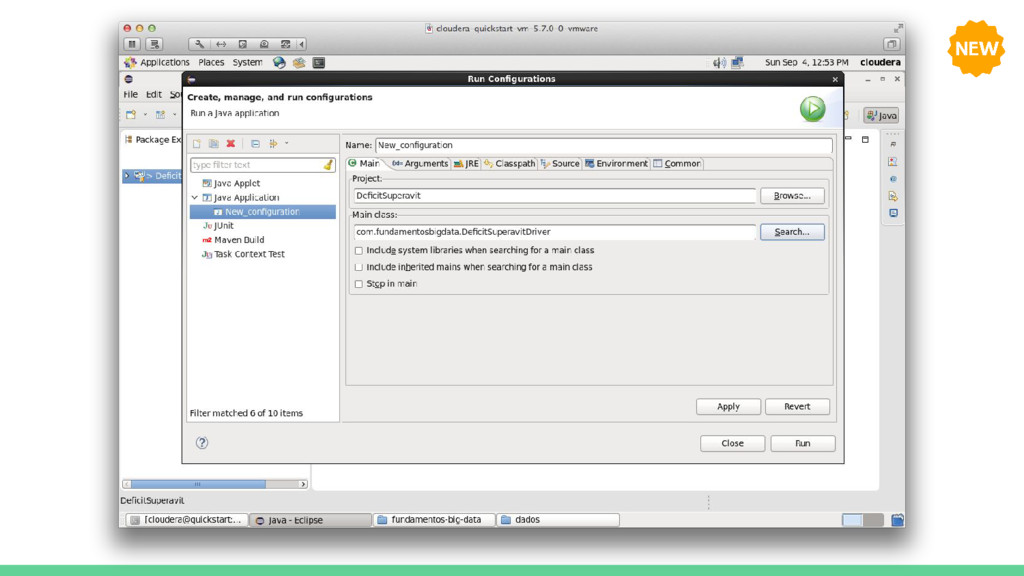
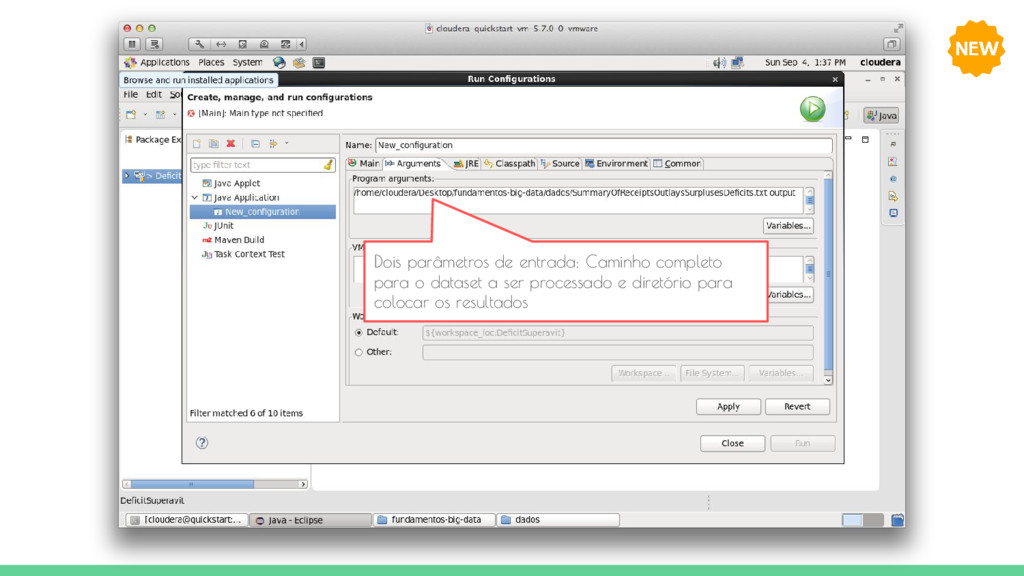
run(String[] args) throws Exception { // Verifica a passagem do arquivo de dados e do diretório de saída if (args.length != 2) { System.err.printf("Argumentos exigidos pela classe %s: <ArquivoEntrada> <DiretorioSaida>\n", getClass().getSimpleName()); System.exit(1); } Job job = new Job(getConf(), "Exemplo de MapReduce"); job.setJarByClass(ExemploDriver.class); job.setMapperClass(ExemploMapper.class); job.setReducerClass(ExemploReducer.class); job.setInputFormatClass(TextInputFormat.class); job.setMapOutputValueClass(Text.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(FloatWritable.class); // Passa o arquivo de entrada e o diretório de saída FileInputFormat.addInputPath(job, new Path(args[0])); FileOutputFormat.setOutputPath(job, new Path(args[1])); // Executa a tarefa de forma síncrona return job.waitForCompletion(true) ? 0 : 1; } public static void main(String[] args) throws Exception { Configuration conf = new Configuration(); System.exit(ToolRunner.run(conf, new ExemploDriver(), args)); } } Classe DRIVER
run(String[] args) throws Exception { // Verifica a passagem do arquivo de dados e do diretório de saída if (args.length != 2) { System.err.printf("Argumentos exigidos pela classe %s: <ArquivoEntrada> <DiretorioSaida>\n", getClass().getSimpleName()); System.exit(1); } Job job = new Job(getConf(), "Exemplo de MapReduce"); job.setJarByClass(ExemploDriver.class); job.setMapperClass(ExemploMapper.class); job.setReducerClass(ExemploReducer.class); job.setInputFormatClass(TextInputFormat.class); job.setMapOutputValueClass(Text.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(FloatWritable.class); // Passa o arquivo de entrada e o diretório de saída FileInputFormat.addInputPath(job, new Path(args[0])); FileOutputFormat.setOutputPath(job, new Path(args[1])); // Executa a tarefa de forma síncrona return job.waitForCompletion(true) ? 0 : 1; } public static void main(String[] args) throws Exception { Configuration conf = new Configuration(); System.exit(ToolRunner.run(conf, new ExemploDriver(), args)); } } Classe DRIVER
run(String[] args) throws Exception { Job job = new Job(getConf(), "Exemplo de MapReduce"); job.setJarByClass(ExemploDriver.class); job.setMapperClass(ExemploMapper.class); job.setReducerClass(ExemploReducer.class); job.setInputFormatClass(TextInputFormat.class); job.setMapOutputValueClass(Text.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(FloatWritable.class); // Passa o arquivo de entrada e o diretório de saída FileInputFormat.addInputPath(job, new Path(args[0])); FileOutputFormat.setOutputPath(job, new Path(args[1])); // Executa a tarefa de forma síncrona return job.waitForCompletion(true) ? 0 : 1; } public static void main(String[] args) throws Exception { Configuration conf = new Configuration(); System.exit(ToolRunner.run(conf, new ExemploDriver(), args)); } } Classe DRIVER
run(String[] args) throws Exception { Job job = new Job(getConf(), "Exemplo de MapReduce"); job.setJarByClass(ExemploDriver.class); job.setMapperClass(ExemploMapper.class); job.setReducerClass(ExemploReducer.class); job.setInputFormatClass(TextInputFormat.class); job.setMapOutputValueClass(Text.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(FloatWritable.class); // Passa o arquivo de entrada e o diretório de saída FileInputFormat.addInputPath(job, new Path(args[0])); FileOutputFormat.setOutputPath(job, new Path(args[1])); // Executa a tarefa de forma síncrona return job.waitForCompletion(true) ? 0 : 1; } public static void main(String[] args) throws Exception { Configuration conf = new Configuration(); System.exit(ToolRunner.run(conf, new ExemploDriver(), args)); } } Classe DRIVER
run(String[] args) throws Exception { Job job = new Job(getConf(), "Exemplo de MapReduce"); job.setJarByClass(ExemploDriver.class); job.setMapperClass(ExemploMapper.class); job.setReducerClass(ExemploReducer.class); job.setInputFormatClass(TextInputFormat.class); job.setMapOutputValueClass(Text.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(FloatWritable.class); // Passa o arquivo de entrada e o diretório de saída FileInputFormat.addInputPath(job, new Path(args[0])); FileOutputFormat.setOutputPath(job, new Path(args[1])); // Executa a tarefa de forma síncrona return job.waitForCompletion(true) ? 0 : 1; } public static void main(String[] args) throws Exception { Configuration conf = new Configuration(); System.exit(ToolRunner.run(conf, new ExemploDriver(), args)); } } Classe DRIVER
run(String[] args) throws Exception { Job job = new Job(getConf(), "Exemplo de MapReduce"); job.setJarByClass(ExemploDriver.class); job.setMapperClass(ExemploMapper.class); job.setReducerClass(ExemploReducer.class); job.setInputFormatClass(TextInputFormat.class); job.setMapOutputValueClass(Text.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(FloatWritable.class); // Passa o arquivo de entrada e o diretório de saída FileInputFormat.addInputPath(job, new Path(args[0])); FileOutputFormat.setOutputPath(job, new Path(args[1])); // Executa a tarefa de forma síncrona return job.waitForCompletion(true) ? 0 : 1; } public static void main(String[] args) throws Exception { Configuration conf = new Configuration(); System.exit(ToolRunner.run(conf, new ExemploDriver(), args)); } } Classe DRIVER
run(String[] args) throws Exception { Job job = new Job(getConf(), "Exemplo de MapReduce"); job.setJarByClass(ExemploDriver.class); job.setMapperClass(ExemploMapper.class); job.setReducerClass(ExemploReducer.class); job.setInputFormatClass(TextInputFormat.class); job.setMapOutputValueClass(Text.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(FloatWritable.class); // Passa o arquivo de entrada e o diretório de saída FileInputFormat.addInputPath(job, new Path(args[0])); FileOutputFormat.setOutputPath(job, new Path(args[1])); // Executa a tarefa de forma síncrona return job.waitForCompletion(true) ? 0 : 1; } public static void main(String[] args) throws Exception { Configuration conf = new Configuration(); System.exit(ToolRunner.run(conf, new ExemploDriver(), args)); } } Classe DRIVER
run(String[] args) throws Exception { Job job = new Job(getConf(), "Exemplo de MapReduce"); job.setJarByClass(ExemploDriver.class); job.setMapperClass(ExemploMapper.class); job.setReducerClass(ExemploReducer.class); job.setInputFormatClass(TextInputFormat.class); job.setMapOutputValueClass(Text.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(FloatWritable.class); // Passa o arquivo de entrada e o diretório de saída FileInputFormat.addInputPath(job, new Path(args[0])); FileOutputFormat.setOutputPath(job, new Path(args[1])); // Executa a tarefa de forma síncrona return job.waitForCompletion(true) ? 0 : 1; } public static void main(String[] args) throws Exception { Configuration conf = new Configuration(); System.exit(ToolRunner.run(conf, new ExemploDriver(), args)); } } Classe DRIVER
run(String[] args) throws Exception { Job job = new Job(getConf(), "Exemplo de MapReduce"); job.setJarByClass(ExemploDriver.class); job.setMapperClass(ExemploMapper.class); job.setReducerClass(ExemploReducer.class); job.setInputFormatClass(TextInputFormat.class); job.setMapOutputValueClass(Text.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(FloatWritable.class); // Passa o arquivo de entrada e o diretório de saída FileInputFormat.addInputPath(job, new Path(args[0])); FileOutputFormat.setOutputPath(job, new Path(args[1])); // Executa a tarefa de forma síncrona return job.waitForCompletion(true) ? 0 : 1; } public static void main(String[] args) throws Exception { Configuration conf = new Configuration(); System.exit(ToolRunner.run(conf, new ExemploDriver(), args)); } } Classe DRIVER
run(String[] args) throws Exception { Job job = new Job(getConf(), "Exemplo de MapReduce"); job.setJarByClass(ExemploDriver.class); job.setMapperClass(ExemploMapper.class); job.setReducerClass(ExemploReducer.class); job.setInputFormatClass(TextInputFormat.class); job.setMapOutputValueClass(Text.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(FloatWritable.class); // Passa o arquivo de entrada e o diretório de saída FileInputFormat.addInputPath(job, new Path(args[0])); FileOutputFormat.setOutputPath(job, new Path(args[1])); // Executa a tarefa de forma síncrona return job.waitForCompletion(true) ? 0 : 1; } public static void main(String[] args) throws Exception { Configuration conf = new Configuration(); System.exit(ToolRunner.run(conf, new ExemploDriver(), args)); } } Classe DRIVER
1. Os 4 argumentos da classe MAPER são respectivamente: tipo da chave de entrada, tipo do valor de entrada, tipo da chave de saída e tipo do valor de saída. 2. A classe MAPPER chama o método MAP. 3. Os dois primeiros argumentos do método MAP são a chave e valor correspondentes aos tipos definidos na definição da classe MAPPER. 4. Todas as opções acima. Exercícios
1. Os 4 argumentos da classe REDUCER são respectivamente: tipo da chave de entrada, tipo do valor de entrada, tipo da chave de saída e tipo do valor de saída. 2. Se o valor de saída do MAPPER for Text, o valor de entrada do REDUCER deve ser LongWritable. 3. Se a chave de saida do MAPPER for Text, o valor da chave de entrada da classe REDUCER tambpém deve ser Text. 4. Todas as opções acima. 5. 1 e 3 apenas. Exercícios
1. A classe DRIVER inicialmente verifica a quantidade de argumentos fornecidos. 2. Ela define valores para a tarefa incluindo as classes para o DRIVER, MAPPER e REDUCER utilizados. 3. Na classe DRIVER, pode-se especificar como a tarefa deve ser executada, síncronamente ou assíncronamente. 4. Todas as opções anteriores. Exercícios
entrada do Mapper forem do tipo Text, qual das classes abaixo pode ser utilizada para separar os campos? 1. StringTokenizer. 2. Record Reader. 3. Job Tracker. 4. Task Tracker. Exercícios
1. Chave de saída, valor de saída, configuração e contexto. 2. Chave de entrada, valor de entrada, contexto e configuração. 3. Chave de entrada, valor de entrada, chave de saída e valor de saída. 4. Chave de entrada, chave de saída, valor de entrada e valor de saída. Exercícios
Driver: 1. Também define valores para as classes driver, mapper e reducer utilizados. 2. Deve também definir os valores para o arquivo de entrada. 3. Verifica a sintaxe da linha de comando. 4. Deve também utilizar a interface ToolRunner. Exercícios
1. Ela organiza a saída dos mappers para os reducers. 2. Lê os dados no HDFS. 3. Instancia um objeto Job e suas configurações. 4. Processa a saída. Exercícios
o tipo da chave de saída são ambos Text. O tipo do valor de saída é? 1. LongWritable. 2. FloatWritable. 3. Text. 4. IntWritable. public class WordCountMapper extends Mapper <LongWritable, Text, Text, IntWritable> { … } Exercícios
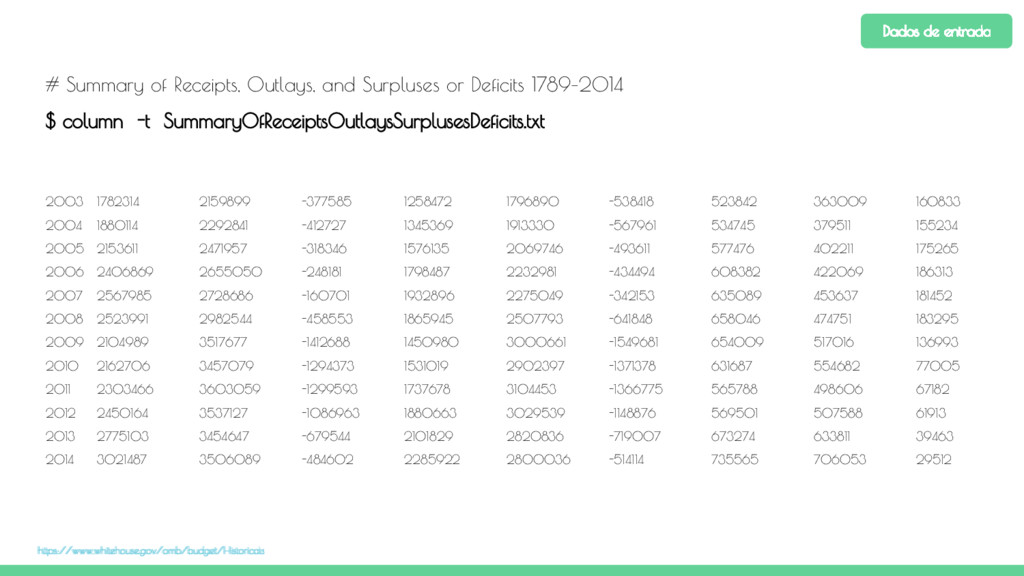
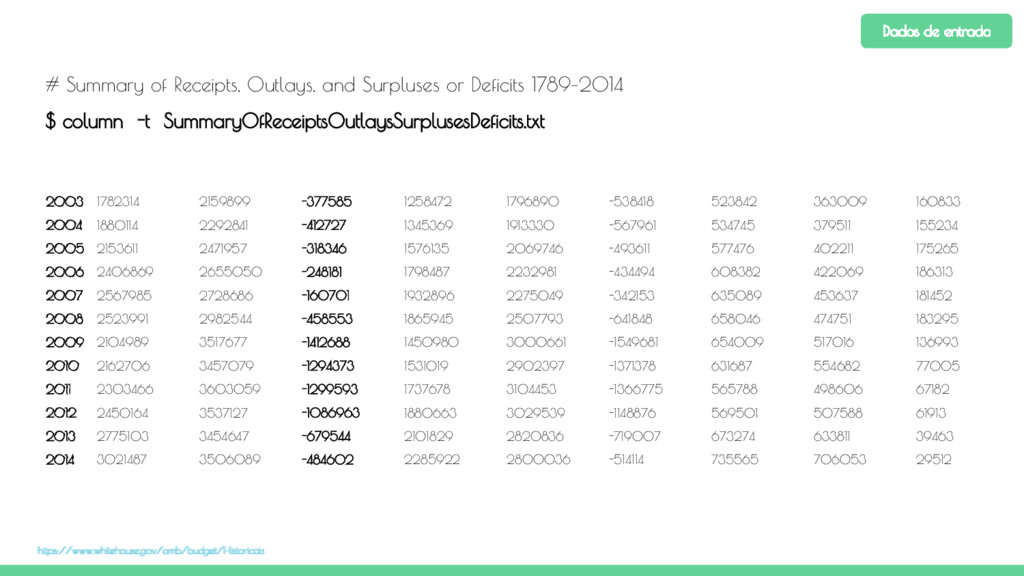
dados Summary of Receipts, Outlays, and Surpluses or Deficits: 1789–2014 para que seja obtido também o maior superávit. 2. Implemente uma aplicação MapReduce que conta o número de palavras existentes no livro Journey to the Center of the Earth. 3. Utilizando o dataset American player by year from 1871-2011, calcule a quantidade total de prêmios ganhos por cada jogador. Para isso utilize o arquivo AwardsPlayers.csv em lahman591-csv. Exercícios
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![public static void main(String[] args) throws Exception { Configuration conf](https://files.speakerdeck.com/presentations/d3bbb779787d409faacac1f9d6166311/slide_53.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
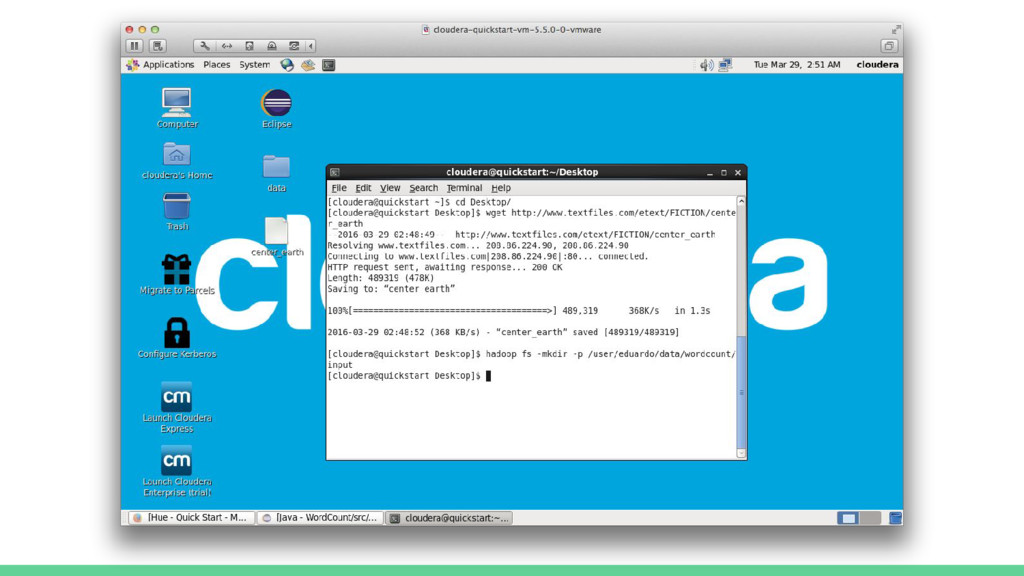
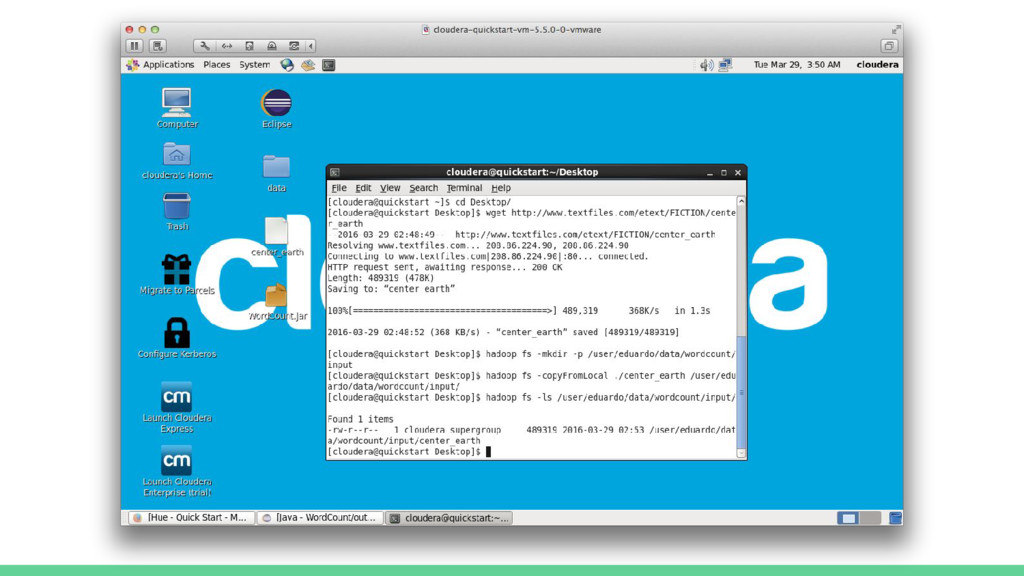
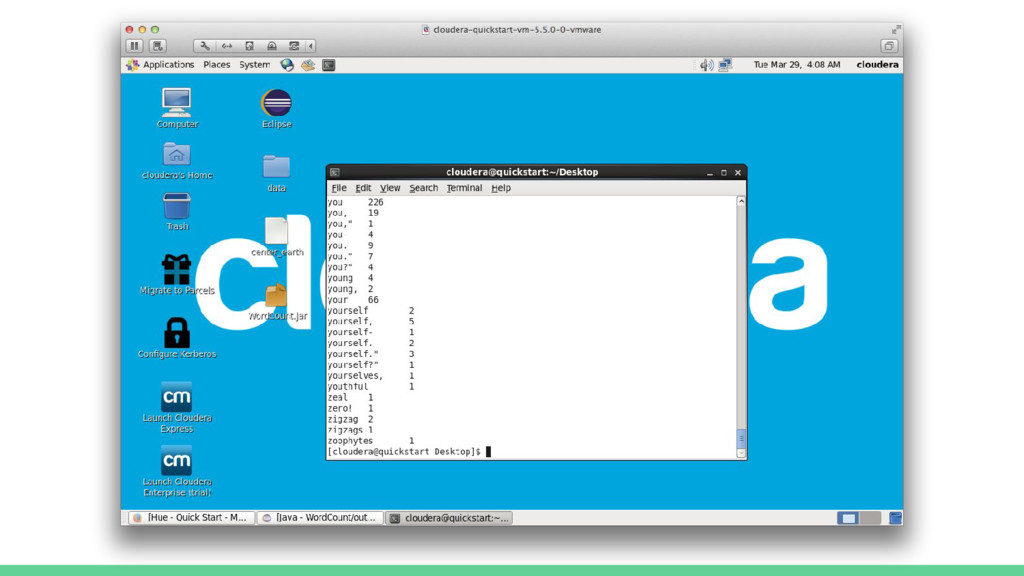
![[cloudera@quickstart ~]$ cd Desktop/ [cloudera@quickstart Desktop]$ wget http://www.textfiles.com/etext/FICTION/center_earth --2016-03-29 02:48:49--](https://files.speakerdeck.com/presentations/d3bbb779787d409faacac1f9d6166311/slide_80.jpg){kind=link}
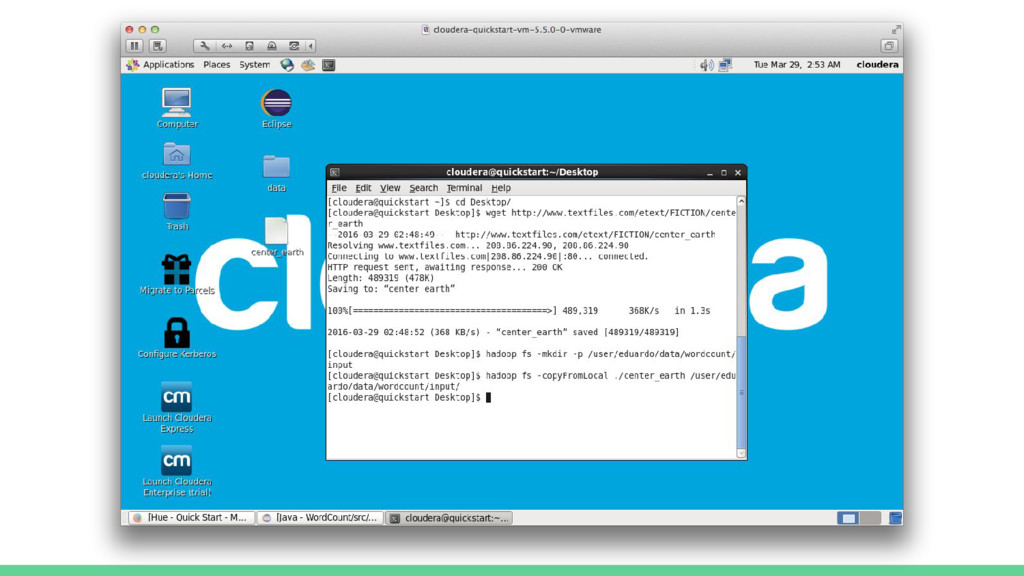
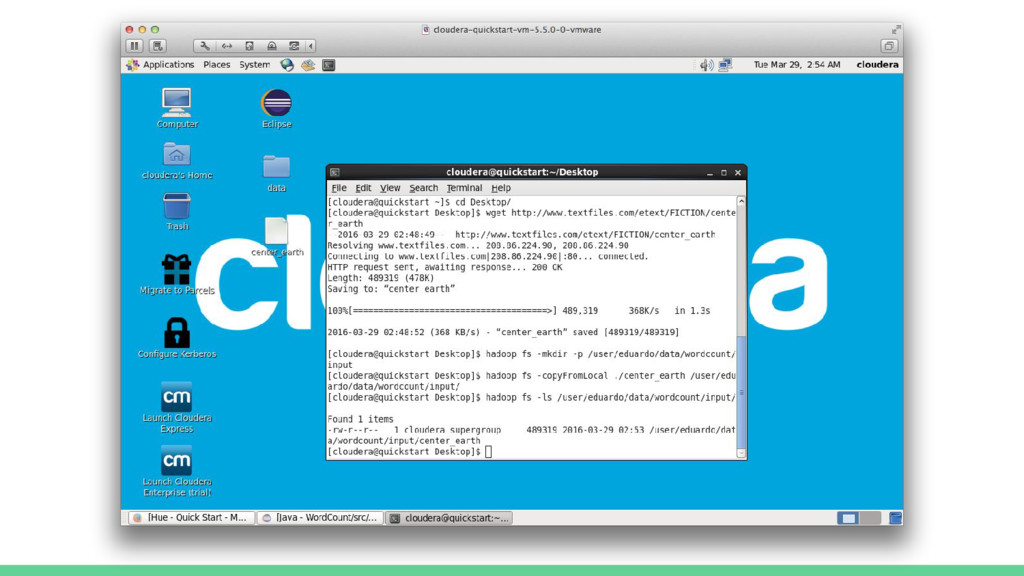
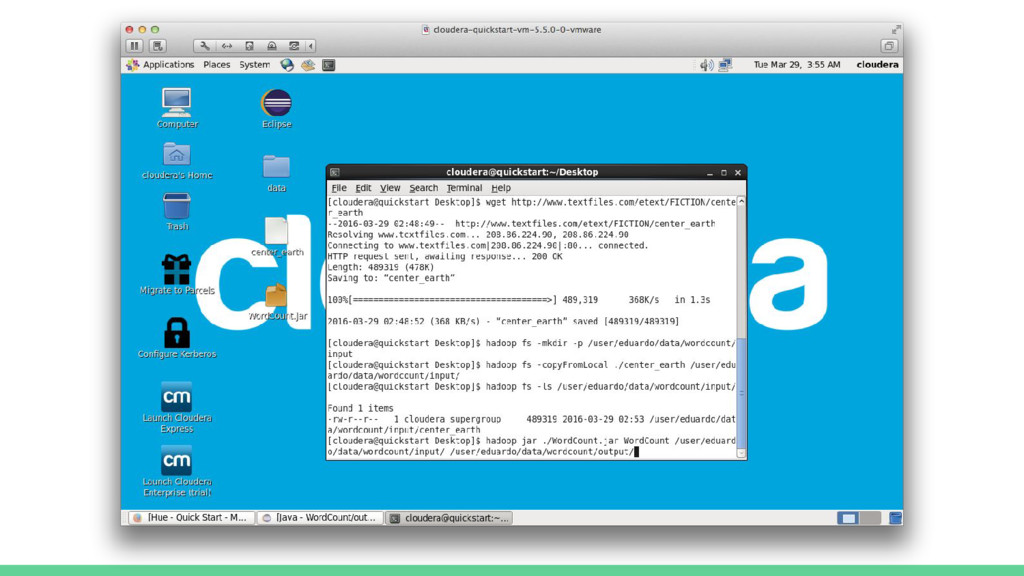
![[cloudera@quickstart Desktop]$ hadoop fs -mkdir -p /user/eduardo/data/wordcount/input [cloudera@quickstart Desktop]$ hadoop](https://files.speakerdeck.com/presentations/d3bbb779787d409faacac1f9d6166311/slide_81.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![[cloudera@quickstart Desktop]$ hadoop jar ./WordCount.jar WordCount /user/eduardo/data/wordcount/input/ /user/eduardo/data/wordcount/output/ 16/03/29 03:56:00](https://files.speakerdeck.com/presentations/d3bbb779787d409faacac1f9d6166311/slide_87.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}