domínio e geralmente é o beneficiário dos resultados. Esta pessoa pode consultar e aconselhar a equipe do projeto do contexto do projeto, o valor dos resultados, e como as saídas serão operacionalizados. Normalmente quem cumpre esse papel são analistas de negócios ou especialista no assunto com profundo domínio do projeto. Patrocinador do projeto - Responsável pela concepção do projeto. Proporciona o impulso e os requisitos para o projeto e define o problema principal. Geralmente fornece os recursos e mede o grau de valor a partir dos resultados finais da equipe. Esta pessoa define as prioridades para o projeto e esclarece as saídas desejadas. Gerente do projeto - Garante que as metas e objetivos principais são atendidas no prazo e com a qualidade esperada. Principais funções em projetos de análise de dados
negócio baseado em um profundo entendimento dos dados, dos indicadores-chave de desempenho (KPIs) e das principais métricas e inteligência do negócios a partir da perspectiva dos relatórios. O analista de business intelligence geralmente cria dashboards e relatórios e possuem grande conhecimento sobre as fontes de dados. Database Administrator (DBA): Configuram o ambiente de banco de dados para apoiar as necessidades de análise da equipe. Suas responsabilidades podem incluir o fornecimento de acesso as bases de dados chave ou tabelas e garantir se os níveis de segurança apropriados estão em vigor. Principais funções em projetos de análise de dados
dados - Possui profundas habilidades técnicas para ajudar com consultas SQL na gestão e extração de dados, e fornece suporte para a ingestão de dados. O engenheiro de dados executa as extrações de dados reais e faz a manipulação dos dados de modo a facilitar as análises. O engenheiro de dados trabalha em estreita colaboração com o cientista de dados para deixar os dados na forma correta para as análises. Cientista de dados - Possui experiência na aplicação de técnicas analíticas e modelagem de dados em problemas de negócios. Projeta e executa métodos analíticos com os dados disponíveis para o projeto. Tende a usar dados de forma mais exploratório, com foco na análise do presente e permitindo decisões informadas sobre o futuro. Um cientista de dados deve olhar para o futuro através da aplicação de estatísticas avançadas e modelagens de dados para descobrir padrões e fazer previsões futuras.
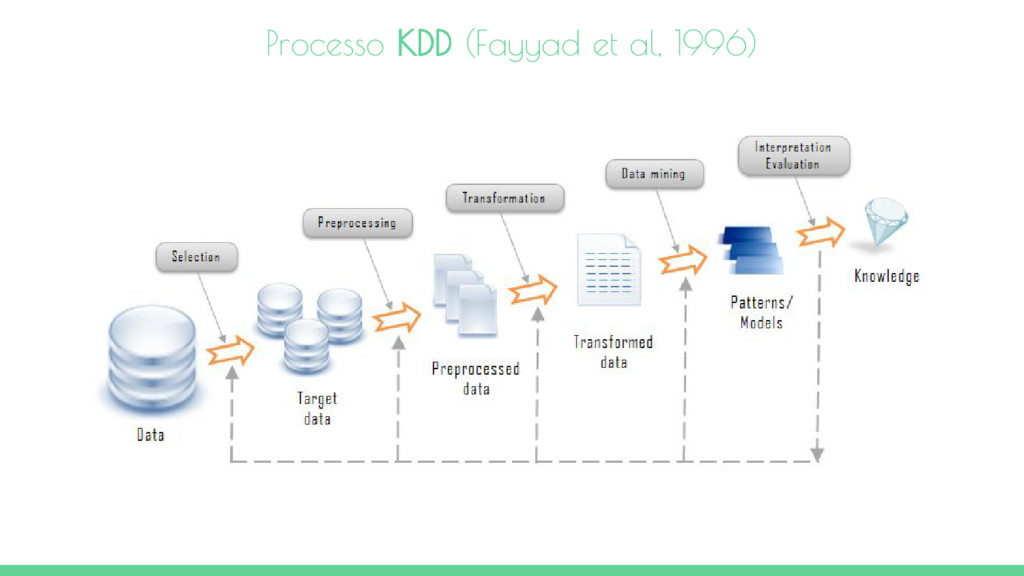
al, 1996) é o processo de utilização de métodos de data mining para extrair o que é considerado conhecimento. Este processo considera 5 fases: Seleção - Esta fase consiste na criação de um conjunto de dados de origem, ou concentra-se em um subconjunto de variáveis ou amostras de dados em que será executado a descoberta. Pré-processamento - Esta fase consiste na limpeza dos dados e pré-processamento, a fim de obter dados consistentes. Transformação - Esta fase consiste na transformação dos dados usando métodos de redução de dimensionalidade ou transformações. Data Mining - Esta fase consiste na busca de padrões de interesse em uma determinada forma de representação, dependendo do objetivo de mineração de dados (normalmente, a previsão). Interpretação / avaliação - Esta fase consiste na interpretação e avaliação dos padrões obtidos. Processo de KDD (Fayyad et al, 1996)
passos com muitas decisões sendo tomadas pelo utilizador. Além disso, o processo KDD deve ser precedido pelo desenvolvimento de uma compreensão do domínio da aplicação, o conhecimento prévio relevante e as metas do usuário final. Também deve ser continuado pela consolidação do conhecimento, incorporando esse conhecimento para o sistema (Fayyad et al, 1996). Processo de KDD (Fayyad et al, 1996)
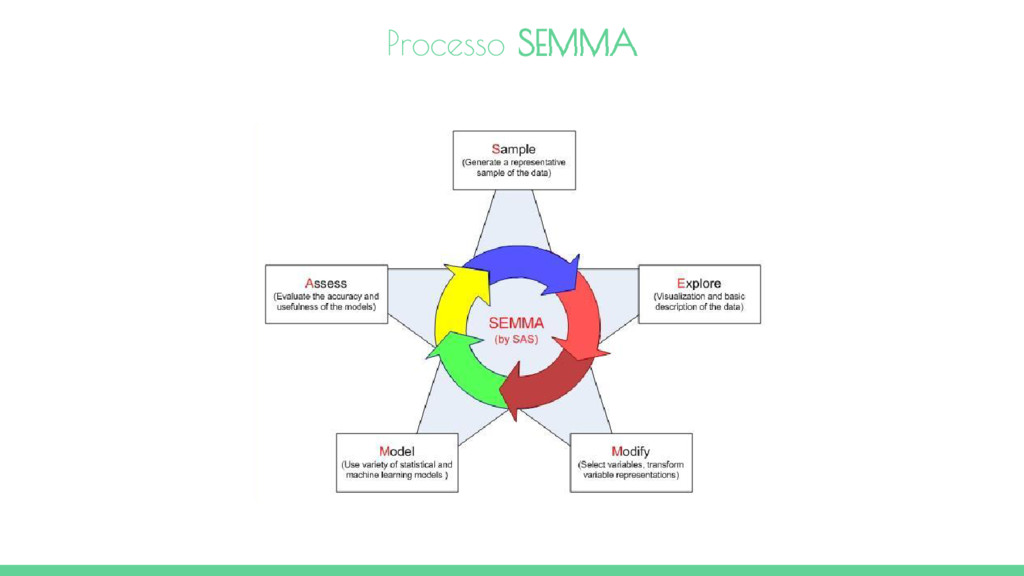
um ciclo com 5 etapas para o processo: Amostra - Esta fase consiste na amostragem dos dados, extração de uma parte de um grande conjunto de dados, grande o suficiente para conter informações significativas e pequeno o suficiente para manipular rapidamente. Este estágio é apontado como sendo opcional. Exploração - Esta fase consiste na exploração dos dados através da procura de tendências imprevistas e anomalias, a fim de ganhar a compreensão e ideias. Modificação - Esta fase consiste na modificação dos dados por meio da criação, seleção e transformação das variáveis com foco no processo de seleção do modelo. Modelo - Esta fase consiste na modelagem dos dados, permitindo que o software pesquise automaticamente por uma combinação de dados que consiga predizer com confiabilidade um resultado desejado. Avaliação - Esta etapa consiste em avaliar os dados, a utilidade e confiabilidade dos resultados do processo Processo SEMMA
mining escolhida, ele está ligada ao software SAS Enterprise Miner que busca orientar o usuário sobre as implementações de aplicações de data mining. Processo SEMMA
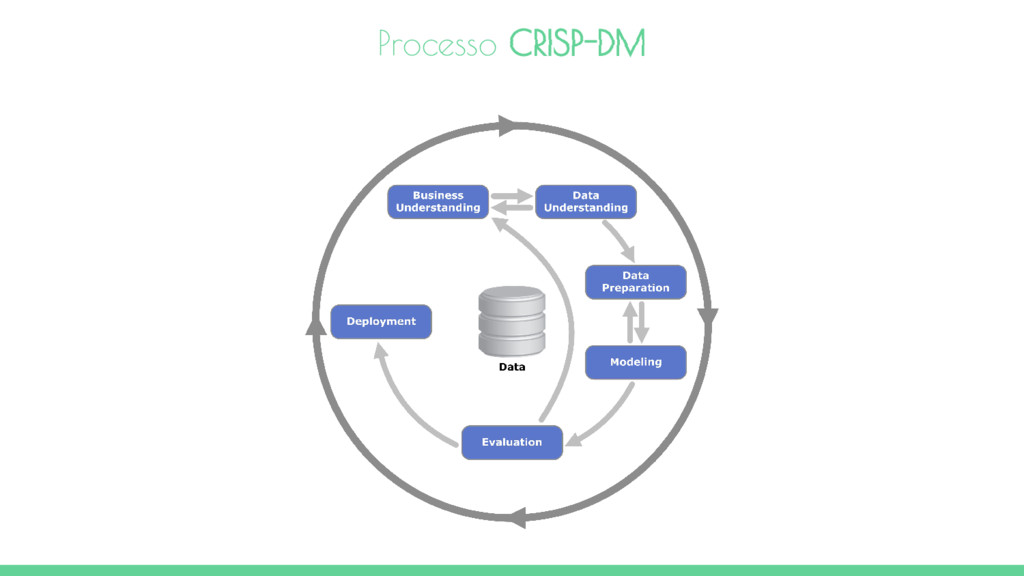
de um consórcio composto inicialmente por DaimlerChryrler, SPSS e NCR. CRISP-DM significa CRoss-Industry Standard Process for Data Mining. Ele consiste em um ciclo que compreende seis fases: Conhecimento do negócio - Esta fase inicial se concentra em entender os objetivos do projeto e requisitos a partir de uma perspectiva de negócios. Em seguida, converter esse conhecimento na definição do problema de mineração de dados e um plano preliminar projetado para atingir os objetivos. Compreensão dos dados - A fase de entendimento dos dados começa com uma coleta de dados inicial e prossegue com atividades, a fim de se familiarizar com os dados, para identificar problemas de qualidade de dados, para descobrir os primeiros insights sobre os dados ou para detectar subconjuntos interessantes para formar hipóteses para encontrar as informações escondidas. Preparação dos dados - A fase de preparação de dados abrange todas as atividades de construção da base de dados final a partir dos dados brutos iniciais. Processo CRISP-DM
e aplicados e os parâmetros são calibrados para os valores ótimos. Avaliação - Nesta fase, o modelo (ou modelos) obtidos são mais bem avaliados e os passos executados para construir o modelo são revistos para ter certeza que alcançaram adequadamente os objetivos do negócio. Implementação - Criação do modelo não é geralmente o fim do projeto. Mesmo sendo o objetivo do modelo aumentar o conhecimento dos dados, o conhecimento adquirido terá de ser organizado e apresentado de uma forma que o cliente possa usá-lo. Processo CRISP-DM
do negócio Seleção Amostra Compreensão dos dados Pré-processamento Exploração Transformação Modificação Preparação dos dados Data Mining Modelo Modelagem Interpretação / avaliação Avaliação Avaliação Pós KDD Implementação
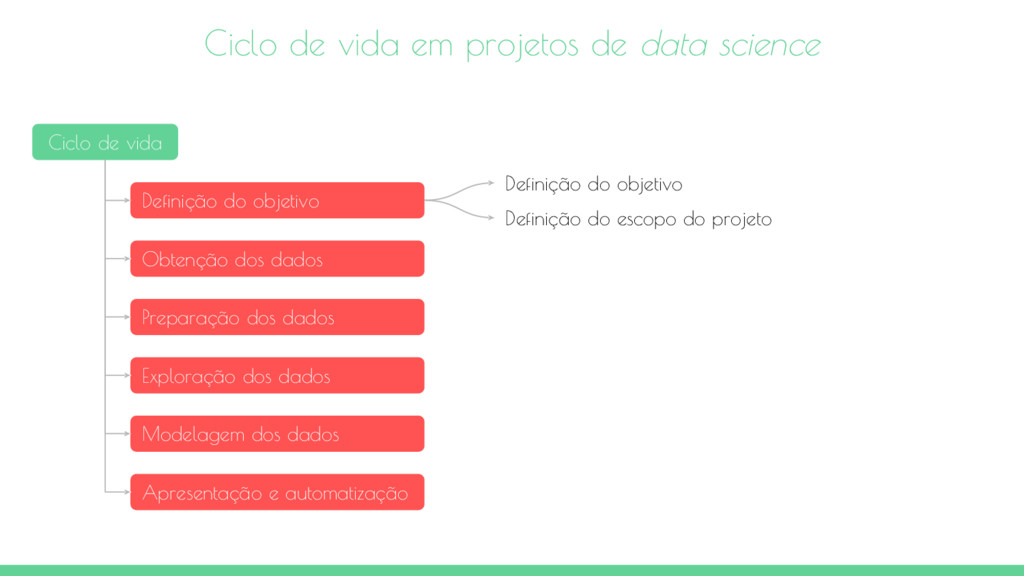
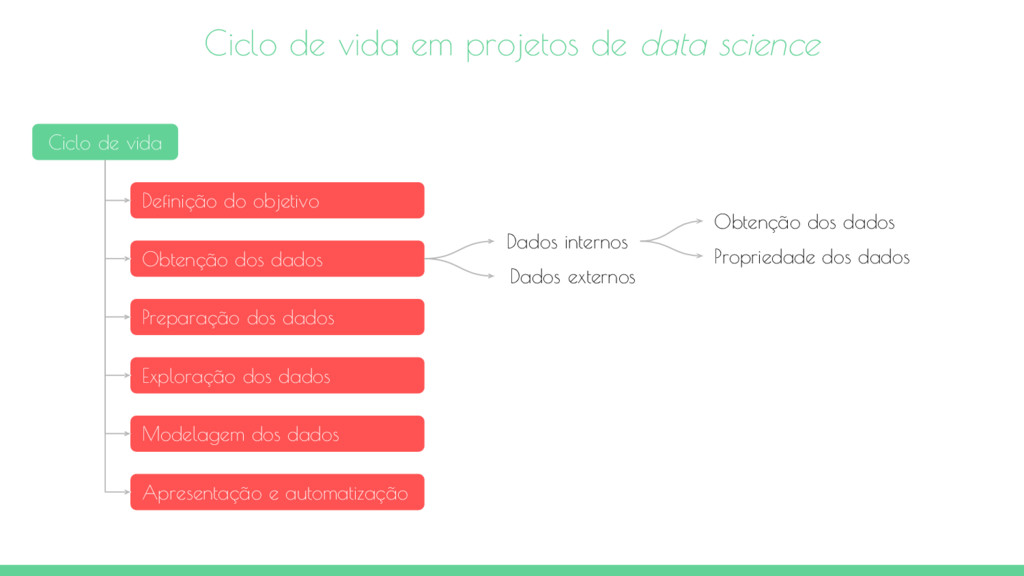
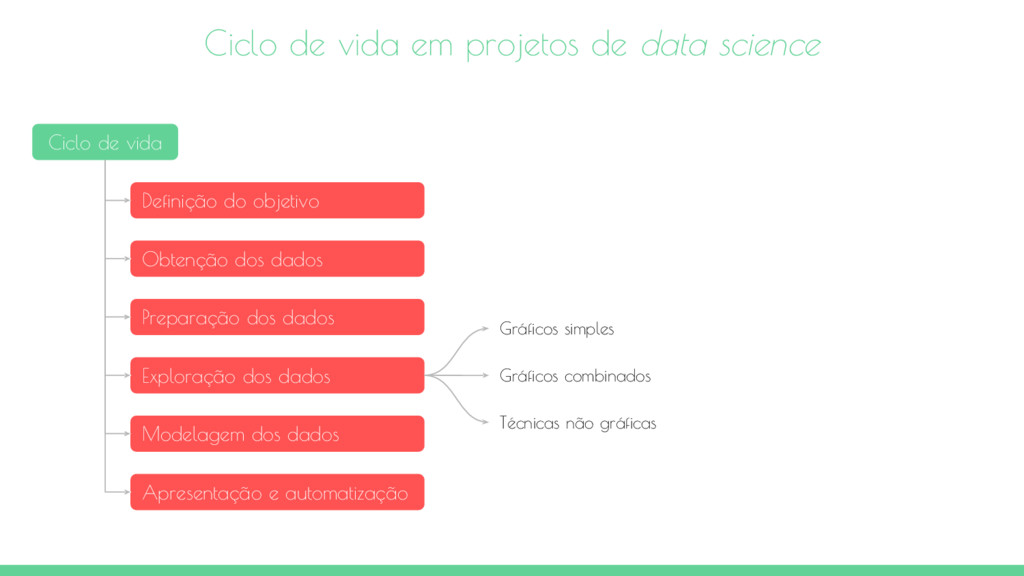
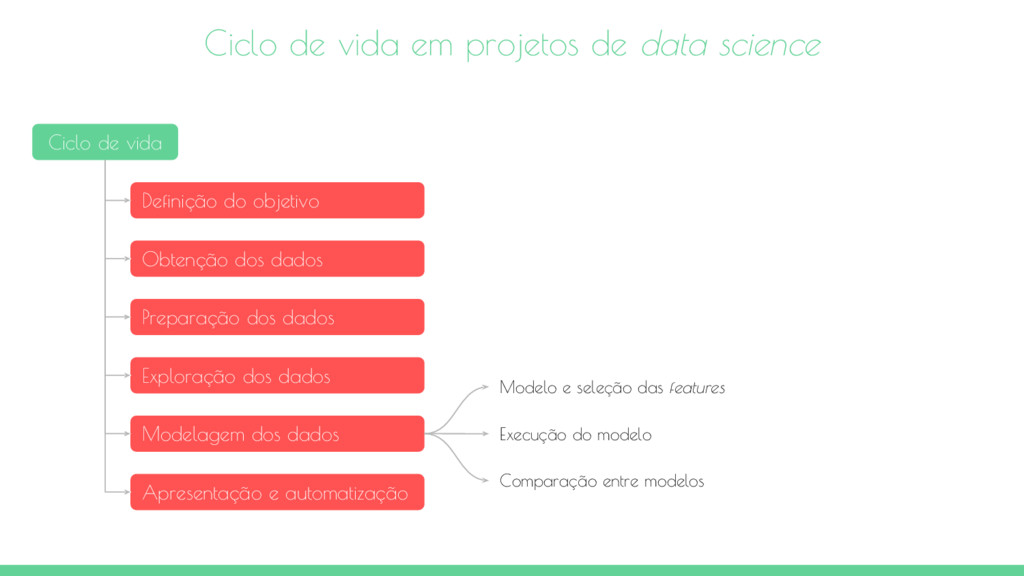
vida Definição do objetivo Obtenção dos dados Preparação dos dados Exploração dos dados Modelagem dos dados Apresentação e automatização Definição do objetivo Definição do escopo do projeto
de como. O que a empresa espera que seja feito? A iniciativa faz parte de um quadro estratégico maior ou é apenas um projeto solitário? A resposta a estas três perguntas (o quê, porquê e como) é o objetivo da primeira fase, de modo que todos os envolvidos possam chegar a um acordo sobre o melhor curso de ação. O resultado desta etapa deve ser um objetivo claro de pesquisa, uma boa compreensão do contexto, as entregas bem definidas e um plano de ação. Nesta fase inicial do projeto, habilidades de pessoas e visão de negócios são mais importantes que a destreza técnica. Definição do objetivo
estão pagando. Assim, depois de você ter uma boa compreensão do problema de negócio, e preciso definir formalmente as entregas. A proposta do projeto exige trabalho em equipe e ela deve abranger pelo menos o seguinte: • Uma meta clara de pesquisa • Como a análise será executada • Quais recursos serão necessários • A prova de viabilidade do projeto, ou uma prova de conceitos • Entregáveis e uma forma de medir o sucesso • Um cronograma Definição do escopo do projeto
vida Definição do objetivo Obtenção dos dados Preparação dos dados Exploração dos dados Modelagem dos dados Apresentação e automatização Dados internos Dados externos Obtenção dos dados Propriedade dos dados
dos dados que estão prontamente disponível dentro da organização. A maioria das empresas têm um programa para manter os dados organizados. Estes dados podem estar armazenados em repositórios de dados oficiais, tais como bancos de dados, data marts, data warehouses ou data lakes. Encontrar dados até mesmo dentro da própria empresa, por vezes, pode ser um desafio. Conforme as empresas crescem, os seus dados torna-se dispersos em muitos lugares. O conhecimento dos dados pode se dispersar a medida que as pessoas mudam de posição ou deixam as empresas. Documentação e metadados não são sempre a primeira prioridade e por isso pode ser trabalhoso juntar todos os pedaços perdidos. Além disso, acessar os dados é outra tarefa difícil. As organizações compreendem o valor e a sensibilidade dos dados e muitas vezes têm políticas em vigor para que todos tenham acesso ao que eles precisam e nada mais. Obtenção dos dados
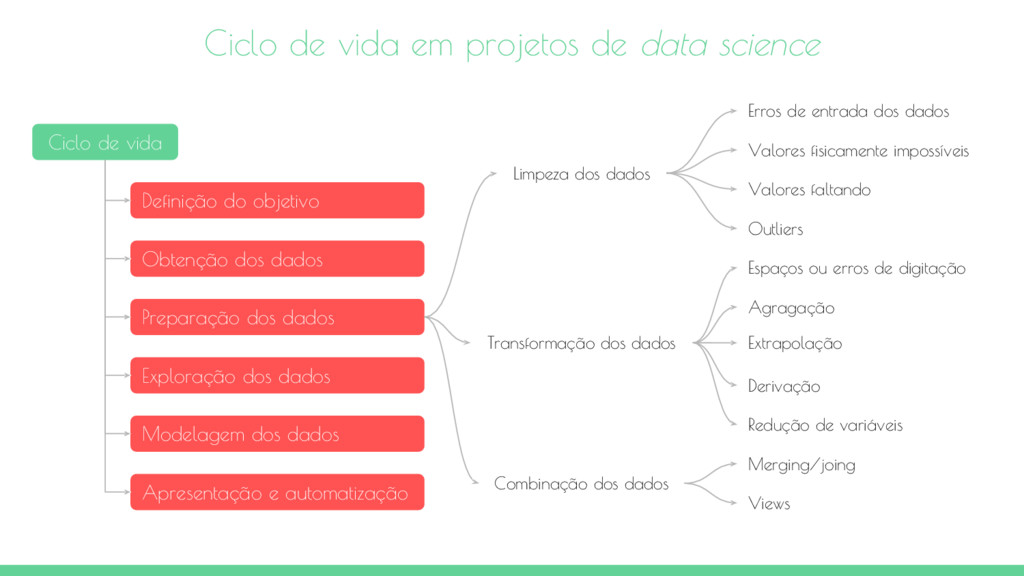
vida Definição do objetivo Obtenção dos dados Preparação dos dados Exploração dos dados Modelagem dos dados Apresentação e automatização Limpeza dos dados Transformação dos dados Erros de entrada dos dados Valores fisicamente impossíveis Combinação dos dados Valores faltando Outliers Espaços ou erros de digitação Agragação Extrapolação Derivação Redução de variáveis Merging/joing Views
remoção de erros em seus dados para que eles se tornem uma representação verdadeira e coerente dos processos que ele origina. Existem pelo menos dois tipos de erros. O primeiro tipo é o erro de interpretação, como dizer que a idade de uma pessoa é maior do que 300 anos. O segundo tipo de erro é a inconsistências entre as fontes de dados ou contra valores padronizados de sua empresa. Um exemplo desta classe de erros está quando utilizamos "Feminino" em uma tabela e "F" em outra, mesmo eles representando a mesma coisa. Outro exemplo é o uso de libras em uma tabela e dólares em outra. Erros de entrada dos dados
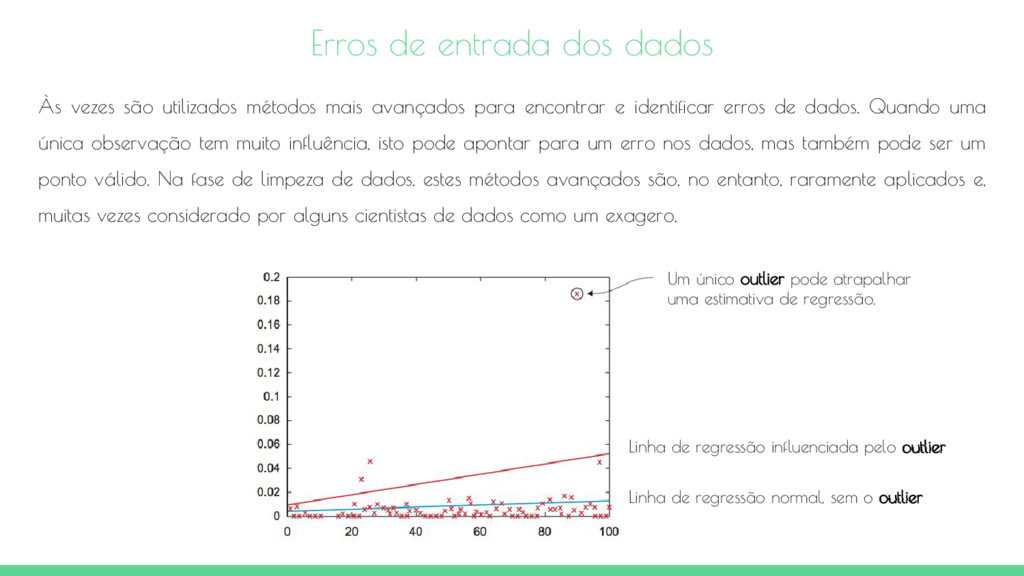
identificar erros de dados. Quando uma única observação tem muito influência, isto pode apontar para um erro nos dados, mas também pode ser um ponto válido. Na fase de limpeza de dados, estes métodos avançados são, no entanto, raramente aplicados e, muitas vezes considerado por alguns cientistas de dados como um exagero. Erros de entrada dos dados Um único outlier pode atrapalhar uma estimativa de regressão. Linha de regressão influenciada pelo outlier Linha de regressão normal, sem o outlier
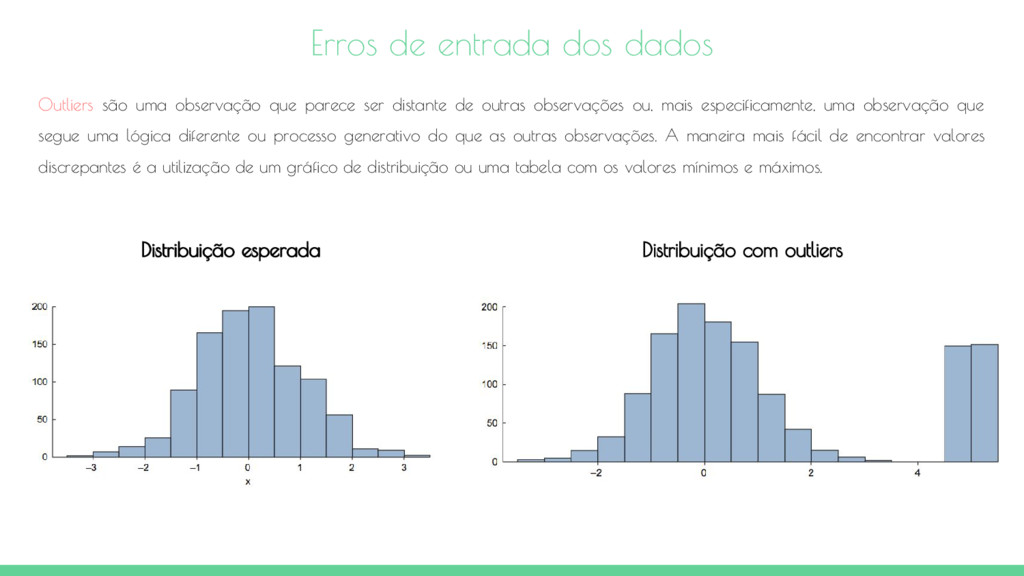
observações ou, mais especificamente, uma observação que segue uma lógica diferente ou processo generativo do que as outras observações. A maneira mais fácil de encontrar valores discrepantes é a utilização de um gráfico de distribuição ou uma tabela com os valores mínimos e máximos. Erros de entrada dos dados Distribuição esperada Distribuição com outliers
e por isso erros acabam sendo introduzidos na coleta dos dados. Mas mesmo dados coletados por máquinas ou computadores não estão livre de erros. Erros podem surgir a partir de negligência humana, enquanto outros são devido a falhas de hardware das máquinas. Exemplos de erros provenientes de máquinas são erros de transmissão ou bugs no processo de ETL. Detecção de erros de dados quando as variáveis não possuem muitas classes pode ser feito por contagens. Quando você tem uma variável que pode assumir apenas dois valores: "Bom" e "Ruim", você pode criar uma tabela de frequência e ver se esses são realmente os únicos dois valores presentes. Outras possíveis causas de erro são espaços em branco como por exemplo: " BR" é diferente de "BR". Outro problema comum é comparar "Brasil" com "brasil". Erros de entrada dos dados Valores Total Bom 654875 Ruim 532564 Bon 3 Ruin 11
mais cedo possível de modo a corrigir o mínimo possível dentro de seu programa. Recuperação de dados é uma tarefa difícil, e as organizações gastam milhões de dólares na esperança de tomar melhores decisões. O processo de coleta de dados é suscetível a erros, ainda mais em grandes organizações que possuem muitas etapas e equipes. Os dados devem ser limpos quando adquiridos por muitas razões: • Nem todo mundo percebe as anomalias nos dados. Os tomadores de decisão podem tomar decisões erradas com base em dados incorrectos a partir de aplicações que não conseguem corrigir os dados defeituosos. • Se os erros não são corrigidos logo no início do processo, a limpeza terá de ser feito para cada projeto que utilizar esses dados. Erros de entrada dos dados
apontar para um processo de negócio que não está funcionando como projetado. • Erros de dados podem apontar para equipamentos defeituosos, tais como linhas de transmissão quebrados e sensores defeituosos. • Erros de dados podem apontar para bugs no software ou na integração de software que pode ser crítico para a empresa.
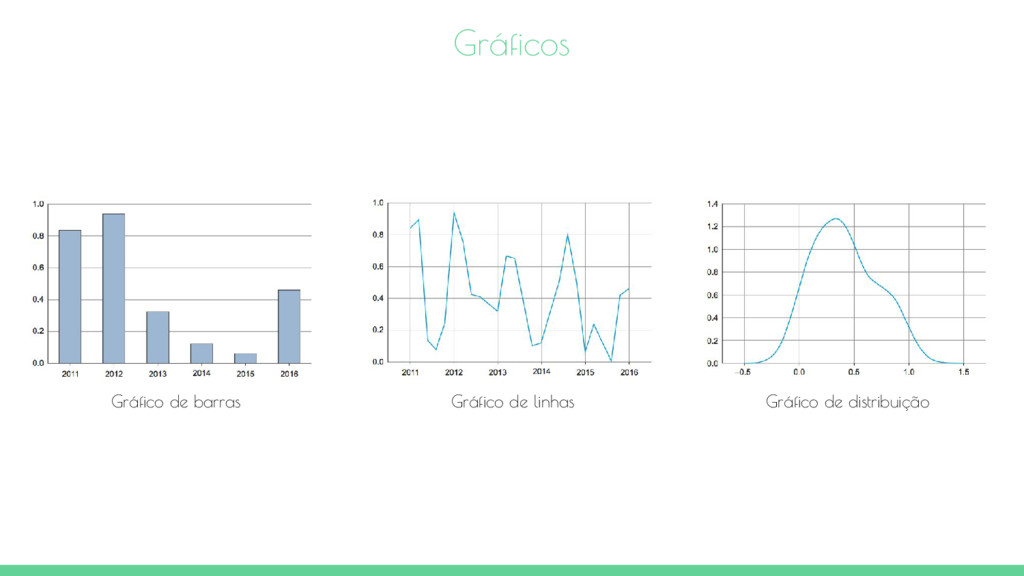
vida Definição do objetivo Obtenção dos dados Preparação dos dados Exploração dos dados Modelagem dos dados Apresentação e automatização Gráficos simples Gráficos combinados Técnicas não gráficas
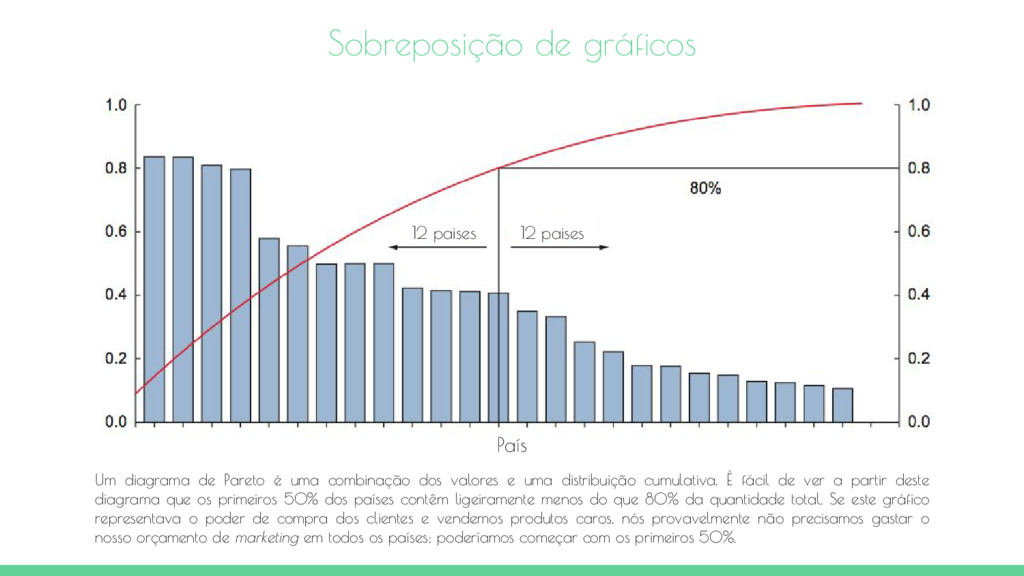
combinação dos valores e uma distribuição cumulativa. É fácil de ver a partir deste diagrama que os primeiros 50% dos países contêm ligeiramente menos do que 80% da quantidade total. Se este gráfico representava o poder de compra dos clientes e vendemos produtos caros, nós provavelmente não precisamos gastar o nosso orçamento de marketing em todos os países; poderíamos começar com os primeiros 50%. 12 paises 12 paises
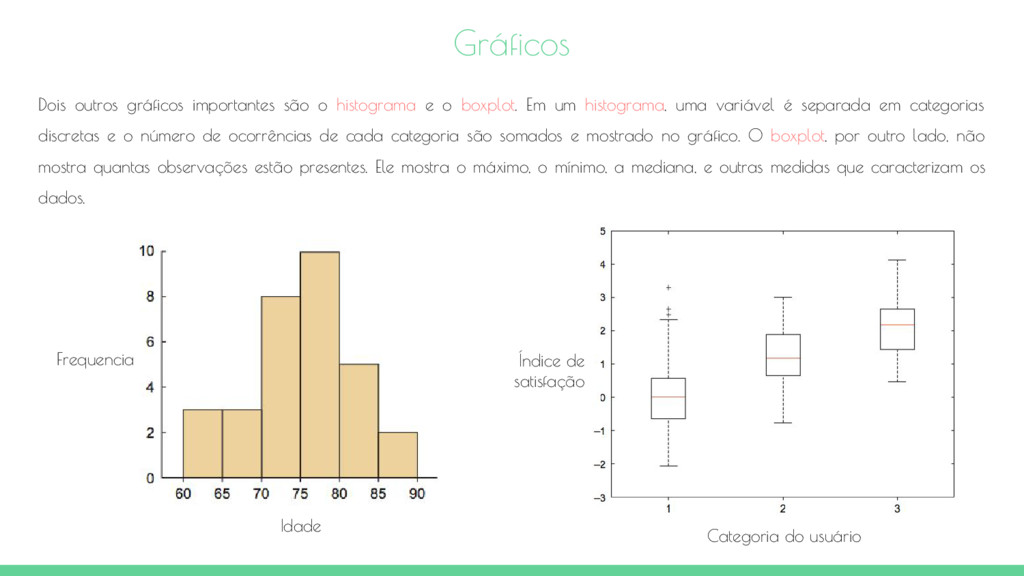
histograma e o boxplot. Em um histograma, uma variável é separada em categorias discretas e o número de ocorrências de cada categoria são somados e mostrado no gráfico. O boxplot, por outro lado, não mostra quantas observações estão presentes. Ele mostra o máximo, o mínimo, a mediana, e outras medidas que caracterizam os dados. Frequencia Idade Índice de satisfação Categoria do usuário
vida Definição do objetivo Obtenção dos dados Preparação dos dados Exploração dos dados Modelagem dos dados Apresentação e automatização Modelo e seleção das features Execução do modelo Comparação entre modelos
incluídas no modelo e na técnica de modelagem. As descobertas a partir da análise exploratória já deve dar uma boa ideia de quais variáveis vão ajudar a construir um bom modelo. Muitas técnicas de modelagem estão disponíveis, e escolher o modelo certo para um problema requer conhecimento. É preciso considerar o desempenho do modelo e se o projeto satisfaz todos os requisitos para utilização do modelo, bem como outros fatores: • O modelo deve ser transferido para um ambiente de produção e, em caso afirmativo, seria fácil de implementar? • Quão difícil é a manutenção do modelo: quanto tempo vai continuar a ser relevante se for deixado intocado? • Será que o modelo precisa ser fácil de explicar?
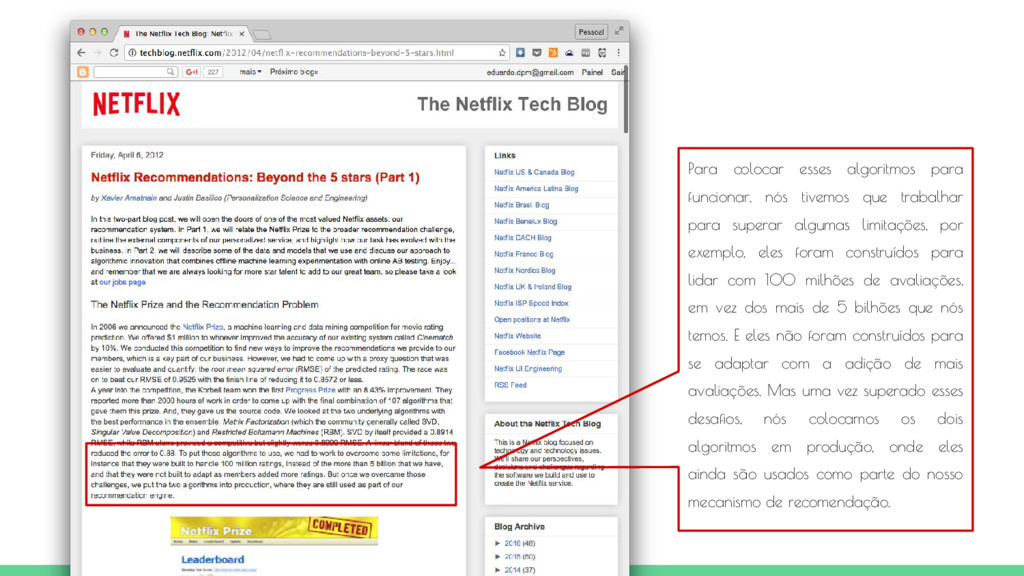
para superar algumas limitações, por exemplo, eles foram construídos para lidar com 100 milhões de avaliações, em vez dos mais de 5 bilhões que nós temos. E eles não foram construídos para se adaptar com a adição de mais avaliações. Mas uma vez superado esses desafios, nós colocamos os dois algoritmos em produção, onde eles ainda são usados como parte do nosso mecanismo de recomendação.
vida Definição do objetivo Obtenção dos dados Preparação dos dados Exploração dos dados Modelagem dos dados Apresentação e automatização Apresentação dos resultados Automarização
imaginar? • Em que fase a equipe espera investir a maior parte do tempo do projeto? Por quê? E onde a equipe espera gastar menos tempo? • Quais são os benefícios de se fazer um projeto piloto antes do início em escala de um grande projeto analítico? • Que tipos de ferramentas seriam usadas nas seguintes fases e para quais tipos de cenários de uso? ◦ Preparação de dados ◦ Construção do modelo • Defina o que é acurácia, precisão, recall e F1. Exercícios
e distribuição de serviços de Big Data: ◦ Infrastructure as a Service (IaaS) ◦ Platform as a Service (PaaS) ◦ Software as a Service (SaaS) ◦ Data as a Service (DaaS) • Defina com suas palavras o que é Cloud computing. • Existem inúmeras combinações de modelos de implantação e entrega em big data. Por exemplo, você pode utilizar uma nuvem pública IaaS ou uma nuvem privado IaaS. Então, o que isso significa para big data e por que a nuvem é uma boa solução? Exercícios
três características de Big Data, e quais são as principais considerações no processamento de Big Data? • O que são dados estruturados e dados não estruturados? • Explique as diferenças entre BI e Ciência de Dados. • Quais são os conjuntos de habilidades fundamentais e características comportamentais de um cientista de dados? • O que é computação em nuvem? Exercícios
que ela gostaria de conquistar nos próximos 9 a 12 meses. Pode ser melhorar a retenção de clientes, aumentar a carteira de clientes, melhorar a manutenção preventiva, etc. • Quais perguntas (descritivas, preditivas e prescritivas) você gostaria de responder com relação as iniciativas de negócio levantadas na questão anterior. • Quais seriam as fontes de dados necessárias que poderiam ajudar a responder tais perguntas. Podem ser dados internos da sua empresa ou qualquer outro dataset do mundo que você poderia ter acesso. Exercícios
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}