Cafarella, Alon Y. Halevy, Daisy Zhe Wang, Eugene Wu, and Yang Zhang. Webtables: exploring the power of tables on the web. PVLDB, 1(1):538–549, 2008. Eric Crestan and Patrick Pantel. A fine-grained taxonomy of tables on the web. In Jimmy Huang, Nick Koudas, Gareth J. F. Jones, Xindong Wu, Kevyn Collins-Thompson, and Aijun An, editors, CIKM, pages 1405–1408. ACM, 2010. Eric Crestan and Patrick Pantel. Web-scale knowledge extraction from semi-structured tables. In Proceedings of the 19th international conference on World wide web, WWW ’10, pages 1081–1082, New York, NY, USA, 2010. ACM. Eric Crestan and Patrick Pantel. Web-scale table census and classification. In Irwin King, Wolfgang Nejdl, and Hang Li, editors, WSDM, pages 545–554. ACM, 2011. Varish Mulwad, Tim Finin, and Anupam Joshi. Automatically Generating Government Linked Data from Tables. In Working notes of AAAI Fall Symposium on Open Government Knowledge: AI Opportunities and Challenges. November 2011. Varish Mulwad, Tim Finin, Zareen Syed, and Anupam Joshi. Using linked data to interpret tables. In Proceedings of the the First International Workshop on Consuming Linked Data, November 2010. Introduction WTT-Detection WTT-Interpretation On-going work Future work 37/39
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Introduction III Table understanding in Web documents include [WH02]: Table](https://files.speakerdeck.com/presentations/e2e58f7188b6466dbb20d4189467ac55/slide_4.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
![Table detection: [WH02] I A Machine Learning Based Approach for](https://files.speakerdeck.com/presentations/e2e58f7188b6466dbb20d4189467ac55/slide_8.jpg){kind=link}
![Table detection: [WH02] II A Machine Learning Based Approach for](https://files.speakerdeck.com/presentations/e2e58f7188b6466dbb20d4189467ac55/slide_9.jpg){kind=link}
![Table detection: [CP10b] I Web-Scale Knowledge Extraction from Semi-Structured Tables](https://files.speakerdeck.com/presentations/e2e58f7188b6466dbb20d4189467ac55/slide_10.jpg){kind=link}
![Table detection: [CP10b] II Web-Scale Knowledge Extraction from Semi-Structured Tables](https://files.speakerdeck.com/presentations/e2e58f7188b6466dbb20d4189467ac55/slide_11.jpg){kind=link}
![Table detection: [CP10b] III Web-Scale Knowledge Extraction from Semi-Structured Tables](https://files.speakerdeck.com/presentations/e2e58f7188b6466dbb20d4189467ac55/slide_12.jpg){kind=link}
![Table detection: [CP10b] IV Web-Scale Knowledge Extraction from Semi-Structured Tables](https://files.speakerdeck.com/presentations/e2e58f7188b6466dbb20d4189467ac55/slide_13.jpg){kind=link}
![Table detection: [CP10a, CP11] I Web-scale Table Census and Classification](https://files.speakerdeck.com/presentations/e2e58f7188b6466dbb20d4189467ac55/slide_14.jpg){kind=link}
![Table detection: [CP10a, CP11] II Table classes [CP10a, CP11] propose](https://files.speakerdeck.com/presentations/e2e58f7188b6466dbb20d4189467ac55/slide_15.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
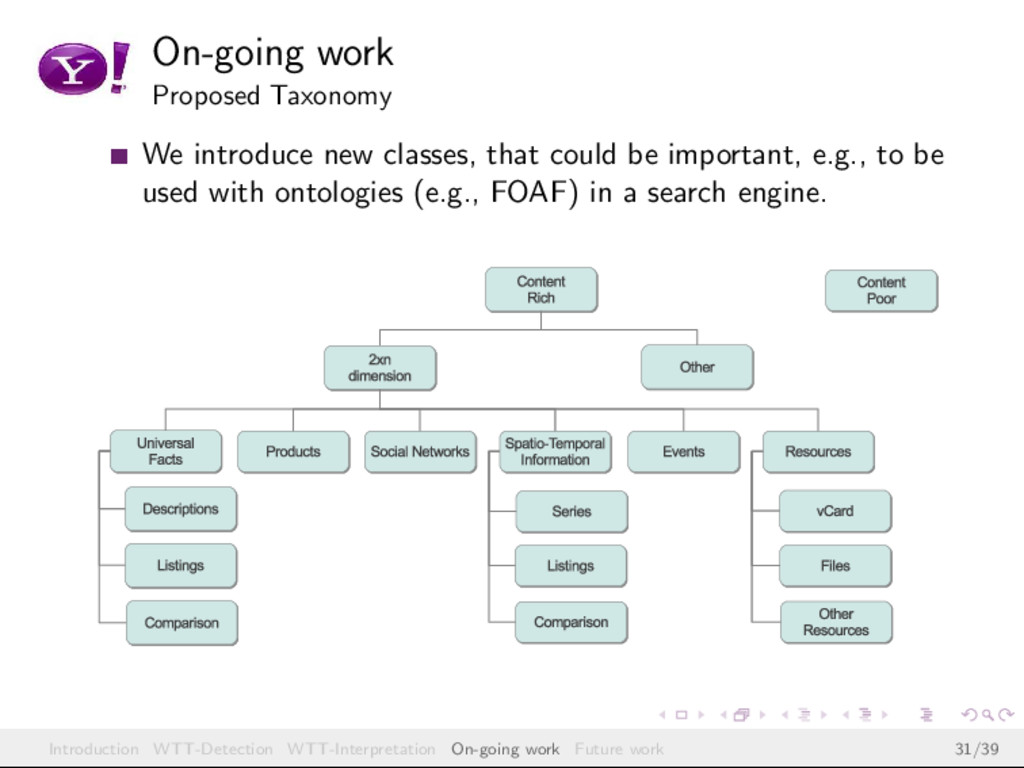{kind=link}
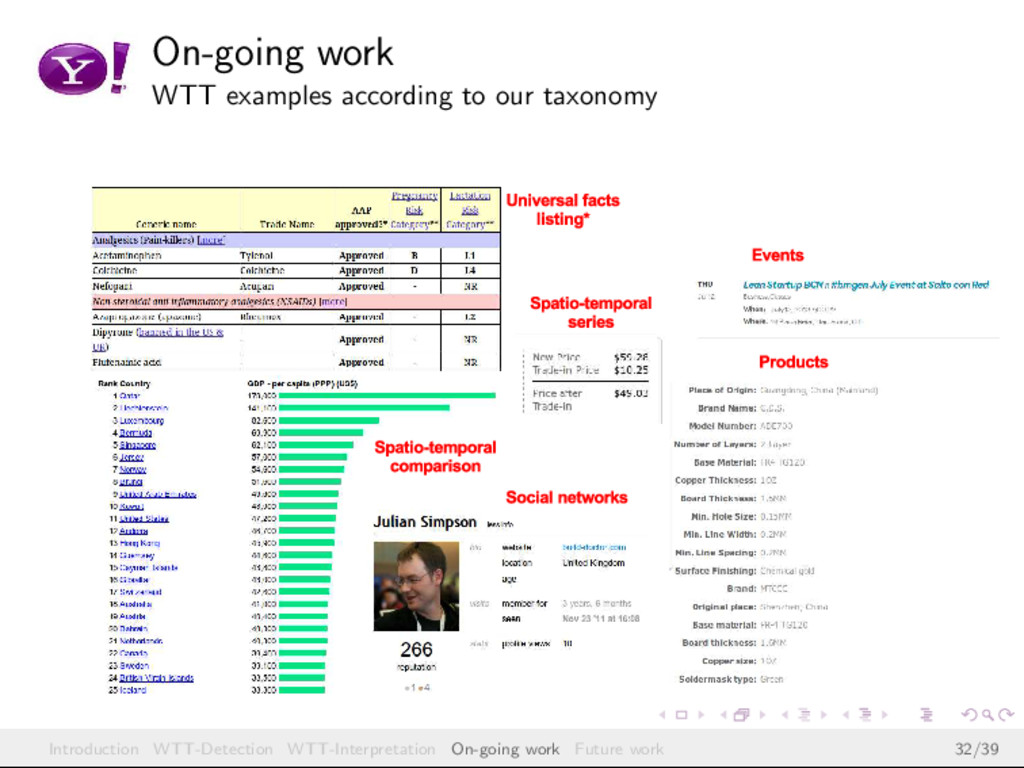{kind=link}
{kind=link}
{kind=link}
{kind=link}
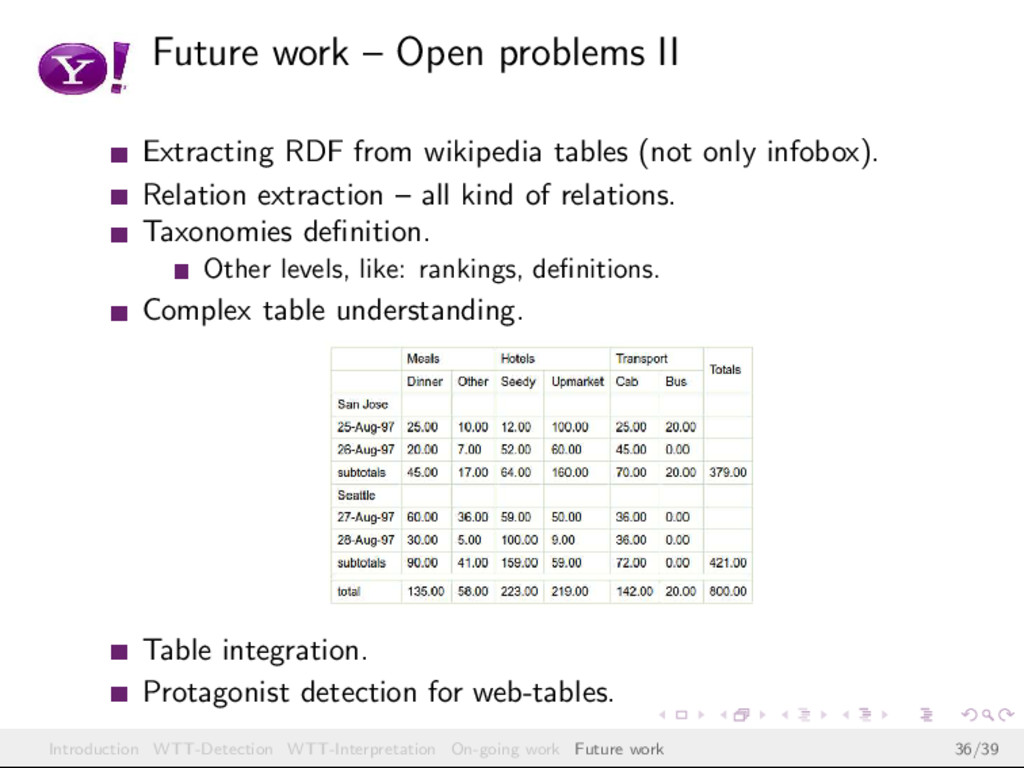{kind=link}
{kind=link}
{kind=link}
{kind=link}