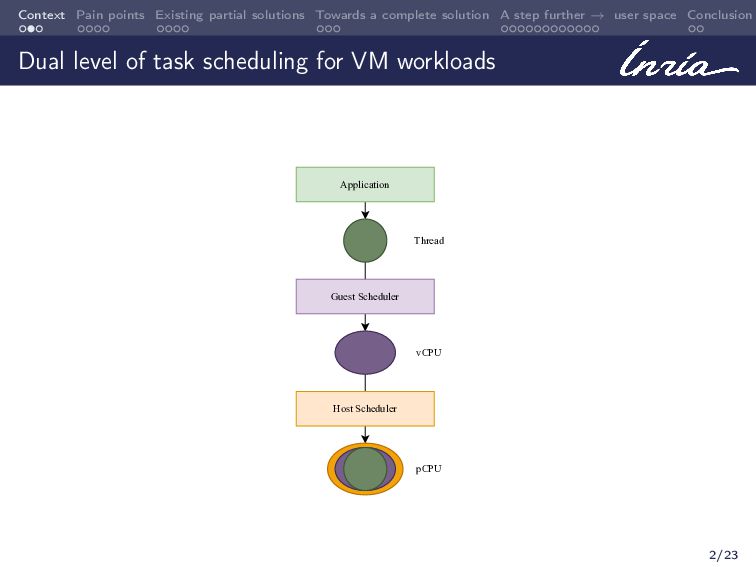
When a multi-threaded application runs inside a virtual machine, it experiences a dual level of task scheduling. The guest OS’ task scheduler decides how to place application threads on the vCPUs, and the host OS’ task scheduler decides how to place these vCPU threads on the pCPUs. While the guest is aware of the application threads’ activities inside the VM, it is often oblivious about the status of its vCPUs on the host. On the other hand, the host is aware of the status of the vCPUs, but it is oblivious about the application threads’ activities inside the VM. Thus, neither the guest nor the host have the complete information to make optimal task placement decisions across both the levels. This leads to the well-known semantic gap between the host and the guest task schedulers. Many existing academic as well as in-kernel solutions partially help by targeting specific issues spanning from the semantic gap. And more recently, we might be getting closer to achieving a generic and complete solution with the efforts of standardizing the paravirt scheduling interface[1].
In this talk, we will take a deep dive into the issues spanning from the semantic gap. We will review the paravirt scheduling proposal as well as some of the noteworthy partial solutions. And finally, we will learn about the semantic gap related research at Whisper that builds upon the idea of paravirt scheduling and proposes a new use-case for it.
[1] [RFC PATCH v2 0/5] Paravirt Scheduling (Dynamic vcpu priority
management) – https://lore.kernel.org/kvm/[email protected]/T/
Himadri CHHAYA-SHAILESH
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}