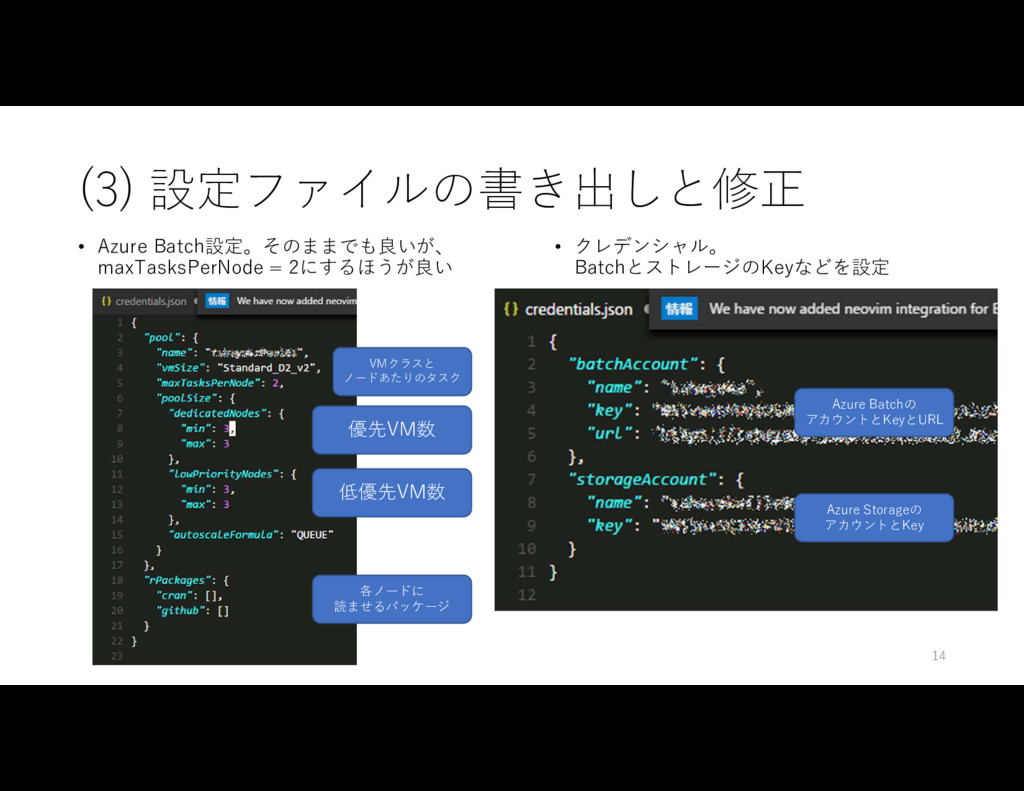
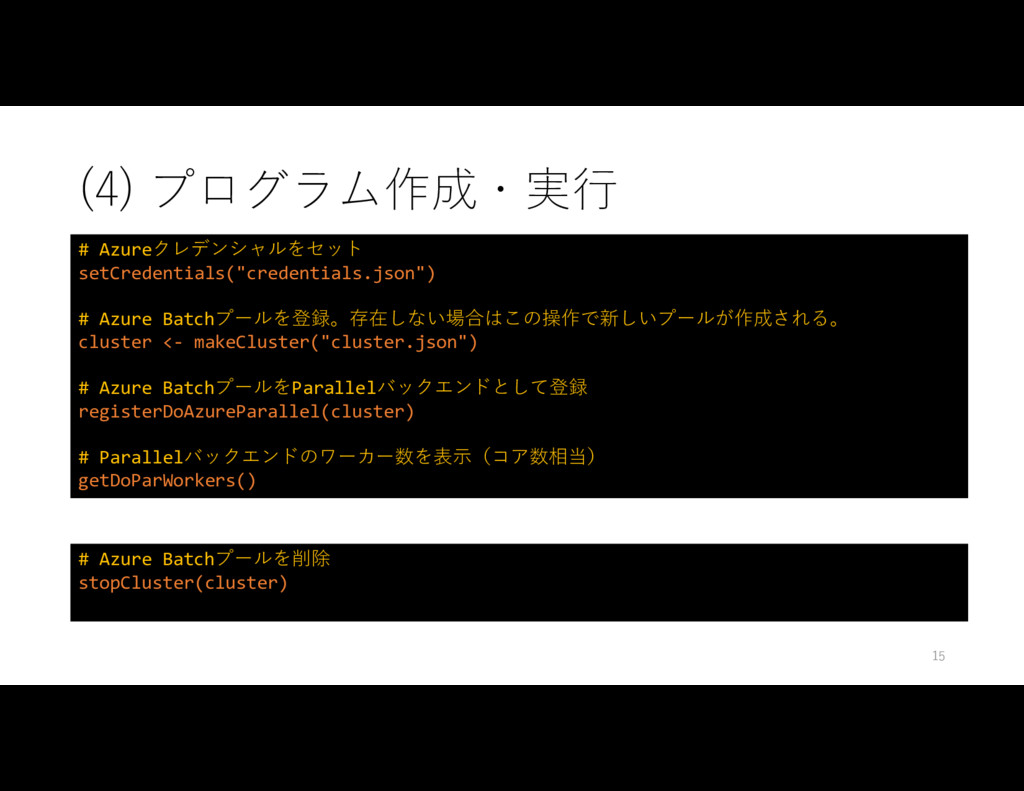
• クレデンシャル設定 ( credential.json ) > generateClusterConfig("cluster.json") [1] "A cluster settings has been generated c:/Users/User/desktop/cluster.json. Please enter your cluster specification." [1] "Note: To maximize all CPU cores, set the maxTasksPerNode property up to 4x the number of cores for the VM size." > generateCredentialsConfig("credentials.json") [1] "A config file has been generated c:/Users/User/desktop/credentials.json. Please enter your Batch credentials." 13
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
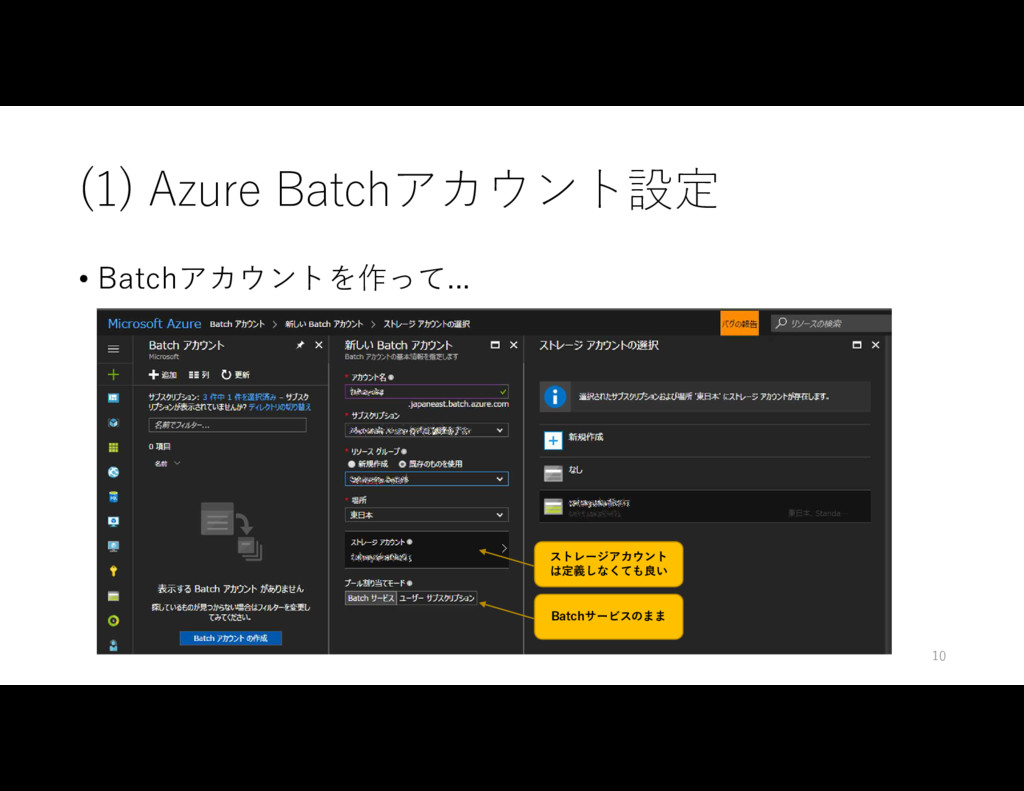{kind=link}
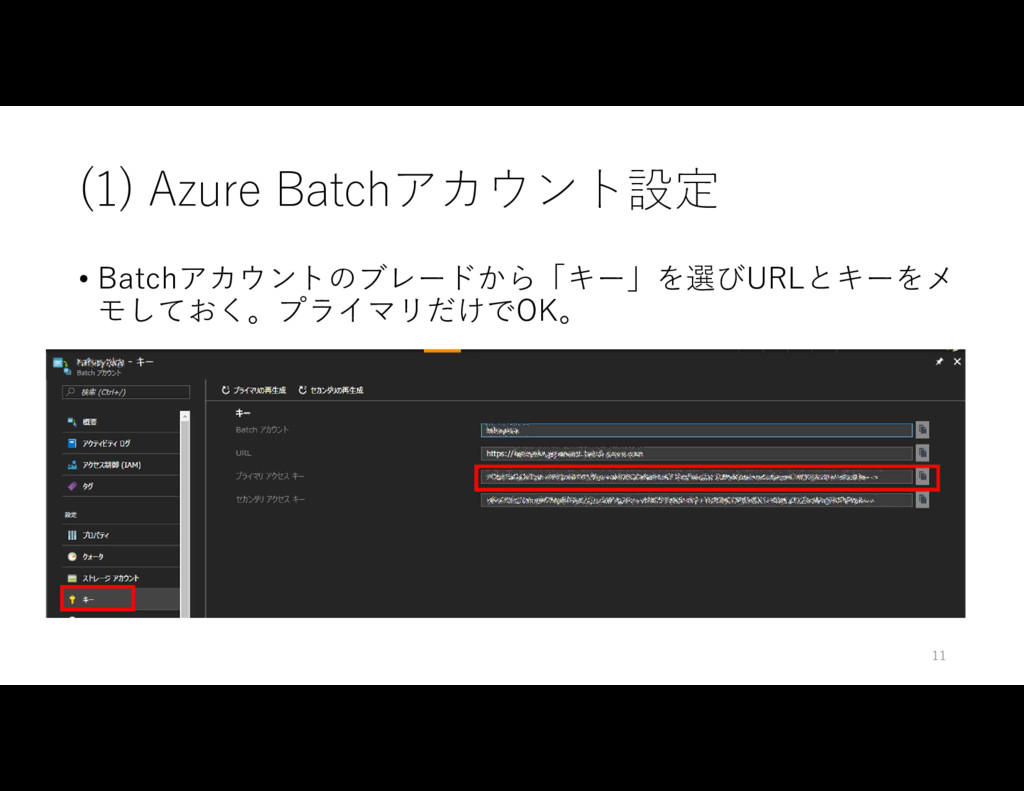{kind=link}
{kind=link}
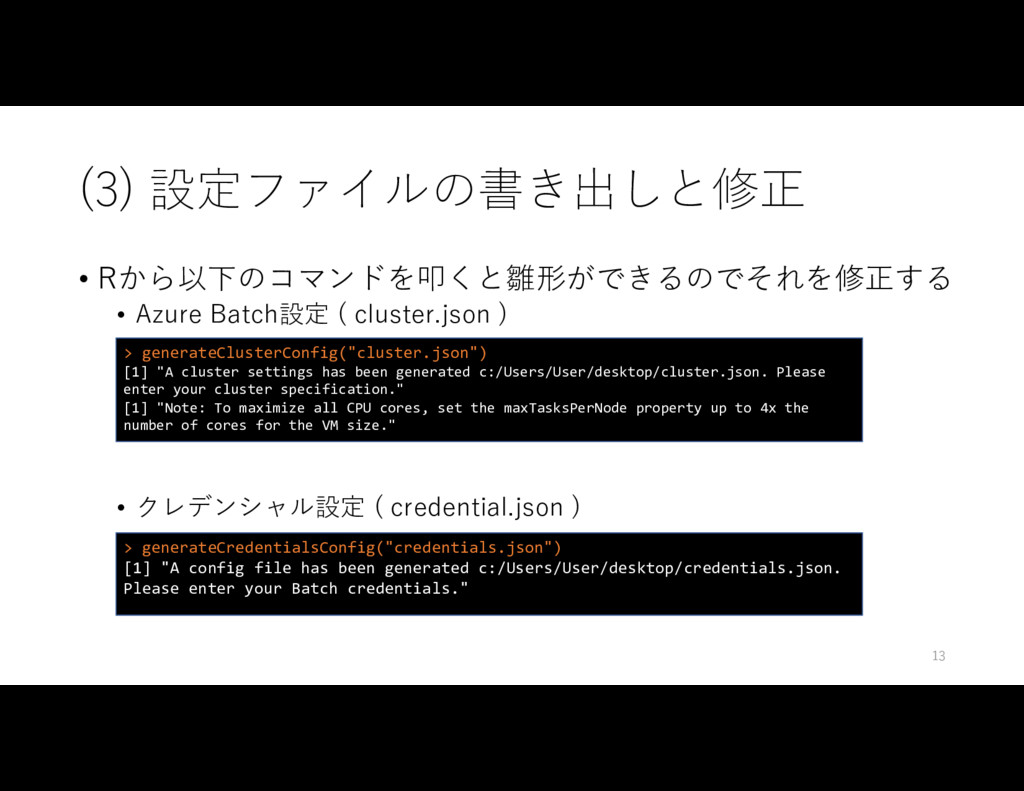{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}