2. Myths about Web Scraping 3. Main use cases a. In our website b. In external websites 4. Understanding the DOM 5. Extraction methods 6. Web Scraping Tools 7. Web Scraping with Python 8. Tips 9. Case studies 10. Bonus by @estevecastells & @NachoMascort
is a technique with which through software, information or content is extracted from a website. There are simple 'scrapers' that parse the HTML of a website, to browsers that render JS and perform complex navigation and extraction tasks.
uses of scraping are infinite, only limited by your creativity and the legality of your actions. The most basic uses can be to check changes in your own or a competitor's website, even to create dynamic websites based on multiple data sources.
of Certain HTML Tags ➜ Are all elements as defined in our documentation? ◦ Deployment checks ➜ Are we sending conflicting signals? ◦ HTTP Headers ◦ Sitemaps vs goals ◦ Duplicity of HTML tags ◦ Incorrect label location ➜ Disappearance of HTML tags
what a human would do and you can save money ◦ Visual changes • Are you adding new features? ◦ Changes in HTML (goals, etc.) • Are you adding new Schema tagging or changing your indexing strategy? ◦ Content changes • Do you update/cure your content? ◦ Monitor ranking changes in Google
can consult any HTML of a site by typing in the browser bar: view-source: https://www.domain.tld/path *With CSS and JS it is not necessary because the browser does not render them ** Ctrl / Cmd + u
over a year ago: The idea is to modify the Meta Robots tag (via JS) of a URL to deindex the page and see if Google pays attention to the value found in the source code or in the DOM. URL to experiment with: https://seohacks.es/dashboard/
1. Delete the current meta tag robots 2. Creates a variable called "meta" that stores the creation of a "meta" type element (worth the redundancy) 3. It adds the attributes "name" with value "robots" and "content" with value "noindex, follow".
1. Delete the current meta tag robots 2. Creates a variable called "meta" that stores the creation of a "meta" type element (worth the redundancy) 3. It adds the attributes "name" with value "robots" and "content" with value "noindex, follow". 4. Adds to the head the meta variable that contains the tag with the values that cause a deindexation
each document using different models that are quite similar to each other. These are the ones: ➜ Xpath ➜ CSS Selectors ➜ Others such as regex or specific tool selectors
same selectors we use to write CSS. We can get them: ➜ Writing them ourselves with the same syntax as modifying the styles of a site ➜ Through developer tools within a browser *tip: to select a label we can use the xpath syntax and remove the @ from the attribute
> a Child o Subchild //div//a div a ID //div[@id=”example”] #example Class //div[@clase=”example”] .example Attributes //input[@name='username'] input[name='user name'] https://saucelabs.com/resources/articles/selenium-tips-css-selectors
Scraping Plugins Tools Scraper Jason The Miner Here there are more than 30 if you didn’t like these ones. https://www.octoparse.com/blog/top-30-free-web-scraping-software/
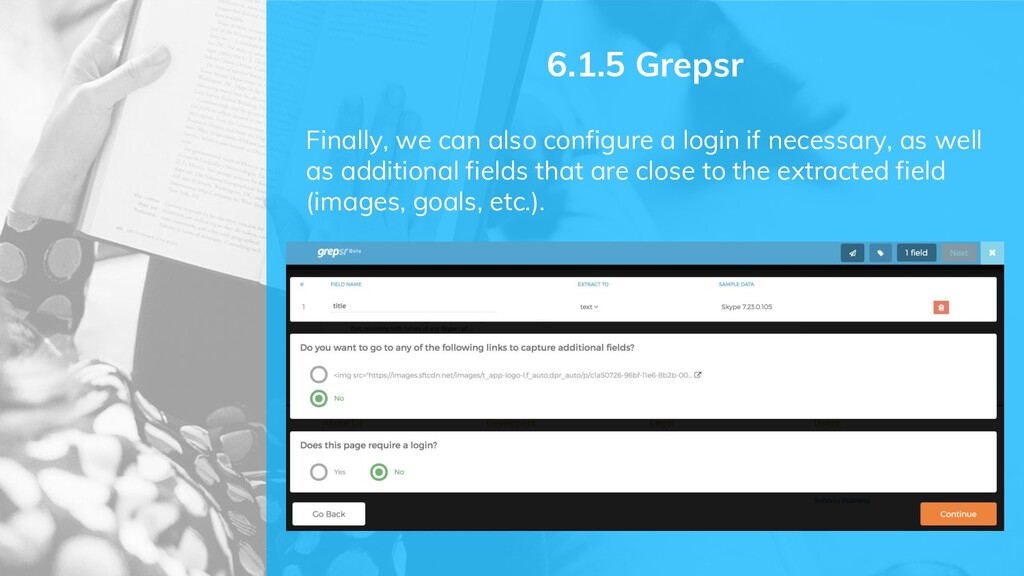
do basic scrapings, in some cases to get data out faster without having to pull out Python or JS to 'advanced' tools. ➜ Scraper ➜ Screaming Frog ➜ Google Sheets ➜ Grepsr 6.1 Web Scraping Tools
to make small scrapings of elements in a minimally well-structured HTML. It is also useful to remove the XPath when sometimes Google Chrome Dev Tools does not remove it well to use it in other tools. As a plus, it works like Google Chrome Dev Tools, on the DOM 6.1.1 Scraper
which can also be used for basic (and even advanced) scraping. As a crawler you can use Text only (pure HTML) or JS rendering, if your website uses client-side rendering. Its extraction mode is simple but with it you can get much of what you need to do, for the other you can use Python or other tools. 6.1.2 Screaming Frog
both on original websites and competitors. ➜ Monitor changes/lost data in a deploy ➜ Monitor weekly changes in web content ➜ Check quantity increase or decrease or content/thin content ratios The limit of scraping with Screaming Frog. You can do 99% of the things you want to do and with JS-rendering made easy!
removing all URLs from a sitemap index is to import the entire list and then clean it up with Excel. In case you don't (yet) know how to use Python. 1. Go to Download Sitemap index 2. Put the URL of the sitemap index
have all the clean URLs of a sitemap index. In this way we can then clean and pull results by URL patterns those that are interesting to us. Ex: a category, a page type, containing X word in the URL, etc. That way we can segment even more our scraping from either our website or a competitor's website.
most elements of a web page, from HTML to JSON with a small external script. ➜ Pro's: ◦ It imports HTML, CSV, TSV, XML, JSON and RSS. ◦ Hosted in the cloud ◦ Free and for the whole family ◦ Easy to use with familiar functions ➜ Con’s: ◦ It gets caught easily and usually takes thousands of rows to process
understand ➜ Easy approach for those starting with programming ➜ Much growth and great community behind it ➜ Core uses for massive data analysis and with very powerful libraries behind it (not just scraping) ➜ We can work on the browser! ◦ https://colab.research.google.com
on two: ➜ Requests + BeautifulSoup: To scrape data from the source code of a site. Useful for sites with static data. ➜ Selenium: Tool to automate QA that can help us scrape sites with dynamic content whose values are in the DOM but not in the source code. Colab does not support selenium, we will have to work with Jupyter (or any IDE)
User-agent basis. Sometimes you will be interested in being a desktop device, sometimes a mobile device. Sometimes a Windows, sometimes a Mac. Sometimes a Googlebot, sometimes a bingbot. Adapt each scraping to what you need to get the desired results! 8.1 User-agent
it will be necessary to use proxies, among other measures. Proxies act as an intermediary between a request made by an X computer and a Z server. In this way, we leave little trace when it comes to being identified. Depending on the website and number of requests we recommend using one quantity or another. Generally, more than one request per second from the same IP address is not recommended. 8.2 Proxies
VPN, since the VPN does the same thing but under a single IP. It is always advisable to use a VPN with another geo for any kind of tracking on third party websites, to avoid possible problems or identifications. Also, if you are caught by IP (e.g. Cloudflare) you will never be able to access the web again from that IP (if it is static). Recommended service: ExpressVPN 8.3 VPN’s
a network can make per second. We are interested in limiting the requests we always make, in order to avoid saturating the server, be it ours or a competitor's. If we saturate the server, we will have to make the requests again or, depending on the case, start the whole crawling process again. Indicative numbers: ➜ Small websites: 5 req/sec - 5 threads ➜ Large websites: 20 req/sec - 20 threads
scraping, we find data that does not fit what we need. Normally, we'll have to work on the data to clean it up. Some of the most common corrections: ➜ Duplicates ➜ Format correction/unification ➜ Spaces ➜ Strange characters ➜ Currencies
It can be firmly said that the best search engine at the moment is Google. What if we use Google's results to generate our own listings, based on the ranking (relevancy) that it gives to websites that position for what we want to position?
Jason The Miner, a scraping library made by Marc Mignonsin, Principal Software Engineer at Softonic (@mawrkus) at Github and (@crossrecursion) at Twitter
We will enter the top 20-30 results, analyze HTML and extract the link ID from the Amazon links. Then we will do a count and we will be automatically validating based on dozens of websites which is the best washing machine.
with their URL, which we can scrape directly from Google Play or using their API, and semi-automatically fill our CMS (WordPress, or whatever we have). This allows us to automate content research/curing and focus on delivering real value in what we write. Screenshot is an outcome based on Google Play Store
(HTTP, file, json, ....) ➜ Parse (HTML w/ CSS by default) ➜ Transform But this is ok, but we need to do it in bulk for tens or hundreds of cases, we cannot do it one by one.
➜ Bulk (imported from a CSV) ➜ Load (HTTP, file, json, ....) ➜ Parse (HTML w/ CSS by default) ➜ Transform Creating a variable that would be the query we inserted in Google.
our CMS, we will have to execute another basic scraping process or with an API such as Amazon to get all the data of each product (logo, name, images, description, etc). Once we have everything, the lists will be sorted and we can add the editorial content we want, with very little manual work to do.
Amazon Products ➜ Listings of restaurants that are on TripAdvisor ➜ Hotel Listings ➜ Netflix Movie Listings ➜ Best PS4 Games ➜ Better android apps ➜ Best Chromecast apps ➜ Best books
the same code over and over again. You need to find out how paginated URLs are formed in order to access them: >>>https://www.casadellibro.com/libros/novela-negra/126000000/p + page
easily. API's such as Dandelion APIs, which are used for semantic analysis of texts, can be very useful for the day to day running of our SEO. ➜ Entity Extraction ➜ Semantic similarity ➜ Keywords extraction ➜ Sentimental analysis 10.2 Dandelion API
➜ https://twitter.com/i/moments/949019183181856769 ➜ Scraping ‘People Also Ask’ boxes for SEO and content research https://builtvisible.com/scraping-people-also-ask-boxes-for-seo-a nd-content-research/ ➜ https://stackoverflow.com/questions/3964681/find-all-files-in-a-di rectory-with-extension-txt-in-python ➜ 6 Actionable Web Scraping Hacks for White Hat Marketers https://ahrefs.com/blog/web-scraping-for-marketers/ ➜ https://saucelabs.com/resources/articles/selenium-tips-css-selec tors EXTRA RESOURCES
https://www.smashingmagazine.com/2015/04/web-scraping-with-node js/ ➜ X-ray, The next web scraper. See through the noise: https://github.com/lapwinglabs/x-ray ➜ Simple, lightweight & expressive web scraping with Node.js: https://github.com/eeshi/node-scrapy ➜ Node.js Scraping Libraries: http://blog.webkid.io/nodejs-scraping-libraries/ ➜ https://www.scrapesentry.com/scraping-wiki/web-scraping-legal-or-ille gal/ ➜ http://blog.icreon.us/web-scraping-and-you-a-legal-primer-for-one-of-it s-most-useful-tools/ ➜ Web scraping o rastreo de webs y legalidad: https://www.youtube.com/watch?v=EJzugD0l0Bw
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![5.1.1 Xpath Syntax The writing standard is as follows: //tag[@attribute=’value’]](https://files.speakerdeck.com/presentations/a8ac6114503f41dba2a798e72108cf32/slide_42.jpg){kind=link}
![5.1.1 Xpath Syntax The writing standard is as follows: //tag[@attribute=’value’]](https://files.speakerdeck.com/presentations/a8ac6114503f41dba2a798e72108cf32/slide_43.jpg){kind=link}
![5.1.1 Xpath Syntax //tag[@attribute=’value’] For this tag: <input id=”seoplus” type=”submit”](https://files.speakerdeck.com/presentations/a8ac6114503f41dba2a798e72108cf32/slide_44.jpg){kind=link}
![5.1.1 Xpath Syntax //tag[@attribute=’value’] For this tag: <input id=”seoplus” type=”submit”](https://files.speakerdeck.com/presentations/a8ac6114503f41dba2a798e72108cf32/slide_45.jpg){kind=link}
![5.1.1 Xpath Syntax //tag[@attribute=’value’] For this tag: <input id=”seoplus” type=”submit”](https://files.speakerdeck.com/presentations/a8ac6114503f41dba2a798e72108cf32/slide_46.jpg){kind=link}
![5.1.1 Xpath Syntax //input[@id=’seoplus’]](https://files.speakerdeck.com/presentations/a8ac6114503f41dba2a798e72108cf32/slide_47.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}