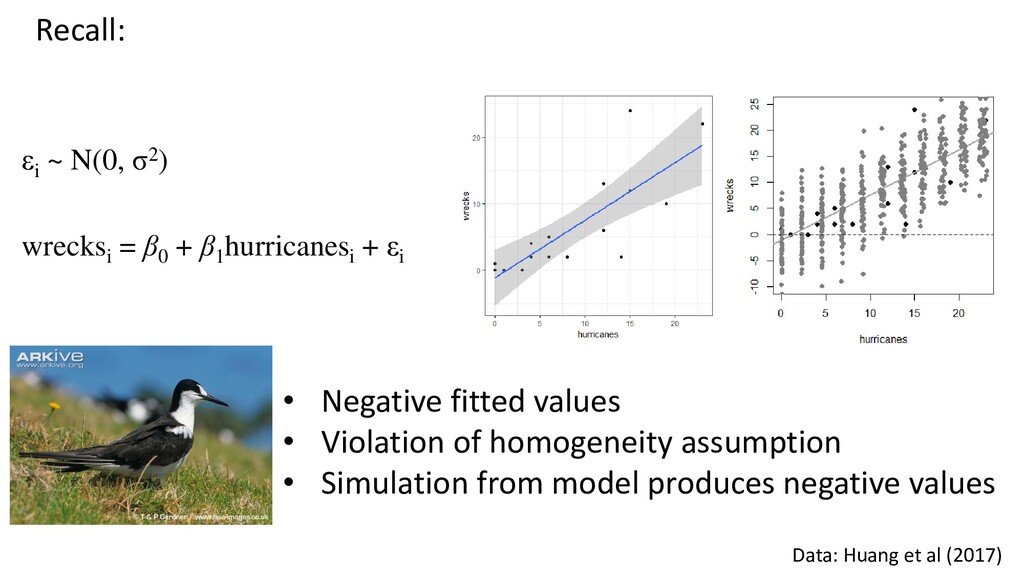
) E(CatchRate) = μ ij Log(μ ij ) = GearType ij + Temperature ij + FleetDeployment i FleetDeployment i ~ N(0, σ2) Using lme4: m <- glmer(CatchRate ~ GearType + Temperature + (1 | FleetDeployment), family = poisson) FISH 6003 FISH 6003: Statistics and Study Design for Fisheries Brett Favaro 2017 This work is licensed under a Creative Commons Attribution 4.0 International License
in which we gather as the ancestral homelands of the Beothuk, and the island of Newfoundland as the ancestral homelands of the Mi’kmaq and Beothuk. We would also like to recognize the Inuit of Nunatsiavut and NunatuKavut and the Innu of Nitassinan, and their ancestors, as the original people of Labrador. We strive for respectful partnerships with all the peoples of this province as we search for collective healing and true reconciliation and honour this beautiful land together. http://www.mun.ca/aboriginal_affairs/
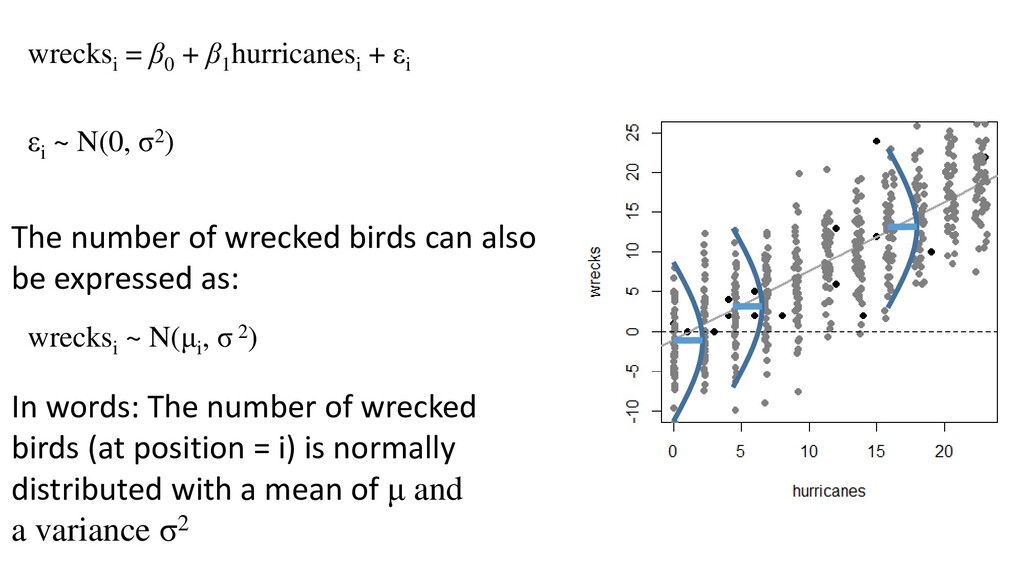
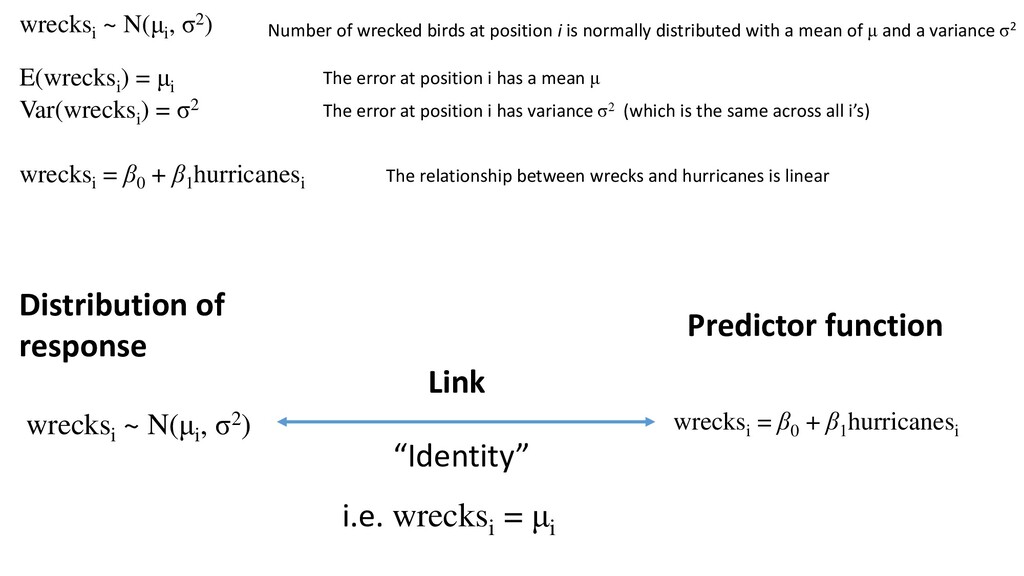
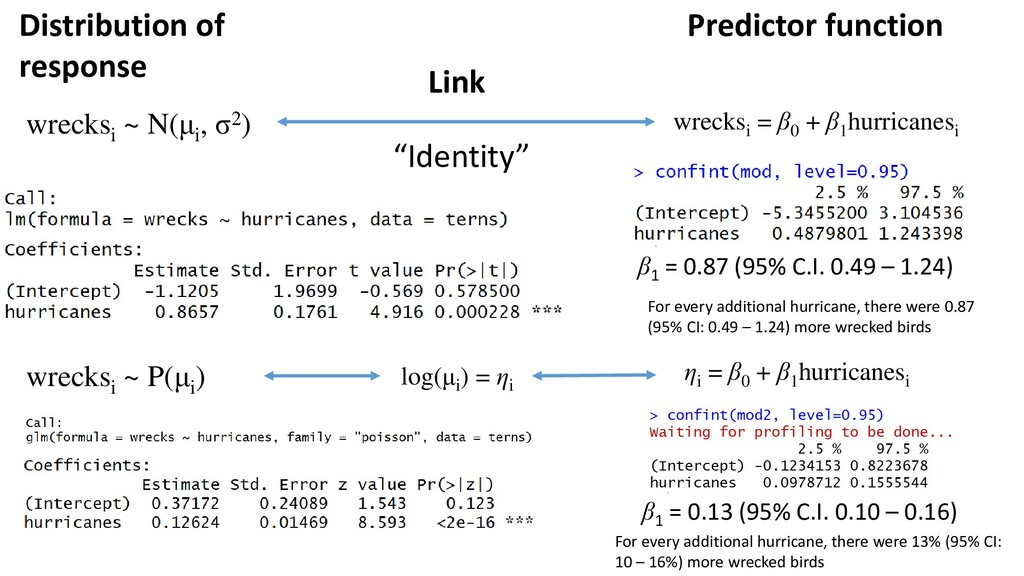
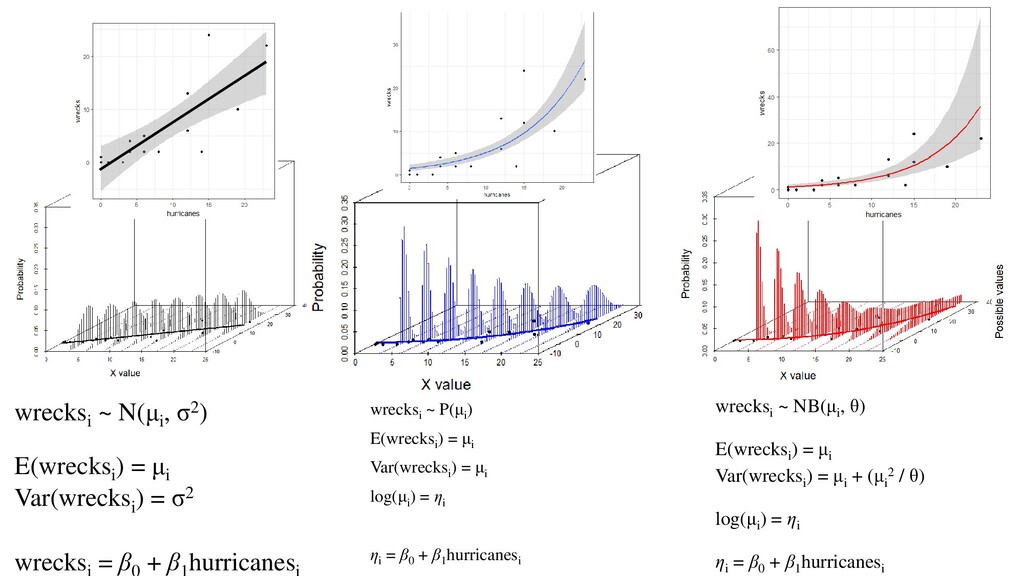
of wrecked birds can also be expressed as: wrecksi ~ N(μi , σ 2) εi ~ N(0, σ2) In words: The number of wrecked birds (at position = i) is normally distributed with a mean of μ and a variance σ2
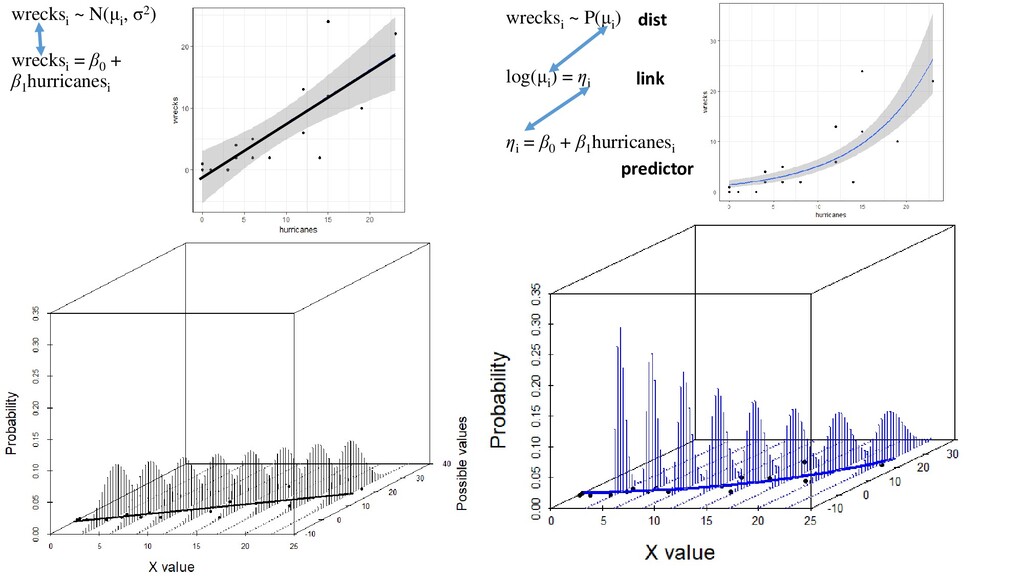
) = σ2 wrecksi = β0 + β1 hurricanesi Number of wrecked birds at position i is normally distributed with a mean of μ and a variance σ2 The error at position i has a mean μ The error at position i has variance σ2 (which is the same across all i’s) The relationship between wrecks and hurricanes is linear Distribution of response Predictor function wrecksi ~ N(μi , σ2) wrecksi = β0 + β1 hurricanesi Link “Identity” i.e. wrecksi = μi
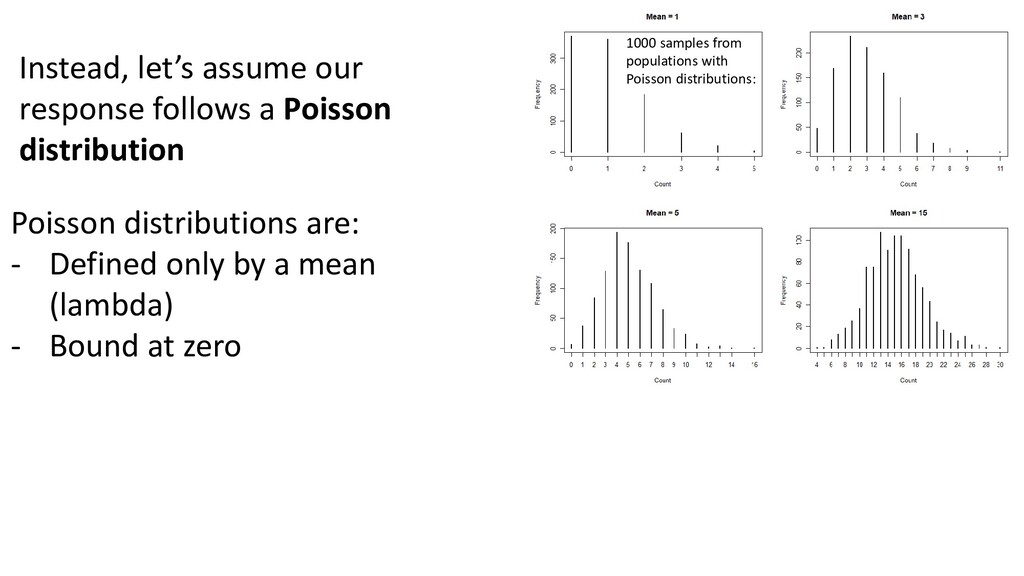
= β0 + β1 hurricanesi Link (eta) log(μi ) = ηi μi = eηi μi = eβ0 + β1 hurricanesi log-link function (default) Notes: - No more assumption of equal variance (Poisson distribution has just one parameter) - Fitted values will never be negative - Still a linear model
= β0 + β1 hurricanesi Log-link (eta) log(μi ) = ηi The number of wrecks predicted at 1 hurricane is: e0.371+0.126*1 The number of wrecks predicted at 2 hurricanes is: e0.371+0.126*2 …and so on Also true: e(0.12624) = 1.134554. Round to 1.13 “For every additional hurricane, there was a 13% increase in wrecked birds”
E.g. simple linear regression • E.g. multiple linear regression • … could also be described as a Gaussian Generalized Linear Model • What we are now calling a Poisson Generalized Linear Model is also sometimes called: • Log-linear regression • Poisson regression
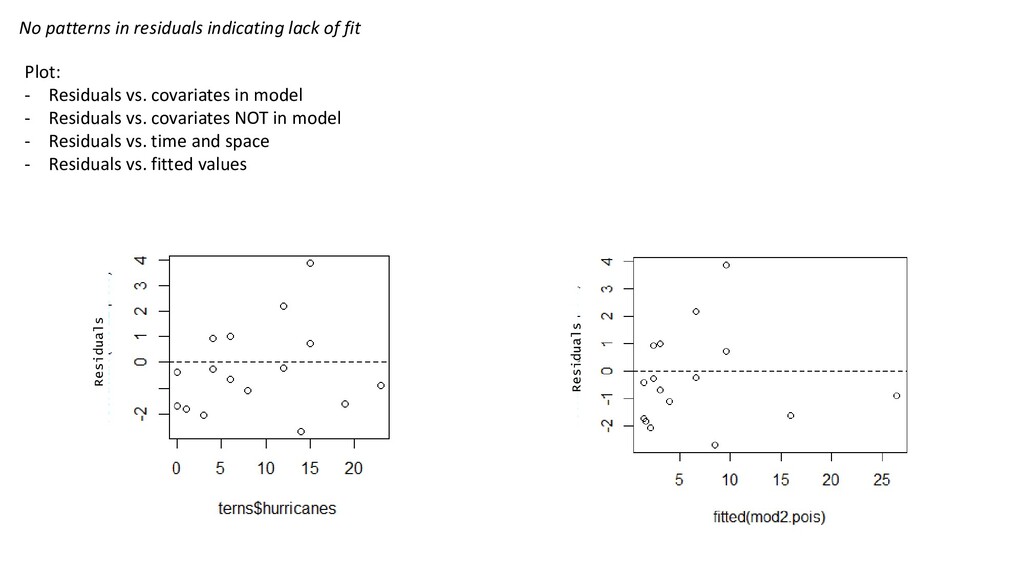
= μi log(μi ) = ηi ηi = β0 + β1 hurricanesi Validation Still need: • Independence • Fixed X With non-Gaussian GLMs, there are a variety of ‘families’ of residuals one could compute Pearson Residuals are most common Don’t need: • Normality Need • No overdispersion • No patterns in residuals indicating lack of fit
= μi ηi = β0 + β1 hurricanesi Need: • Independence • Fixed X • No overdispersion • No patterns in residuals indicating lack of fit Conclusion: Overdispersed Two types of overdispersion: 1. Apparent • Fixable within the model 2. Real • The real process is actually very dispersed Bad because it can make contribution of covariate appear significant, even if it isn’t
in Y 2. Missing covariates 3. Missing interactions 4. Zero-inflation 5. Dependency not accounted for 6. Non-linear patterns 7. Wrong link function Solutions Rule each of these out. Wrong choice = biased parameters 1. Remove 2. Add 3. Add 4. Use Zero-Inflated model (later) 5. Add a ‘random effect’ (later) 6. Use a Generalized Additive Model (not this course) 7. Change it
is <10, and if you have a very strong effect size • Adjusts standard error, but not coefficients. Makes it less likely to find significant effect, but doesn’t correct your results • This isn’t great… the coefficients themselves are affected by overdispersion. Use quasi-poisson with caution Variance doesn’t have to = 1 * mean in quasipoisson
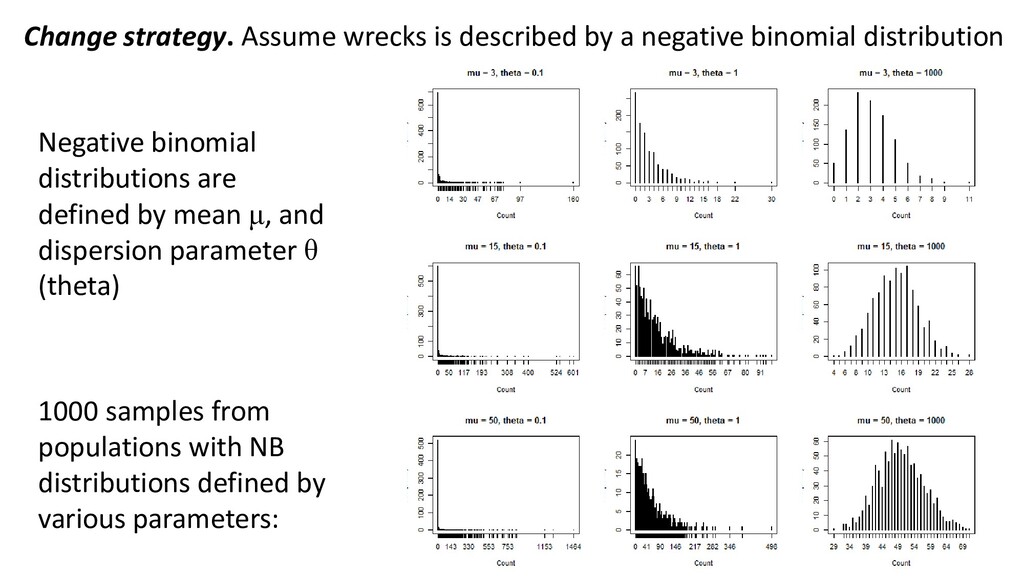
distribution Negative binomial distributions are defined by mean μ, and dispersion parameter θ (theta) 1000 samples from populations with NB distributions defined by various parameters:
a geometric distribution Var(wrecksi ) = μi + (μi 2 / θ) • If your data could never have a zero value, use a “zero-truncated model” • When using negative binomial models, get residuals with: mod$resid, NOT residuals(mod)
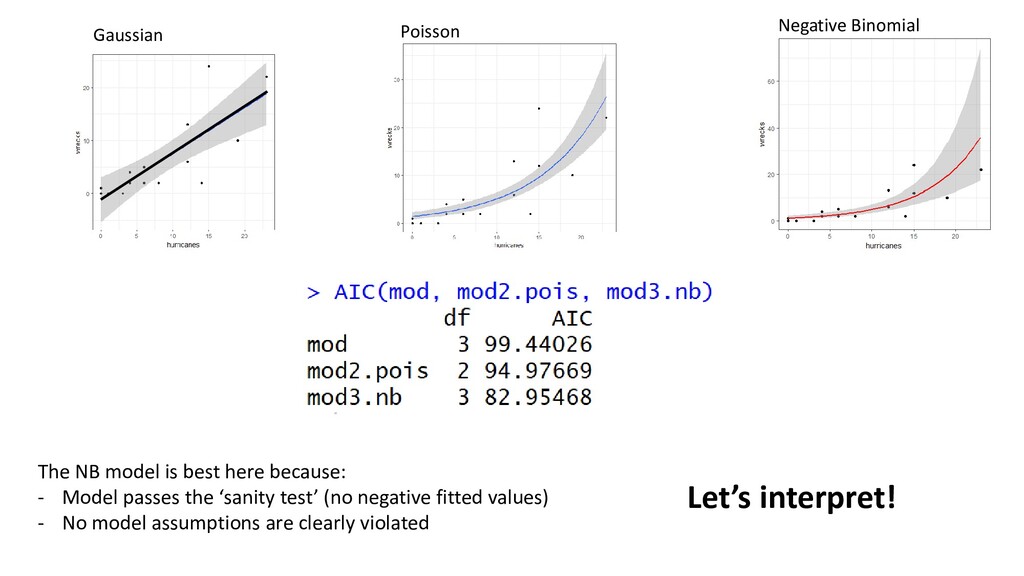
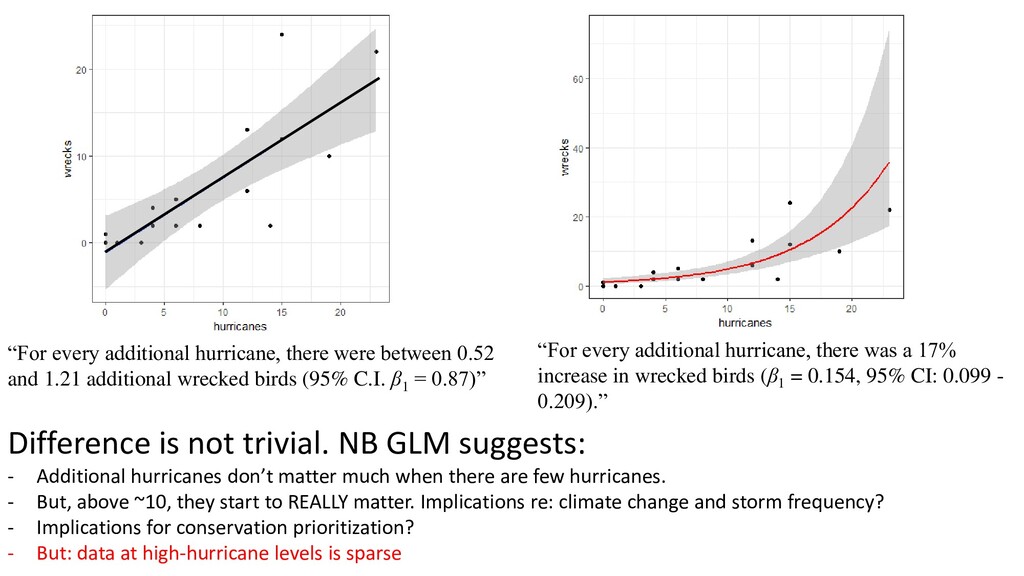
In results: “There was a positive association between wrecked birds and hurricanes (β1 = 0.154, 95% CI: 0.099 - 0.209, Figure 1, Table 1)” Figure 1: Modelled relationship between wrecked birds and hurricanes. Black dots are observed data, and the red line represents the negative binomial GLM (eqn 1). Grey shaded area represents 95% C.I. Estimate Std. error Z value P-value Intercept 0.0302 0.380 0.080 0.937 Hurricanes 0.154 0.028 5.467 <0.001 Table 1: Estimated regression parameters, standard errors, z-values, and P-values for the Negative Binomial GLM in eqn (1) In methods: “We modelled the relationship between wrecked birds and hurricanes by fitting a negative binomial GLM, with a log link function, using the MASS package in R (eqn 1, *citations*). The log link function ensures positive fitted values, and the negative binomial distribution was used because a Poisson GLM was overdispersed.” *Say how you validated model assumptions*
additional wrecked birds (95% C.I. β1 = 0.87)” “For every additional hurricane, there was a 17% increase in wrecked birds (β1 = 0.154, 95% CI: 0.099 - 0.209).” Difference is not trivial. NB GLM suggests: - Additional hurricanes don’t matter much when there are few hurricanes. - But, above ~10, they start to REALLY matter. Implications re: climate change and storm frequency? - Implications for conservation prioritization? - But: data at high-hurricane levels is sparse
should be: 1. Poisson GLM 2. If overdispersed: Negative Binomial GLM Assumptions must be verified: NB • Independence • Fixed X • No patterns in residuals indicating misfit Gaussian • Independence • Fixed X • Normality • Homogenous variance Poisson • Independence • Fixed X • Not overdispersed • No patterns in residuals indicating misfit
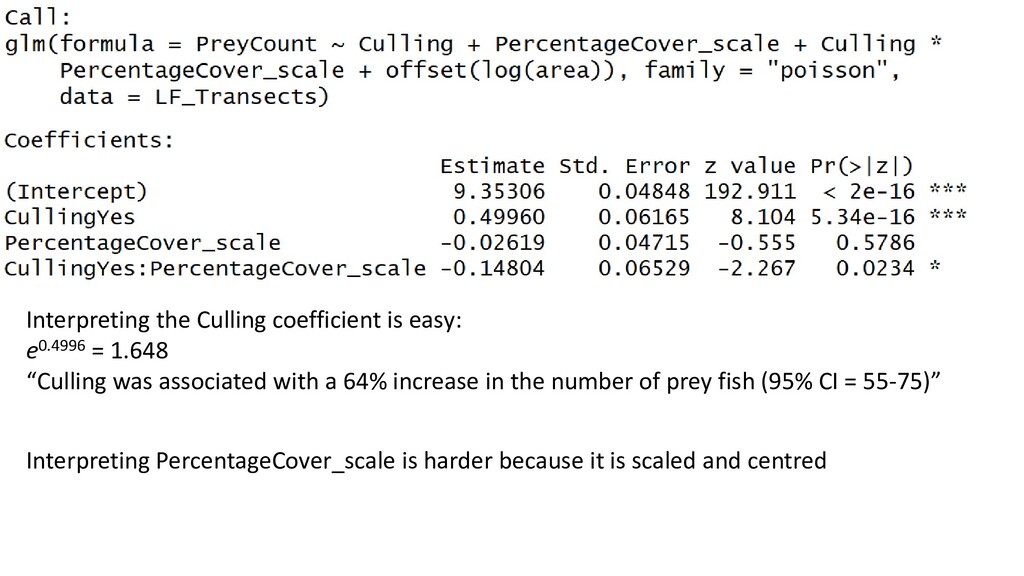
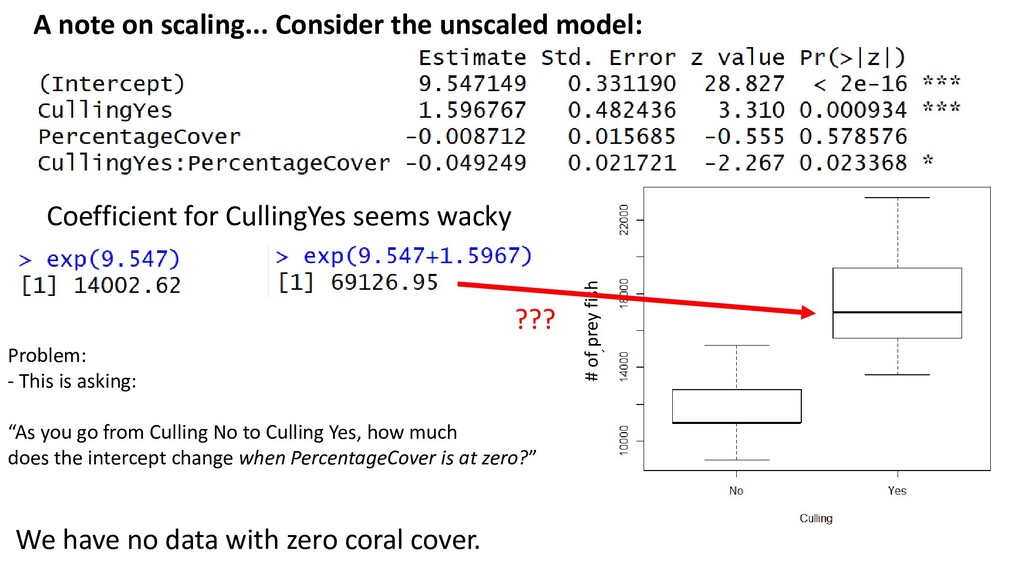
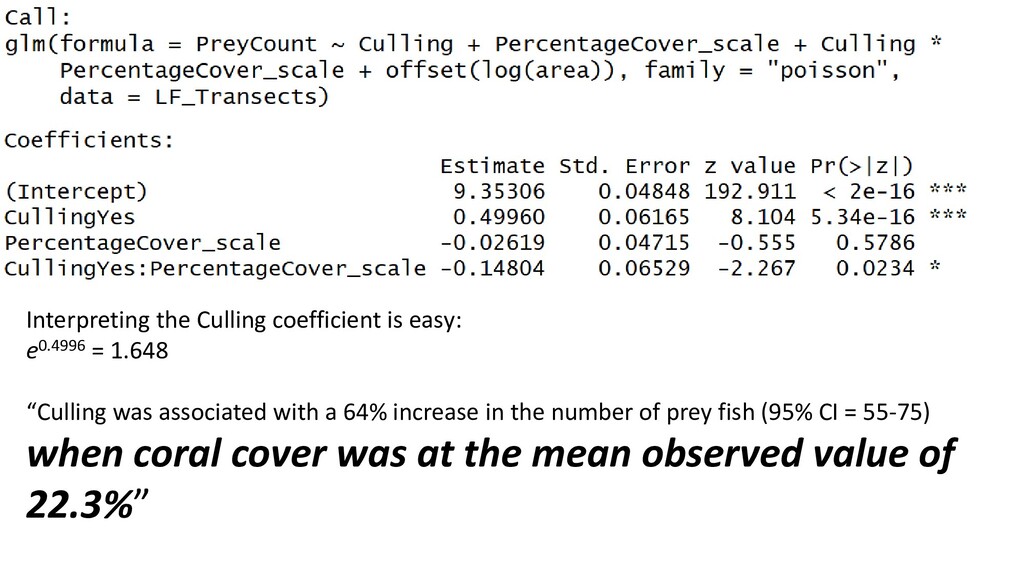
was associated with a 64% increase in the number of prey fish (95% CI = 55-75)” Interpreting PercentageCover_scale is harder because it is scaled and centred
prey fish Coefficient for CullingYes seems wacky ??? Problem: - This is asking: “As you go from Culling No to Culling Yes, how much does the intercept change when PercentageCover is at zero?” We have no data with zero coral cover.
of culling on prey, you would need to make sure to add enough “percentage cover” units for this to be a reasonable interpretation. “At a median value for PercentageCover, a one-unit increase in Culling increases prey fish density by…” The Visreg package (http://pbreheny.github.io/visreg/glm.html) can assist here
not normally distributed data • Especially well-suited for: • Count data (Poisson, Negative Binomial) • Binomial outcome data (Binomial logistic regression) • Three components to a GLM: • Predictor function • Link function • Distribution • Validation is different for each type of GLM Recap:
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}