Wie überwacht man eine dynamische Wolke von Microservices, in der das ständige Fehlschlagen von Services zum Normalfall wird?
Success-Stories von Netflix, Google oder Soundcloud befeuern einen der wichtigsten Entwicklungen in der Software-Architektur unserer Tage: Microservices. Applikationen werden dabei in viele kleine Services zerlegt, die unabhängig voneinander betrieben, skaliert und gewartet werden können.
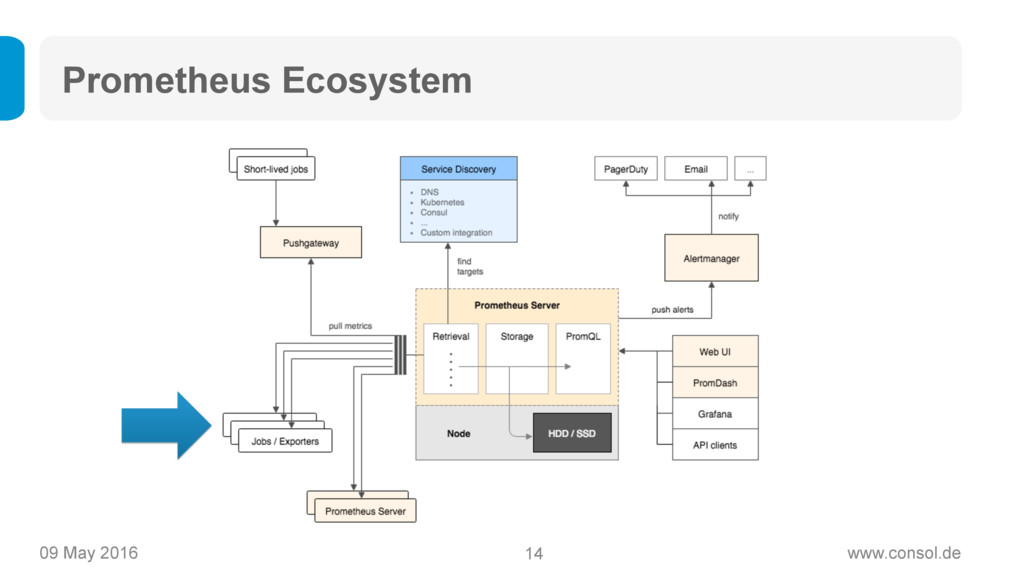
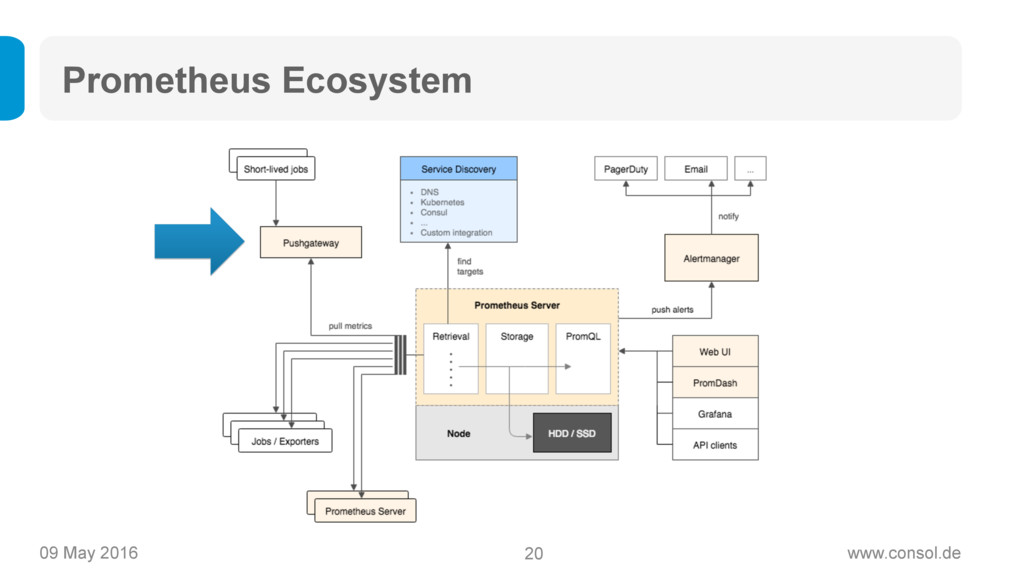
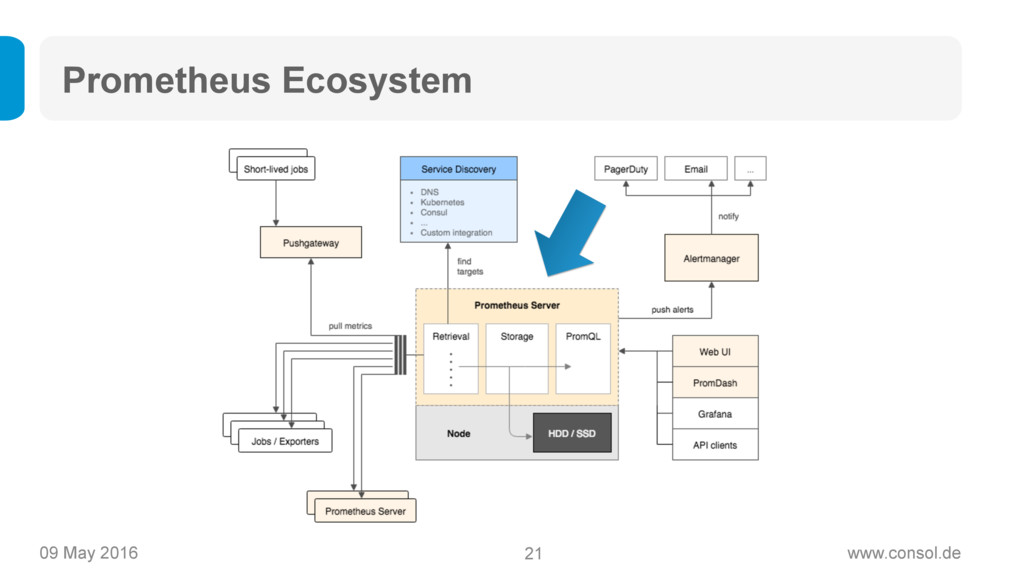
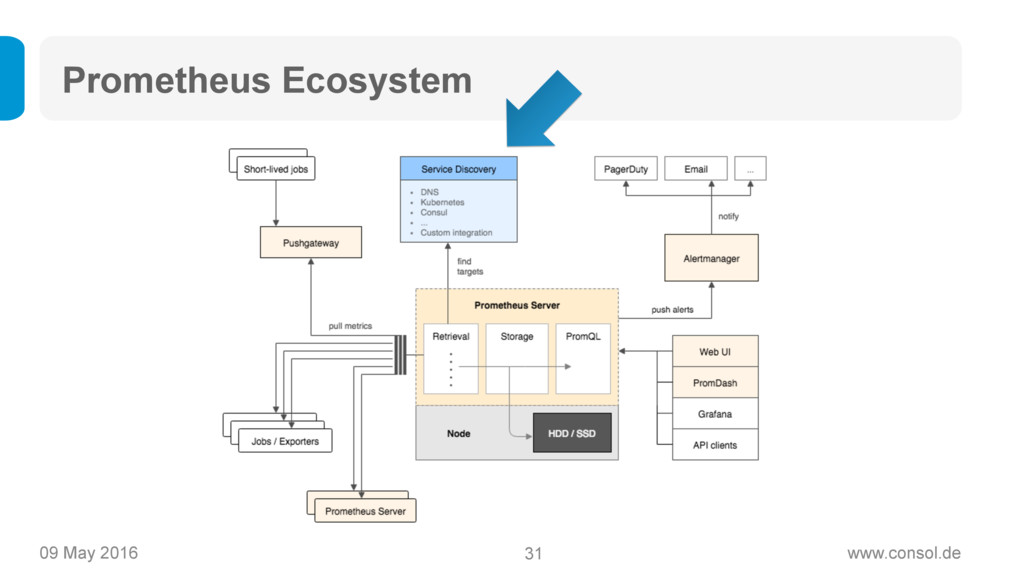
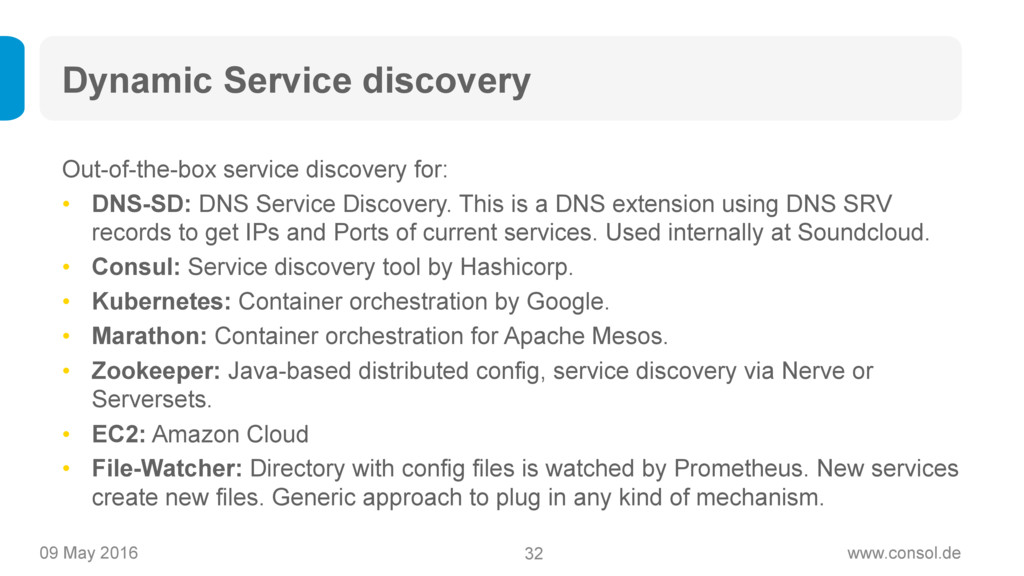
Prometheus (https://www.prometheus.io) ist ein Open Source Projekt von Soundcloud, das als der neue Heilsbringer für Monitoring von modernen, dynamischen Microservice-Architekturen gilt: Das Time-Series-Datenmodell ermöglicht statistisches Monitoring, Prometheus ist einfach aufzusetzen und zu betreiben, es ist super skalierbar und bringt eine mächtige Query-Sprache mit sich.
---
http://www.meetup.com/de-DE/Munchner-Monitoring-Stammtisch/events/230654620/
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}