Dataductos en R con dplyr - Sesión 1
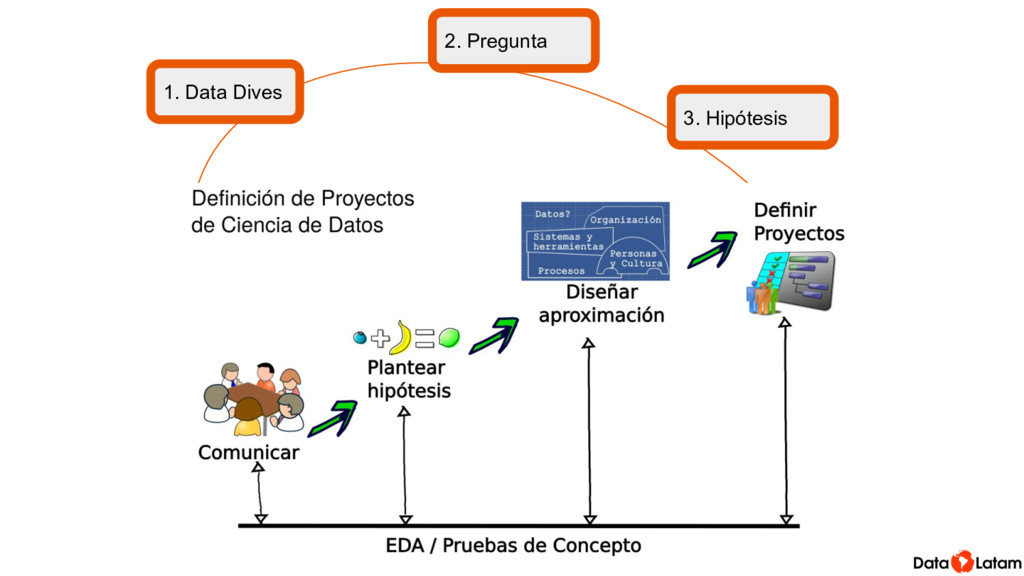
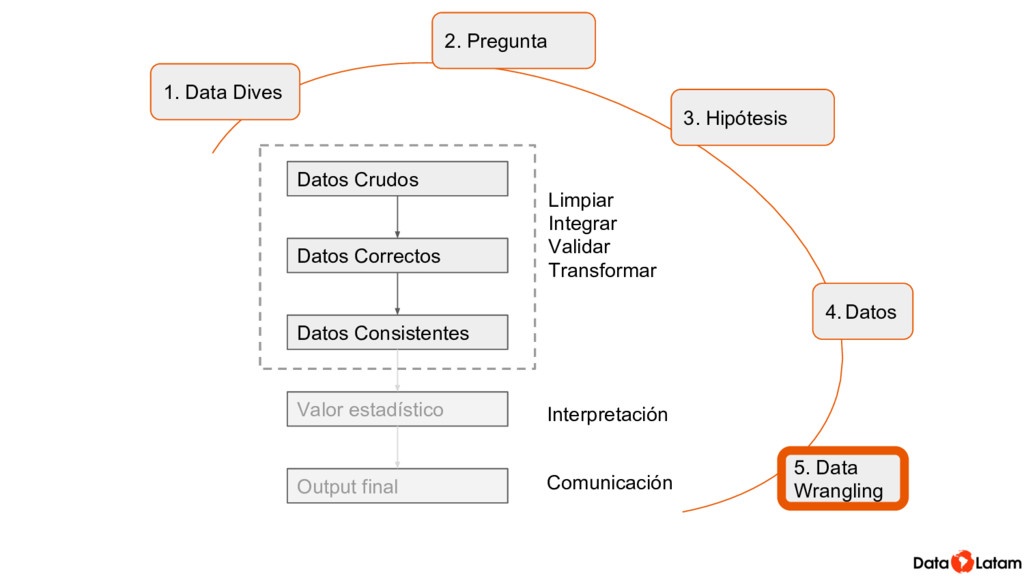
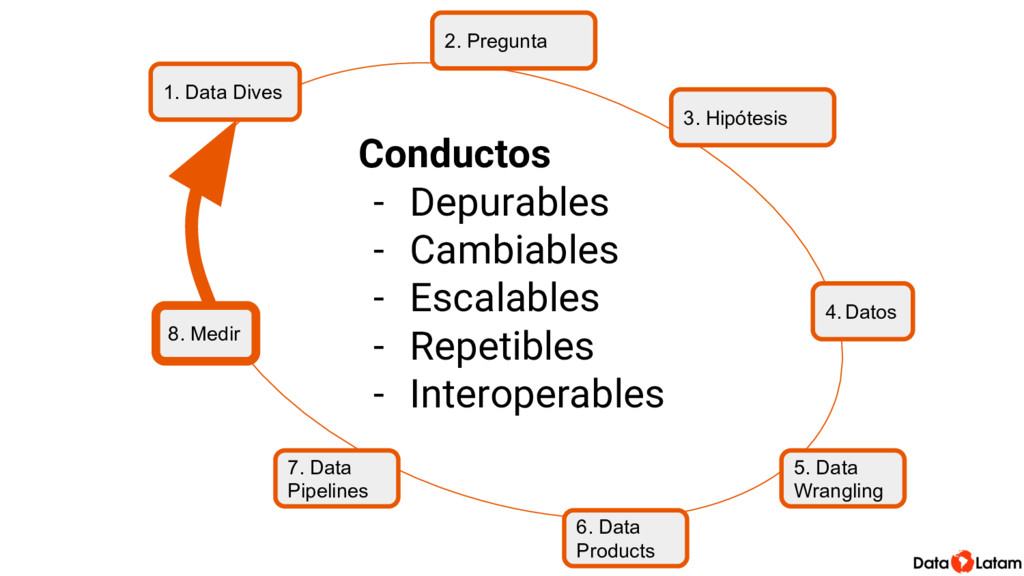
Una de las labores principales de para correr análisis es preparar datos para que sean adecuados para entrar a la función con la ejecutamos el método, o para visualizarlos. Esto incluye acciones como por ejemplo crear subconjuntos, transformar valores, crear nuevas variables basadas en las que ya tenemos.
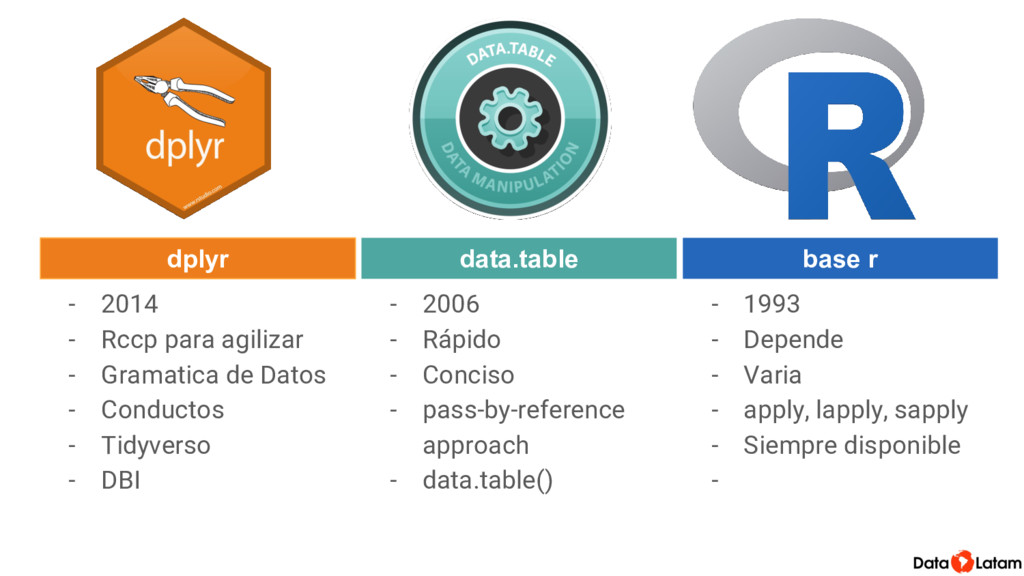
Mucho de esto se puede hacer con funciones que son parte del R base. Pero dplyr implementa el concepto de la gramática de datos y permite hacerlo de una forma consistente que es fácil de leer (y por lo tanto más fácil de corregir). Además engancha con todos los demás paquetes del así llamado Tidyverso, para extender las opciones que tenemos para manipular datos usando la misma forma de escribir.
Quieres mas infórmación sobre los cursos de Data Latam? Apuntate en nuestra lista de correo para recibir noticias:
http://www.datalatam.com/noticias
Data Latam es una comunidad Latinoamericana de profesionales y académicos aplicando ciencia de datos en su día a día en la industria de datos en Latino América. En sus eventos, cursos y programas de extensión exploramos tecnologías, aprendemos sobre ciencia de datos, hablamos de tendencias y eventos relevantes de la industria, y compartimos novedades del sector.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Base-R - data[1:3, 56:1023] - data[data$variable == "valor", ] -](https://files.speakerdeck.com/presentations/d516e519c5784064a03d96ad59979953/slide_11.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}