ara esta ocasión tendremos un invitado especial, Frans van Dunné Científico de Datos. Frans, quien cuenta con más de 15 años de experiencia en análisis e innovación con datos ha colaborado con múltiples empresas en definición de estrategia y productos de datos, como parte de estos procesos ha trabajado en modelado de procesos, minería de datos, y gestión de datos con organizaciones alrededor del mundo. Frans se formó como ecólogo y tiene un doctorado de la Universidad de Amsterdam.
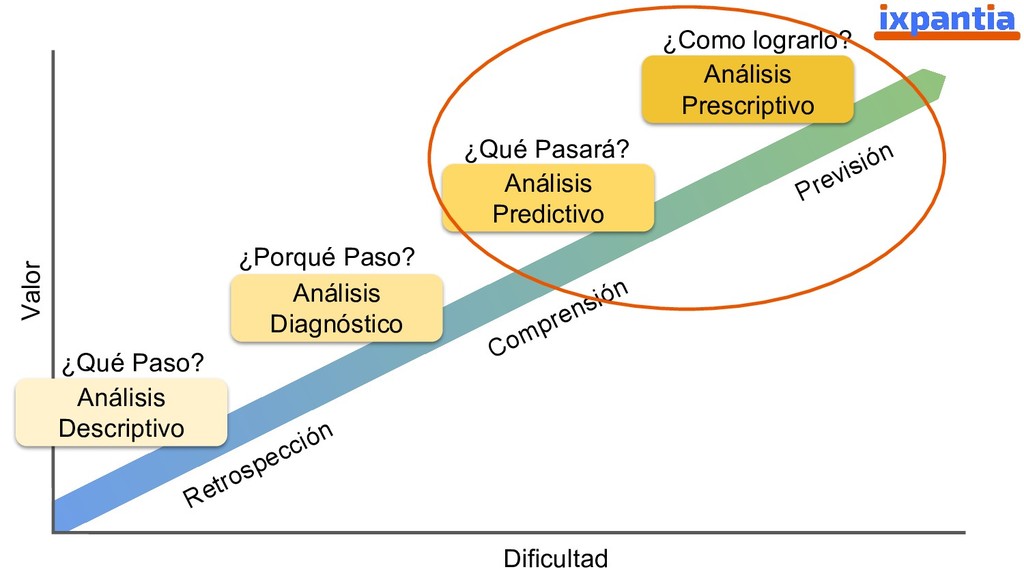
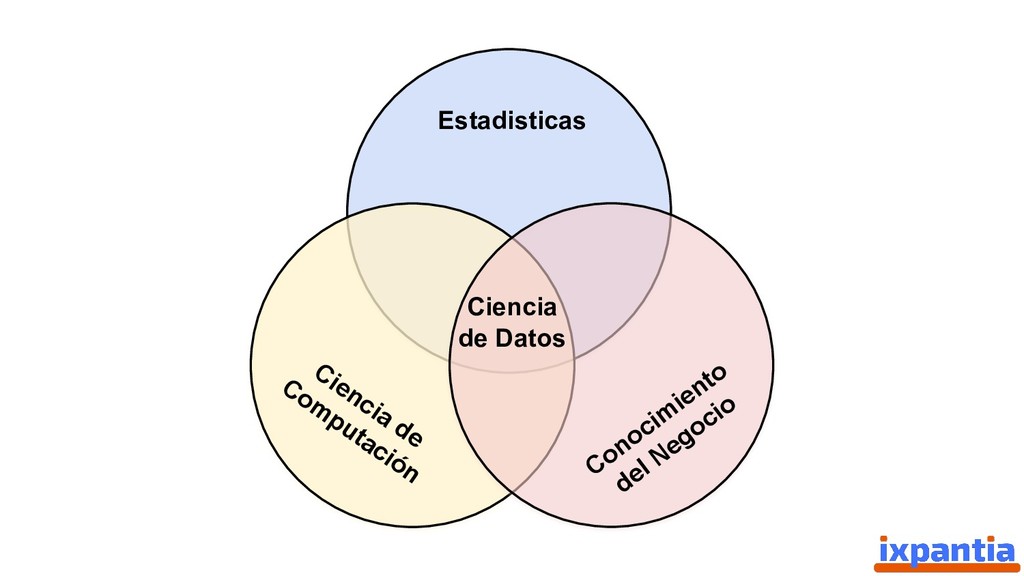
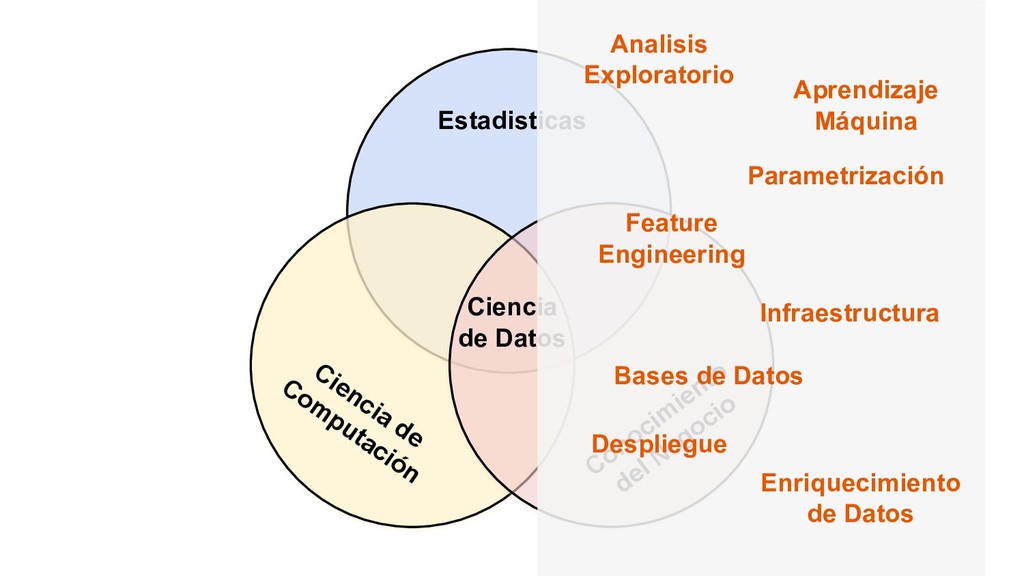
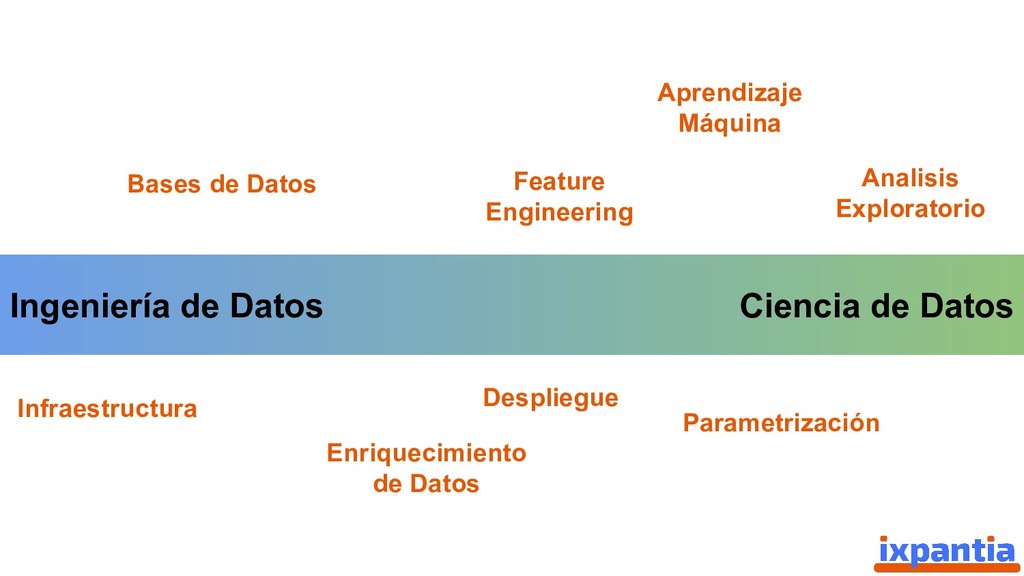
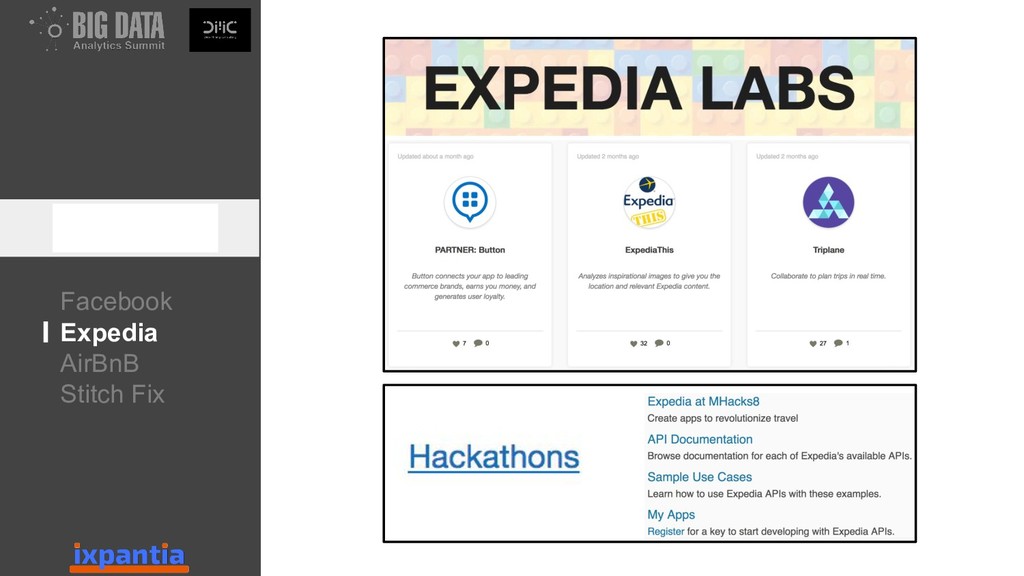
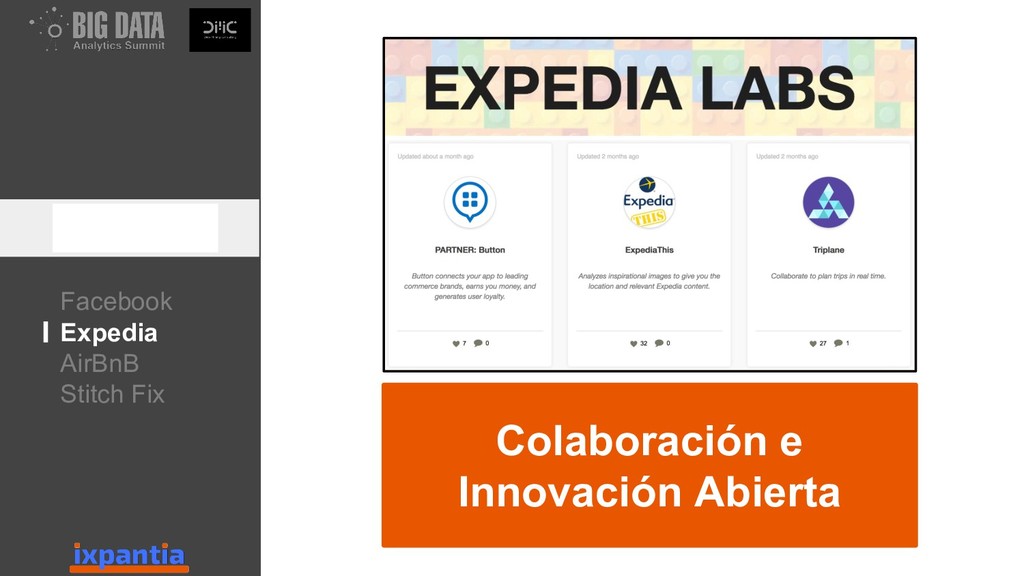
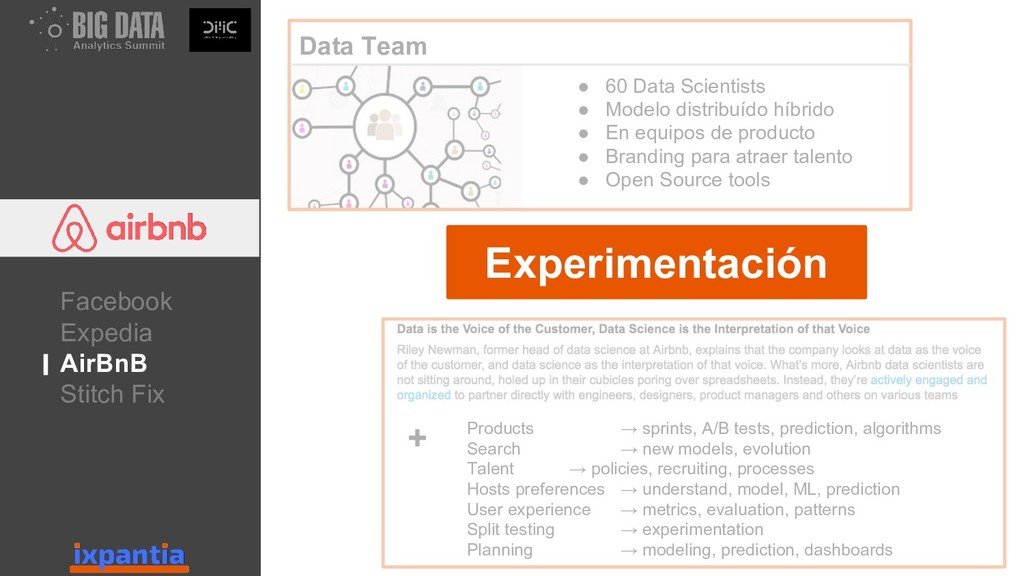
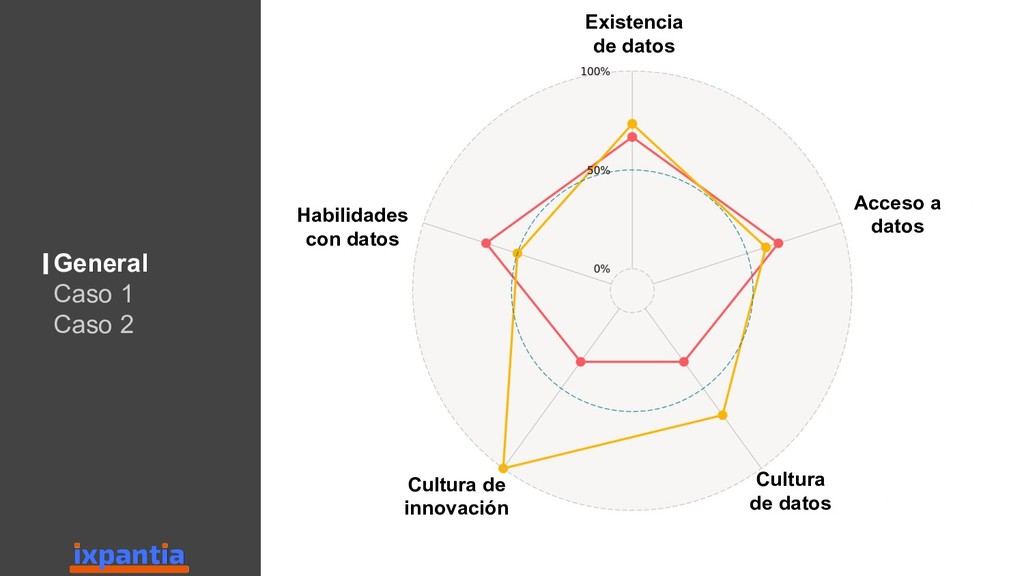
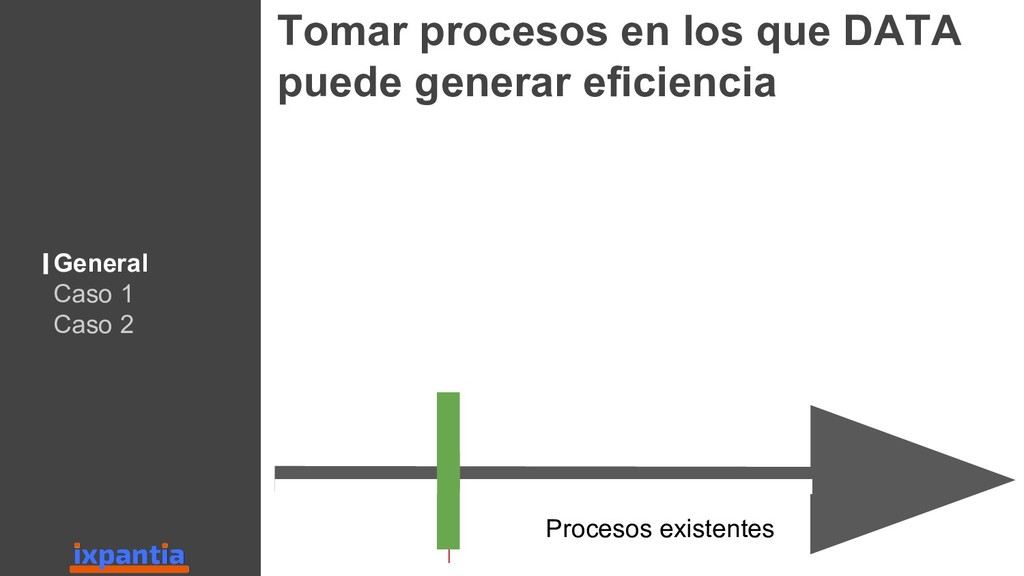
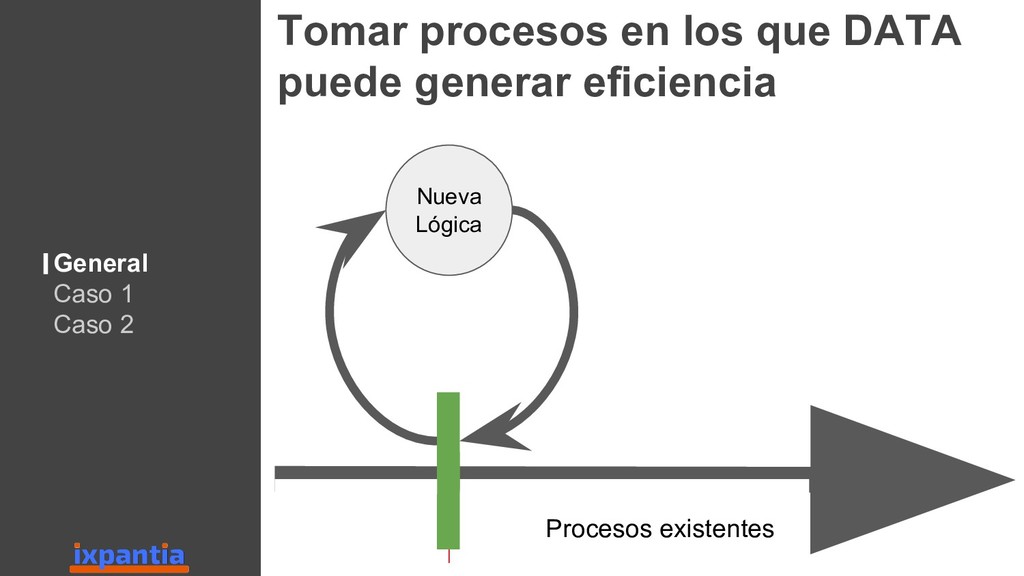
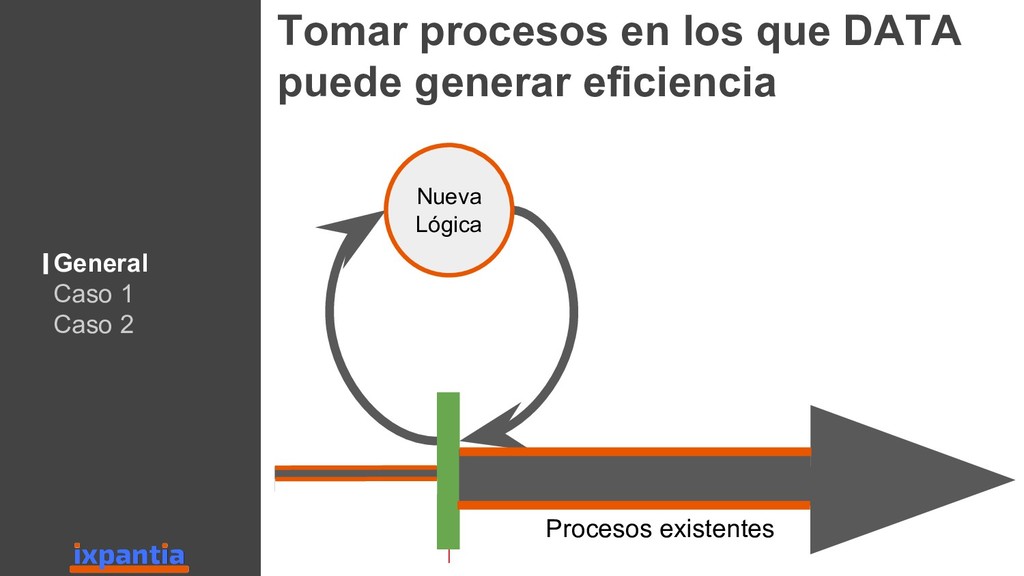
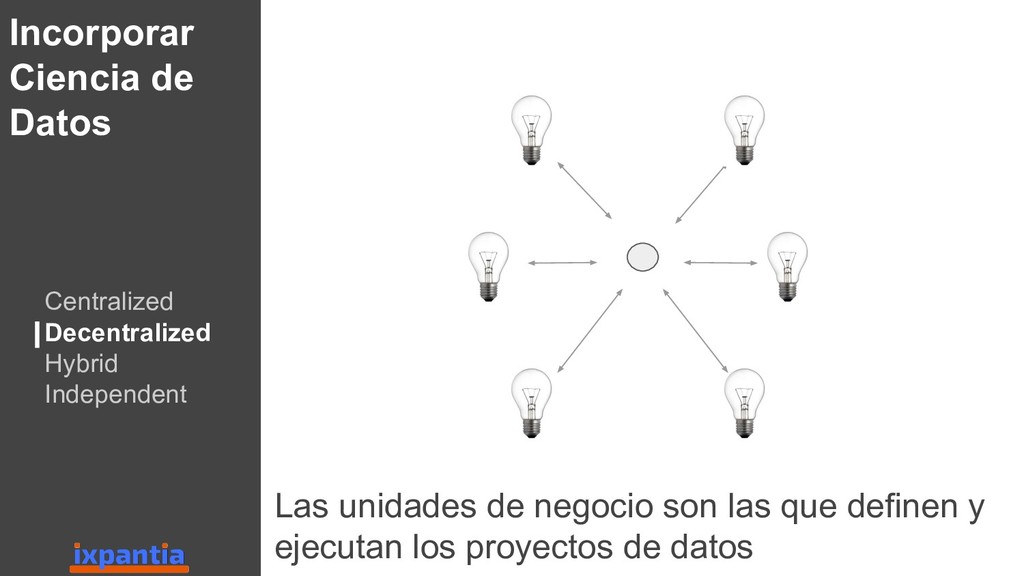
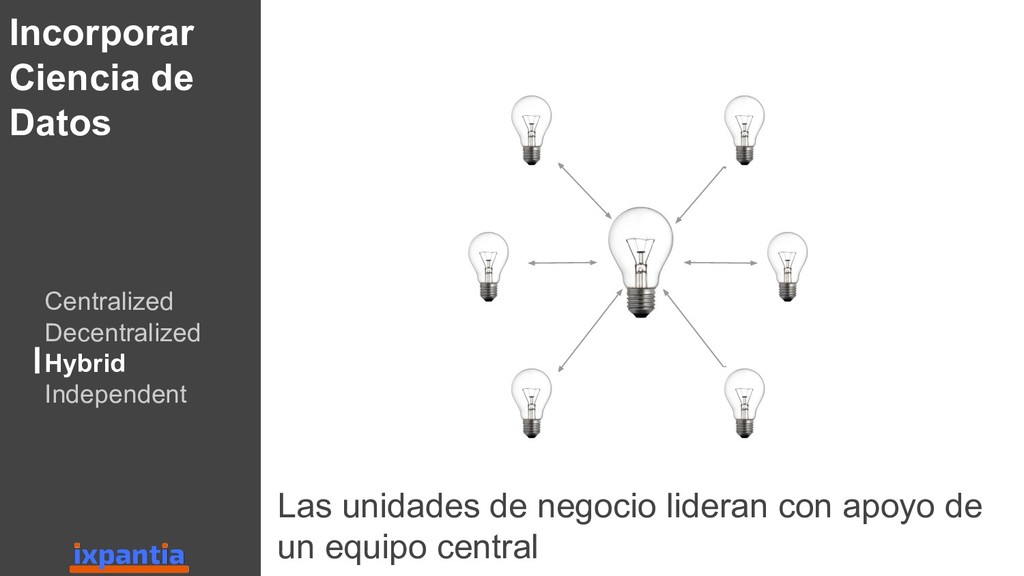
En esta ocasión vamos a hablar sobre la experiencias de empresas que han logrado innovar con datos hasta el punto de ser "data driven". Así como, las diferentes estructuras para organizar grupo analíticos a nivel laboral.
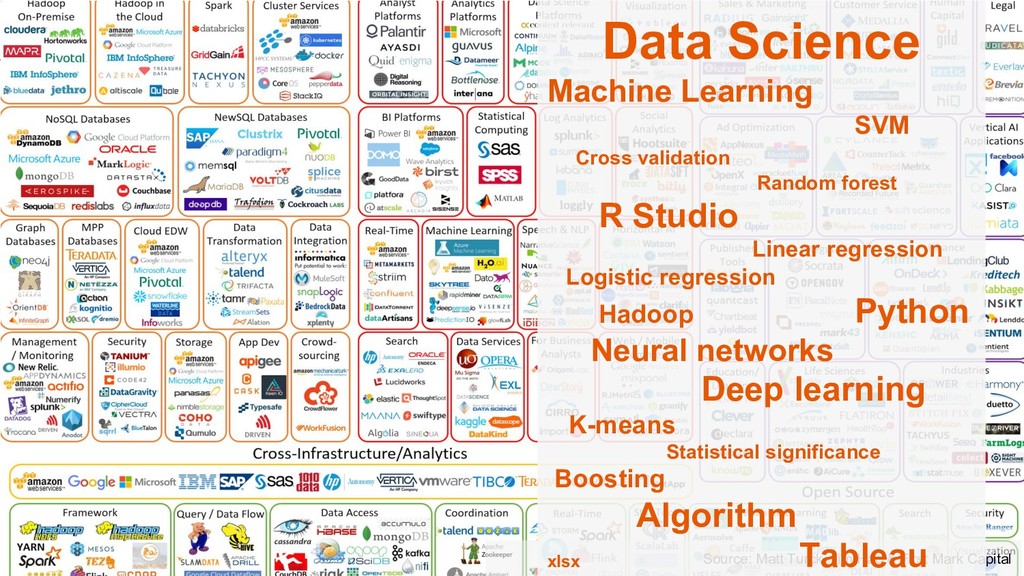
Adicionalmente, se hablara sobre el lenguaje de programación R, su auge en la ciencia y en la industria, su estado actual y los puntos que lo distinguen de otros lenguajes populares para Data Science (como python).
Además damos una vista hacía el futuro para identificar criterios sobre los cuales una empresa, o un grupo analítico, pueda decidir si es estratégico invertir en R a futuro, o no.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Gracias por su atención! @fransvandunne [email protected] www.datalatam.com www.ixpantia.com](https://files.speakerdeck.com/presentations/02fdecbd687f459097426a8e631892ba/slide_79.jpg){kind=link}