the time we need a ton of data… - … which we don’t always have - … and even if we do sometimes they are unlabeled - Manually collecting data & labeling them requires human effort
of our data (in hopes of avoiding overfitting) without actually collecting new data - Is useful not just for limited datasets but also imbalanced datasets
Y. PatchShuffle regularization. arXiv preprint. 2017. 5.66% error rate on CIFAR-10 vs 6.33% achieved without PatchShuffle Using hyperparams: - 2 × 2 filters - 0.05 probability of swapping Can be implemented as a layer in CNN instead
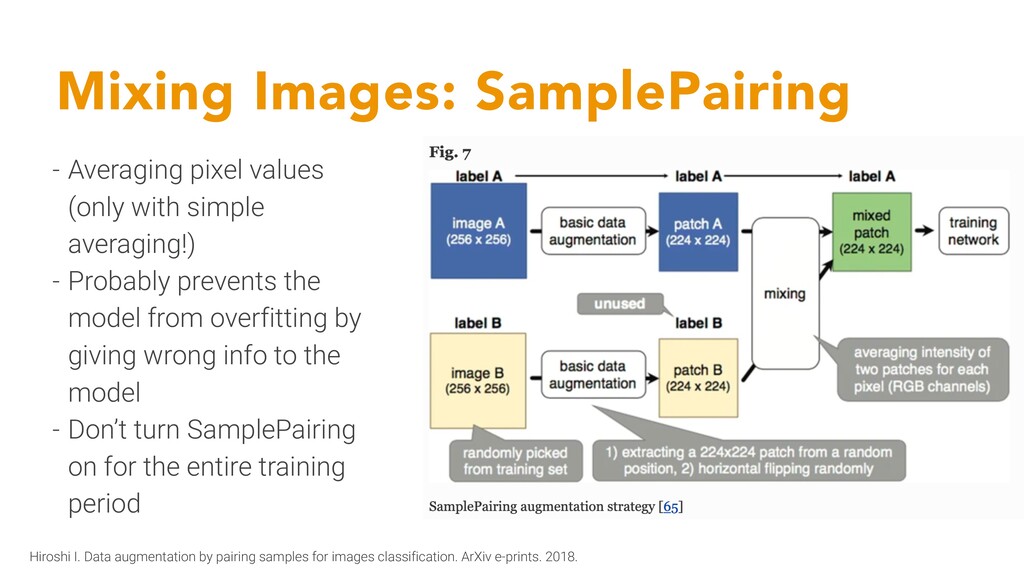
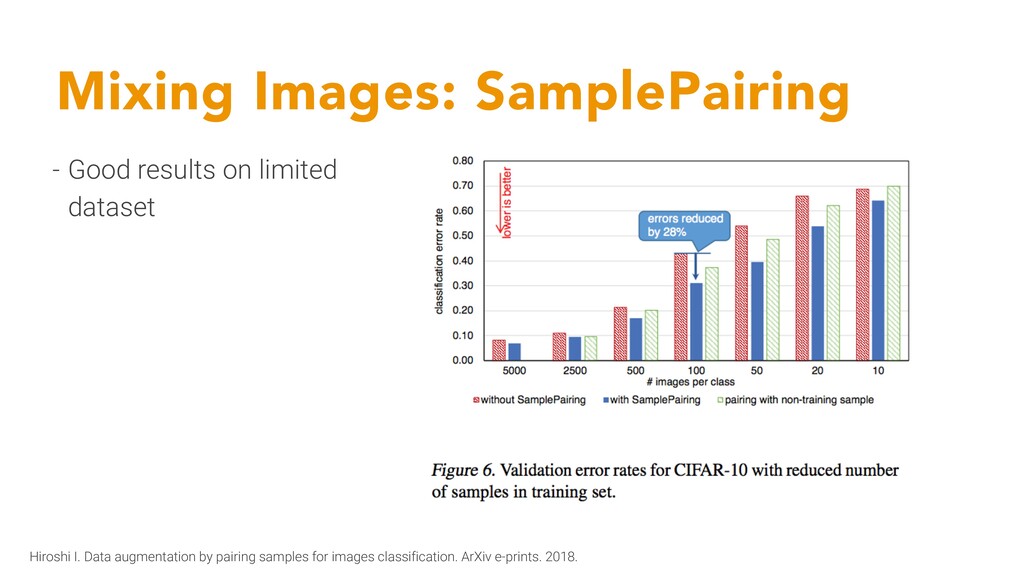
averaging!) - Probably prevents the model from overfitting by giving wrong info to the model - Don’t turn SamplePairing on for the entire training period Hiroshi I. Data augmentation by pairing samples for images classification. ArXiv e-prints. 2018.
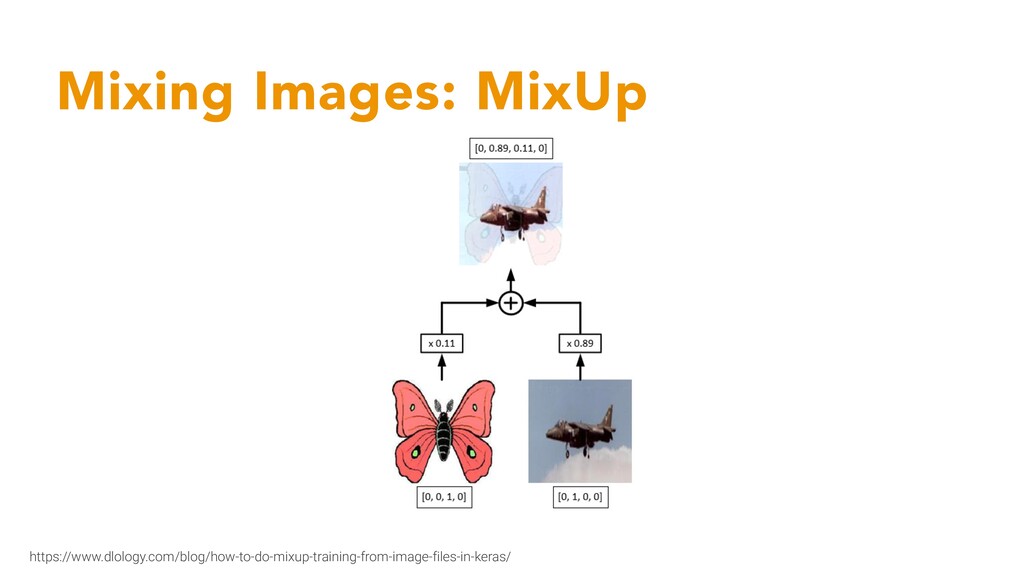
M Cisse, YN Dauphin and D Lopez-Paz (2017) mixup: Beyond Empirical Risk Minimization - Take 2 images & do a linear combination of them - Λ is randomly sampled from beta distribution
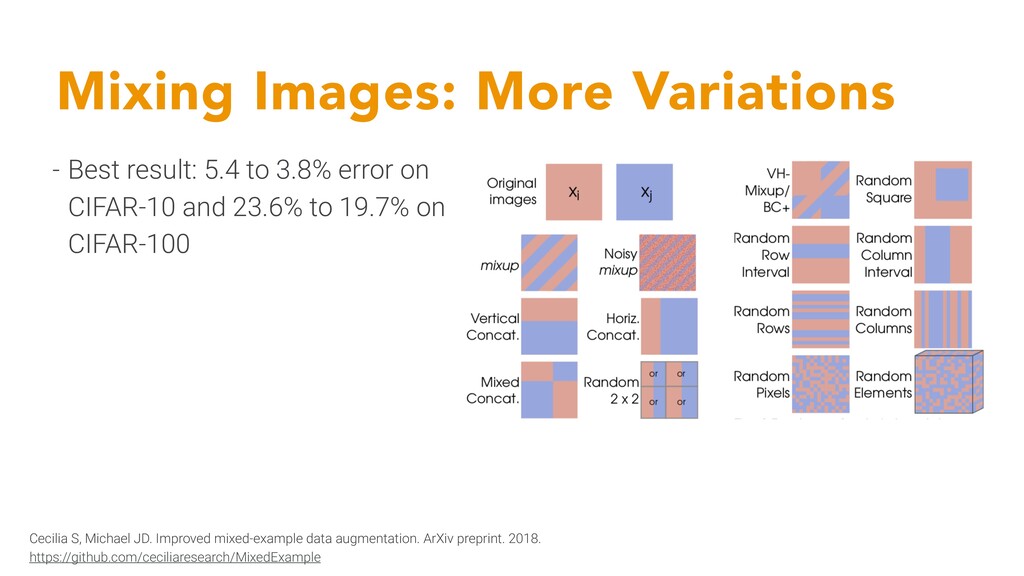
error on CIFAR-10 and 23.6% to 19.7% on CIFAR-100 Cecilia S, Michael JD. Improved mixed-example data augmentation. ArXiv preprint. 2018. https://github.com/ceciliaresearch/MixedExample
error on CIFAR-10 and 23.6% to 19.7% on CIFAR-100 Cecilia S, Michael JD. Improved mixed-example data augmentation. ArXiv preprint. 2018. https://github.com/ceciliaresearch/MixedExample
input data - Designed to handle occlusion -> where some parts of the object are unclear - Forcing the model to learn more descriptive features - Also forces the model to pay attention the entire image Zhun Z, Liang Z, Guoliang K, Shaozi L, Yi Y. Random erasing data augmentation. ArXiv e-prints. 2017.
to be random values. - Params: the fill method and size of the masks Zhun Z, Liang Z, Guoliang K, Shaozi L, Yi Y. Random erasing data augmentation. ArXiv e-prints. 2017.
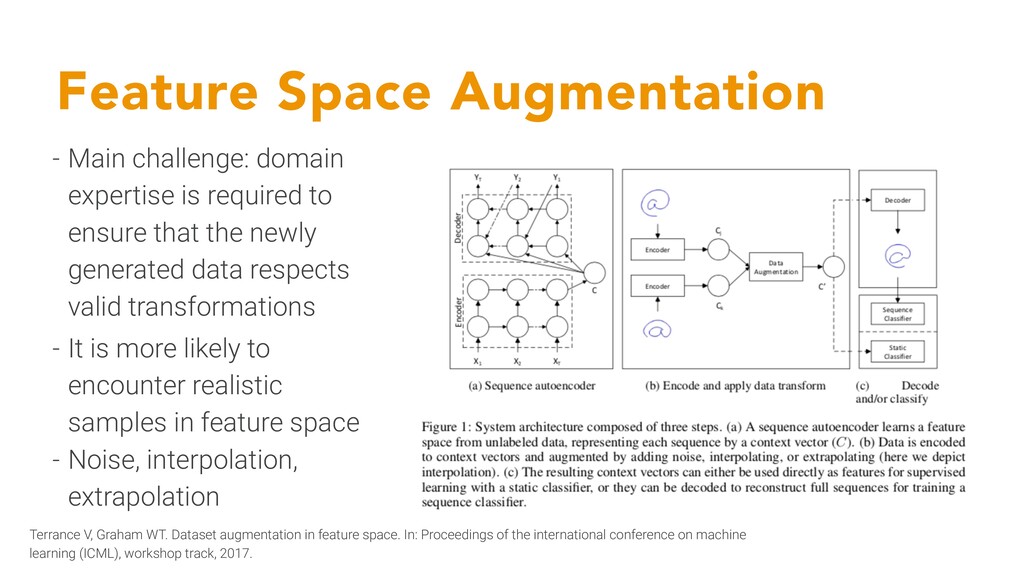
feature space. In: Proceedings of the international conference on machine learning (ICML), workshop track, 2017. - Main challenge: domain expertise is required to ensure that the newly generated data respects valid transformations - It is more likely to encounter realistic samples in feature space - Noise, interpolation, extrapolation
Yong Jae Lee. MixNMatch: Multifactor Disentanglement and Encoding for Conditional Image Generation. ArXiv preprint. 2019. - Built upon FineGAN - Requires bounding boxes for training
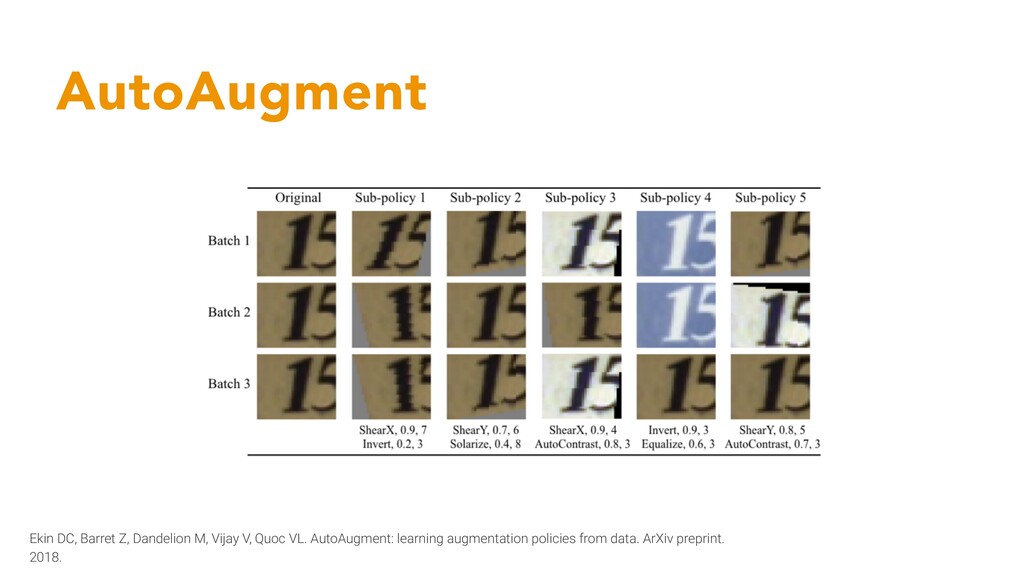
dataset with Reinforcement Learning - Search space of all possible transformations is huge: - A policy consists of 5 sub-policies - Each sub-policy applies 2 image operations in sequence - Each of those image operations has two parameters: The probability of applying it and the magnitude of the operation (e.g. rotate 30 degrees in 70% of cases). Ekin DC, Barret Z, Dandelion M, Vijay V, Quoc VL. AutoAugment: learning augmentation policies from data. ArXiv preprint. 2018.
when transferred to the Stanford Cars and FGVC Aircraft image recognition tasks. Ekin DC, Barret Z, Dandelion M, Vijay V, Quoc VL. AutoAugment: learning augmentation policies from data. ArXiv preprint. 2018.
- Difficult & time-consuming to implement (it takes $37,500 to discover the best policies for ImageNet) :/ - Follow up: Population Based Augmentation (2019) https:// bair.berkeley.edu/blog/2019/06/07/data_aug/ Ekin DC, Barret Z, Dandelion M, Vijay V, Quoc VL. AutoAugment: learning augmentation policies from data. ArXiv preprint. 2018.
of data augmentation alternatives beyond cropping & rotating - Data augmentation is not a silver bullet - e.g. if you’re trying to classify dogs but you only have bulldogs and no instances of golden retrievers, no method is going to automagically create golden retrievers for you
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}