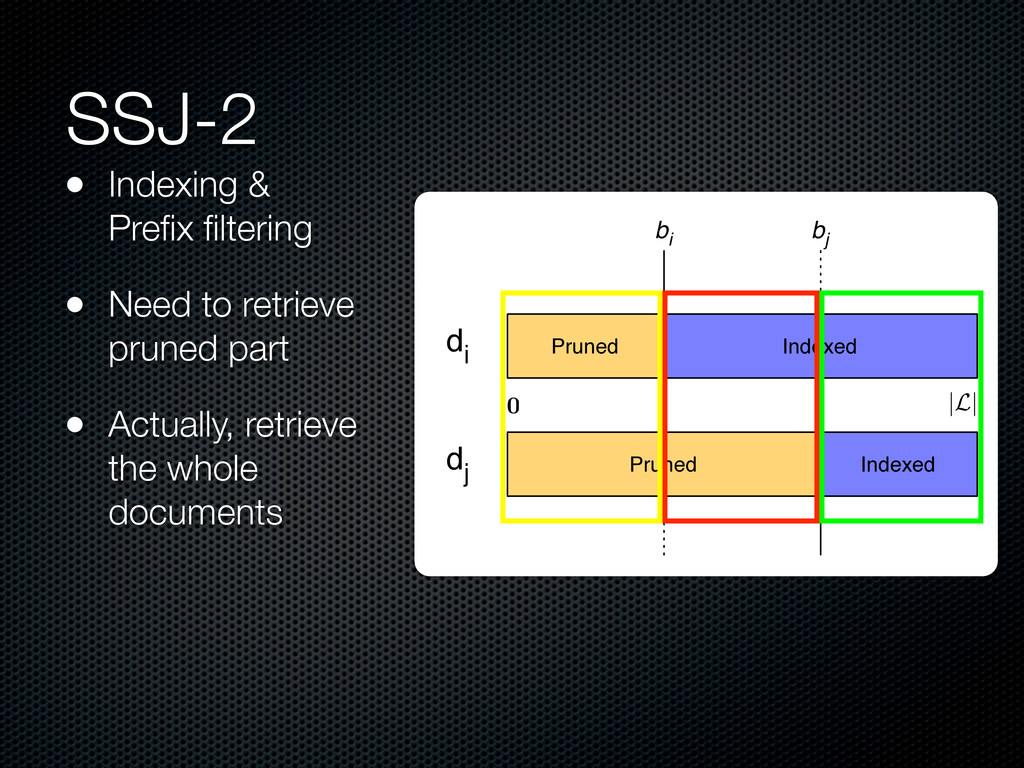
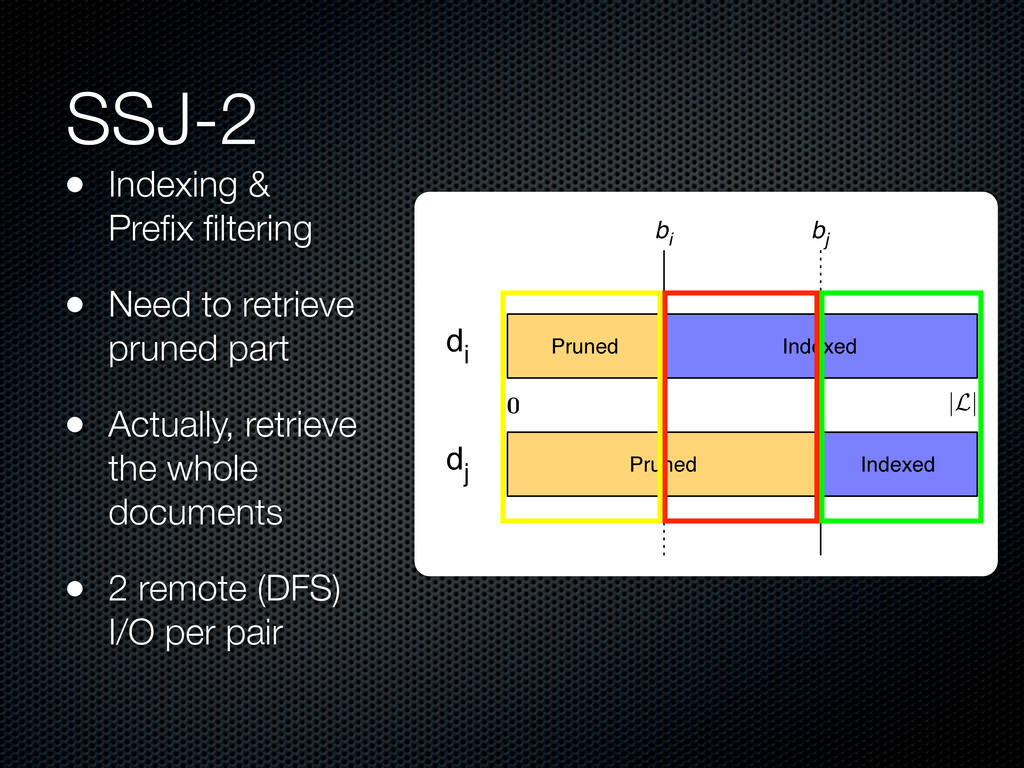
,1)]> <D, [(d2 ,2)]> <B, (d1 ,1)> <C, (d1 ,1)> <D, (d2 ,2)> <B, (d3 ,2)> <C, (d3 ,1)> map d1 "A A B C" map d2 "B D D" map d3 "A B B C" <B, [(d1 ,1), (d3 ,2)]> <C, [(d1 ,1), (d3 ,1)]> <D, [(d2 ,2)]> reduce reduce reduce Indexing shuffle <(d1 ,d3 ), 2> <(d1 ,d3 ), 1> <(d1 ,!),"A A B C"> <(d1 ,d3 ), 2> <(d1 ,d3 ), 1> reduce <(d1 ,d3 ), 5> Similarity map map map map Remainder File d1 "A A" d3 "A" d2 "B" Distributed Cache <(d1 ,!), "A A B C"> <(d3 ,!), "A B B C"> shuffle <B, [(d1 ,1), (d3 ,2)]> <C, [(d1 ,1), (d3 ,1)]> <D, [(d2 ,2)]> <B, (d1 ,1)> <C, (d1 ,1)> <D, (d2 ,2)> <B, (d3 ,2)> <C, (d3 ,1)> map d1 "A A B C" map d2 "B D D" map d3 "A B B C" <B, [(d1 ,1), (d3 ,2)]> <C, [(d1 ,1), (d3 ,1)]> <D, [(d2 ,2)]> reduce reduce reduce Indexing shuffle <(d1 ,d3 ), 2> <(d1 ,d3 ), 1> <(d1 ,!),"A A B C"> <(d1 ,d3 ), 2> <(d1 ,d3 ), 1> reduce <(d1 ,d3 ), 5> Similarity map map map map Remainder File d1 "A A" d3 "A" d2 "B" Distributed Cache <(d1 ,!), "A A B C"> <(d3 ,!), "A B B C"> SSJ-2R Example
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![(d0 ,d1 ),[w1 ,w2 ,w3 ...] (d0 ,d3 ),[w1 ,w2](https://files.speakerdeck.com/presentations/5032966c8bc57e000205d99a/slide_20.jpg){kind=link}
![(d0 ,d1 ),[w1 ,w2 ,w3 ...] (d0 ,d3 ),[w1 ,w2](https://files.speakerdeck.com/presentations/5032966c8bc57e000205d99a/slide_21.jpg){kind=link}
![(d0 ,d1 ),[w1 ,w2 ,w3 ...] (d0 ,d3 ),[w1 ,w2](https://files.speakerdeck.com/presentations/5032966c8bc57e000205d99a/slide_22.jpg){kind=link}
![shuffle <B, [(d1 ,1), (d3 ,2)]> <C, [(d1 ,1), (d3](https://files.speakerdeck.com/presentations/5032966c8bc57e000205d99a/slide_23.jpg){kind=link}
![shuffle <B, [(d1 ,1), (d3 ,2)]> <C, [(d1 ,1), (d3](https://files.speakerdeck.com/presentations/5032966c8bc57e000205d99a/slide_24.jpg){kind=link}
![shuffle <B, [(d1 ,1), (d3 ,2)]> <C, [(d1 ,1), (d3](https://files.speakerdeck.com/presentations/5032966c8bc57e000205d99a/slide_25.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}