open questions, etc..) Increase the engagement of the user with the platform Effectiveness of the system depends on: Relevance (consumer) Exposure (producer)
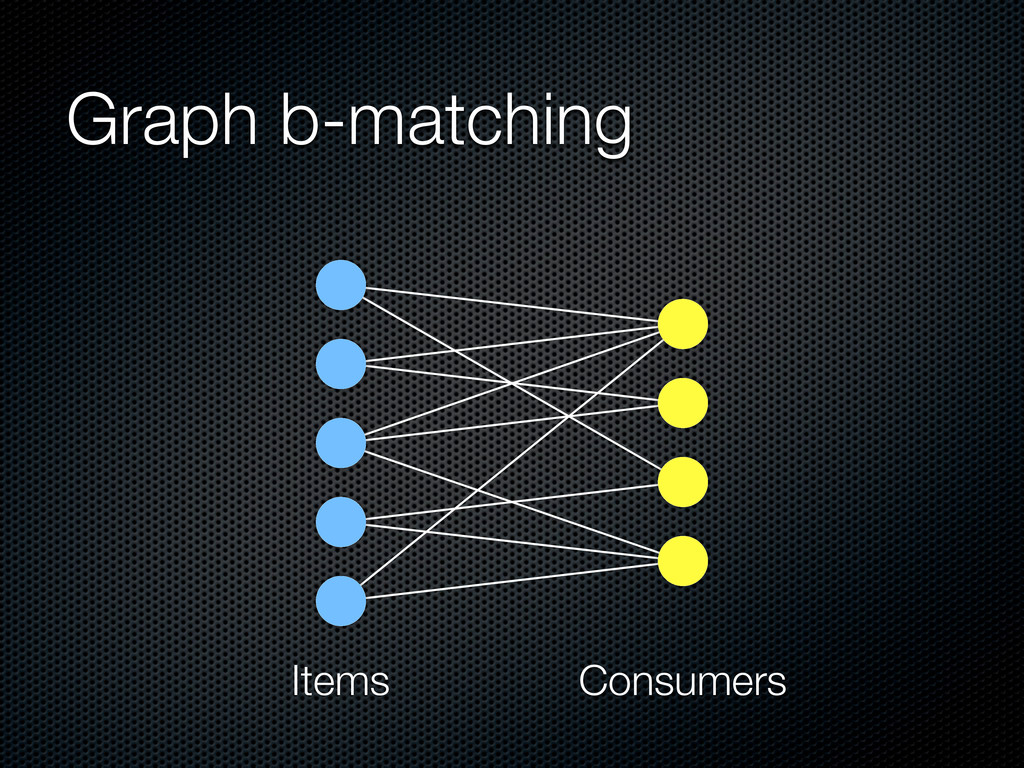
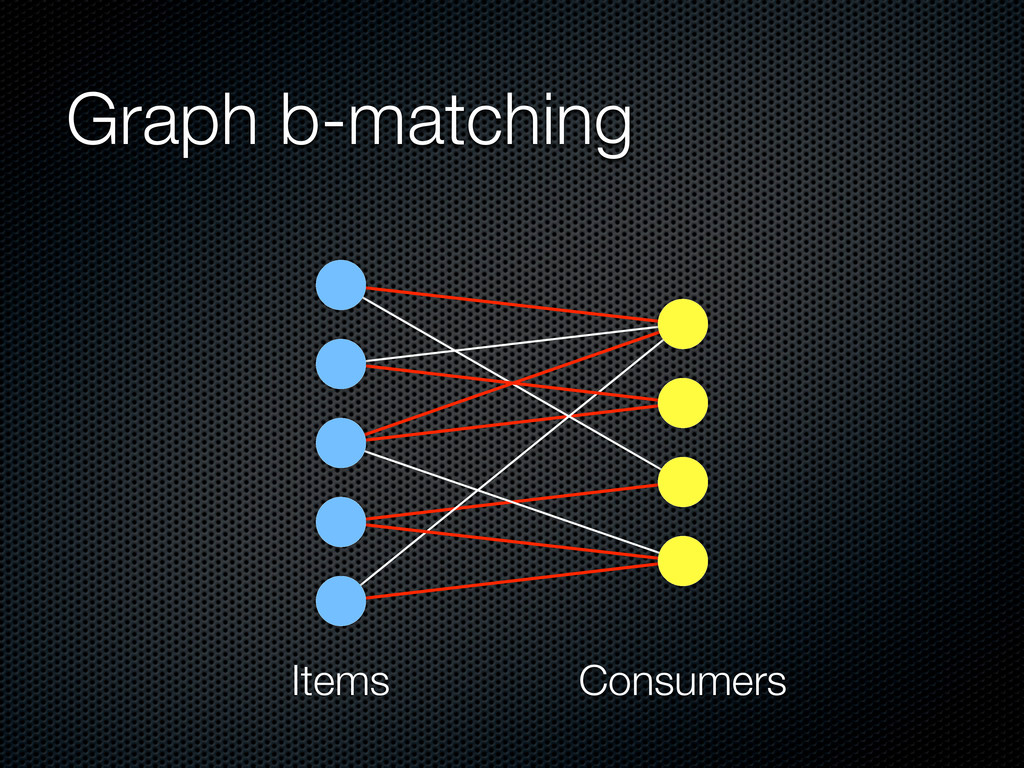
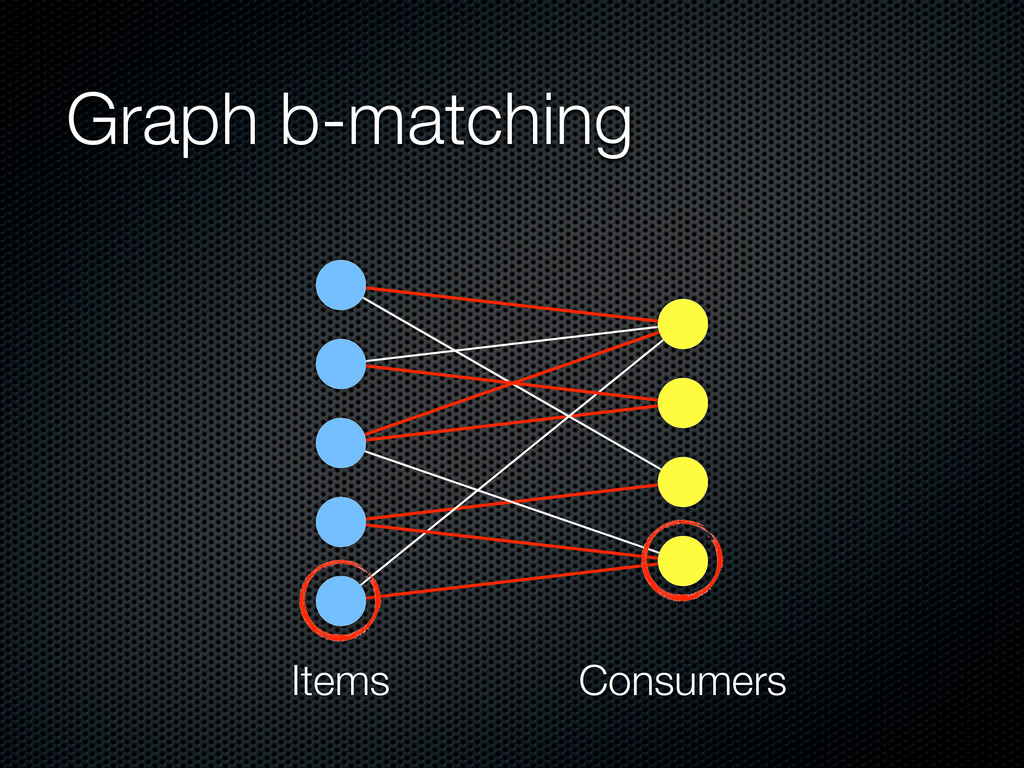
bipartite graph, weights w(ti, cj), capacity constraints b(ti) and b(cj) The goal is to find a matching M = {(t, c)} such that: (i) |M(ti )| ≤ b(ti ) (ii) |M(cj )| ≤ b(cj ) (iii) the total value w(M) of the matching is maximized
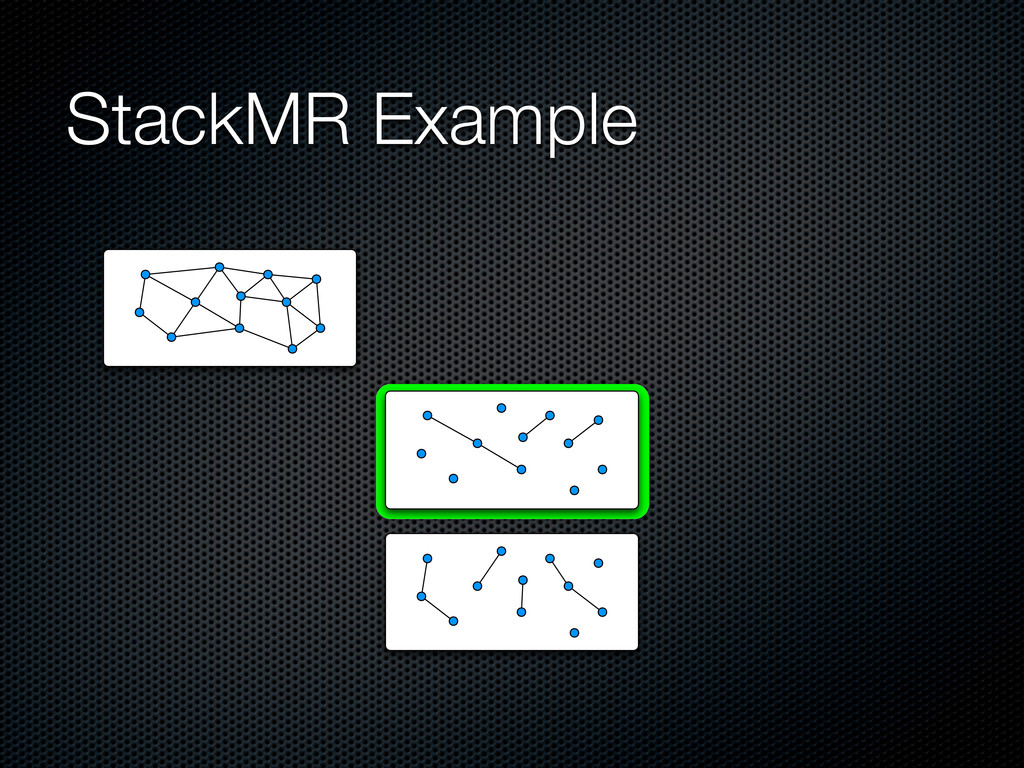
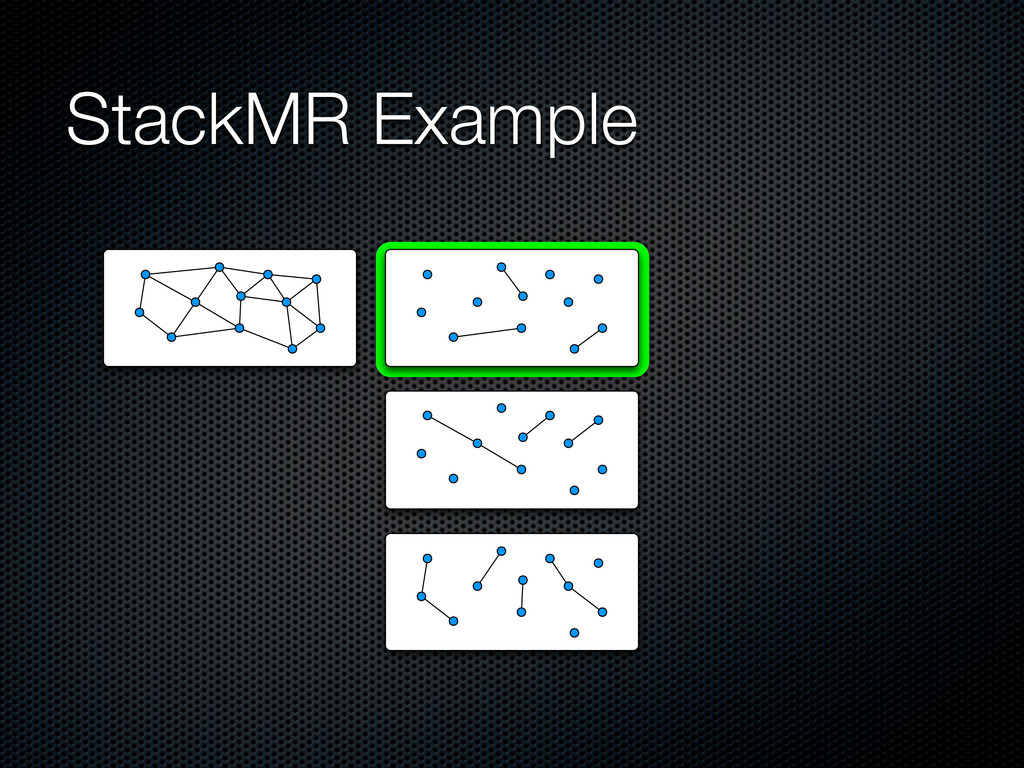
content distribution Devise a fully-MapReduce framework to address it StackMR GreedyMR Use SSJ-2R to build the graph Large scale experiments with real-world datasets
in the range from hours to days) Before the beginning of the ith phase, the application makes a tentative allocation of items to users Capacity constraints User: an estimate of the number of logins during the ith phase Items: proportional to a quality assessment or constant B = c∈C b(c) = t∈T b(t)
vector representations of the item and the consumer w(ti, cj) = v(ti ) · v(cj) Prune the candidate edges O(|T||C|) by discarding low weight edges (we want to maximize the total weight) Similarity join between T and C in MapReduce
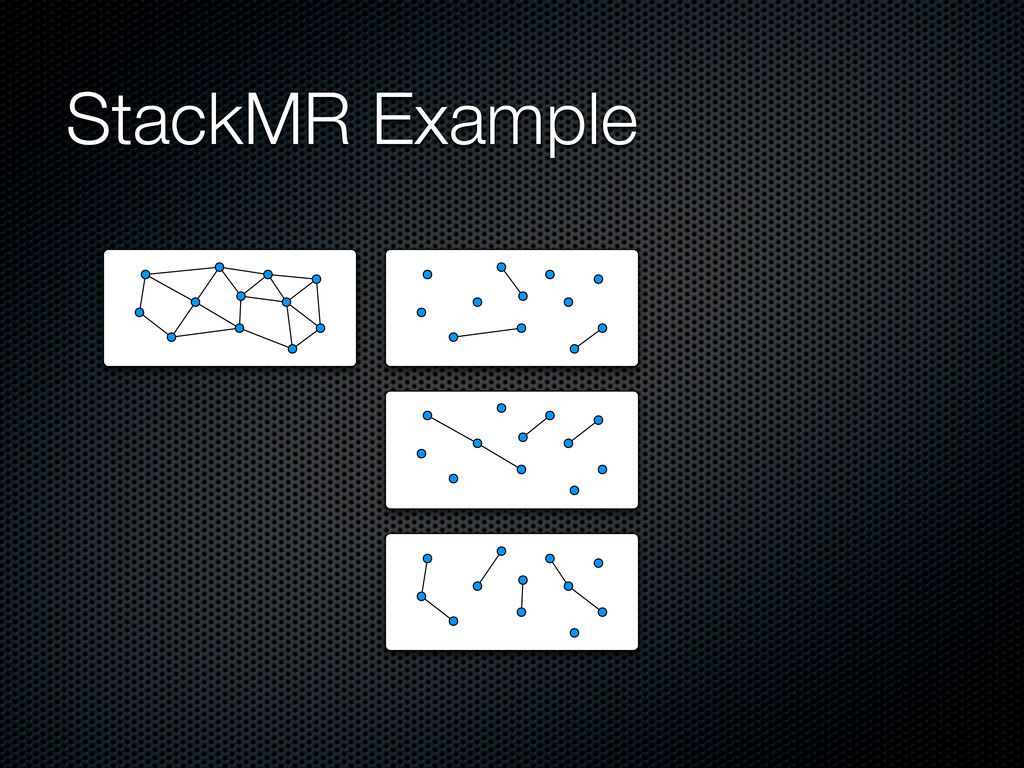
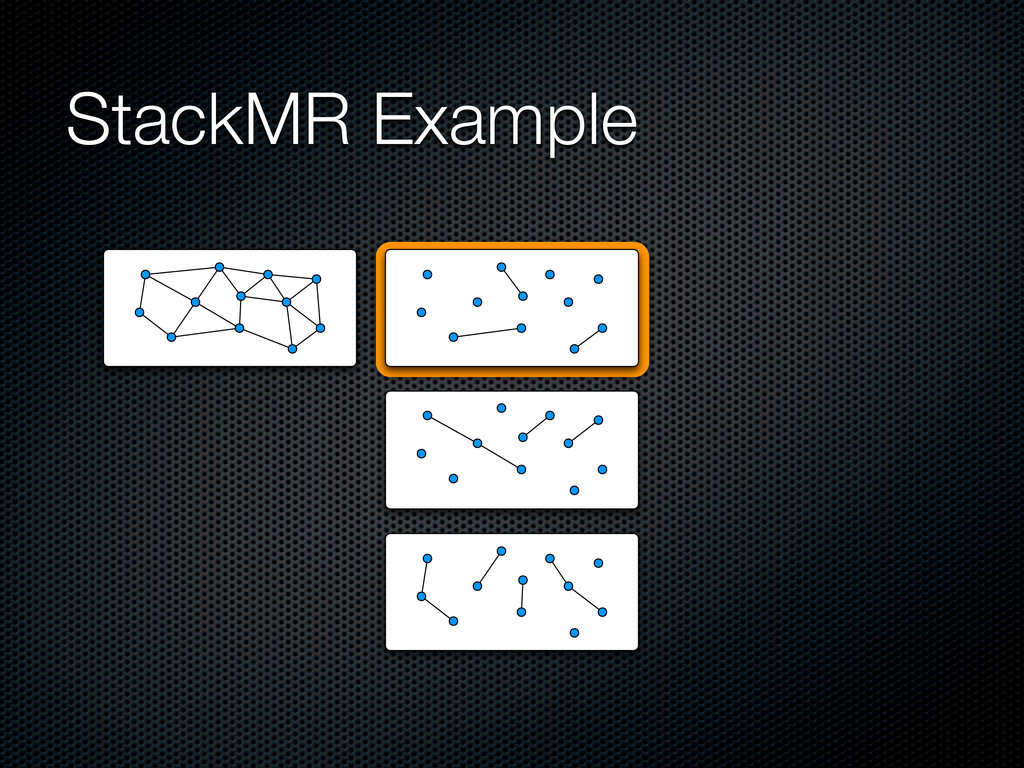
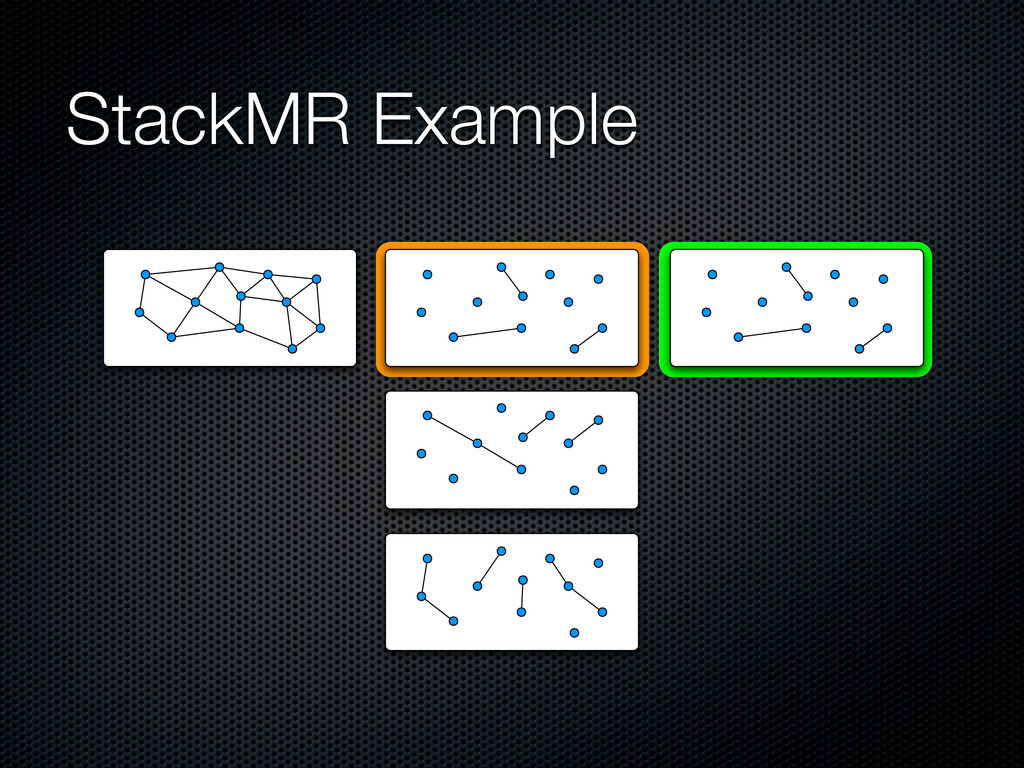
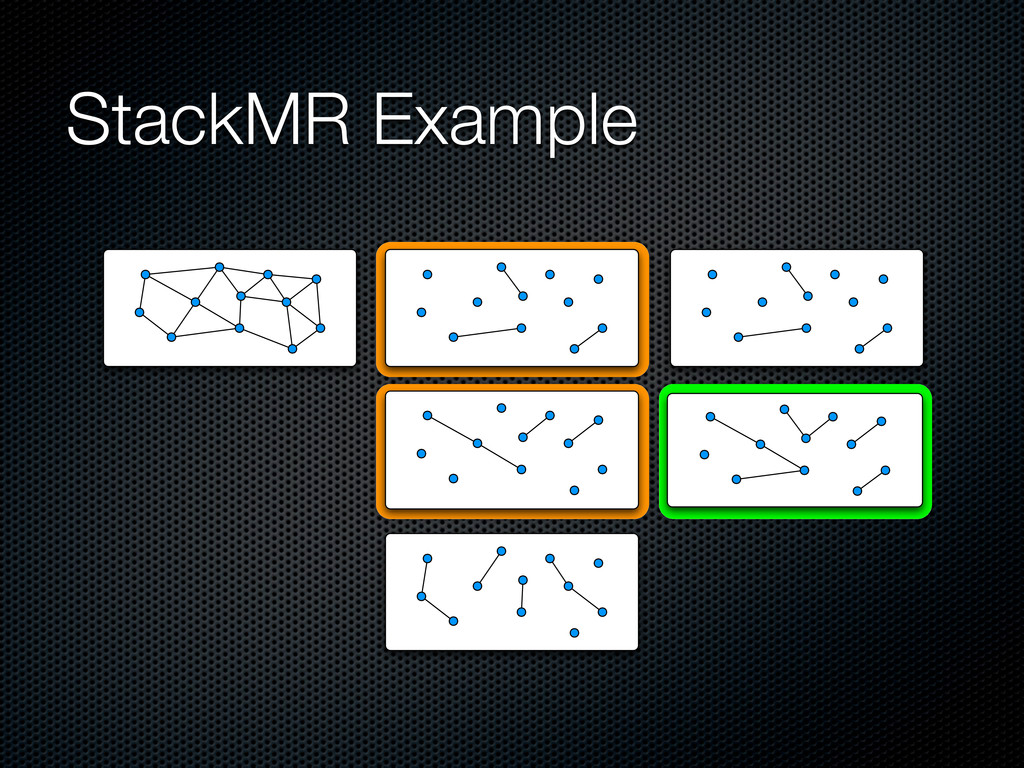
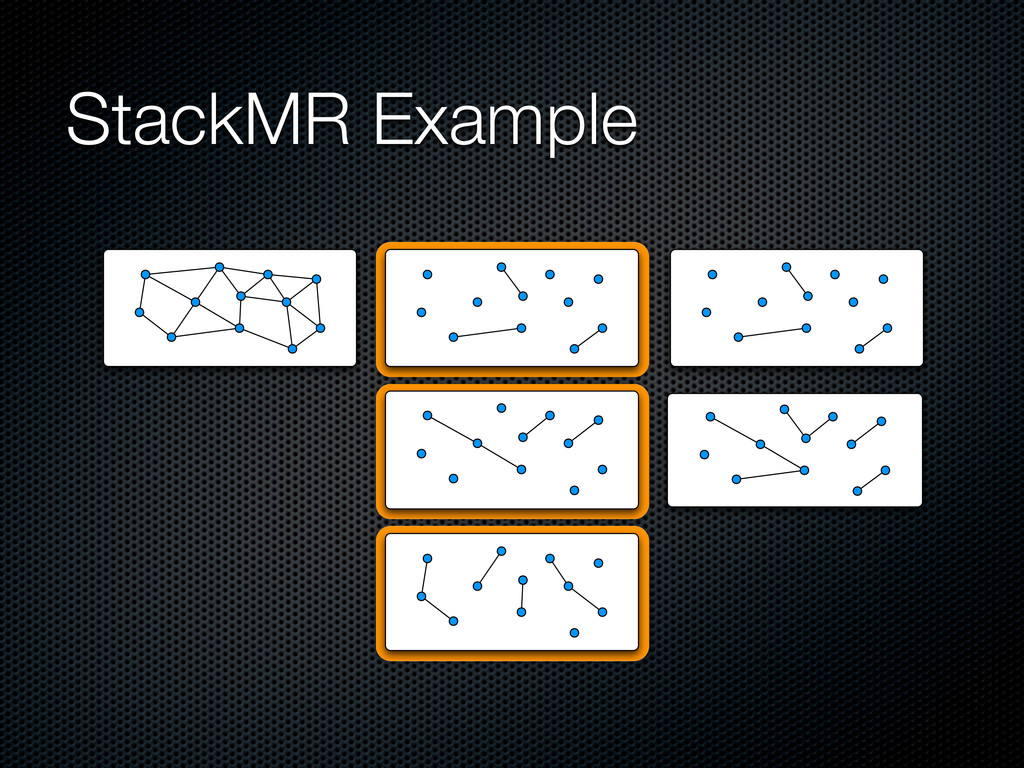
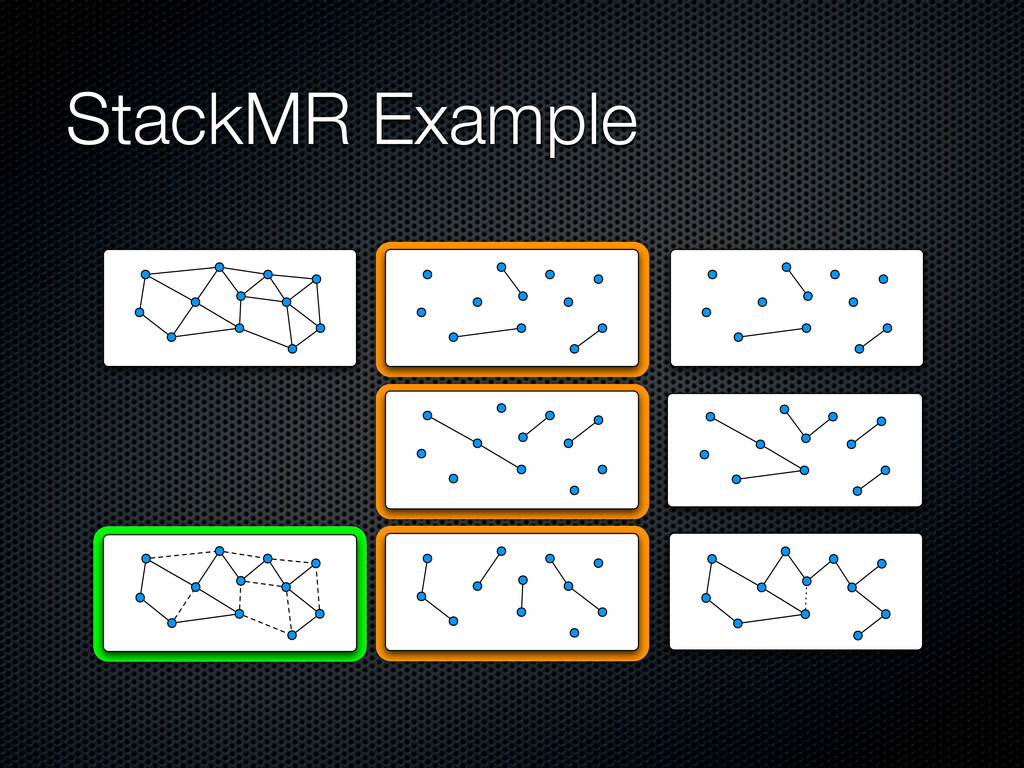
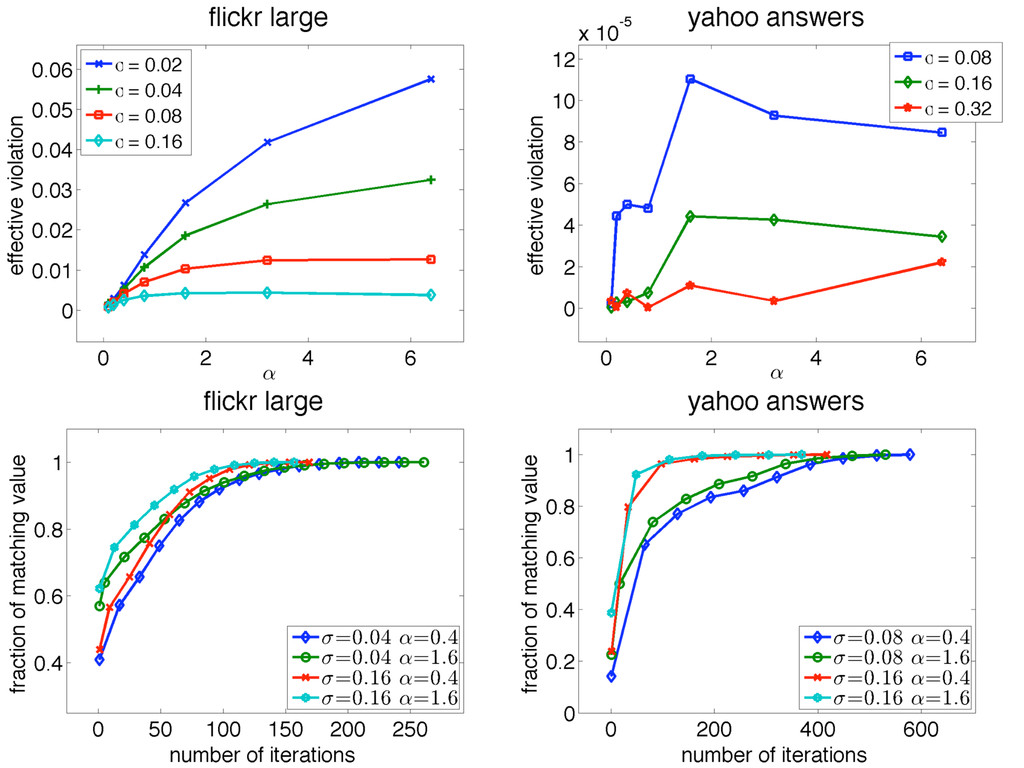
a maximal ⌈㸜C⌉-matching in parallel Push it in the stack, update dual variables and remove covered edges When there are no more edges, pop the whole stack and include edges in the solution layer by layer For efficiency, allows (1+∊) violations on capacity constraints
the edges by weight, include the current edge if it maintains the constraints and update the capacities) At each round, each node proposes its top weighting b(v) edges to its neighbors The intersection between the proposal of each node and the ones of its neighbors is included in the solution Capacities are updated in parallel Yields a feasible sub-optimal solution at each round
heuristic in one of the randomized phases, when choosing the edges to propose We tried also with a proportional heuristic, but the results were always worse than with the greedy one Mixed results overall
in all photos flickr items (photos): set of tags Y! Answers users: set of words used in all answers Y! Answers items (questions): set of words Y! Answers: stopword removal, stemming, tf-idf
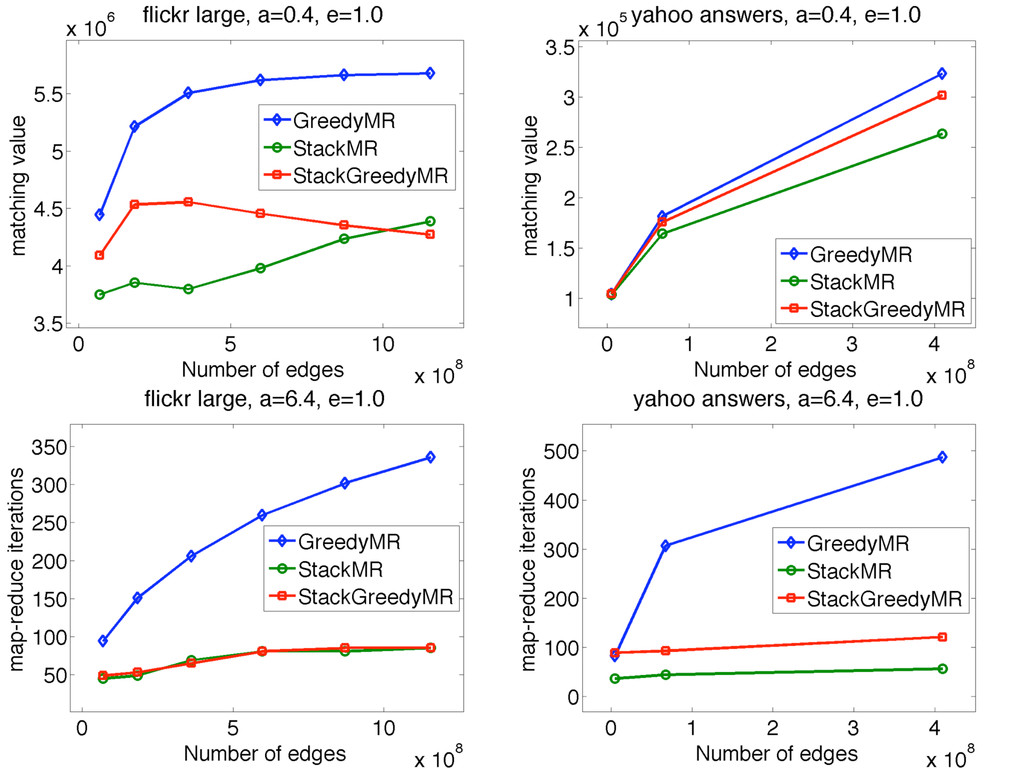
and efficiency StackMR scales to very large datasets, has provable poly-logarithmic complexity and is faster in practice, capacity violations are negligible GreedyMR yields higher quality results, has ½ approximation and can be stopped at any time
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}