Evolutionary Signal Processing & Informatics Lab Department of Electrical & Computer Engineering Philadelphia, PA, USA [email protected] http://github.com/gditzler/eces436-proteus April 29, 2014 Gregory Ditzler Introduction to Feature Selection
selection? Examples? Algorithms for subset selection: wrapper, embedded and filter methods. How should I evaluate a subset selection algorithm? What does the current research look like? Time Permitting: Proteus examples (not feature selection related) Gregory Ditzler Introduction to Feature Selection
outcome? Bacterial abundance profiles are collected from IBD and healthy patients. What are the bacteria that best differentiate between the two populations? Observations of a variable are not free. Which variables should I “pay” for, possibly in the future, to build a classifier? Gregory Ditzler Introduction to Feature Selection
ever increasing number of applications that generate high dimensional data! Biometric authentication Pharmaceutical industries Systems biology Cancer diagnosis Metagenomics Gregory Ditzler Introduction to Feature Selection
we learn a function to classify feature vectors from labeled training data. x: feature vector made up of variables X := {X1 , X2 , . . . , XK } y: label to a feature vector (e.g., y ∈ {+1, −1}) D: data set X = [x1 , x2 , . . . , xN ]T , y = [y1 , y2 , . . . , yN ]T Gregory Ditzler Introduction to Feature Selection
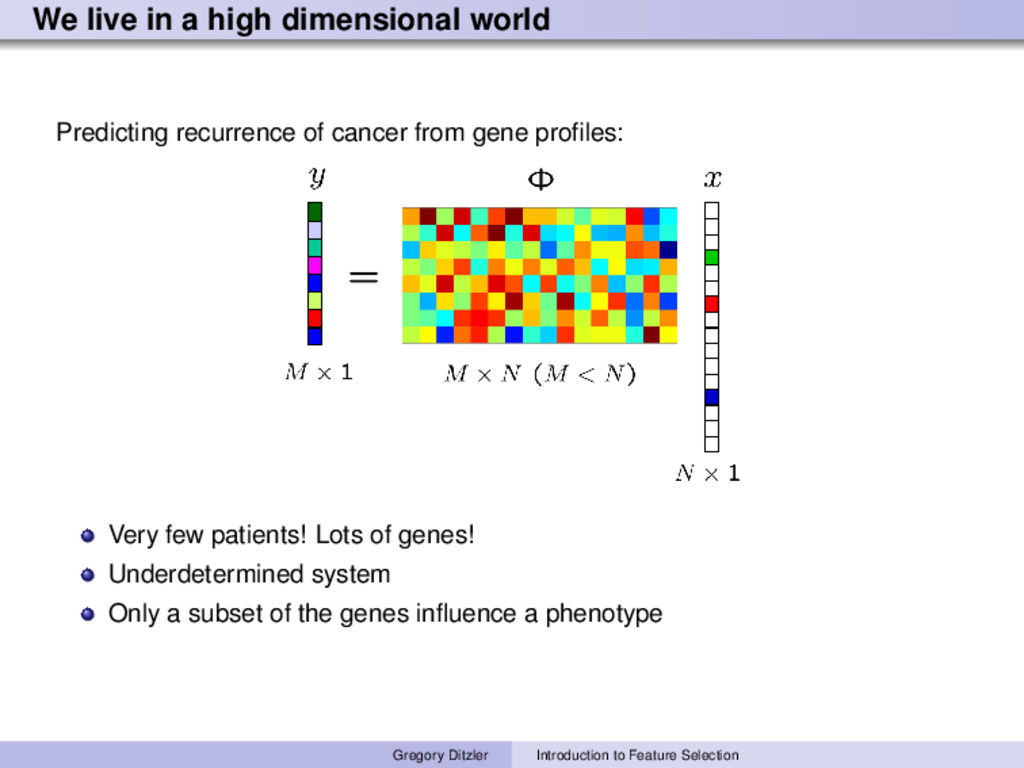
cancer from gene profiles: Very few patients! Lots of genes! Underdetermined system Only a subset of the genes influence a phenotype Gregory Ditzler Introduction to Feature Selection
team at Google presented a methods of parallelized coordinate using Nesterov’s accelerated gradient descent. BOOM was intended to used for large-scale learning setting The authors used two synthetic data sets Data set 1: 7.964B and 80.435M examples in the train and test sets, and 24.343M features Data set 2: 5.243B and 197.321M examples in the train and test sets, and 712.525M features Gregory Ditzler Introduction to Feature Selection
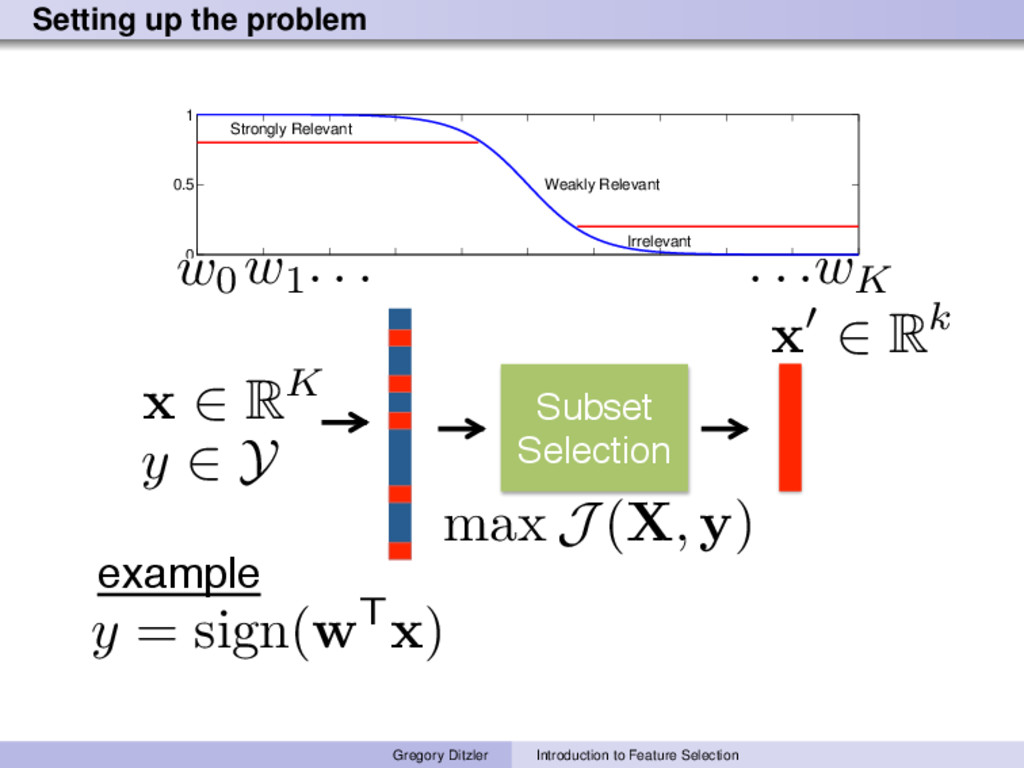
improve accuracy of a classification or regression function. Subset selection does not always improve the accuracy of a classifier. Can you think of an example or reason why? Complexity of many machine learning algorithms scales with the number of features. Fewer features → lower complexity. Consider a classification algorithm who’s complexity is o( √ ND2). If you can work with D/50 features, then we have o( √ N(D/50)2) as the final complexity. Reduce cost of future measurements Improved data/model understanding Gregory Ditzler Introduction to Feature Selection
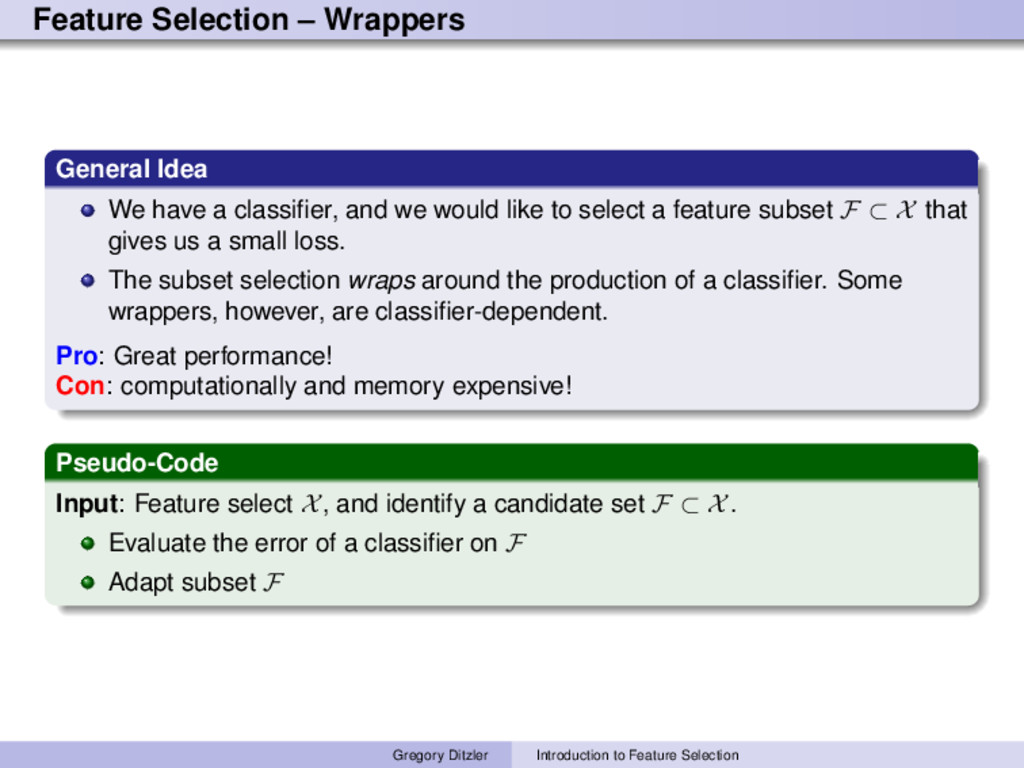
and we would like to select a feature subset F ⊂ X that gives us a small loss. The subset selection wraps around the production of a classifier. Some wrappers, however, are classifier-dependent. Pro: Great performance! Con: computationally and memory expensive! Pseudo-Code Input: Feature select X, and identify a candidate set F ⊂ X. Evaluate the error of a classifier on F Adapt subset F Gregory Ditzler Introduction to Feature Selection
selection project. . . Get Some Data Your friend goes out and collects data, D, for their project Select Some Features Using D, your friend tries many subsets F ⊂ X by adapting F based on the error. They return F that corresponds to the smallest classification error. Learning Procedure Make a new data set D with F features Repeat 50 times Split D into training & testing sets Train a classifier and record its error Report the error averaged over 50 trials Reflection Gregory Ditzler Introduction to Feature Selection
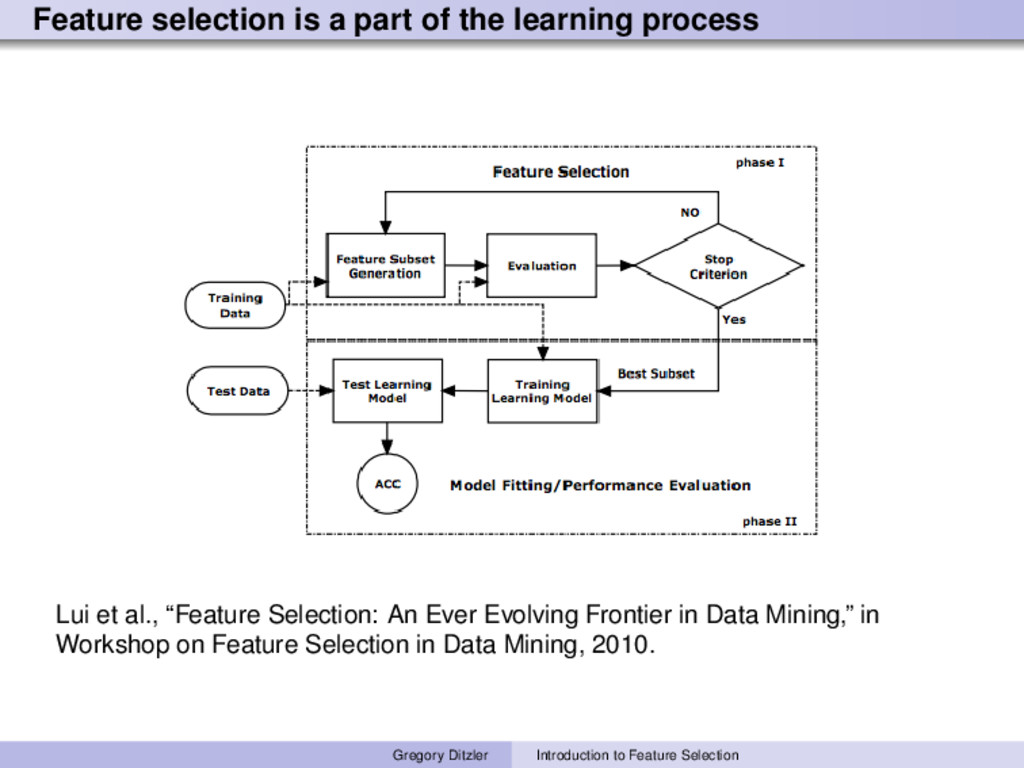
et al., “Feature Selection: An Ever Evolving Frontier in Data Mining,” in Workshop on Feature Selection in Data Mining, 2010. Gregory Ditzler Introduction to Feature Selection
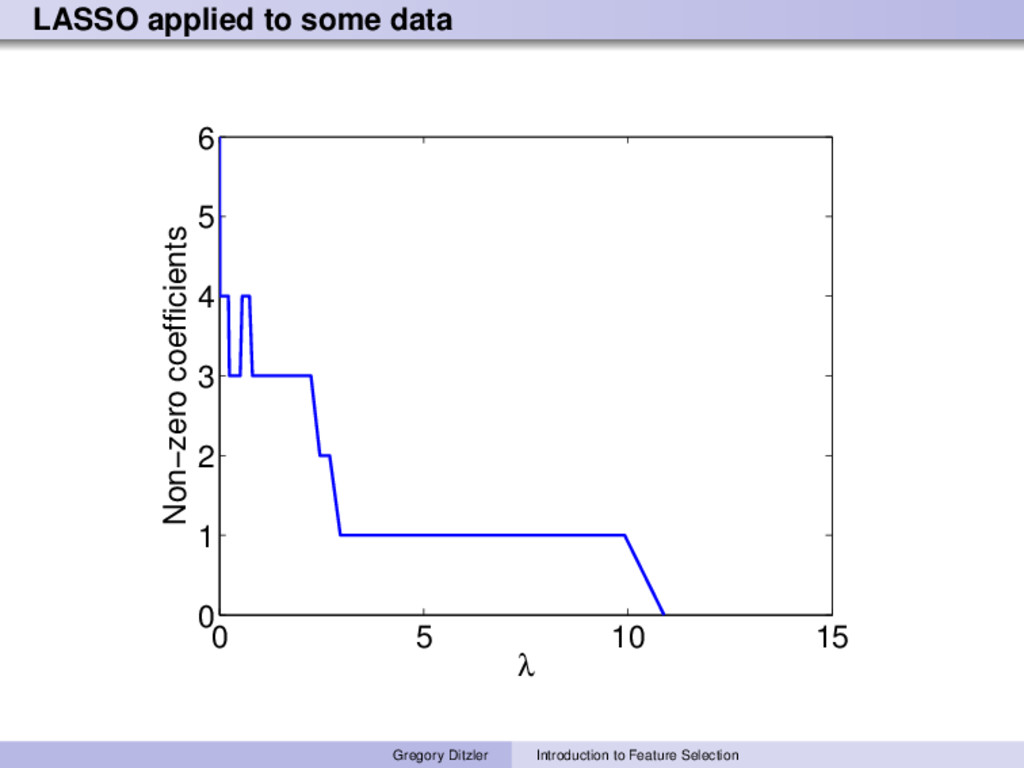
feature set around the classifier, whereas embedded methods optimize the classifier and feature selector jointly. Embedded methods are generally less prone to overfitting than a feature selection wrapper and they are generally have lower computational costs. During the machine learning lecture, was there any algorithm that performed feature selection? Examples Least absolute shrinkage and selection operator (LASSO) β∗ = arg min β∈RK 1 2N y − Xβ 2 2 + λ β 1 Elastic Nets β∗ = arg min β∈RK 1 2N y − Xβ 2 2 + 1 − α 2 β 2 2 + α β 1 Gregory Ditzler Introduction to Feature Selection
relied on a classifier to produce a feature scoring function, however, the classifier adds quite a bit of complexity. Filter subset selection algorithms score features and sets of features independent of a classifier. Examples χ2 statistics, information theory, and redundancy measures. Entropy: H(X) = − i p(Xi ) log P(Xi ) Mutual information I(X; Y) = H(X) − H(X|Y) Gregory Ditzler Introduction to Feature Selection
objective function J , k features to select, and initialize an empty set F 1 Maximize the objective function X∗ = arg max Xj∈X J (Xj , Y, F) 2 Update relevant feature set such that F ← F ∪ X∗ 3 Remove relevant feature from the original set X ← X\X∗ 4 Repeat until |F| = k Figure : Generic forward feature selection algorithm for a filter-based method. Gregory Ditzler Introduction to Feature Selection
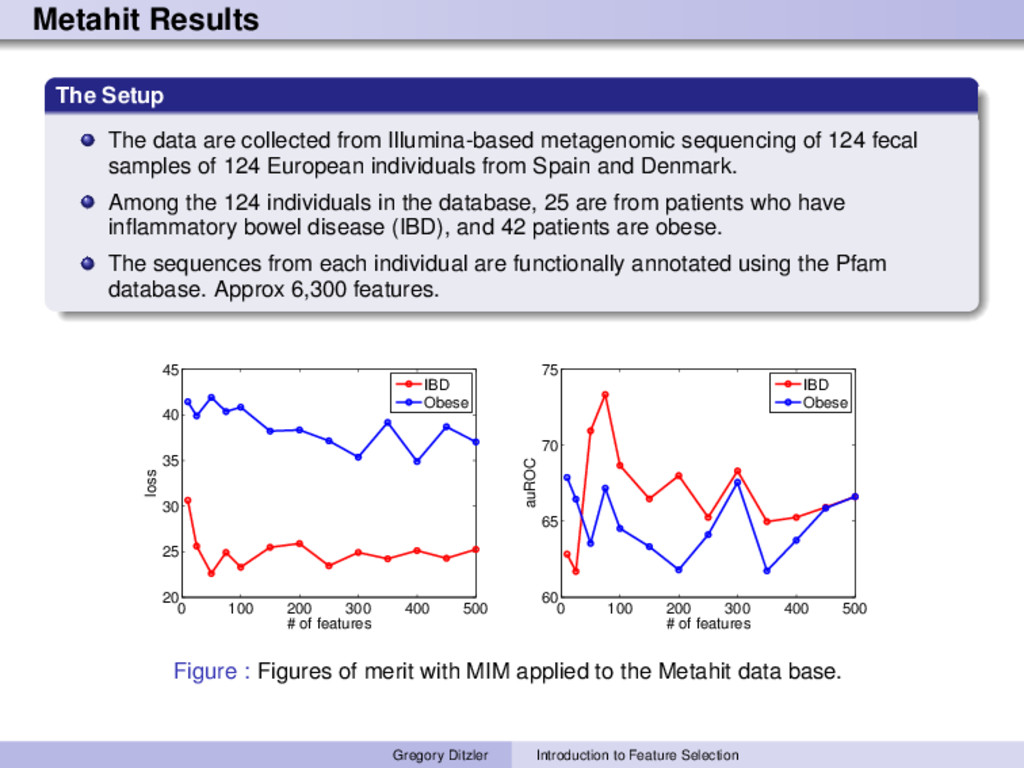
metagenomic sequencing of 124 fecal samples of 124 European individuals from Spain and Denmark. Among the 124 individuals in the database, 25 are from patients who have inflammatory bowel disease (IBD), and 42 patients are obese. The sequences from each individual are functionally annotated using the Pfam database. Approx 6,300 features. 0 100 200 300 400 500 20 25 30 35 40 45 # of features loss IBD Obese 0 100 200 300 400 500 60 65 70 75 # of features auROC IBD Obese Figure : Figures of merit with MIM applied to the Metahit data base. Gregory Ditzler Introduction to Feature Selection
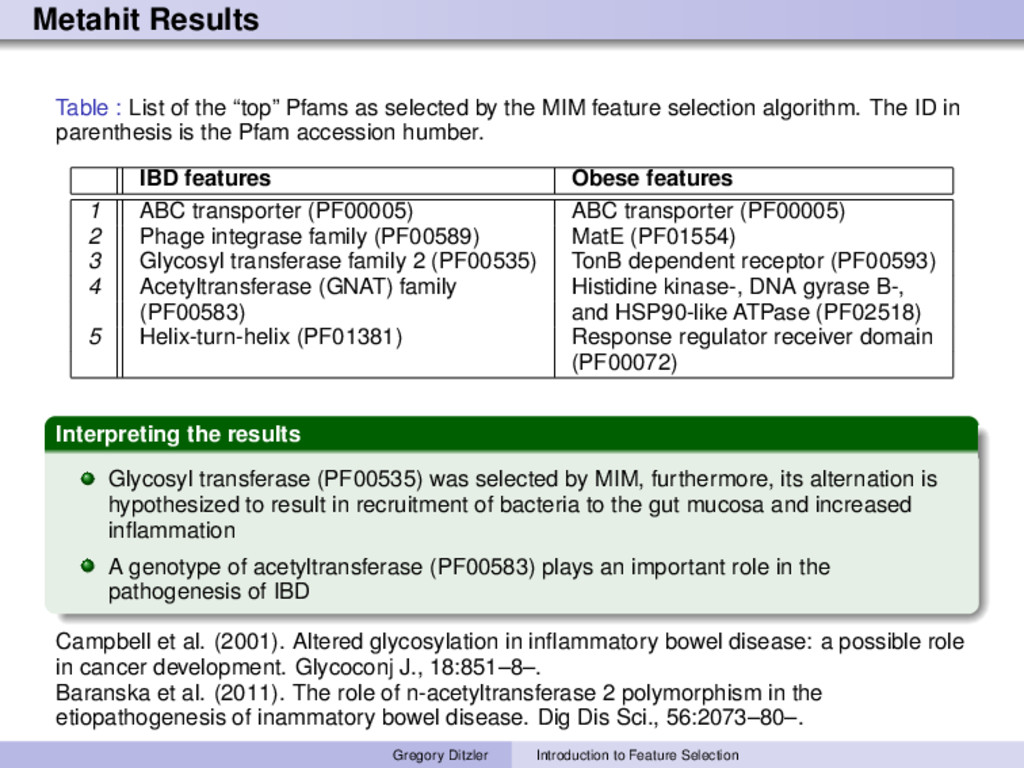
selected by the MIM feature selection algorithm. The ID in parenthesis is the Pfam accession humber. IBD features Obese features 1 ABC transporter (PF00005) ABC transporter (PF00005) 2 Phage integrase family (PF00589) MatE (PF01554) 3 Glycosyl transferase family 2 (PF00535) TonB dependent receptor (PF00593) 4 Acetyltransferase (GNAT) family Histidine kinase-, DNA gyrase B-, (PF00583) and HSP90-like ATPase (PF02518) 5 Helix-turn-helix (PF01381) Response regulator receiver domain (PF00072) Interpreting the results Glycosyl transferase (PF00535) was selected by MIM, furthermore, its alternation is hypothesized to result in recruitment of bacteria to the gut mucosa and increased inflammation A genotype of acetyltransferase (PF00583) plays an important role in the pathogenesis of IBD Campbell et al. (2001). Altered glycosylation in inflammatory bowel disease: a possible role in cancer development. Glycoconj J., 18:851–8–. Baranska et al. (2011). The role of n-acetyltransferase 2 polymorphism in the etiopathogenesis of inammatory bowel disease. Dig Dis Sci., 56:2073–80–. Gregory Ditzler Introduction to Feature Selection
= z|H0 ) = n z pz 1 (1 p1 )n z n z pz 0 (1 p0 )n z > ⇣crit Hypothesis Test Based on the Likelihood Ratio! H0 : p = p0 H1 : p > p0 Hypothesis Test! f1 f2 fK . . . . . . f3 Bootstrap! 1 2 3 4 n . . . Features! Chance ! p0 = k K X X1i = k X X2i = k X X3i = k X X4i = k X Xni = k {z}1 = X Xl1 {z}K = X XlK Gregory Ditzler Introduction to Feature Selection
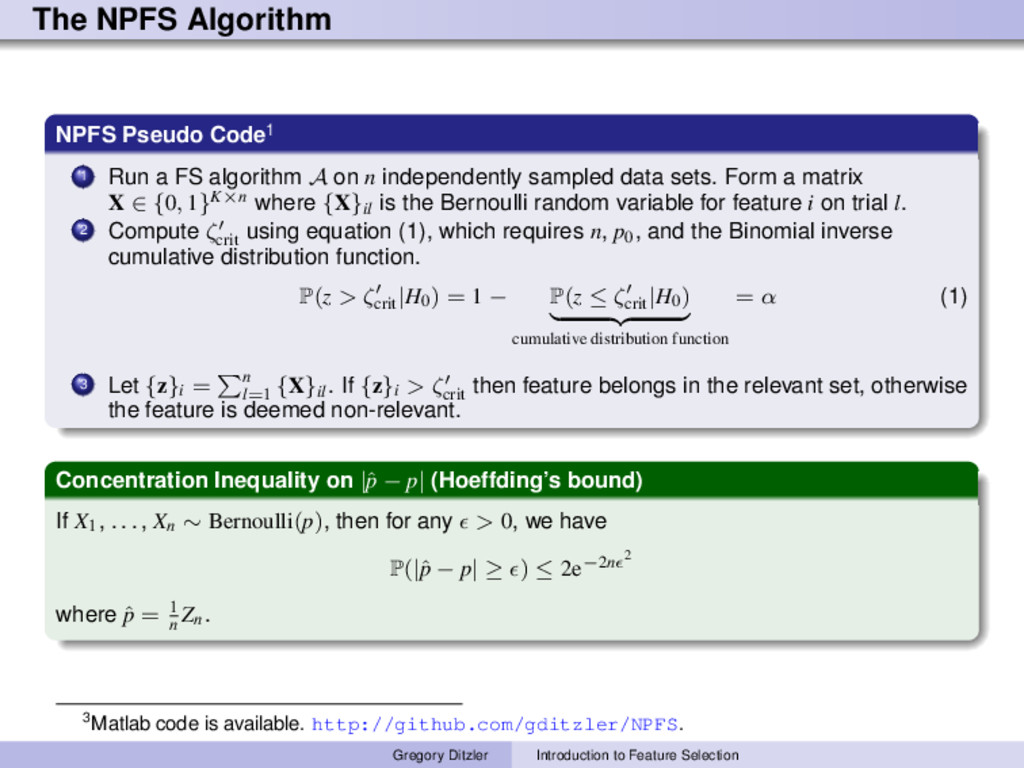
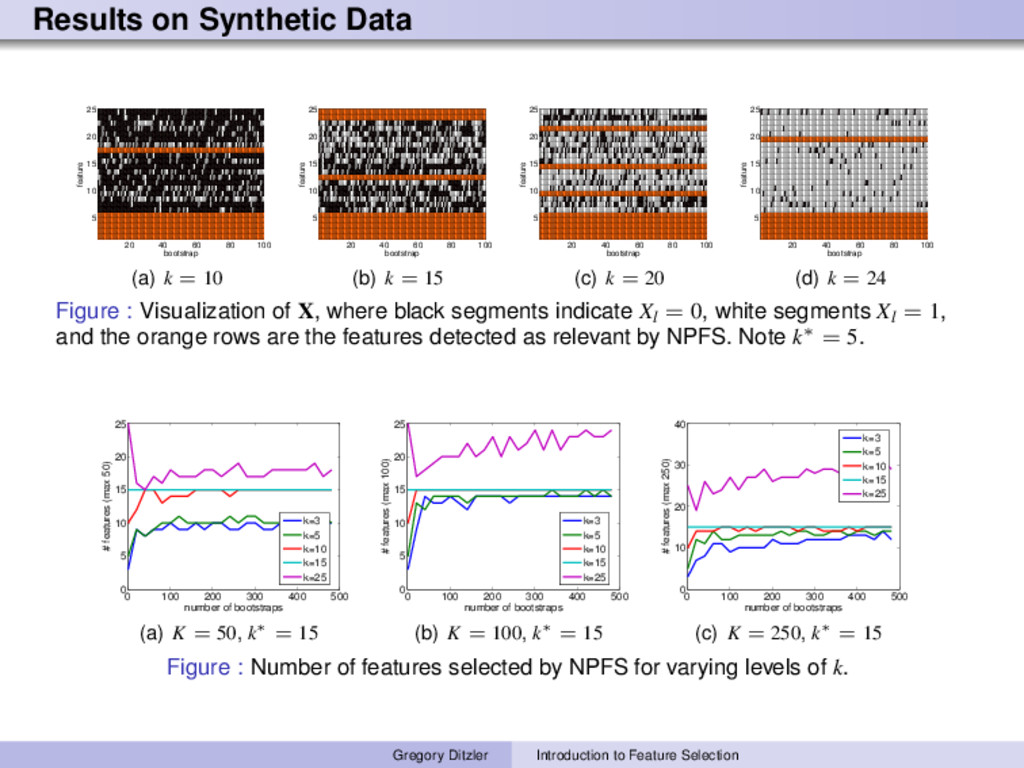
algorithm A on n independently sampled data sets. Form a matrix X ∈ {0, 1}K×n where {X}il is the Bernoulli random variable for feature i on trial l. 2 Compute ζ crit using equation (1), which requires n, p0 , and the Binomial inverse cumulative distribution function. P(z > ζcrit |H0) = 1 − P(z ≤ ζcrit |H0) cumulative distribution function = α (1) 3 Let {z}i = n l=1 {X}il . If {z}i > ζ crit then feature belongs in the relevant set, otherwise the feature is deemed non-relevant. Concentration Inequality on |ˆ p − p| (Hoeffding’s bound) If X1 , . . . , Xn ∼ Bernoulli(p), then for any > 0, we have P(|ˆ p − p| ≥ ) ≤ 2e−2n 2 where ˆ p = 1 n Zn. 3Matlab code is available. http://github.com/gditzler/NPFS. Gregory Ditzler Introduction to Feature Selection
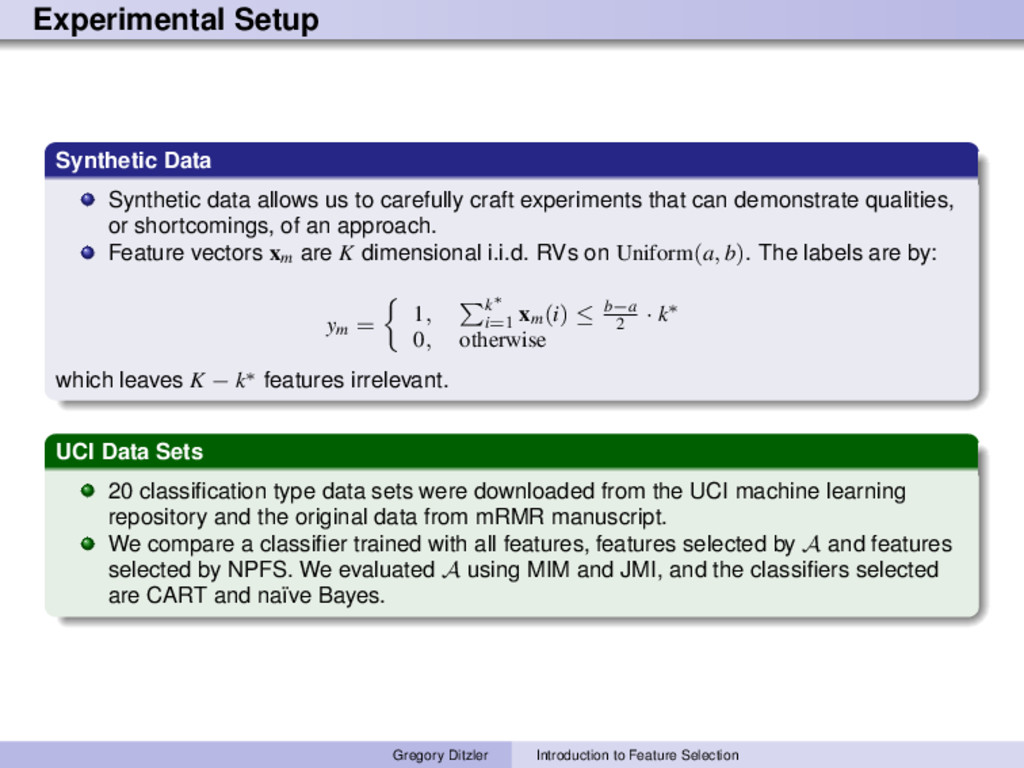
craft experiments that can demonstrate qualities, or shortcomings, of an approach. Feature vectors xm are K dimensional i.i.d. RVs on Uniform(a, b). The labels are by: ym = 1, k∗ i=1 xm(i) ≤ b−a 2 · k∗ 0, otherwise which leaves K − k∗ features irrelevant. UCI Data Sets 20 classification type data sets were downloaded from the UCI machine learning repository and the original data from mRMR manuscript. We compare a classifier trained with all features, features selected by A and features selected by NPFS. We evaluated A using MIM and JMI, and the classifiers selected are CART and na¨ ıve Bayes. Gregory Ditzler Introduction to Feature Selection
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}