Using Survival Analysis Isaksen et al., 2015 • Flappy Bird • 人間をモデル化したAI Human-Like Playtesting with Deep Learning Stefan Freyr et al., 2016 • Candy Crash • プレイヤの行動ログから学習させたAI Exploring Gameplay With AI Agents Mesentier Silva et al., 2018 • The Sims • A*アルゴリズムで探索するAI 背景:テストプレイAIによる効率化 4
with a Natural Language Action Space He et al., 2016 ゲームの強化学習効率化に関する先行研究 9 • テキストゲームの強化学習効率化 • 状態が自然言語で表される • 行動を自然言語で入力する • Deep Reinforcement Relevance Network (DRRN) • 状態だけでなく行動の意味も行動価値関数に入力 • 状態と行動をそれぞれ埋め込む あなたは川のそばにいます > 南へ行く 川は5cm程の隙間に流れ込んでいます > 隙間へ行く 隙間は狭すぎて入れません
{kind=link}
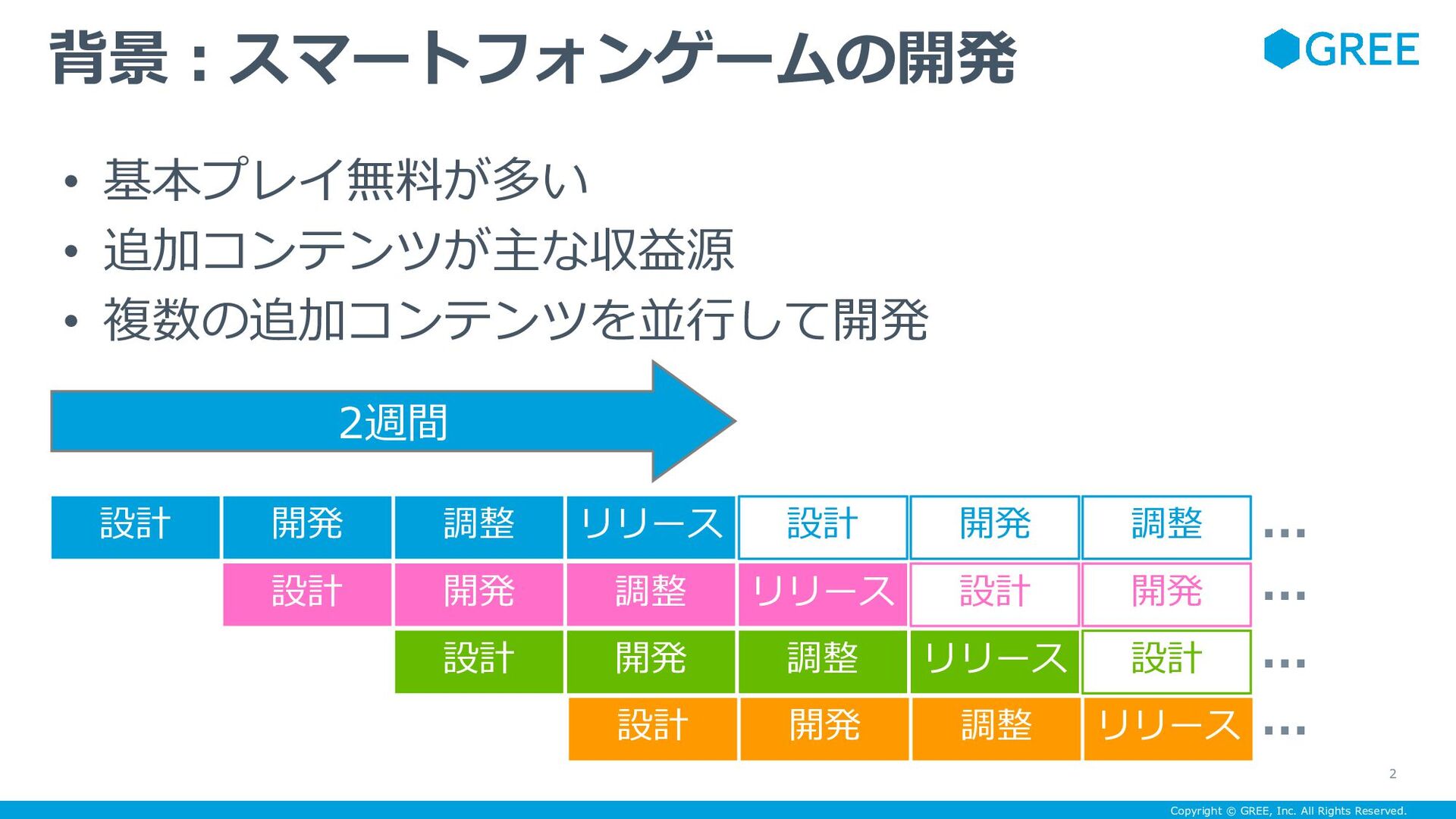{kind=link}
{kind=link}
{kind=link}
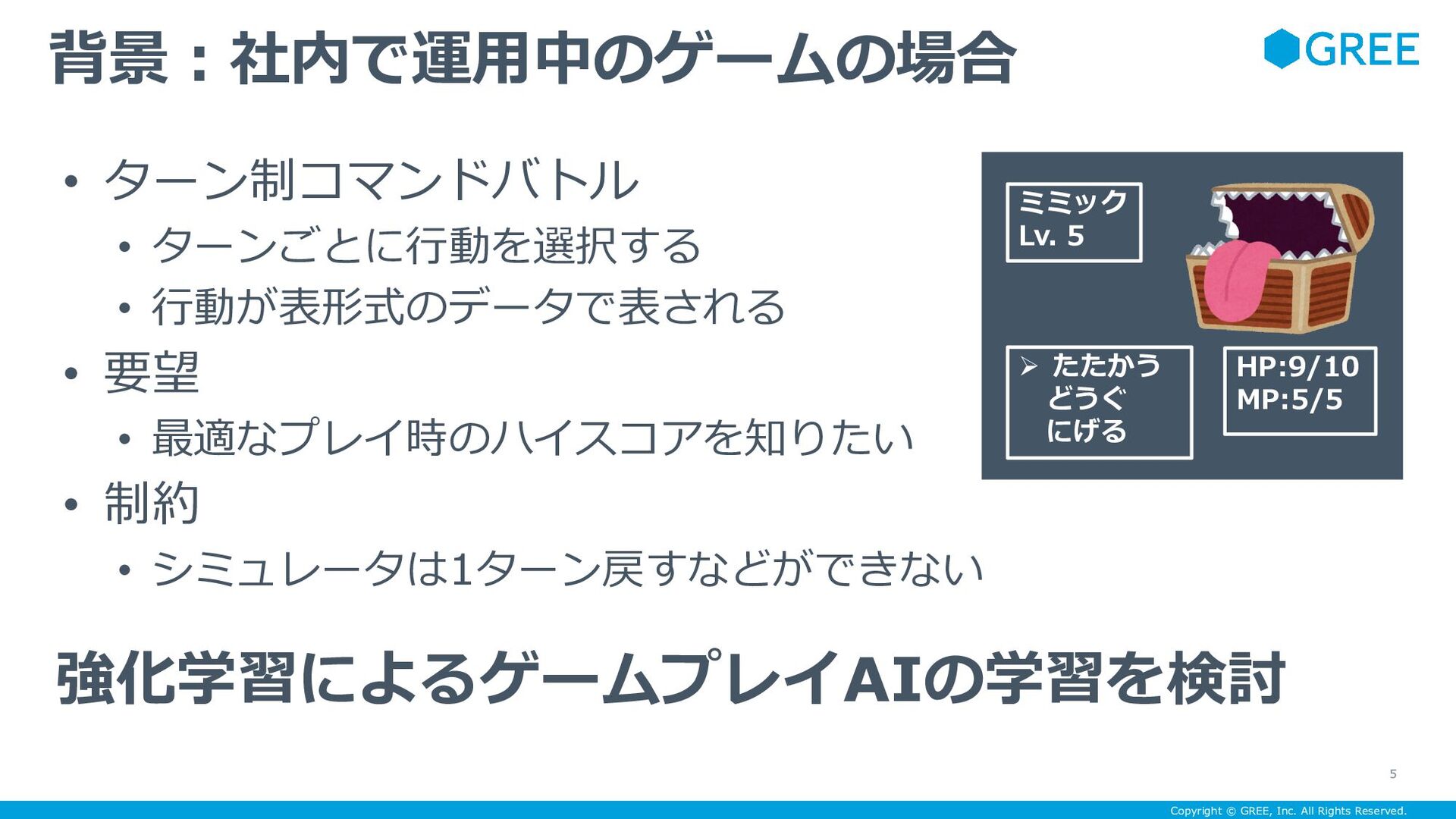{kind=link}
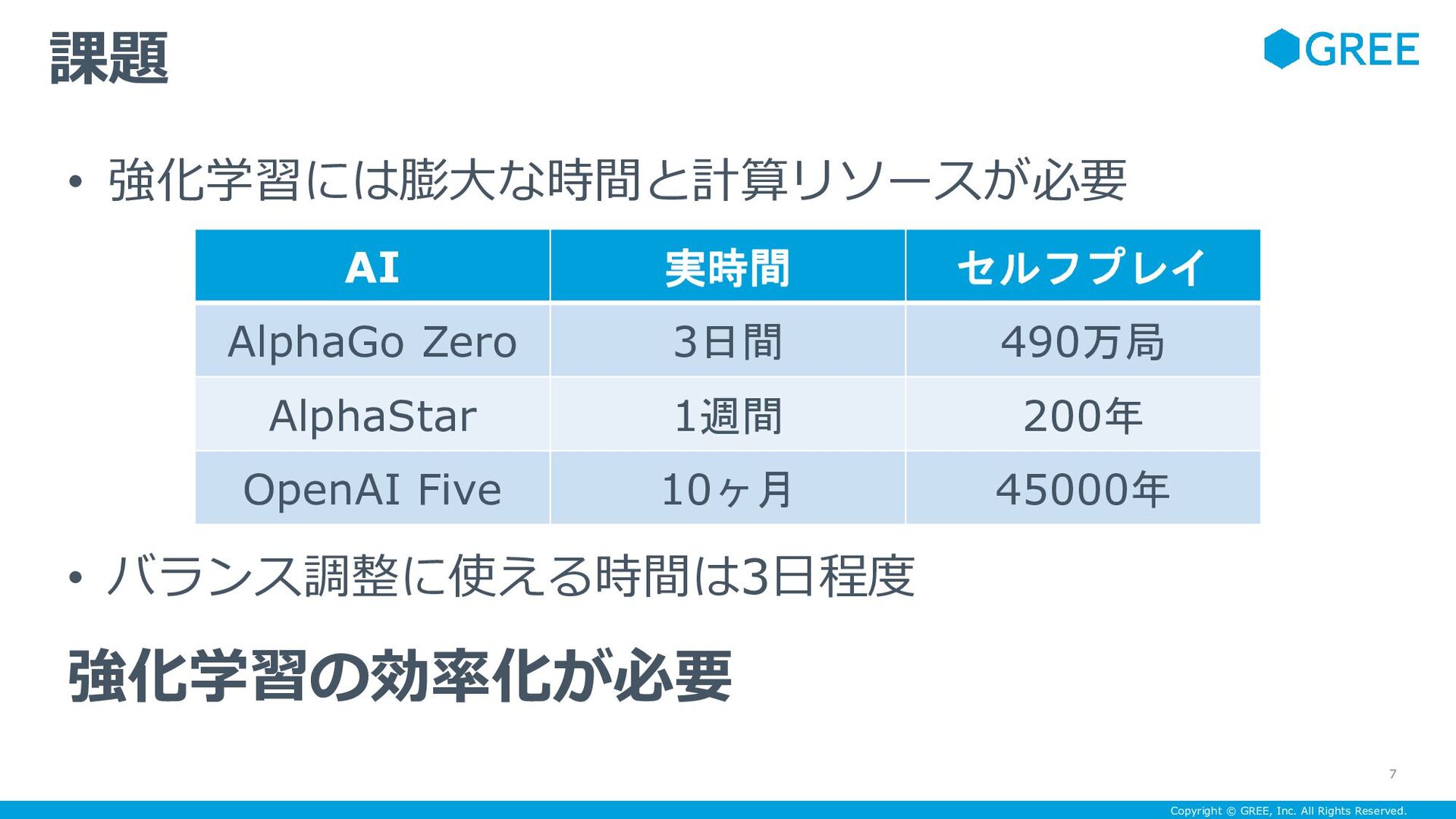
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
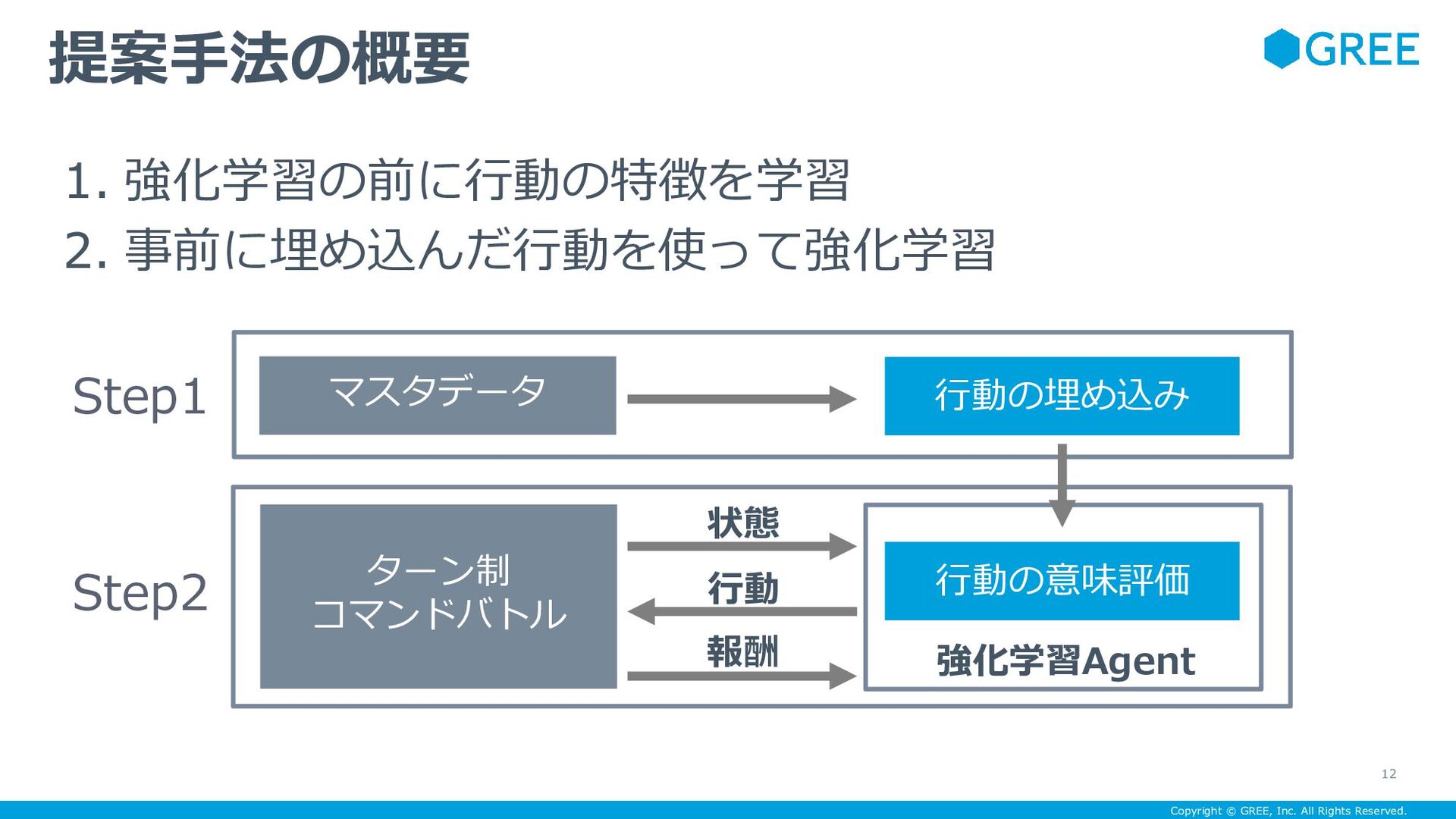{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}