These slides were part of a guest lecture in the Agile Software Engineering course (https://www.cs.manchester.ac.uk/study/undergraduate/courses/courseunitsyllabus/?courseunitcode=COMP33711), of the School of Computer Science, University of Manchester.
It focuses on the technical practices which are necessary ingredients to agility, such as Continuous Integration and Continuous Delivery, as well as basics like version control and automated testing.
The goal was to give students some information on practices they should _expect_ to see in their jobs as graduates, if their teams really want to be called "agile".
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
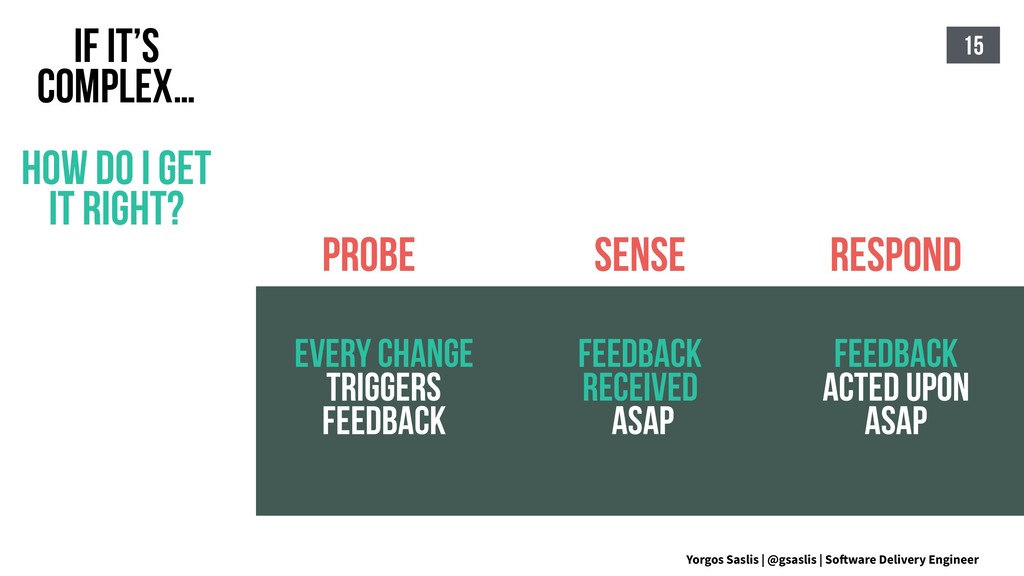{kind=link}
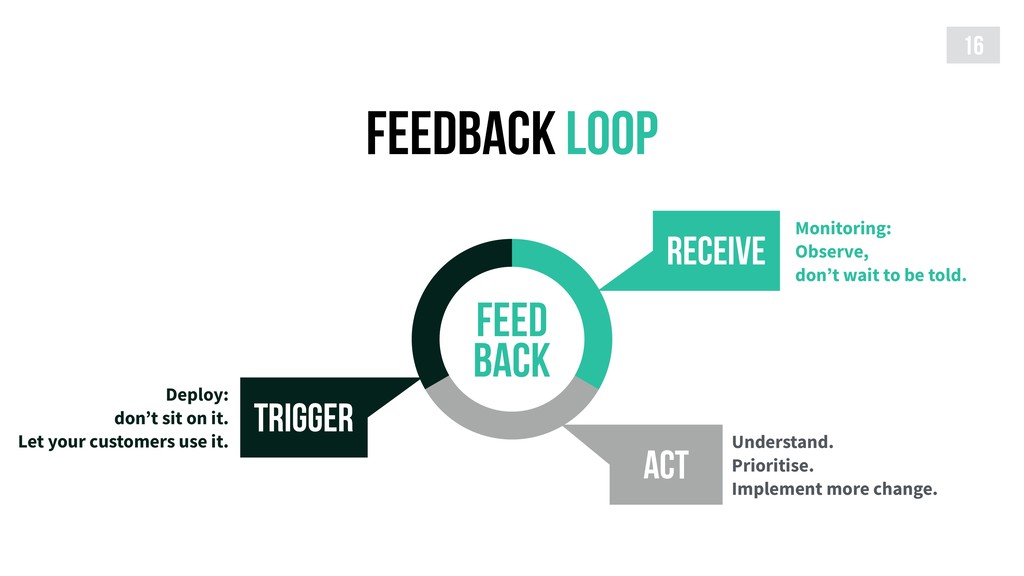{kind=link}
{kind=link}
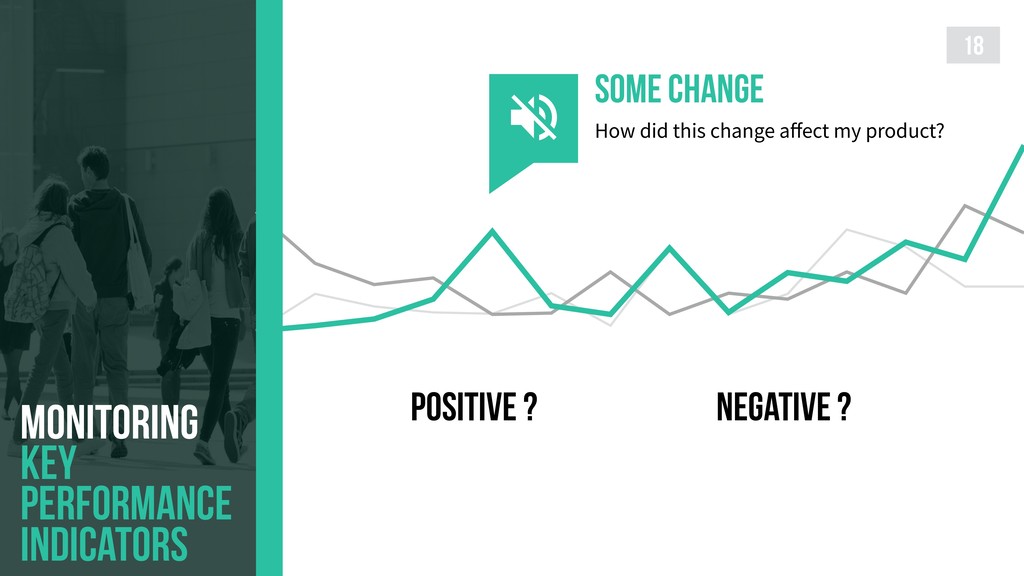{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
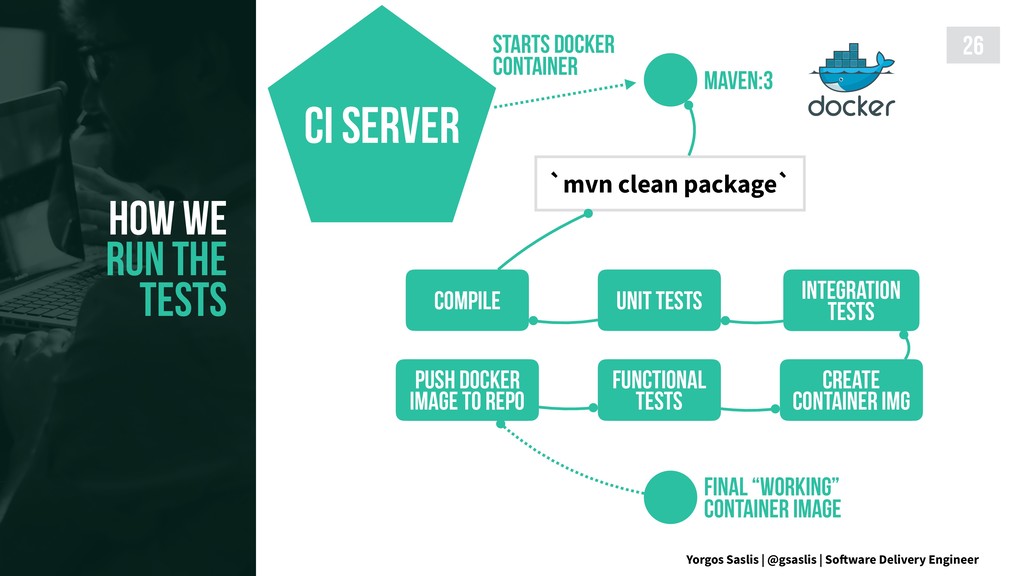{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
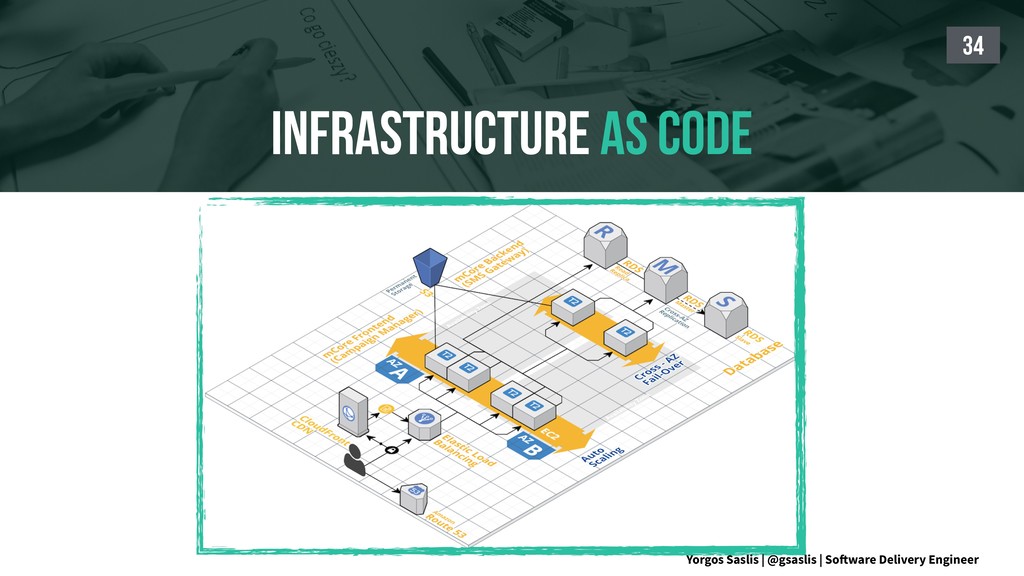{kind=link}
{kind=link}
{kind=link}
{kind=link}
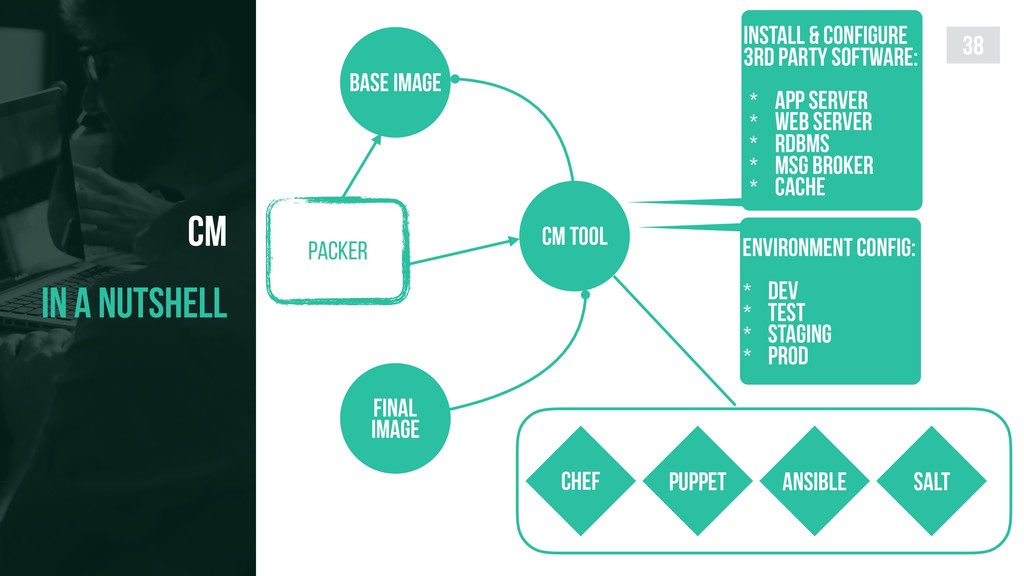{kind=link}
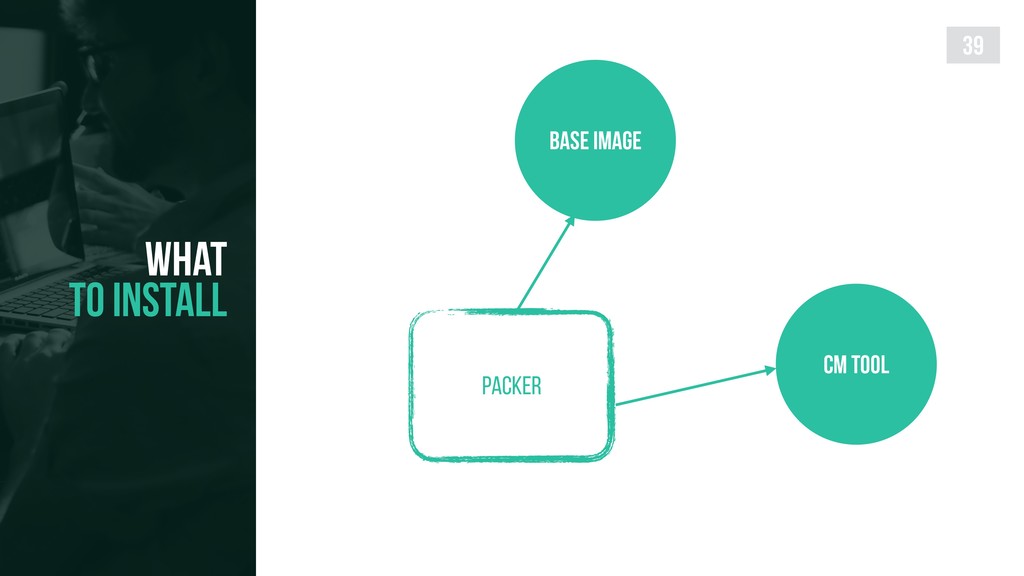{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}