The slides used for the guest lecture in the ML in feedback systems class (CS6784) at Cornell.
video recording: https://vod.video.cornell.edu/media/Guest+Lecture%3A+Off-Policy+Evaluation+and+Learning+%28ML+In+Feedback+Sys+F25%29+/1_eyiazrlc
class info: https://github.com/ml-feedback-sys/materials-f25/tree/main
----
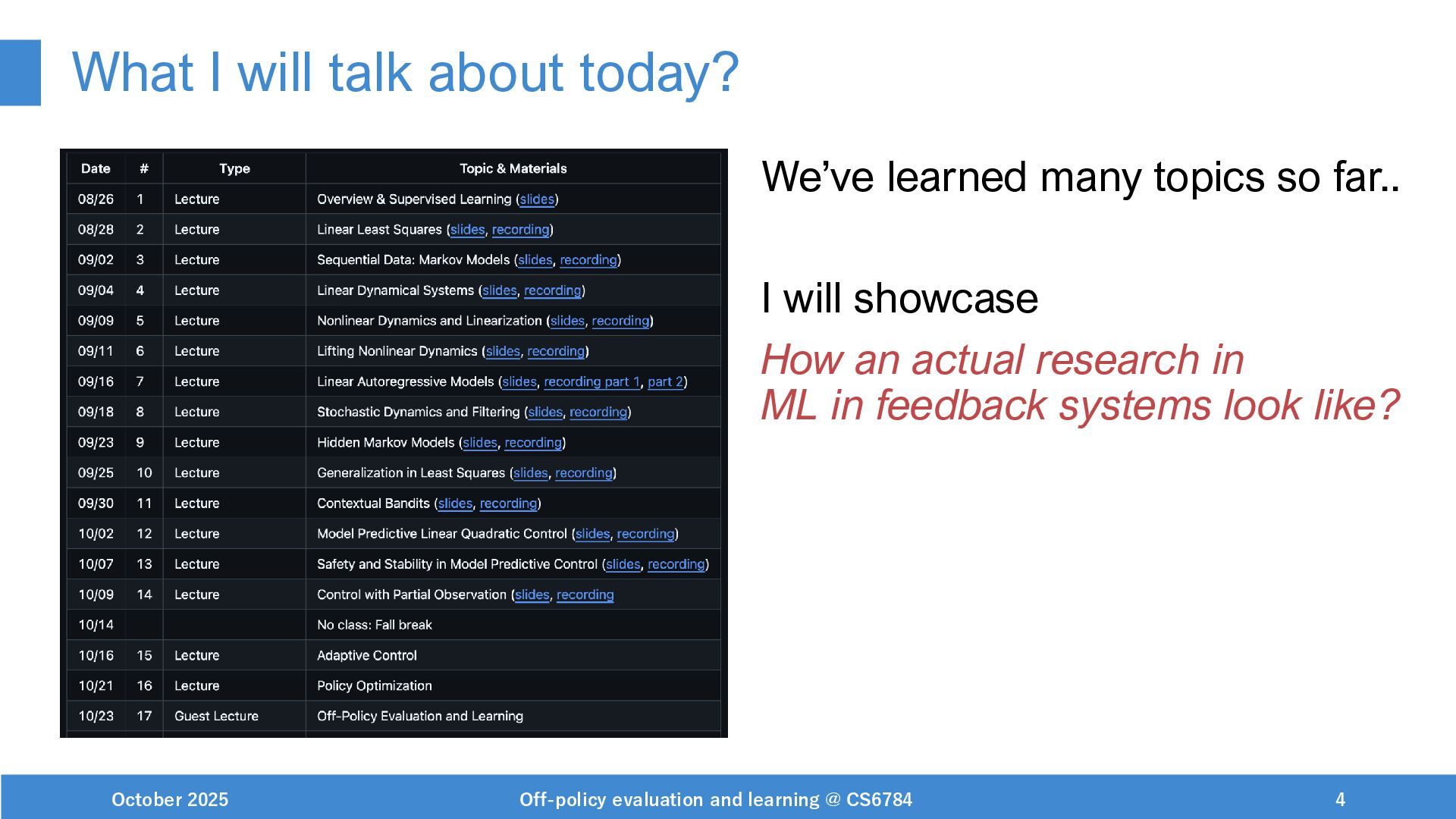
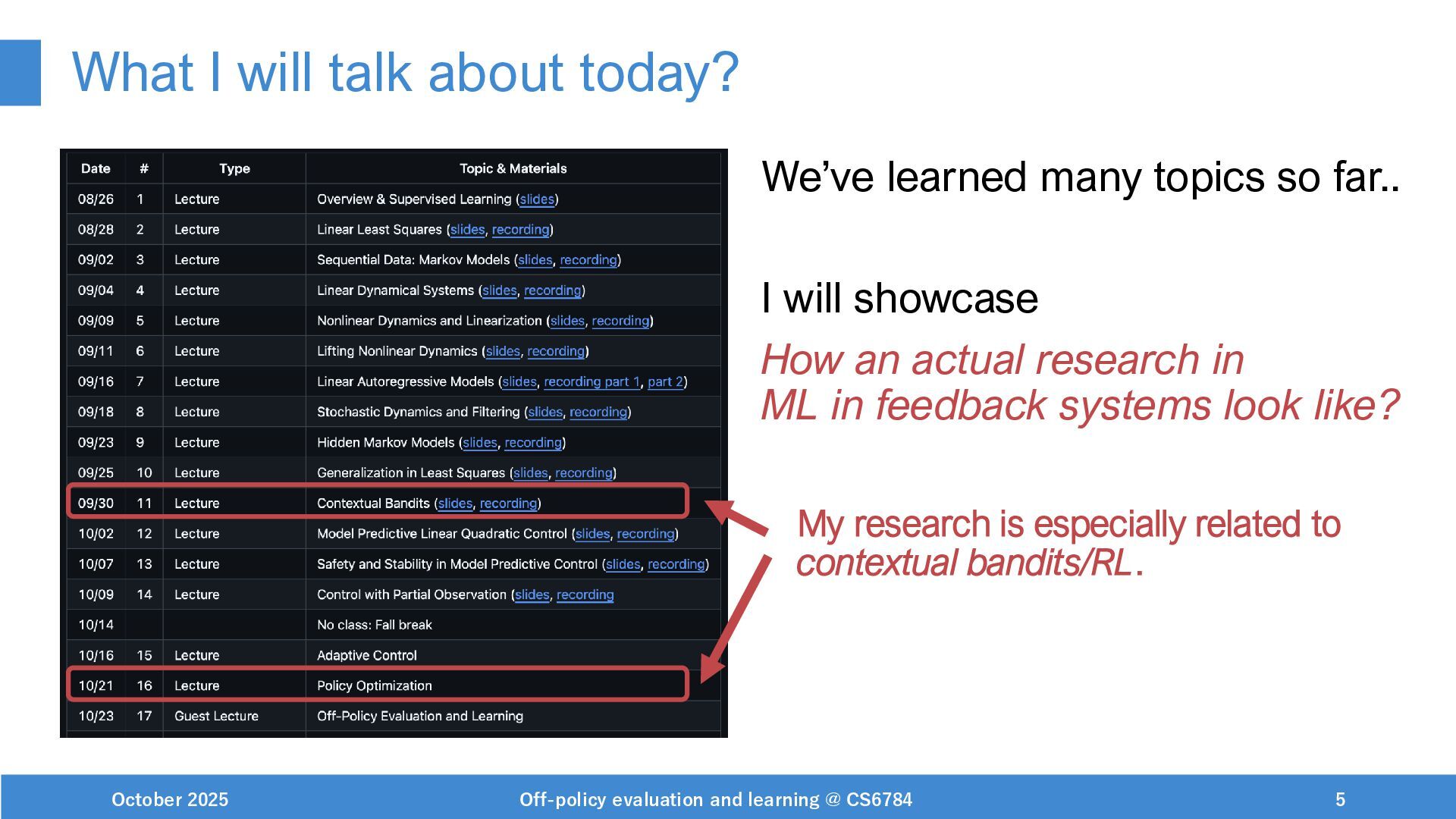
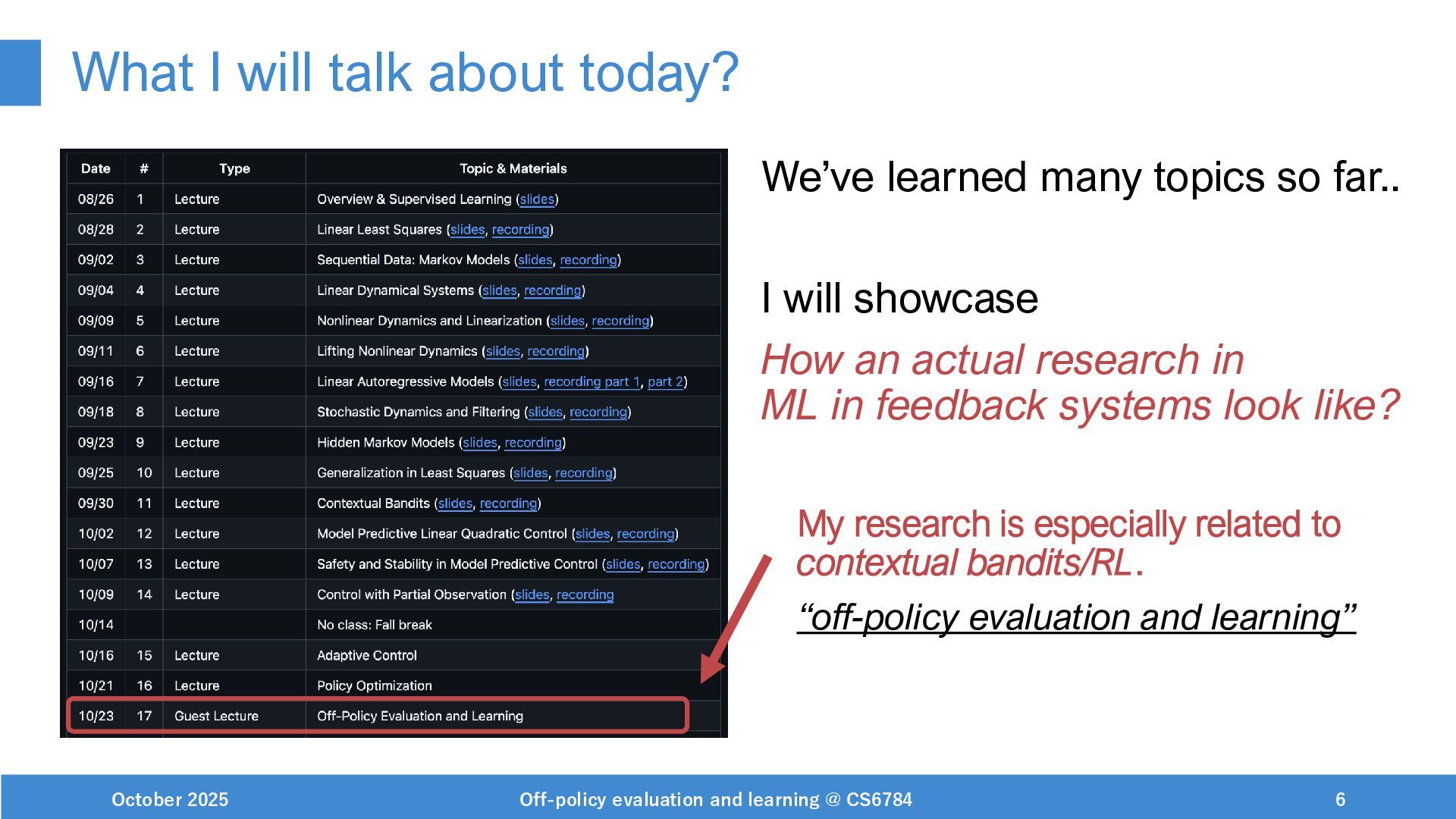
The main content is (1) Intro to off-policy evaluation and learning (OPE/L) and (2) Research example of OPL for sentence personalization. I also briefly mentioned my research interests related to "ML in feedback systems" topics, and mentioned the following papers in the lecture.
OPL for sentence personalization
paper: https://arxiv.org/abs/2504.02646
slides: https://speakerdeck.com/harukakiyohara_/opl-prompt
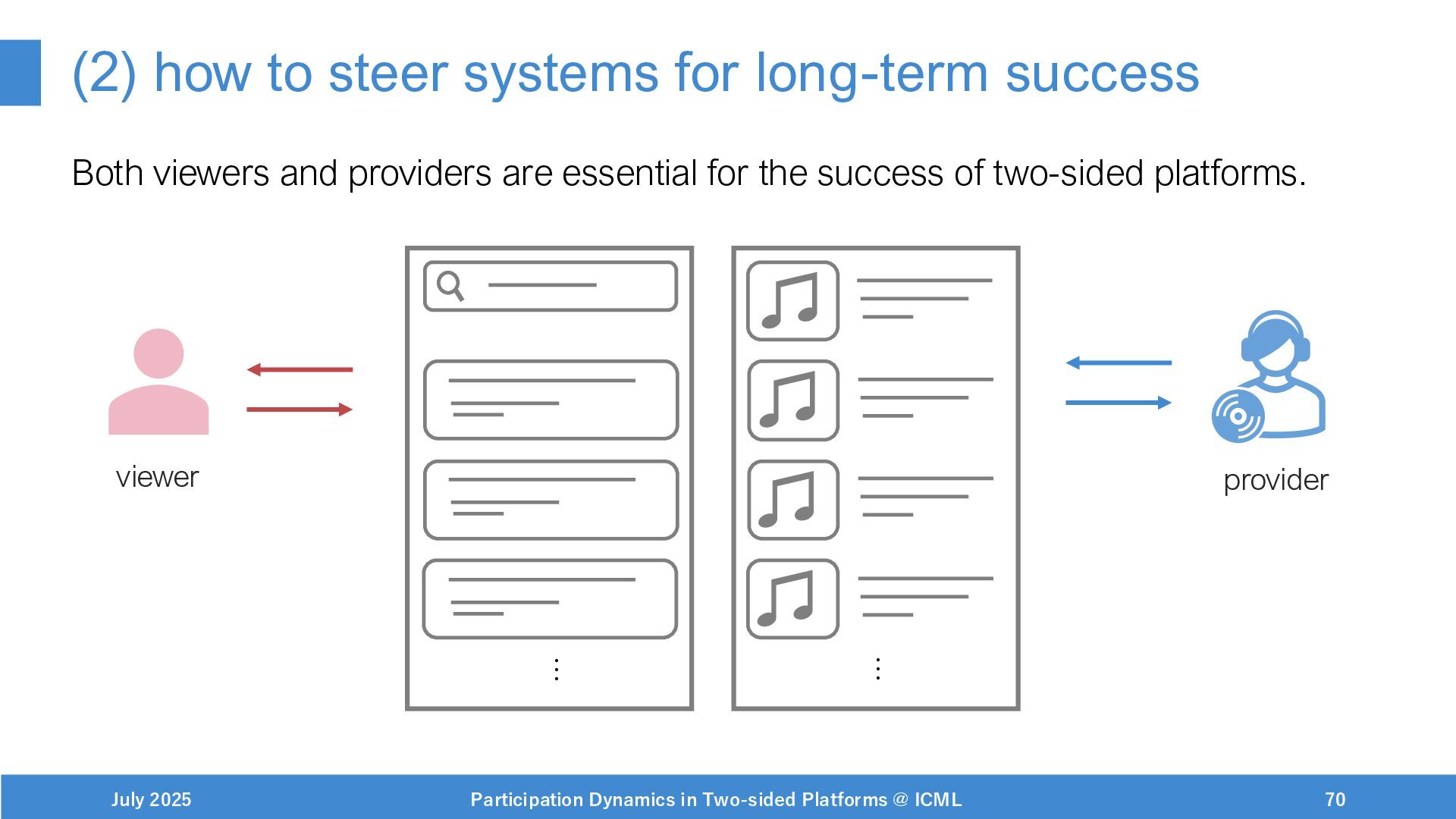
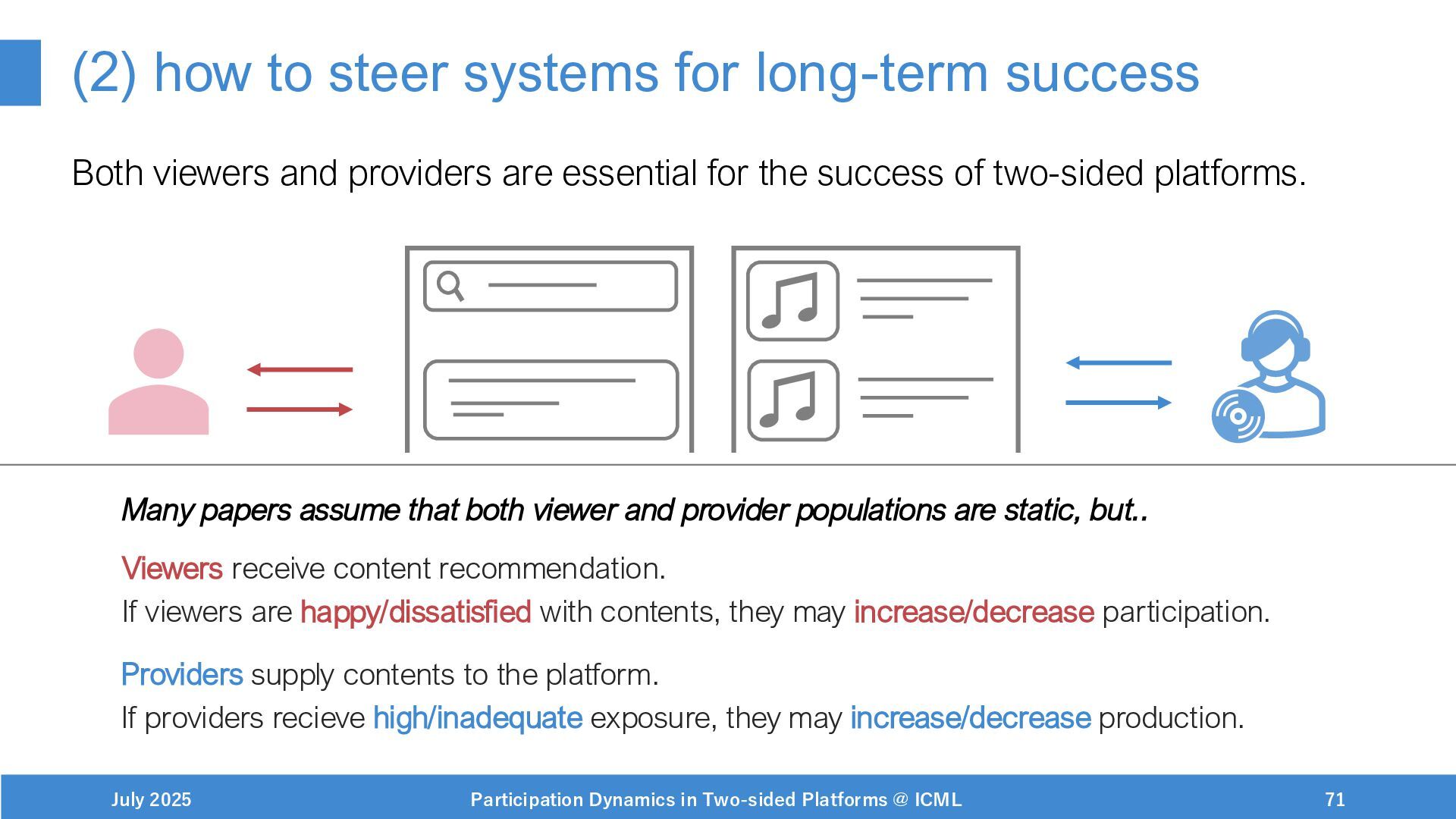
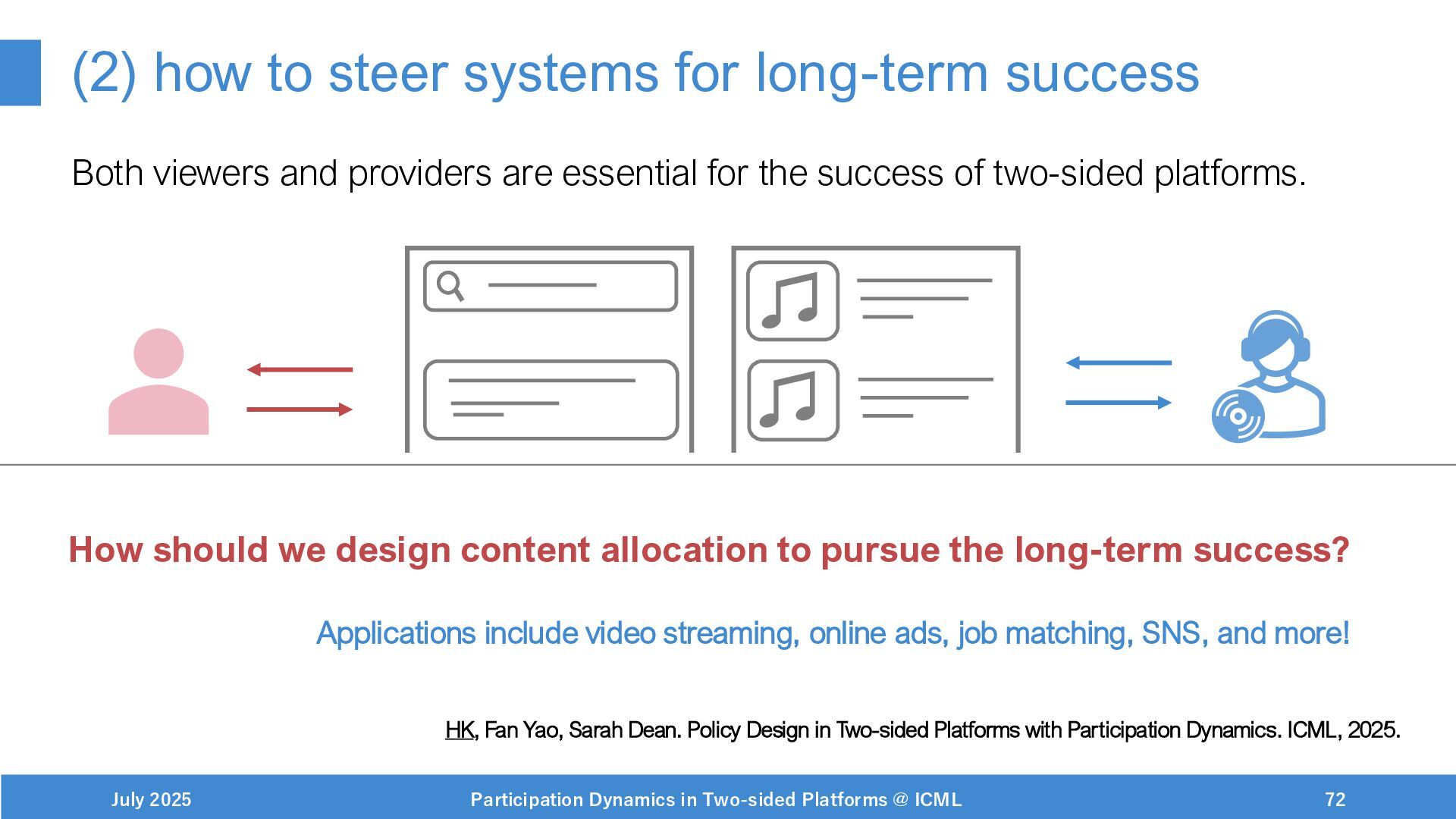
Steering systems for long-term objectives
paper: https://arxiv.org/abs/2502.01792
slides: https://speakerdeck.com/harukakiyohara_/dynamics-two-stage-rec
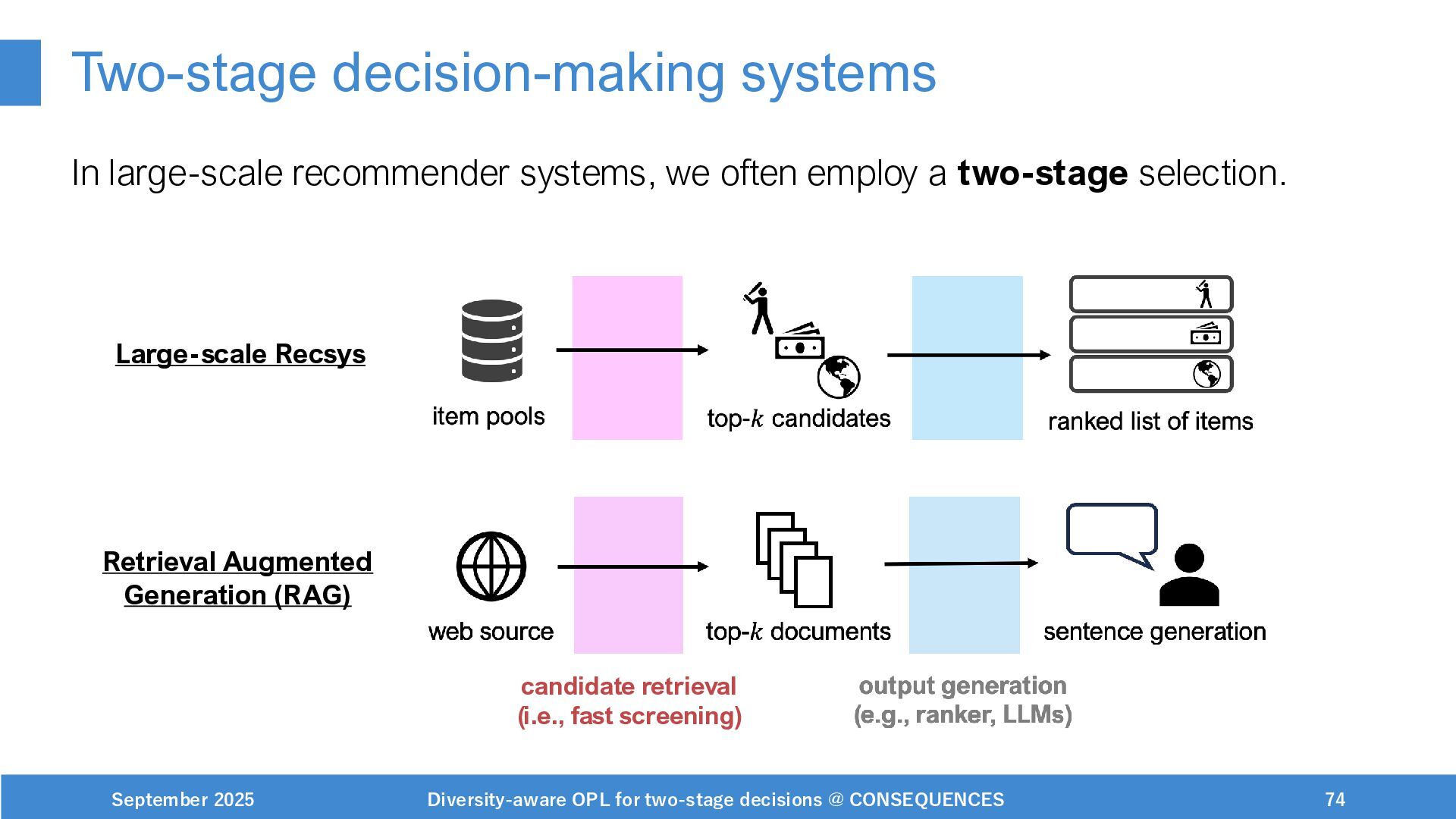
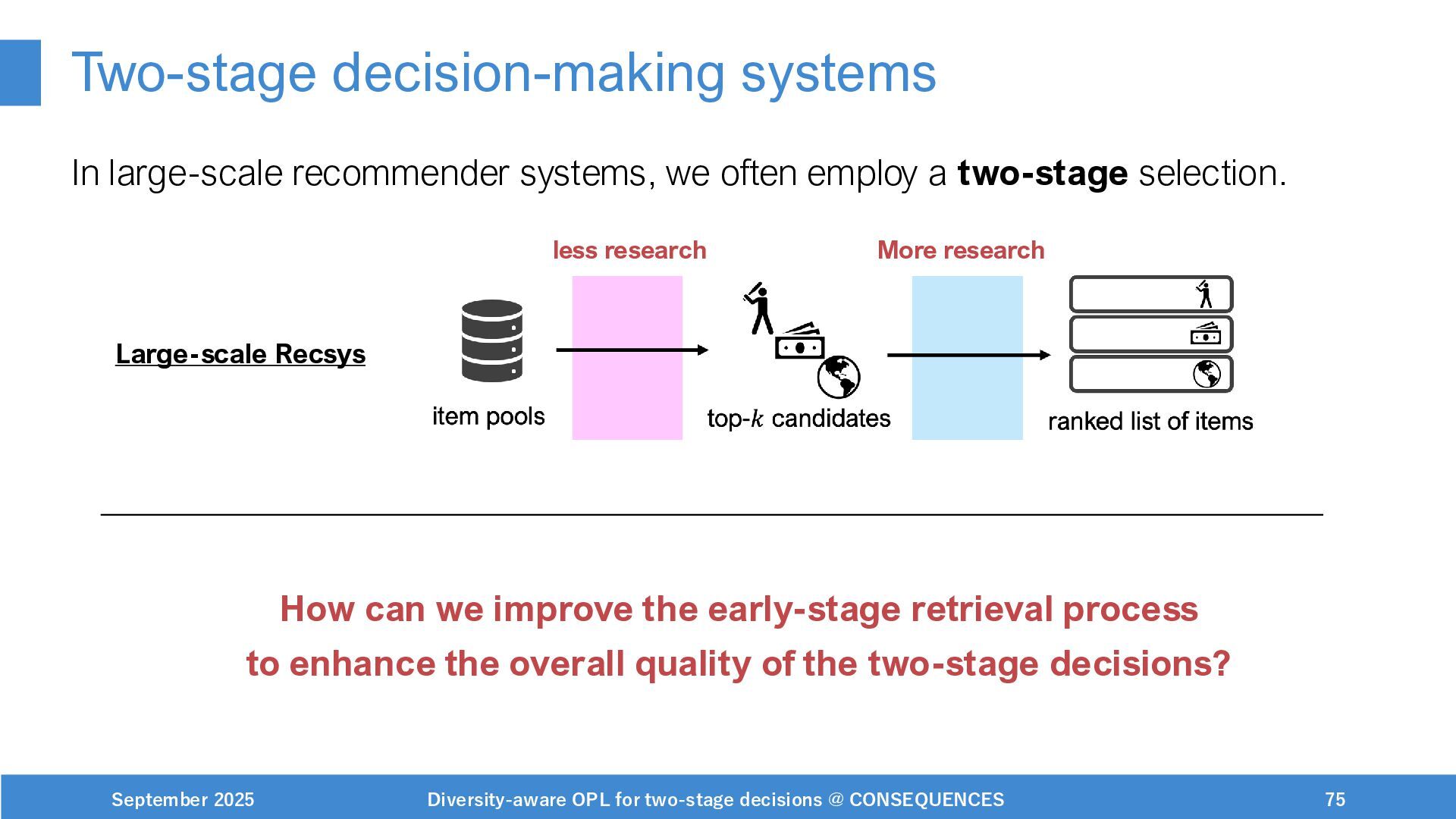
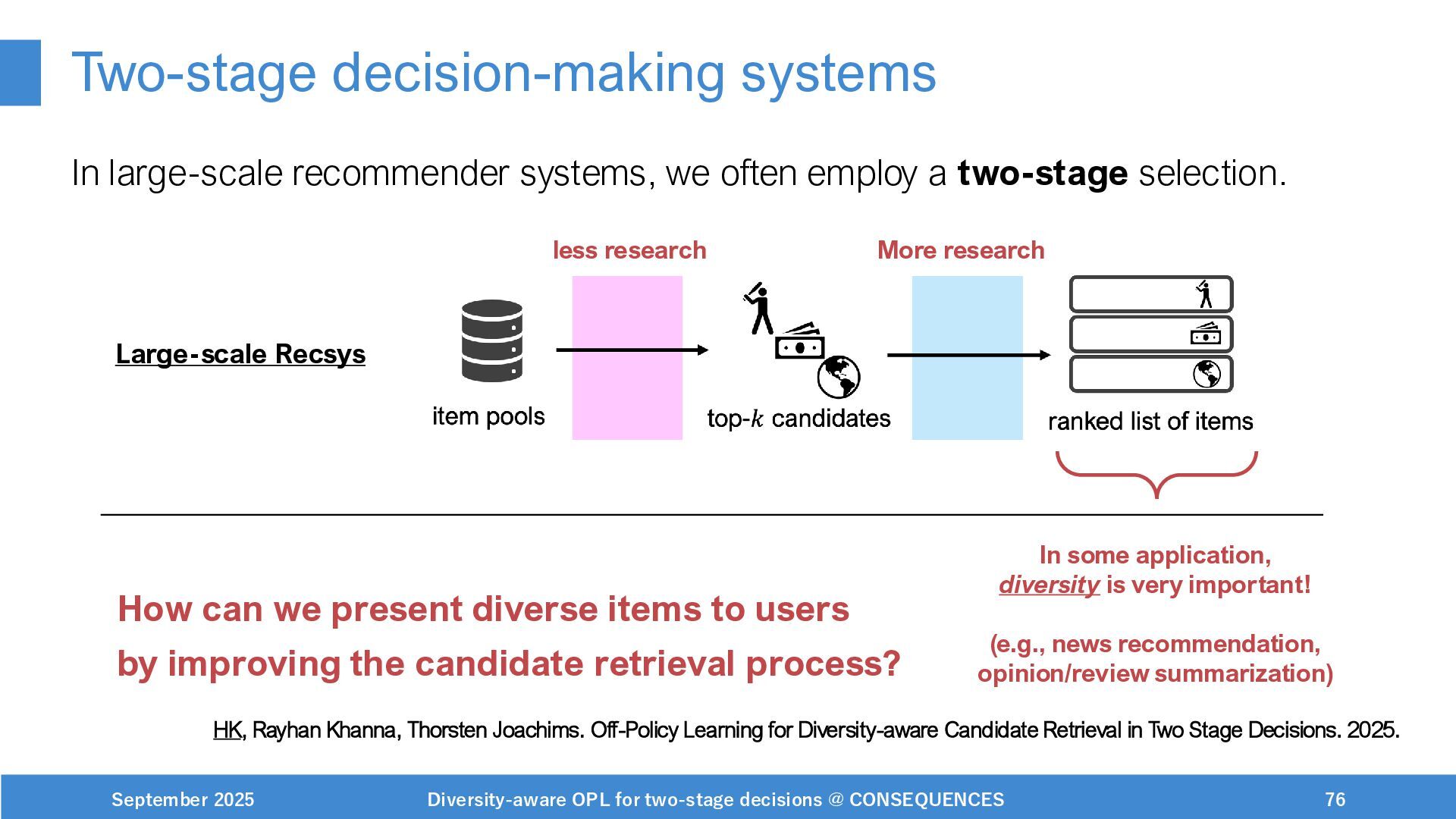
Scalable and adaptable RecSys under practical constraints
(on-going, workshop) paper: https://drive.google.com/file/d/1pc7aa5dvv9cpMRnbUDaeh9-dKP6wzC5J/view?usp=drive_link
----
My research statement is available here.
https://drive.google.com/file/d/1LqONxB8Qw4Z0GSUavAwSSV_oCANcl9TI/view?usp=sharing
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
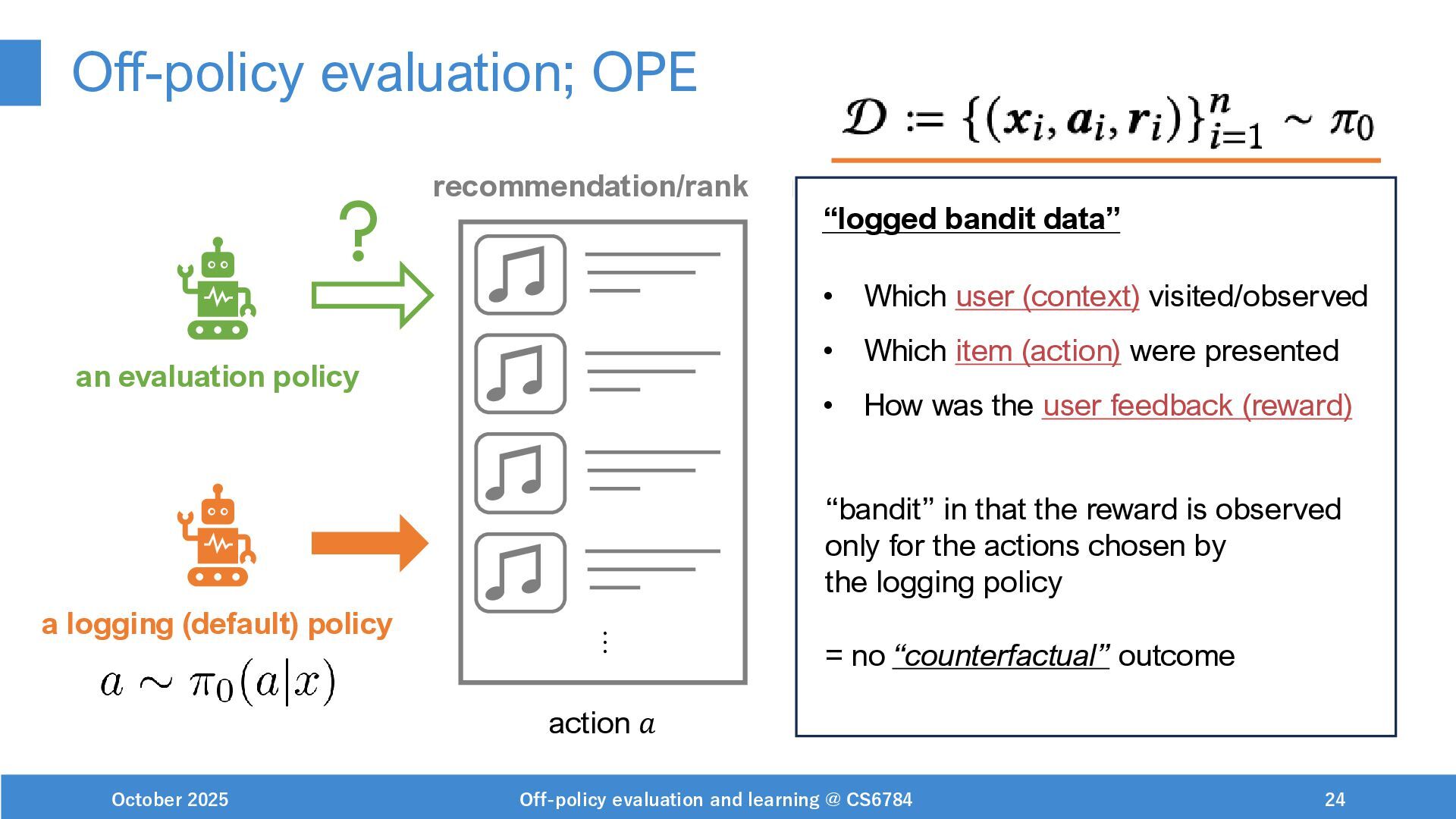{kind=link}
{kind=link}
{kind=link}
{kind=link}
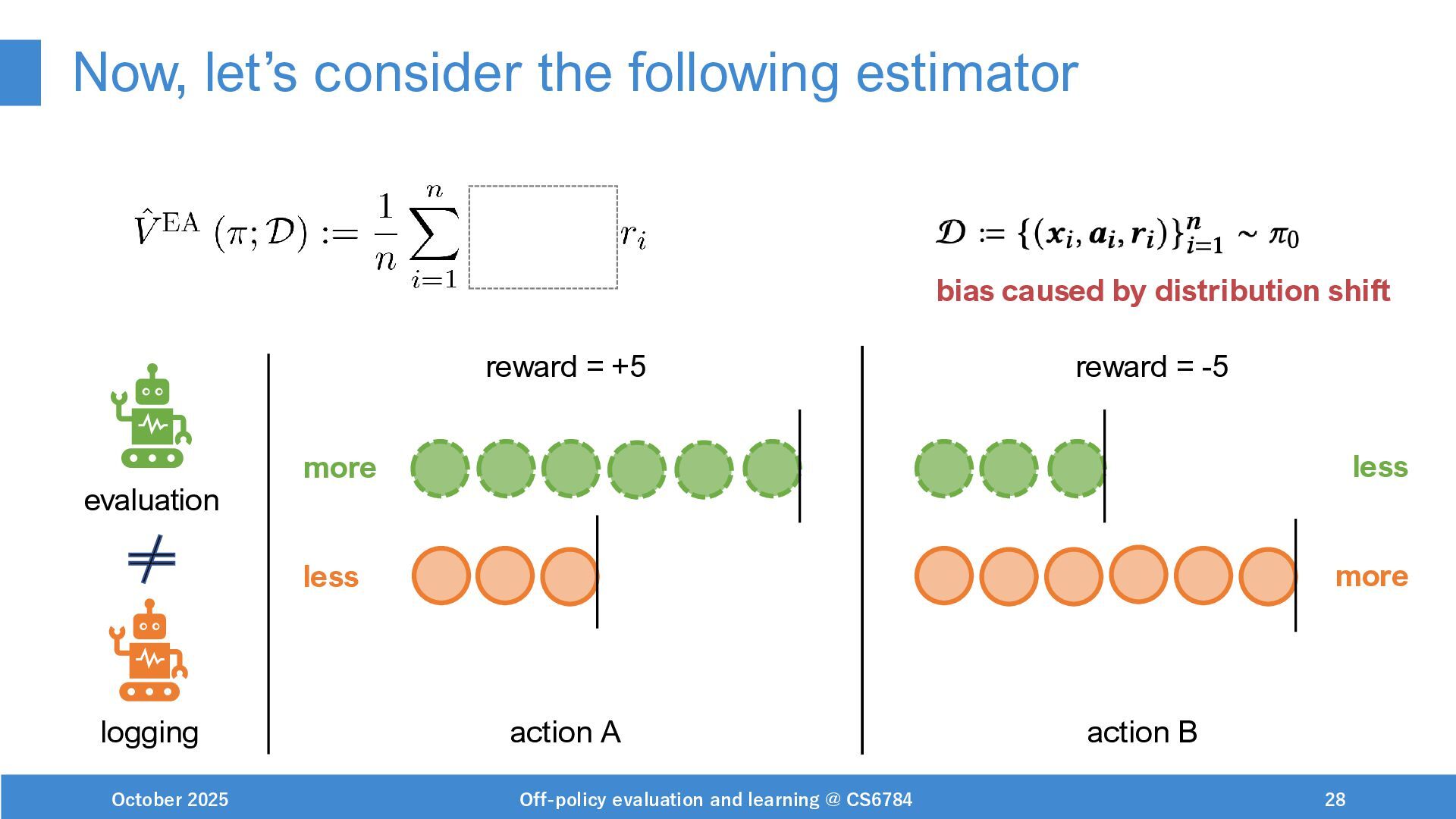{kind=link}
![Importance sampling [Strehl+,10] October 2025 Off-policy evaluation and learning @](https://files.speakerdeck.com/presentations/1f5169bfa89149d79ff4bdaa3f745048/slide_28.jpg){kind=link}
![Importance sampling [Strehl+,10] October 2025 Off-policy evaluation and learning @](https://files.speakerdeck.com/presentations/1f5169bfa89149d79ff4bdaa3f745048/slide_29.jpg){kind=link}
![Importance sampling [Strehl+,10] October 2025 Off-policy evaluation and learning @](https://files.speakerdeck.com/presentations/1f5169bfa89149d79ff4bdaa3f745048/slide_30.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
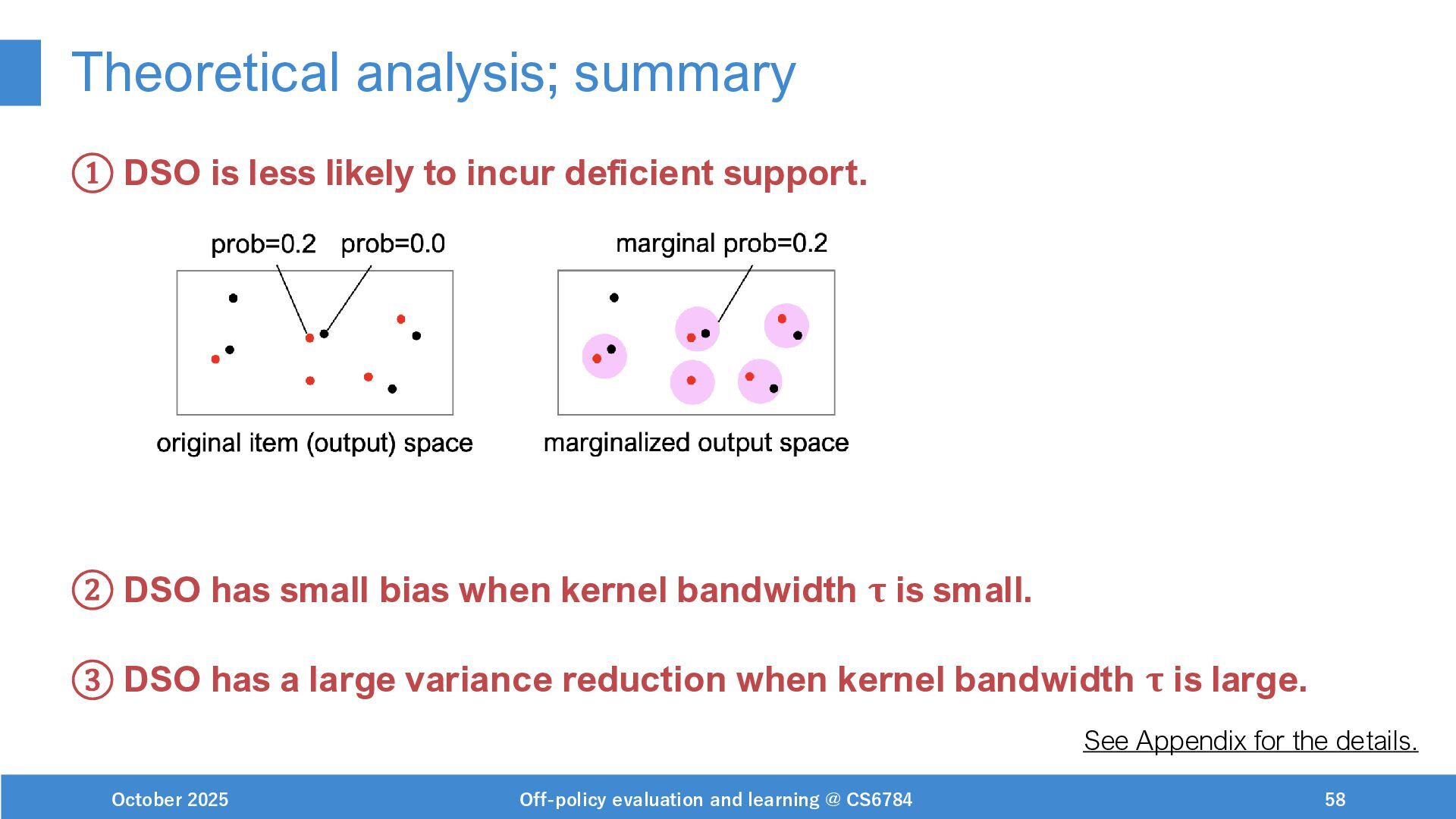{kind=link}
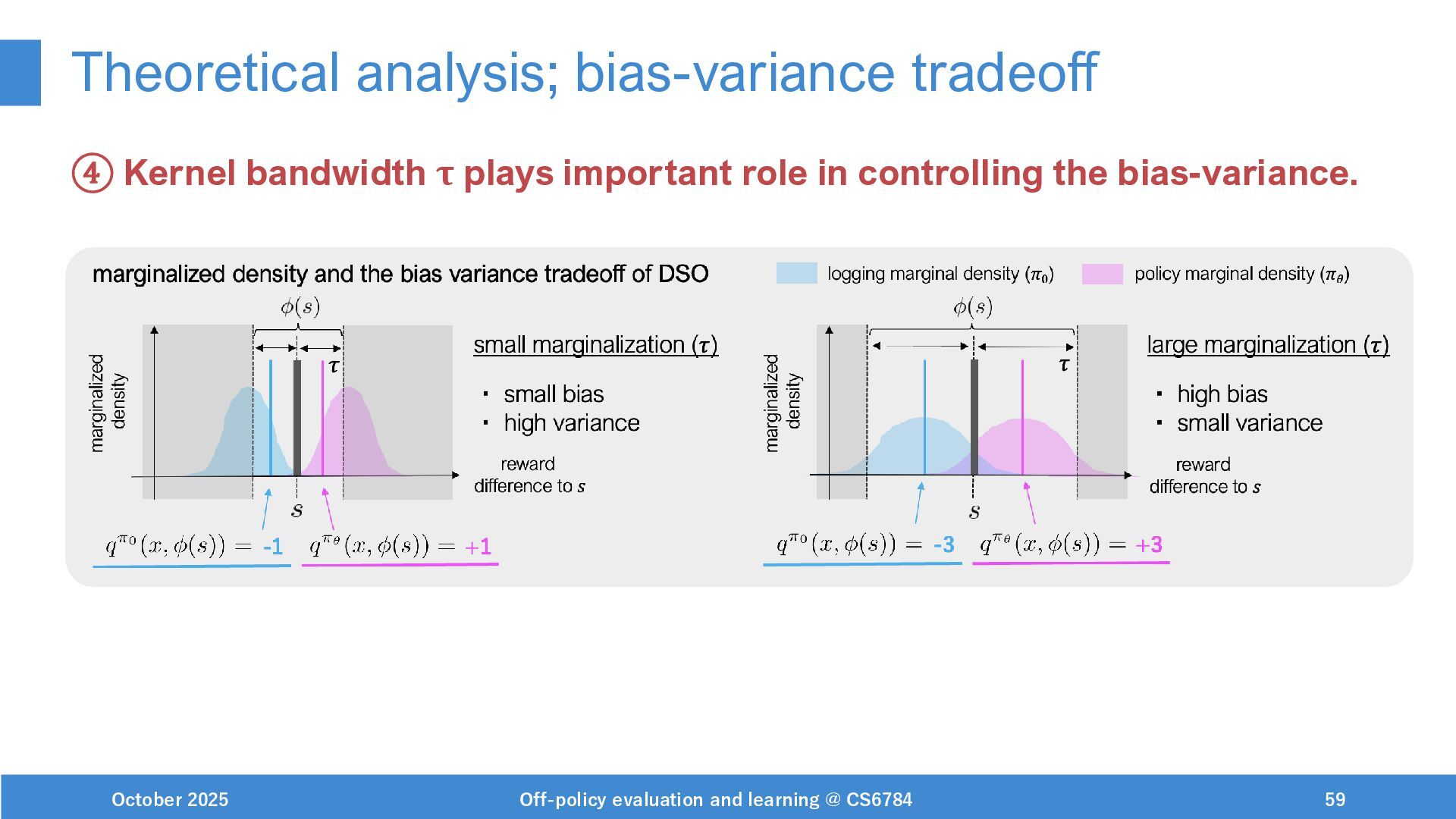{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Reference (1/6) [SST20] Noveen Sachdeva, Yi Su, Thorsten Joachims. Off-policy](https://files.speakerdeck.com/presentations/1f5169bfa89149d79ff4bdaa3f745048/slide_79.jpg){kind=link}
![Reference (2/6) [SSK20] Yi Su, Pavithra Srinath, Akshay Krishnamurthy. Adaptive](https://files.speakerdeck.com/presentations/1f5169bfa89149d79ff4bdaa3f745048/slide_80.jpg){kind=link}
![Reference (3/6) [YRJ22] Yuta Saito, Qingyang Ren, Thorsten Joachims. Off-Policy](https://files.speakerdeck.com/presentations/1f5169bfa89149d79ff4bdaa3f745048/slide_81.jpg){kind=link}
![Reference (4/6) [STKKNS24] Tatsuhiro Shimizu, Koichi Tanaka, Ren Kishimoto, Haruka](https://files.speakerdeck.com/presentations/1f5169bfa89149d79ff4bdaa3f745048/slide_82.jpg){kind=link}
![Reference (5/6) [Konda&Tsitsiklis,99] Vijay Konda and John Tsitsiklis. Actor-critic algorithms.](https://files.speakerdeck.com/presentations/1f5169bfa89149d79ff4bdaa3f745048/slide_83.jpg){kind=link}
![Reference (6/6) [Jiang+,23] Albert Q Jiang, Alexandre Sablayrolles, Arthur Mensch,](https://files.speakerdeck.com/presentations/1f5169bfa89149d79ff4bdaa3f745048/slide_84.jpg){kind=link}