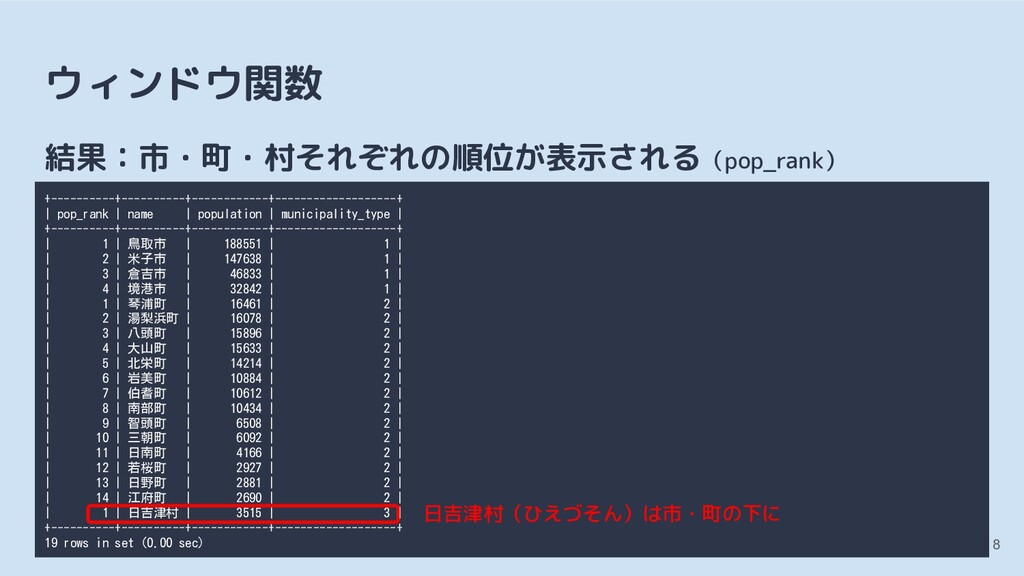
BY で市町村種別を指定→市・町・村別の順位に ◦ ORDER BY で人口の降順を指定 7 SELECT RANK() OVER (PARTITION BY municipality_type ORDER BY population DESC) AS pop_rank, name, population, municipality_type FROM population ORDER BY municipality_type ASC;
COUNT(*) + 1 FROM population AS pop WHERE pop.municipality_type = population.municipality_type AND pop.population > population.population ) AS pop_rank, name, population, municipality_type FROM population ORDER BY municipality_type ASC, population DESC;
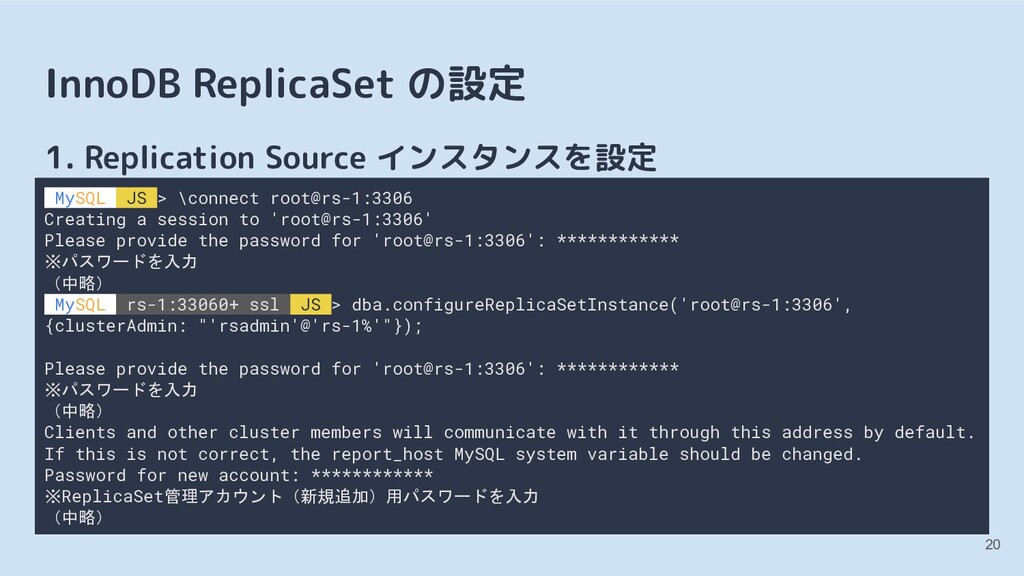
> \connect root@rs-1:3306 Creating a session to 'root@rs-1:3306' Please provide the password for 'root@rs-1:3306': ************ ※パスワードを入力 (中略) MySQL rs-1:33060+ ssl JS > dba.configureReplicaSetInstance('root@rs-1:3306', {clusterAdmin: "'rsadmin'@'rs-1%'"}); Please provide the password for 'root@rs-1:3306': ************ ※パスワードを入力 (中略) Clients and other cluster members will communicate with it through this address by default. If this is not correct, the report_host MySQL system variable should be changed. Password for new account: ************ ※ReplicaSet管理アカウント(新規追加)用パスワードを入力 (中略)
JS > var rs = dba.createReplicaSet("example") ※ReplicaSet「example」を作成 A new replicaset with instance 'rs-1:3306' will be created. * Checking MySQL instance at rs-1:3306 This instance reports its own address as rs-1:3306 rs-1:3306: Instance configuration is suitable. * Updating metadata... ReplicaSet object successfully created for rs-1:3306. Use rs.addInstance() to add more asynchronously replicated instances to this replicaset and rs.status() to check its status.
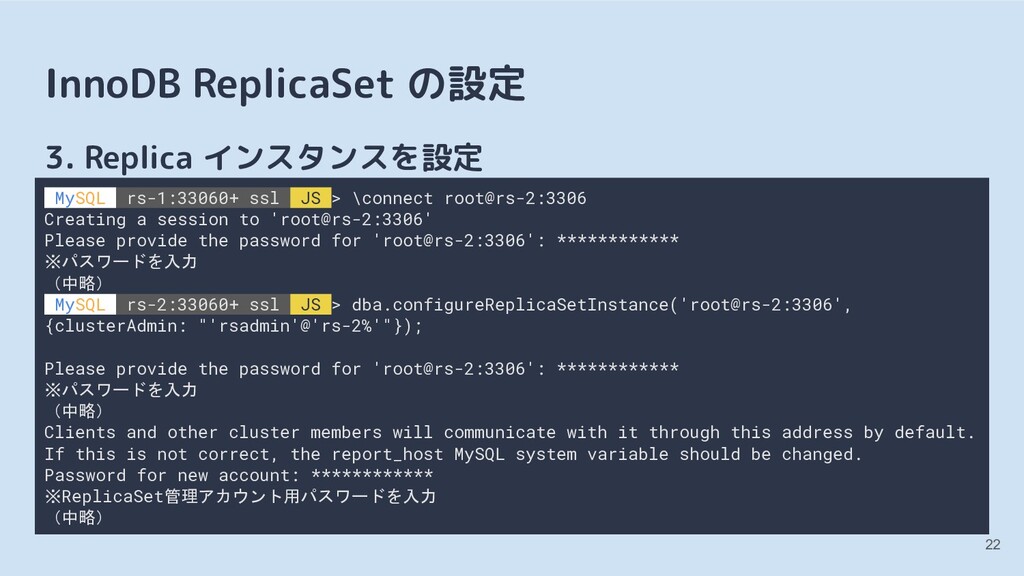
JS > \connect root@rs-2:3306 Creating a session to 'root@rs-2:3306' Please provide the password for 'root@rs-2:3306': ************ ※パスワードを入力 (中略) MySQL rs-2:33060+ ssl JS > dba.configureReplicaSetInstance('root@rs-2:3306', {clusterAdmin: "'rsadmin'@'rs-2%'"}); Please provide the password for 'root@rs-2:3306': ************ ※パスワードを入力 (中略) Clients and other cluster members will communicate with it through this address by default. If this is not correct, the report_host MySQL system variable should be changed. Password for new account: ************ ※ReplicaSet管理アカウント用パスワードを入力 (中略)
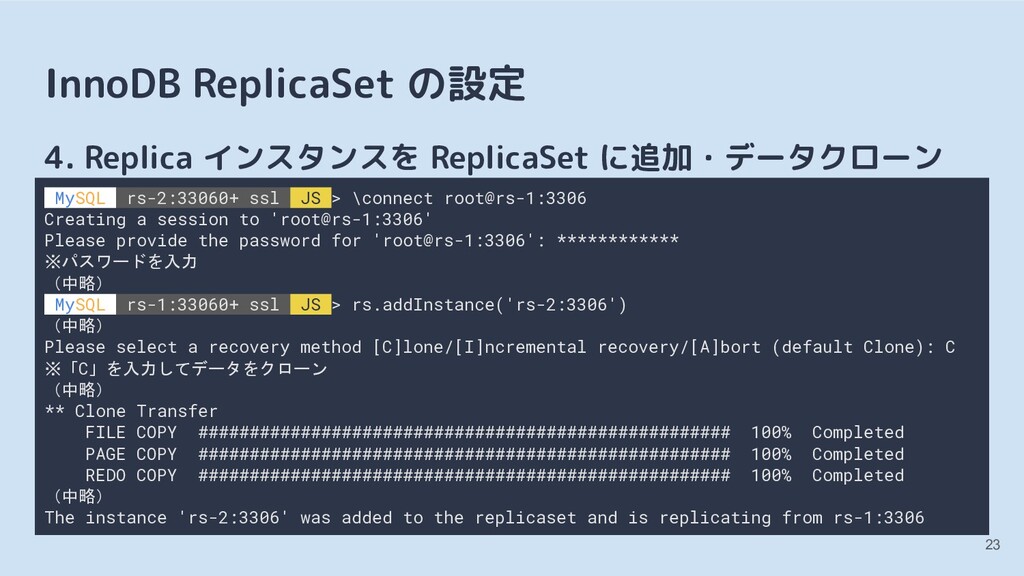
rs-2:33060+ ssl JS > \connect root@rs-1:3306 Creating a session to 'root@rs-1:3306' Please provide the password for 'root@rs-1:3306': ************ ※パスワードを入力 (中略) MySQL rs-1:33060+ ssl JS > rs.addInstance('rs-2:3306') (中略) Please select a recovery method [C]lone/[I]ncremental recovery/[A]bort (default Clone): C ※「C」を入力してデータをクローン (中略) ** Clone Transfer FILE COPY #################################################### 100% Completed PAGE COPY #################################################### 100% Completed REDO COPY #################################################### 100% Completed (中略) The instance 'rs-2:3306' was added to the replicaset and is replicating from rs-1:3306
• 以前よく使われていた LEFT JOIN で null と結合する手法では 27 mysql> EXPLAIN FORMAT=TREE SELECT * FROM t2 -> WHERE NOT EXISTS (SELECT * FROM t1 WHERE t1.col1 = t2.col1)\G *************************** 1. row *************************** EXPLAIN: -> Nested loop antijoin -> Table scan on t2 (cost=0.85 rows=6) -> Single-row index lookup on <subquery2> using <auto_distinct_key> (c1=t2.c1) -> Materialize with deduplication -> Filter: (t1.c1 is not null) (cost=0.85 rows=6) -> Table scan on t1 (cost=0.85 rows=6) SELECT t2.* FROM t2 LEFT JOIN t1 ON t1.col1 = t2.col1 WHERE t1.col1 IS null;
Skip Scan Range Access Method • 複合インデックスの 1 列目を WHERE 句で指定していなくてもインデックス が使えるように(細かい制約条件あり) CATS(The Contention-Aware Transaction Scheduling) • 効率的なロックスケジューラ(FIFO から置き換え) 28 UPDATE t1 SET t1.a=value WHERE t1.a IN (SELECT t2.a FROM t2); ↓ UPDATE t1, (SELECT 1) dummy SET t1.a=value WHERE t1.a IN (SELECT t2.a FROM t2);
{kind=link}
{kind=link}
![今回のテーマ MySQL 5.6・5.7 から 8.0 に移行するときに、知っておくと良さ そうな点について取り上げます • [1] MySQL](https://files.speakerdeck.com/presentations/7b882c9957274a38bab45fb6901bea6a/slide_2.jpg){kind=link}
{kind=link}
![[1] MySQL 8.0 に移行すると嬉しいこと 使える機能が増える • 他の RDBMS と遜色のないレベルの SQL(文)サポート](https://files.speakerdeck.com/presentations/7b882c9957274a38bab45fb6901bea6a/slide_4.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
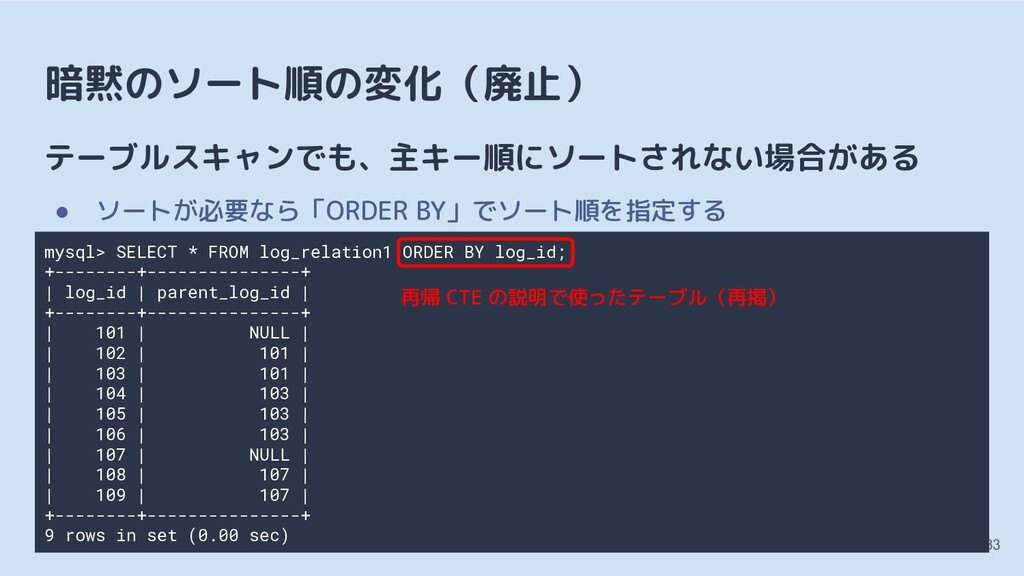
![[2] MySQL 8.0 に移行するときの注意点 マイナーバージョンアップで機能追加・変更・非推奨化・削除 • 例:予約語、実行計画とオプティマイザスイッチ デフォルトの変更により動作が変わる • 例:認証プラグイン、暗黙のソート順](https://files.speakerdeck.com/presentations/7b882c9957274a38bab45fb6901bea6a/slide_28.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
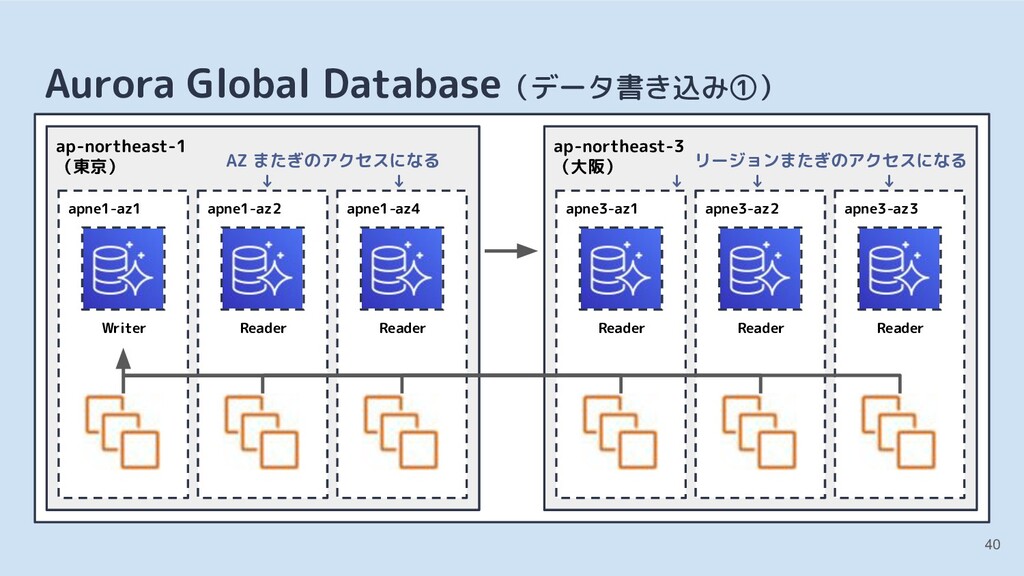
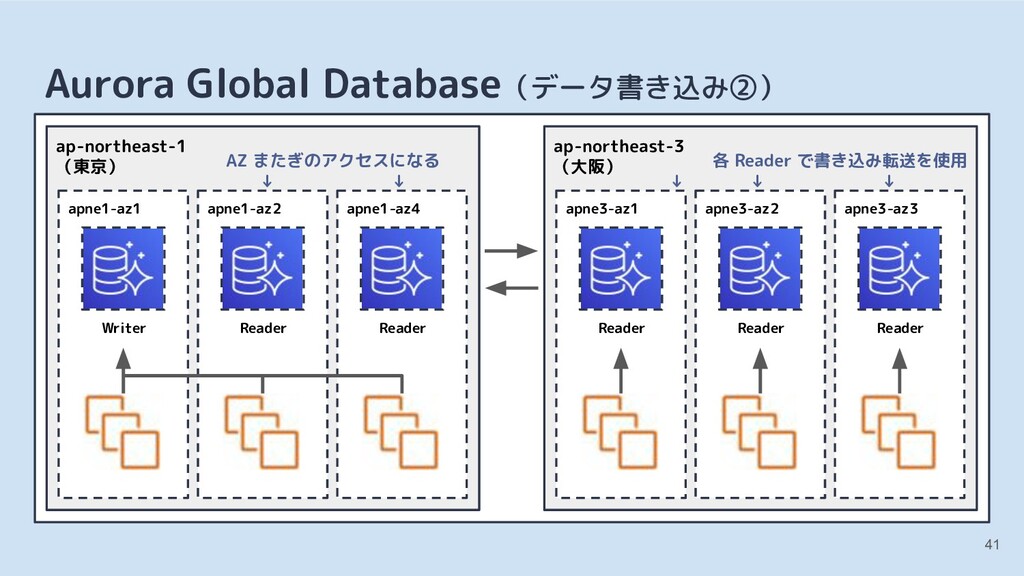
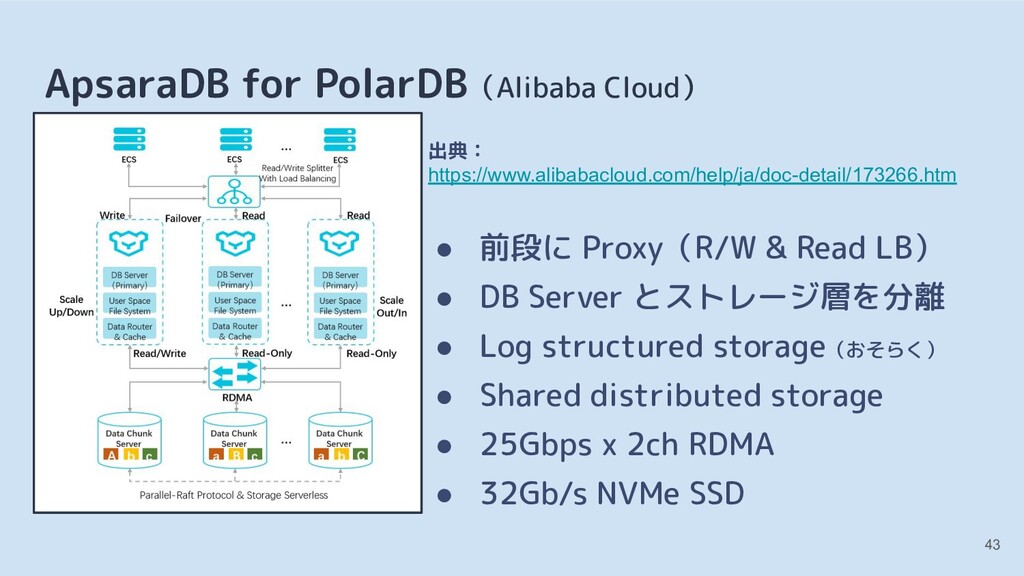
![[3] クラウドのマネージドサービスとの比較 Amazon Aurora(Amazon Web Services) • MySQL 5.6・5.7 互換](https://files.speakerdeck.com/presentations/7b882c9957274a38bab45fb6901bea6a/slide_35.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}