Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Deeplearning from almost scratch
Search
Sponsored
·
Ship Features Fearlessly
Turn features on and off without deploys. Used by thousands of Ruby developers.
→
HN410
May 05, 2022
Technology
2.2k
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
Deeplearning from almost scratch
サークルで行った「1から始めるディープラーニング」のLT資料です.
HN410
May 05, 2022
More Decks by HN410
See All by HN410
Lex, YACC講習会
hn410
0
2.1k
Brainf*ckで15パズル
hn410
0
1.6k
Android入門
hn410
0
2k
計算量理論
hn410
0
2.4k
Produire
hn410
0
3.4k
Other Decks in Technology
See All in Technology
AIと共生する開発者プラットフォーム:バクラクのモノレポ×マイクロサービス基盤
sakajunquality
2
3.6k
AI時代の開発生産性は、個人技からチーム設計へ
moongift
PRO
4
2.2k
AI Driven AI Governance
pict3
0
460
“それは自分の仕事じゃない"を 越えて行け
yuukiyo
1
400
AICoEでAIネイティブ組織への進化
yukiogawa
0
180
個人開発で育てる「大規模設計の苗床」 - AI時代の1人開発から始める業務への知識接続 / The Seedbed for Large-Scale Design - From AI-Era Solo Projects to Professional Knowledge
bitkey
PRO
1
270
SRE依存からの脱却 運用を開 発チームへ移す、 フルサイ クル開 発体制の実践
joooee0000
0
2.8k
インフラと開発の垣根を超えていき!〜元AWSインフラエンジニアがAWS開発で奮闘している話〜
hatahata021
3
280
Kaggleで成長するために意識したこと
prgckwb
2
390
AI Coding Agent時代のcdk-nagガードレール 〜組織ルールを強制CIで守り抜く設計の挑戦〜
mhrtech
3
300
公式ドキュメントの歩き方etc
coco_se
0
110
事業価値を⽣み出すSREへ SREが担うべき意思決定の5層
kenta_hi
2
3.8k
Featured
See All Featured
Lightning Talk: Beautiful Slides for Beginners
inesmontani
PRO
2
610
Digital Ethics as a Driver of Design Innovation
axbom
PRO
1
340
Joys of Absence: A Defence of Solitary Play
codingconduct
1
410
Design in an AI World
tapps
1
260
[RailsConf 2023] Rails as a piece of cake
palkan
59
6.7k
Chrome DevTools: State of the Union 2024 - Debugging React & Beyond
addyosmani
10
1.3k
A designer walks into a library…
pauljervisheath
211
24k
How to build a perfect <img>
jonoalderson
1
5.8k
4 Signs Your Business is Dying
shpigford
187
22k
Why Your Marketing Sucks and What You Can Do About It - Sophie Logan
marketingsoph
0
270
The State of eCommerce SEO: How to Win in Today's Products SERPs - #SEOweek
aleyda
2
11k
Navigating Team Friction
lara
192
16k
Transcript
1から作る DEEP LEARNING 19 HN
今日の目標 • ディープラーニングについての基礎的な理論を1から理解する. • 必須能力 … 高校3年までの数学 • 要望能力 …
大学一年生程度の数学 (線形代数,微分積分学) • 性能を上げるための基礎的な工夫について理解する.
DEEP LEARNINGとは • ディープラーニングとは、データの背景にあるルールやパターンを学習するために、 多層的(ディープ)に構造で考える方法です。 一般的なデータ分析は、入力データ(インプット)と出力データ(アウトプット)の 関係を直接分析しますが、ディープラーニングは、中間層と呼ばれる構造を設け、さ らに多層化することで、データの背景にあるルールやパターンを考えることができま す。 NRI
ナレッジ・インサイト 用語解説より • ニューラルネットワークを使ったものが多い • あらゆる分野 (画像処理,自然言語処理,音声処理など…)でState-of-the-art (その時点 で最も優れた性能)を達成しているモデルがこれに基づいている.
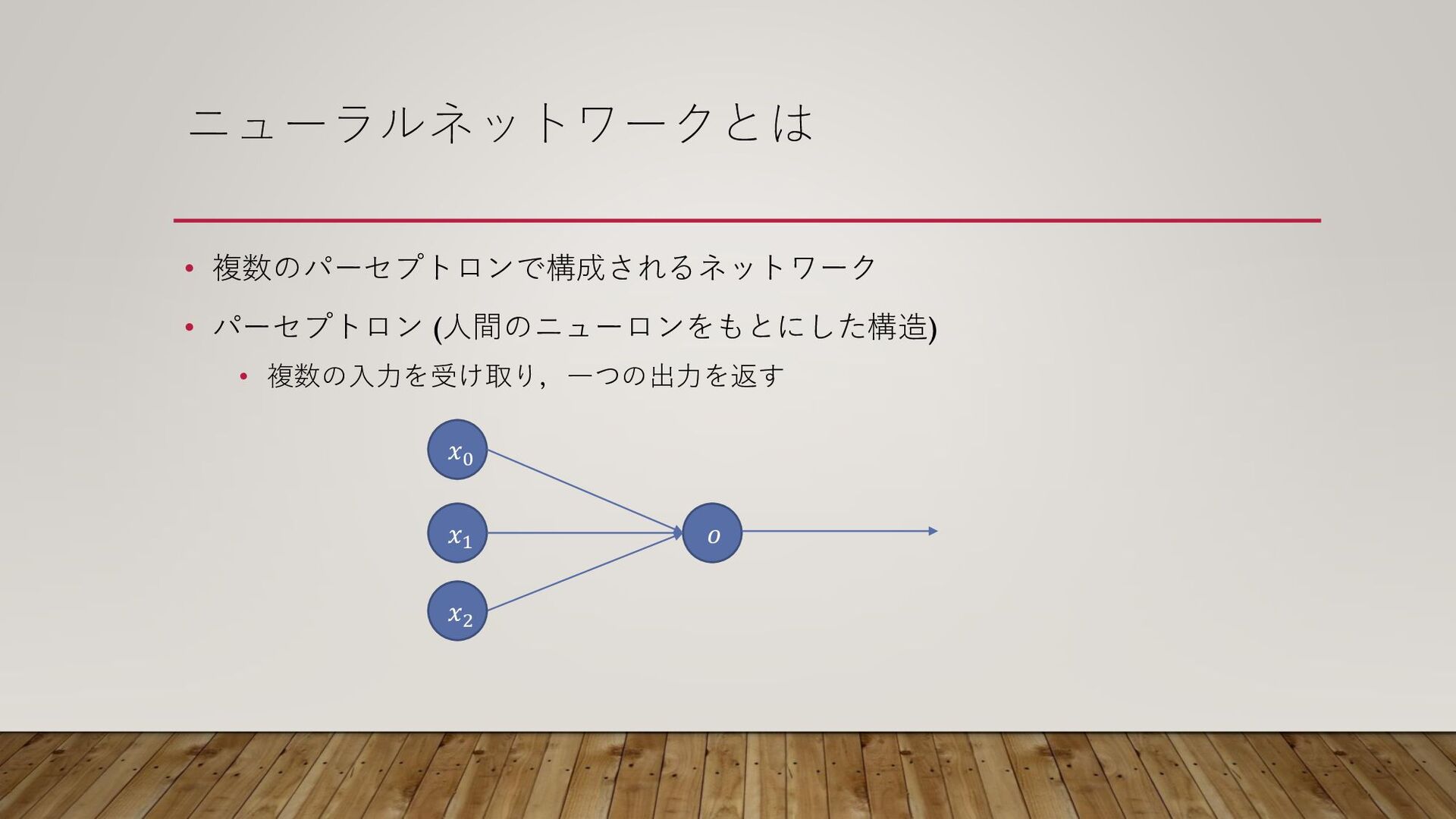
ニューラルネットワークとは • 複数のパーセプトロンで構成されるネットワーク • パーセプトロン (人間のニューロンをもとにした構造) • 複数の入力を受け取り,一つの出力を返す 𝑥0 𝑜
𝑥1 𝑥2
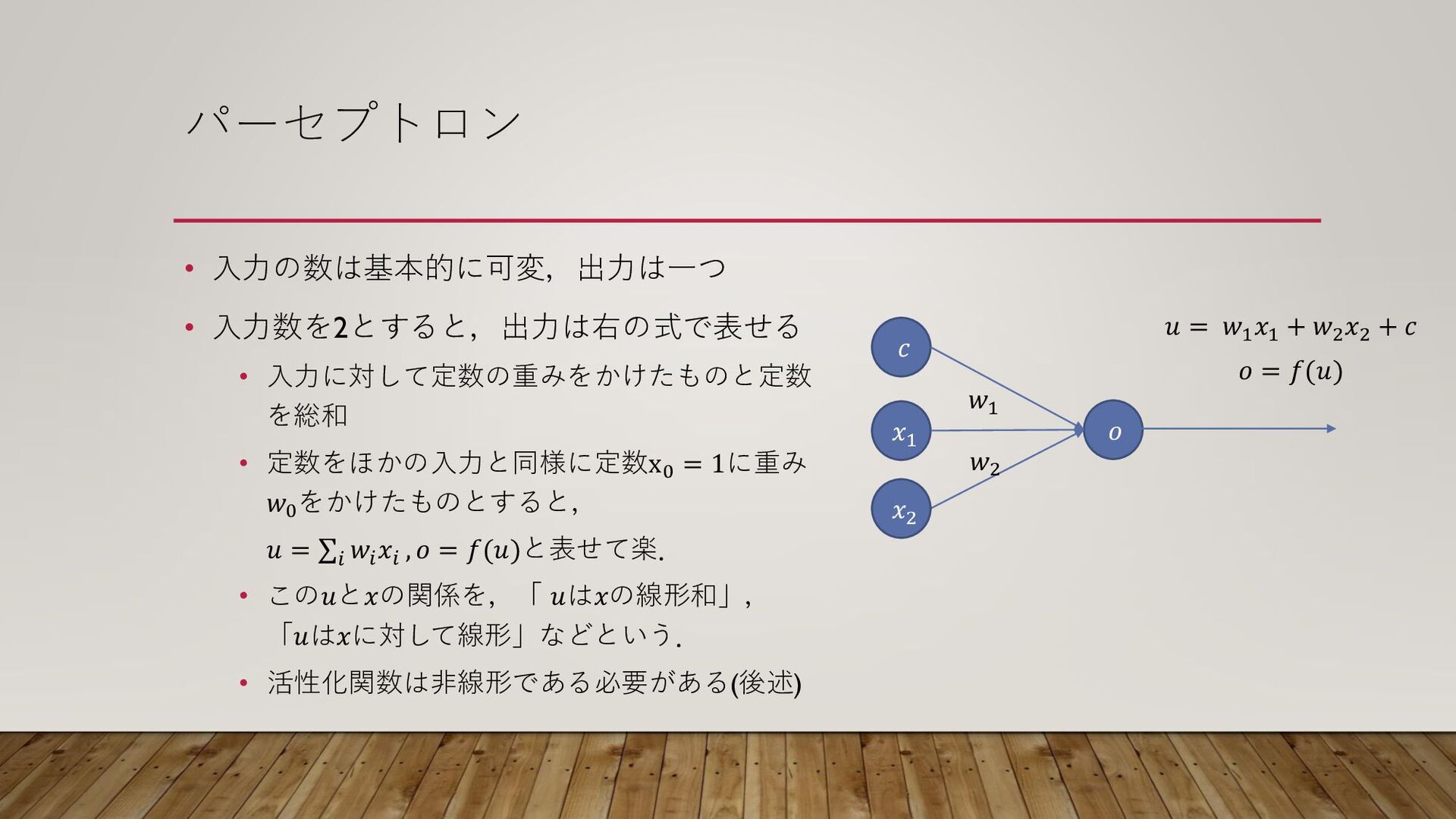
パーセプトロン • 入力の数は基本的に可変,出力は一つ • 入力数を2とすると,出力は右の式で表せる • 入力に対して定数の重みをかけたものと定数 を総和 • 定数をほかの入力と同様に定数x0
= 1に重み 𝑤0 をかけたものとすると, 𝑢 = σ𝑖 𝑤𝑖 𝑥𝑖 , 𝑜 = 𝑓(𝑢)と表せて楽. • この𝑢と𝑥の関係を,「 𝑢は𝑥の線形和」, 「𝑢は𝑥に対して線形」などという. • 活性化関数は非線形である必要がある(後述) 𝑐 𝑜 𝑥1 𝑥2 𝑤1 𝑤2 𝑢 = 𝑤1 𝑥1 + 𝑤2 𝑥2 + 𝑐 𝑜 = 𝑓(𝑢)
1層パーセプトロンの例 • 入力数2つ,𝑓を単位ステップ関数 (右図)とする と,出力は例えば下のようになる • 直線で分けられる
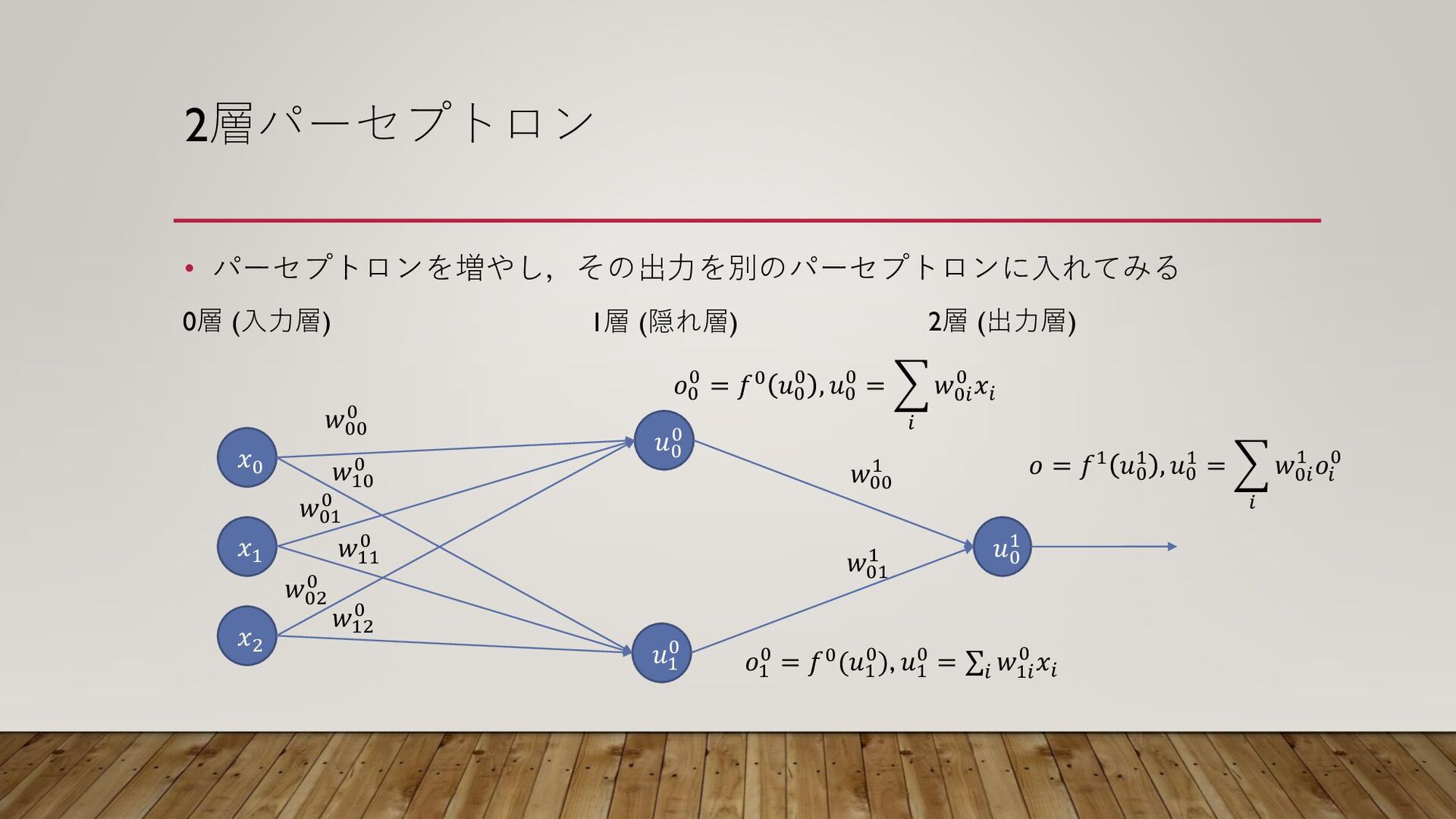
2層パーセプトロン • パーセプトロンを増やし,その出力を別のパーセプトロンに入れてみる 𝑥1 𝑥2 𝑥0 𝑢0 0 𝑢1 0
𝑢0 1 𝑤00 0 𝑤10 0 𝑤01 0 𝑤11 0 𝑤02 0 𝑤12 0 𝑤00 1 𝑤01 1 𝑜0 0 = 𝑓0 𝑢0 0 , 𝑢0 0 = 𝑖 𝑤0𝑖 0 𝑥𝑖 𝑜1 0 = 𝑓0(𝑢1 0), 𝑢1 0 = σ𝑖 𝑤1𝑖 0 𝑥𝑖 𝑜 = 𝑓1 𝑢0 1 , 𝑢0 1 = 𝑖 𝑤0𝑖 1 𝑜𝑖 0 0層 (入力層) 1層 (隠れ層) 2層 (出力層)
2層パーセプトロン • 𝑜は出力 • 添え字で複数のものを区別 • (下添え字1 … 次の層のどこにつながるか) •
重みのみ • 下添え字2 … 今の層のどこか • 上添え字 … 今何層目か • 𝑓についても微分の回数ではない • 例 • 𝑤01 1 … 1層目(0始まり)の0番パーセプトロンから次の1番パーセプトロンへの重み 𝑥1 𝑥2 𝑥0 𝑢0 0 𝑤00 0 𝑤01 0 𝑤02 0 𝑜0 0 = 𝑓0 𝑢0 0 , 𝑢0 0 = 𝑖 𝑤0𝑖 0 𝑥𝑖
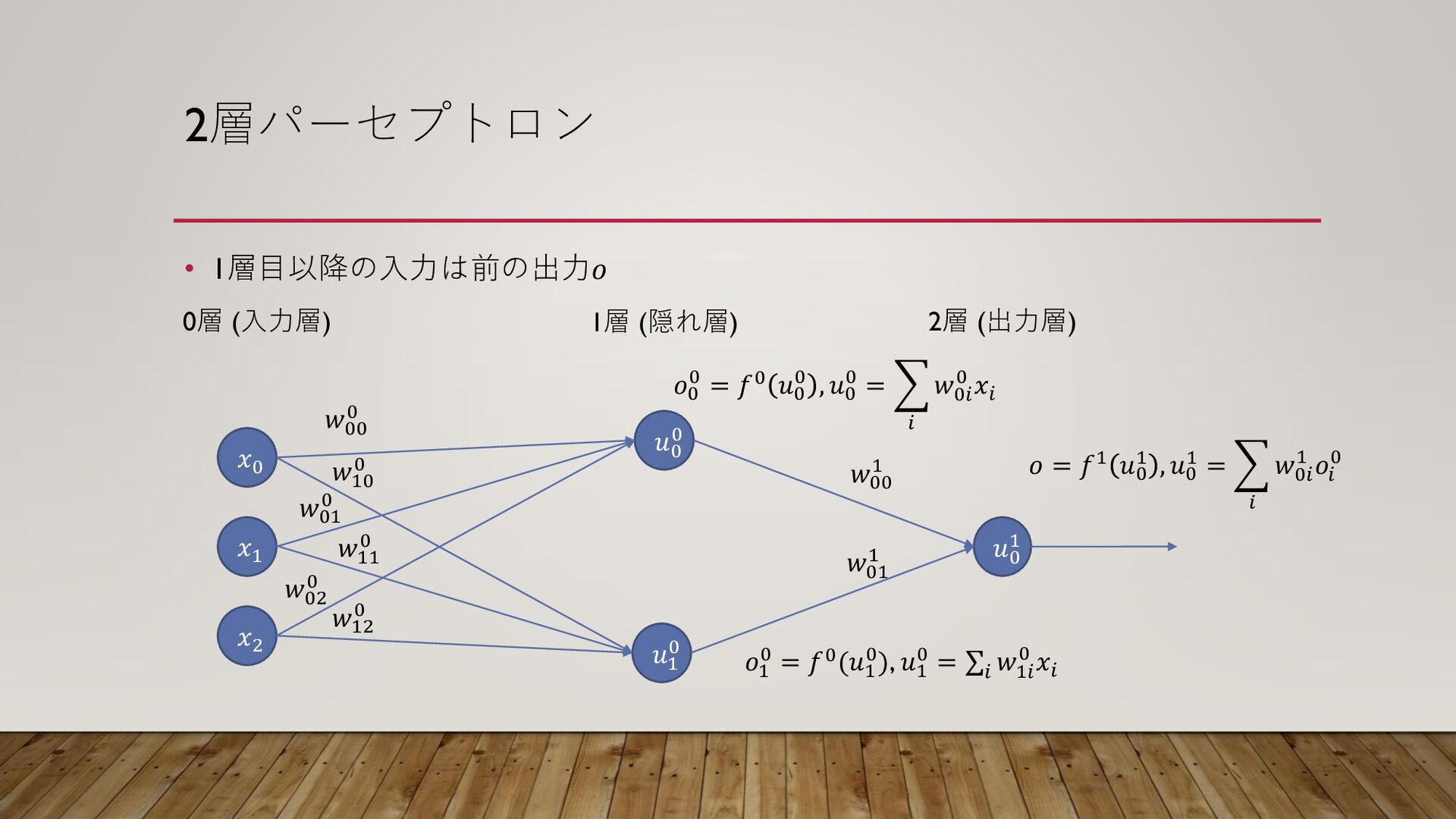
2層パーセプトロン • 1層目以降の入力は前の出力𝑜 𝑥1 𝑥2 𝑥0 𝑢0 0 𝑢1 0
𝑢0 1 𝑤00 0 𝑤10 0 𝑤01 0 𝑤11 0 𝑤02 0 𝑤12 0 𝑤00 1 𝑤01 1 𝑜0 0 = 𝑓0 𝑢0 0 , 𝑢0 0 = 𝑖 𝑤0𝑖 0 𝑥𝑖 𝑜1 0 = 𝑓0(𝑢1 0), 𝑢1 0 = σ𝑖 𝑤1𝑖 0 𝑥𝑖 𝑜 = 𝑓1 𝑢0 1 , 𝑢0 1 = 𝑖 𝑤0𝑖 1 𝑜𝑖 0 0層 (入力層) 1層 (隠れ層) 2層 (出力層)
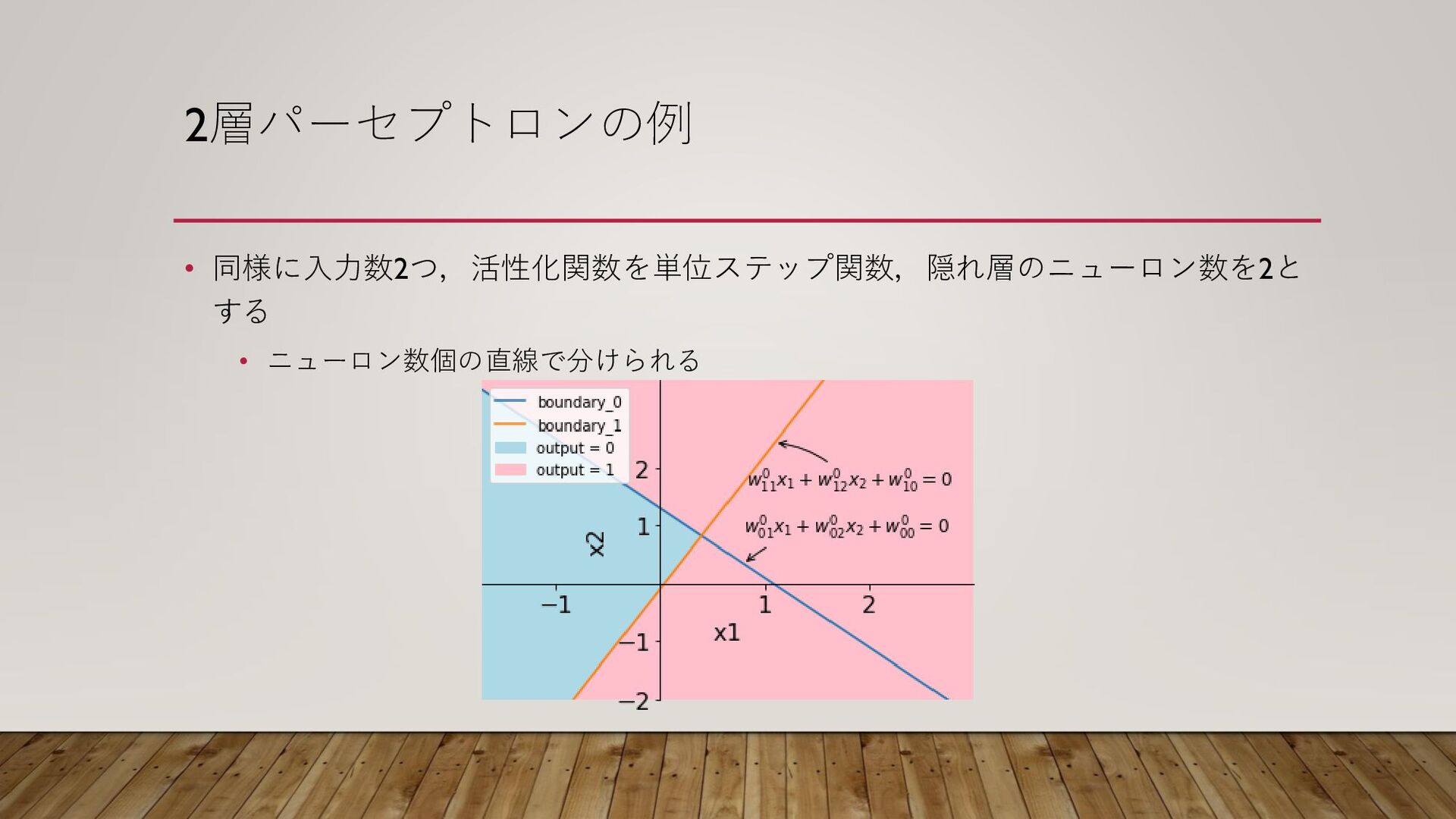
2層パーセプトロンの例 • 同様に入力数2つ,活性化関数を単位ステップ関数,隠れ層のニューロン数を2と する • ニューロン数個の直線で分けられる
ニューラルネットワークの完全性 • 以上のようなパーセプトロンを用いたネットワークをニューラルネットワークと 呼ぶ. • 三層以上のニューラルネットワークは,適切な(大量の)ニューロン数を用意すれ ば任意の関数を実現できる • 視覚的な説明 https://nnadl-ja.github.io/nnadl_site_ja/chap4.html
• 一般には大量のニューロン(数千~)を多層 (数十程度)積み重ねる
(補足)行列表示 • 実用的には大量のニューロンを用意する • →添え字表示はあまりに面倒 • →行列(テンソル)とベクトルで表示するのが一般的 • 駒場の線形代数でやると思うので軽く触れます
(補足)行列表示 𝑥1 𝑥2 𝑥0 𝑢0 𝑢1 𝑜 𝒐0 = 𝒇0
𝑾0𝒙 𝑜 = 𝑓1 𝑾1𝒐0 0層 (入力層) 1層 (隠れ層) 2層 (出力層) 𝑾0 𝒙 𝑾1 • 行列は大文字,太字はベクトル
ニューラルネットワークの学習 • 大量のニューロンとを用意して,適切に重みを設定すれば任意の関数を表現できる • 画像を入力して,クラスを出力(分類) • 音声を入力してテキストを出力(音声処理) 等 • 天文学的な数の重みを手動で調整するのは現実的でない
• →自動的に学習させてしまう
ニューラルネットワークの学習 • 重みつきの関数𝑓(𝑥; 𝑊) (𝑥: 入力, 𝑊: 重み)を任意の𝑥に対して最適な出力𝑦(𝑥)を得 られるように最適化する •
最適さの定式化? • 最適化の方法? • 任意の𝑥に対して?
最適さの定式化(機械学習) • 出力𝑓(𝑥𝑖 )と正解𝑦(𝑥)の「距離」が近ければ近いほどよい • これを損失𝐿といい,損失を返す関数は損失関数と呼ぶ • 小さいほど良い • 入力の種類,用途によってさまざま
• スカラ,ベクトル値によく使われるもの • L1 Loss σ𝑖 |𝑦(𝑥𝑖 ) − 𝑓(𝑥𝑖 )| • L2 Loss (最小二乗誤差, MSE) σ𝑖 𝑦(𝑥𝑖 ) − 𝑓 𝑥𝑖 2 • クロスエントロピー誤差 σ𝑖 𝑦(𝑥𝑖 ) log 𝑓 𝑥𝑖 ※σ𝑖 (1 − 𝑦 𝑥𝑖 ) log 1 − 𝑓 𝑥𝑖 を足すことも
最適化の方法 • 損失関数を用いれば,重みの最適化は「損失𝐿を重み𝑊の関数とみて,それを任 意の𝑥に対して最小にするような重み𝑊を求めること」といえる. • 解析的に最小値を求められない場合の最小化
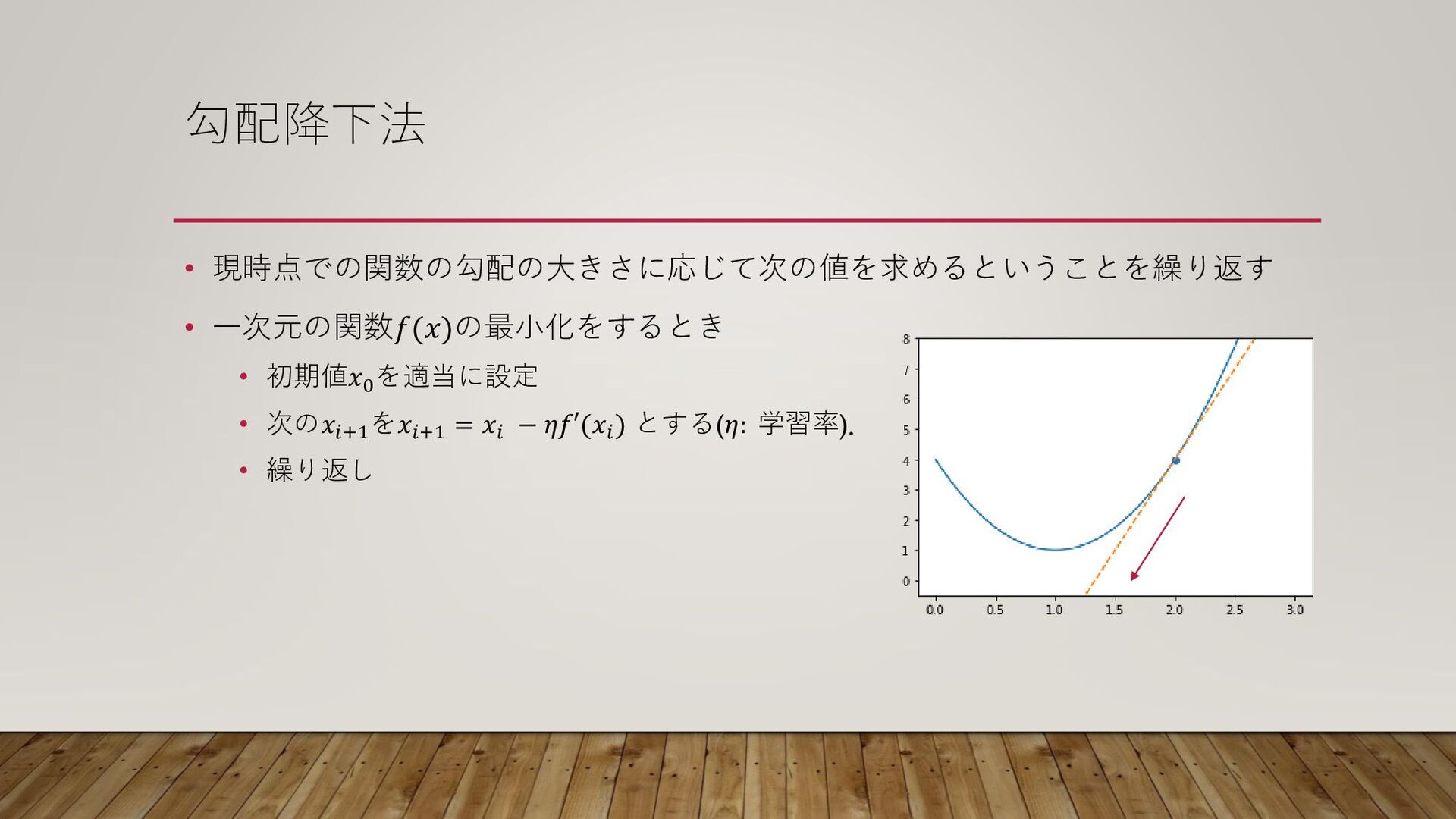
勾配降下法 • 現時点での関数の勾配の大きさに応じて次の値を求めるということを繰り返す • 一次元の関数𝑓(𝑥)の最小化をするとき • 初期値𝑥0 を適当に設定 • 次の𝑥𝑖+1
を𝑥𝑖+1 = 𝑥𝑖 − 𝜂𝑓′(𝑥𝑖 ) とする(𝜂: 学習率). • 繰り返し
変数が複数の時の微分 • 重みに対しても同じように考えたいが,損失関数は1変数関数ではない • →偏微分 • 2変数以上の関数で,一つの入力に対し,ほかの入力を変化させずに微分することを 偏微分という • 関数𝑓
𝑥0 , 𝑥1 , … の𝑥0 による偏微分𝑓𝑥0 は,lim ℎ→0 𝑓 𝑥0+ℎ,𝑥1,… −𝑓(𝑥0,𝑥1,… ) ℎ • 基本普通に微分するだけ • ほかの変数についても同様 • 偏微分は𝑓𝑥0 , 𝑓𝑥0 (𝑥0 , 𝑥1 , … ) 𝜕𝑓 𝜕𝑥0 , 𝜕 𝜕𝑥0 𝑓 𝑥0 , 𝑥1 , … などのように表される • 𝜕 は「partial」「round d」などと呼ばれる • 微分積分学でやります (1A?)
連鎖律 • 損失関数の重み𝑤𝑖𝑗 𝑘 による偏微分を求めたい • 損失関数は入力と重みを入力とする合成関数 • →解析的に求められる •
(復習) 一変数の合成関数の微分 • 𝑑 𝑑𝑥 𝑓 𝑔 𝑥 = 𝑔′ 𝑥 𝑓′ 𝑔 𝑥 • 𝑑 𝑑𝑥 𝑓 𝑔 ℎ(𝑥) = ℎ′(𝑥)𝑔′ ℎ(𝑥) 𝑓′(𝑔(ℎ(𝑥)))
連鎖律 • 𝑛入力関数𝑓(𝑠0 , … ), 𝑛個の𝑚入力関数𝑔𝑖 (𝑡0 , …
)による,𝑚入力の合成関数ℎ 𝑡0 , … = 𝑓 𝑔0 (𝑡0 , … , … )の𝑡𝑗 による偏微分は, 𝜕𝑓 𝜕𝑡𝑗 = 𝑖 𝑚 𝜕𝑓 𝜕𝑠𝑖 𝜕𝑔𝑖 𝜕𝑡𝑗 • 𝑠𝑖 = 𝑔𝑖 (𝑡0 , … )なので,下のように表記することが多い 𝜕𝑓 𝜕𝑡𝑗 = 𝑖 𝑚 𝜕𝑓 𝜕𝑔𝑖 𝜕𝑔𝑖 𝜕𝑡𝑗 • 一変数の時のやつを,内側の関数全部にやって,それを総和
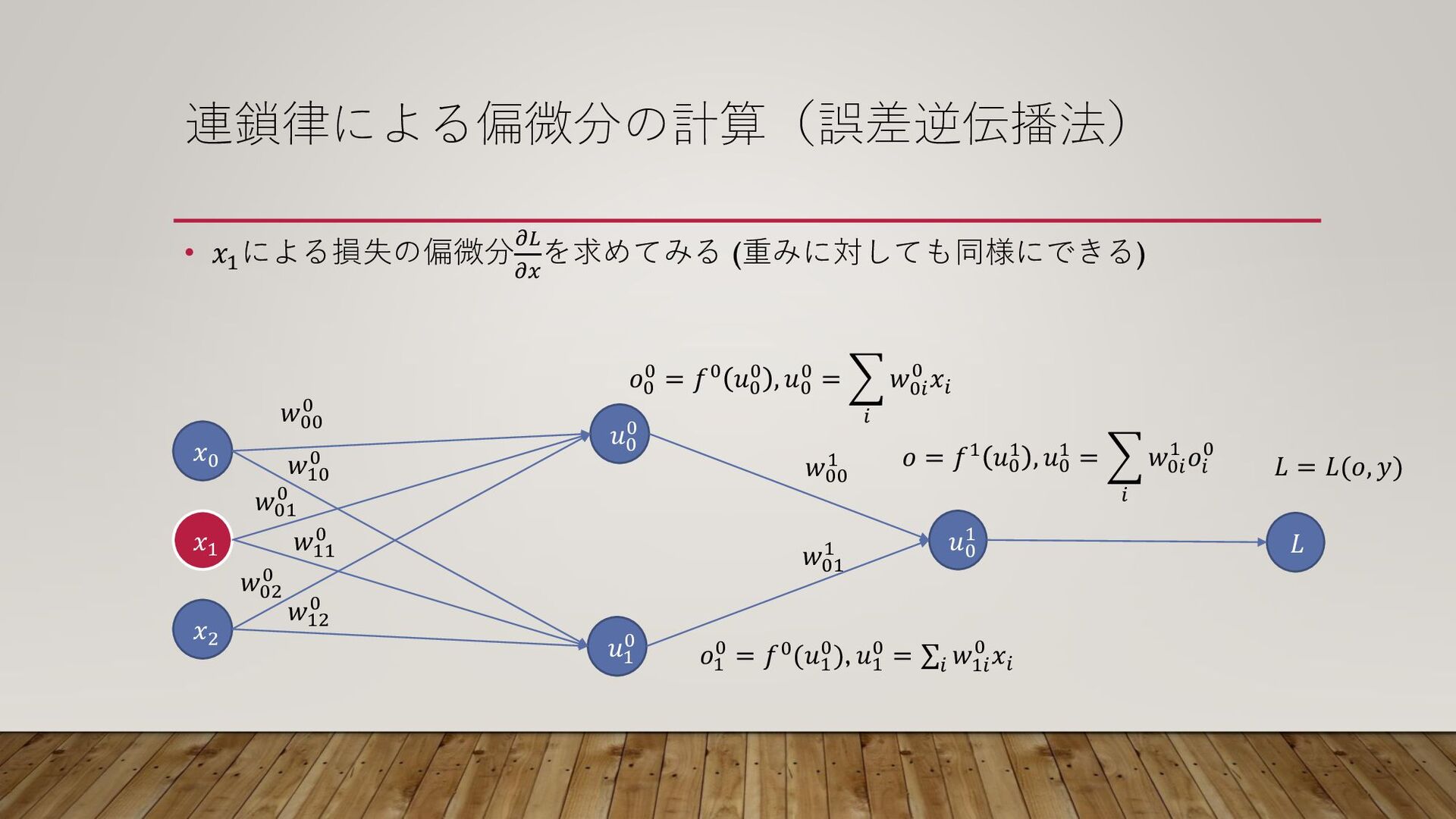
連鎖律による偏微分の計算(誤差逆伝播法) • 𝑥1 による損失の偏微分𝜕𝐿 𝜕𝑥 を求めてみる (重みに対しても同様にできる) 𝐿 𝑥1 𝑥2
𝑥0 𝑢0 0 𝑢1 0 𝑢0 1 𝑤00 0 𝑤10 0 𝑤01 0 𝑤11 0 𝑤02 0 𝑤12 0 𝑤00 1 𝑤01 1 𝑜0 0 = 𝑓0 𝑢0 0 , 𝑢0 0 = 𝑖 𝑤0𝑖 0 𝑥𝑖 𝑜1 0 = 𝑓0(𝑢1 0), 𝑢1 0 = σ𝑖 𝑤1𝑖 0 𝑥𝑖 𝑜 = 𝑓1 𝑢0 1 , 𝑢0 1 = 𝑖 𝑤0𝑖 1 𝑜𝑖 0 𝐿 = 𝐿(𝑜, 𝑦)
連鎖律による偏微分の計算(誤差逆伝播法) • 𝜕𝐿 𝜕𝑥1 = 𝜕𝐿 𝜕𝑦 𝜕𝑦 𝜕𝑥1 +
𝜕𝐿 𝜕𝑜 𝜕𝑜 𝜕𝑥1 = 𝜕𝐿 𝜕𝑜 𝜕𝑜 𝜕𝑥1 (正解ラベルは定数) • 𝜕𝑜 𝜕𝑥1 = 𝑑𝑜 𝑑𝑢0 1 𝜕𝑢0 1 𝜕𝑥1 = (𝑓1)′(𝑢0 1) 𝜕𝑢0 1 𝜕𝑥1 (𝑓は一変数関数) 𝐿 𝑢0 1 𝑜 = 𝑓1 𝑢0 1 𝐿 = 𝐿(𝑜, 𝑦)
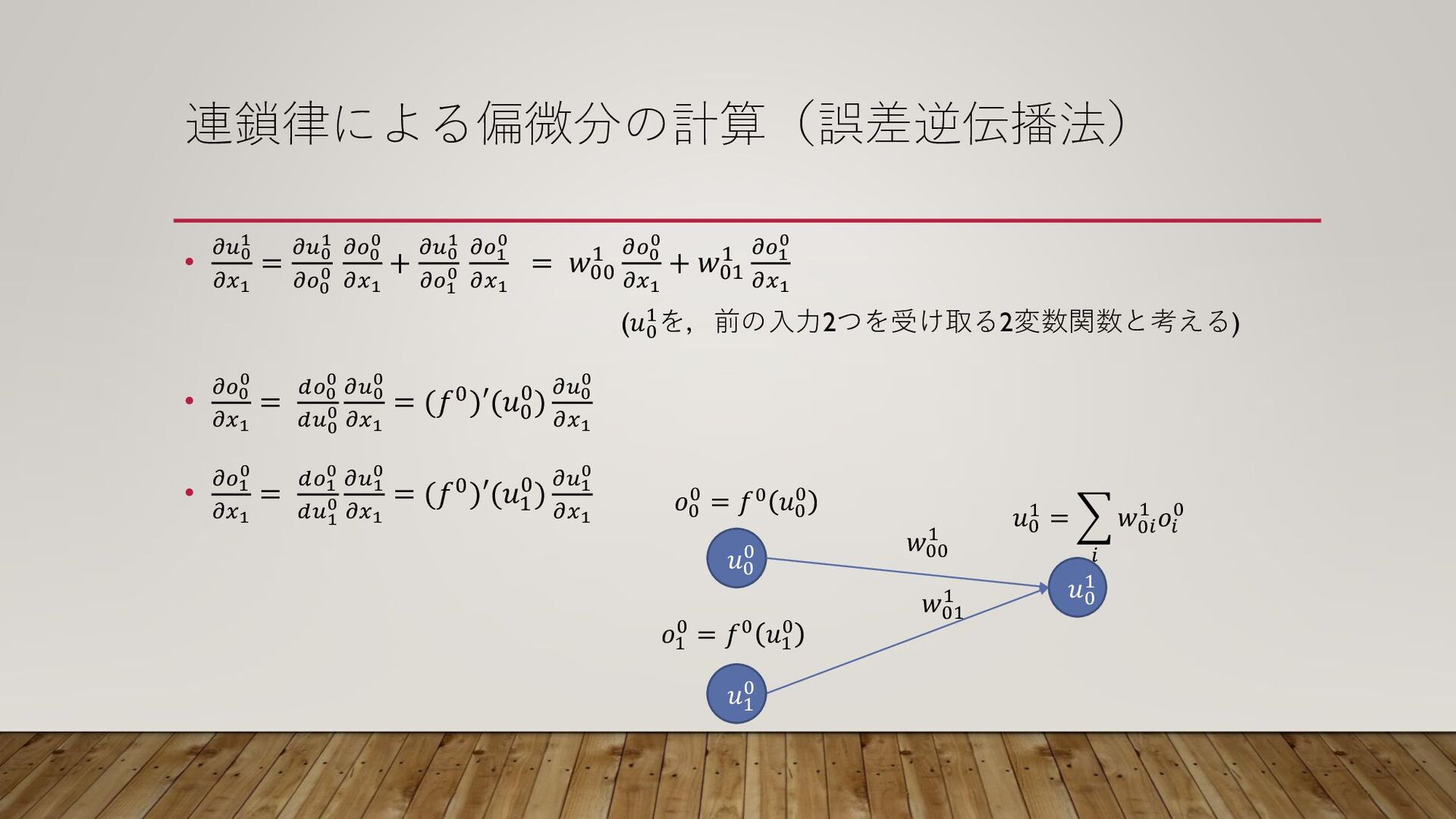
連鎖律による偏微分の計算(誤差逆伝播法) • 𝜕𝑢0 1 𝜕𝑥1 = 𝜕𝑢0 1 𝜕𝑜0 0
𝜕𝑜0 0 𝜕𝑥1 + 𝜕𝑢0 1 𝜕𝑜1 0 𝜕𝑜1 0 𝜕𝑥1 = 𝑤00 1 𝜕𝑜0 0 𝜕𝑥1 + 𝑤01 1 𝜕𝑜1 0 𝜕𝑥1 (𝑢0 1を,前の入力2つを受け取る2変数関数と考える) • 𝜕𝑜0 0 𝜕𝑥1 = 𝑑𝑜0 0 𝑑𝑢0 0 𝜕𝑢0 0 𝜕𝑥1 = (𝑓0)′(𝑢0 0) 𝜕𝑢0 0 𝜕𝑥1 • 𝜕𝑜1 0 𝜕𝑥1 = 𝑑𝑜1 0 𝑑𝑢1 0 𝜕𝑢1 0 𝜕𝑥1 = (𝑓0)′(𝑢1 0) 𝜕𝑢1 0 𝜕𝑥1 𝑢0 0 𝑢1 0 𝑢0 1 𝑤00 1 𝑤01 1 𝑢0 1 = 𝑖 𝑤0𝑖 1 𝑜𝑖 0 𝑜0 0 = 𝑓0 𝑢0 0 𝑜1 0 = 𝑓0 𝑢1 0
連鎖律による偏微分の計算(誤差逆伝播法) • 𝜕𝑢0 0 𝜕𝑥1 = 𝑤01 0 , 𝜕𝑢1
0 𝜕𝑥1 = 𝑤11 0 • よって, 𝜕𝐿 𝜕𝑥1 = 𝜕𝐿 𝜕𝑜 (𝑓1)′(𝑢0 1) 𝑤00 1 (𝑓0)′(𝑢0 0)𝑤01 0 + 𝑤01 1 (𝑓0)′(𝑢1 0)𝑤11 0 • →損失を計算する際に途中結果を保存しておけば効率よく計算可能 • 後ろから伝播していくようなので,誤差逆伝播法と呼ぶ. 𝑥1 𝑢0 0 𝑤01 0 𝑢0 0 = 𝑖 𝑤0𝑖 0 𝑥𝑖 𝑢1 0 𝑤11 0 𝑢1 0 = 𝑖 𝑤1𝑖 0 𝑥𝑖
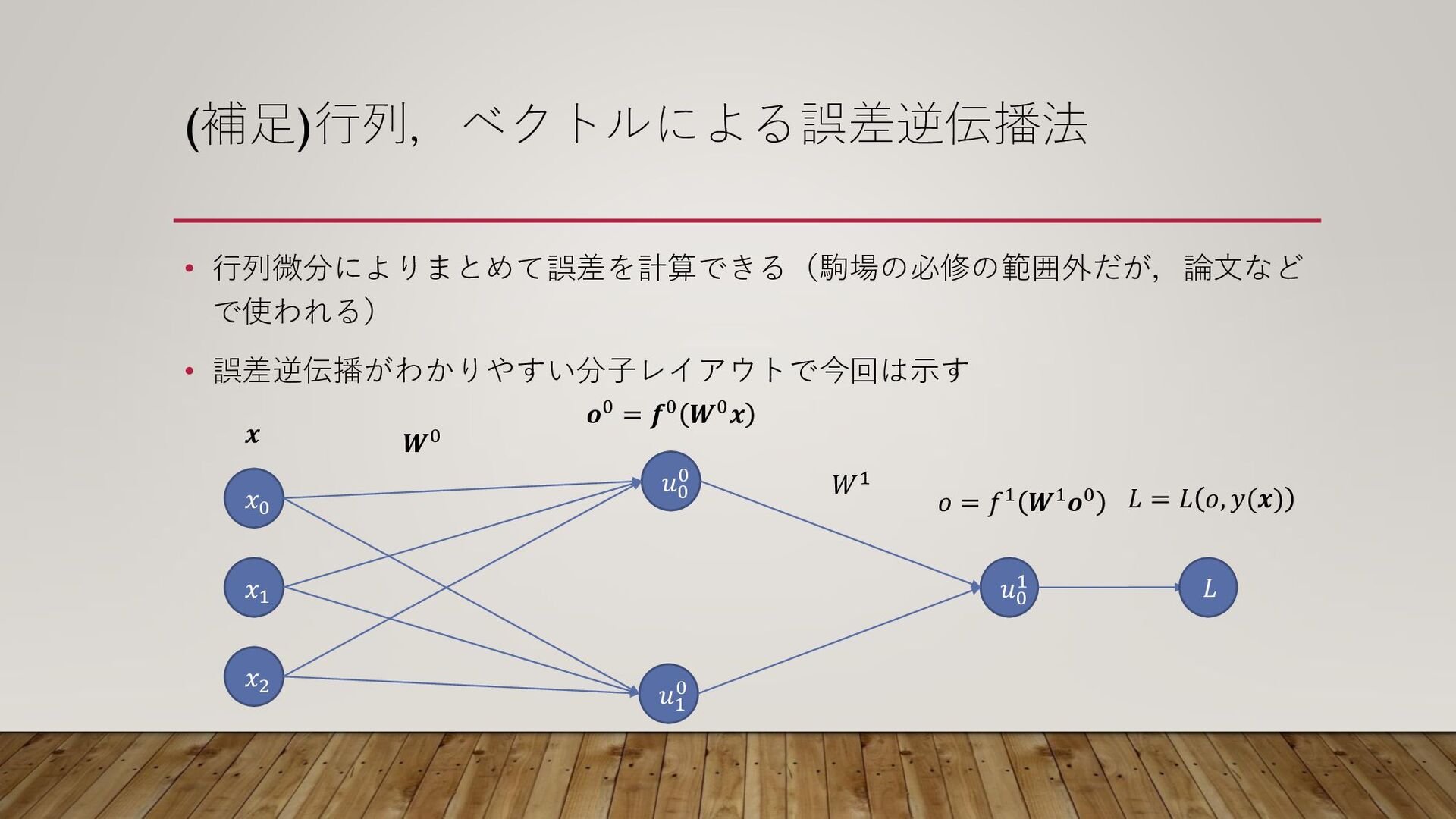
(補足)行列,ベクトルによる誤差逆伝播法 • 行列微分によりまとめて誤差を計算できる(駒場の必修の範囲外だが,論文など で使われる) • 誤差逆伝播がわかりやすい分子レイアウトで今回は示す 𝑥1 𝑥2 𝑥0 𝑢0
0 𝑢1 0 𝑢0 1 𝒐0 = 𝒇0 𝑾0𝒙 𝑜 = 𝑓1 𝑾1𝒐0 𝑾0 𝑊1 𝒙 𝐿 𝐿 = 𝐿 𝑜, 𝑦(𝒙)
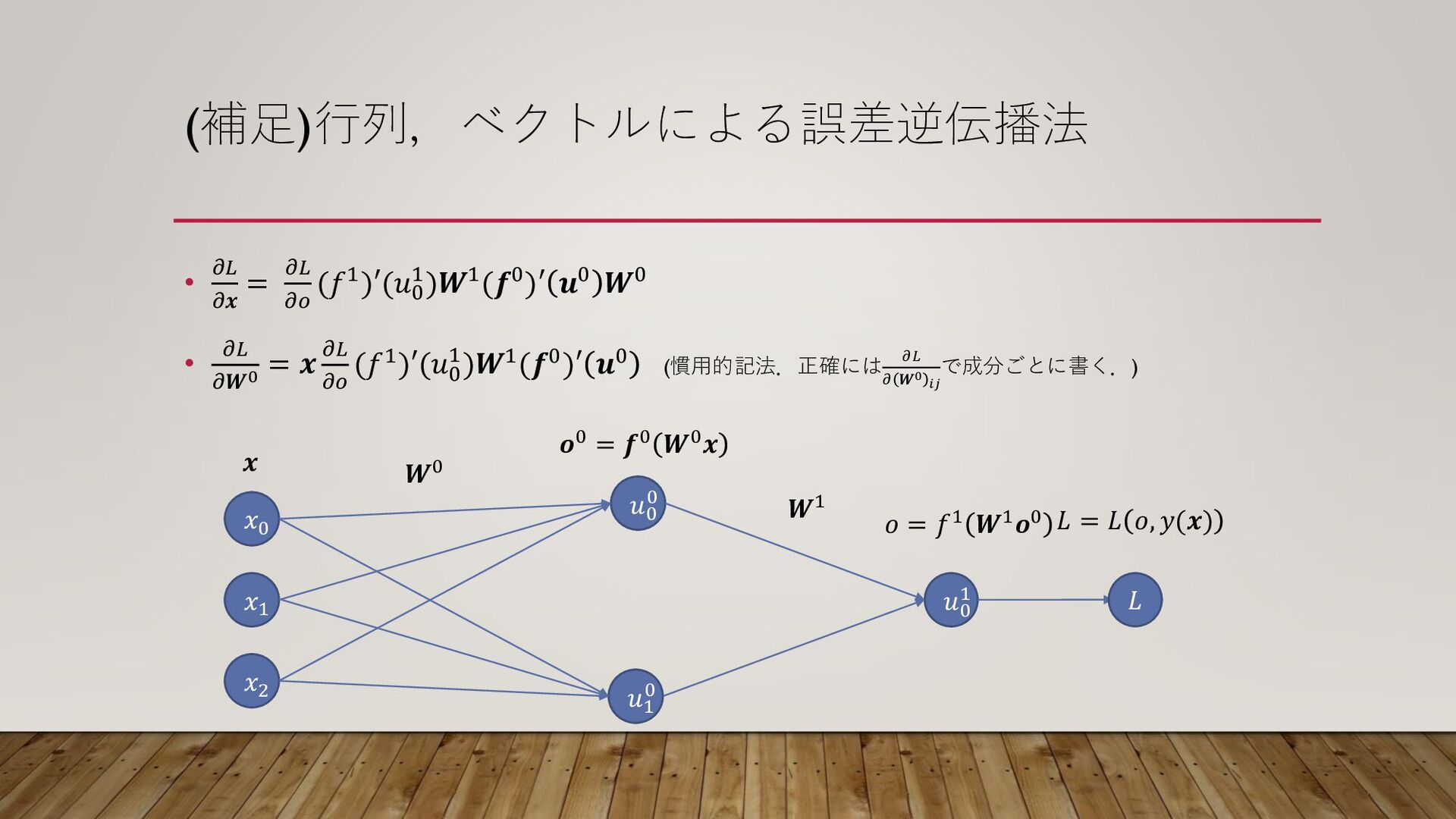
(補足)行列,ベクトルによる誤差逆伝播法 • 𝜕𝐿 𝜕𝒙 = 𝜕𝐿 𝜕𝑜 (𝑓1)′(𝑢0 1)𝑾1(𝒇0)′ 𝒖0
𝑾0 • 𝜕𝐿 𝜕𝑾0 = 𝒙 𝜕𝐿 𝜕𝑜 (𝑓1)′(𝑢0 1)𝑾1(𝒇0)′ 𝒖0 (慣用的記法.正確には 𝜕𝐿 𝜕 𝑾0 𝑖𝑗 で成分ごとに書く.) 𝑥1 𝑥2 𝑥0 𝑢0 0 𝑢1 0 𝑢0 1 𝒐0 = 𝒇0 𝑾0𝒙 𝑜 = 𝑓1 𝑾1𝒐0 𝑾0 𝑾1 𝒙 𝐿 𝐿 = 𝐿 𝑜, 𝑦(𝒙)
誤差逆伝播法 • 解析的に計算できるためには.損失関数𝐿,活性化関数𝑓は解析的に微分が計算で きないといけない • ステップ関数はそもそも𝑥 = 0で微分不可 • よく使われる活性化関数
• シグモイド関数 • ReLU関数 • Leaky ReLU関数
確率的勾配降下法(SGD) • データセット 𝑥 𝑖 の数が巨大な時は,毎回の更新時にすべての𝑥に対して最小化する のは無駄そう? • データセットの中から一部(バッチ)をとってきてそれに対して勾配を求めて重みを更新す る
• これを確率的勾配降下法と呼ぶ • アルゴリズム (𝑚は一つのバッチに含まれるデータの数) • 重み初期値𝑊0 • 𝑊𝑖+1 = 𝑊𝑖 − 𝜂 ⋅ 1 𝑚 σ𝑗 𝑚 𝜕𝐿 𝜕𝑊 𝑇 • 以上をすべてのバッチに対して行う • 繰り返し • 局所最適解にはまるのを防ぐ効果も(後述)
性能の限界 • このあたりのアルゴリズムは1990年代までには考案されていた • しかし,様々な問題があったため,実用性に欠けていた • データの不足 • 局所最適解に陥りやすい •
収束が遅すぎる • 勾配消失問題,勾配爆発問題
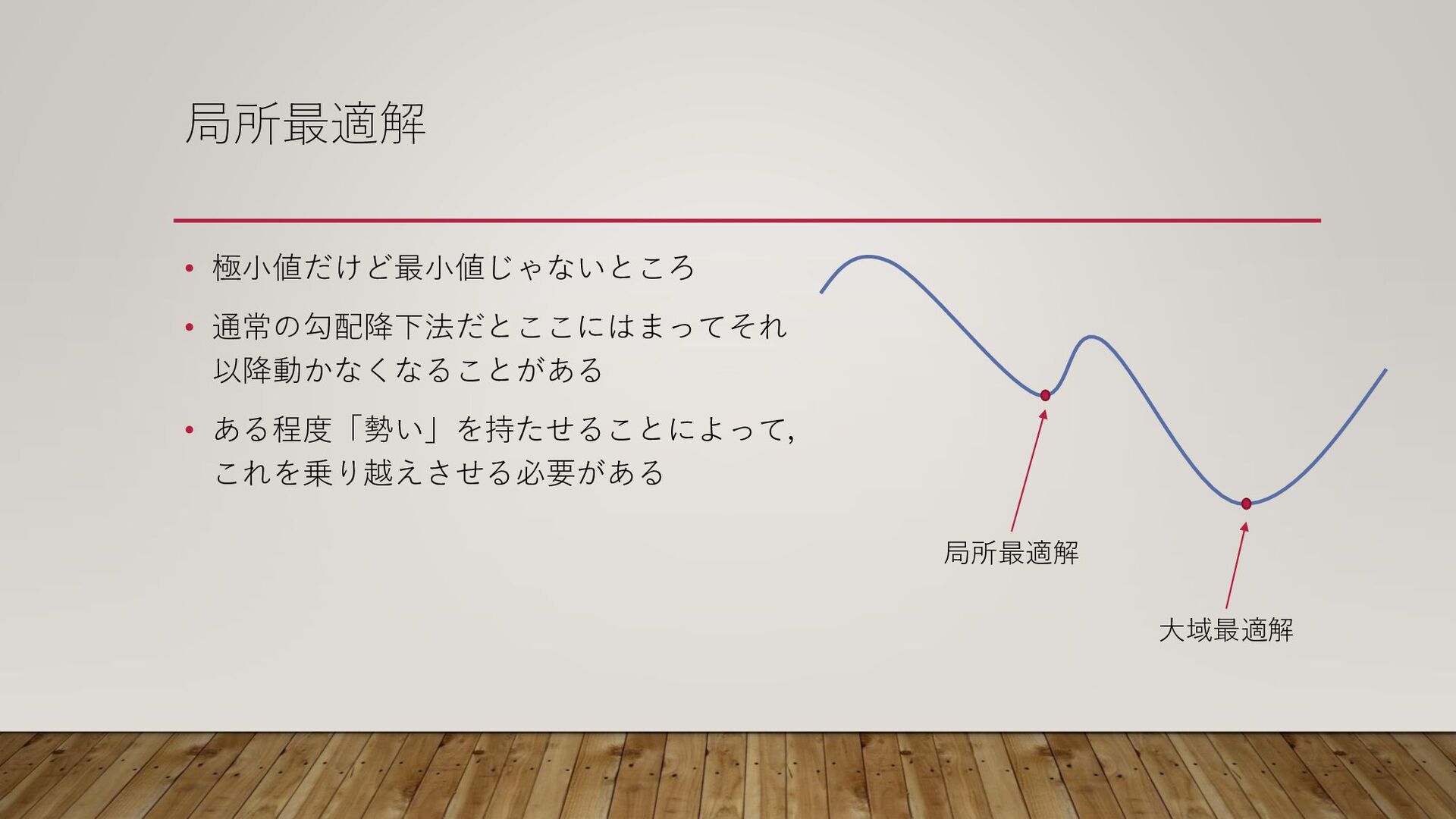
局所最適解 • 極小値だけど最小値じゃないところ • 通常の勾配降下法だとここにはまってそれ 以降動かなくなることがある • ある程度「勢い」を持たせることによって, これを乗り越えさせる必要がある 局所最適解
大域最適解
収束が遅い • SGDは最適解にはまらずずっとウロチョロ動く • Pathological Curveにはまってしまう • Pathological Curve •
鋭いくぼみを持つ形状. • 確率的勾配降下法は勾配が大きいほど動くため, この間をウロチョロ動いてしまう • 学習率をうまく制御すれば…? 実際の動き 理想の動き
様々な確率的最大化 • 一応SGD自体にもこれを防ぐ効果はある • Momentum SGD … 「勢い」を表す項の追加 • RMS
Prop … 前に大きく変化したところは変化を抑える • Adam … momentum, RMSの合わせ技 • 現在ではよく使われる • 一般的にAdamが良い性能を示すことが多いが,実際にどのアルゴリズムを使う のがいいかはネットワークによって異なる. • 各アルゴリズムの可視化→https://imgur.com/a/Hqolp
勾配消失問題 • 多層ネットワークの勾配はさっき見たように何項もの積で表される • 各項が1よりも小さければ勾配はものすごく小さくなり,学習が遅くなる(勾配消失) • こっちのほうが起こりやすい • 各項が1よりも大きければ勾配はものすごく大きくなり,学習が不安定になる(勾配爆発) •
活性化関数としてのSigmoid関数 • かつてはよく使われた • 入力の絶対値がある程度大きいと微分がほぼ0 • →勾配消失問題を加速 • 計算が不安定になりやすい
勾配消失問題の解決 • 活性化関数としてReLU (上)を採用 • 入力が正なら微分は正の定数 (1) • 入力が負の時は微分は0 •
あまりよくない…? • 最近ではLeaky ReLU (下)を採用することも増えた • 入力が負の時は微分は小さい正の定数 • 0.03などが良く使われる • Shortcutで微分を直接伝える (ResNetなど) • 一部の層に対してそれを通す入力と通さない入力を2つ取り入れる
シグモイド関数についての注意 • Sigmoid君無能じゃん→× • Sigmoid関数の利点 • 出力が[0, 1]に制限される • クロスエントロピー誤差(C
𝑥 = σ𝑖 −𝑦 log 𝑓 𝑥𝑖 − 1 − 𝑦 log(1 − 𝑓 𝑥𝑖 ))と相性がい い • シグモイド関数を𝜎 𝑥 = 1 1+𝑒−𝑥 ,損失を𝐿 𝑢 = 𝐶(𝜎(𝑥))とおく. • 𝜕𝐿 𝜕𝑢 = − 𝑦 𝜎 𝑢 + 1−𝑦 1−𝜎 𝑥 ⋅ 𝜎 𝑢 1 − 𝜎 𝑢 = −𝑦 + 𝜎(𝑢) ※𝜎′ 𝑥 = 𝜎(𝑥)(1 − 𝜎(𝑥)) • →不安定さの原因となる𝜎, 1/𝜎の積が消える • 出力が二値で十分なクラス分類などのネットワークの最後の層の活性化関数としてし ばしば使われる
過学習 • データの本質的な傾向よりも,サンプルデータの傾向を強く学習してしまい,未 知データへの予測結果が劣化すること • 機械学習の目的は標本集団から母集団の性質を推測することなので,未知データを正 しく予測できなければ無価値 • 例 •
過去問の丸暗記 • 右図(3次式+ノイズを多項式近似)
過学習を防ぐ工夫 • データセットを3つに分ける • 訓練データ,検証データ,テストデータ • 訓練データ …モデルの訓練に使用 • 検証データ
…モデルが未知データにも適用可能であるかを調べるために使う • 訓練中に何度もこのデータを使って評価する • テストデータ…すべての訓練が訓練が終わった後に1度だけ使い,最終的な評価を下すために使う • テストデータは2回以上使ってはいけない(厳密には) • テストデータに合うようなモデルを作ってしまえば… • 検証データは訓練に使えない…? • →交差検証
過学習を防ぐ工夫 • 正則化項の追加 • 過学習しているときは重みが異常に大きくなっていることが多い • 損失関数に重みの2乗和などを加える • Drop outの導入
(ニューラルネット限定,後述) • 学習の早期中断 • より表現の乏しいモデル(線形回帰など)を使う • どうしてもとれるデータが少ないとき
様々な工夫(データ処理) • 正規化 • 入力データを一定のルールに従って加工し,利用しやすくすること • 例 各成分について平均0, 標準偏差1になるように前処理する •
範囲が[0, 1]に収まるようにすることもある • 単位の違うデータなどを入力するときは特に効果的 • バッチノーマライゼーションも参照のこと(データ処理じゃないけど) • オーグメンテーション • 入力データの水増し • 例…画像入力の際に,回転した画像,ずらした画像,ノイズを入れた画像もデータに加える
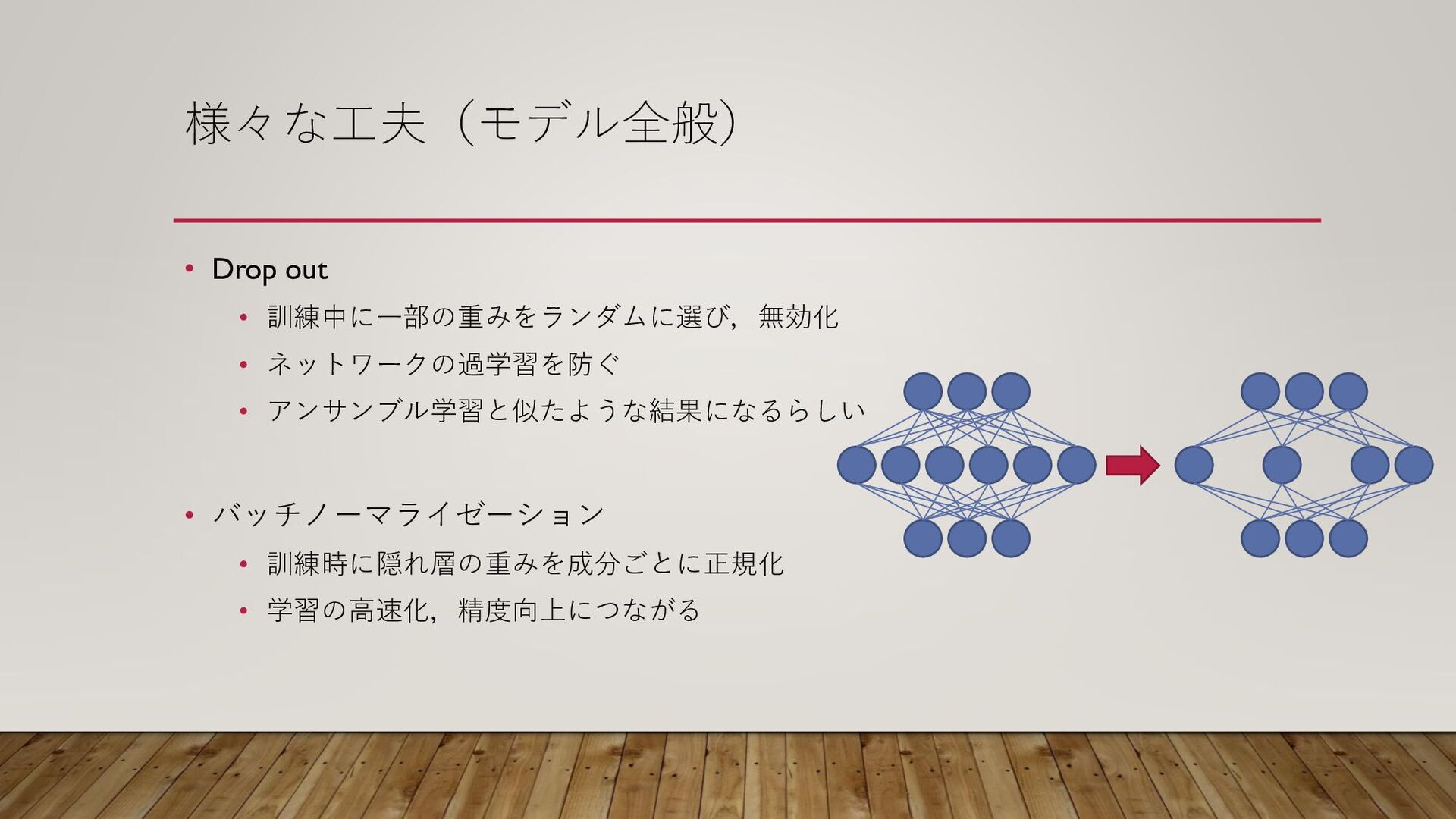
様々な工夫(モデル全般) • Drop out • 訓練中に一部の重みをランダムに選び,無効化 • ネットワークの過学習を防ぐ • アンサンブル学習と似たような結果になるらしい
• バッチノーマライゼーション • 訓練時に隠れ層の重みを成分ごとに正規化 • 学習の高速化,精度向上につながる
様々な工夫(画像) • 畳み込みネットワーク • 画像の局所性,移動普遍性を活用したネットワーク • GAN … 敵対的生成ネットワーク •
フェイク画像を作る側とそれを見抜く側両方のモデルを作って同時に学習させる • 損失関数をつくるのが難しいときに有効 • 学習が不安定になりやすい
様々な工夫(一次元データ) • RNN(LSTM, GRU) • データをループさせることで以前の入力を記憶 • テキスト処理など • Transformer
(Attention機構) • 入力のどこに注目すべきかを表す内部表現を作り,それとデータとの内積をとること で重要なデータを取り出す • テキスト処理など
実際にやってみる • プログラミング言語はPythonが主流 • ライブラリ • Keras + Tensorflow •
Pytorch • JAX/Flax • … • Pytorchが今はおすすめ • Kerasはバージョン間でしばしば互換性がない • Pytorchもだけど,体感こっちのほうがひどい気がする • Pytorchで実装された既存のモデルが多い
参考文献,使用ライブラリ • 参考文献 • ゼロから作るDeep Learning • ニューラルネットワークと深層学習 • NRI
ナレッジ・インサイト 用語解説 • 使用ライブラリ • Pyplot • Scikit-learn
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![シグモイド関数についての注意 • Sigmoid君無能じゃん→× • Sigmoid関数の利点 • 出力が[0, 1]に制限される • クロスエントロピー誤差(C](https://files.speakerdeck.com/presentations/459e21b5322940259466bbd7dcefadd4/slide_35.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}