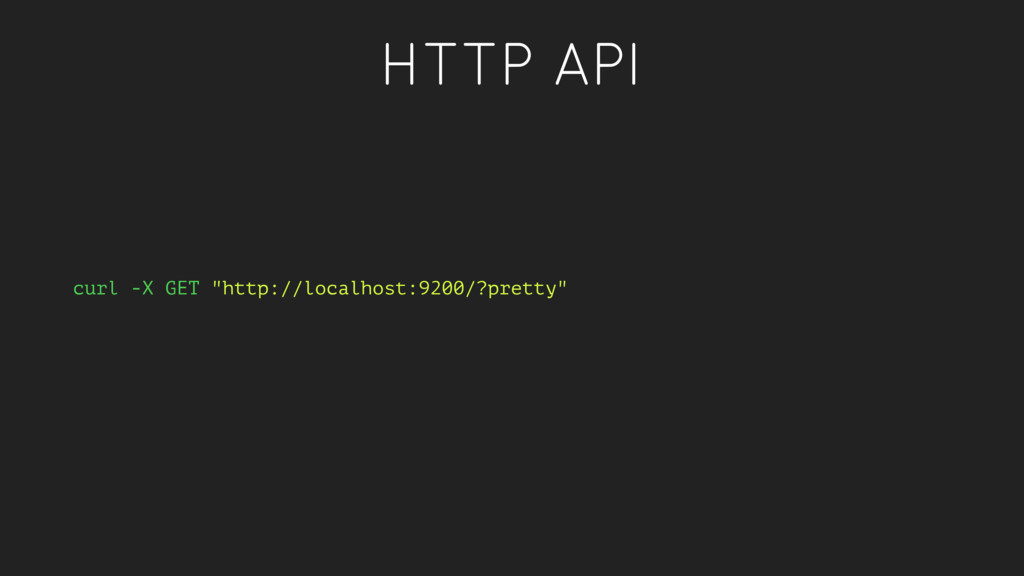
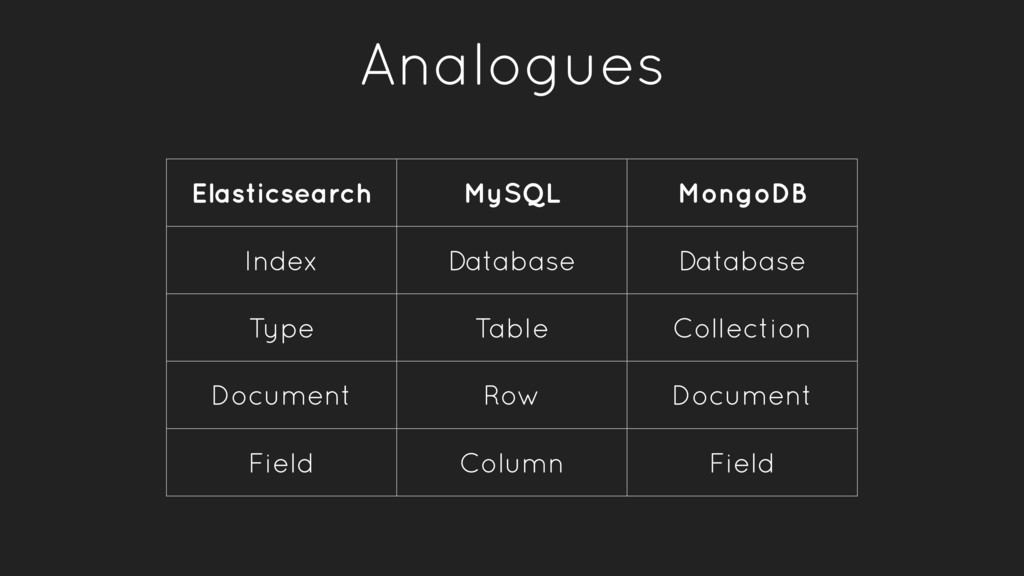
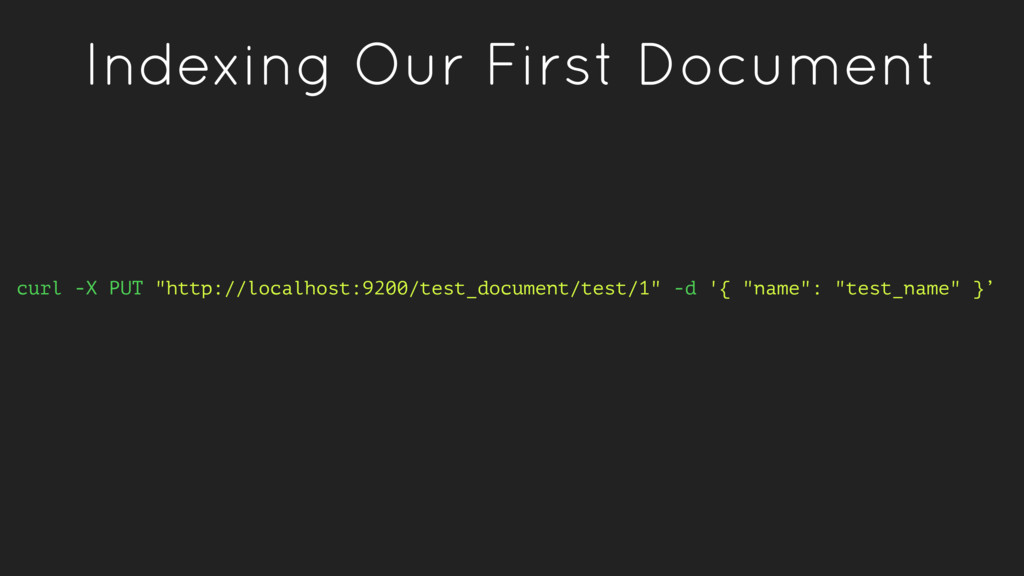
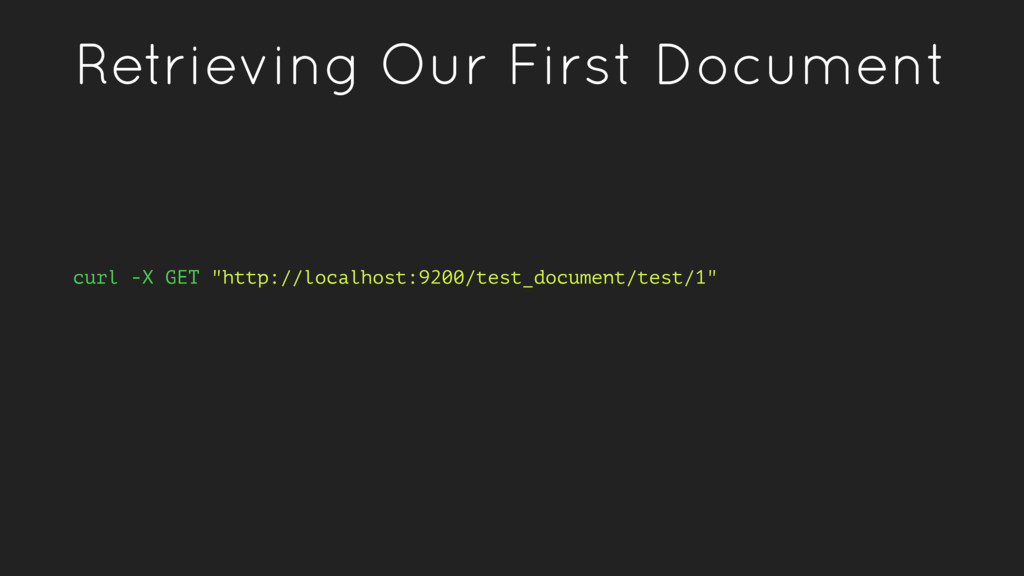
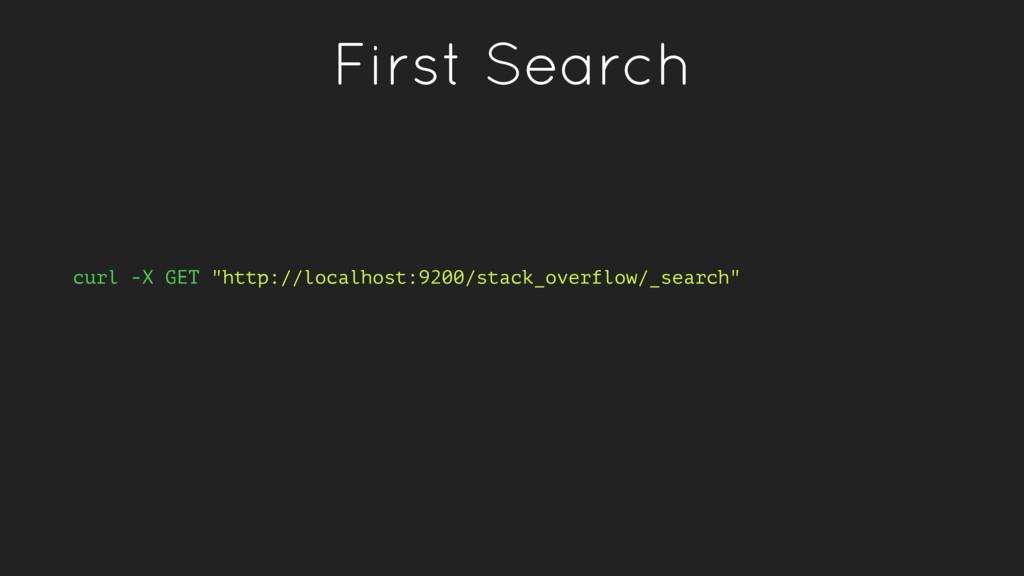
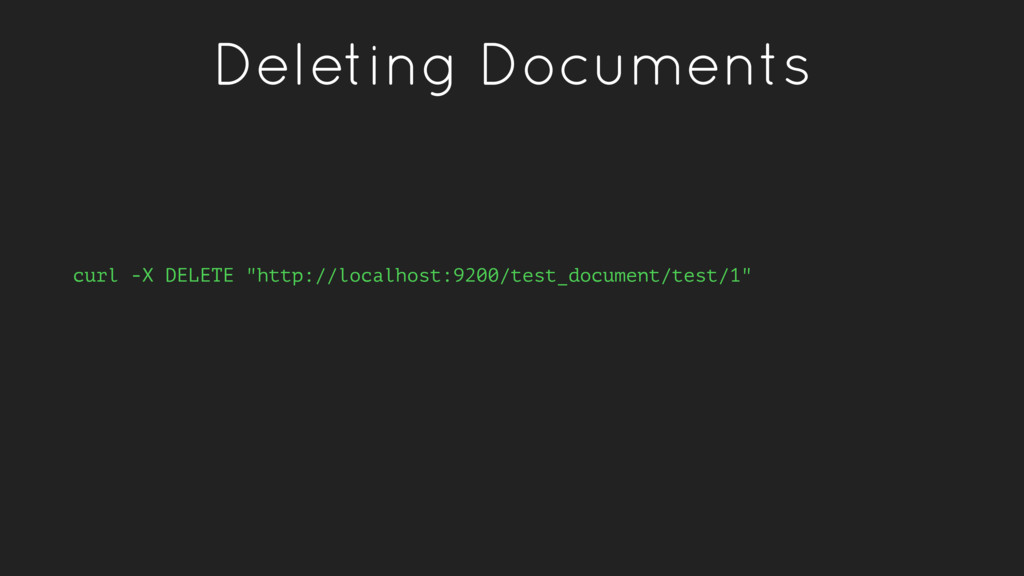
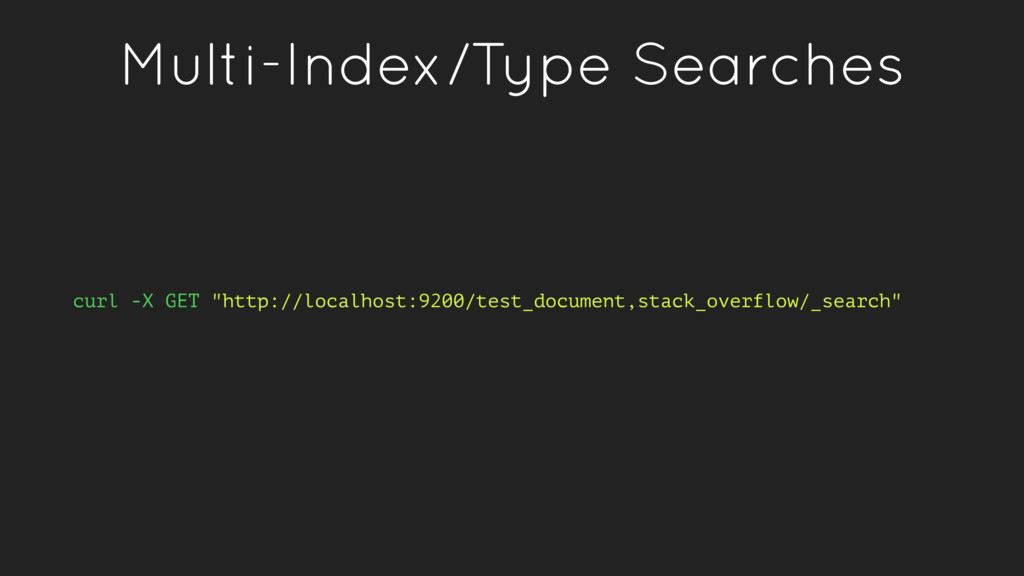
a verb, to index a document is store a document in an index. This is analogous to an SQL INSERT operation. • As a noun, an index is a collection of documents. • Fields within a document have inverted indexes, similar to how a column in an SQL table may have an index.
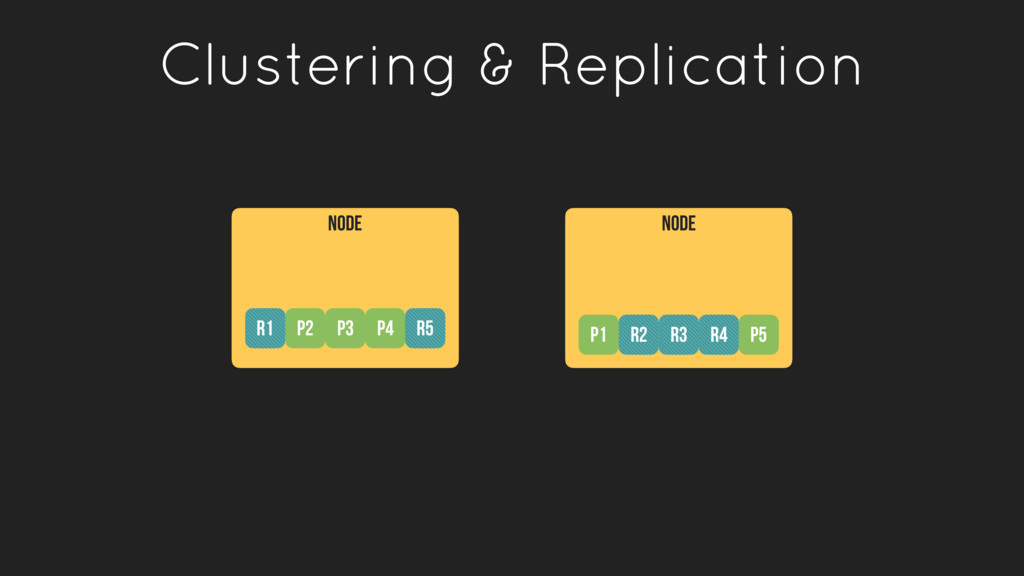
to run in a distributed fashion. • Indices (collections of documents) are partitioned in to shards. • Shards can be stored on a single or multiple nodes. • Shards are balanced across the cluster to improve performance • Shards are replicated for redundancy and high availability
that work together to… • serve a dataset that exceeds the capacity of a single server… • provide federated indexing (writes) and searching (reads)… • provide H/A through sharing and replication of data
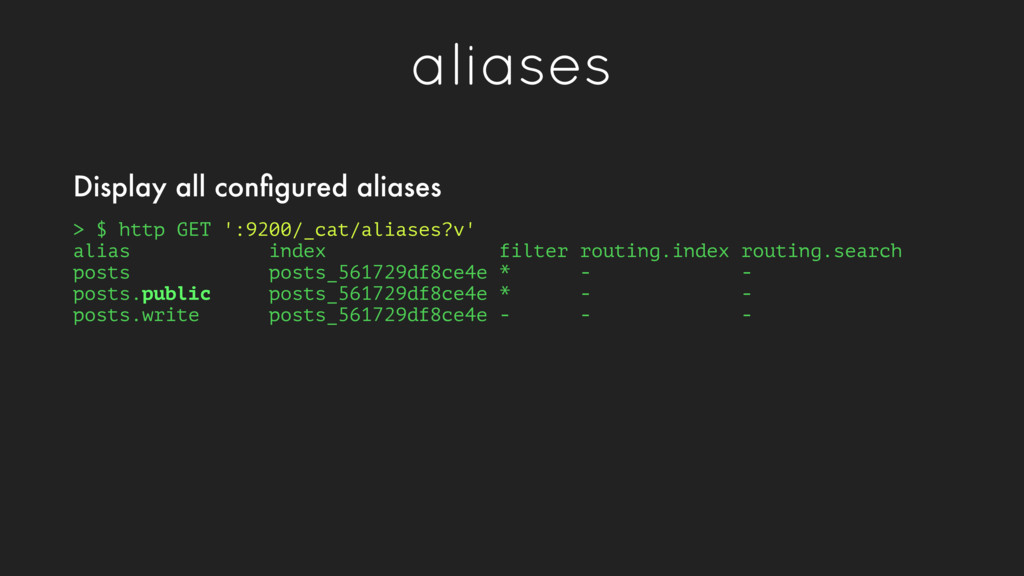
collection of documents, roughly analogous to a database in MySQL • An index is in reality a namespace that points to one or more physical shards which contain data • When indexing a document, if the specified index does not exist, it will be created automatically
of available data • A shard represents a single instance of lucene and is fully- functional, self-contained search engine • Shards are either primary or replicas and are assigned to nodes
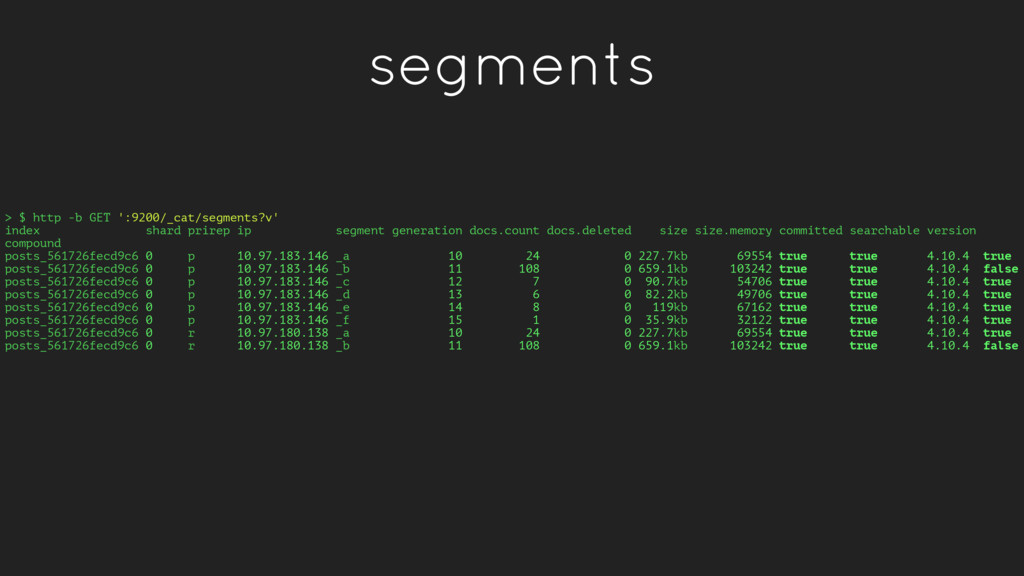
disk.percent host 33 2.6gb 21.8gb 24.4gb 10 host1 33 3gb 21.4gb 24.4gb 12 host2 34 2.6gb 21.8gb 24.4gb 10 host3 Show how many shards are allocated per node, with disk utilization info
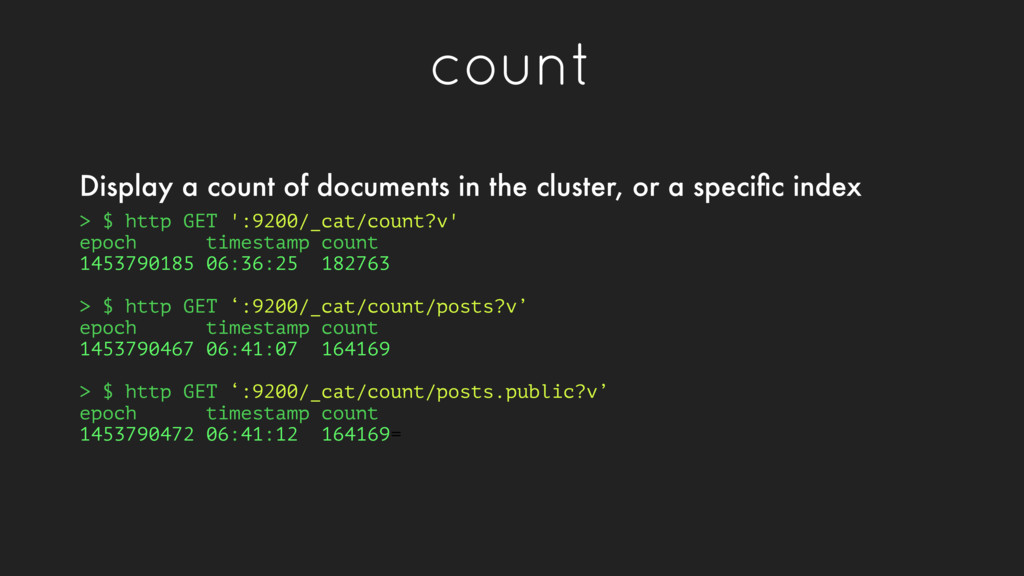
06:36:25 182763 > $ http GET ‘:9200/_cat/count/posts?v’ epoch timestamp count 1453790467 06:41:07 164169 > $ http GET ‘:9200/_cat/count/posts.public?v’ epoch timestamp count 1453790472 06:41:12 164169= Display a count of documents in the cluster, or a specific index
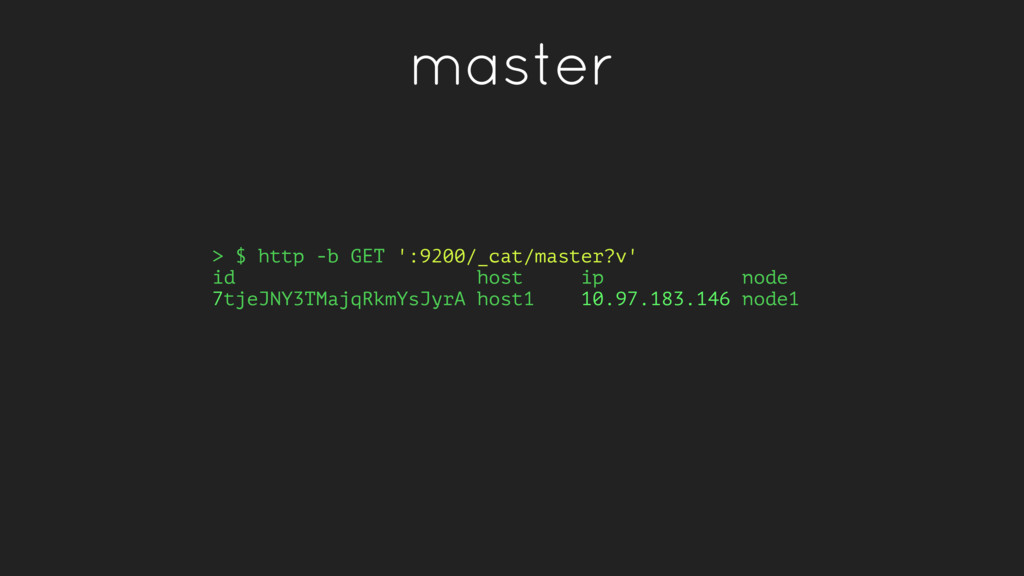
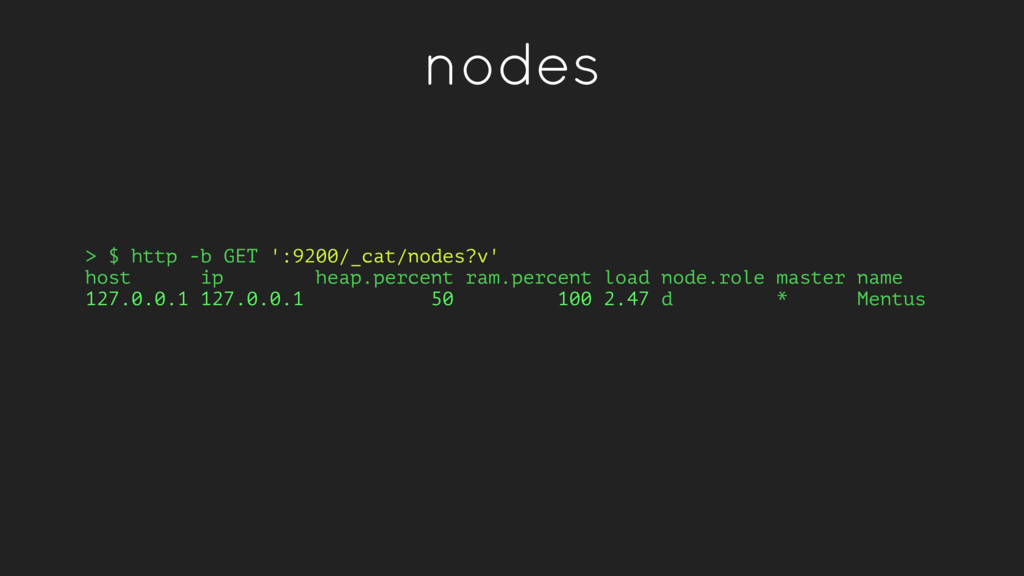
node total site_id published 7tjeJNY3TMajqRkmYsJyrA host1 10.97.183.146 node1 1.1mb 170.1kb 996.5kb __xrpsKAQW6yyCY8luLQdQ host2 10.97.180.138 node2 1.6mb 329.3kb 1.3mb bdoNNXHXRryj22YqjnqECw host3 10.97.181.190 node3 1.1mb 154.7kb 991.7kb Shows how much memory is allocated to fielddata (metadata used for sorts)
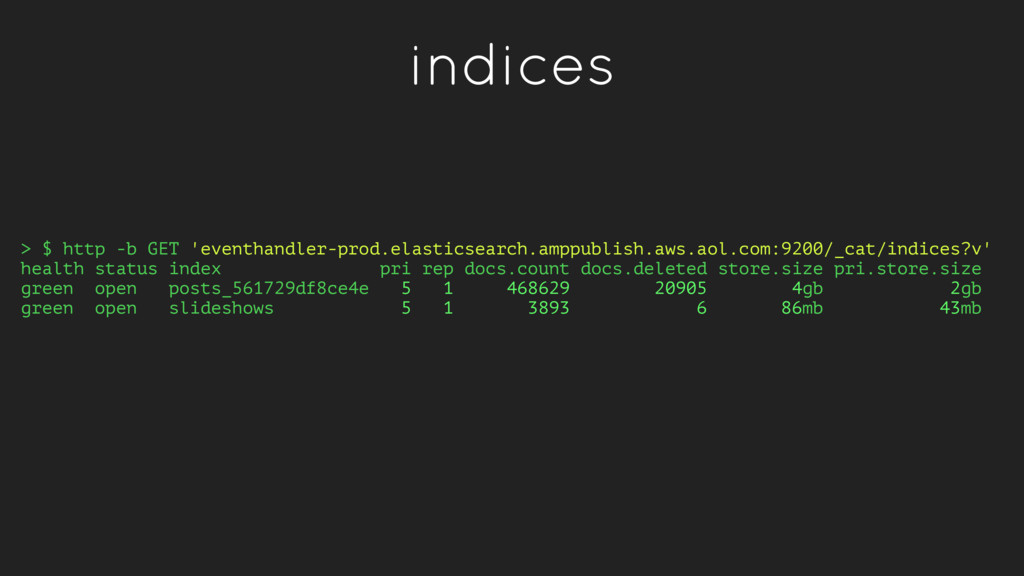
pri rep docs.count docs.deleted store.size pri.store.size green open posts_561729df8ce4e 5 1 468629 20905 4gb 2gb green open slideshows 5 1 3893 6 86mb 43mb
855ms HIGH update-mapping [foo][t] 1686 843ms HIGH update-mapping [foo][t] 1693 753ms HIGH refresh-mapping [foo][[t]] 1688 816ms HIGH update-mapping [foo][t] 1689 802ms HIGH update-mapping [foo][t] 1690 787ms HIGH update-mapping [foo][t] 1691 773ms HIGH update-mapping [foo][t]
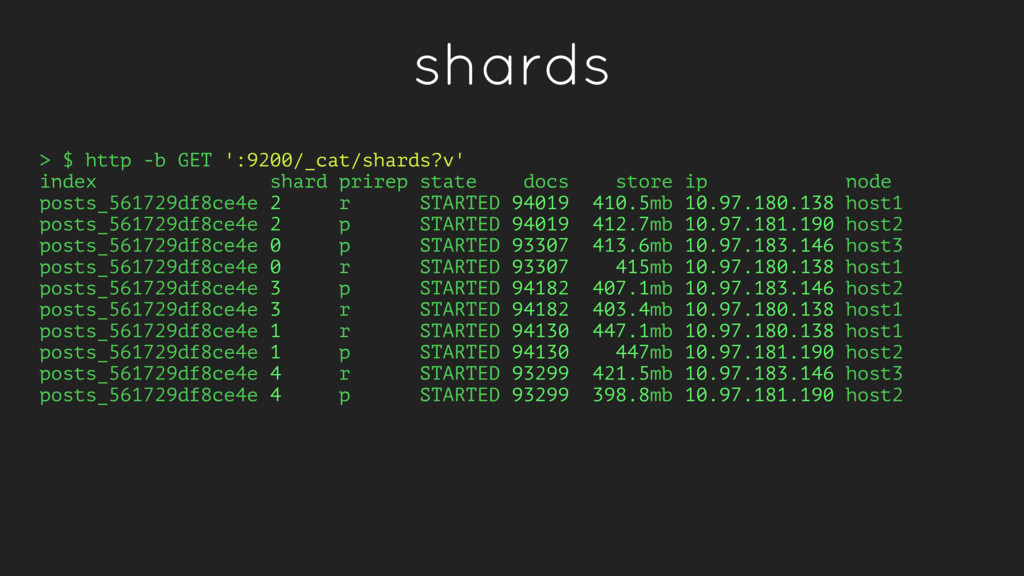
state docs store ip node posts_561729df8ce4e 2 r STARTED 94019 410.5mb 10.97.180.138 host1 posts_561729df8ce4e 2 p STARTED 94019 412.7mb 10.97.181.190 host2 posts_561729df8ce4e 0 p STARTED 93307 413.6mb 10.97.183.146 host3 posts_561729df8ce4e 0 r STARTED 93307 415mb 10.97.180.138 host1 posts_561729df8ce4e 3 p STARTED 94182 407.1mb 10.97.183.146 host2 posts_561729df8ce4e 3 r STARTED 94182 403.4mb 10.97.180.138 host1 posts_561729df8ce4e 1 r STARTED 94130 447.1mb 10.97.180.138 host1 posts_561729df8ce4e 1 p STARTED 94130 447mb 10.97.181.190 host2 posts_561729df8ce4e 4 r STARTED 93299 421.5mb 10.97.183.146 host3 posts_561729df8ce4e 4 p STARTED 93299 398.8mb 10.97.181.190 host2
doesn’t exist already • index - Index a document, replacing it if it exists • update - Apply a partial update to a document • delete - Delete a document
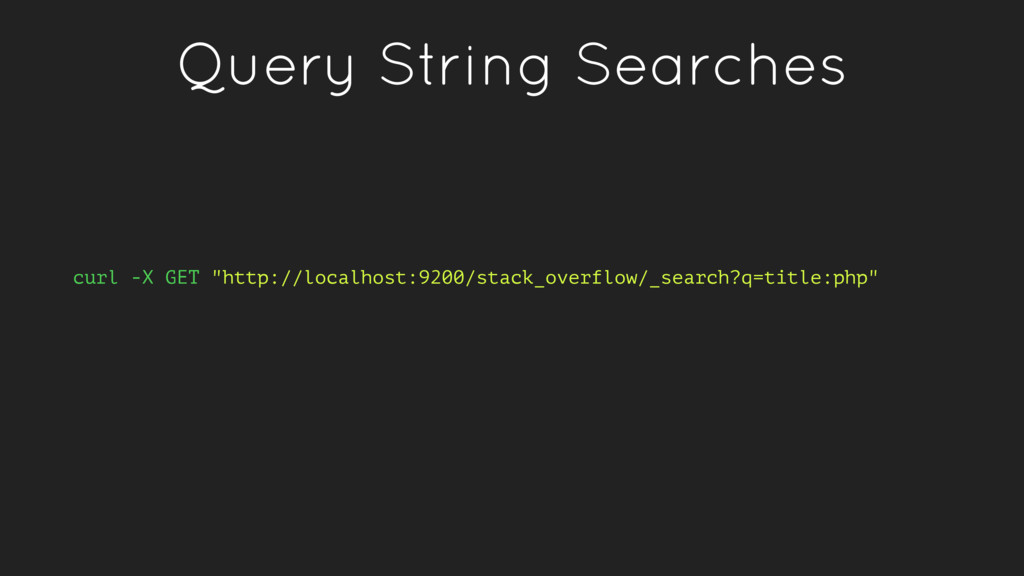
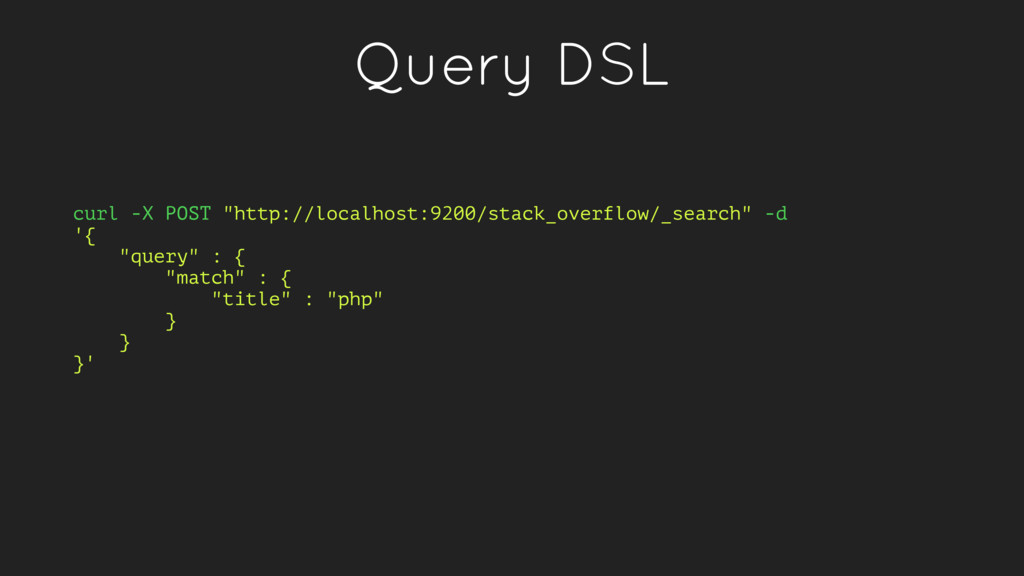
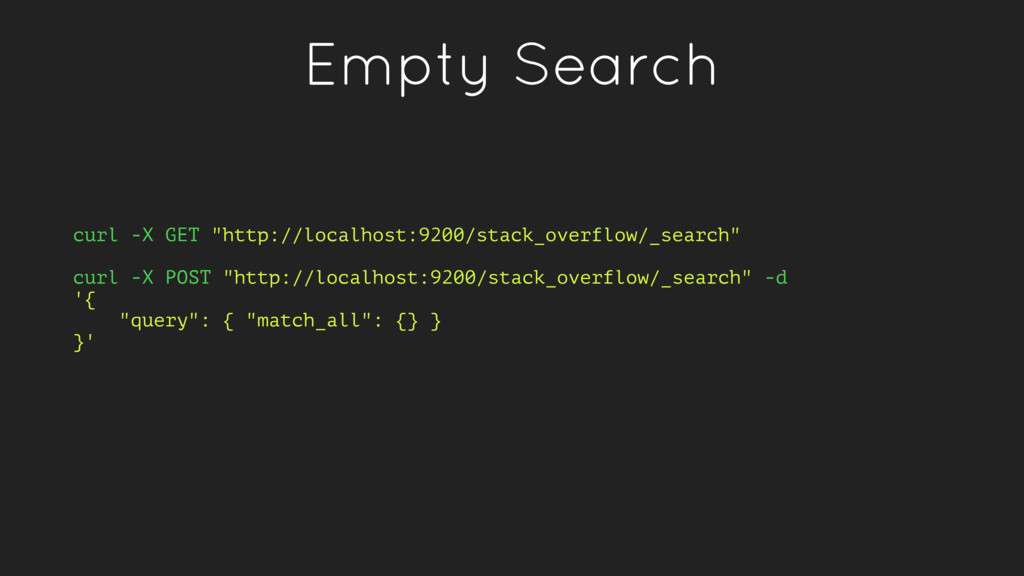
like “title” or “score” which return specific documents. • Full-text queries - queries that find documents which match a search query and return them sorted by relevance
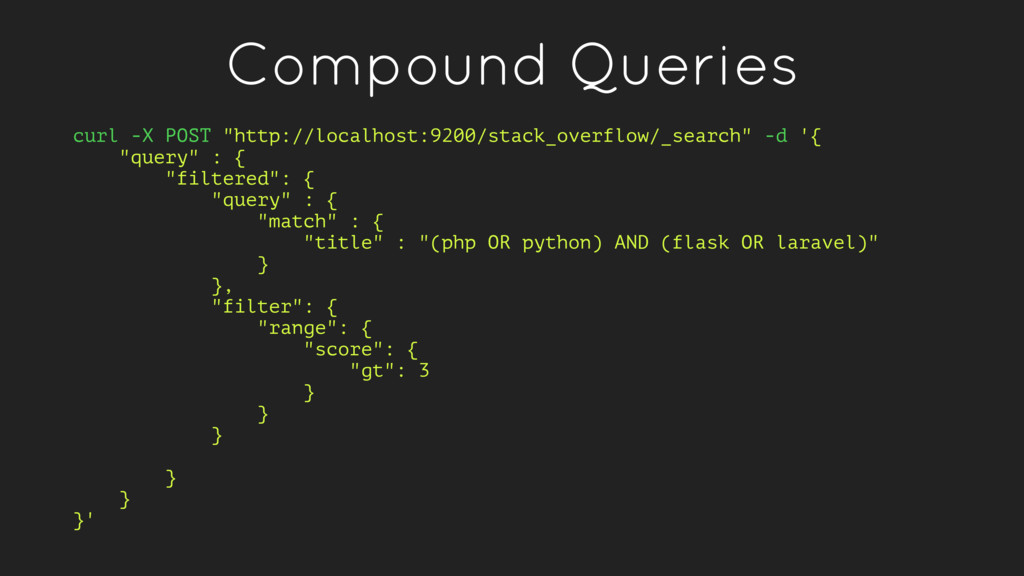
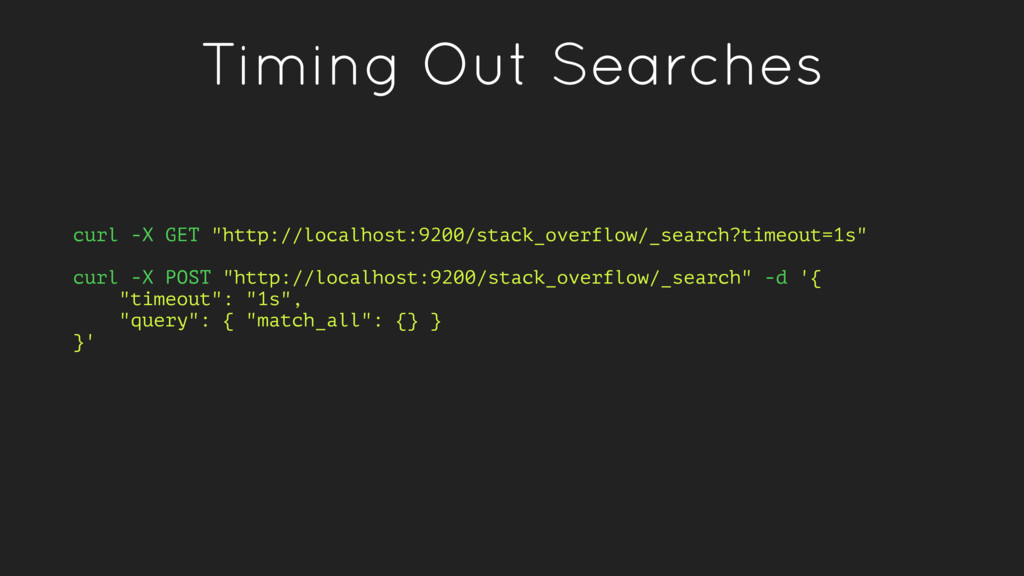
in a given field. These queries are standalone. Examples: match, range, term • Compound Queries - Combinations of leaf queries and other compound queries which combine operations together either logically (e.g. bool queries) or alter their behavior (e.g. score queries)
paged queries must be sorted at each shard, combined, and resorted • The cost of paging in distributed data sets can increase exponentially • It is a wise practice to set limits to how many pages of results can be returned
• multi_match - Match which spans multiple fields • common_terms - Match query which preferences uncommon words • query_string - Match documents using a search “mini-dsl” • simple_query_string - A simpler version of query_string that never throws exceptions, suitable for exposing to users
• terms - Search for an exact value in multiple fields • range - Find documents where a value is in a certain range • exists - Find documents that have any non-null value in a field • missing - Inversion of `exists` • prefix - Match terms that begin with a string • wildcard - Match terms with a wildcard • regexp - Match terms against a regular expression • fuzzy - Match terms with configurable fuzziness
context, giving all results a constant score • bool - Combines multiple leaf queries with `must`, `should`, `must_not` and `filter` clauses • dis_max - Similar to bool, but creates a union of subquery results scoring each document with the maximum score of the query that produced it • function_score - Modifies the scores of documents returned by a query . Useful for altering the distribution of results based on recency, popularity, etc. • boosting - Takes a `positive` and `negative` query, returning the results of `positive` while reducing the scores of documents that also match `negative` • filtered - Combines a query clause in query context with one in filter context • limit - Perform the query over a limited number of documents in each shard
types of data found in fields • Determines how individual fields are analyzed & stored • Sets the format of date fields • Sets rules for mapping dynamic fields
which group documents logically. • Types contain meta fields, which can be used to customize metadata like _index, _id, _type, and _source • Types can also list fields that have consistent structure across types.
prior to indexing • Elasticsearch selects the most likely type for dynamic fields, based on configurable rules • Explicit fields are defined exactly prior to indexing • Types cannot accept data that is the wrong type for an explicit mapping
created, if no mapping was previously specified. • Elasticsearch is good at identifying fields much of the time, but it’s far from perfect! • Fields can contain basic data-types, but importantly, mappings optimize a field for either structured (exact) or full-text searching
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Exact Value • “[email protected]” is an email address in all](https://files.speakerdeck.com/presentations/d1ee740018f84b0d8292491241e18219/slide_81.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
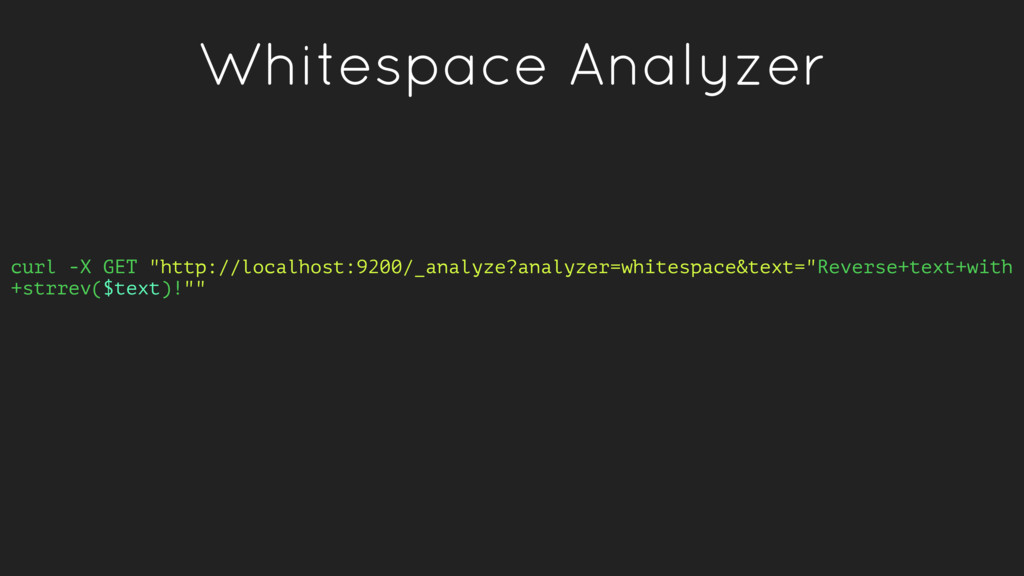{kind=link}
{kind=link}
{kind=link}
{kind=link}
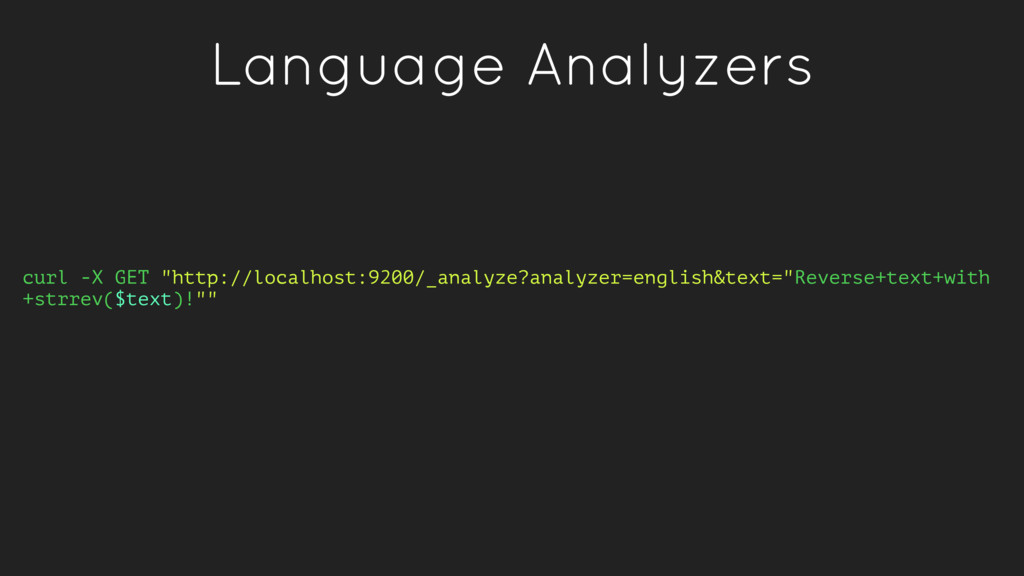{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
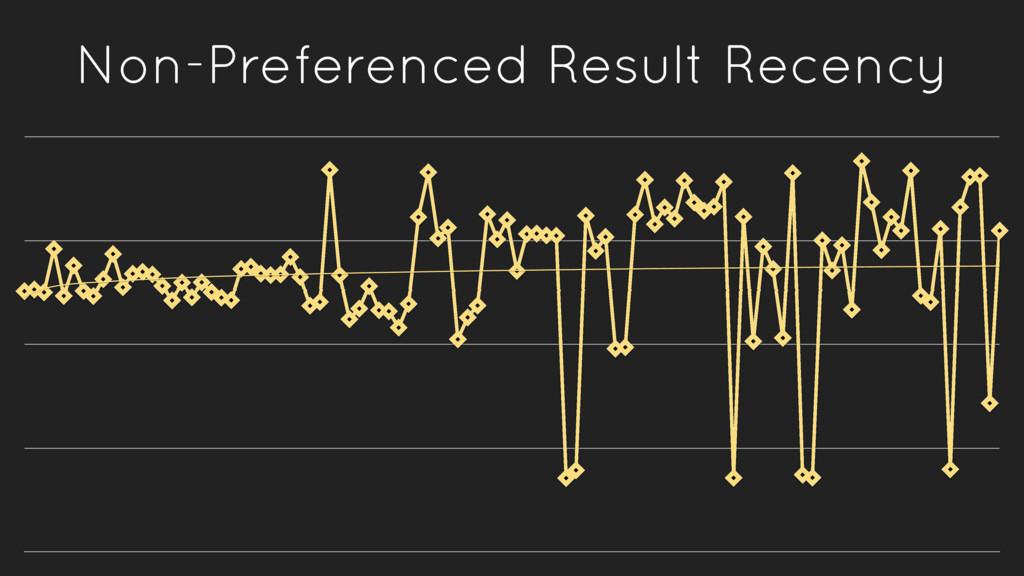{kind=link}
{kind=link}
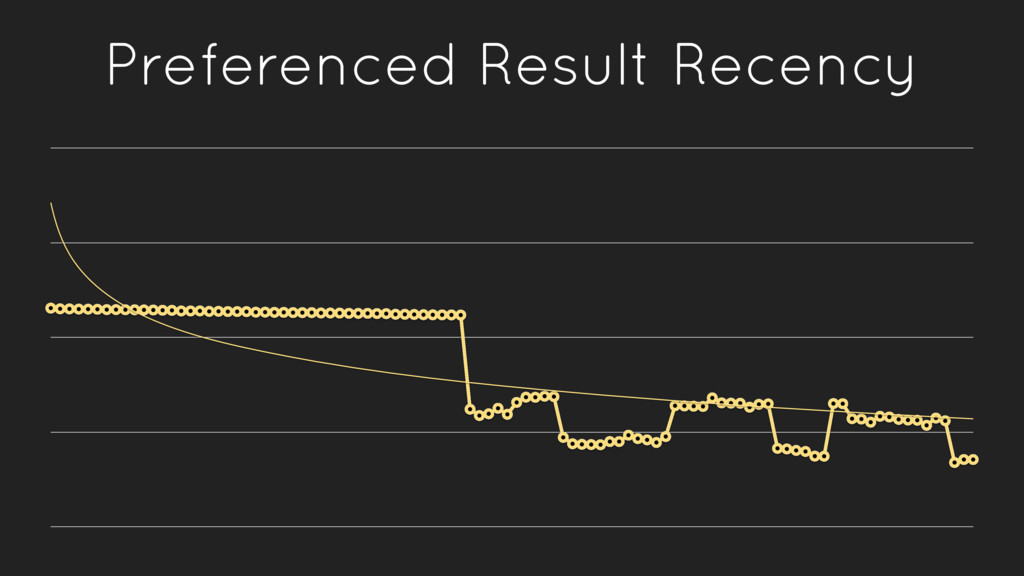{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}