Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
RLSP2021資料
Search
Ryunosuke-Ikeda
April 14, 2021
Research
230
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
RLSP2021資料
東京大学松尾研究室が主催する強化学習のセミナーの最終課題発表資料.
Ryunosuke-Ikeda
April 14, 2021
More Decks by Ryunosuke-Ikeda
See All by Ryunosuke-Ikeda
映像情報を活用した次世代のAIアシスタントシステム"Salieri" 資料
imr0305
0
190
Open Hack U 発表資料(チームうどん)
imr0305
0
62
JPHacks2021 発表資料(チームうどん)
imr0305
0
56
自己紹介スライド
imr0305
1
2.1k
技育展2021 発表資料(チームうどん)
imr0305
0
48
RPNを完全に理解しよう
imr0305
1
370
技育展2020 登壇資料(チームうどん)
imr0305
0
200
Other Decks in Research
See All in Research
Unified Audio Source Separation (Defense Slides)
kohei_1979
1
630
言語モデルから言語について語る際に押さえておきたいこと
eumesy
PRO
6
2.5k
長時間動画QAにおけるマルチエージェント推論 ・SVAgent: Storyline-Guided Long Video Understanding via Cross-Modal Multi-Agent Collaboration
murakawatakuya
1
160
Spatial Active Noise Control Based on Sound Field Interpolation Incorporating Physical Constraints
skoyamalab
0
120
Ankylosing Spondylitis
ankh2054
0
180
Data Visualization Tools in the Age of AI
flekschas
0
170
東京大学工学部計数工学科、計数工学特別講義の説明資料
kikuzo
0
550
第64回CV・PRML勉強会 論文紹介:Linguistic Priors for Visual Decoupling: Towards Symmetric Vision-Brain Alignment
sokikatayama
0
140
YOLO26_ Key Architectural Enhancements and Performance Benchmarking for Real-Time Object Detection
satai
3
870
SLAMはどこまで解決されたのか?
tomonom
0
780
羽田新ルート運用6年の検証
1manken
0
170
ScoreMatchingRiesz for Automatic Debiased Machine Learning and Policy Path Estimation with an Application to Japanese Monetary Policy Evaluation
masakat0
0
300
Featured
See All Featured
Code Reviewing Like a Champion
maltzj
528
40k
WENDY [Excerpt]
tessaabrams
11
38k
Un-Boring Meetings
codingconduct
0
340
So, you think you're a good person
axbom
PRO
2
2.1k
Visual Storytelling: How to be a Superhuman Communicator
reverentgeek
2
590
Faster Mobile Websites
deanohume
310
32k
We Are The Robots
honzajavorek
0
270
What Being in a Rock Band Can Teach Us About Real World SEO
427marketing
0
1k
Lightning talk: Run Django tests with GitHub Actions
sabderemane
0
220
A Modern Web Designer's Workflow
chriscoyier
698
190k
Java REST API Framework Comparison - PWX 2021
mraible
34
9.5k
What’s in a name? Adding method to the madness
productmarketing
PRO
24
4.1k
Transcript
深層強化学習 小型AIロボットカー実装 東京電機大学 M1 長野 紘士朗 東京電機大学 B4 池田柳之介 京都大学
B1 中尾友紀 RLSP2021 最終課題
目次 (Table of Contents) 1. 問題設定 2. 手法 3. 実験結果
4. 結論 5. 参考サイト・URL
問題設定 - 昨今のIoTデバイスの増加に伴い、小型端末に組み込むことができるエッジAI の開発が注目されている。 - エッジAIは従来のようなクラウド環境で情報の処理を行う必要がなく、エッ ジAI上で推論と学習を行うことができ、処理の高速化やコストダウンが期待 されている 参考) https://ainow.ai/2020/02/2
1/183186/#AIAI
問題設定 - 私たちは深層強化学習を利用して、小型AIロボットカーに走行を学習させる ことを目指しました。 - 実装する上で、シミュレータ環境と実環境の2通りの実験を行いました Jetbot (Waveshare社) Donkey Car
(gym-donkeycar)
シミュレータ環境
デモ
手法 ・SAC自体について 観測するStateには画像から得られる物のみを用いている. 学習コードにはエントロピー最適化も含めて実装. ※細かいパラメータはScrapbox上のリンクからコードを見てください.
手法 ・SAC いくつか環境に工夫をしている 1. 報酬関数の変更 2. 環境から観測された画像(State)に対するVAEによる事前処理 3. 環境のReset時に一定間隔の間,ランダムな行動を入力する事で初期状態に変 化を与えている
手法 ・VAEによる事前処理 左の様な入力画像からVAEによって情報を32次元に圧縮している. 元画像 復元画像
手法 ・SAC Agentにも工夫をしている 1. 各stepにおいて確率ε(0.0 ≦ε< 1.0)でランダムに行動する 2. 環境からの直前n枚のフレームをVAEで圧縮したベクトルを状態とする. εとnを変化させる事による性能の変化を考察した.
手法 ・実験 εとnを変化させる事で生まれる性能の変化を考察した. 1. ε = 0.0, n = 1
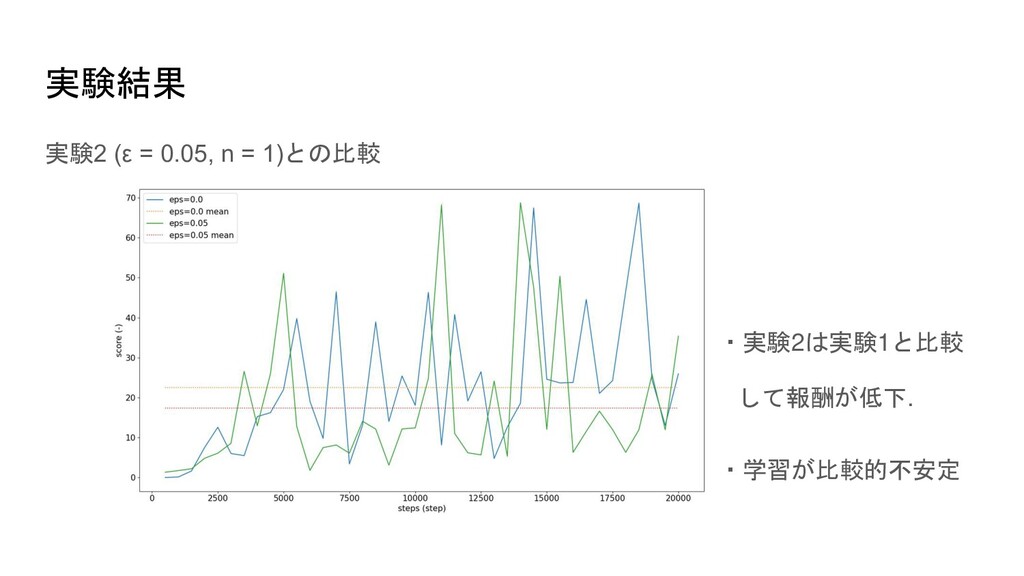
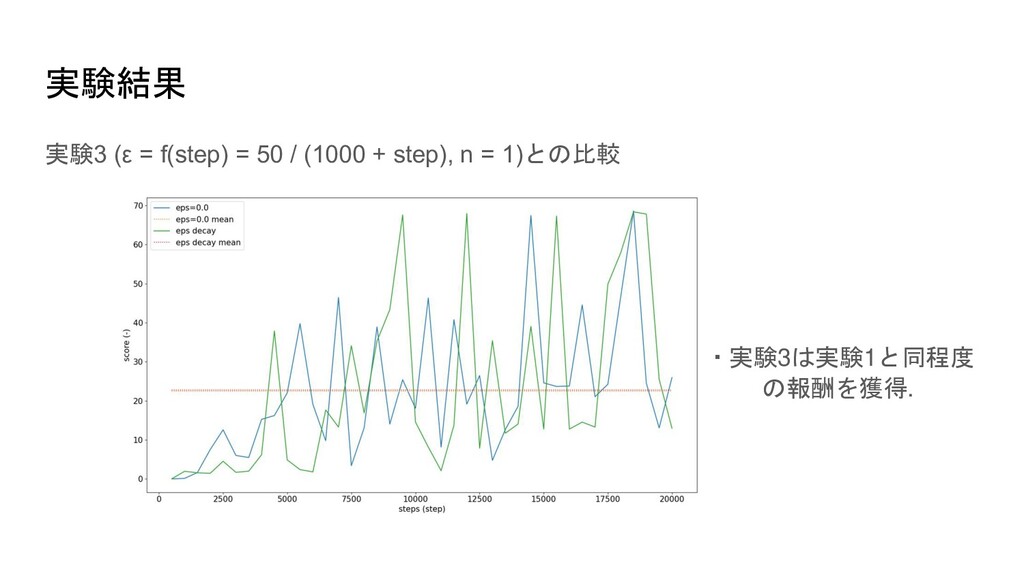
2. ε = 0.05, n = 1 3. ε = f(step) = 50 / (1000 + step), n = 1 4. ε = 0.0, n = 3 実験1. の結果を基準とする.
実験結果 実験2 (ε = 0.05, n = 1)との比較 ・実験2は実験1と比較 して報酬が低下.
・学習が比較的不安定
実験結果 実験3 (ε = f(step) = 50 / (1000 +
step), n = 1)との比較 ・実験3は実験1と同程度 の報酬を獲得.
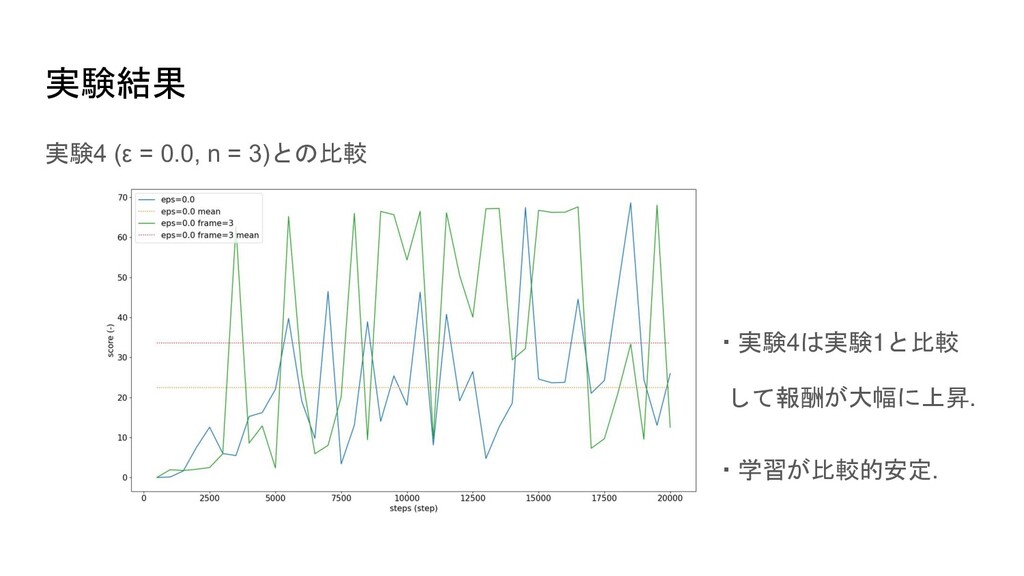
実験結果 実験4 (ε = 0.0, n = 3)との比較 ・実験4は実験1と比較 して報酬が大幅に上昇.
・学習が比較的安定.
結論 ・単純なランダム行動(実験2)だけでは方策の大幅な性能向上は見込めない ・入力に持つ画像フレーム数を増やす事で飛躍的に性能が上がる ・入力に持つ画像フレーム数を増やす事で方策の安定性が上昇する ※詳細はScrapboxを見てください.
実環境
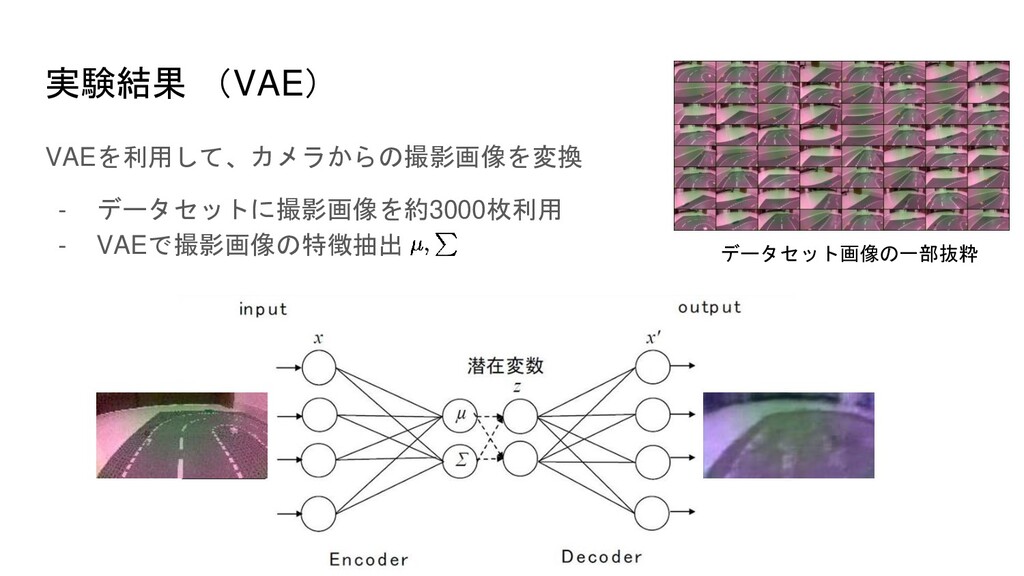
実験結果 (VAE) VAEを利用して、カメラからの撮影画像を変換 - データセットに撮影画像を約3000枚利用 - VAEで撮影画像の特徴抽出 データセット画像の一部抜粋
深層強化学習アルゴリズムSACによる走行結果 当初の予定ではこちらにSACによる走行動画を載せたかったのですが、Jetbotの Cuda環境のエラーが発生し、締切まであげられなかったため、このように動いて ほしかったという結果をサイト記事から引用させていただきこちらに載せる。 マニュアル(人手)操作 SACによる走行結果
結論 ・実環境ではVAEは学習しやすかったが、動作環境を整えるのが大変 原因 - Colabratoryで作成したVAEの重みをロードするのに実環境のロボットの 動作を行うパッケージがtorch1.3に依存しているためロードできなかっ た >> Jetson nano
の環境をアップデートしてtorchのバージョンを1.6 以上にして実験を行う
参考記事・サイト • Jetson Nanoで動く深層強化学習を使ったラジコン向け自動運転ソフトウェアの 紹介 • Learning_RacerをWaveshare製Jetbotで試した。 • Donkey Carを組み立てる前にシミュレーターで楽しんでみる
Donkey Car 3.1.0編 • https://towardsdatascience.com/learning-to-drive-smoothly-in-minutes- 450a7cdb35f4 まとめ 私たちは深層強化学習を利用して、シミュレータ環境と実環境の2通りで実験を 行いました。 - 実環境ではロボット本体に組み込むときの動作環境を整えることができず実 験まで行えなかったが、シミュレータ環境では学習を行うことができ、ロボ ットカーでコースを何週も周れることができた。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}