We rely on our monitoring to tell us when our services, applications, or infrastructure diverge from “normal.” Containers have created a new world of dynamic infrastructure where normal is changing constantly, making it quite difficult to define. How do you check if a service is up when your scheduler or clustering tools are changing the hosts and ports it runs on? Ilan Rabinovitch will review techniques for successful monitoring workflows and explains how to instrument your code in your containers and track the performance and availability of your applications as they move around. The techniques discussed will apply regardless of the monitoring platform you choose.
{kind=link}
![$ finger ilan@datadog [datadoghq.com] Name: Ilan Rabinovitch Role: Director, Technical](https://files.speakerdeck.com/presentations/f60f572ef0fd4beaa6bc43513d46b440/slide_1.jpg){kind=link}
{kind=link}
{kind=link}
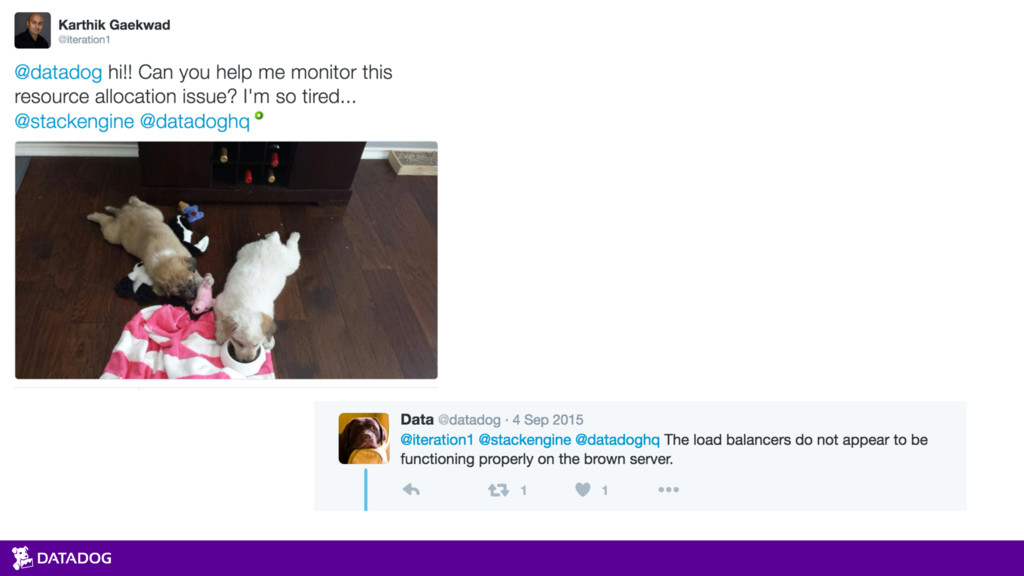{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
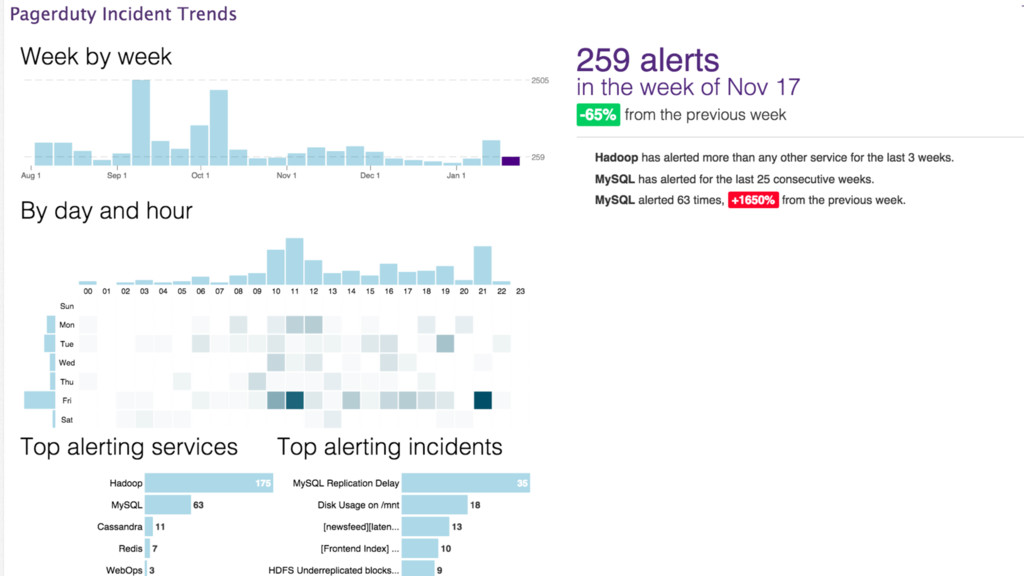{kind=link}
{kind=link}
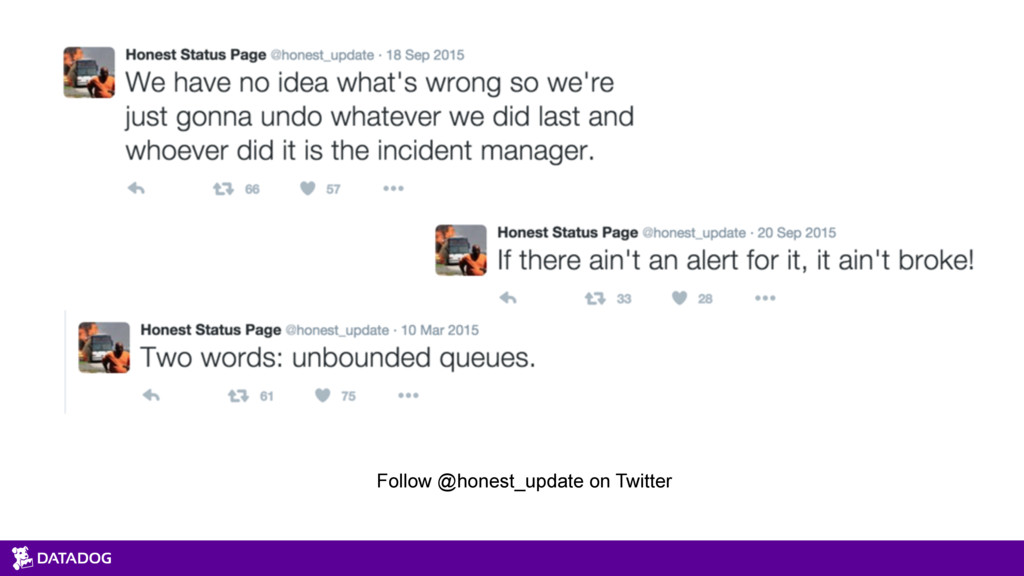{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
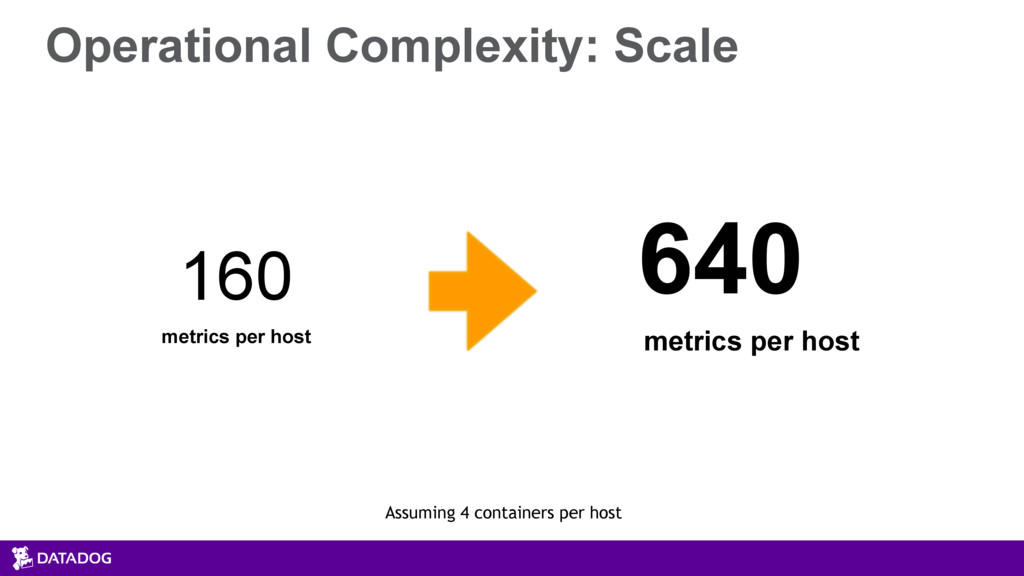{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
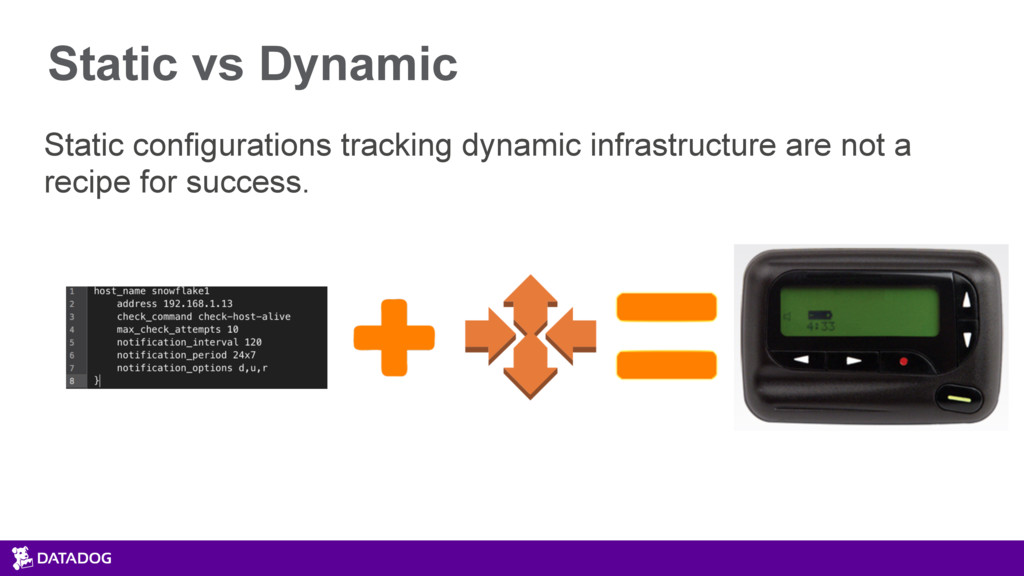{kind=link}
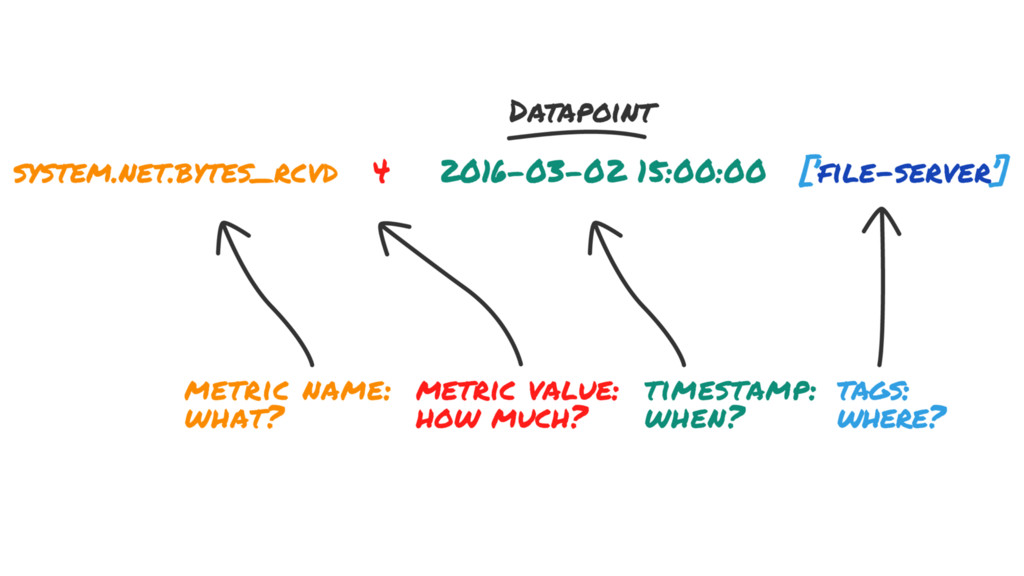{kind=link}
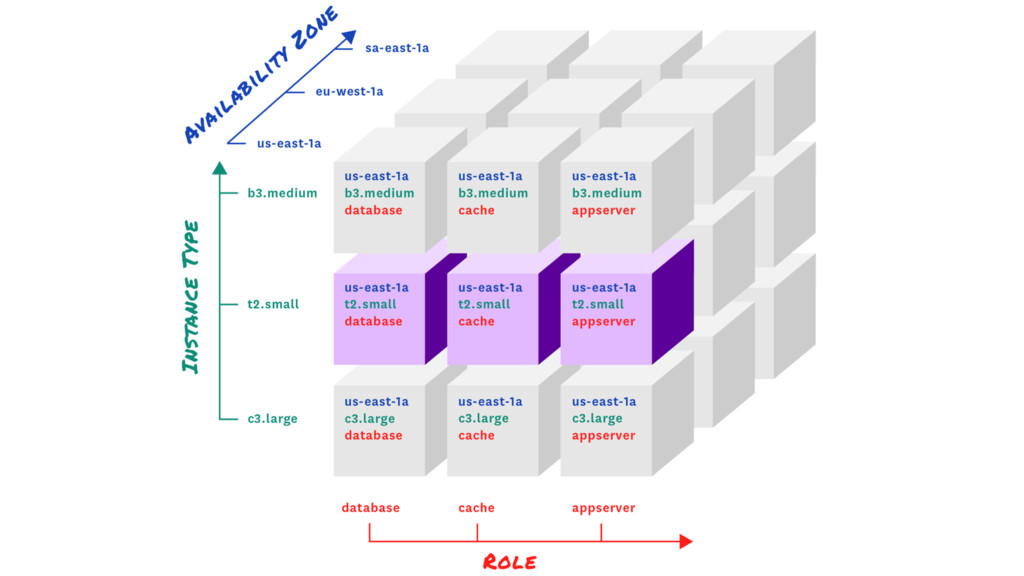{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
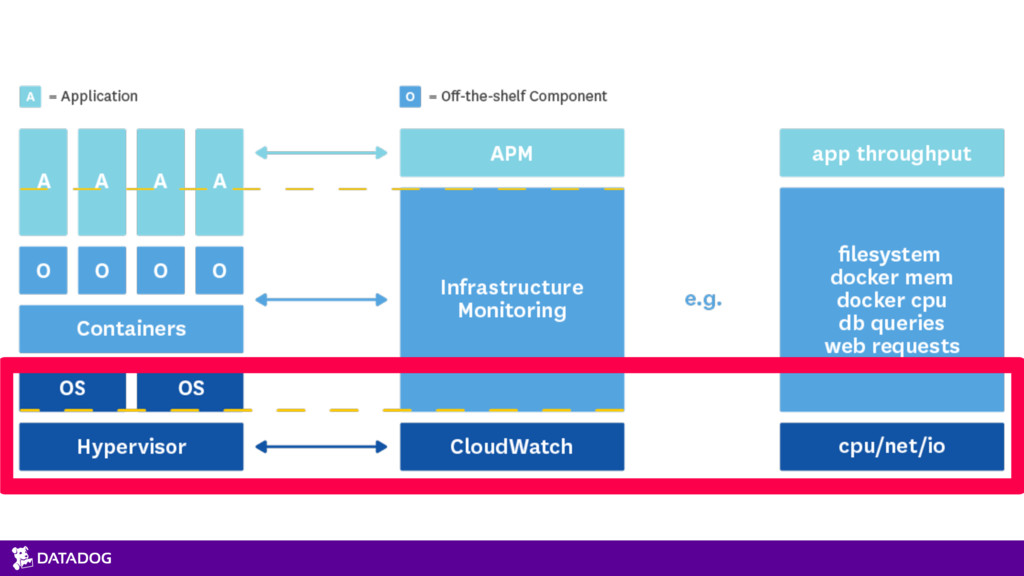{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![STATS Command # Usage: docker stats CONTAINER [CONTAINER...] $ docker](https://files.speakerdeck.com/presentations/f60f572ef0fd4beaa6bc43513d46b440/slide_68.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
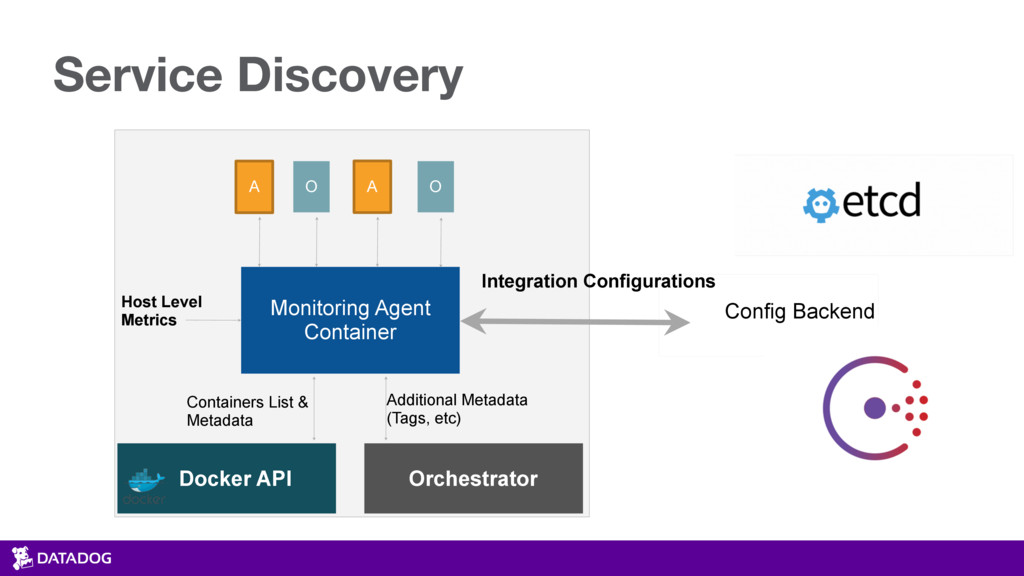{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}