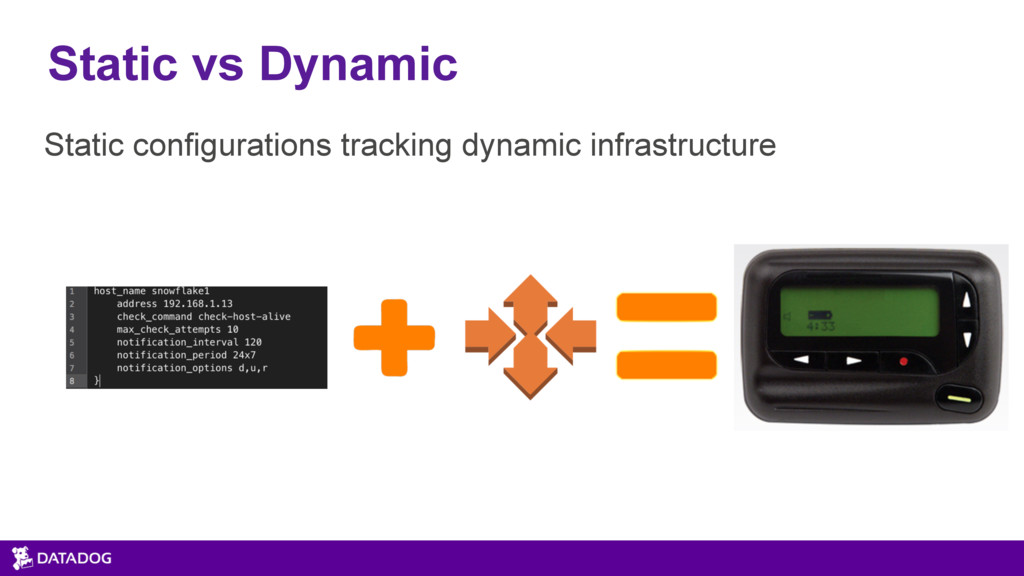
You need to monitor only a few machines and applications before identifying and fixing issues in your environment becomes very complicated. Throw in the type of dynamic infrastructure provided by cloud providers and container orchestration, and your static monitoring strategies will most likely not scale. Knowing which metrics to watch and how to troubleshoot based on those metrics will help you solve problems more quickly. In this session, we will look at a framework for your metrics and how to use it to find solutions to the issues that come up. We will cover the three types of monitoring data; what to collect; what should trigger an alert (avoiding an alert storm and pager fatigue); and how to follow the resources to find the root causes of problems. This focus of this session is not tool specific, so attendees will leave with strategies and frameworks they can implement in environments today regardless of the platforms and tools they use.
{kind=link}
{kind=link}
![$ finger ilan@datadog [datadoghq.com] Name: Ilan Rabinovitch Role: Director, Technical](https://files.speakerdeck.com/presentations/d7b35f3a4b2e4fbfa0a04c01a8d784cf/slide_2.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
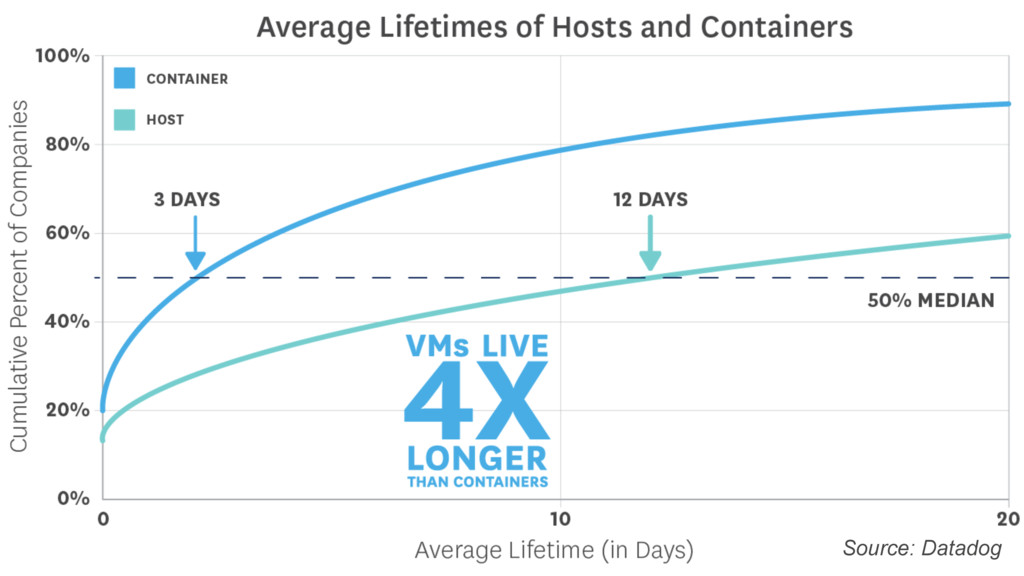{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
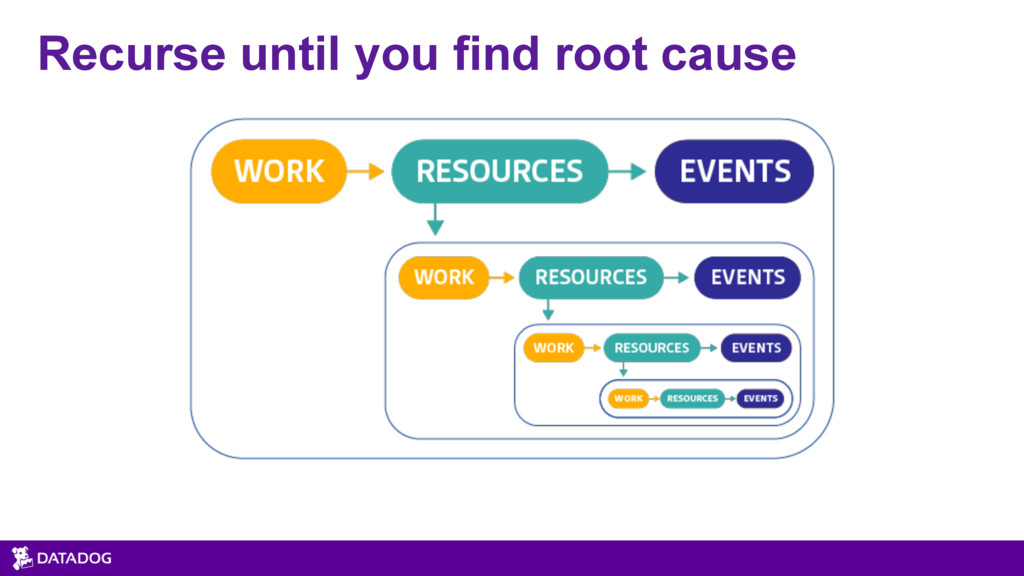{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}