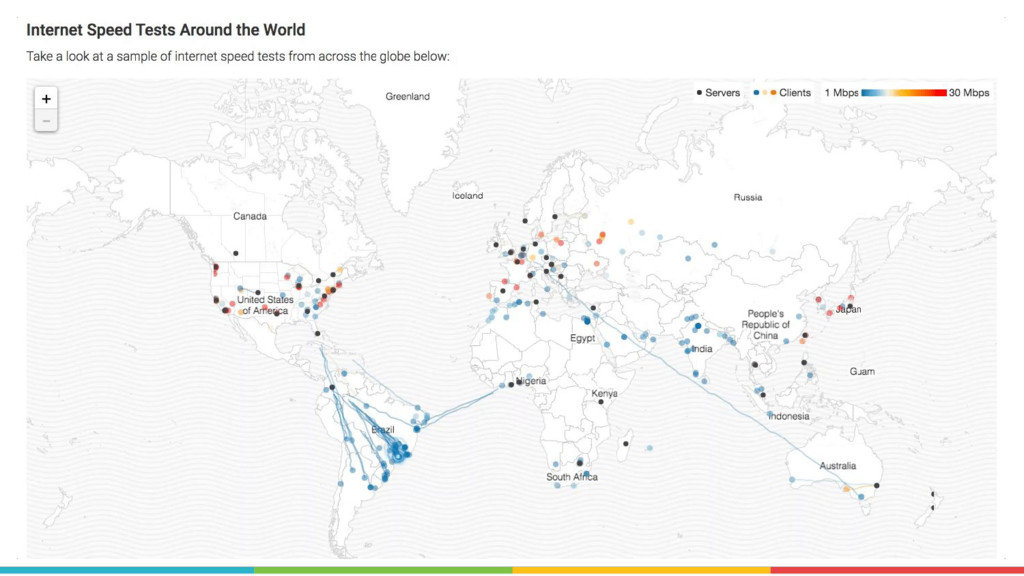
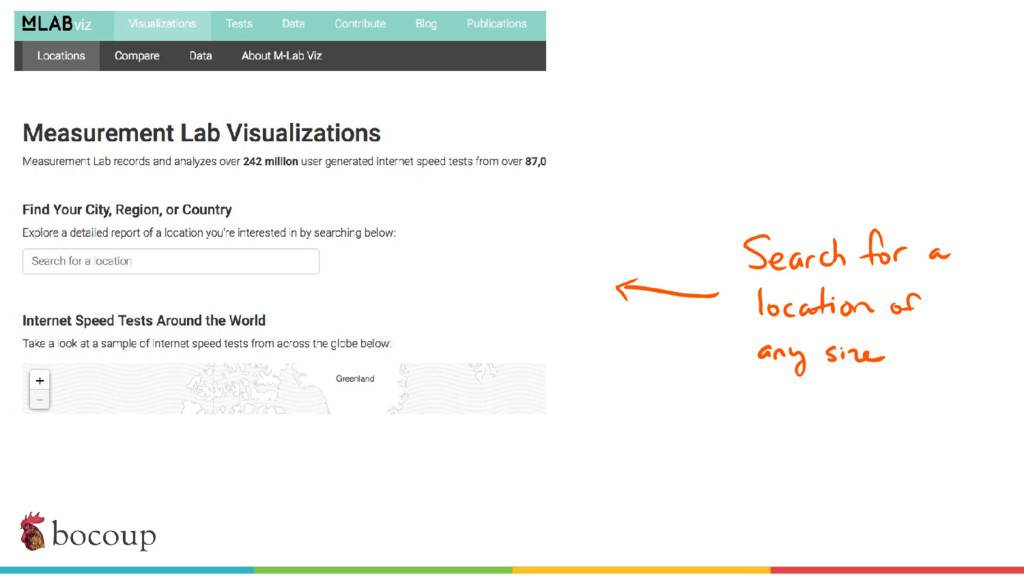
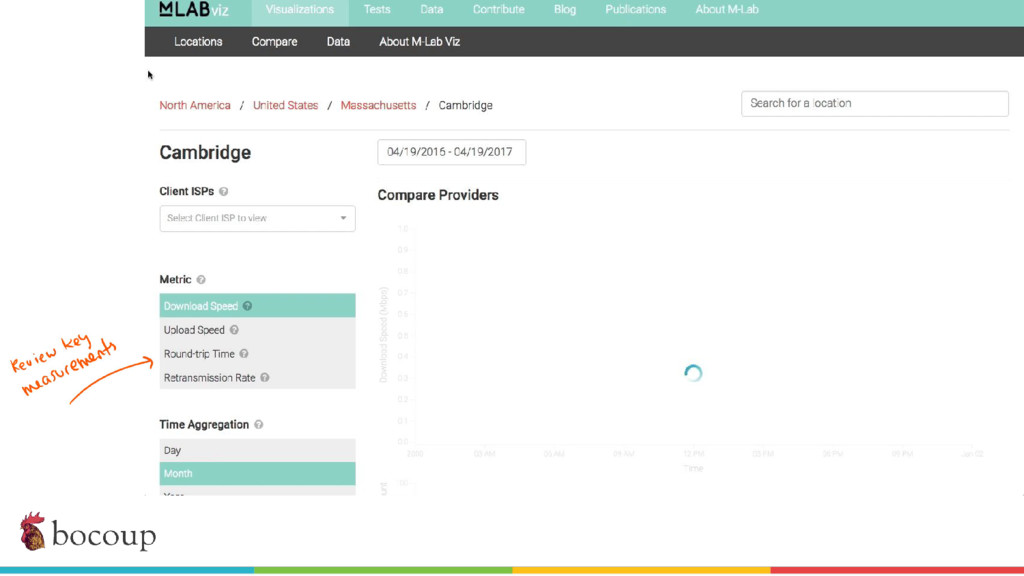
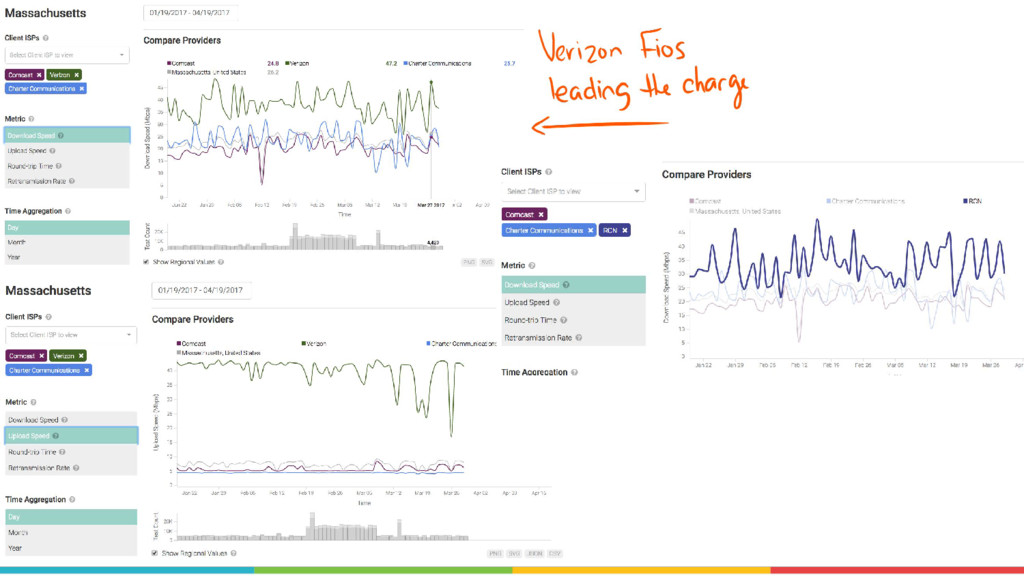
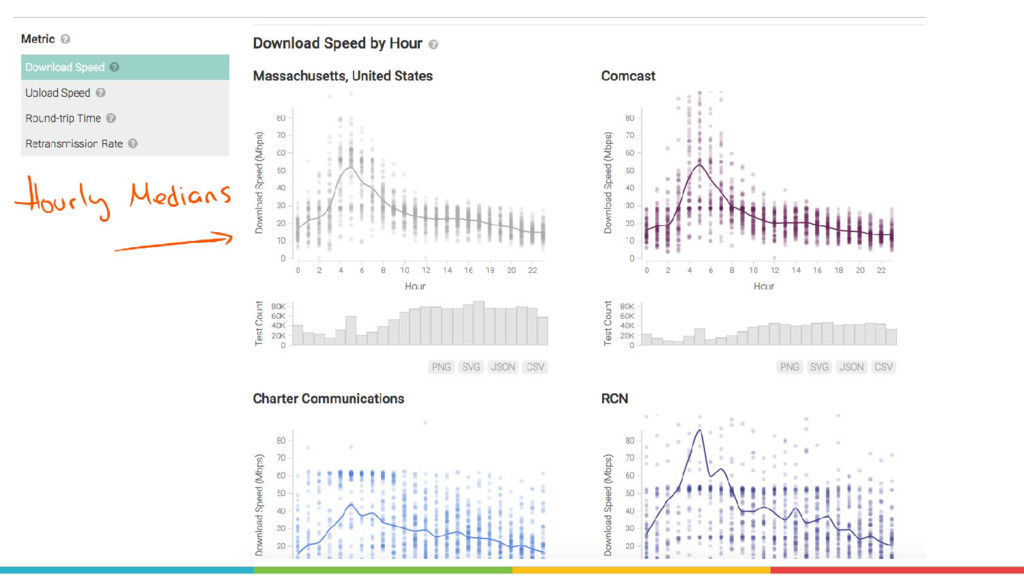
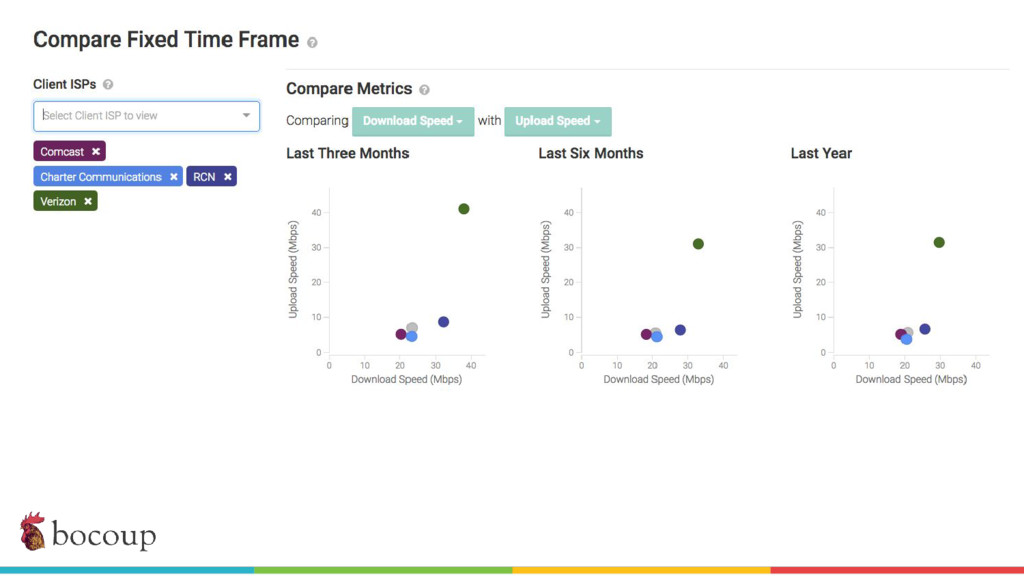
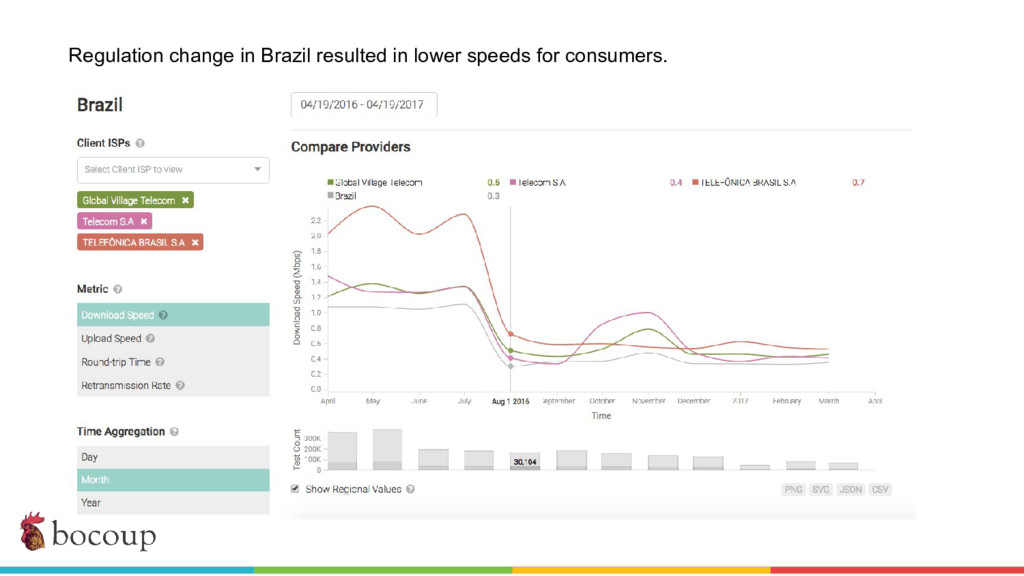
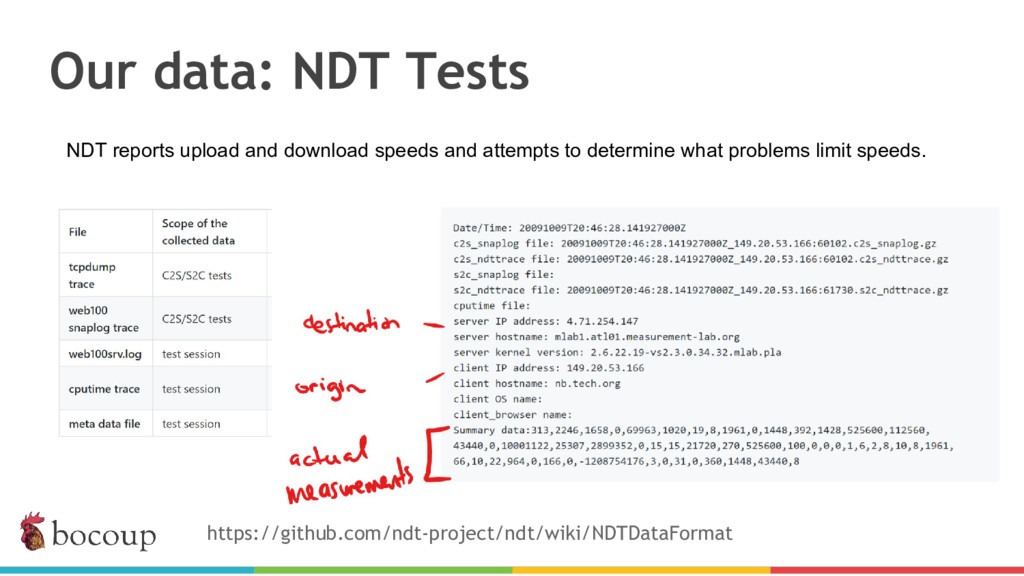
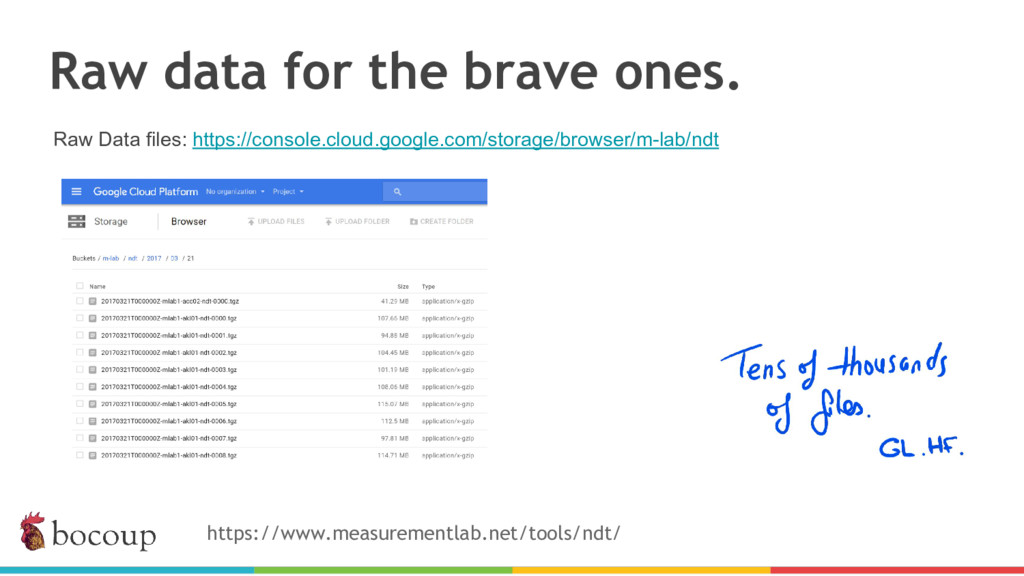
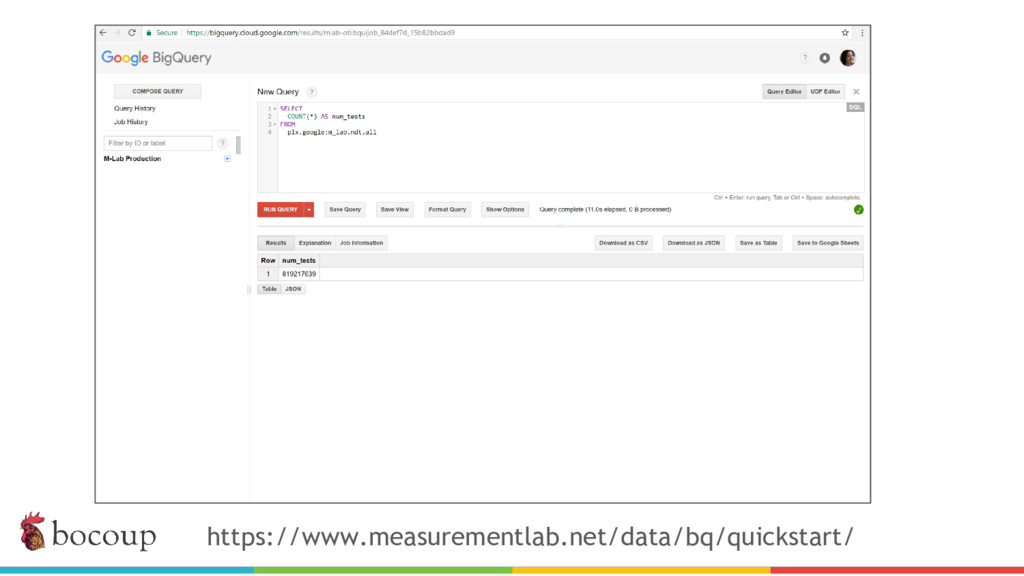
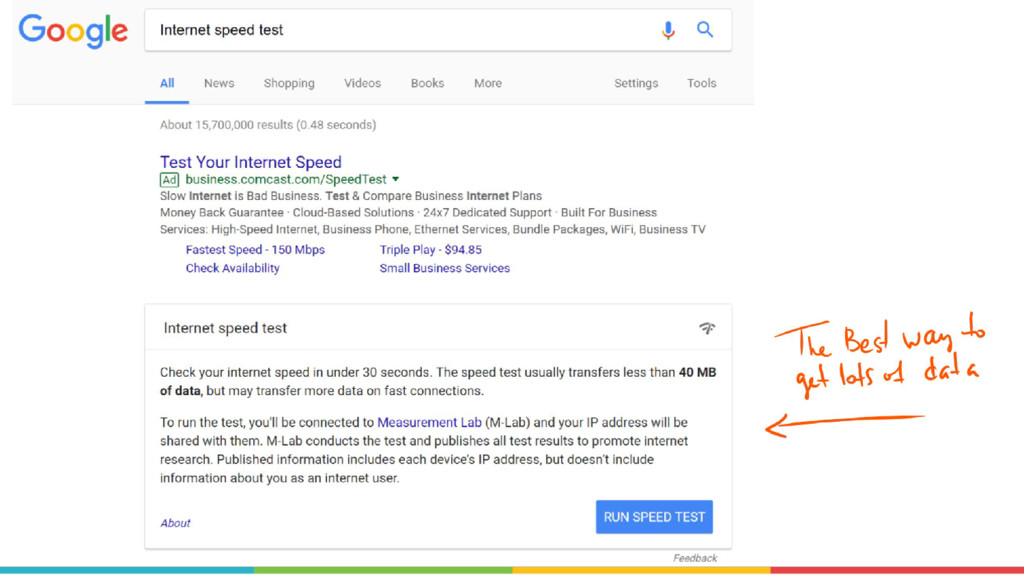
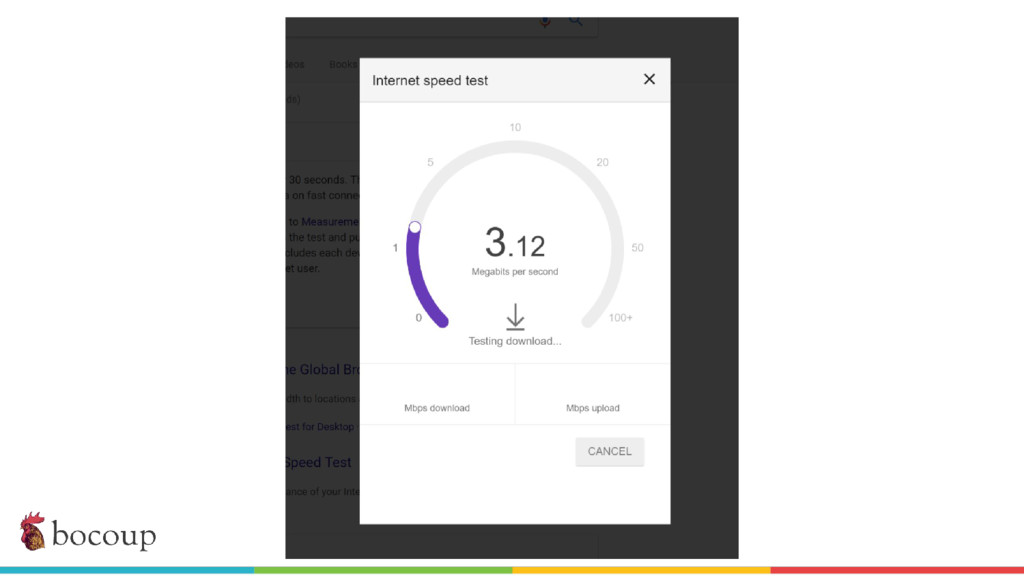
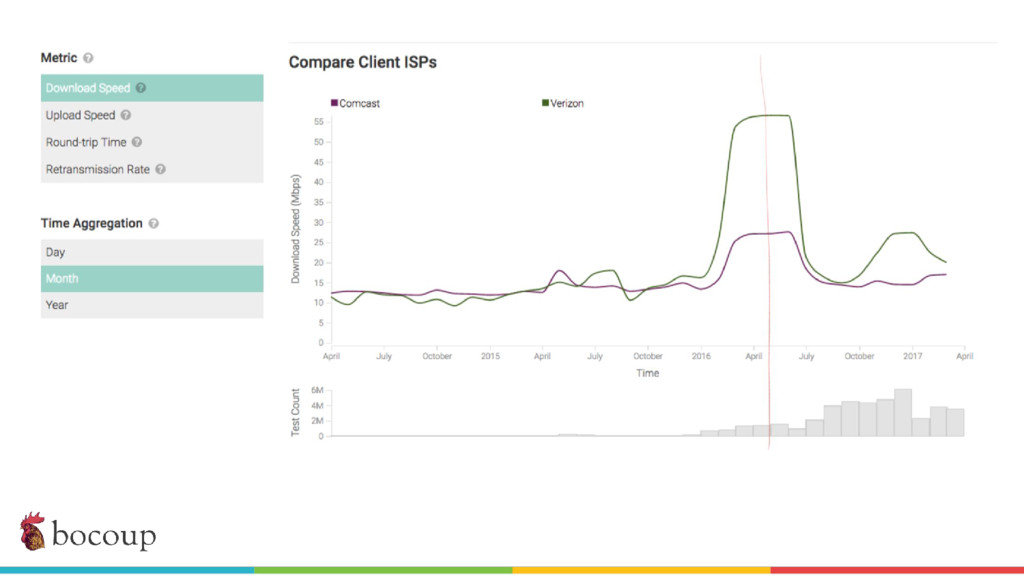
Measurement Lab (M-Lab)—the largest collection of open internet performance data on the planet—collects hundreds of thousands of consumer internet performance tests daily and provides that data in the public domain for research, analysis, and advocacy. Data has been piling up since 2009 (over five petabytes of information about the quality of experience on the internet), and more data is generated every day. Big data at this scale presents interesting challenges for everything from readability, visualization, and navigation to public access and affordability. The M-Lab data allows anyone to explore how their internet experience is mediated by all of the various actors that make up the internet.
In this talk, I share recent work with the M-Lab team to develop a data processing pipeline, API, and visualizations to make the data more accessible to anyone interested in exploring open internet through consumer measurements, exploring both the technical and design aspects of the project.
To see a live version of this presentation (with all the gif goodness) you can see it here: https://docs.google.com/presentation/d/1RBMzIIvfyE1NDRPJZHvFBpJ5BEg2cE21L3pUtz29qfI/pub?start=false&loop=false&delayms=60000&slide=id.p
{kind=link}
![Get in touch! [email protected] http://bocoup.com/datavis](https://files.speakerdeck.com/presentations/cd8ee3bdb9a54c49947de47650e447f2/slide_1.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
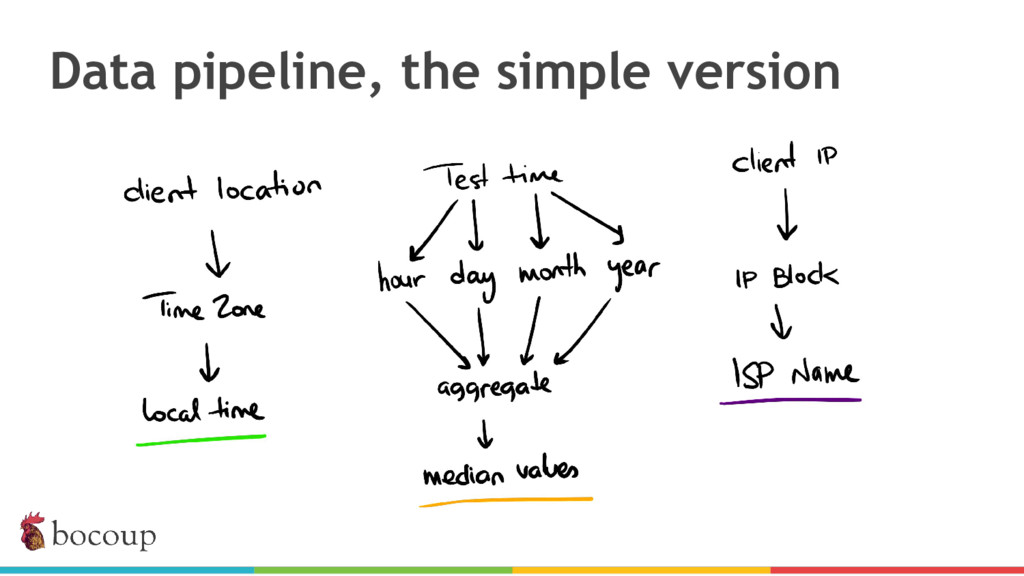{kind=link}
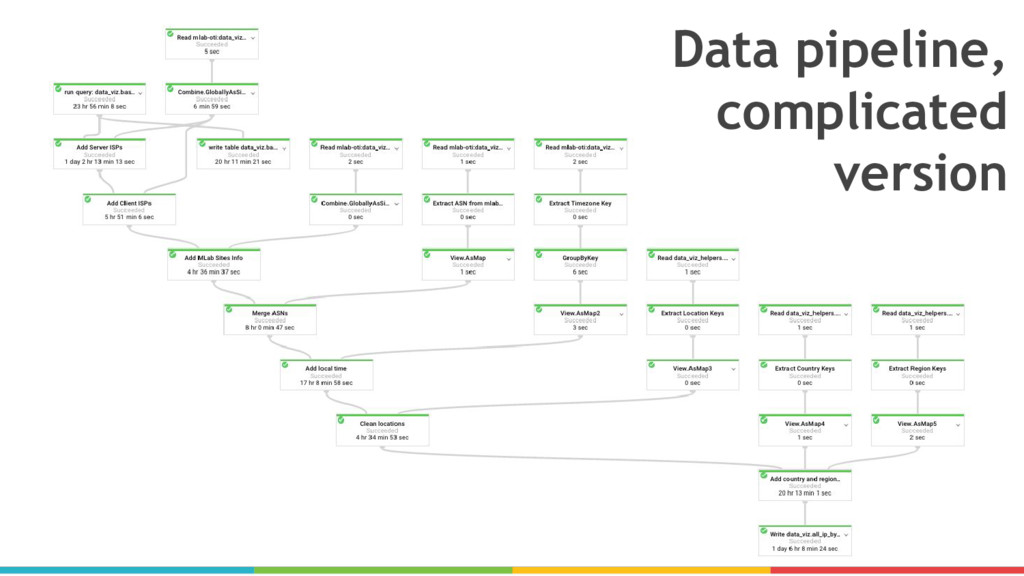{kind=link}
{kind=link}
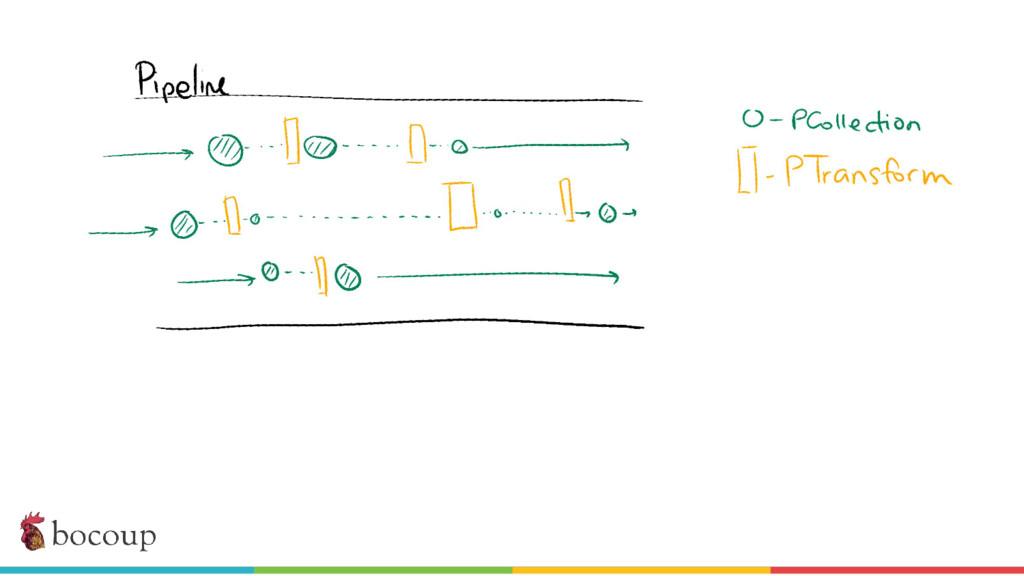{kind=link}
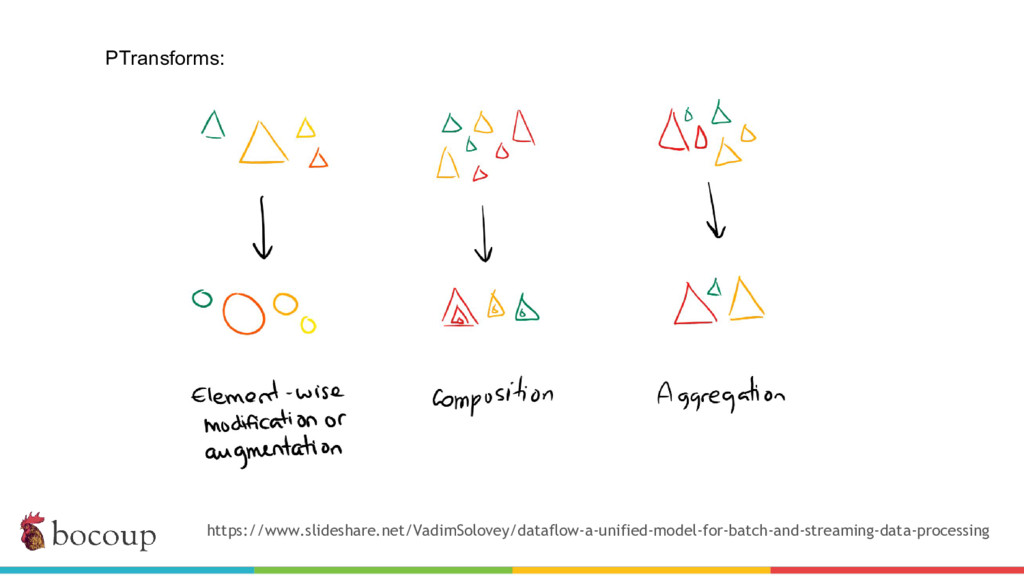{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
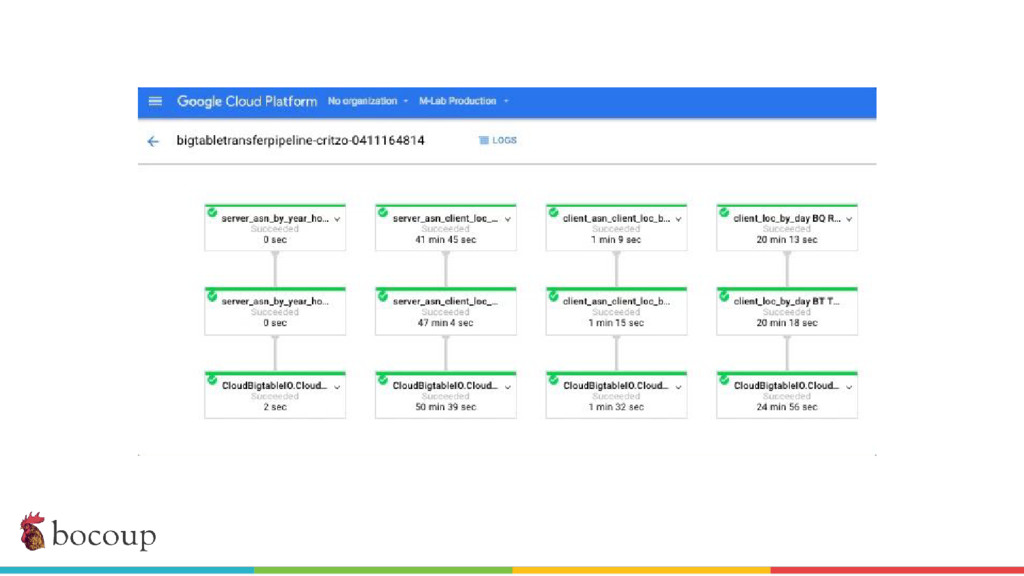{kind=link}
{kind=link}
{kind=link}
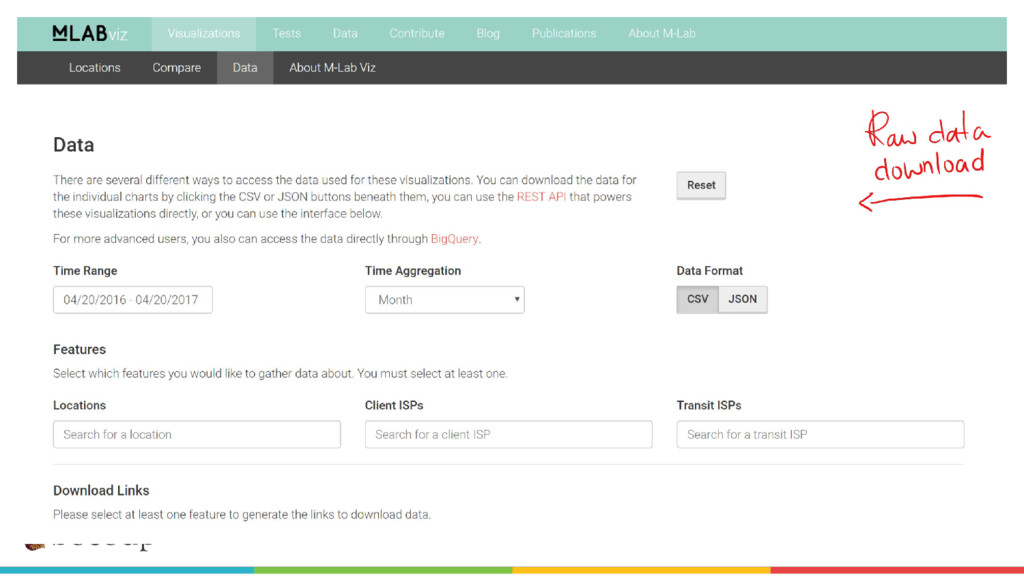{kind=link}
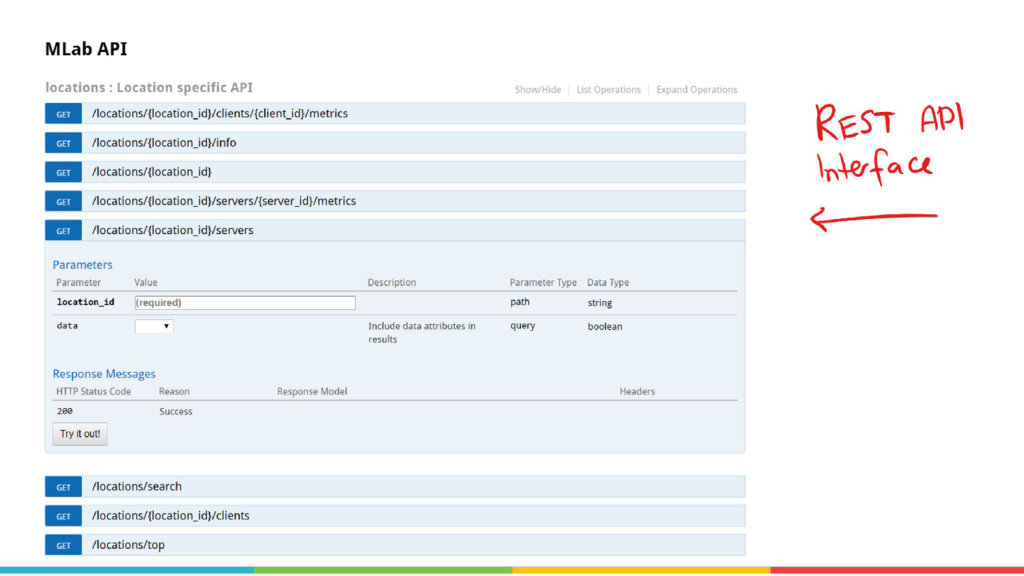{kind=link}
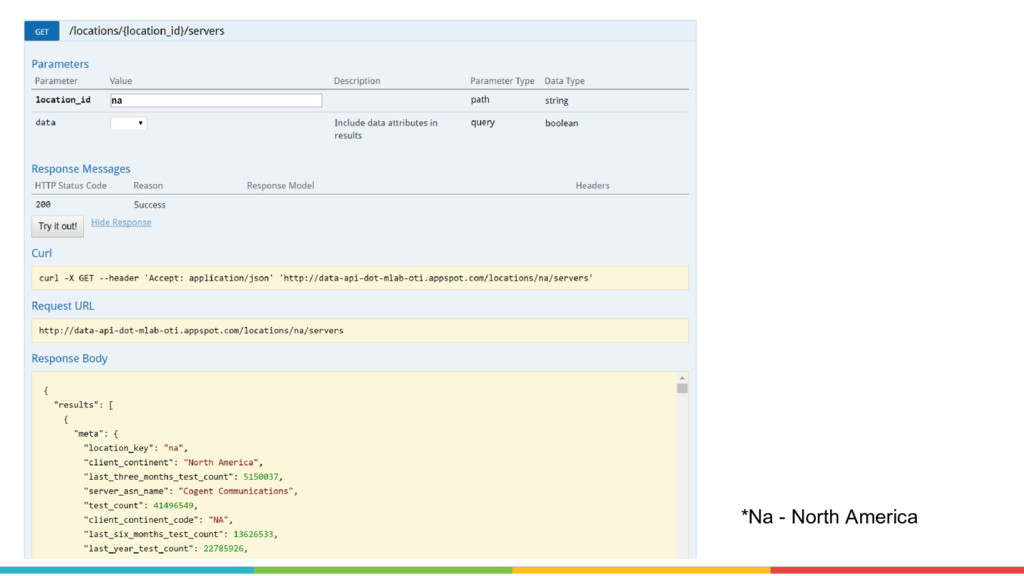{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Thank you Irene Ros [email protected] @ireneros Get in touch! [email protected]](https://files.speakerdeck.com/presentations/cd8ee3bdb9a54c49947de47650e447f2/slide_58.jpg){kind=link}