Text is one of the most interesting and varied data sources on the web and beyond, but it is one of the most difficult to deal with because it is fundamentally a messy, fragmented, and unnormalized format. If you have ever wanted to analyze and visualize text, but don’t know where to get started, this talk is for you.
Delivered at Plotcon 2016
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
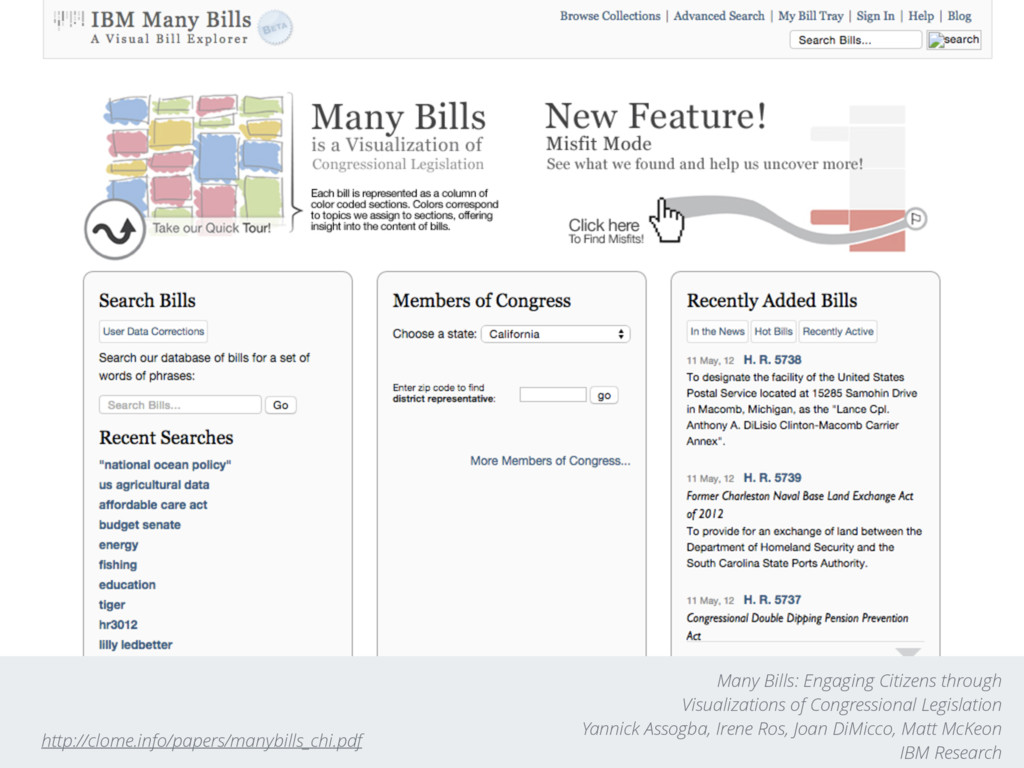{kind=link}
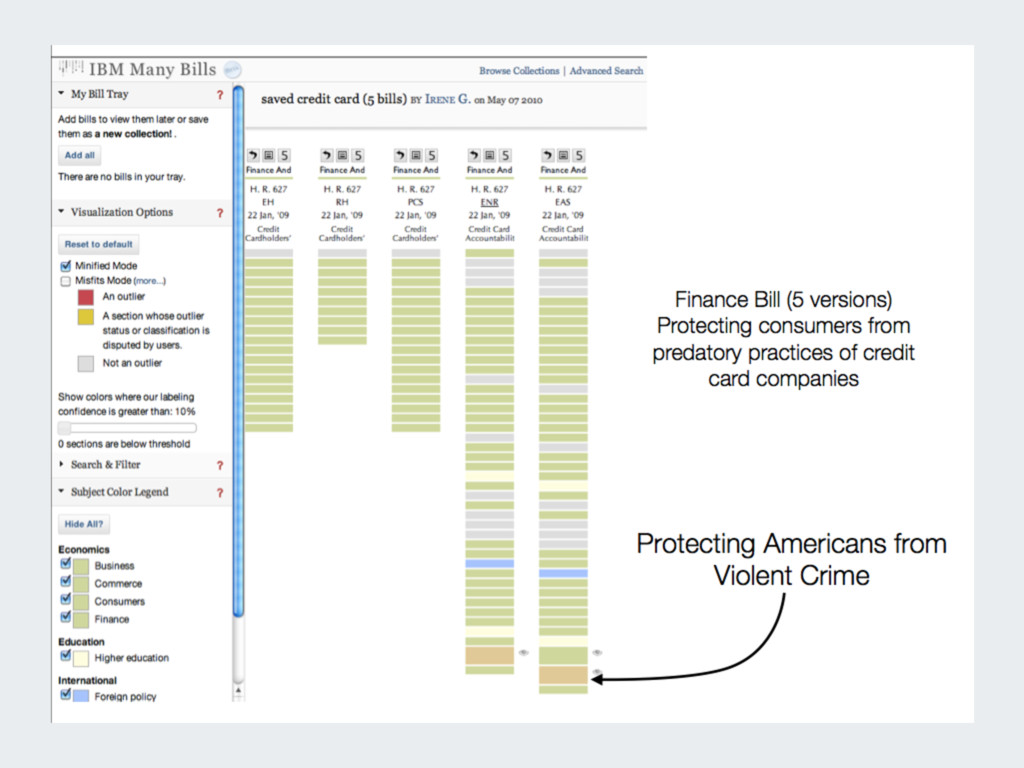{kind=link}
{kind=link}
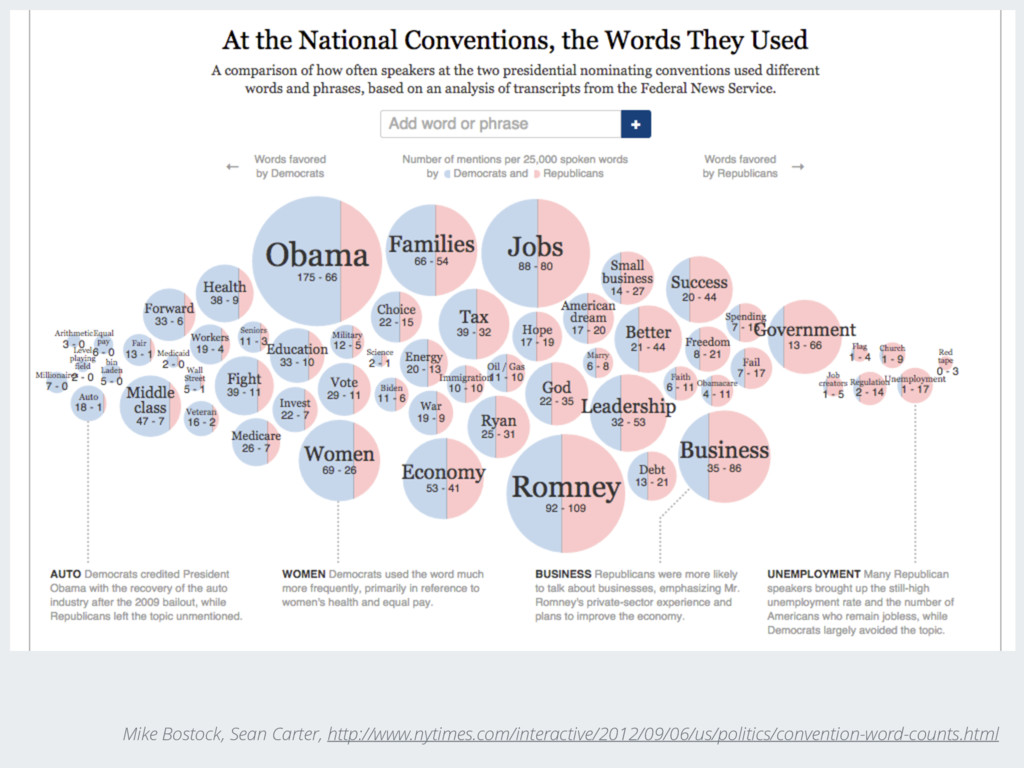{kind=link}
{kind=link}
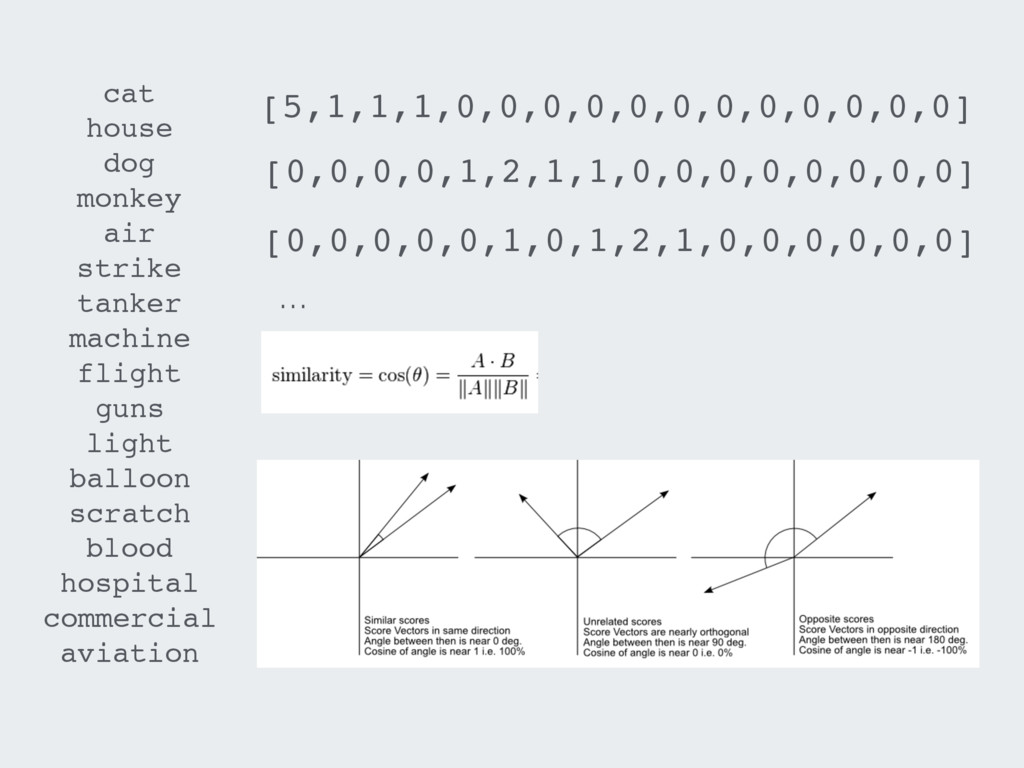{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Irene Ros [email protected] @ireneros http:/ /ireneros.com | http:/ /bocoup.com/datavis THANK](https://files.speakerdeck.com/presentations/fcde6b3113e04eb6bffa2ebdcab86834/slide_63.jpg){kind=link}
{kind=link}