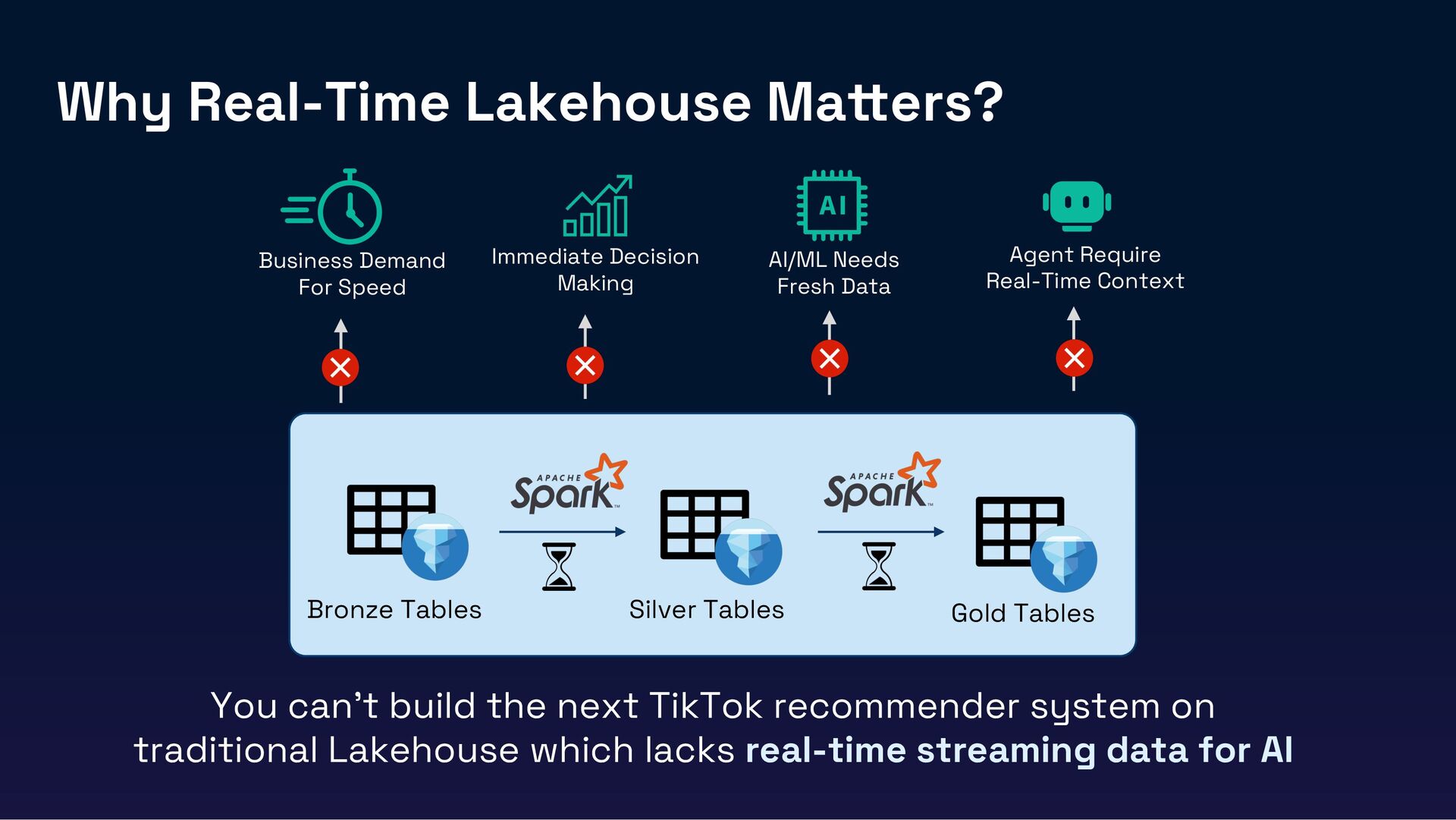
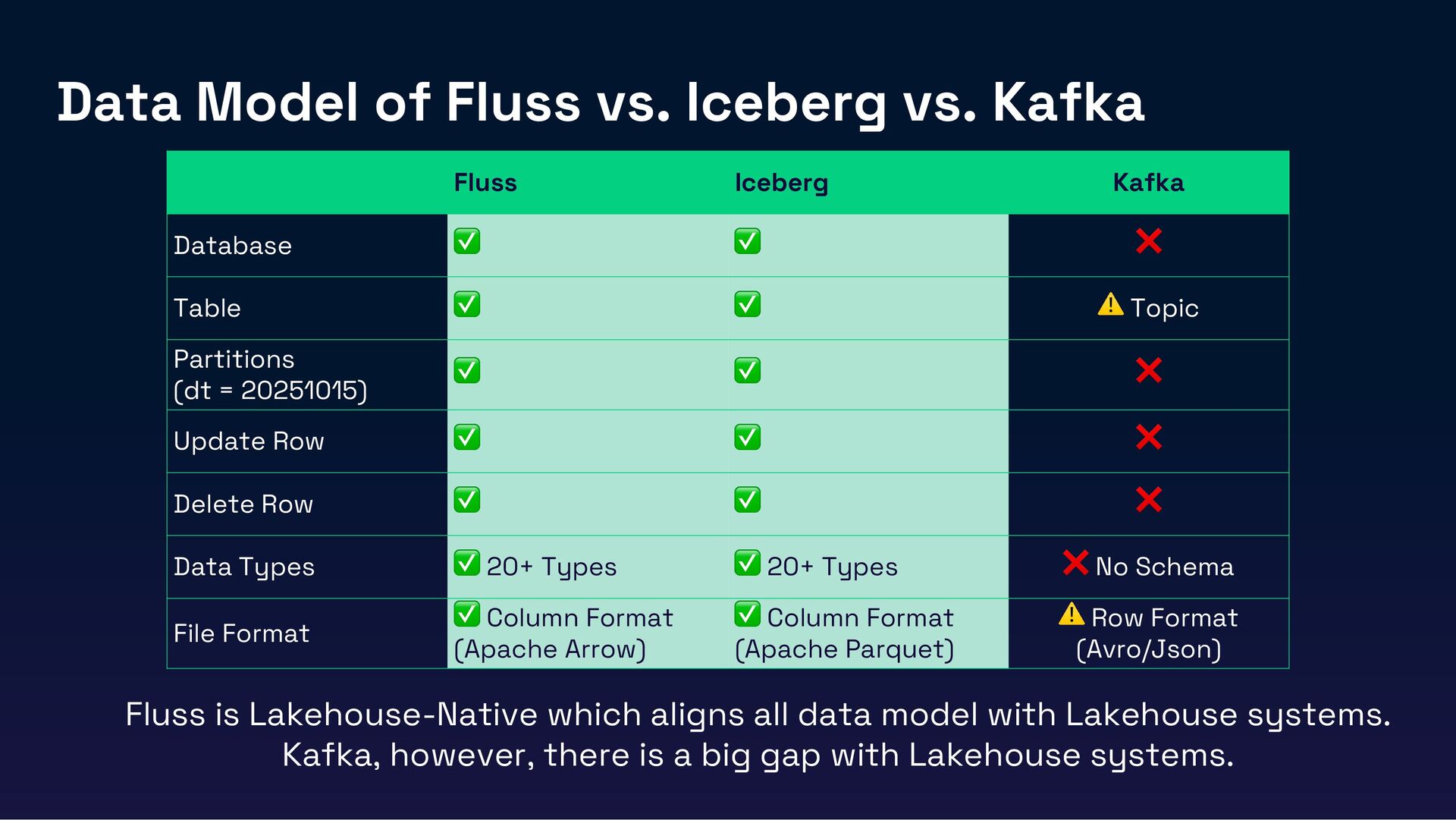
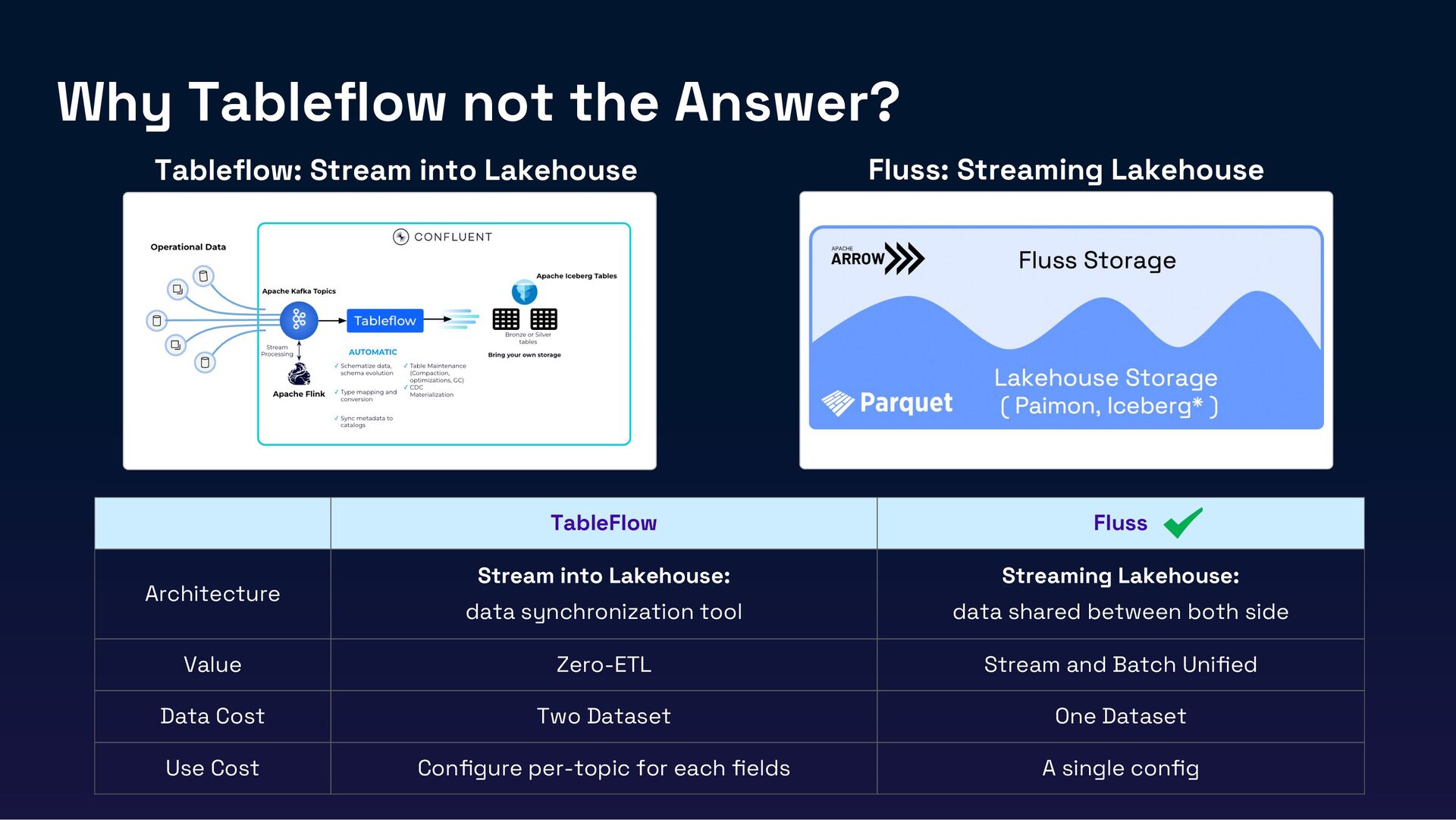
Modern data architectures demand seamless integration between real-time streaming and analytical systems. Especially in the era of Gen AI, real-time lakehouses are no longer optional—they’re essential. High-quality, real-time data is critical to ensuring the accuracy, responsiveness, and reliability of AI-driven applications. However, traditional batch-oriented lakehouses struggle to meet these demands, while legacy streaming tools like Kafka lack native integration with modern lakehouse architectures, leading to inefficiencies in cost, latency, and scalability.
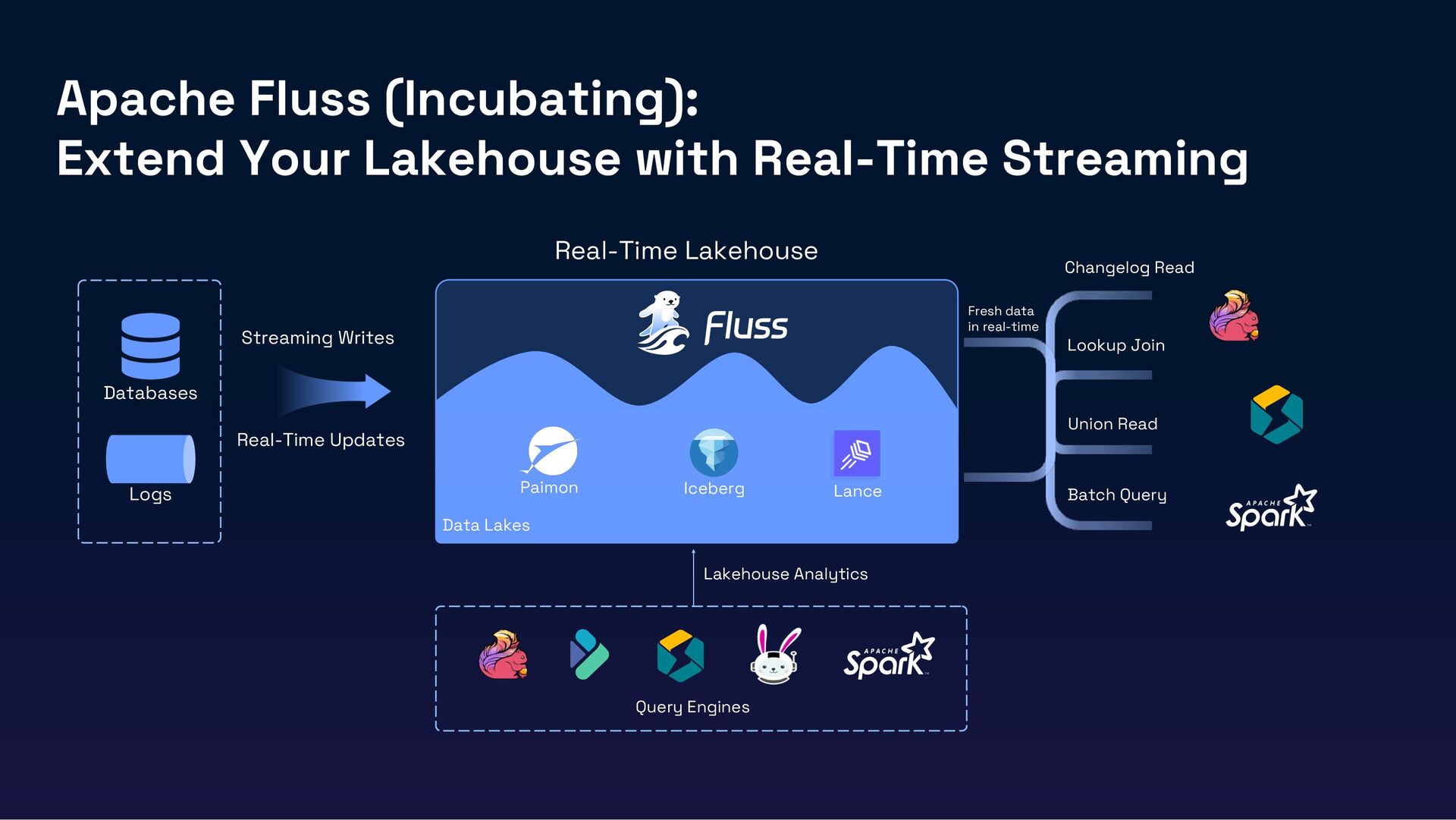
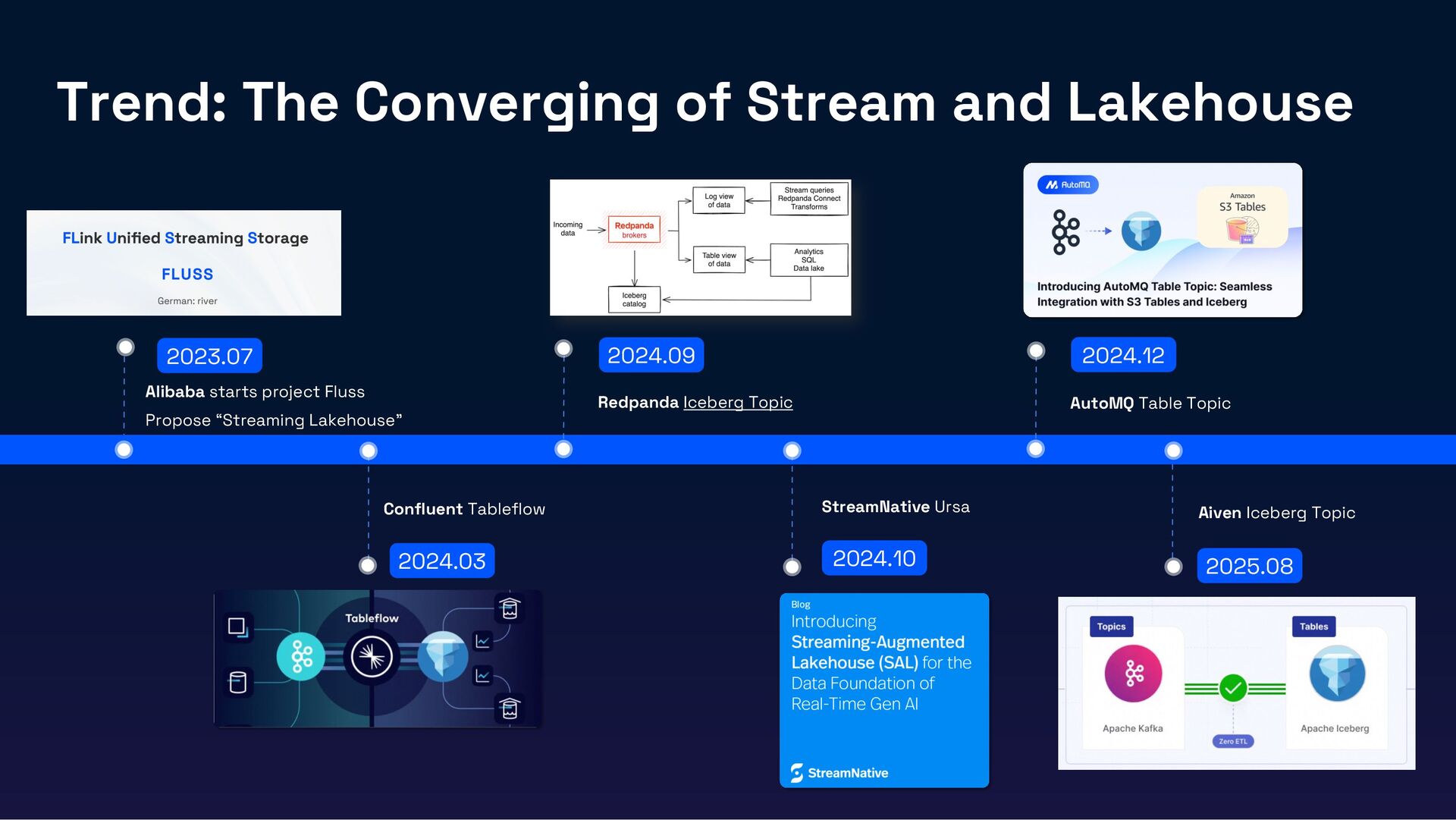
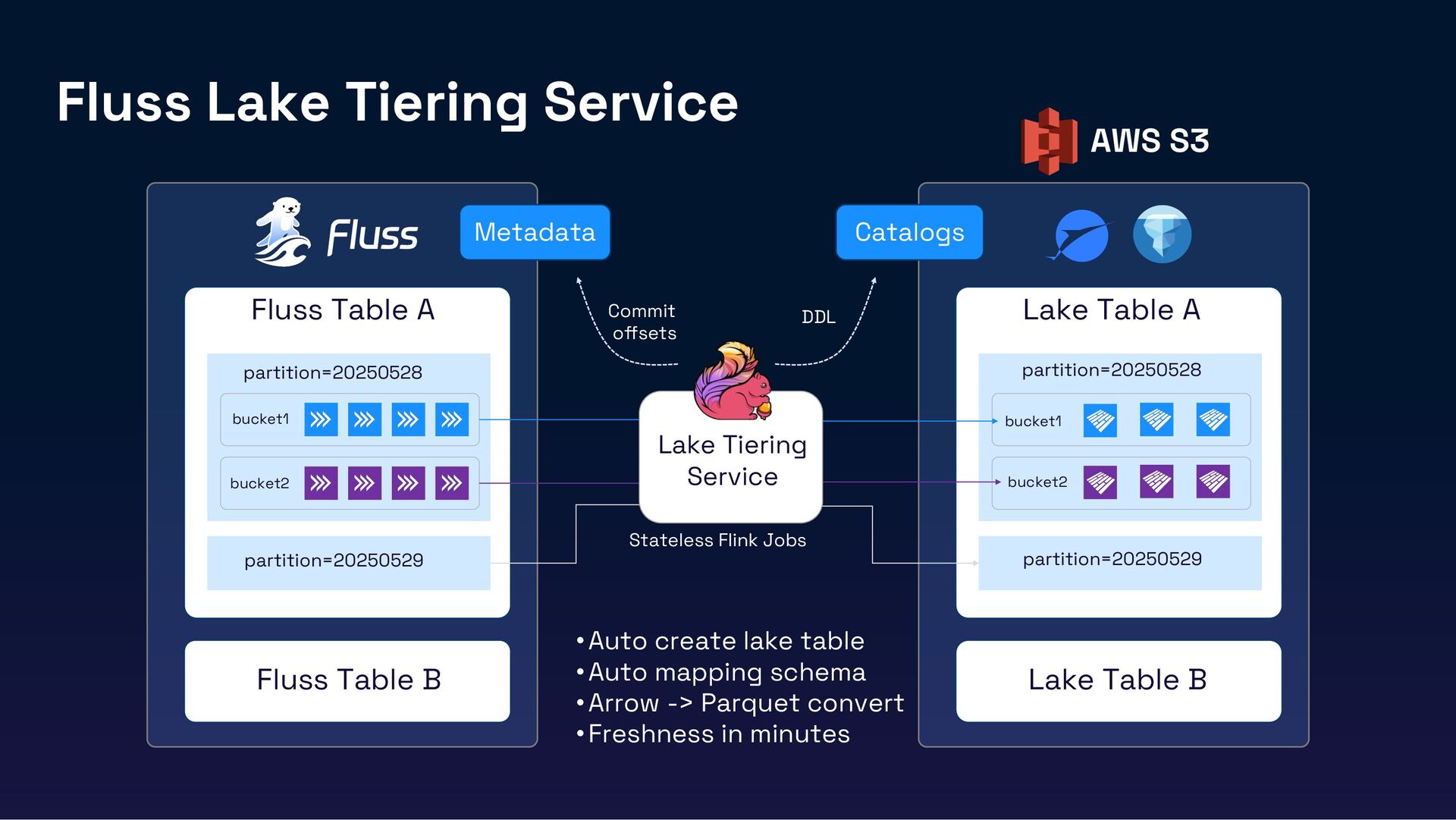
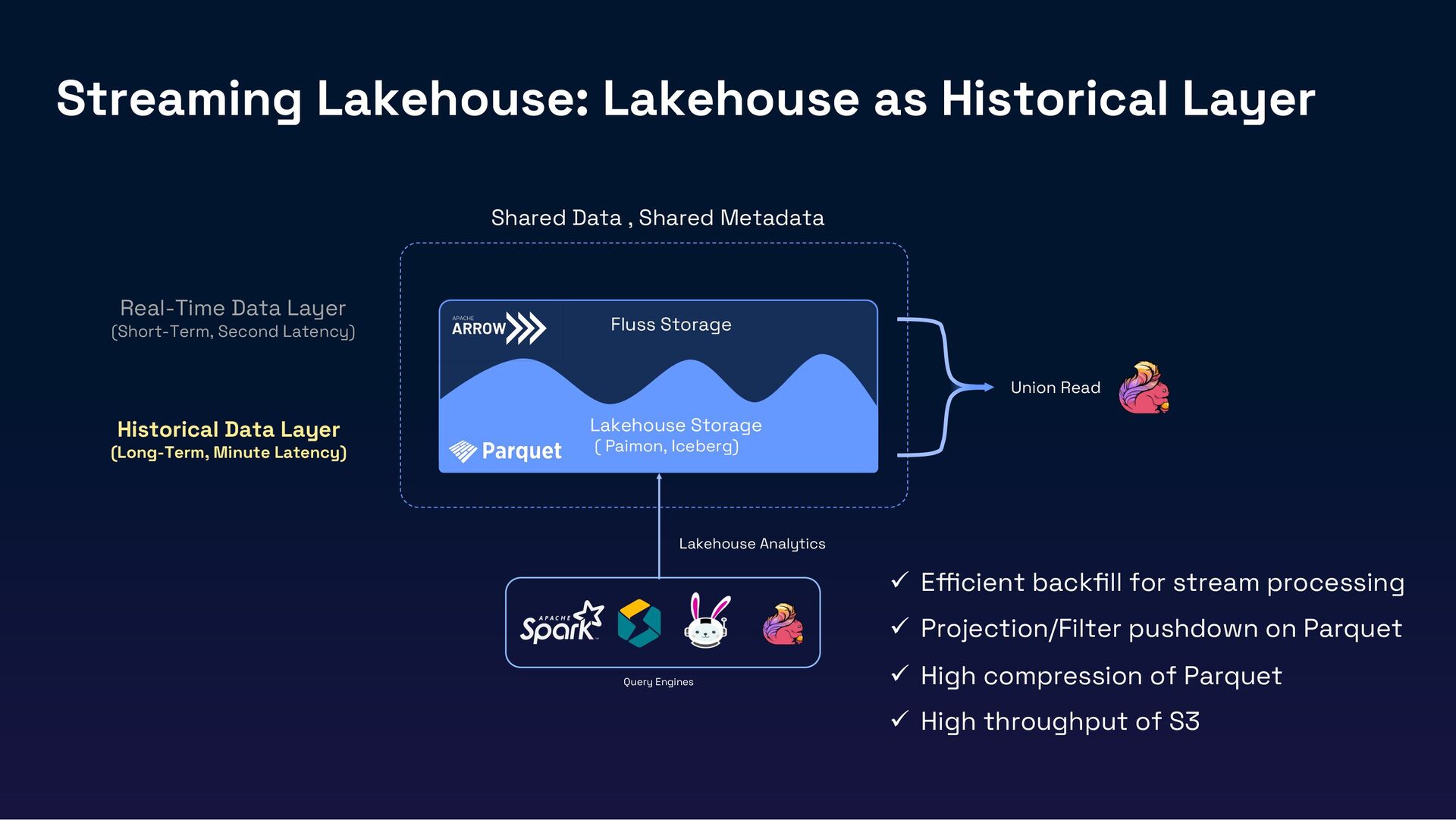
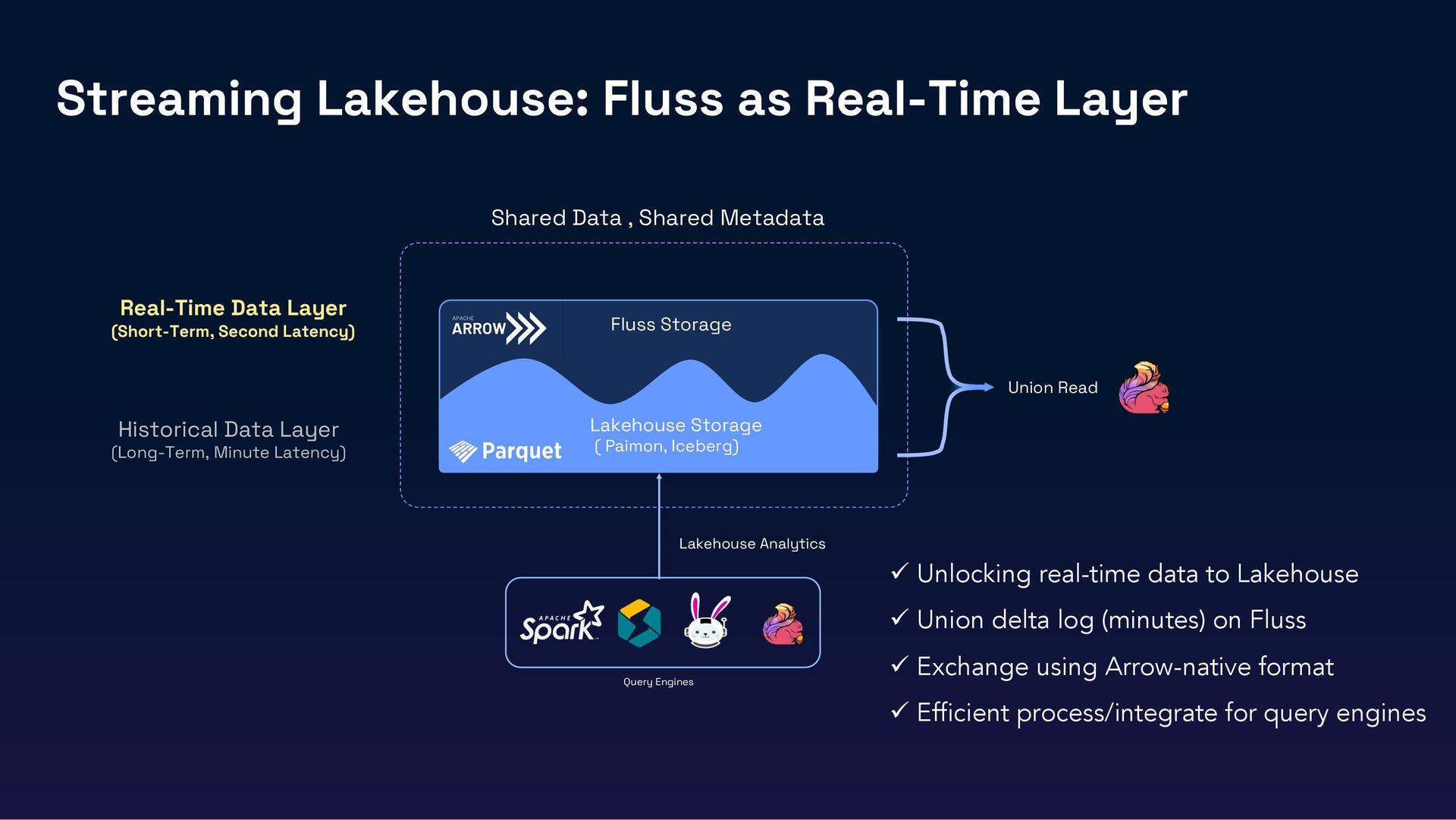
In this session, we’ll introduce Fluss, a Lakehouse-native streaming storage designed for analytics workloads. Discuss how Fluss unifies data streaming and data Lakehouse by serving real-time streaming data on top of the Lakehouse (Iceberg). This not only brings powerful analytics capabilities to data streams but also delivers low-latency data to Iceberg, transforming it into a Real-Time Lakehouse. Finally, we’ll explore real-world use cases where Fluss enables Real-Time Lakehouses, highlighting its benefits and the potential to power the next generation of AI applications.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
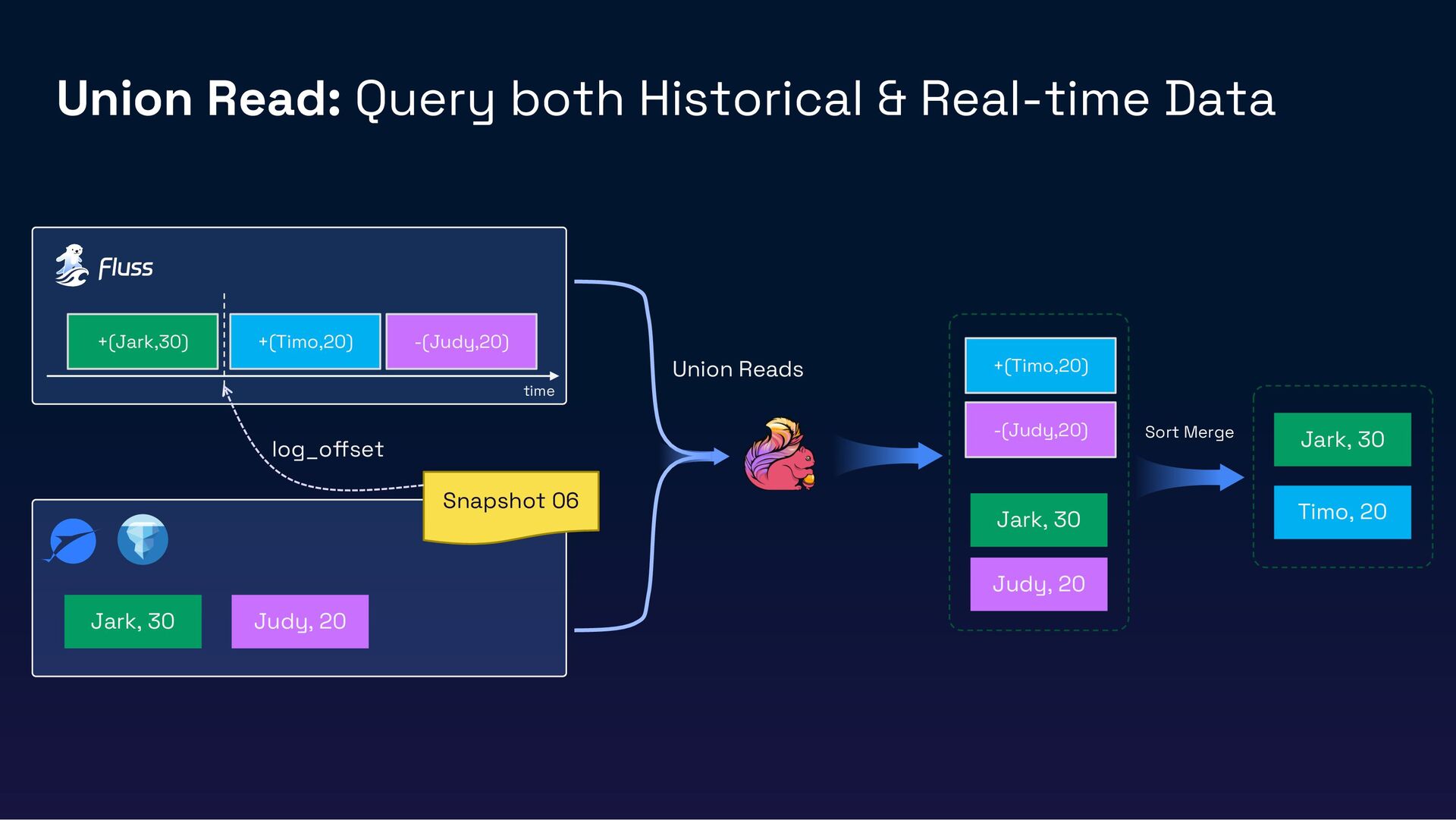{kind=link}
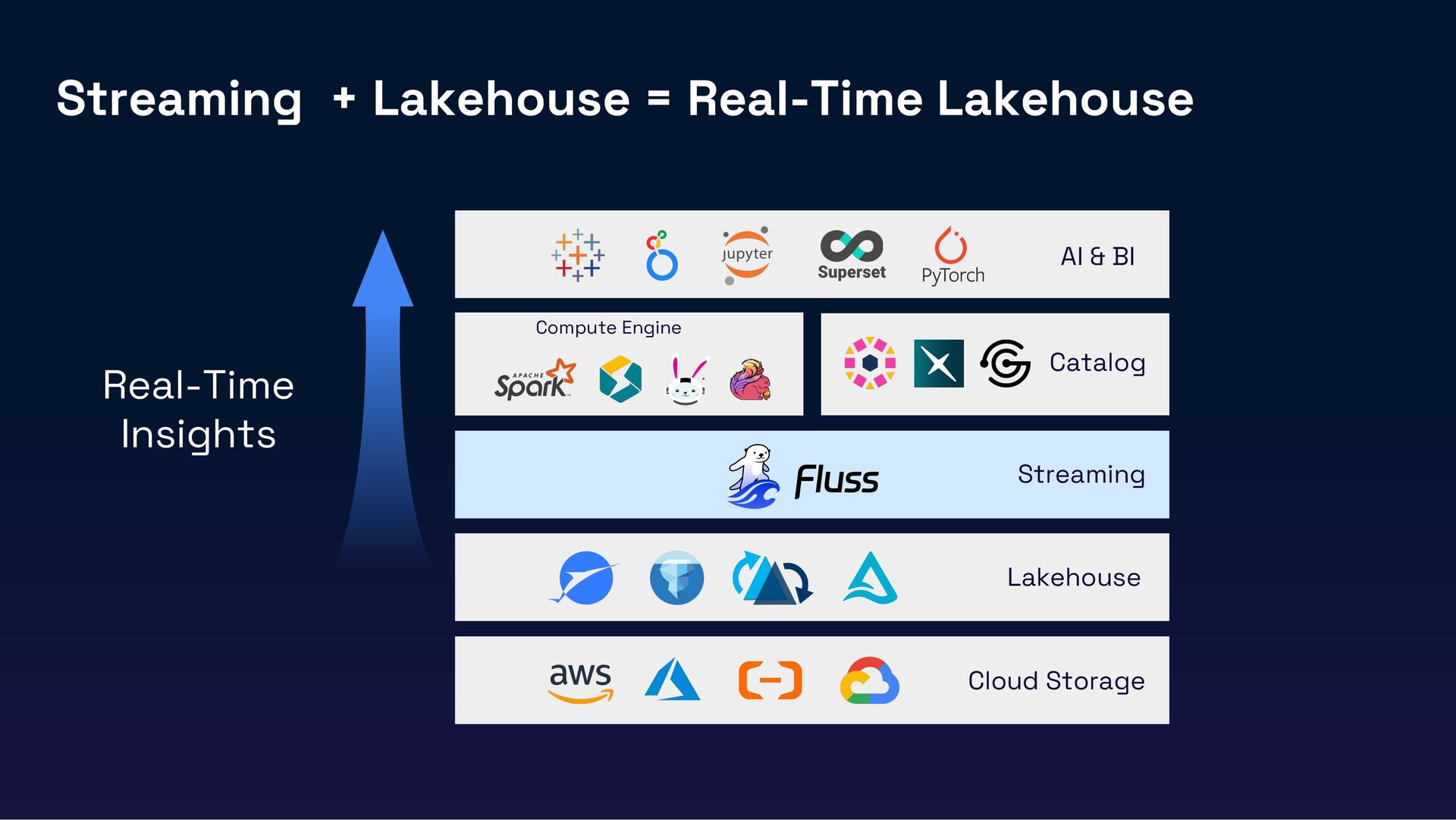{kind=link}
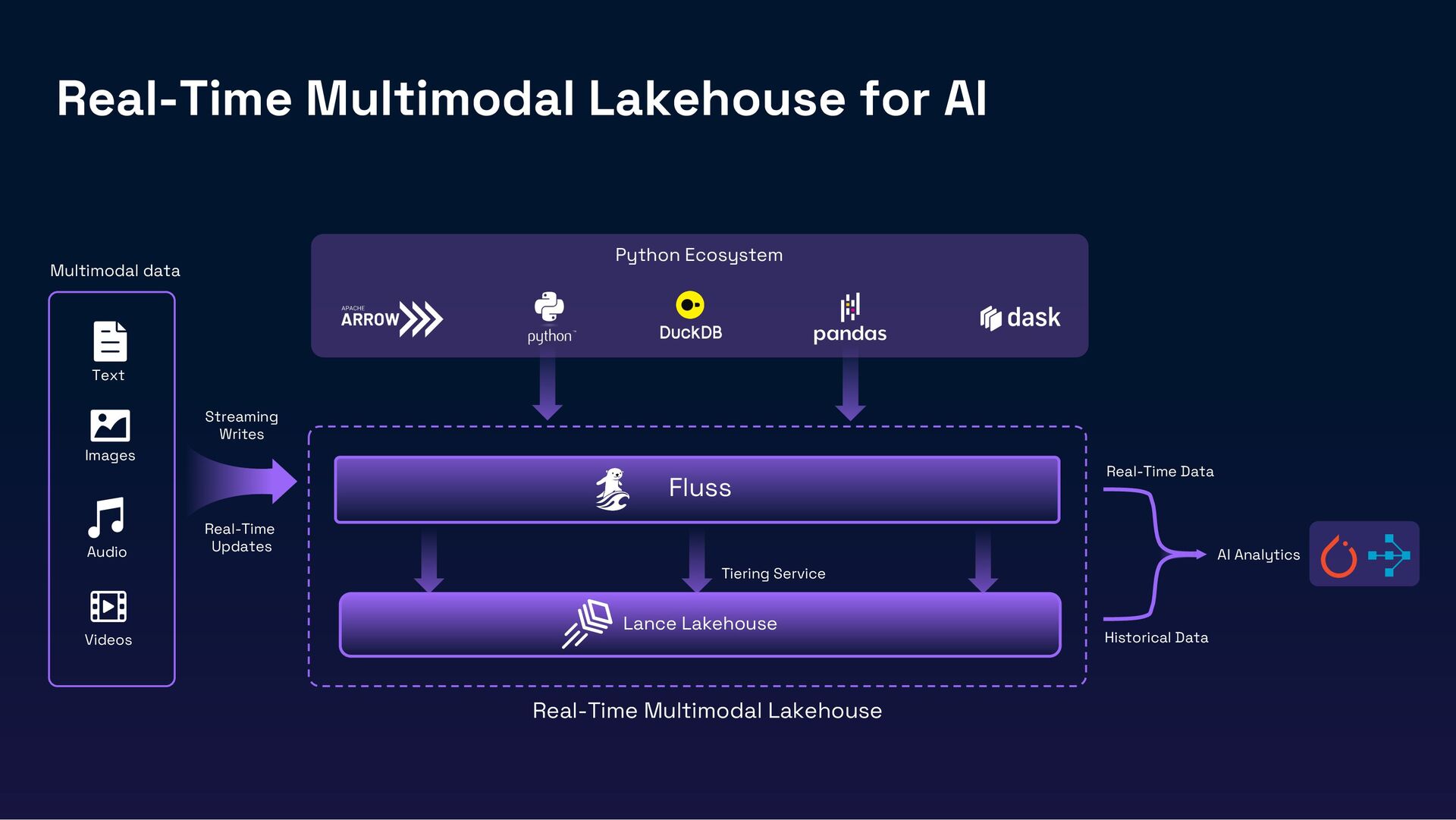{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}