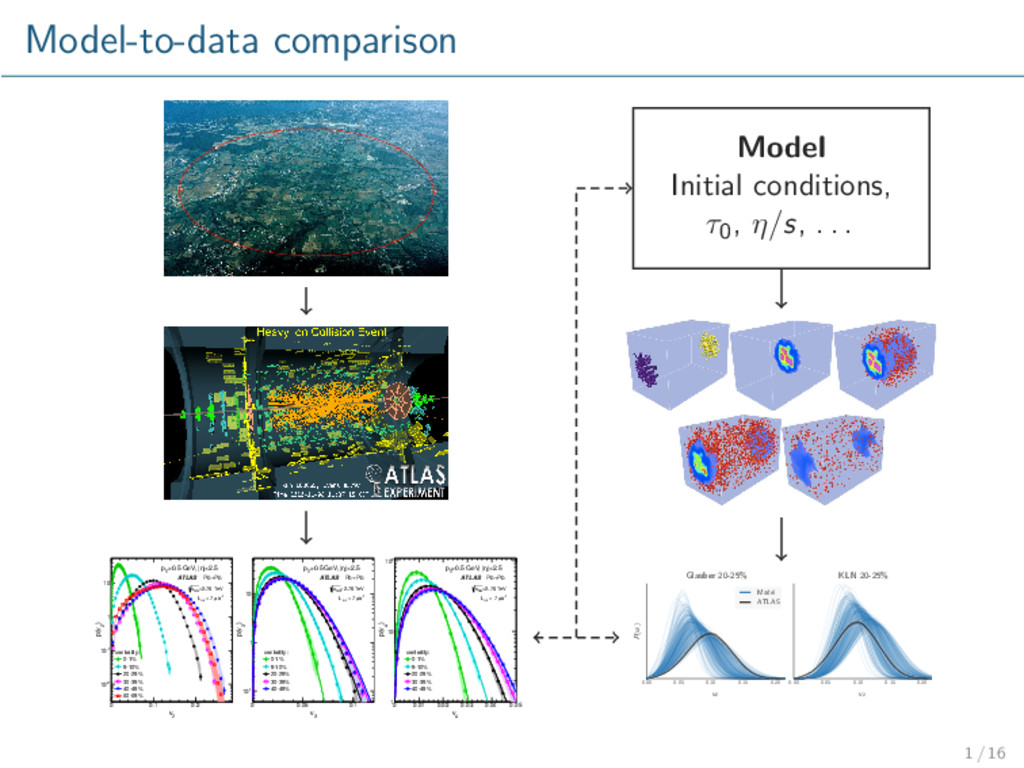
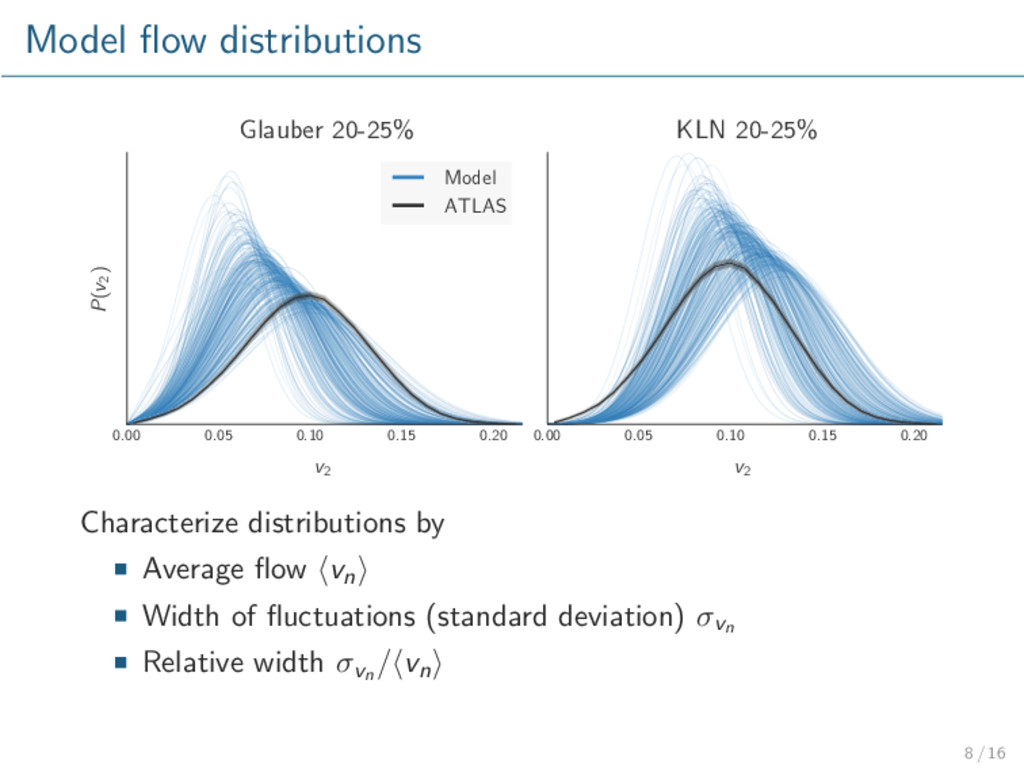
-2 10 -1 10 1 10 |<2.5 η >0.5 GeV, | T p centrality: 0-1% 5-10% 20-25% 30-35% 40-45% 60-65% ATLAS Pb+Pb =2.76 TeV NN s -1 b µ = 7 int L 3 v 0 0.05 0.1 ) 3 p(v -1 10 1 10 |<2.5 η >0.5 GeV, | T p centrality: 0-1% 5-10% 20-25% 30-35% 40-45% ATLAS Pb+Pb =2.76 TeV NN s -1 b µ = 7 int L 4 v 0 0.01 0.02 0.03 0.04 ) 4 p(v 1 10 2 10 |<2.5 η >0.5 GeV, | T p centrality: 0-1% 5-10% 20-25% 30-35% 40-45% ATLAS Pb+Pb =2.76 TeV NN s -1 b µ = 7 int L 0.05 Model Initial conditions, τ0, η/s, . . . 0.00 0.05 0.10 0.15 0.20 v2 P(v2 ) Glauber 20-25% Model ATLAS 0.00 0.05 0.10 0.15 0.20 v2 KLN 20-25% 1 / 16
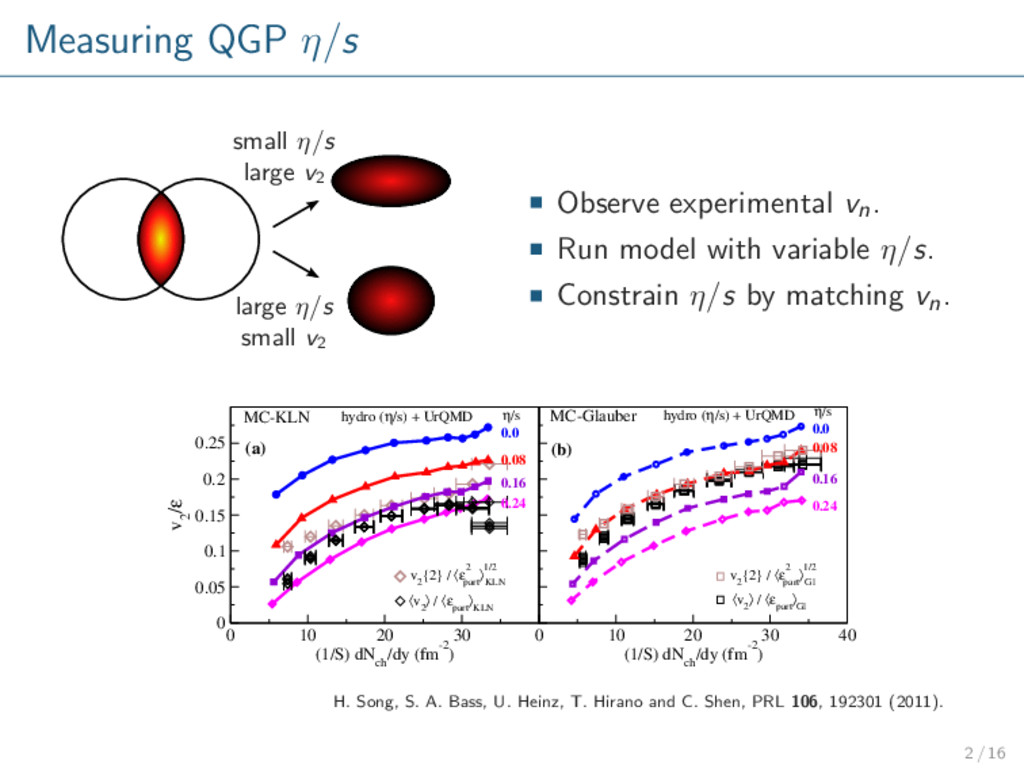
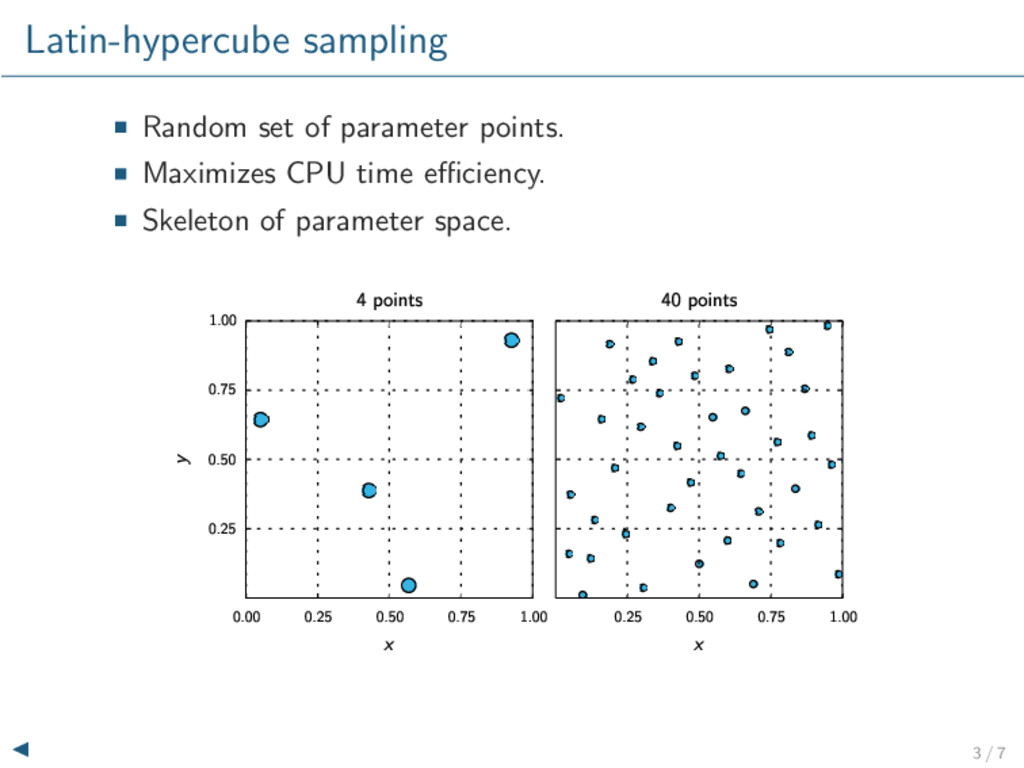
other parameters fixed. Only several discrete values. Qualitative constraints lacking uncertainty. This project∗ Event-by-event model. Vary all salient parameters: η/s, τ0, IC parameters, . . . Continuous parameter space. Quantitative constraints including uncertainty. ∗ See also J. Novak, K. Novak, S. Pratt, C. Coleman-Smith and R. Wolpert, PRC 89, 034917 (2014), arXiv:1303.5769 [nucl-th]. −→ −→ −→ −→ 3 / 16
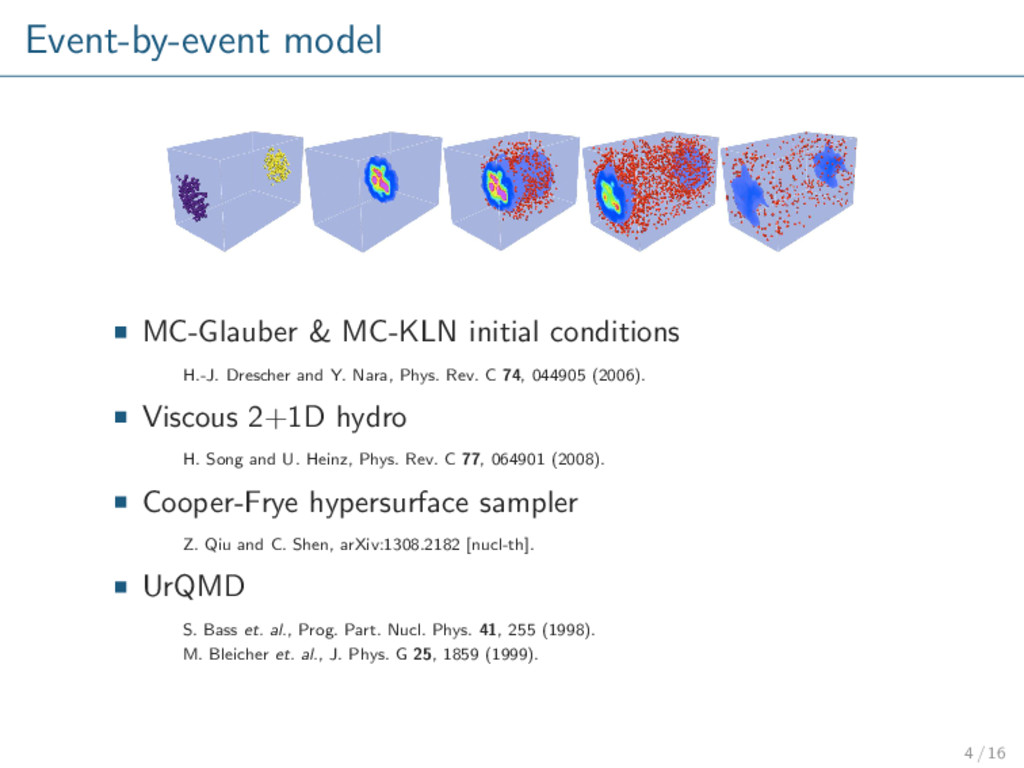
Y. Nara, Phys. Rev. C 74, 044905 (2006). Viscous 2+1D hydro H. Song and U. Heinz, Phys. Rev. C 77, 064901 (2008). Cooper-Frye hypersurface sampler Z. Qiu and C. Shen, arXiv:1308.2182 [nucl-th]. UrQMD S. Bass et. al., Prog. Part. Nucl. Phys. 41, 255 (1998). M. Bleicher et. al., J. Phys. G 25, 1859 (1999). 4 / 16
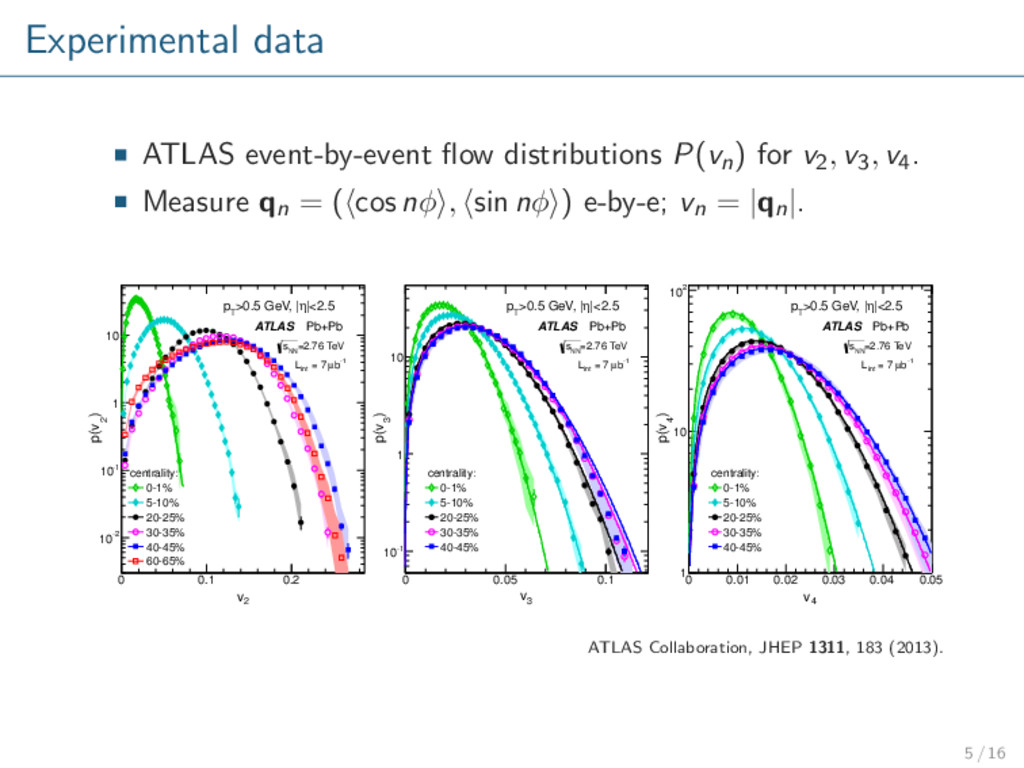
v4. Measure qn = ( cos nφ , sin nφ ) e-by-e; vn = |qn|. 2 v 0 0.1 0.2 ) 2 p(v -2 10 -1 10 1 10 |<2.5 η >0.5 GeV, | T p centrality: 0-1% 5-10% 20-25% 30-35% 40-45% 60-65% ATLAS Pb+Pb =2.76 TeV NN s -1 b µ = 7 int L 3 v 0 0.05 0.1 ) 3 p(v -1 10 1 10 |<2.5 η >0.5 GeV, | T p centrality: 0-1% 5-10% 20-25% 30-35% 40-45% ATLAS Pb+Pb =2.76 TeV NN s -1 b µ = 7 int L 4 v 0 0.01 0.02 0.03 0.04 ) 4 p(v 1 10 2 10 |<2.5 η >0.5 GeV, | T p centrality: 0-1% 5-10% 20-25% 30-35% 40-45% ATLAS Pb+Pb =2.76 TeV NN s -1 b µ = 7 int L 0.05 ATLAS Collaboration, JHEP 1311, 183 (2013). 5 / 16
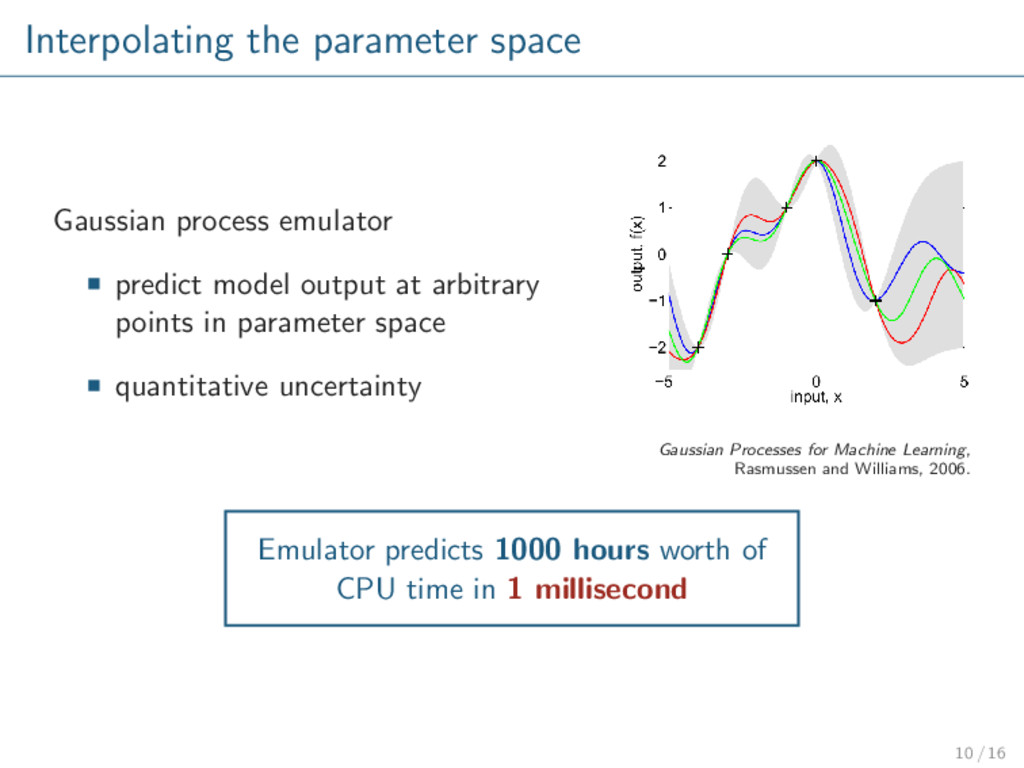
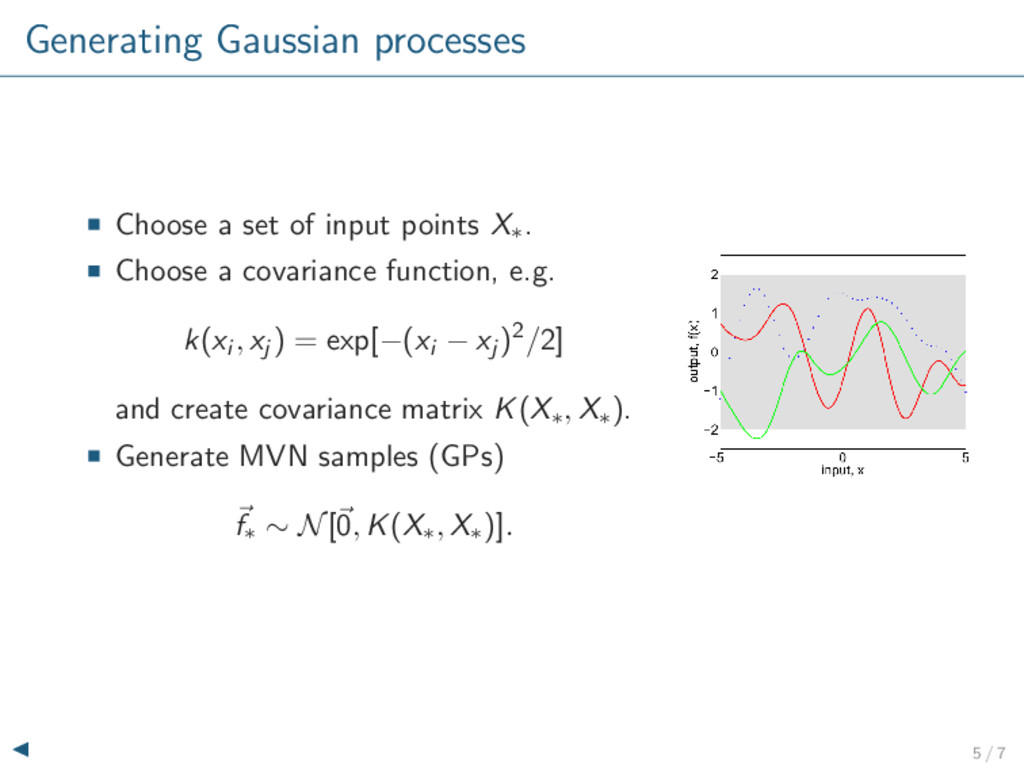
at arbitrary points in parameter space quantitative uncertainty Gaussian Processes for Machine Learning, Rasmussen and Williams, 2006. Emulator predicts 1000 hours worth of CPU time in 1 millisecond 10 / 16
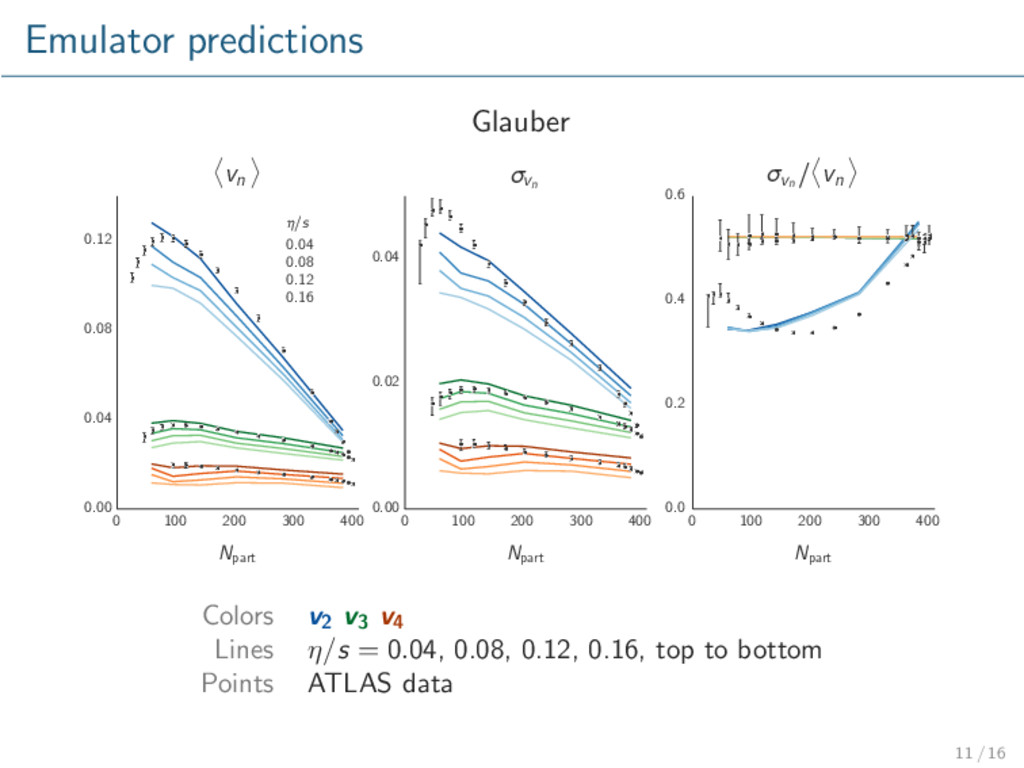
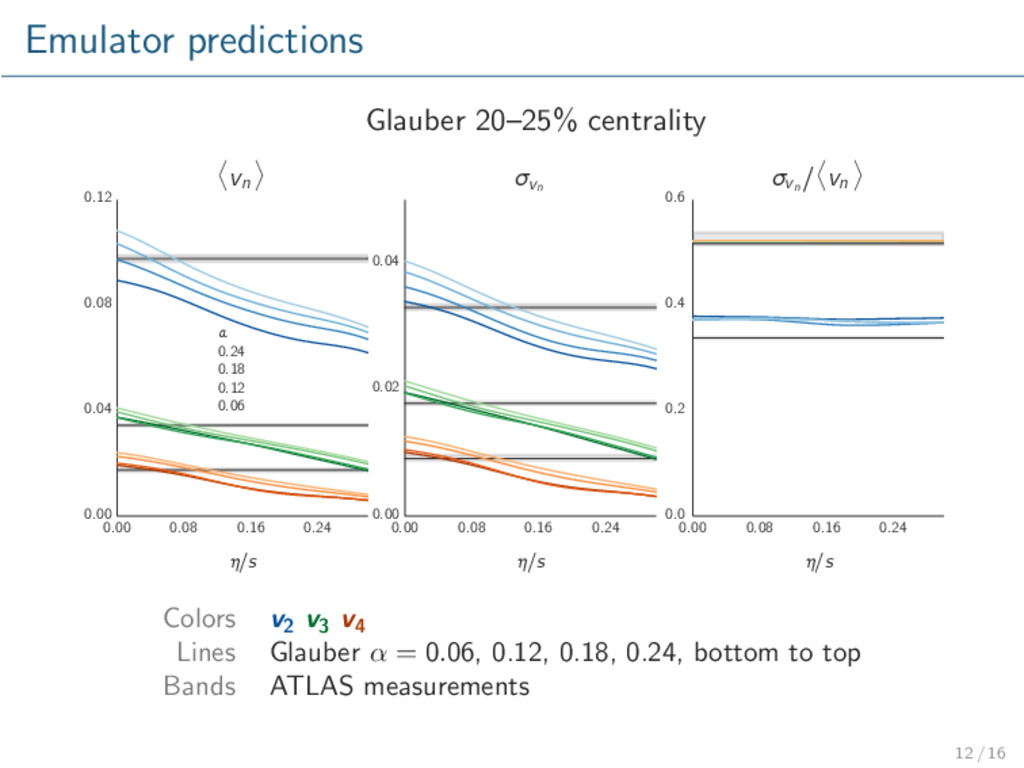
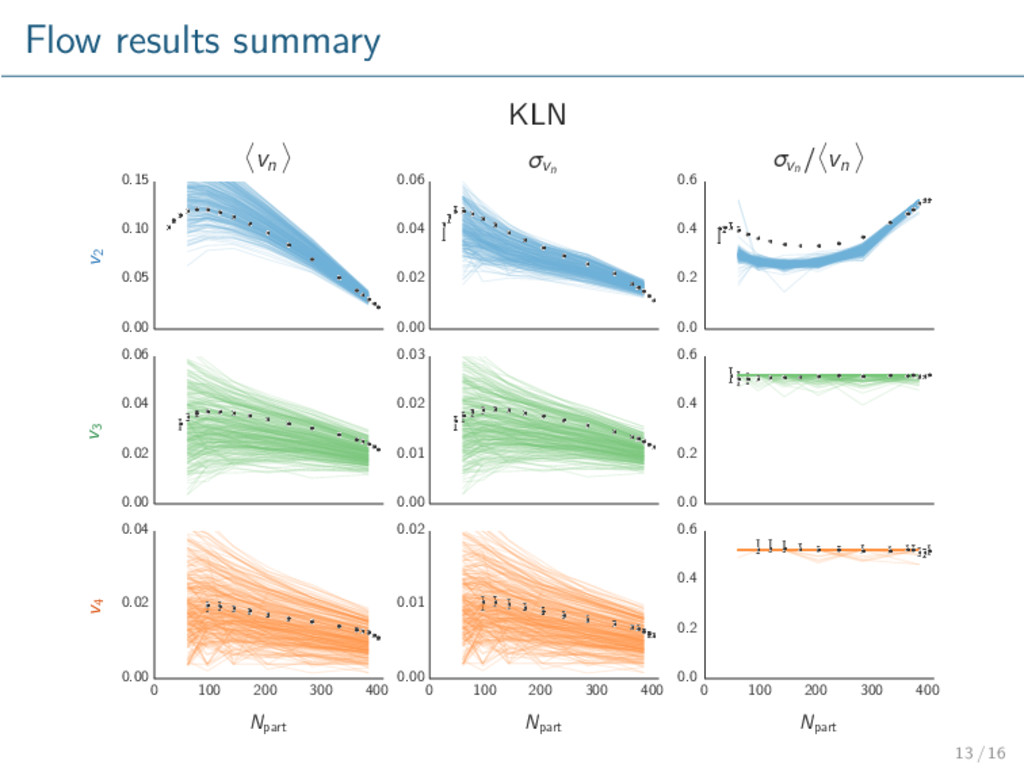
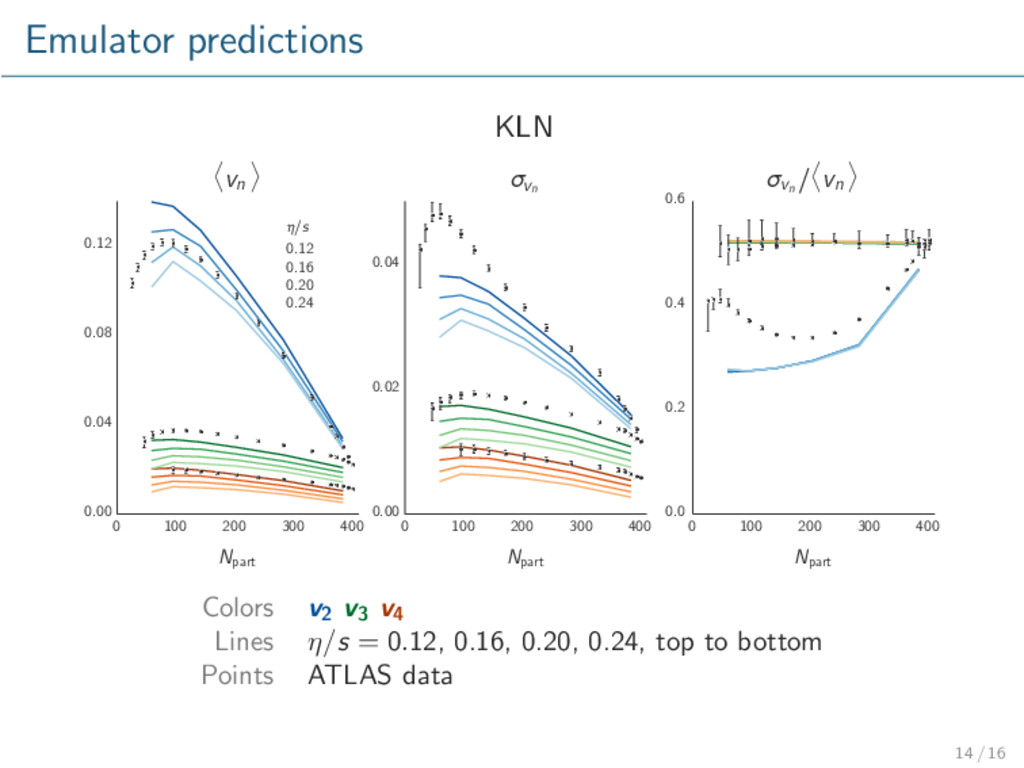
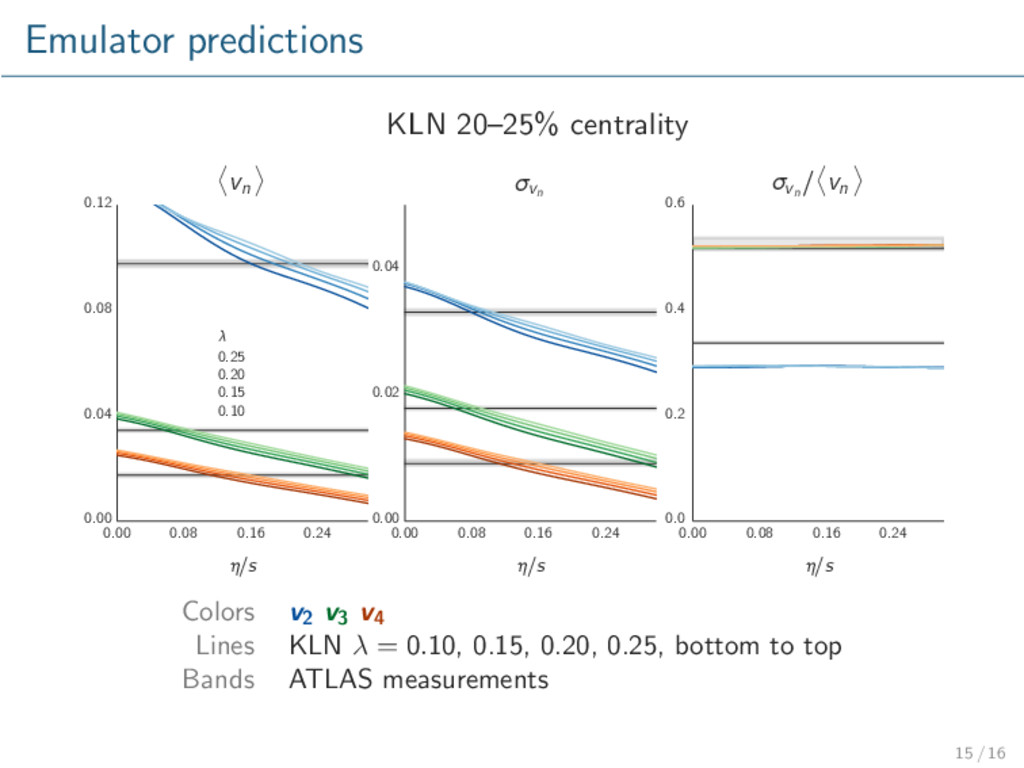
model validation / exclusion. Glauber qualitatively describes data. KLN does not. Repeat with more advanced models, especially initial conditions. Rigorously calibrate model to data → extract optimal parameters with uncertainty. Consider other observables, e.g. multiplicity. 16 / 16
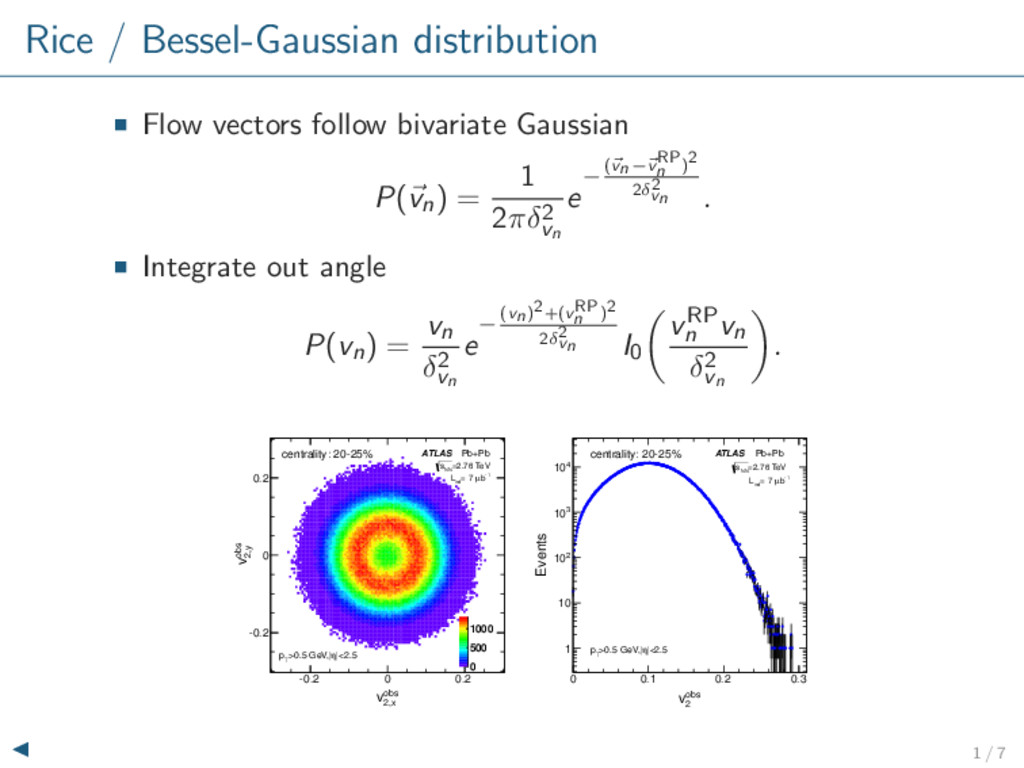
= 1 2πδ2 vn e −(vn−vRP n )2 2δ2 vn . Integrate out angle P(vn) = vn δ2 vn e −(vn)2+(vRP n )2 2δ2 vn I0 vRP n vn δ2 vn . obs 2,x v -0.2 0 0.2 obs 2,y v -0.2 0 0.2 0 500 1000 centrality: 20-25% ATLAS Pb+Pb =2.76 TeV NN s -1 b µ = 7 int L |<2.5 η >0.5 GeV,| T p obs 2 v 0 0.1 0.2 0.3 Events 1 10 2 10 3 10 4 10 |<2.5 η >0.5 GeV,| T p ATLAS Pb+Pb =2.76 TeV NN s -1 b µ = 7 int L centrality: 20-25% 1 / 7
and nonflow P(vobs n ) = P(vobs n |vn)P(vn) dvn where P(vobs n |vn) is the response function. Pure statistical smearing → Gaussian response P(vobs n |vn) = vobs n δ2 vn e −(vobs n )2+(vn)2 2δ2 vn I0 vnvobs n δ2 vn . vRP n unaffected; width increased as δ2 vn → δ2 vn + 1/2M. 2 / 7
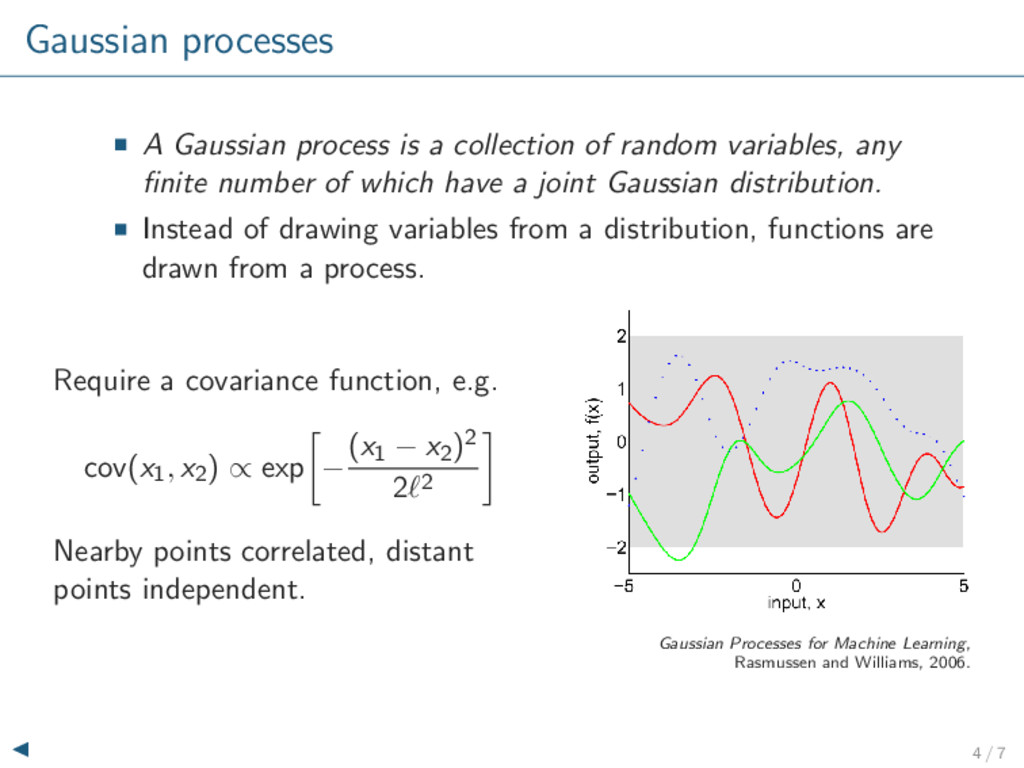
variables, any finite number of which have a joint Gaussian distribution. Instead of drawing variables from a distribution, functions are drawn from a process. Require a covariance function, e.g. cov(x1, x2) ∝ exp − (x1 − x2)2 2 2 Nearby points correlated, distant points independent. Gaussian Processes for Machine Learning, Rasmussen and Williams, 2006. 4 / 7
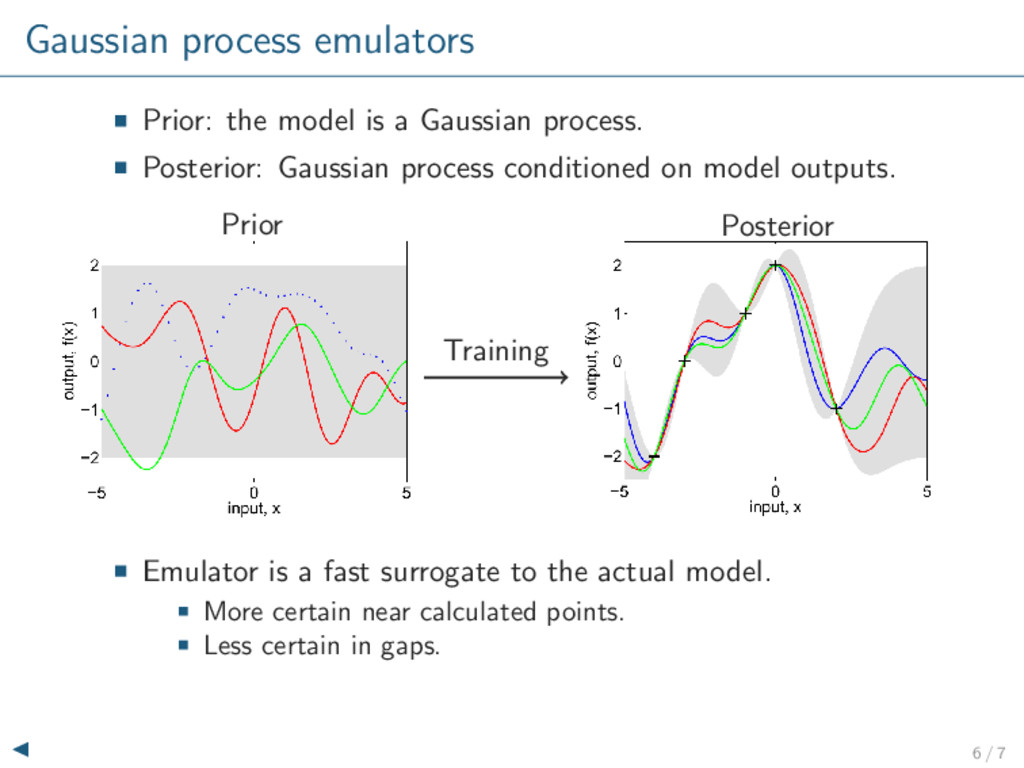
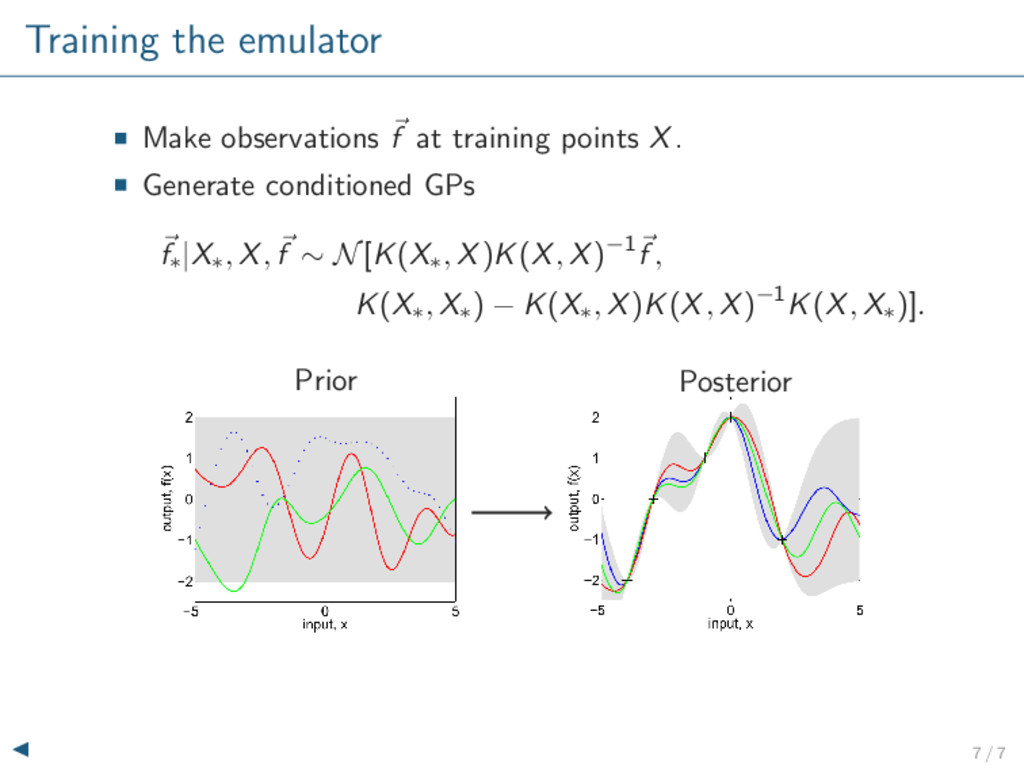
Posterior: Gaussian process conditioned on model outputs. Training Prior Posterior Emulator is a fast surrogate to the actual model. More certain near calculated points. Less certain in gaps. 6 / 7
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}