development effort is spent on them If we didn’t have them, programming would be easy (maybe even automatic) How many bugs aren’t edge cases? This is important stuff!
pointless edge case module GooglePlus module_function def has_any_circles?(user) !!check_api_for_any_circles?(user) end def circles(user) if has_any_circles? user get_circles_from_api(user) else nil end end # ... end
circles case, if needed circles = GooglePlus.circles(user) if circles.empty? # handle no circles here... else circles.each do |circle| # use with circle here... end end
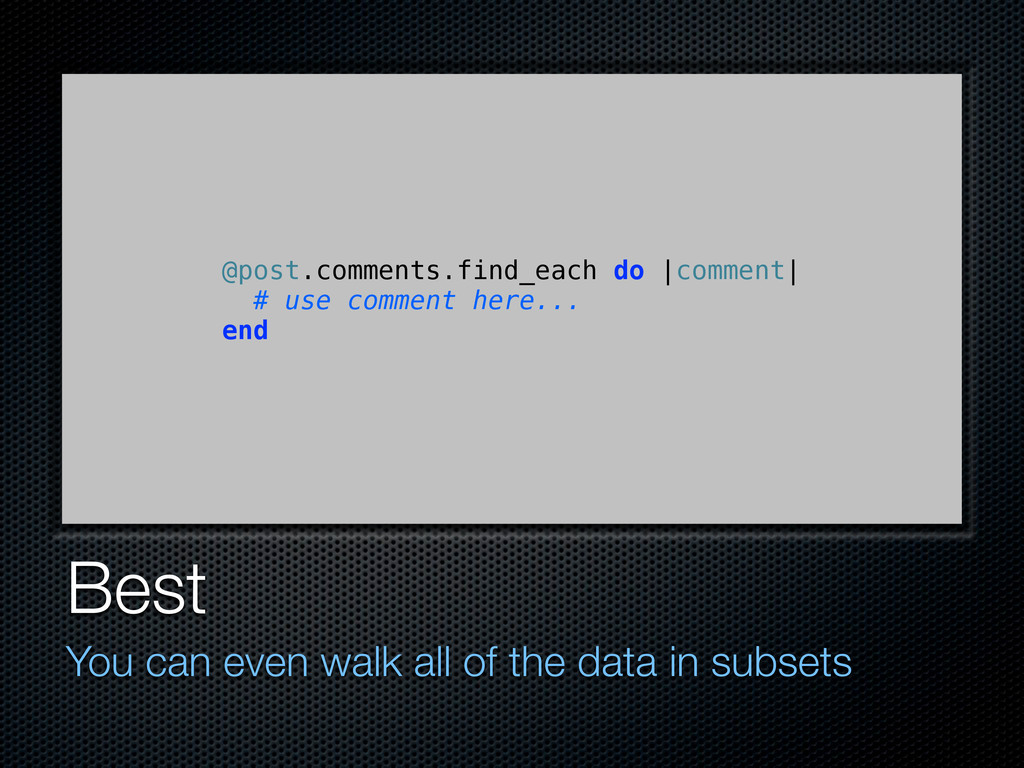
in whenever possible Big data is a scary edge case Draw only what you need at once Come back for more as needed This applies to all data, including database queries
do it "is editable within an hour of creation" do Post.new(created_at: 10.minutes.ago).must_be :editable? end it "is not editable beyond an hour of creation" do Post.new(created_at: 1.day.ago).wont_be :editable? end end
do it "is editable within an hour of creation" do Post.new(created_at: 10.minutes.ago).must_be :editable? end it "is not editable beyond an hour of creation" do Post.new(created_at: 1.day.ago).wont_be :editable? end end
instead describe Post do it "is editable within an hour of creation" do Post.new(created_at: 1.hour.ago).must_be :editable? end it "is not editable beyond an hour of creation" do Post.new(created_at: (1.hour + 1.minute).ago).wont_be :editable? end end
instead describe Post do it "is editable within an hour of creation" do Post.new(created_at: 1.hour.ago).must_be :editable? end it "is not editable beyond an hour of creation" do Post.new(created_at: (1.hour + 1.minute).ago).wont_be :editable? end end
guarantee we do not touch API's class Geokit::Geocoders::MultiGeocoder def self.geocode(*args) fail "Tried to contact Google" end end class Boomerang::APICall def initialize(*args) fail "Tried to contact Amazon" end end module SendGridDisabler def make_api_call(*args) fail "Tried to contact SendGrid" end private :make_api_call end SendGrid.extend(SendGridDisabler)
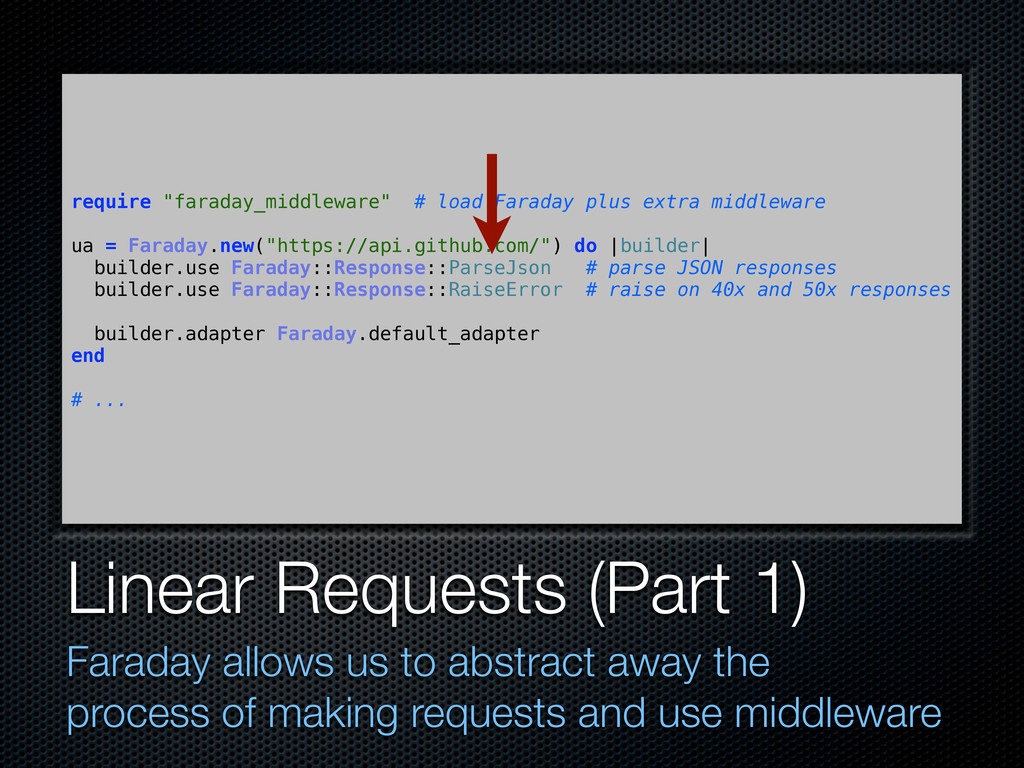
the process of making requests and use middleware require "faraday_middleware" # load Faraday plus extra middleware ua = Faraday.new("https://api.github.com/") do |builder| builder.use Faraday::Response::ParseJson # parse JSON responses builder.use Faraday::Response::RaiseError # raise on 40x and 50x responses builder.adapter Faraday.default_adapter end # ...
the process of making requests and use middleware require "faraday_middleware" # load Faraday plus extra middleware ua = Faraday.new("https://api.github.com/") do |builder| builder.use Faraday::Response::ParseJson # parse JSON responses builder.use Faraday::Response::RaiseError # raise on 40x and 50x responses builder.adapter Faraday.default_adapter end # ...
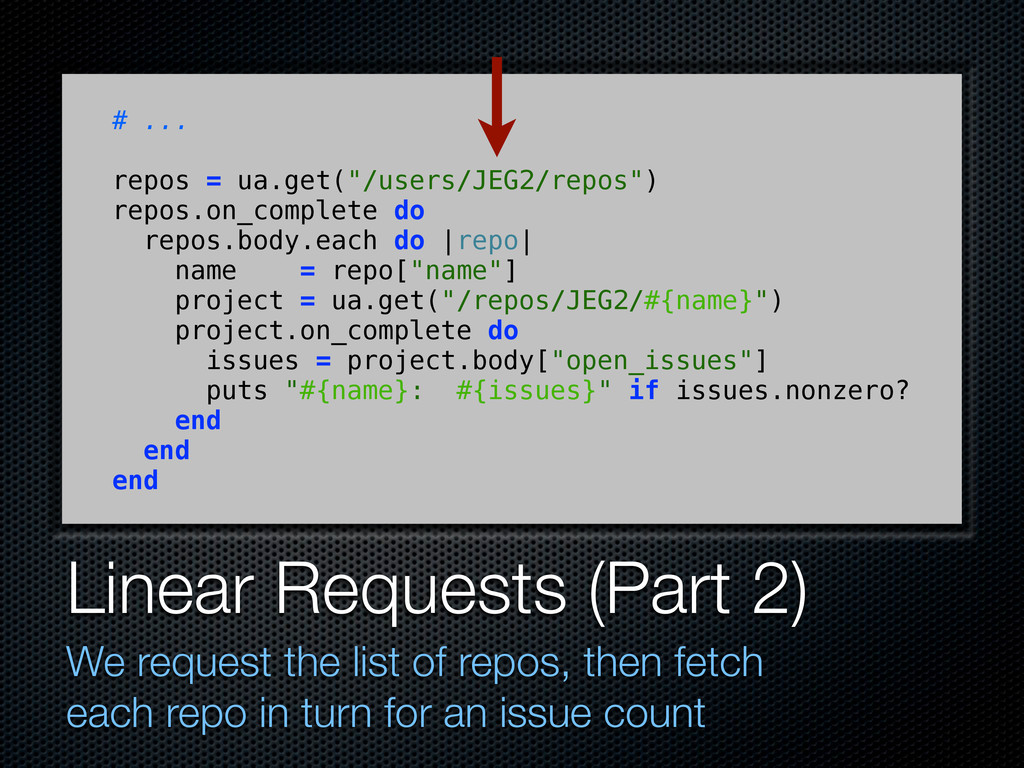
then fetch each repo in turn for an issue count # ... repos = ua.get("/users/JEG2/repos") repos.on_complete do repos.body.each do |repo| name = repo["name"] project = ua.get("/repos/JEG2/#{name}") project.on_complete do issues = project.body["open_issues"] puts "#{name}: #{issues}" if issues.nonzero? end end end
then fetch each repo in turn for an issue count # ... repos = ua.get("/users/JEG2/repos") repos.on_complete do repos.body.each do |repo| name = repo["name"] project = ua.get("/repos/JEG2/#{name}") project.on_complete do issues = project.body["open_issues"] puts "#{name}: #{issues}" if issues.nonzero? end end end
then fetch each repo in turn for an issue count # ... repos = ua.get("/users/JEG2/repos") repos.on_complete do repos.body.each do |repo| name = repo["name"] project = ua.get("/repos/JEG2/#{name}") project.on_complete do issues = project.body["open_issues"] puts "#{name}: #{issues}" if issues.nonzero? end end end
then fetch each repo in turn for an issue count # ... repos = ua.get("/users/JEG2/repos") repos.on_complete do repos.body.each do |repo| name = repo["name"] project = ua.get("/repos/JEG2/#{name}") project.on_complete do issues = project.body["open_issues"] puts "#{name}: #{issues}" if issues.nonzero? end end end
then fetch each repo in turn for an issue count # ... repos = ua.get("/users/JEG2/repos") repos.on_complete do repos.body.each do |repo| name = repo["name"] project = ua.get("/repos/JEG2/#{name}") project.on_complete do issues = project.body["open_issues"] puts "#{name}: #{issues}" if issues.nonzero? end end end
clients is trivial require "faraday_middleware" # load Faraday plus extra middleware ua = Faraday.new("https://api.github.com/") do |builder| builder.use Faraday::Response::ParseJson # parse JSON responses builder.use Faraday::Response::RaiseError # raise on 40x and 50x responses builder.adapter :typhoeus end # ...
clients is trivial require "faraday_middleware" # load Faraday plus extra middleware ua = Faraday.new("https://api.github.com/") do |builder| builder.use Faraday::Response::ParseJson # parse JSON responses builder.use Faraday::Response::RaiseError # raise on 40x and 50x responses builder.adapter :typhoeus end # ...
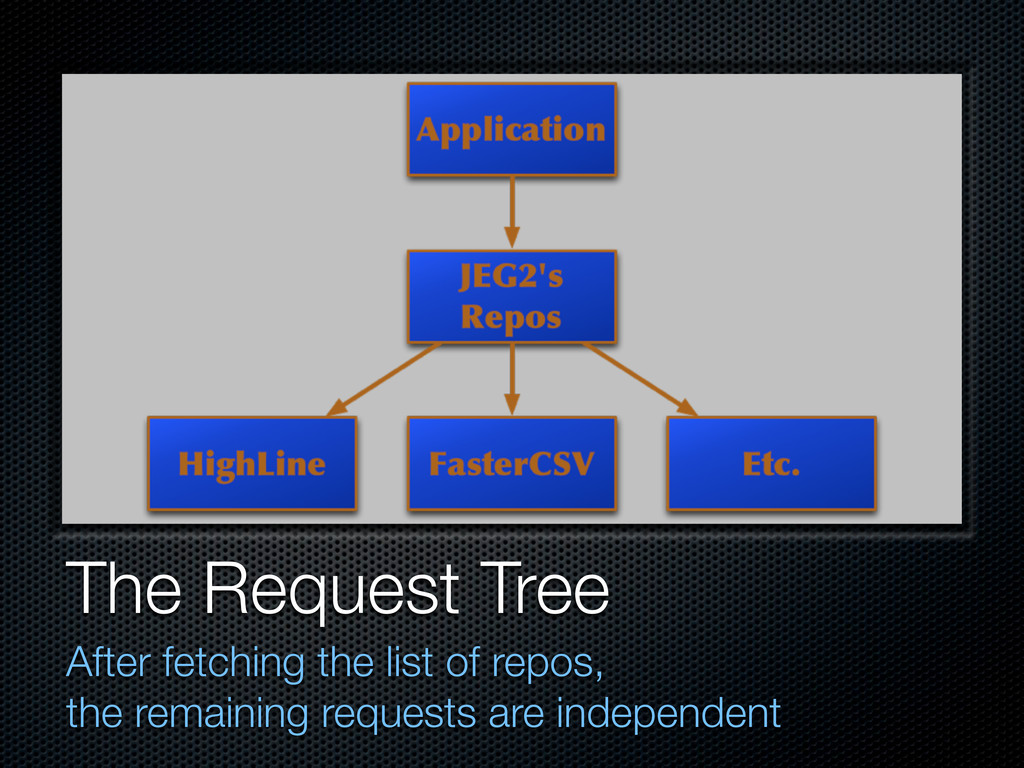
then handle the repo requests in parallel # ... ua.in_parallel(Typhoeus::Hydra.hydra) do repos = ua.get("/users/JEG2/repos") repos.on_complete do repos.body.each do |repo| name = repo["name"] project = ua.get("/repos/JEG2/#{name}") project.on_complete do issues = project.body["open_issues"] puts "#{name}: #{issues}" if issues.nonzero? end end end end
then handle the repo requests in parallel # ... ua.in_parallel(Typhoeus::Hydra.hydra) do repos = ua.get("/users/JEG2/repos") repos.on_complete do repos.body.each do |repo| name = repo["name"] project = ua.get("/repos/JEG2/#{name}") project.on_complete do issues = project.body["open_issues"] puts "#{name}: #{issues}" if issues.nonzero? end end end end
down by about 84% $ time ruby linear_requests.rb highline: 1 faster_csv: 1 real 0m11.087s user 0m0.466s sys 0m0.121s $ time ruby parallel_requests.rb highline: 1 faster_csv: 1 real 0m1.721s user 0m0.403s sys 0m0.104s
down by about 84% $ time ruby linear_requests.rb highline: 1 faster_csv: 1 real 0m11.087s user 0m0.466s sys 0m0.121s $ time ruby parallel_requests.rb highline: 1 faster_csv: 1 real 0m1.721s user 0m0.403s sys 0m0.104s
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}