1) Title Slide
2) Recently I have been spending a lot of time with my second hat on, talking to customers of Big Data technologies. This can be a rather confusing proposition. Actually, I think our whole Big Data community has been deeply confused; philosophically confused. But I think it's going to be just fine.
Let me ground this with a little context.
3) Data Archetypes
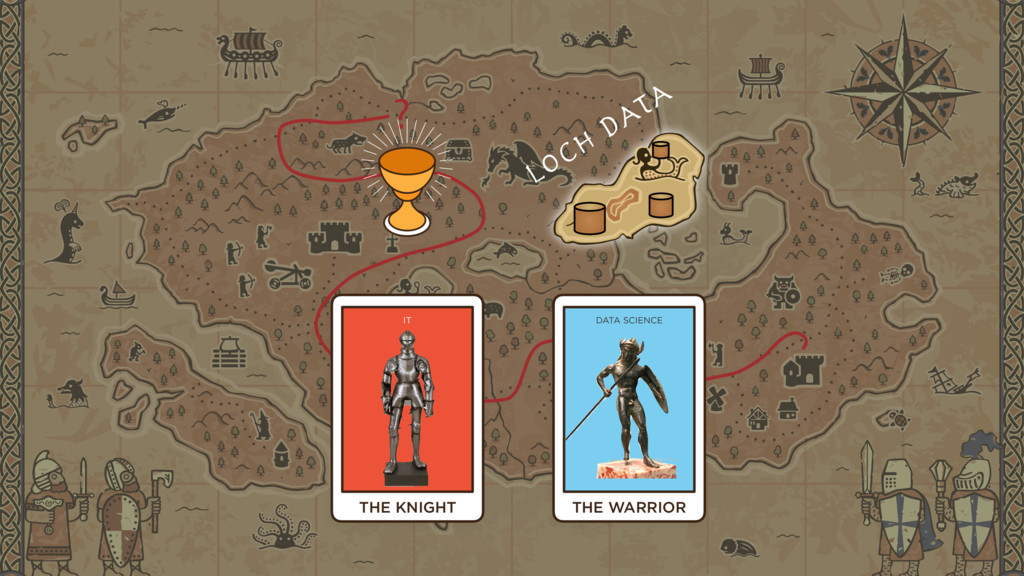
When I go out to talk with organizations excited about big data, I tend to meet three kinds of people. Think of them as Archetypes.
The first group represent the IT department. The faithful Stewards of data. The defenders of the realm. They keep the data safe and reliable.
The second are the Data Scientists. They are a relatively new force, tasked with achieving Victory: extracting Value from data, and using it to crush the competition—whether the competitors are business competitors, deadly viruses, or criminal syndicates.
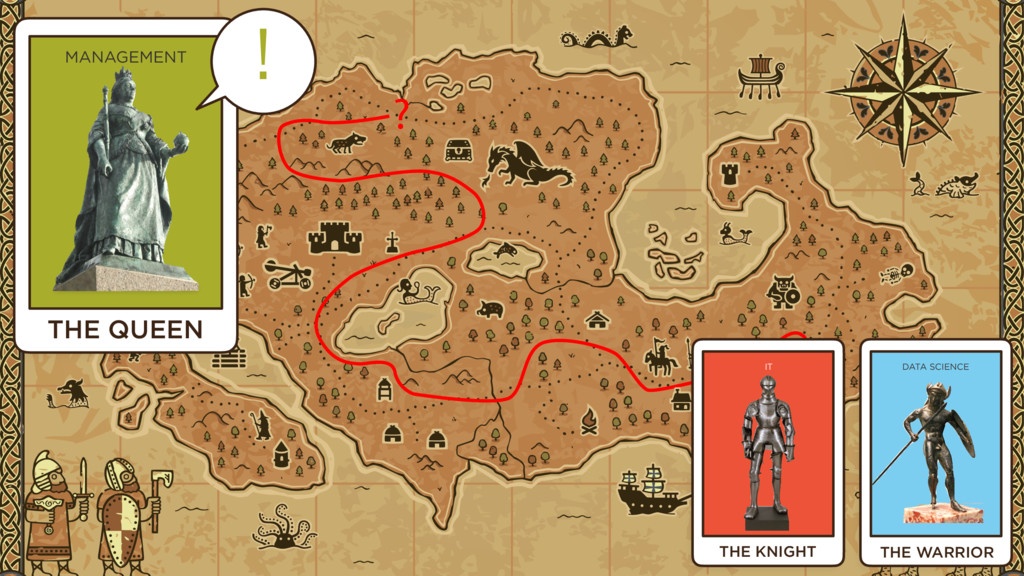
Overseeing both of these is Management (which, despite sometimes changing its goals on a whim) has generally has been excited for some years now about our Big Data initiatives. Our potential to use massive compute and data resources to predict the future. Our inexorable march toward a new reality that they had better be part of. Management wants Big Data and wants it to win.
4) The Quest
As a result, many of these organizations have sent their IT and Data Science folk to start a Big Data journey. A quest. Data scientists are empowered to go seek advantage and pursue victory. IT is given an exciting promotion, stewarding more data affecting more vibrant and strategic parts of the organizations.
5) These two start on the Big Data journey. And many things happen. Too many things. Sometimes confusing things. Incomplete and even contradictory things. And the road is not straight. And the end is not in sight.
And the Quest leads Questions.
Typically the IT folks are the first to get worried. They begin to ask questions. Basic questions. The kinds of questions they've always asked. Simple questions.
"What is True?"
"Once we have truth, what do we Know?"
And the professor in me quietly gets a big grin on his face and says "YES! Yes, these are the questions we should be asking!" Philosophical questions! Ontological and epistemological questions! Plato! Aristotle! Vico! (More on all this shortly.)
But I keep my businessman hat on and I ask them: "What do you mean?"
And they say:
6) Dialog: On Truth
”For example. What is Truth? We have a customer named Bob Smith, at 101 Berkeley Place. And we have a customer named Robert Smythe at 101 Barkeley Close. Are they the same?
Or riddle me this. We brought in such-and-such an amount of revenue last year. How much of it is taxable? Within which country? I know the truth exists; I just need to carefully compile it and protect it.” IT is persistently in search of the The Master Data ... the Single Source of Truth. IT is persistently in search of the The Master Data ... the Single Source of Truth.
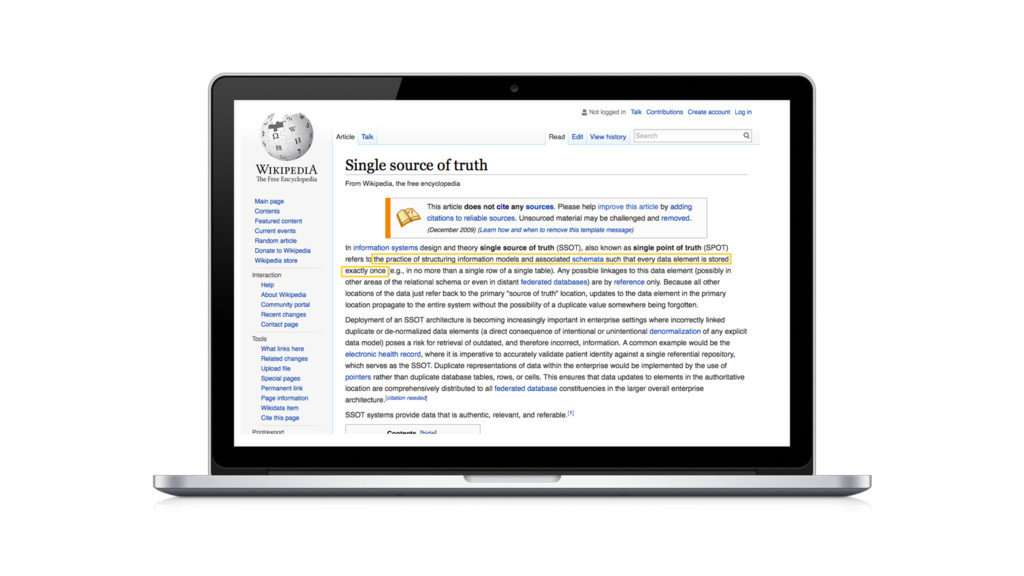
7) By the way ... I googled the single source of truth. No, it is not Google.
This is a description of the Single Source of Truth. You will notice that this is not in the Philosophy section of Wikipedia.
8)Here's the key aspect of the definition: "every data element is stored exactly once". Well that's a very practical notion of Truth you might say. But of course it's not so simple. In fact, the SSOT is a very EXPENSIVE source of truth, as you know. It costs years and millions to compile.
9) But it is THE HOLY GRAIL of data integration.
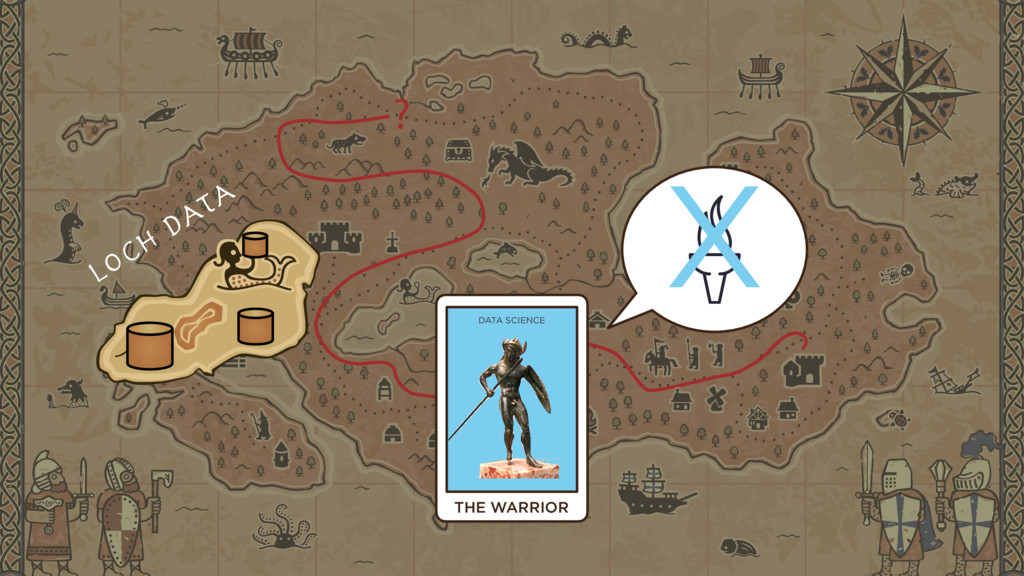
10) Meanwhile the Data Science Warrior says: “This Truth you speak of does not interest me. But there is a Lakeful of Data! And with enough data, I am sure I can deliver Victory.”
The Warrior is in search of opportunity ... of Value — by conquering large new sources of raw data.
11) These two parties are philosophically disconnected. They do not agree on what the Truth is, or if Truth even exists. This makes the Big Data Journey very difficult.
12) Dialog: On Knowledge
Meanwhile, What can we Know?
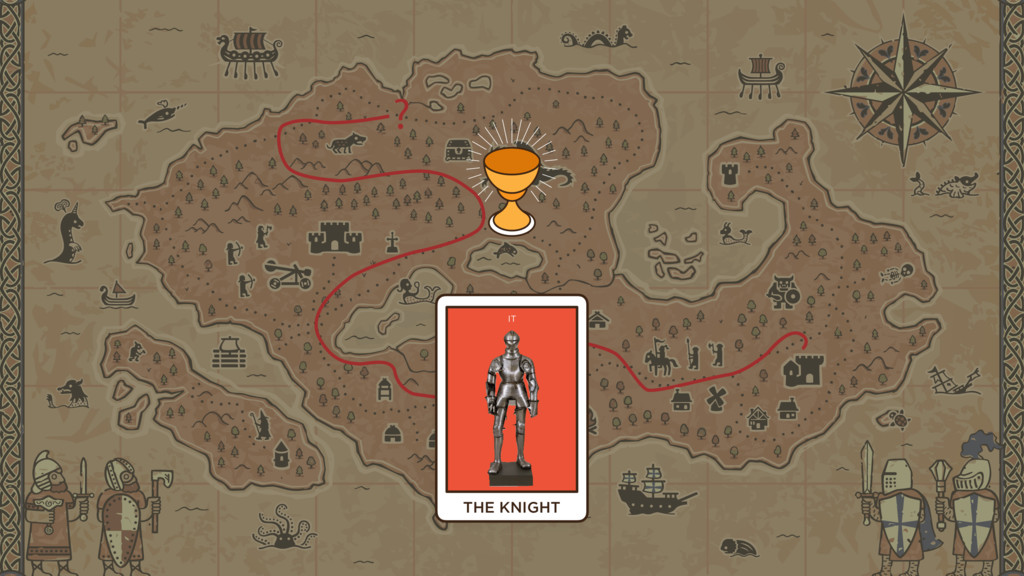
Our IT Knight says: “There are things we need to Know. And we do know. We have a Data Warehouse. It refers to the Single Source of Truth. From it we are able to SHOW THE NUMBERS. We roll them up, counting and summing and producing charts and reports. It is Business INTELLIGENCE. Things the business knows. Things the boss uses to make DECISIONS. Without this, we would be a morass of bad billing and lawsuits over accounting, taxes, privacy, you name it.”
Our Data Science Warrior says: Don't ask what we Know. Ask instead what's Likely, and then we can predict it and measure the result. It's our job to extract signal from the noise. We use PROBABILISTIC models to do PREDICTIVE analytics. We test out models empirically to see if they work to predict future behavior. We know they work if they're better than random. We know they're improving if they're getting even better over time.”
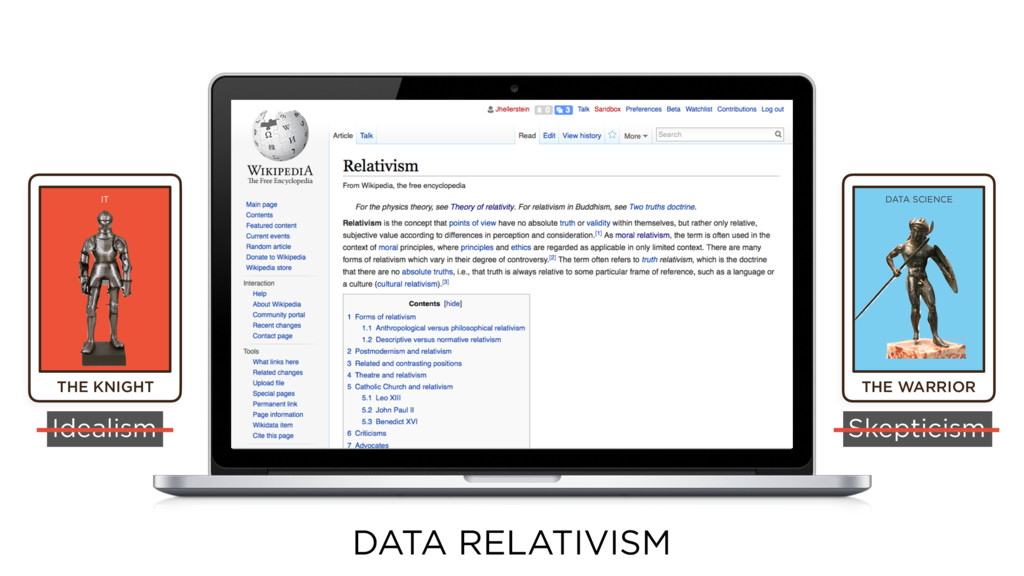
FTW. It's not just a pessimist versus an optimist. It's an Idealist--someone who believes in a unified truth and attempts to know things--versus a Skeptic--someone who doubts our ability to *know* things at all.
13) A Microcosm. Political data. This dataset includes a record of donations to American presidential political campaigns. Facts. Truth. (Though surprisingly dirty data!) It also includes a log of tweets mentioning the leading presidential candidates. You can think of these as facts (about what people posted on Twitter) or opinions. Or simply bags of empty words. It also includes a set of results from various political polls. These are statistical samples, which may be some representation of the truth, depending on methodology.
14) IT Knight comes to this data lake: The truth here: Donor data. Should be cleaned up. Still: A small cup of Truth from a vast Data Lake. The twitter data, which is not the "truth", is where you can identify the candidates stances on issues, after all.
Data Scientists come to the lake: Individual battles ... sometimes bloody skirmishes ... to try and eke out tactical wins.
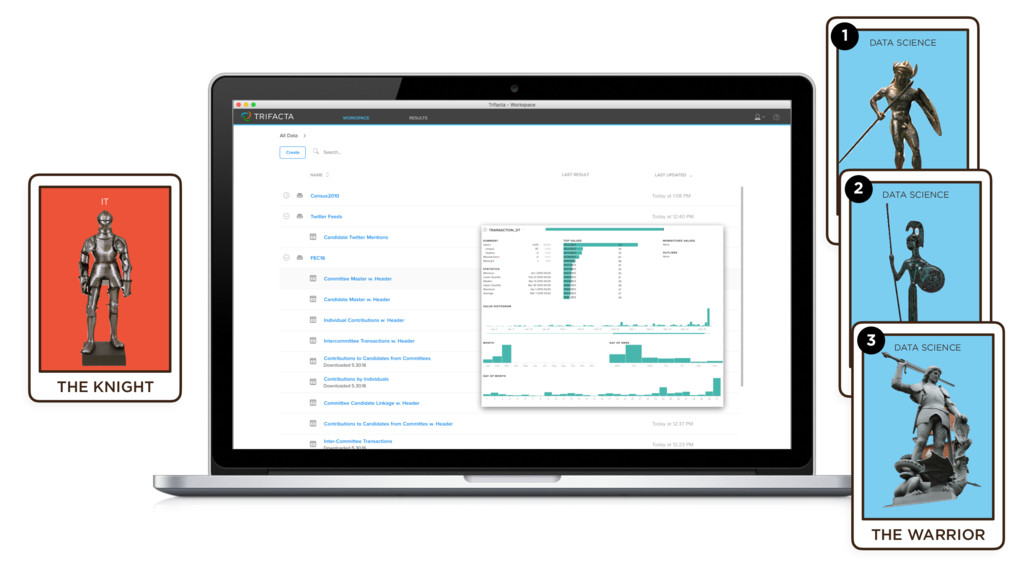
- From this data set, ANALYST 1 (in a non-profit) could predict the opinions of different candidates on their issues of interest.
- From this data set, ANALYST 2 (in the security organization) could predict the names of rabble-rousers and eject them from political rallies. [Photo of a Secret Service dude]
- From this data set, ANALYST 3 (a pollster) might simply want to predict the outcome of the election. [photos of Trump/Clinton/Sanders with check mark for winner]
Each one of these tasks could be quite different -- Wrangling different features out of the data, running different statistical models, and establishing very different and apparently unrelated predictions. Each of these efforts is likely to be of interest, but unclear value -- both because of uncertainty in the accuracy of the prediction, and uncertainty in the implications of acting on the prediction
15) In the end, nobody's goals are wrong in this story. Here's where practice benefits from understanding philosophy. What these archetypal people have wrong is their underlying, competing philosophies.
The IT Knight's idealism is far too limited. A small cup of truth in a massive data lake.
The Data Science Warrior's skepticism is far too narrowminded and tactical . Bespoke work that is not reusable — or reused.
16) Because, as I like to tell my practical friends, we have entered into the world of Data Relativism.
17) This is the Wikipedia entry for relativism. You'll note that it *is* in the Philosophy section.
18) Much of the time, there is no absolute Truth, only noisy evidence. We know this. The IT department knows this too, really ... it's the reason the SSOT is so expensive to approximate.
Yet we still establish what we Know. Most of the time, what we Know is based on models and code that we construct, and training data that we select .. it is, in a computational sense, a function of what we choose to believe.
19) Or as Giambattista Vico famously wrote in his 18th century opus "The New Science":
20) "Verum esse ipsum factum: Truth is what is Made”. Truth is verified through creation or invention.
So what is a data-driven organization to do?
21) Embrace Data Relativism.
There may be no single Truth. But there are many contextual truths.
If you can capture context over time, context + data + computation = knowledge.
Everyone in the organization needs to respect and work with this contextual model of truth and knowledge.
And to support this, we need new software: Context Services—software to manage context.
22) To recall what we did previously:
Analyst 1 models candidate stances on the issues.
Analyst 2 figures out who to evict from rallies.
Analyst 3 predicts election outcome.
Now the Queen sends in Analyst 4 to "Figure out what stocks to short." Analyst 4 is new to the territory. He would like to know
- What data do we have?
- Who knows this data? What have they done with it before?
- How can I wrangle out features of companies? All the data sets have company data actually.
- What other data should I get? Surely financial data.
- Are there predictive correlations between the previous data and my data? Surely knowing who's likely to win and their position on issues should help.
etc.
23) And eventually, this might lead to another notion of truth.
Meanwhile, the Queen asks the Knight to link customer data (Truth!) to twitter handles (also Truth!). That linkage will require ... Data Science! Aha! Here's where Data Science can transition to inform Truth.
So enough with parables. What’s a data driven organization to do?
24) What’s needed is a new class of software service. A Data Context Service. I'm leading one such service, called Ground.
A service to store contextual information over time. Metadata about datasets. About people. About code and models. Usage information. Data lineage. Statistical models and parameter settings. A/B testing framework data and other experimental controls and results. Workflows. Version histories ... the "data exhaust" of data science itself. And yes, reference data, perhaps with Wiki style curation. Governance and security metadata too.
This myriad of context .. this is the Common Ground for relativistic data, for many truths.
25) The Ground project is an Open Source Data Context system we’ve begun building at Berkeley. Initial APIs and metamodels are under active design, and we're beginning to build out both the reference services and initial applications. We're happy to be in ongoing conversation and collaboration with open-source-minded friends who bring real-world experience and challenges.
And our goal .. is to provide a platform where rich data context can thrive.
26) A platform where data scientists can work in an agile and aggressive fashion exploring new frontiers in extracting Value from Data. Where organizations can work collectively on data governance, developing and evolving shared notions of Truth.
An open platform for enabling both researchers and commercial products to improve our breadth of understanding of data context.
Be in touch if you’d like to know more.
Thank you.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}