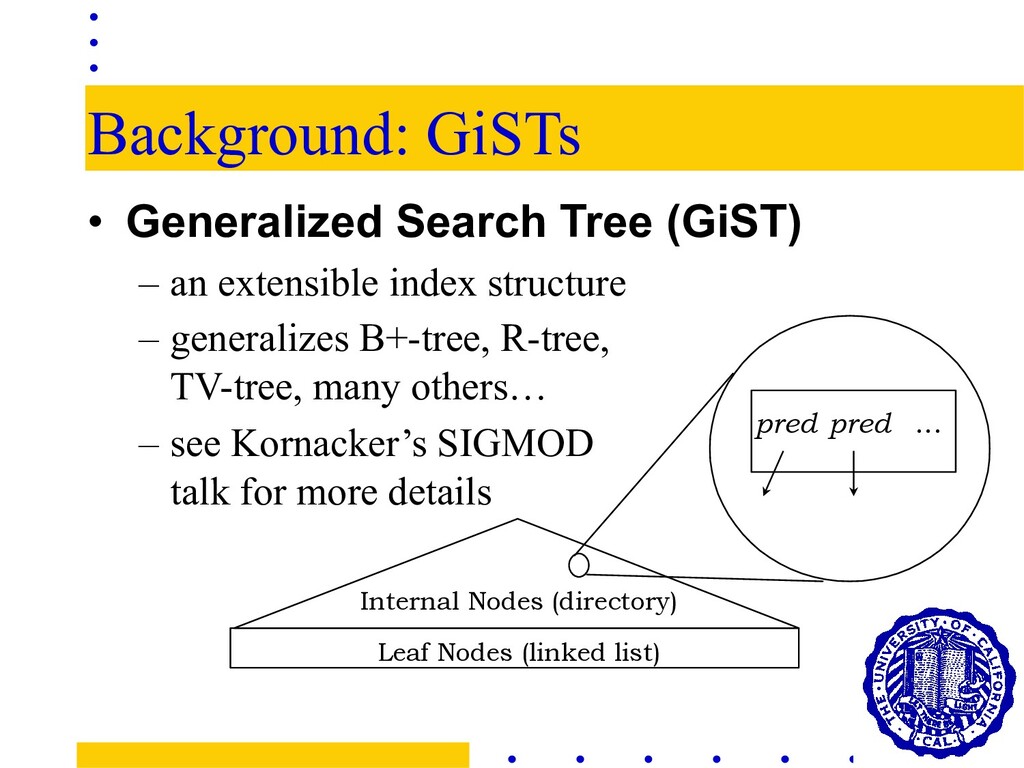
index structure Internal Nodes (directory) Leaf Nodes (linked list) pred pred ... – generalizes B+-tree, R-tree, TV-tree, many others… – see Kornacker’s SIGMOD talk for more details
can index any data type – can support any set of queries!! • So what is an index? – A clustering scheme for data... – ...with a “directory” • For 2-ary storage: – cluster size = disk block – directory: high-fanout, balanced tree
theory problem – some things are more “indexable” than others – how to characterize this? • Keep faithful to the systems problem – cost metric is #I/Os – block size is a fundamental parameter!
domain (e.g. Z, R2, P(Z)) – I Ì D: a (finite) instance – Q Ì P(I): a set of queries – workload:indexability » language:complexity • Indexing scheme – collection S = {S1 , …, Sn} of blocks – |Si | = B (200 or so), – scheme performance » algorithm perf. I S i i = !
cover Q) / (é|Q|/Bù) – Note: worst possible performance = B – access overhead of an indexing scheme is max access overhead over all queries Ideal performance Ideal performance Actual performance Actual performance
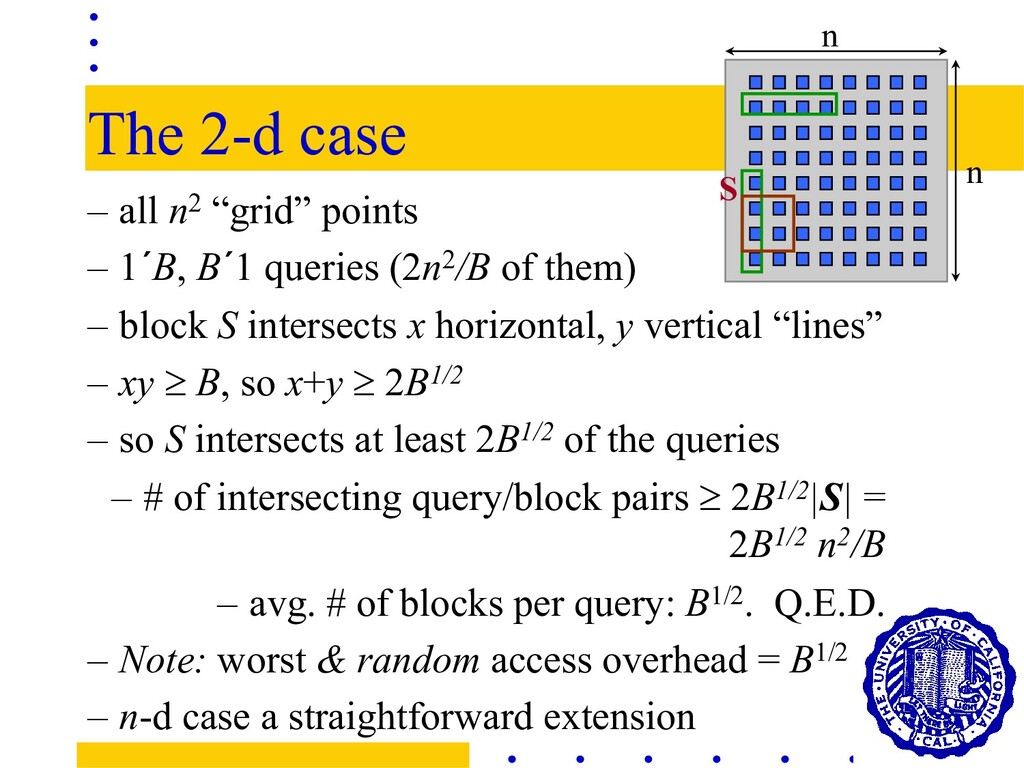
B´1 queries (2n2/B of them) – block S intersects x horizontal, y vertical “lines” – xy ³ B, so x+y ³ 2B1/2 – so S intersects at least 2B1/2 of the queries – # of intersecting query/block pairs ³ 2B1/2|S| = 2B1/2 n2/B – avg. # of blocks per query: B1/2. Q.E.D. – Note: worst & random access overhead = B1/2 – n-d case a straightforward extension n n S
a and redundancy r must satisfy r a2log(2a2) ³ (logB)/2. • Proof – uses result from extremal set theory • (a/k/a Johnson’s Lemma, coding theory) – assumes n = W(B2) • Conjecture – r ³ log B/log a ?
Query: find all sets contained in s – Theorem: For each redundancy r, there exists a set workload with access overhead B. – Proof: instance is singleton sets {1}, …, {n}, query is subset of B items from {1, …, n}. • Each element can be in same block with at most rB elements • So there are n/(rB) ³ B elements such that no 2 of them are in the same block. Query with B of these takes B blocks.
• upper bounds and structures for 2-d range queries [Kanellakis, Ramswamy, Subramanian, Vengroff, Vitter, et al.] • special case of Thm 1 by Kanellakis, et al. in a recent version of PODS ‘93 paper • “additive” lower bound redundancy result in SODA ‘95 paper (2-d range queries) – Empirical/statistical studies
to index – growing query set (learning theory?) • Complexity of indexing schemes – How hard is it to find a “good” indexing scheme for a workload? – How hard is it to find a covering set of blocks for a query?
natural workloads – R.E. queries over strings – spatial layout queries over images – near-neighbor queries in n-d – harmonic-progression queries over MIDI. – Etc. • Use performance measures in empirical analysis – spatial index benchmarking
amenable to interesting theory – framework exists for implementing/testing results/conjectures in commercial systems! • Opportunity for a nice theory/systems feedback loop • More info? – http://gist.cs.berkeley.edu
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}