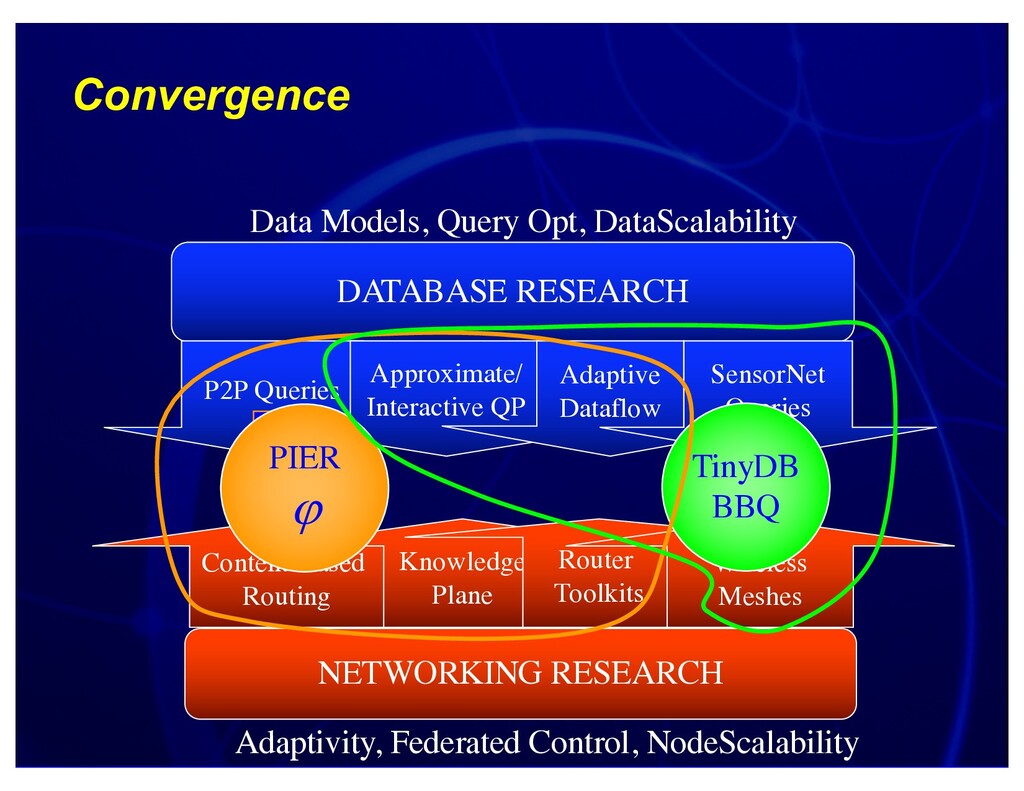
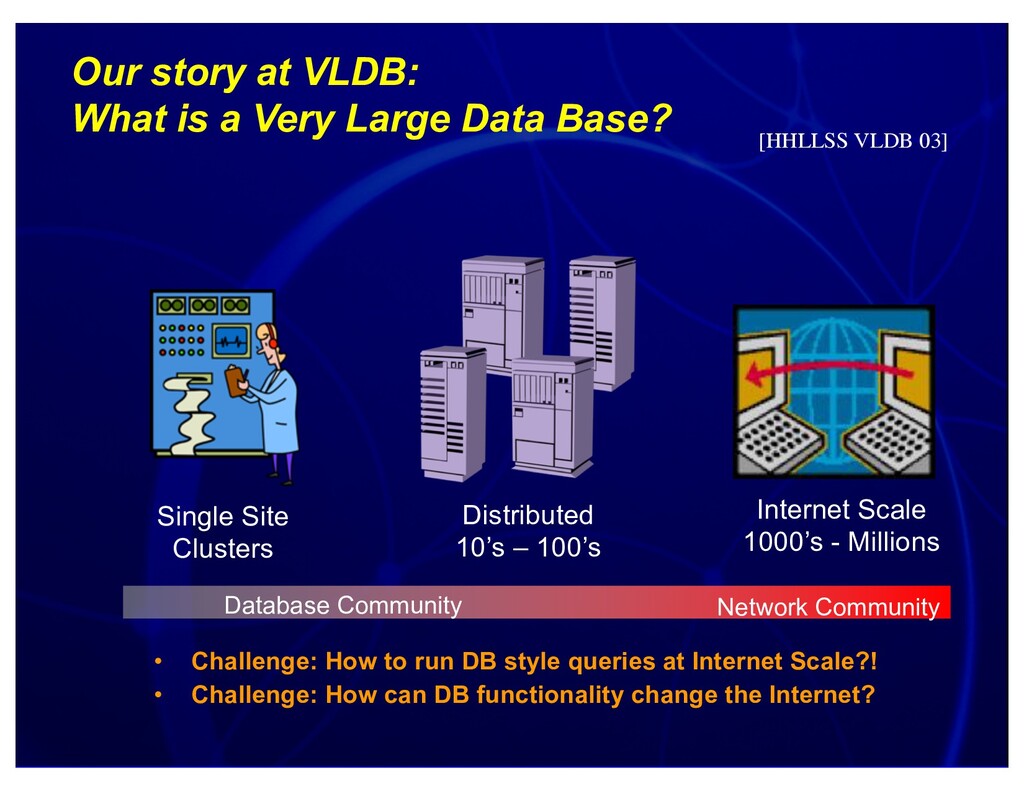
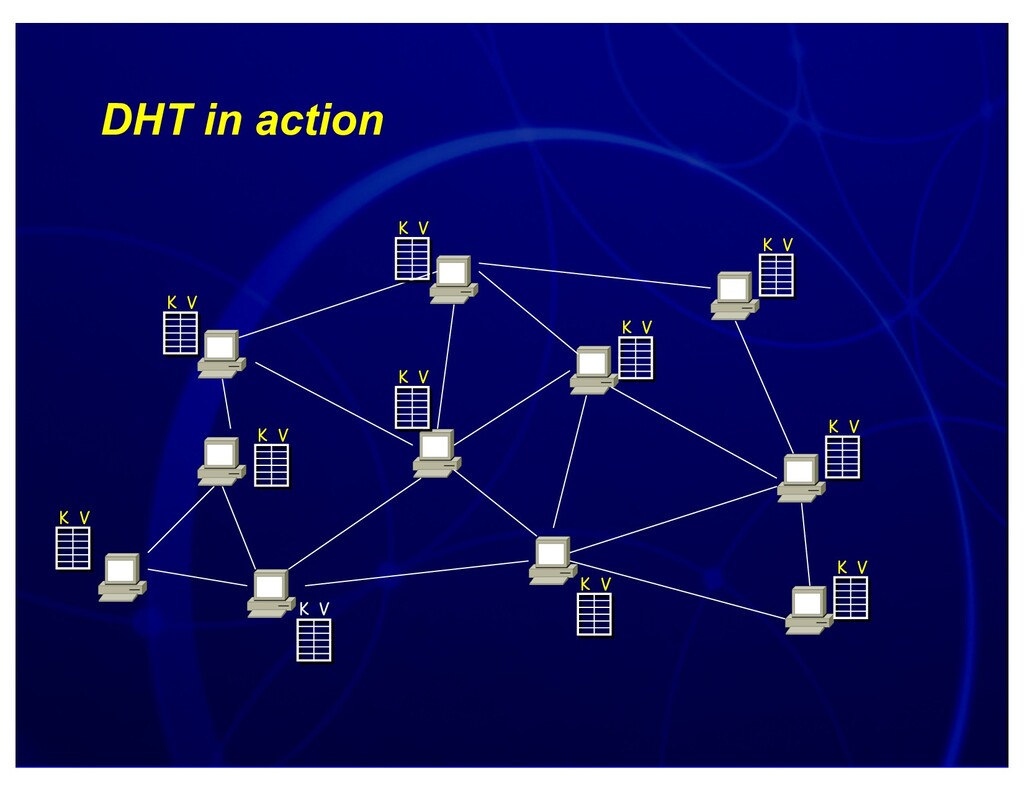
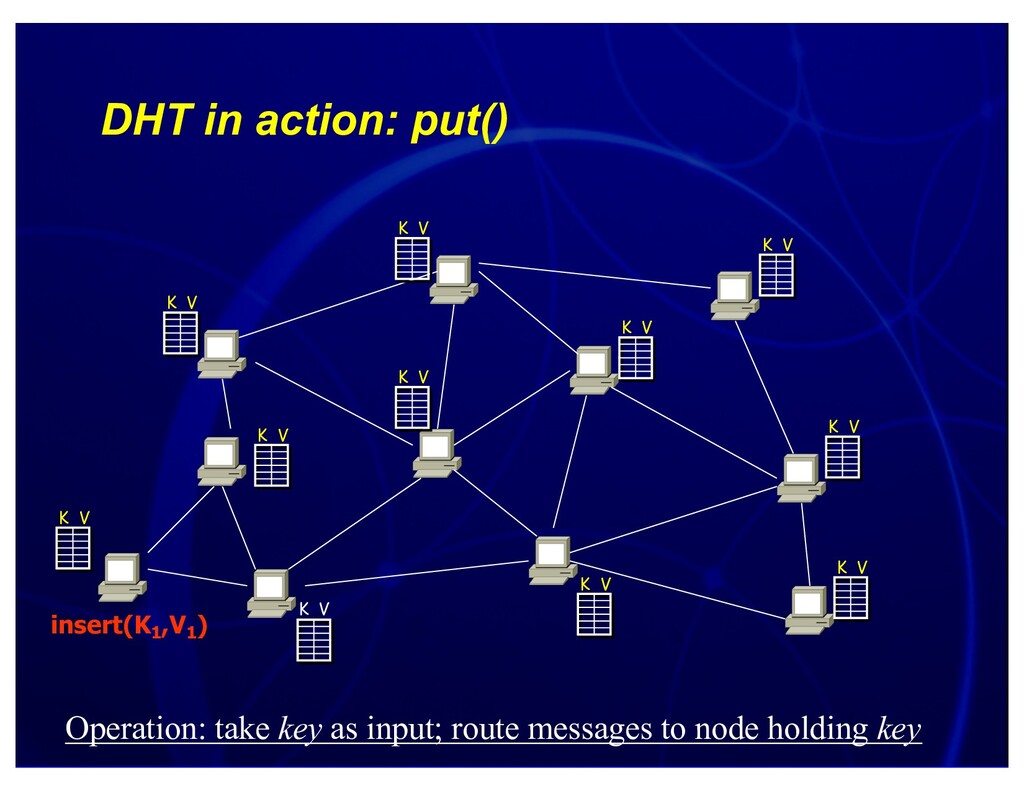
Distinguished Lecture, UMass and UBC, 2004. Discusses connections between networking and database research, and research we're exploring at the seams, including sensornet query processing (e.g. TinyDB and BBQ) and p2p query processing (e.g. PIER and PHI).
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
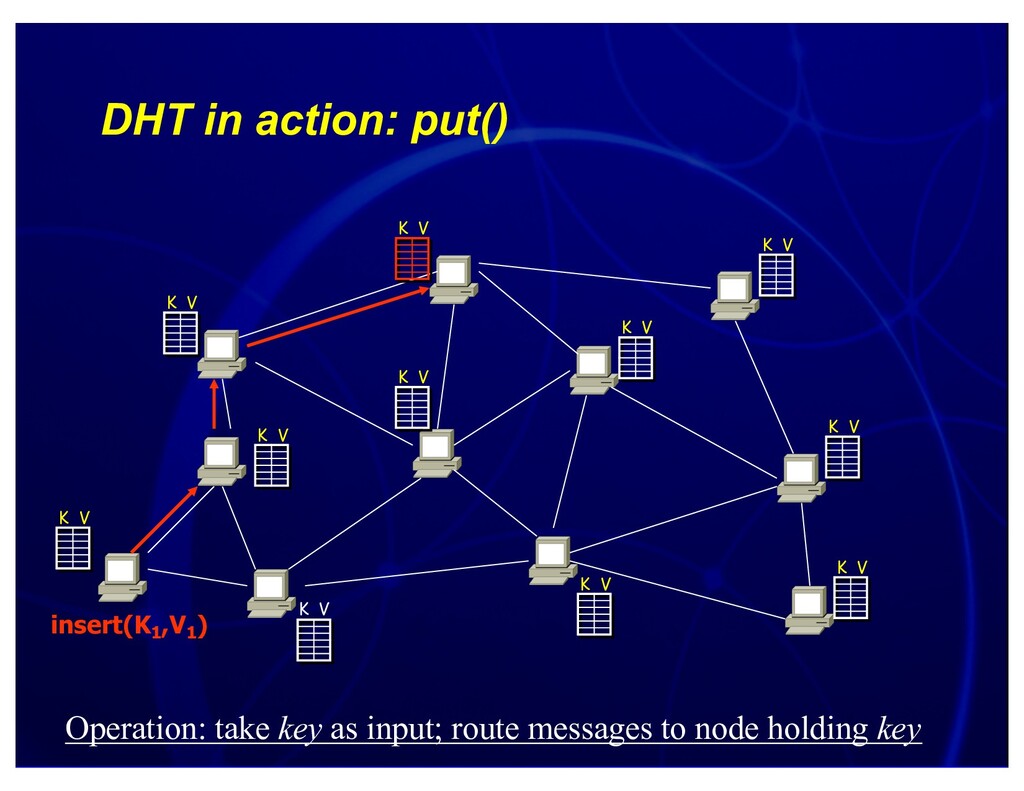{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
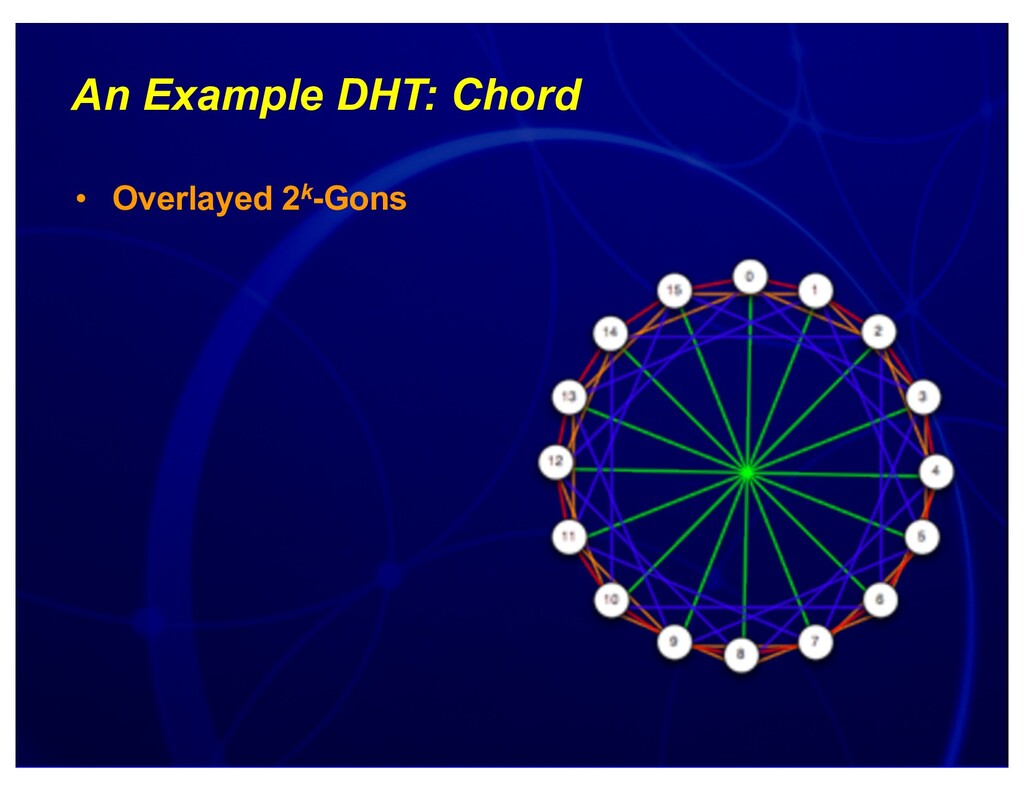{kind=link}
{kind=link}
{kind=link}
{kind=link}
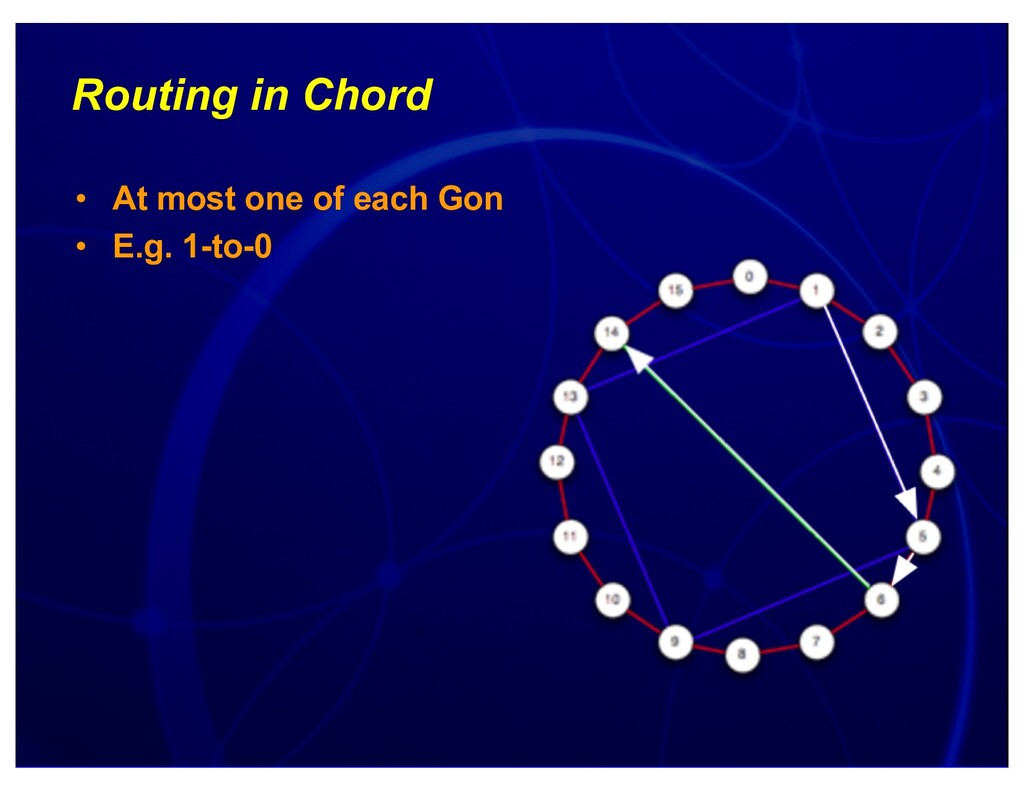{kind=link}
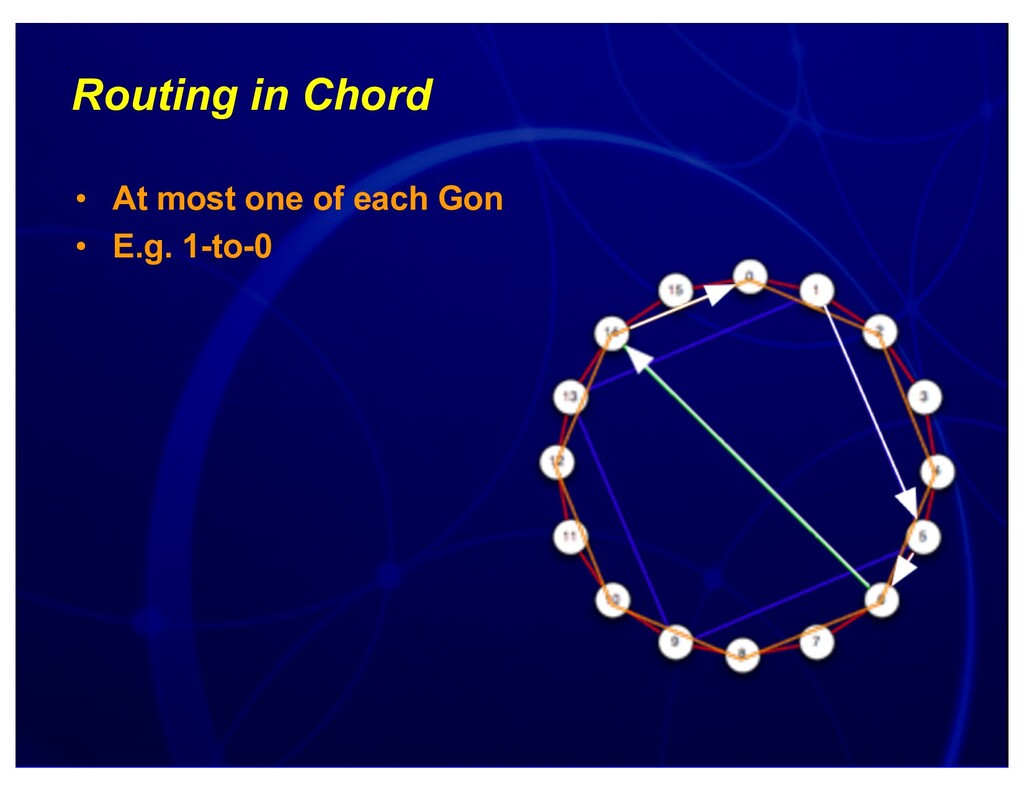{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
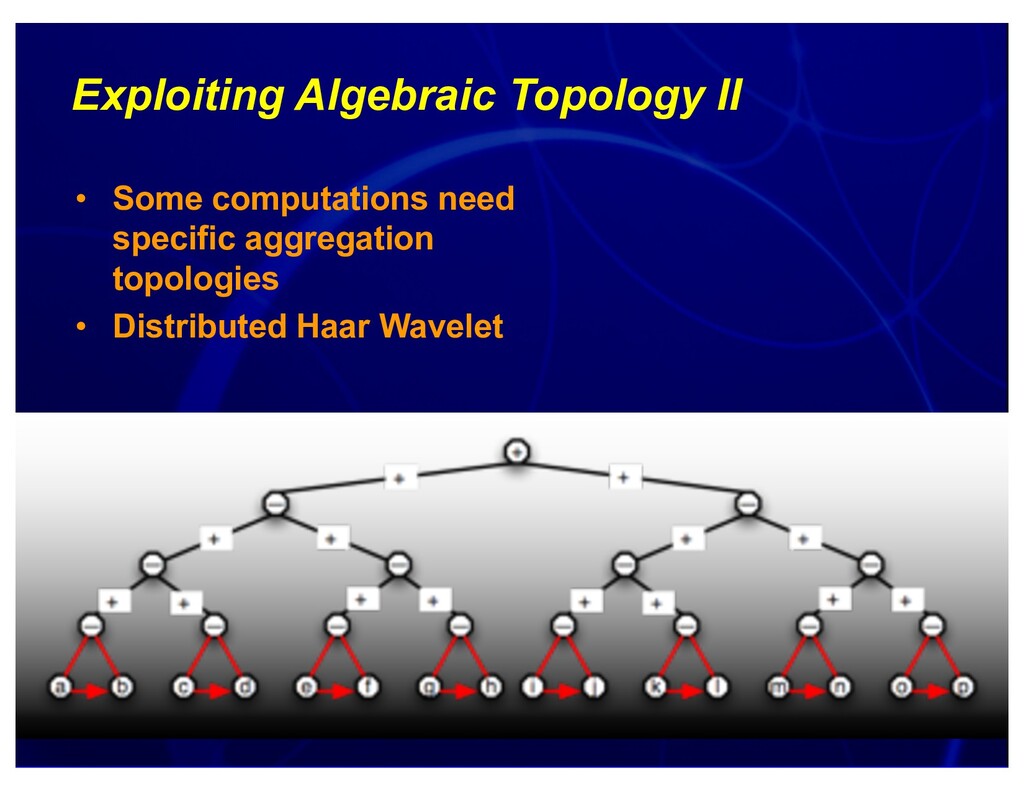{kind=link}
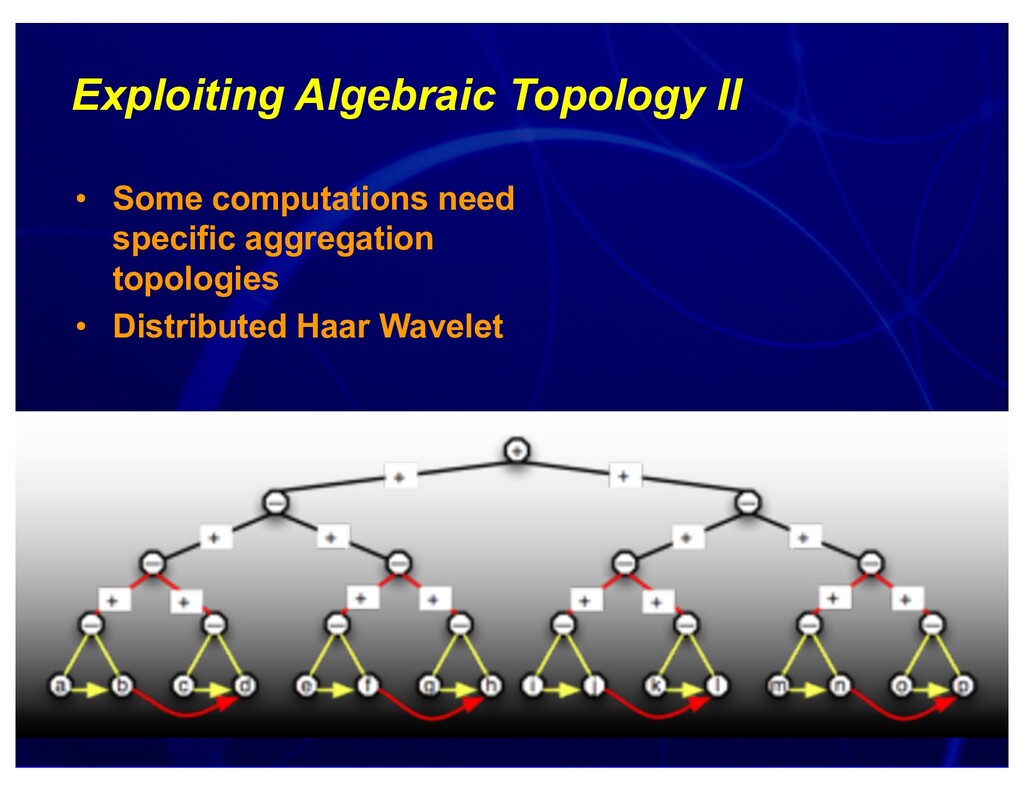{kind=link}
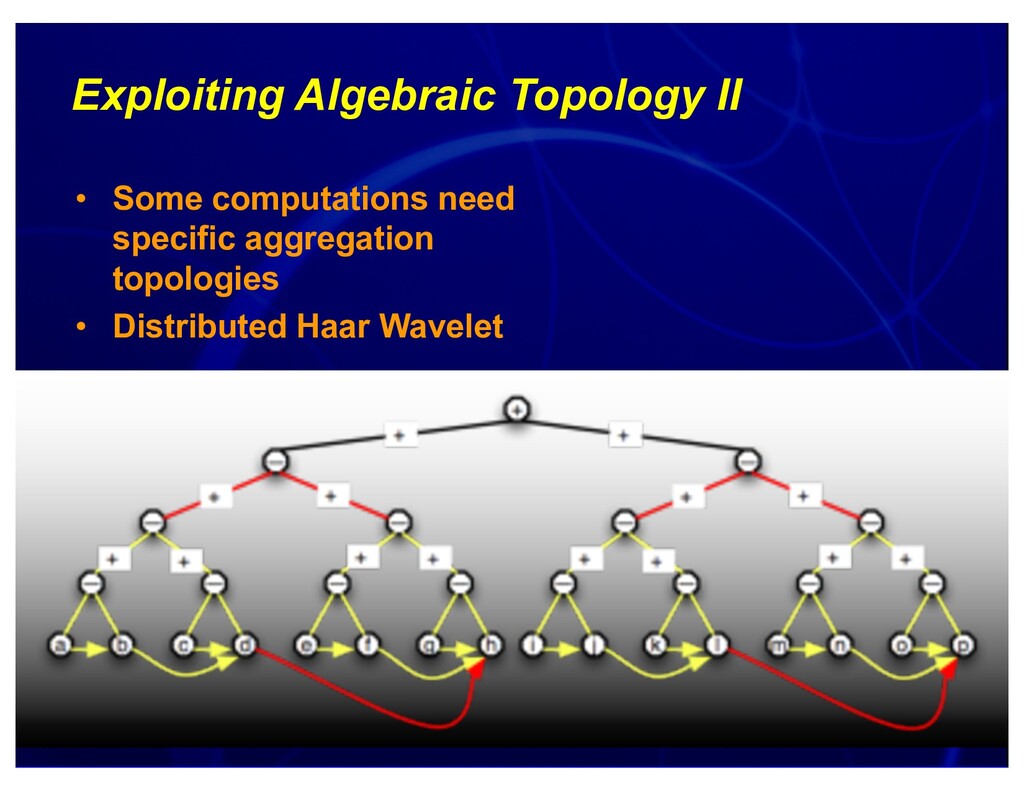{kind=link}
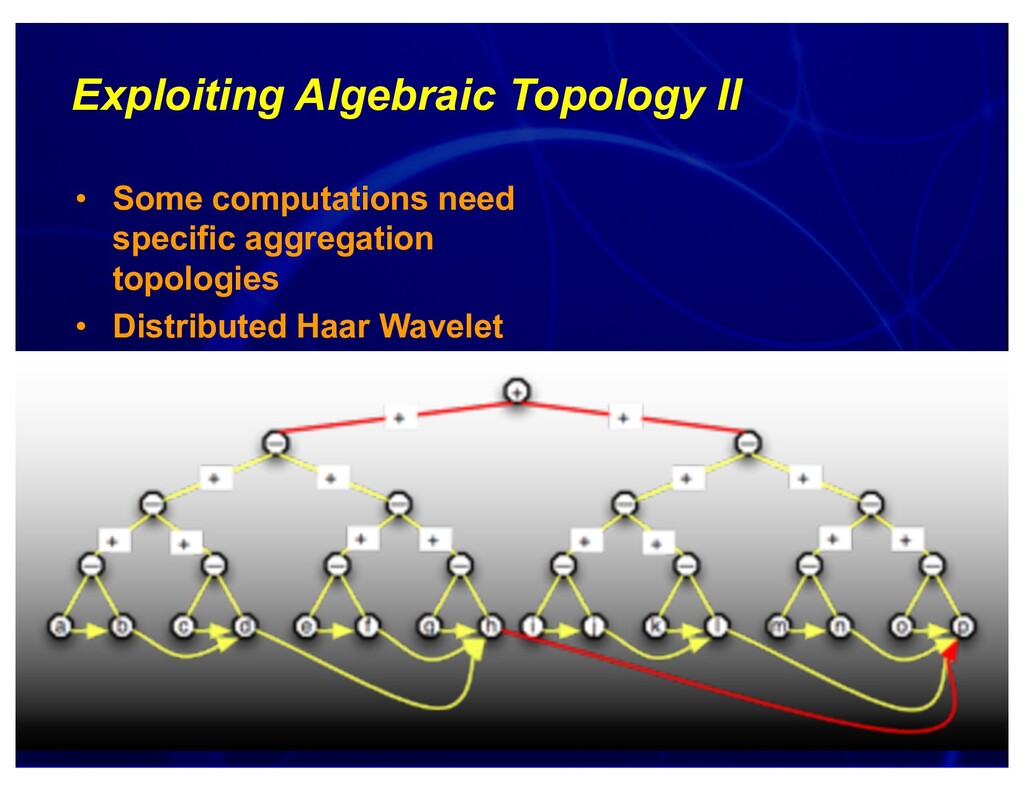{kind=link}
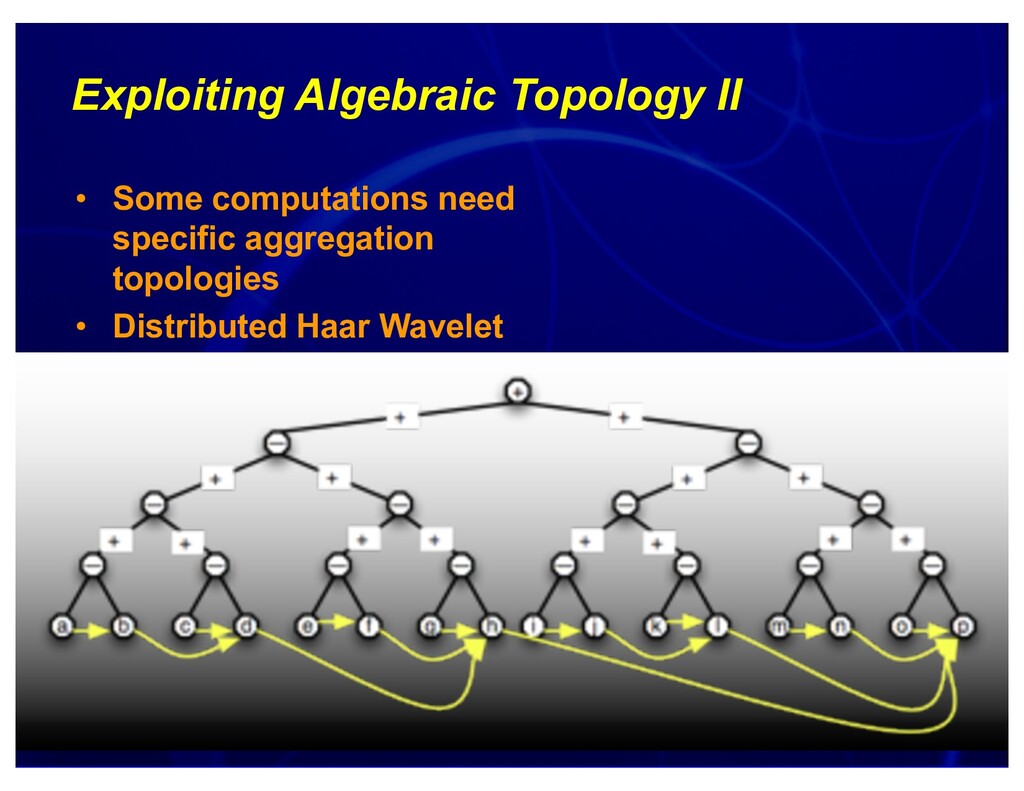{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
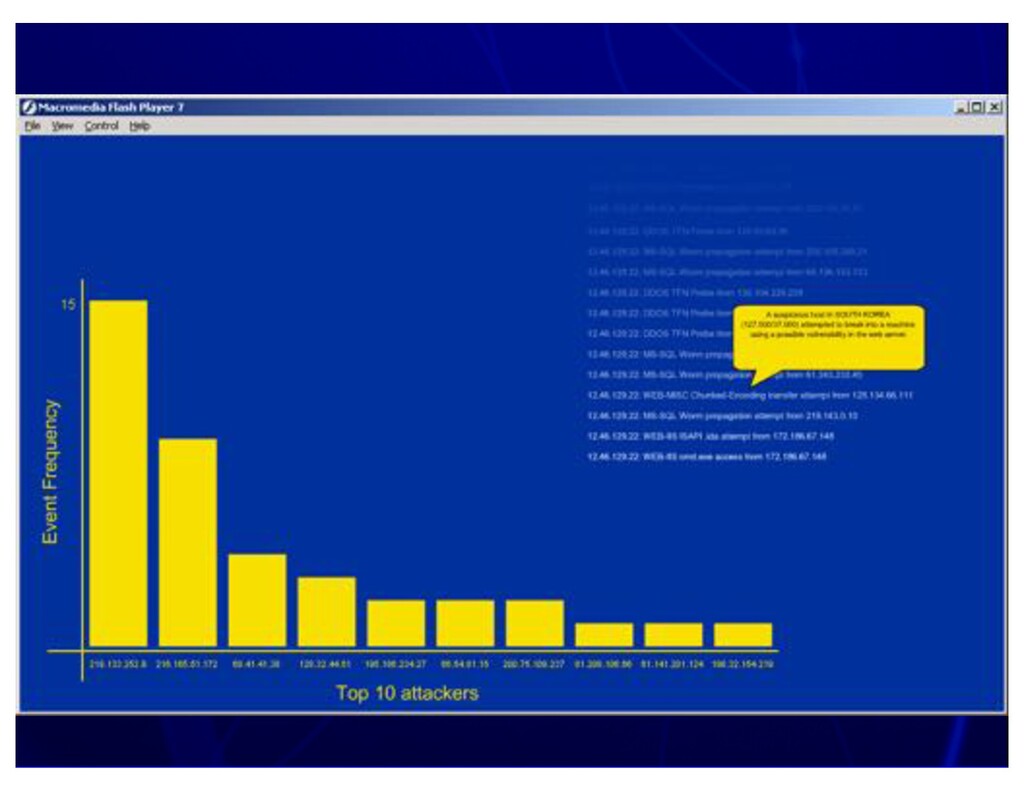{kind=link}
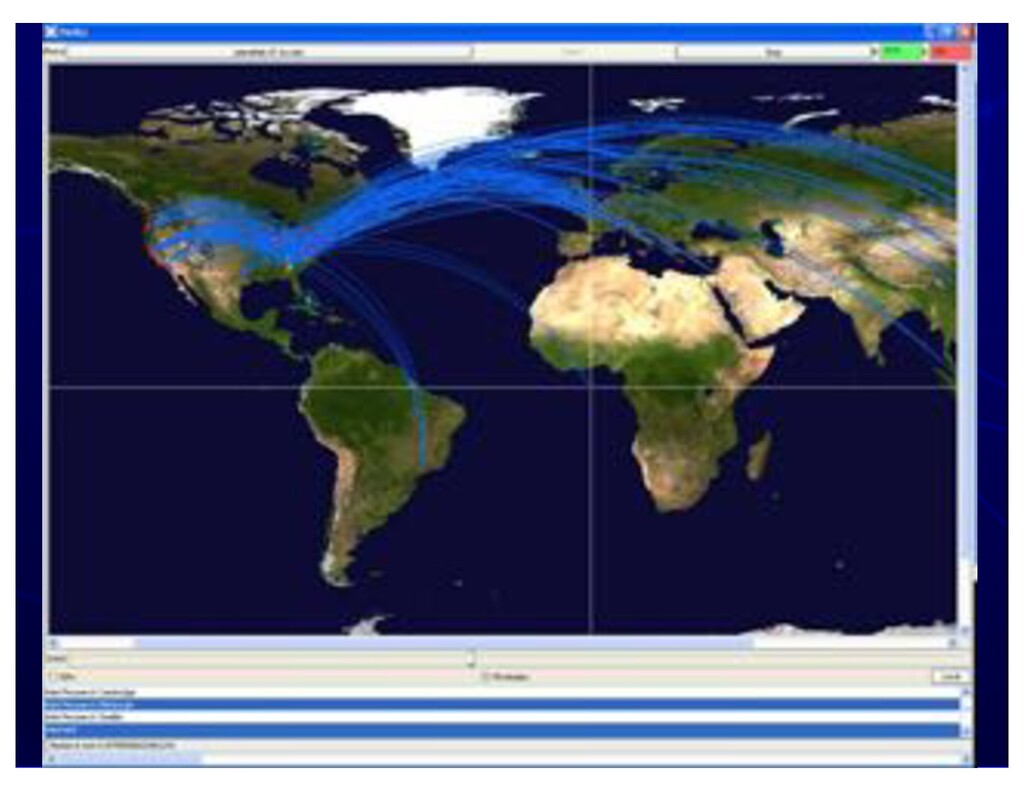{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
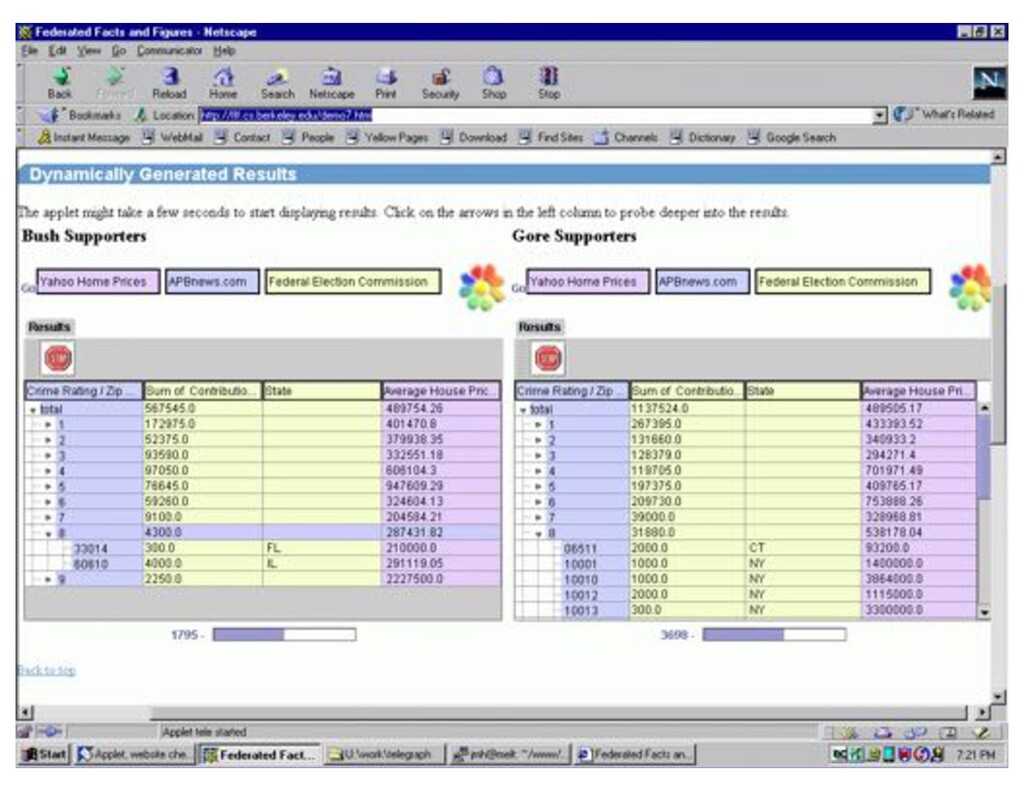{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
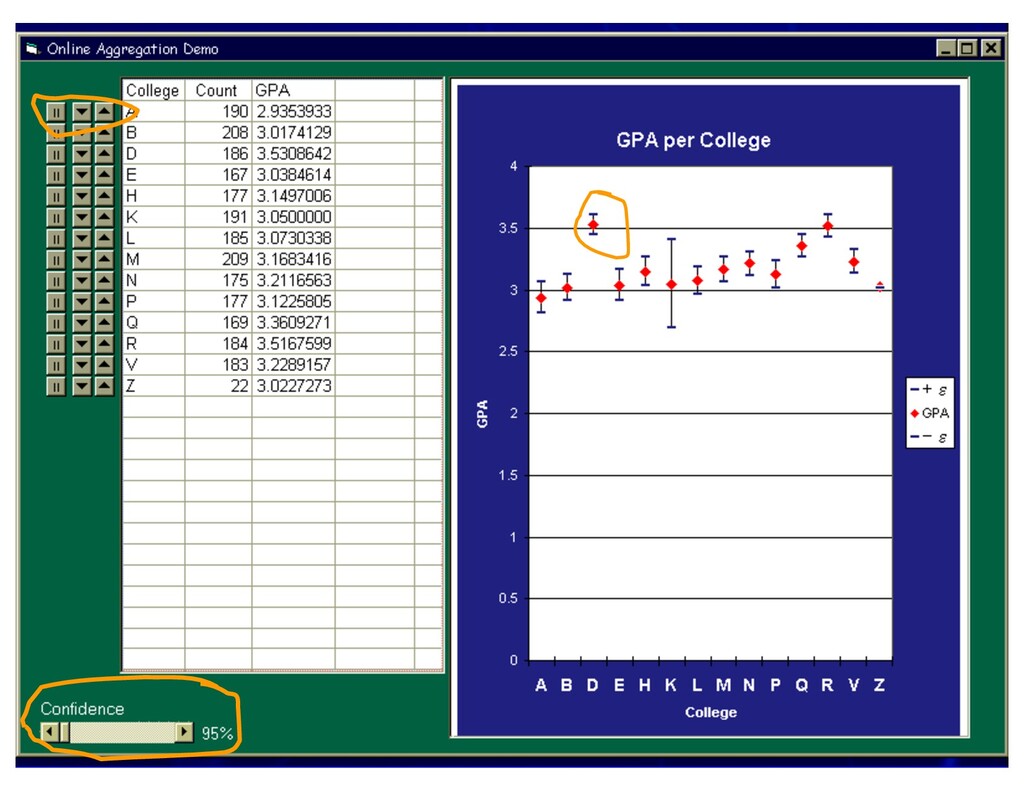
![Example: Online Aggregation [HHW SIGMOD 97, HH SIGMOD 99]](https://files.speakerdeck.com/presentations/2e62a21375184afcac396a654b371f04/slide_80.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
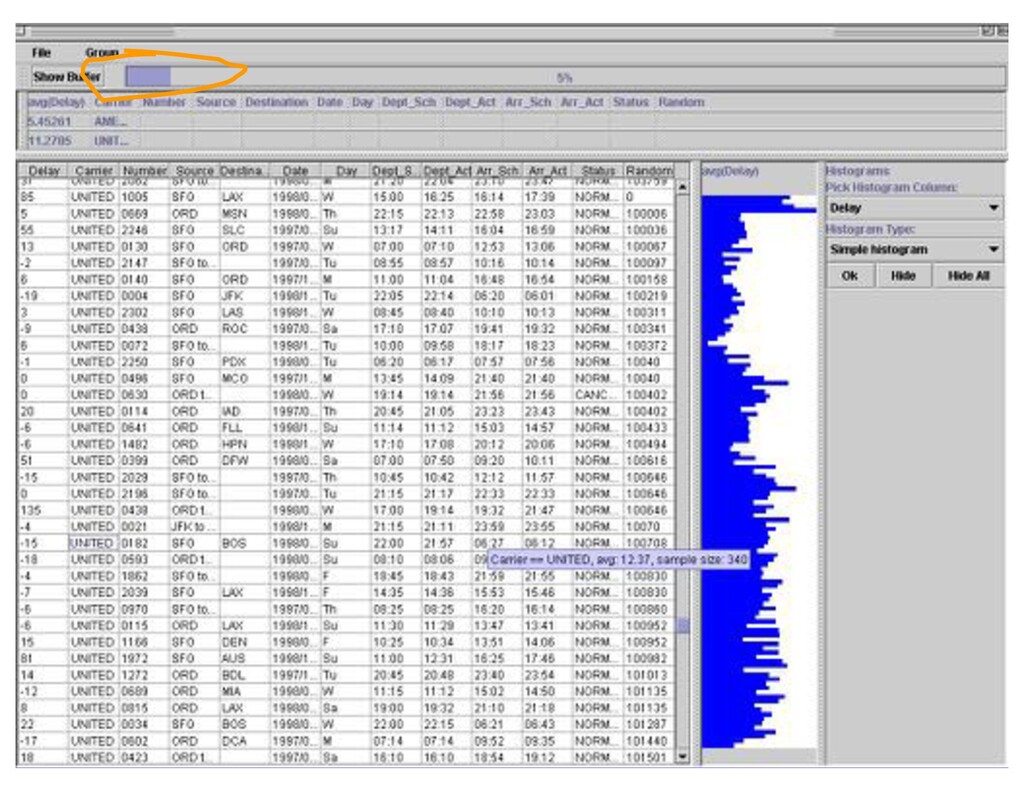
![Example: Scalable Spreadsheets [RCH DMKD 99]](https://files.speakerdeck.com/presentations/2e62a21375184afcac396a654b371f04/slide_85.jpg){kind=link}
{kind=link}
![Example: Potter’s Wheel [RH VLDB 01]](https://files.speakerdeck.com/presentations/2e62a21375184afcac396a654b371f04/slide_87.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
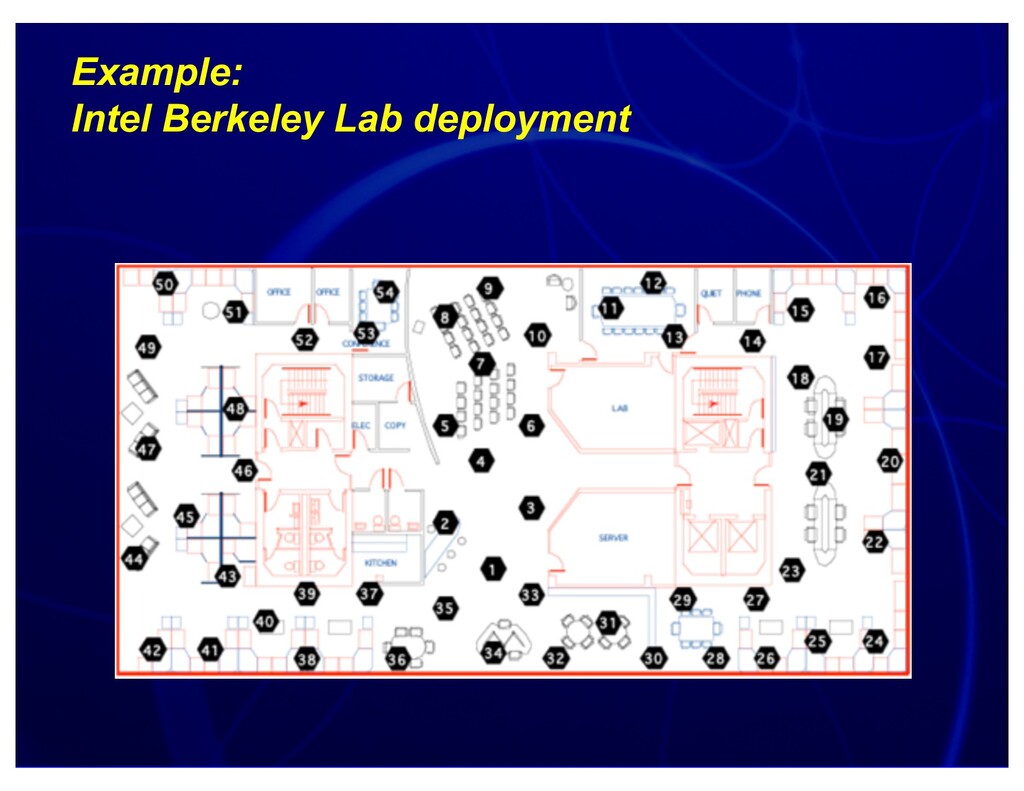{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
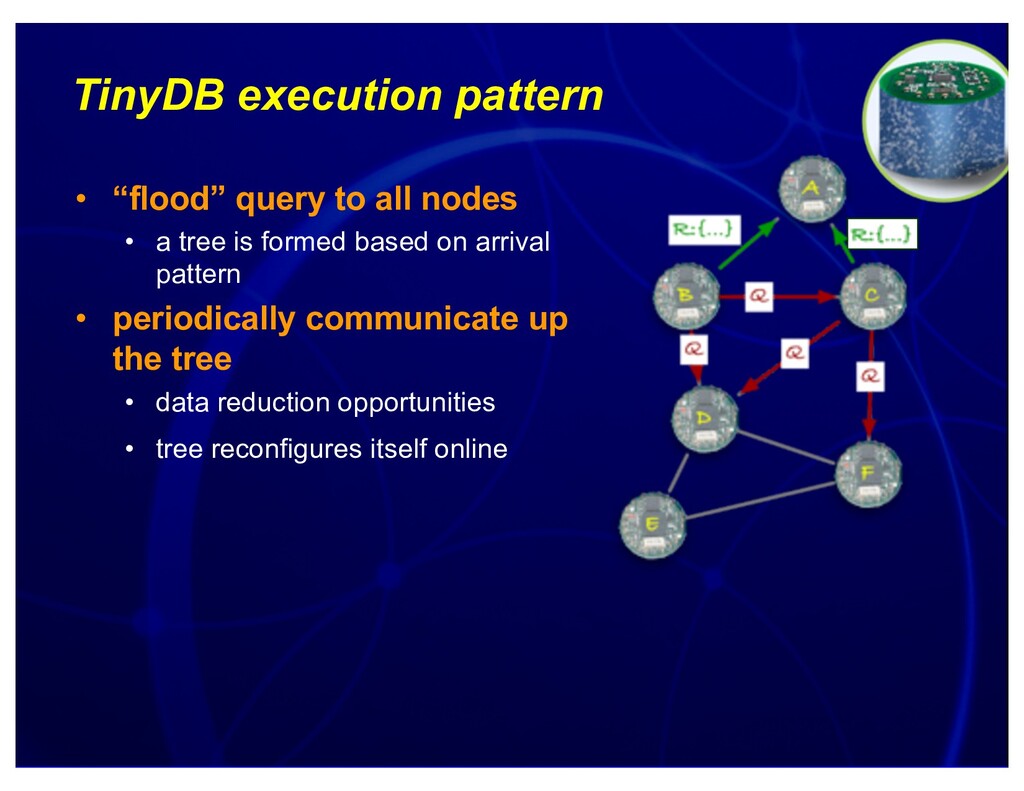{kind=link}
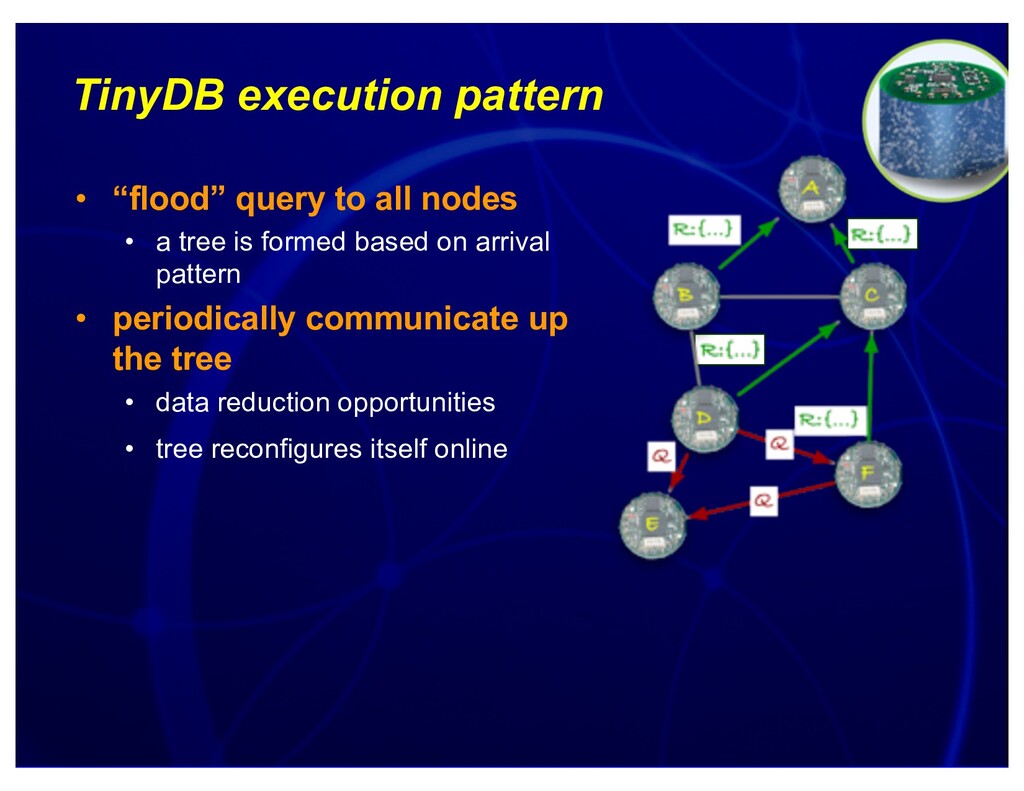{kind=link}
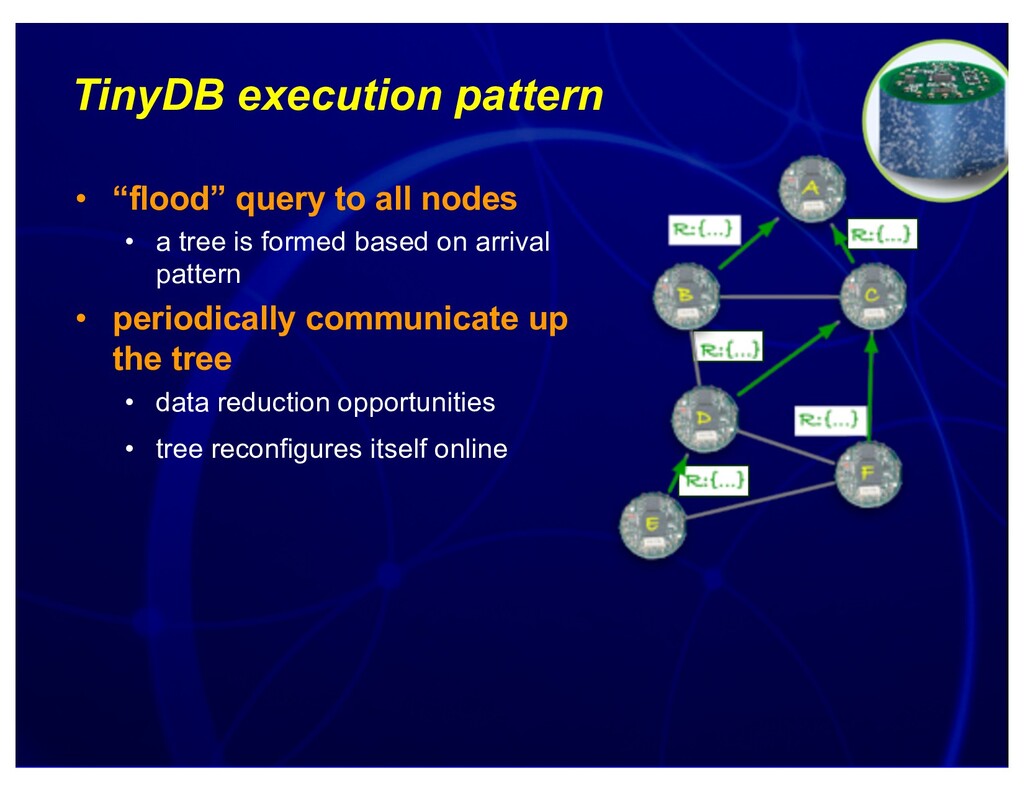{kind=link}
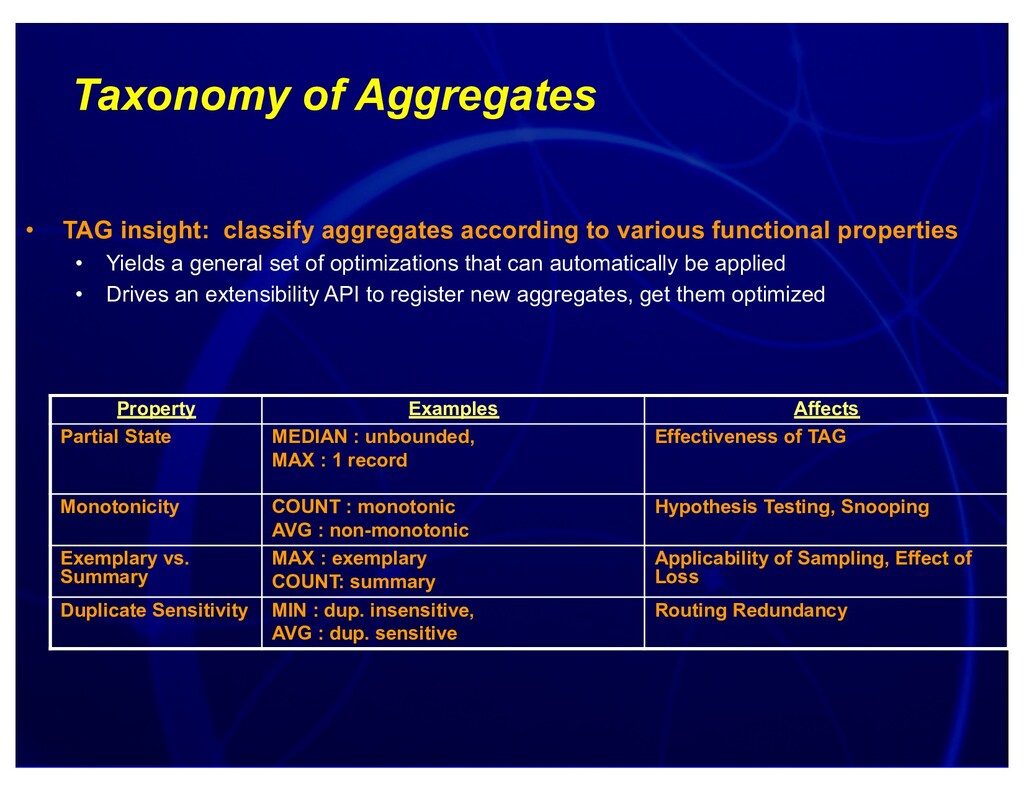{kind=link}
{kind=link}
{kind=link}
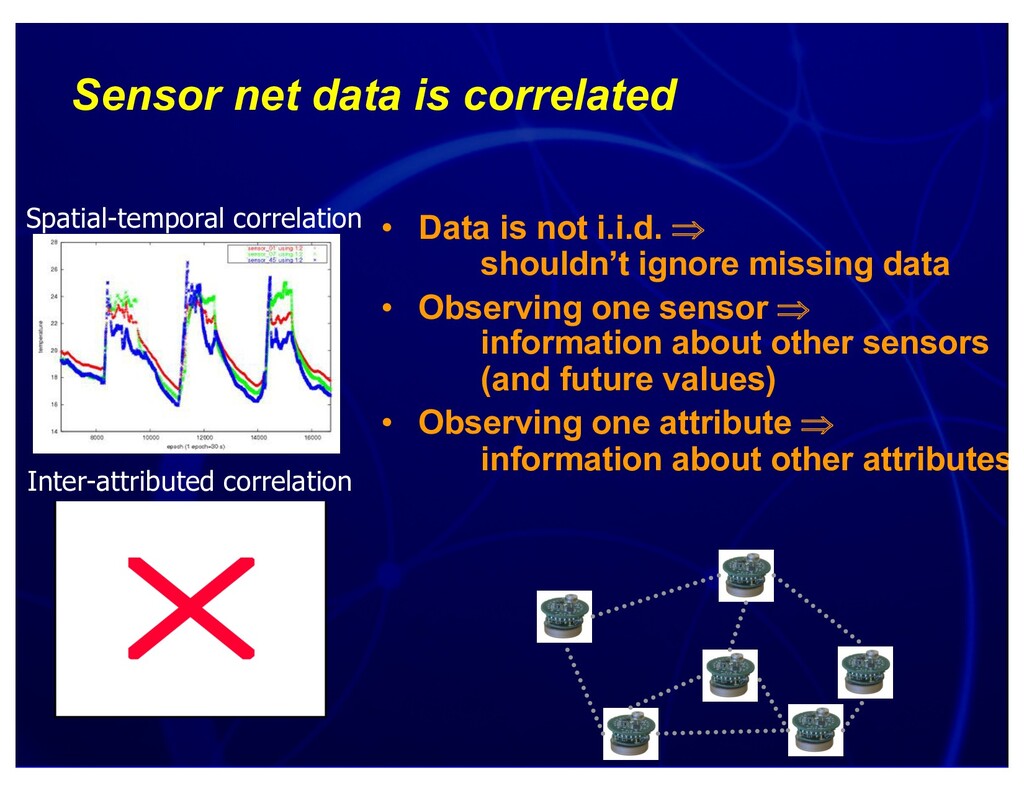{kind=link}
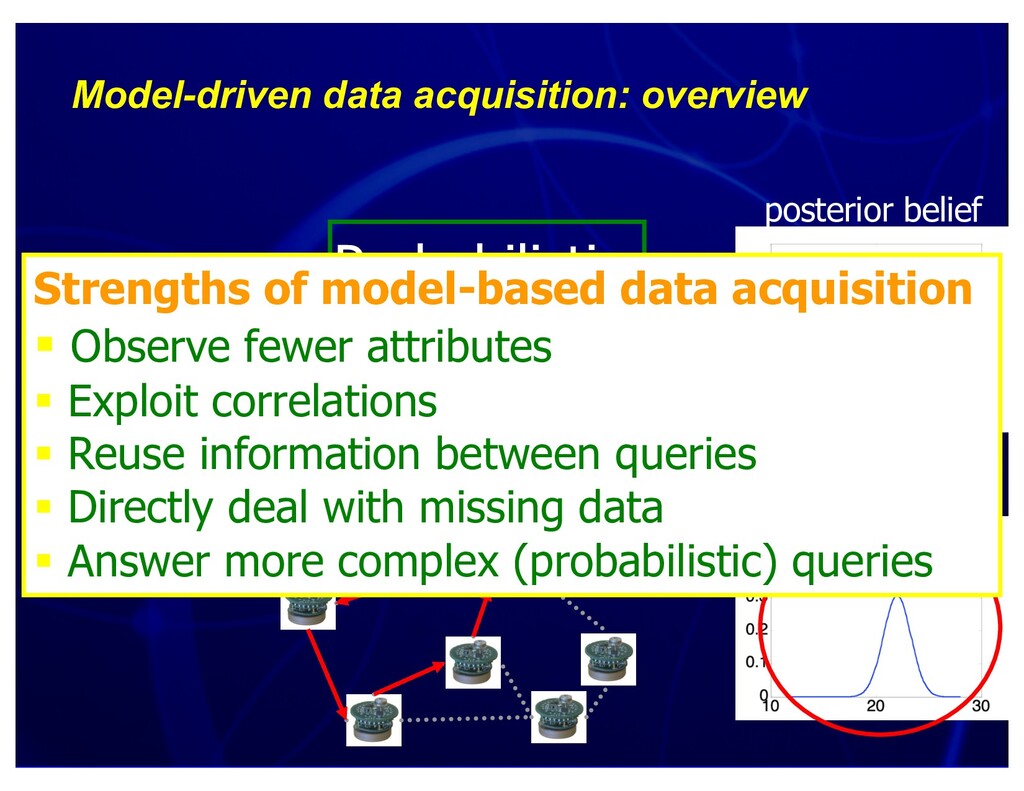{kind=link}