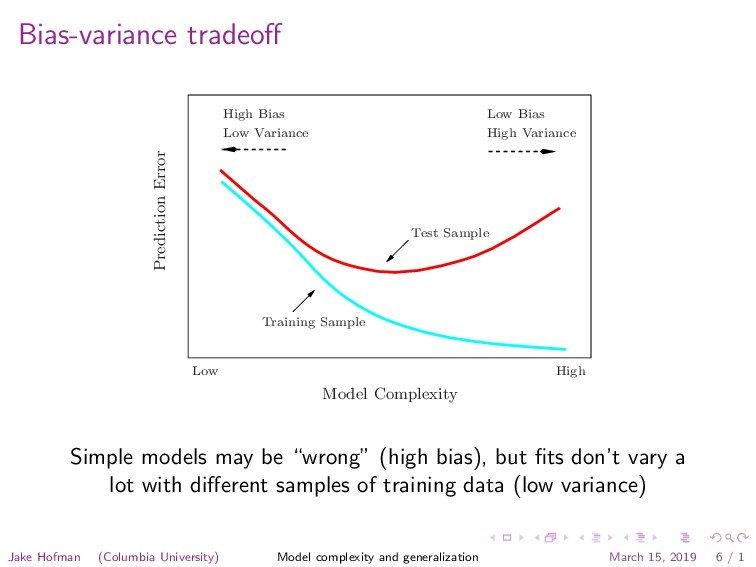
Low Variance Low Bias High Variance Prediction Error Model Complexity Training Sample Test Sample Low High FIGURE 2.11. Test and training error as a function of model complexity. be close to f(x0 ). As k grows, the neighbors are further away, and then anything can happen. The variance term is simply the variance of an average here, and de- creases as the inverse of k. So as k varies, there is a bias–variance tradeoff. Simple models may be “wrong” (high bias), but fits don’t vary a lot with different samples of training data (low variance) Jake Hofman (Columbia University) Model complexity and generalization March 15, 2019 6 / 1
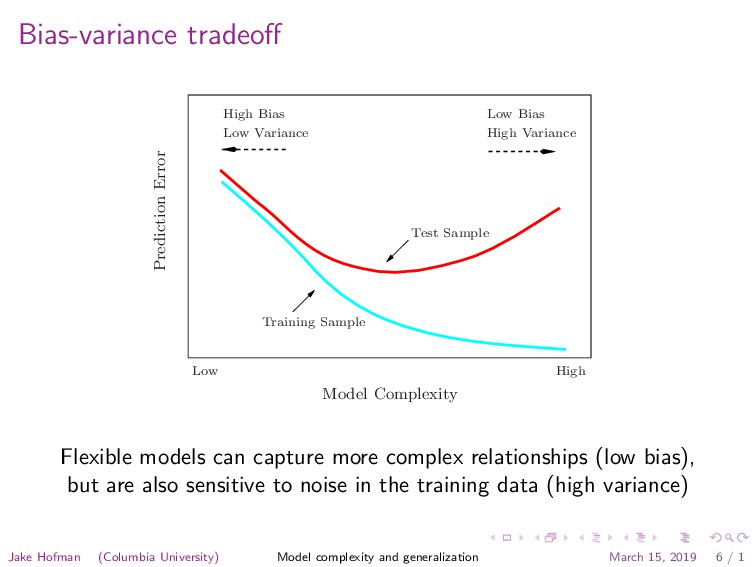
Low Variance Low Bias High Variance Prediction Error Model Complexity Training Sample Test Sample Low High FIGURE 2.11. Test and training error as a function of model complexity. be close to f(x0 ). As k grows, the neighbors are further away, and then anything can happen. The variance term is simply the variance of an average here, and de- creases as the inverse of k. So as k varies, there is a bias–variance tradeoff. Flexible models can capture more complex relationships (low bias), but are also sensitive to noise in the training data (high variance) Jake Hofman (Columbia University) Model complexity and generalization March 15, 2019 6 / 1
the true test error, sometimes substantially. It is difficult to give a general rule on how to choose the number of observations in each of the three parts, as this depends on the signal-to- noise ratio in the data and the training sample size. A typical split might be 50% for training, and 25% each for validation and testing: Test Train Validation Test Train Validation Test Validation Train Validation Test Train The methods in this chapter are designed for situations where there is insufficient data to split it into three parts. Again it is too difficult to give a general rule on how much training data is enough; among other things, this depends on the signal-to-noise ratio of the underlying function, and the complexity of the models being fit to the data. • Randomly split our data into three sets • Fit models on the training set • Use the validation set to find the best model • Quote final performance of this model on the test set Jake Hofman (Columbia University) Model complexity and generalization March 15, 2019 8 / 1
validation split can be noisy, so shuffle data and average over K distinct validation partitions instead Jake Hofman (Columbia University) Model complexity and generalization March 15, 2019 9 / 1
for each model for each of the K folds train on everything but one fold measure the error on the held out fold store the training and validation error compute and store the average error across all folds pick the model with the lowest average validation error evaluate its performance on a final, held out test set Jake Hofman (Columbia University) Model complexity and generalization March 15, 2019 10 / 1
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}