under- stand, as far as possible with the available data, how the conditional distribution of the response varies across subpopulations determined by the possible values of the predictor or predictors.” -“Applied Regression Including Computing and Graphics” Cook & Weisberg (1999) Jake Hofman (Columbia University) Regression March 8, 2019 2 / 6
conditions Predict Make forecasts for future outcomes or unobserved conditions Explain Account for associations between predictors and outcomes Jake Hofman (Columbia University) Regression March 8, 2019 3 / 6
conditions Never “false”, but may be wasteful or misleading Predict Make forecasts for future outcomes or unobserved conditions Varying degrees of success, often room for improvement Explain Account for associations between predictors and outcomes Difficult to establish causality in observational studies See “Regression Analysis: A Constructive Critique”, Berk (2004) Jake Hofman (Columbia University) Regression March 8, 2019 3 / 6
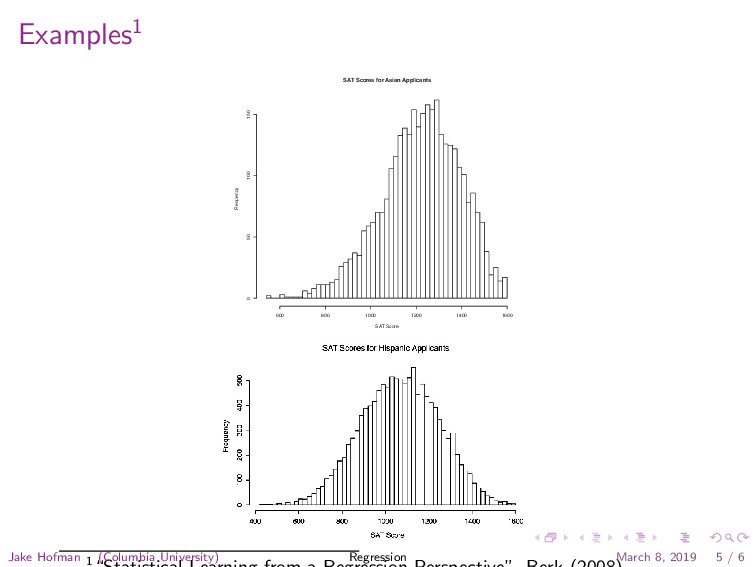
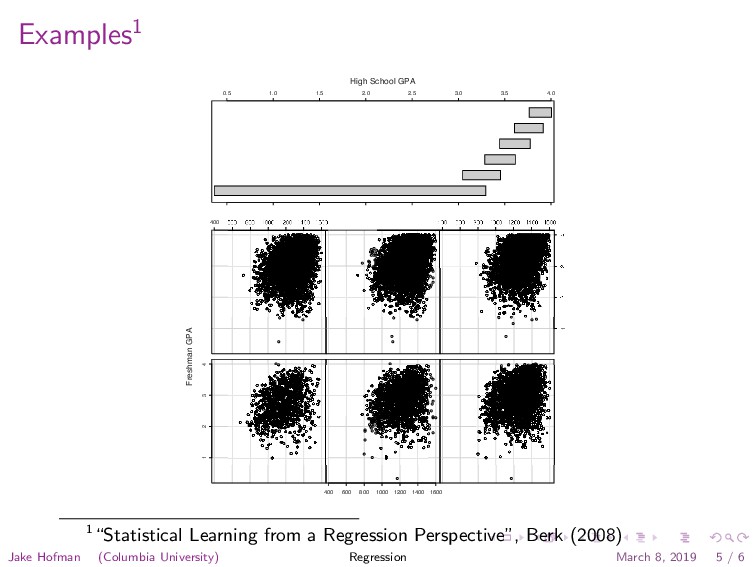
especially interested in a comparison of the means, one could proceed descriptively with a conventional least squares regression analysis as a special case. That is, for each observation i, one could let ˆ yi = β0 + β1 xi , (1.1) where the response variable yi is each applicant’s SAT score, xi is an indicator variable coded “1” if the applicant is Asian and “0” if the applicant is Hispanic, β0 is the mean SAT score for Hispanic applicants, β1 is how much larger (or smaller) the mean SAT score for Asian applicants happens to be, and i is an index running from 1 to the number of Hispanic and Asian applicants, N. Fig. 1.2. Distribution of SAT scores for Asian applicants. SAT Scores for Asian Applicants SAT Score Frequency 600 800 1000 1200 1400 1600 0 50 100 150 to equate regression analysis with causal modeling. This is too narrow and even misleading. Causal modeling is actually an interpretive framework that is imposed on the results of a regression analysis. An alternative knee-jerk response may be to equate regression analysis with the general linear model. At most, the general linear model can be seen as a special case of regression analysis. Statisticians commonly define regression so that the goal is to understand “as far as possible with the available data how the conditional distribution of some response y varies across subpopulations determined by the possible values of the predictor or predictors” (Cook and Weisberg, 1999: 27). That is, interest centers on the distribution of the response variable Y conditioning on one or more predictors X. This definition includes a wide variety of elementary procedures easily implemented in R. (See, for example, Maindonald and Braun, 2007: Chapter 2.) For example, consider Figures 1.1 and 1.2. The first shows the distribution of SAT scores for recent applicants to a major university, who self-identify as “Hispanic.” The second shows the distribution of SAT scores for recent applicants to that same university, who self-identify as “Asian.” 1 Jake Hofman (Columbia University) Regression March 8, 2019 5 / 6
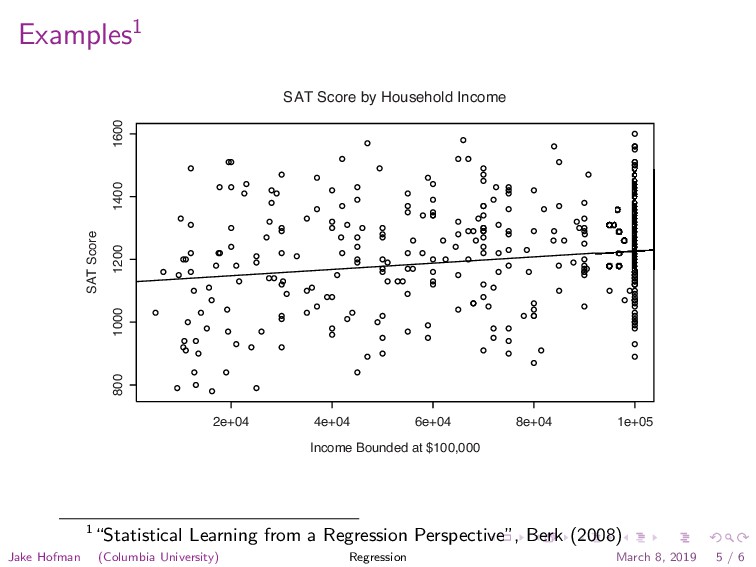
1000 1200 1400 1600 SAT Score by Household Income Income Bounded at $100,000 SAT Score Fig. 1.4. SAT scores by family income. 1“Statistical Learning from a Regression Perspective”, Berk (2008) Jake Hofman (Columbia University) Regression March 8, 2019 5 / 6
form of the model relating them • Define a loss function that quantifies how close a model’s predictions are to observed outcomes • Develop an algorithm to fit the model to the observations by minimizing this loss • Assess model performance and interpret results. Jake Hofman (Columbia University) Regression March 8, 2019 6 / 6
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}