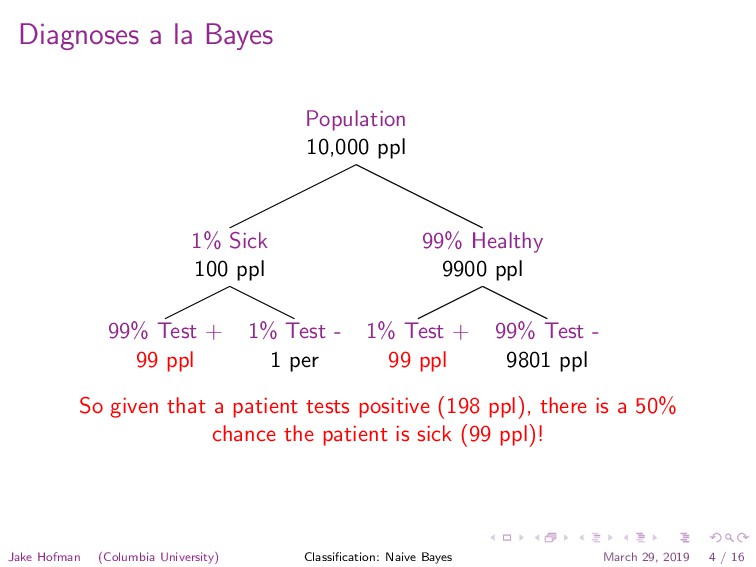
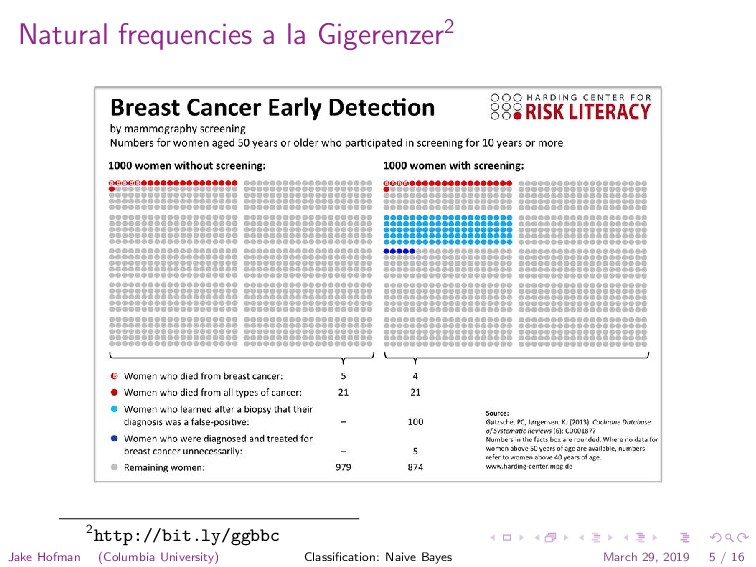
disease: • 1% of the population is infected • You have a highly sensitive and specific test: • 99% of sick patients test positive • 99% of healthy patients test negative • Given that a patient tests positive, what is probability the patient is sick? 1Wiggins, SciAm 2006 Jake Hofman (Columbia University) Classification: Naive Bayes March 29, 2019 3 / 16
ppl 99% Test + 99 ppl 1% Test - 1 per 99% Healthy 9900 ppl 1% Test + 99 ppl 99% Test - 9801 ppl So given that a patient tests positive (198 ppl), there is a 50% chance the patient is sick (99 ppl)! Jake Hofman (Columbia University) Classification: Naive Bayes March 29, 2019 4 / 16
ppl 99% Test + 99 ppl 1% Test - 1 per 99% Healthy 9900 ppl 1% Test + 99 ppl 99% Test - 9801 ppl The small error rate on the large healthy population produces many false positives. Jake Hofman (Columbia University) Classification: Naive Bayes March 29, 2019 4 / 16
left-hand sides of product rule p (y|x) p (x) = p (x, y) = p (x|y) p (y) and divide to get the probability of y given x from the probability of x given y: p (y|x) = p (x|y) p (y) p (x) where p (x) = y∈ΩY p (x|y) p (y) is the normalization constant. Jake Hofman (Columbia University) Classification: Naive Bayes March 29, 2019 6 / 16
what is probability the patient is sick? p (sick|+) = 99/100 p (+|sick) 1/100 p (sick) p (+) 99/1002+99/1002=198/1002 = 99 198 = 1 2 where p (+) = p (+|sick) p (sick) + p (+|healthy) p (healthy). Jake Hofman (Columbia University) Classification: Naive Bayes March 29, 2019 7 / 16
a one-word spam classifier: p (spam|word) = p (word|spam) p (spam) p (word) where we estimate these probabilities with ratios of counts: ˆ p(word|spam) = # spam docs containing word # spam docs ˆ p(word|ham) = # ham docs containing word # ham docs ˆ p(spam) = # spam docs # docs ˆ p(ham) = # ham docs # docs Jake Hofman (Columbia University) Classification: Naive Bayes March 29, 2019 8 / 16
where xj = 1 if the j-th word appears in the document (xj = 0 otherwise). Modeling each word as an independent Bernoulli random variable, the probability of observing a document x of class c is: p (x|c) = j θxj jc (1 − θjc)1−xj where θjc denotes the probability that the j-th word occurs in a document of class c. Jake Hofman (Columbia University) Classification: Naive Bayes March 29, 2019 12 / 16
a logarithm, we have: log p (c|x) = log p (x|c) p (c) p (x) = j xj log θjc 1 − θjc + j log(1 − θjc) + log θc p (x) where θc is the probability of observing a document of class c. Jake Hofman (Columbia University) Classification: Naive Bayes March 29, 2019 13 / 16
classes to estimate θjc and θc: ˆ θjc = njc nc ˆ θc = nc n and use these to calculate the weights ˆ wj and bias ˆ w0: ˆ wj = log ˆ θj1(1 − ˆ θj0) ˆ θj0(1 − ˆ θj1) ˆ w0 = j log 1 − ˆ θj1 1 − ˆ θj0 + log ˆ θ1 ˆ θ0 . We we predict by simply adding the weights of the words that appear in the document to the bias term. Jake Hofman (Columbia University) Classification: Naive Bayes March 29, 2019 15 / 16
model is easy to update given new observations3 3http://www.springerlink.com/content/wu3g458834583125/ Jake Hofman (Columbia University) Classification: Naive Bayes March 29, 2019 16 / 16
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}