年齢 ASC 昇順でソート SELECT * FROM 社員 ORDER BY 年齢 ASCは省略可能 SELECT * FROM 社員 ORDER BY 年齢, 社員番号 年齢が同じ場合、社員番号でさらにソートする SELECT 受注ID, SUM(数量) FROM 社員 ORDER BY 2 ASC 数字を指定するとSELECT中の項目番号を指す。 この場合は ORDER BY SUM(数量) ASC と同じ意味
'39' 年齢が30以上39以下でない WHERE 年齢 NOT IN ('30', '35') 年齢が30または35でない WHERE 氏名 NOT LIKE '山%' 氏名が山~(任意長)でない WHERE 氏名 NOT LIKE '山_' 氏名が山~(1文字)でない WHERE 所属 IS NOT NULL 所属がNULLでない
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
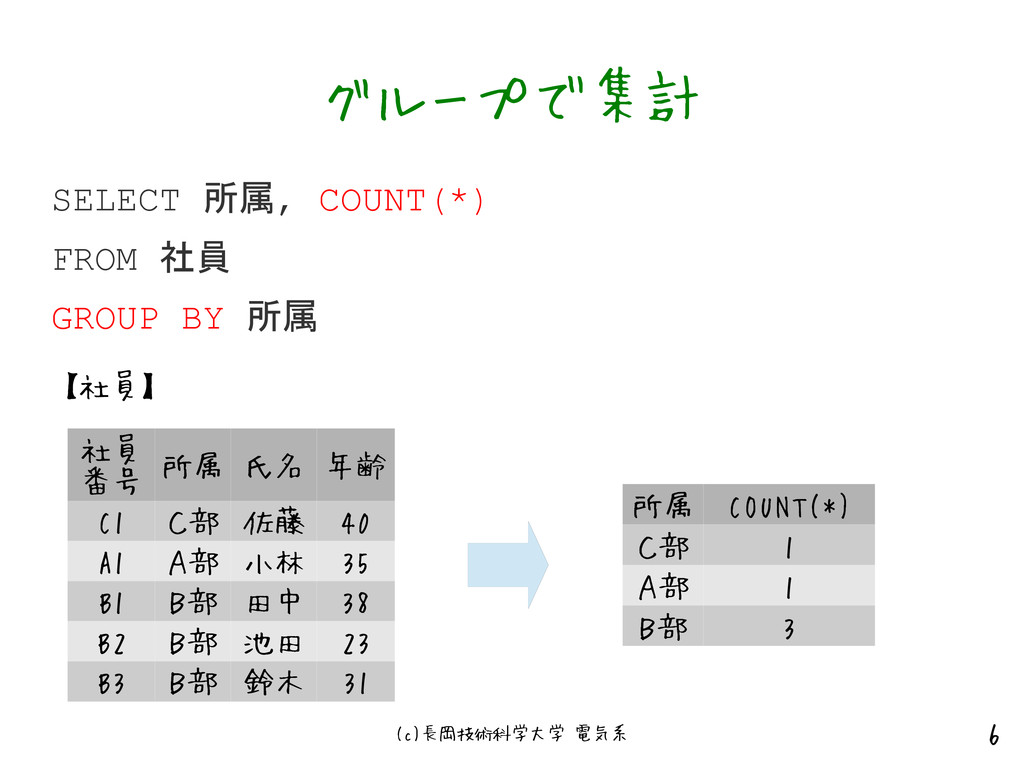{kind=link}
{kind=link}
{kind=link}
{kind=link}
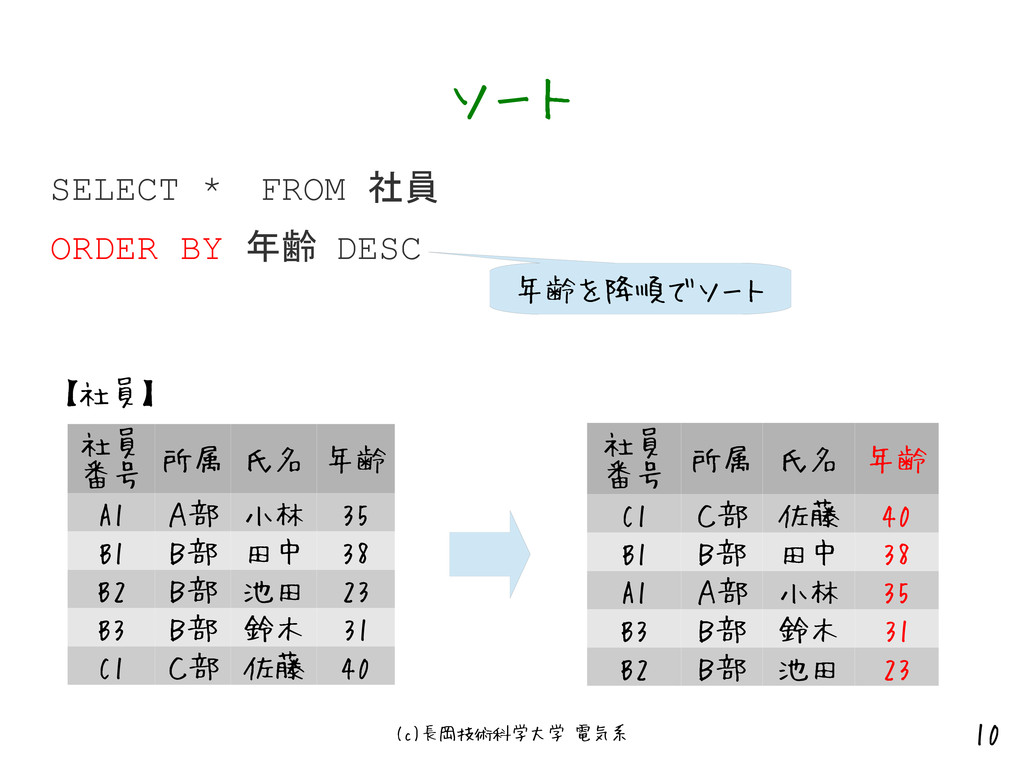{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
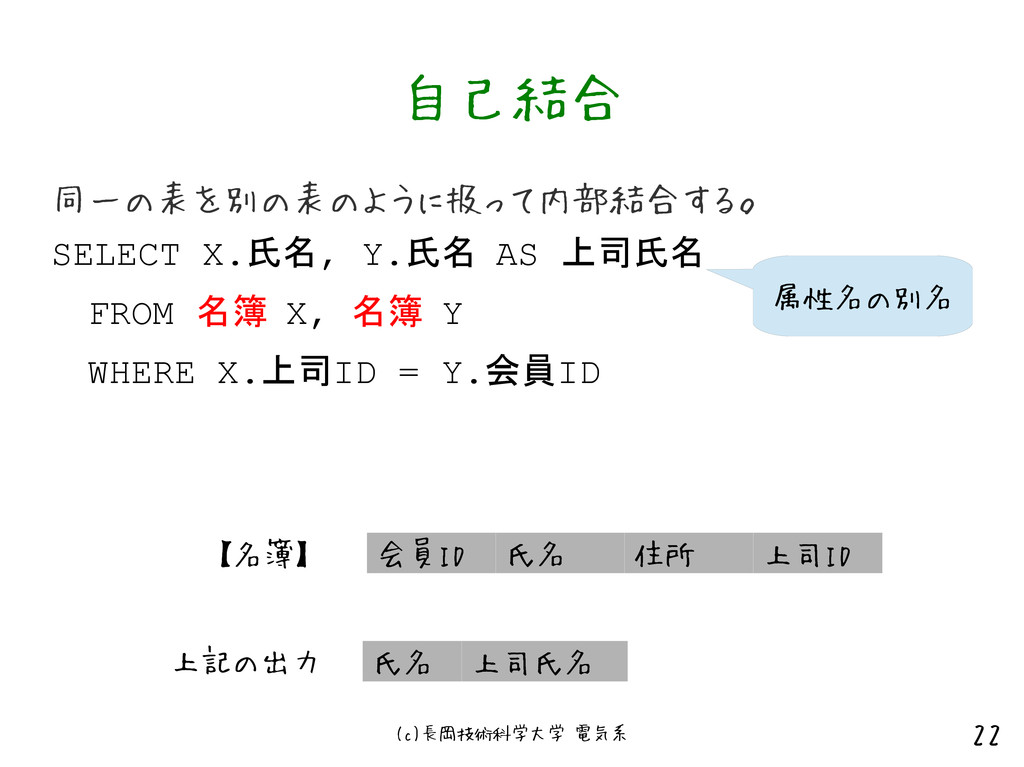{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}