Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
素性の相対性による分布類似度計算
Search
自然言語処理研究室
March 31, 2010
Research
160
1
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
素性の相対性による分布類似度計算
朝倉 剛史, 山本 和英. 素性の相対性による分布類似度計算. 言語処理学会第16回年次大会, pp.688-691 (2010.3)
自然言語処理研究室
March 31, 2010
More Decks by 自然言語処理研究室
See All by 自然言語処理研究室
データサイエンス14_システム.pdf
jnlp
0
410
データサイエンス13_解析.pdf
jnlp
0
530
データサイエンス12_分類.pdf
jnlp
0
370
データサイエンス11_前処理.pdf
jnlp
0
500
Recurrent neural network based language model
jnlp
0
170
自然言語処理研究室 研究概要(2012年)
jnlp
0
160
自然言語処理研究室 研究概要(2013年)
jnlp
0
120
自然言語処理研究室 研究概要(2014年)
jnlp
0
150
自然言語処理研究室 研究概要(2015年)
jnlp
0
230
Other Decks in Research
See All in Research
「車1割削減、渋滞半減、公共交通2倍」を 熊本から岡山へ@RACDA設立30周年記念都市交通フォーラム2026
trafficbrain
1
1.2k
COFFEE-Japan PROJECT Impact Report(海ノ向こうコーヒー)
ontheslope
0
2k
LiDAR点群の地表面分類手法の比較・検証
vegapunkhiroshi79
0
120
2026 東京科学大 情報通信系 研究室紹介 (すずかけ台)
icttitech
0
3.8k
SAKURAONE: An Open Ethernet-based AI HPC System And Its Observed Workload Dynamics in a Single-Tenant LLM Development Environment
yuukit
1
350
SoftMatcha 2: 1兆語規模コーパスの超高速かつ柔らかい検索
e869120_sub
6
3.5k
適応的スパムフィルタのための軽量な類似メッセージカウンタ / jsai2026-adaptive-spam-filter
monochromegane
0
3.7k
2026年1月の生成AI領域の重要リリース&トピック解説
kajikent
0
1k
National high-resolution cropland classification of Japan with agricultural census information and multi-temporal multi-modality datasets
satai
3
290
討議:RACDA設立30周年記念都市交通フォーラム2026
trafficbrain
0
960
Any-Optical-Model: A Universal Foundation Model for Optical Remote Sensing
satai
3
840
RS-Agent: Automating Remote Sensing Tasks through Intelligent Agent
satai
2
310
Featured
See All Featured
How to build an LLM SEO readiness audit: a practical framework
nmsamuel
1
780
Navigating Weather and Climate Data
rabernat
0
220
KATA
mclloyd
PRO
35
15k
Navigating the Design Leadership Dip - Product Design Week Design Leaders+ Conference 2024
apolaine
1
350
Helping Users Find Their Own Way: Creating Modern Search Experiences
danielanewman
31
3.2k
How GitHub (no longer) Works
holman
316
150k
Git: the NoSQL Database
bkeepers
PRO
432
67k
10 Git Anti Patterns You Should be Aware of
lemiorhan
PRO
659
62k
Making Projects Easy
brettharned
120
6.7k
The Limits of Empathy - UXLibs8
cassininazir
1
360
Building Adaptive Systems
keathley
44
3.1k
Code Review Best Practice
trishagee
74
20k
Transcript
素性の相対性による 分布類似度計算 長岡技術科学大学 朝倉剛史 山本和英 1
発表の流れ 2 1.研究の背景 2.既存研究とその問題 3.提案手法の説明 4.実験及び考察 5.まとめ
研究の背景 電子文書の増加に伴い、 機械処理の必要性が高まっている。 文書の分類、話題抽出などのため、 単語の類似性を求めたい。 単語の類似度計算の必要性が高まっている。 3 1.研究の背景
類似度計算 (1) シソーラスを用いた手法 (2) コーパスを用いた手法 →近年コーパスを用いた手法に注目 ⇒分布類似度 『醤油』 『味噌』 ⇒ 類似度高い 『醤油』 『石』 ⇒ 類似度低い
意味的な類似性を求める 4 1.研究の背景
分布類似度とは? 文書内での単語の使われ方を比較 5 単語の係り先などを素性とする。 ▪『醤油』 「の:香り」「の:原料」「を:製造」 「の:道」「を:投げる」 ・・・ ▪『味噌』 「の:香り」「の:原料」「を:製造」
「から:行く」「を:投げる」・・・ ▪『石』 「を:投げる」「を:蹴る」「の:色」「の:紙」「を:ゴミ」・・・ 1.研究の背景 素性選択の必要性!
発表の流れ 6 1.研究の背景 2.既存研究とその問題 3.提案手法の説明 4.実験及び考察 5.まとめ
▪『醤油』 「の:香り」「の:原料」「を:製造」 「の:道」「を:投げる」 ・・・ ▪『味噌』 「の:香り」「の:原料」「を:製造」 「から:行く」「を:投げる」・・・ ▪『石』 「を:投げる」「を:蹴る」「の:色」「の:紙」「を:ゴミ」・・・ 既存研究の素性選択
7 2.既存研究とその問題 各単語の素性について、単語の特徴を強く 表している要素以外は一律に除外[相澤(08)]。
問題点 ▪『醤油』 「の:香り」「の:原料」「を:製造」 「の:道」「を:投げる」 ・・・ ▪『味噌』 「の:香り」「の:原料」「を:製造」 「から:行く」「を:投げる」・・・ ▪『石』 「を:投げる」「を:蹴る」「の:色」「の:紙」「を:ゴミ」・・・
2単語間で共通して特徴を強く表さない要素 ⇒類似度計算に有効 8 2.既存研究とその問題 除外される 有効な情報まで除外されてしまう
既存手法:単語の特徴を強く表すかどうか 提案手法:特徴を表す度合いが近いかどうか 提案手法 比較対象の単語の素性を用いて 相対的に素性を取捨選択する 。 9 2.既存研究とその問題 2単語間で共通して特徴を強く表さない要素 の獲得が可能。
発表の流れ 1.研究の背景 2.既存研究とその問題 3.提案手法の説明 4.実験及び考察 5.まとめ 10
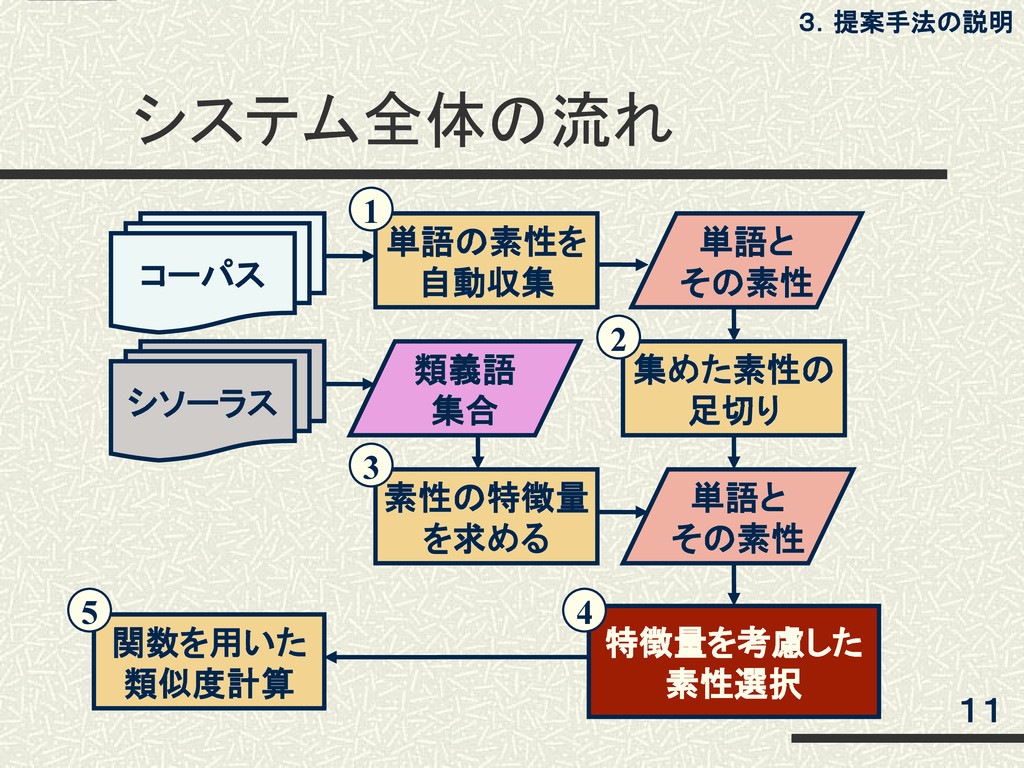
システム全体の流れ 11 3.提案手法の説明 コーパス 単語と その素性 単語の素性を 自動収集 集めた素性の 足切り
素性の特徴量 を求める シソーラス 単語と その素性 特徴量を考慮した 素性選択 類義語 集合 関数を用いた 類似度計算 1 2 3 4 5
例)「お金が必要」 「EUに加盟」 (1)単語の素性を自動収集 コーパスより収集した、以下のような定型表現 を用いる[Lin(98)]。 12 3.提案手法の説明 例えば、『お金』の共起要素として「が:必要」が 得られる。全ての単語wについて、共起要素を 収集し、素性を作成する。
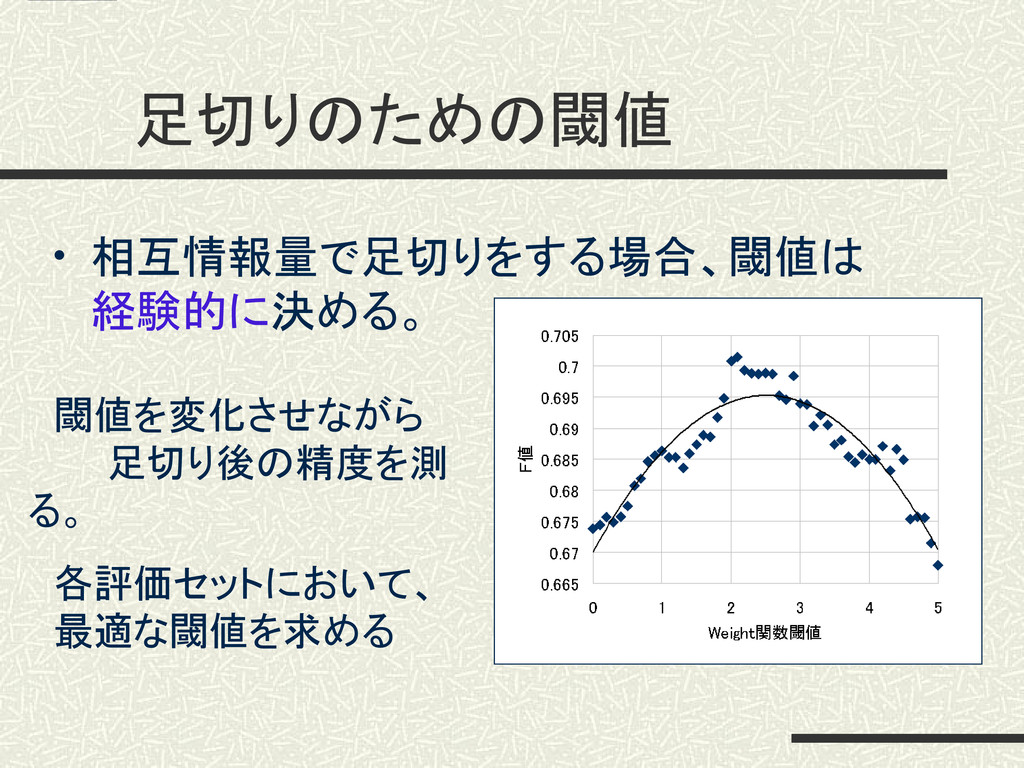
(2)集めた素性の足切り あきらかなノイズなどは、足切りしておく。 共起要素の出現頻度を用いて、相互情報量 (MI)が閾値βに満たないものは、除外する。 13 3.提案手法の説明 閾値βは評価セットによって異なり、経験的 に決める[相澤(08)]。
(3)素性の特徴量を求める 特徴量=共起要素が単語wの特徴を表す度合い 単語wの類義語集合を使用する。 ▪例:『少年』の類義語集合 →「子供」「少女」「児童」「女の子」「青少年」 その類義語集合の中で共通する共起要素ほど、特徴 量を高くする[Zhitomirsky-Geffet and Dagan(09)]。 14
3.提案手法の説明
(4)特徴量を考慮した素性選択 ▪『醤油』 「の:香り(1.0)」「の:原料(0.9)」「を:製造(0.8)」 「の:道(0.4)」「を:投げる(0.1)」・・・ ▪『味噌』 「の:香り(1.0)」「の:原料(0.8)」「を:製造(0.7)」 「から:行く(0.4)」「を:投げる(0.1)」・・・ 15 3.提案手法の説明 共通している要素について特徴量の差が大き
ければ除外し、小さければ除外しない。 ※数字は特徴量
(5)関数を用いた類似度計算 素性の重なりを見る関数である以下の関数 を使用する。 これらの関数を相加平均した値を類似度と する[柴田ら(09)]。 16 3.提案手法の説明
発表の流れ 1.研究の背景 2.既存研究とその問題 3.提案手法の説明 4.実験及び考察 5.まとめ 17
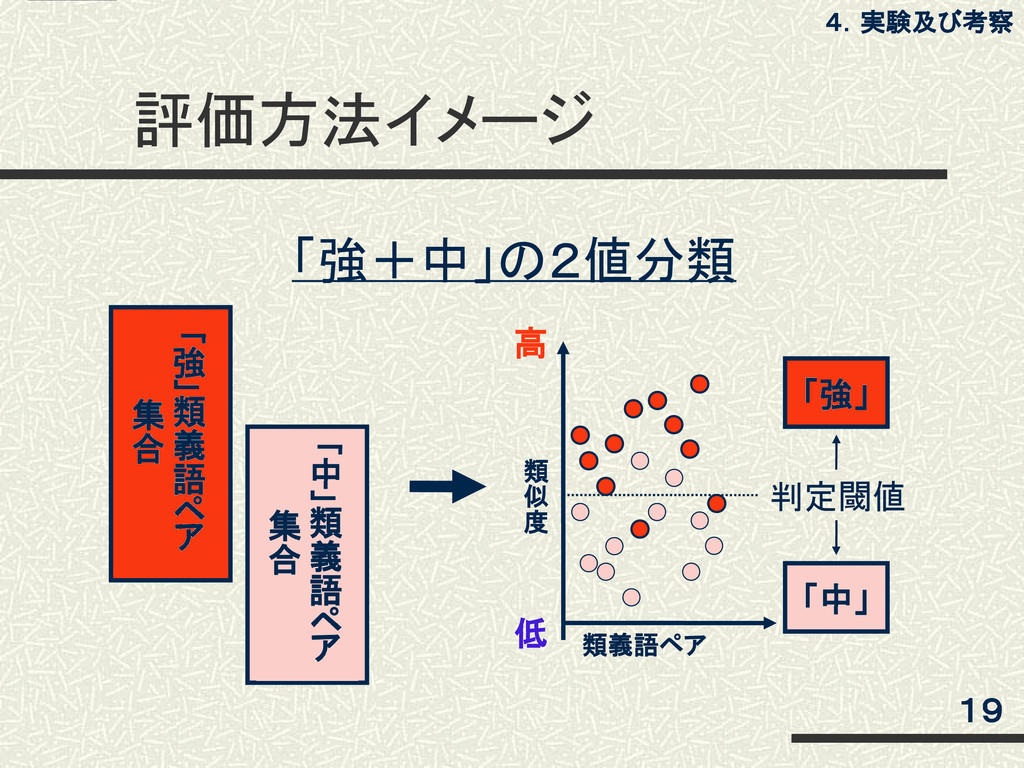
評価方法 4.実験及び考察 18 「強」類義語 「中」類義語 「弱」類義語 「非」類義語 IC:LSI IC:太陽電池 IC:カード
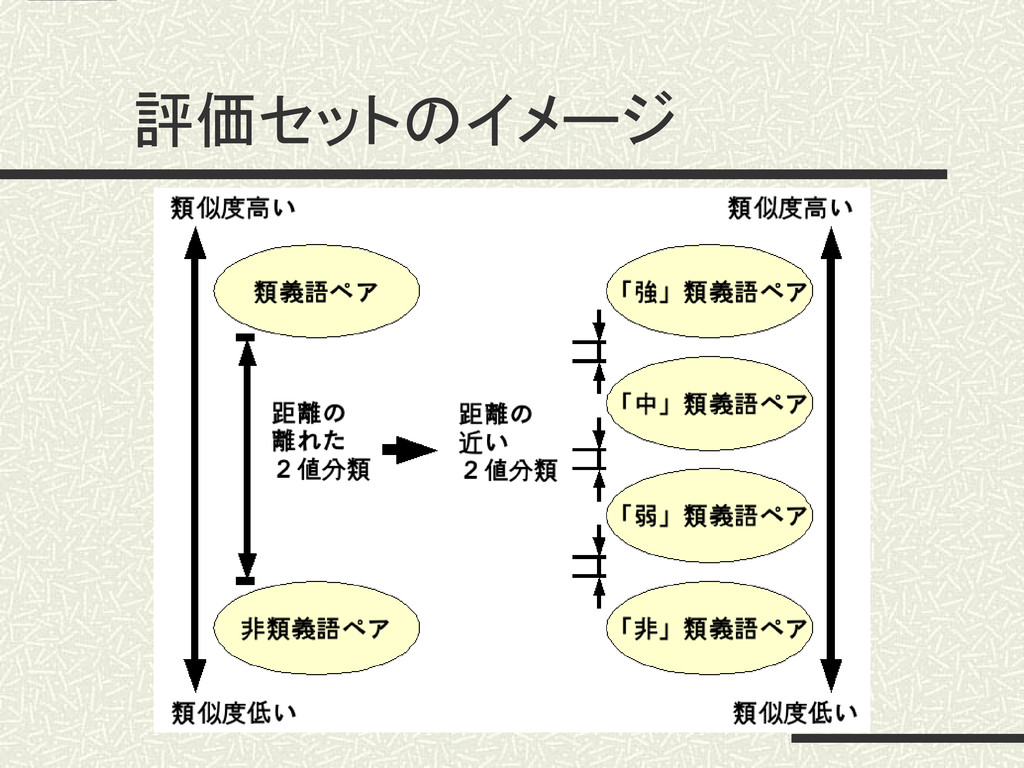
IC:国土庁 アジア:ヨーロッパ アジア:アメリカ アジア:我が国 アジア:システム 居酒屋:パブ 居酒屋:コンビニ 居酒屋:駅 居酒屋:地名 高 低 2組の類義語ペア(「強+中」「中+弱」「弱+非」) を類似度計算した結果で2値分類する。
「強」 評価方法イメージ 「 強 」 類 義 語 ペ ア
集 合 「 中 」 類 義 語 ペ ア 集 合 判定閾値 高 低 19 4.実験及び考察 類義語ペア 類 似 度 「強+中」の2値分類 「中」
実験 (1)柴田らの手法 相互情報量による足切りのみ (2)Zhitomirsky-Geffet and Daganの手法 特徴量を求め、その値で一律に除外 (3)本手法 特徴量を用いて素性を相対的に取捨選択 4.実験及び考察
20 実験は3手法を比較した。
実験条件 • 使用したコーパス 日本経済新聞全記事データーベース 1990-2004年度版 • 使用した単語数 ※共起要素数が20以上 40,678語 21
4.実験及び考察
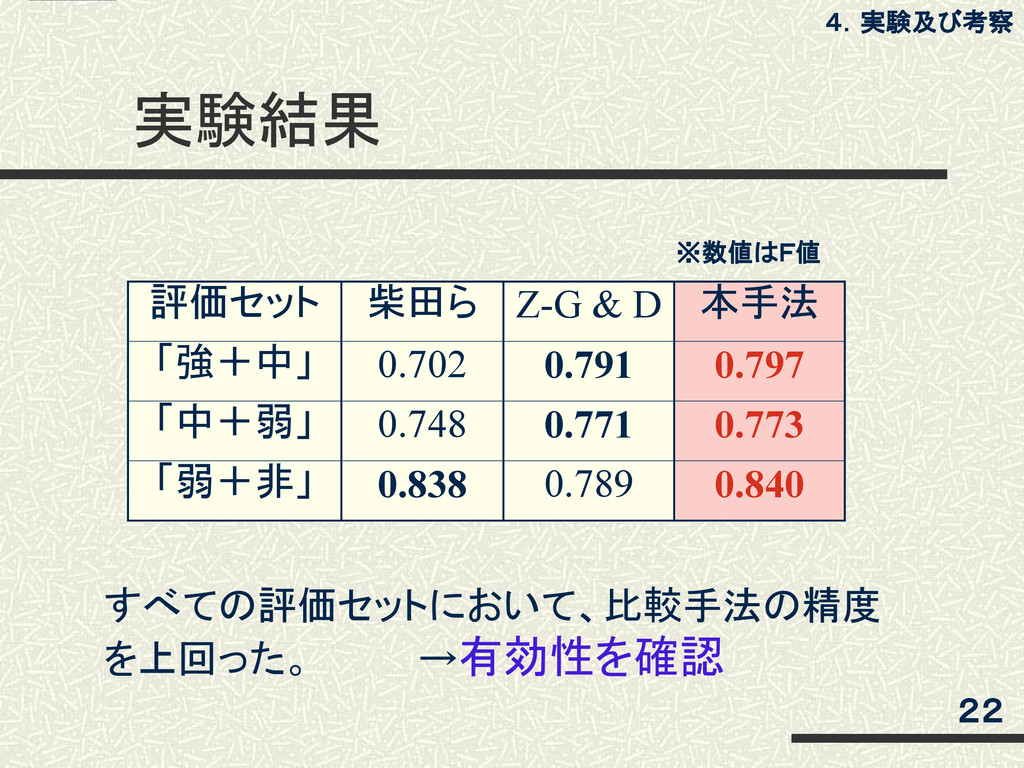
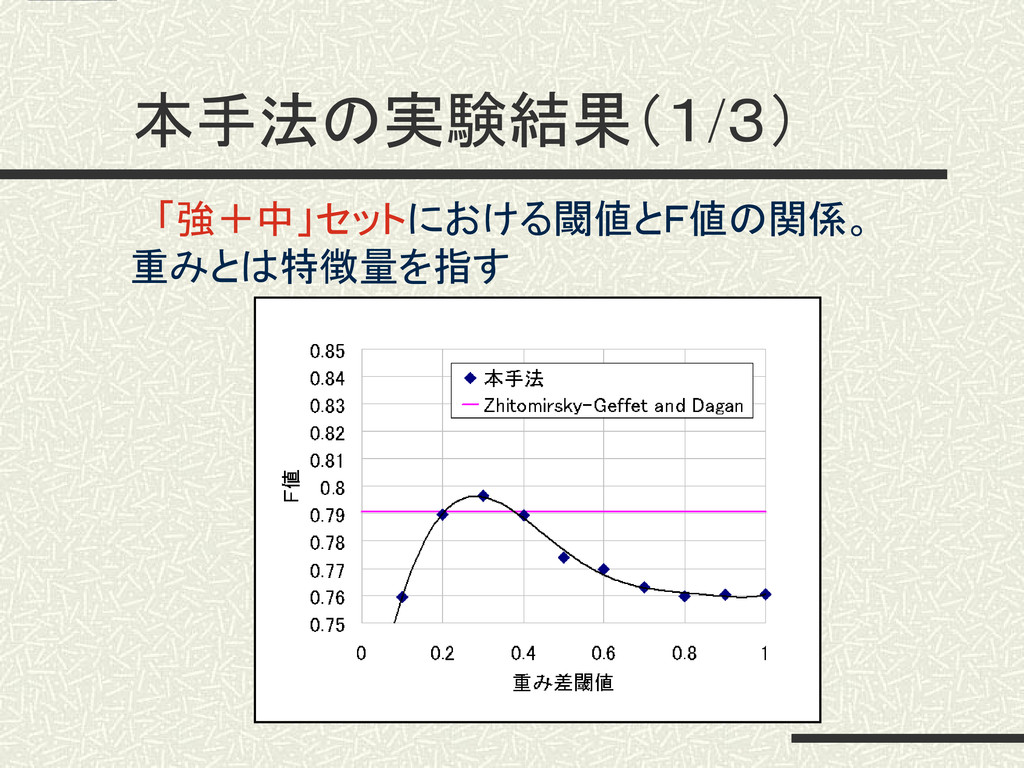
実験結果 評価セット 柴田ら Z-G & D 本手法 「強+中」 0.702 0.791
0.797 「中+弱」 0.748 0.771 0.773 「弱+非」 0.838 0.789 0.840 すべての評価セットにおいて、比較手法の精度 を上回った。 →有効性を確認 4.実験及び考察 22 ※数値はF値
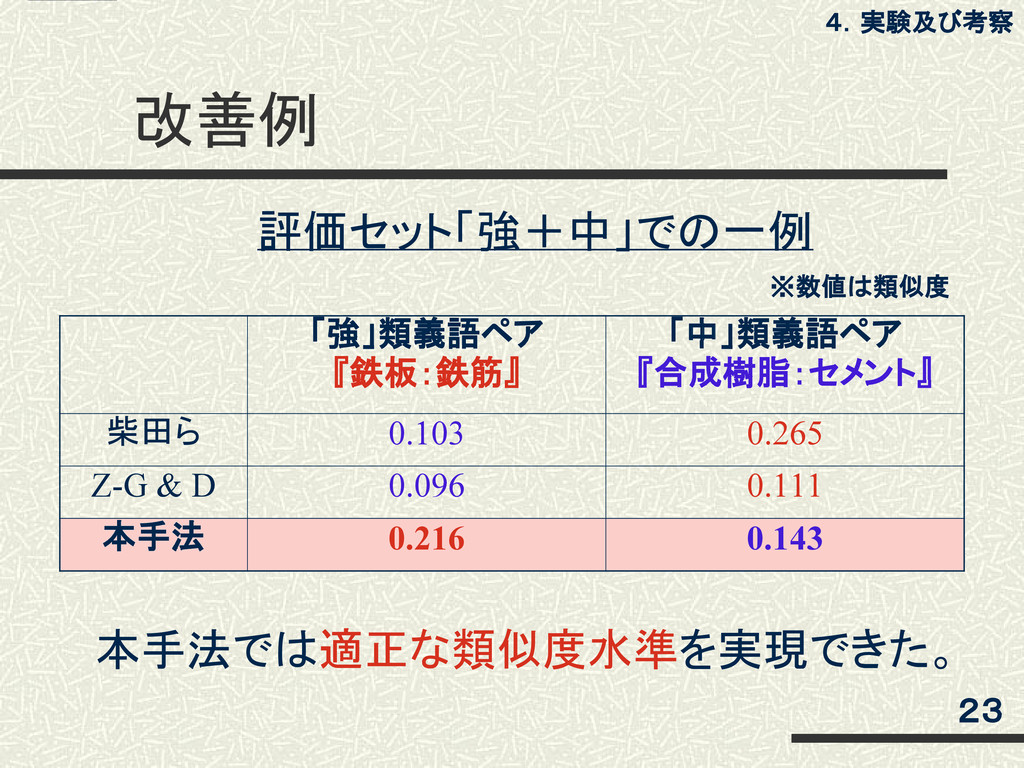
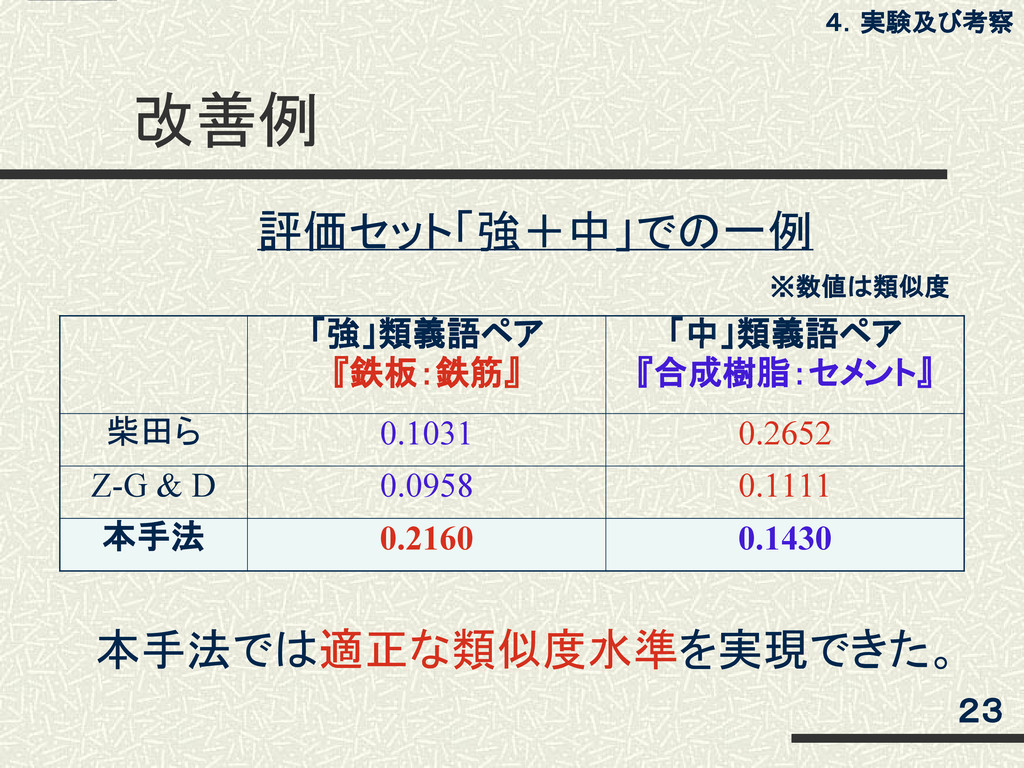
改善例 「強」類義語ペア 『鉄板:鉄筋』 「中」類義語ペア 『合成樹脂:セメント』 柴田ら 0.103 0.265 Z-G &
D 0.096 0.111 本手法 0.216 0.143 4.実験及び考察 23 本手法では適正な類似度水準を実現できた。 ※数値は類似度 評価セット「強+中」での一例
考察 • 低頻度ペアが誤りの中に多く分布していた。 ⇒超大規模コーパスを用いたり、素性を 補完するような手法が求められる。 4.実験及び考察 24 今回用いた特徴量では、精度を維持しながら 削減できる量は、最大約98%に上った。 ⇒類似度計算に必要な素性は非常に限ら
れている。
今後の課題 • 2単語間の素性の共通していない部分にお いては、相対性を用いた素性選択が行えて いない。 →2単語間のみならず、対象の類義語集合 の素性と比べるなどの工夫が求められる。 4.実験及び考察 25
対象とする単語の範囲を広くする。
発表の流れ 1.研究の背景 2.既存研究とその問題 3.提案手法の説明 4.実験及び考察 5.まとめ 26
まとめ • 分布類似度における従来の素性選択では、必要 な素性まで除外されてしまう可能性がある。 • 素性の相対性を考慮した、新しい素性選択手法 を提案した。 • 比較対象の単語の素性と共通する要素について 特徴量の差を考慮した。
• 既存手法を上回る精度であり、有効性を示した。 5.まとめ 27
発表は以上です。 ありがとうございました。 28
評価セットのイメージ
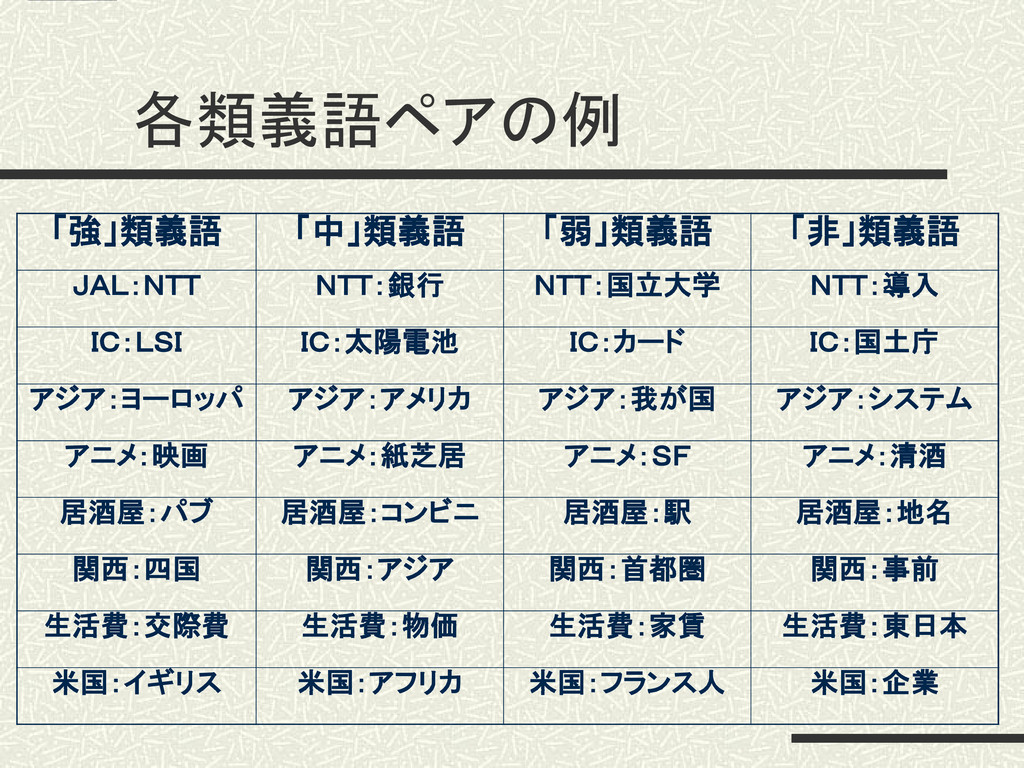
各類義語ペアの例 「強」類義語 「中」類義語 「弱」類義語 「非」類義語 JAL:NTT NTT:銀行 NTT:国立大学 NTT:導入 IC:LSI
IC:太陽電池 IC:カード IC:国土庁 アジア:ヨーロッパ アジア:アメリカ アジア:我が国 アジア:システム アニメ:映画 アニメ:紙芝居 アニメ:SF アニメ:清酒 居酒屋:パブ 居酒屋:コンビニ 居酒屋:駅 居酒屋:地名 関西:四国 関西:アジア 関西:首都圏 関西:事前 生活費:交際費 生活費:物価 生活費:家賃 生活費:東日本 米国:イギリス 米国:アフリカ 米国:フランス人 米国:企業
足切りのための閾値 • 相互情報量で足切りをする場合、閾値は 経験的に決める。 閾値を変化させながら 足切り後の精度を測 る。 各評価セットにおいて、 最適な閾値を求める
本手法の実験結果(1/3) 「強+中」セットにおける閾値とF値の関係。 重みとは特徴量を指す
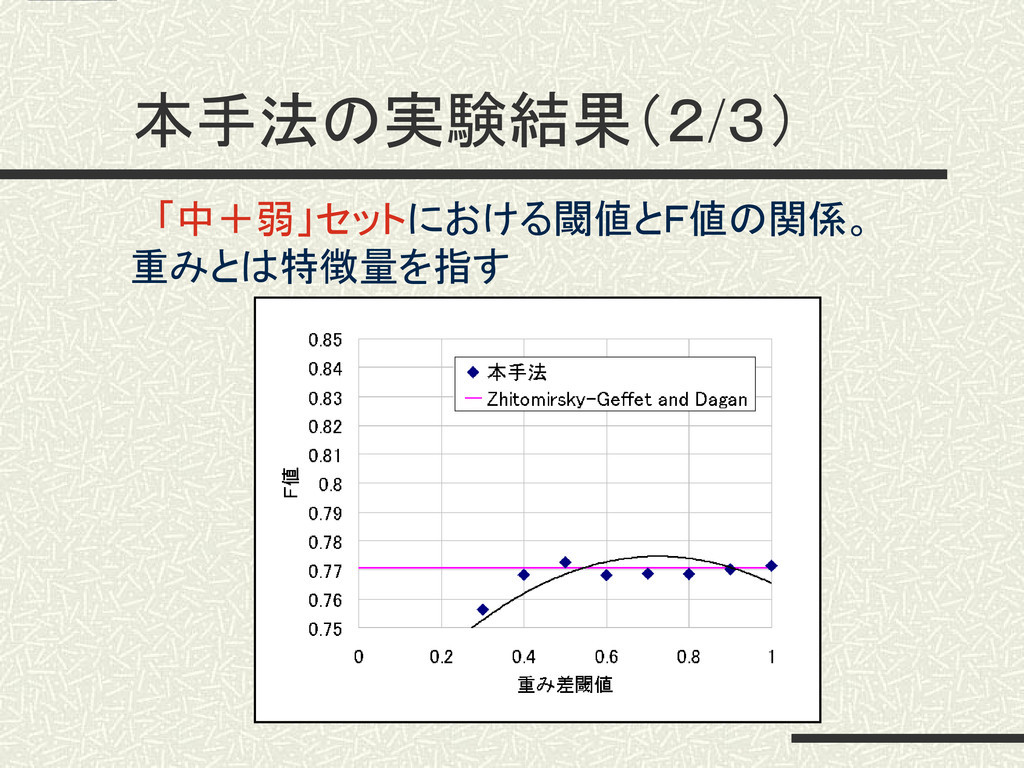
本手法の実験結果(2/3) 「中+弱」セットにおける閾値とF値の関係。 重みとは特徴量を指す
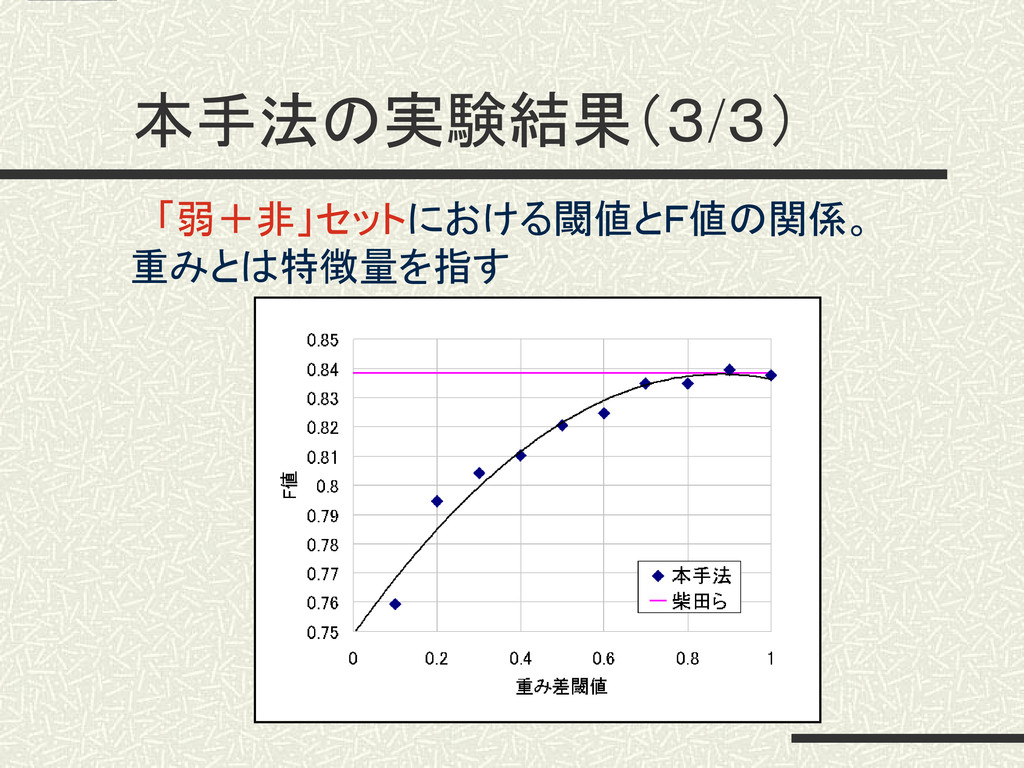
本手法の実験結果(3/3) 「弱+非」セットにおける閾値とF値の関係。 重みとは特徴量を指す
改善例 「強」類義語ペア 『鉄板:鉄筋』 「中」類義語ペア 『合成樹脂:セメント』 柴田ら 0.1031 0.2652 Z-G &
D 0.0958 0.1111 本手法 0.2160 0.1430 4.実験及び考察 23 本手法では適正な類似度水準を実現できた。 ※数値は類似度 評価セット「強+中」での一例
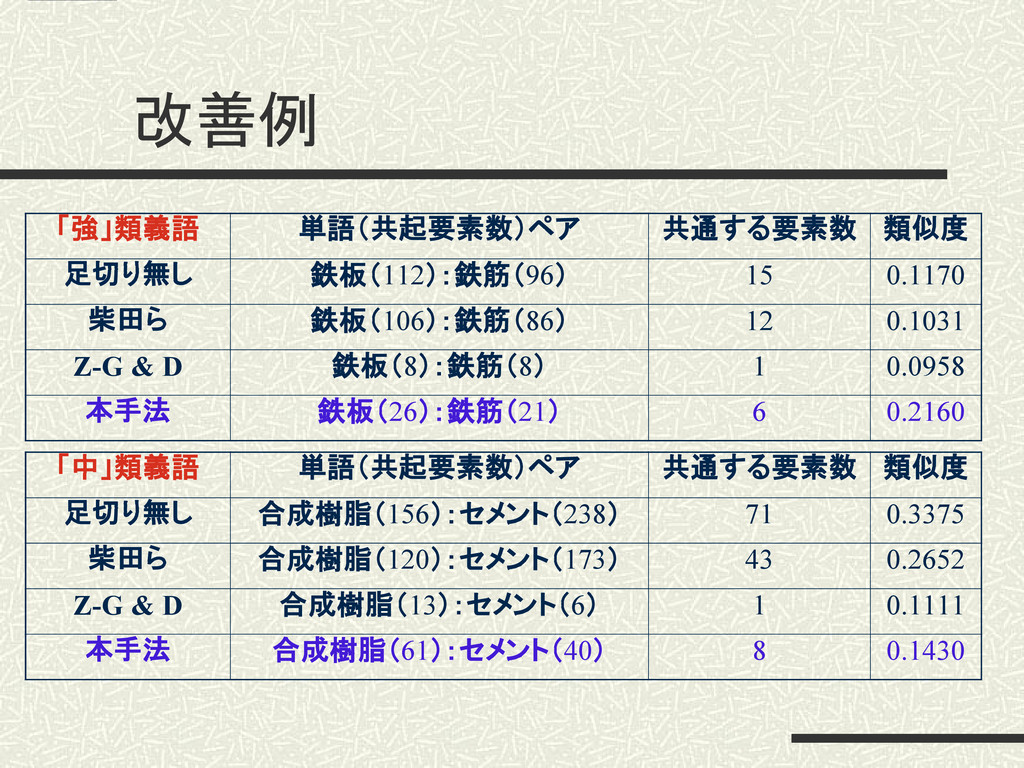
改善例 「強」類義語 単語(共起要素数)ペア 共通する要素数 類似度 足切り無し 鉄板(112):鉄筋(96) 15 0.1170 柴田ら
鉄板(106):鉄筋(86) 12 0.1031 Z-G & D 鉄板(8):鉄筋(8) 1 0.0958 本手法 鉄板(26):鉄筋(21) 6 0.2160 「中」類義語 単語(共起要素数)ペア 共通する要素数 類似度 足切り無し 合成樹脂(156):セメント(238) 71 0.3375 柴田ら 合成樹脂(120):セメント(173) 43 0.2652 Z-G & D 合成樹脂(13):セメント(6) 1 0.1111 本手法 合成樹脂(61):セメント(40) 8 0.1430
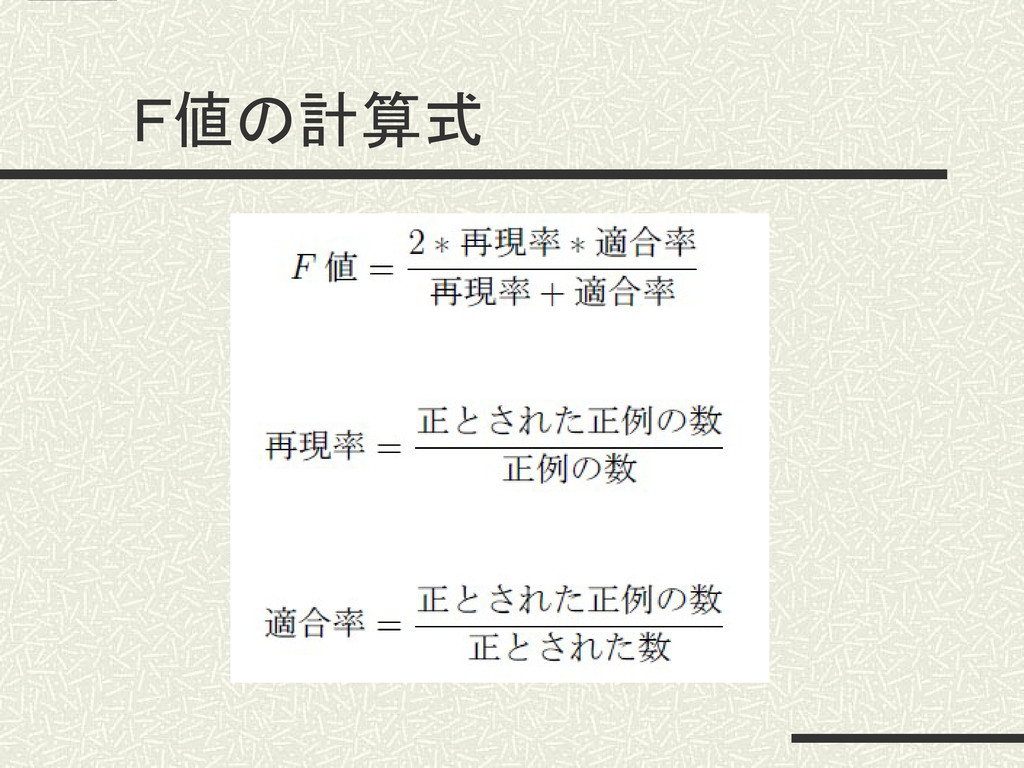
F値の計算式
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![例)「お金が必要」 「EUに加盟」 (1)単語の素性を自動収集 コーパスより収集した、以下のような定型表現 を用いる[Lin(98)]。 12 3.提案手法の説明 例えば、『お金』の共起要素として「が:必要」が 得られる。全ての単語wについて、共起要素を 収集し、素性を作成する。](https://files.speakerdeck.com/presentations/bb0de690c6030130de235662dc1f6446/slide_11.jpg){kind=link}
![(2)集めた素性の足切り あきらかなノイズなどは、足切りしておく。 共起要素の出現頻度を用いて、相互情報量 (MI)が閾値βに満たないものは、除外する。 13 3.提案手法の説明 閾値βは評価セットによって異なり、経験的 に決める[相澤(08)]。](https://files.speakerdeck.com/presentations/bb0de690c6030130de235662dc1f6446/slide_12.jpg){kind=link}
![(3)素性の特徴量を求める 特徴量=共起要素が単語wの特徴を表す度合い 単語wの類義語集合を使用する。 ▪例:『少年』の類義語集合 →「子供」「少女」「児童」「女の子」「青少年」 その類義語集合の中で共通する共起要素ほど、特徴 量を高くする[Zhitomirsky-Geffet and Dagan(09)]。 14](https://files.speakerdeck.com/presentations/bb0de690c6030130de235662dc1f6446/slide_13.jpg){kind=link}
{kind=link}
![(5)関数を用いた類似度計算 素性の重なりを見る関数である以下の関数 を使用する。 これらの関数を相加平均した値を類似度と する[柴田ら(09)]。 16 3.提案手法の説明](https://files.speakerdeck.com/presentations/bb0de690c6030130de235662dc1f6446/slide_15.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}