Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
統計的機械翻訳は意訳しにくいのか?
Search
自然言語処理研究室
March 31, 2009
Research
110
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
統計的機械翻訳は意訳しにくいのか?
竹元 勇太, 山本 和英. 統計的機械翻訳は意訳しにくいのか?. 言語処理学会第15回年次大会, pp.228-231 (2009.3)
自然言語処理研究室
March 31, 2009
More Decks by 自然言語処理研究室
See All by 自然言語処理研究室
データサイエンス14_システム.pdf
jnlp
0
410
データサイエンス13_解析.pdf
jnlp
0
530
データサイエンス12_分類.pdf
jnlp
0
370
データサイエンス11_前処理.pdf
jnlp
0
500
Recurrent neural network based language model
jnlp
0
170
自然言語処理研究室 研究概要(2012年)
jnlp
0
160
自然言語処理研究室 研究概要(2013年)
jnlp
0
130
自然言語処理研究室 研究概要(2014年)
jnlp
0
150
自然言語処理研究室 研究概要(2015年)
jnlp
0
230
Other Decks in Research
See All in Research
「AIとWhyを深堀る」をAIと深堀る
iflection
0
490
羽田新ルート運用6年の検証
1manken
0
160
Cross-Media Information Spaces and Architectures
signer
PRO
0
300
討議:RACDA設立30周年記念都市交通フォーラム2026
trafficbrain
0
970
Φ-Sat-2のAutoEncoderによる情報圧縮系論文
satai
4
790
「なんとなく」の顧客理解から脱却する ──顧客の解像度を武器にするインサイトマネジメント
tajima_kaho
10
7.7k
敵対生成プロンプト同時探索による内省型プロンプト最適化
kinoue_smarthr
0
230
Apache Gravitinoで実現する Icebergカタログ統合とアクセスの一元化
matsumooon
0
290
Can We Teach Logical Reasoning to LLMs? – An Approach Using Synthetic Corpora (AAAI 2026 bridge keynote)
morishtr
1
260
はじまりの クエスチョンブック —余暇と豊かさにあふれた社会とは?
culturaltransition
PRO
0
520
Anthropic が提案する LLM の内部状態を自然言語で説明可能にした Natural Language Autoencoders / Natural Language Autoencoders Produce Unsupervised Explanations of LLM Activations
shunk031
0
130
コーディングエージェントとABNを再考
hf149
2
730
Featured
See All Featured
Leveraging Curiosity to Care for An Aging Population
cassininazir
1
270
Reality Check: Gamification 10 Years Later
codingconduct
0
2.2k
Responsive Adventures: Dirty Tricks From The Dark Corners of Front-End
smashingmag
254
22k
The Language of Interfaces
destraynor
162
27k
Tips & Tricks on How to Get Your First Job In Tech
honzajavorek
1
540
We Have a Design System, Now What?
morganepeng
55
8.2k
How People are Using Generative and Agentic AI to Supercharge Their Products, Projects, Services and Value Streams Today
helenjbeal
1
220
Noah Learner - AI + Me: how we built a GSC Bulk Export data pipeline
techseoconnect
PRO
0
200
How Software Deployment tools have changed in the past 20 years
geshan
0
34k
Crafting Experiences
bethany
1
190
Visualizing Your Data: Incorporating Mongo into Loggly Infrastructure
mongodb
49
10k
The Spectacular Lies of Maps
axbom
PRO
1
820
Transcript
統計的機械翻訳 は意訳しにくい 長岡技術科学大学 山本研究室 竹元勇太 山本和英
概要 ▪統計的機械翻訳は意訳しにくい のか確認を行った TCRによる意訳性の判定 ▪翻訳精度の差を確認 意訳 < 直訳 統計的機械翻訳は意訳しにくい ことを確認
関連研究 ▪直訳性を利用した機械翻訳知識の自 動構築[今村 04] 日英対訳コーパス TCR 英語 日本語 1.00 --a--
--A-- 0.96 --b-- --B-- 0.85 --c-- --C-- 0.82 --d-- --D-- . . 0.65 --g-- --G-- 0.43 --g-- --G-- 0.10 --h-- --H-- 直訳的対訳文を用いた 翻訳モデル 意訳的対訳文を用いた 翻訳モデル
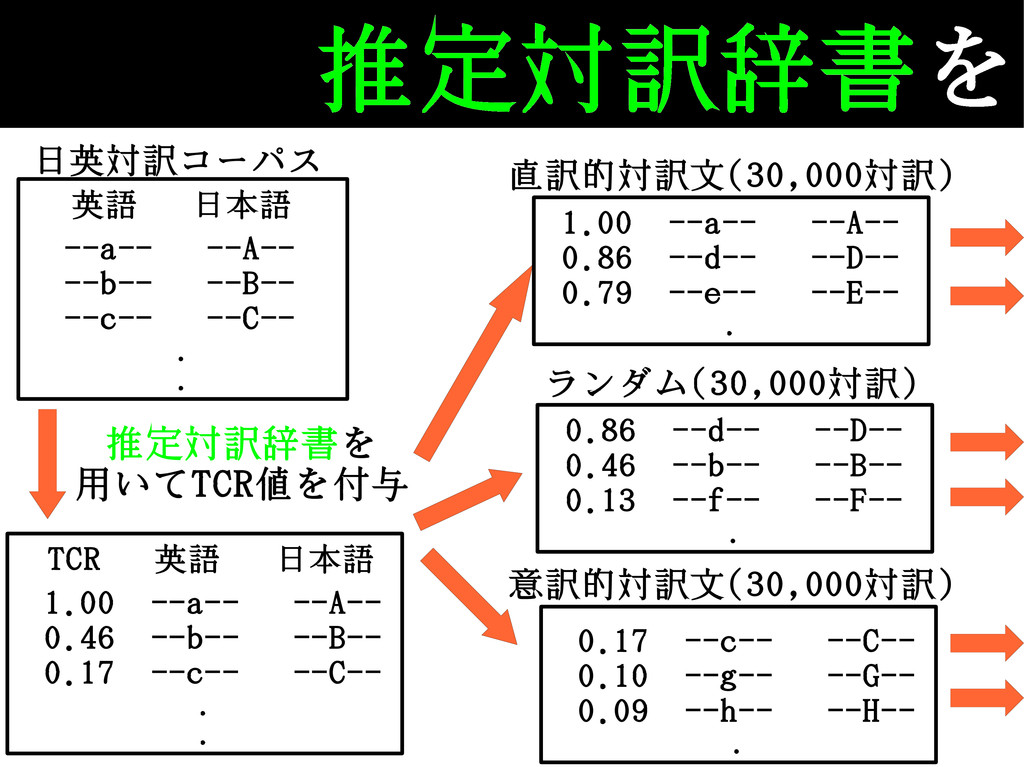
推定対訳辞書を TCR 英語 日本語 1.00 --a-- --A-- 0.46 --b-- --B--
0.17 --c-- --C-- . . 英語 日本語 --a-- --A-- --b-- --B-- --c-- --C-- . . 日英対訳コーパス 推定対訳辞書を 用いてTCR値を付与 1.00 --a-- --A-- 0.86 --d-- --D-- 0.79 --e-- --E-- . 0.86 --d-- --D-- 0.46 --b-- --B-- 0.13 --f-- --F-- . 0.17 --c-- --C-- 0.10 --g-- --G-- 0.09 --h-- --H-- . 直訳的対訳文(30,000対訳) ランダム(30,000対訳) 意訳的対訳文(30,000対訳)
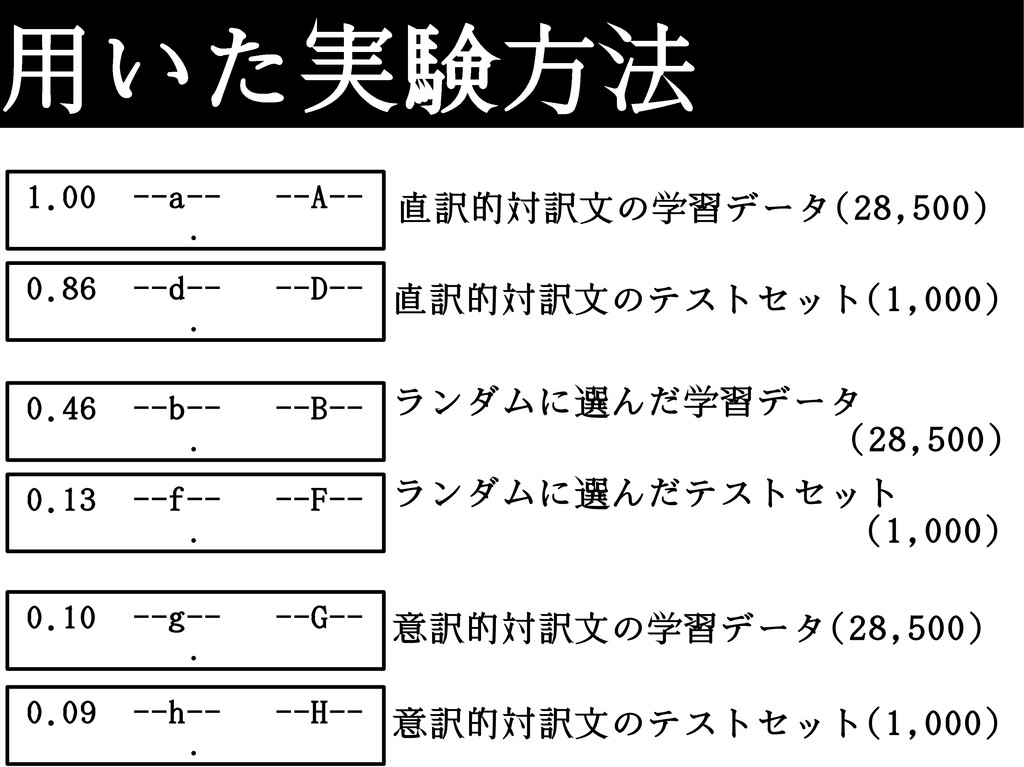
用いた実験方法 1.00 --a-- --A-- . 0.86 --d-- --D-- . 0.46
--b-- --B-- . 0.13 --f-- --F-- . 0.10 --g-- --G-- . 0.09 --h-- --H-- . 直訳的対訳文の学習データ(28,500) 直訳的対訳文のテストセット(1,000) ランダムに選んだ学習データ (28,500) ランダムに選んだテストセット (1,000) 意訳的対訳文の学習データ(28,500) 意訳的対訳文のテストセット(1,000)
推定対訳辞書を用いた実験結果 ▪意訳のテストセットは直訳やランダムの テストセットに比べて翻訳精度が1/2程度 ➔ 意訳しにくいということを表している 翻訳 モデル テストセット 直訳 意訳
ランダム 直訳 0.297 0.087 0.257 意訳 0.201 0.125 0.226 ランダム 0.270 0.099 0.229 平均 0.256 0.104 0.237 Table1 翻訳モデルの違いによる各テストセットの評価結果(BLEU)
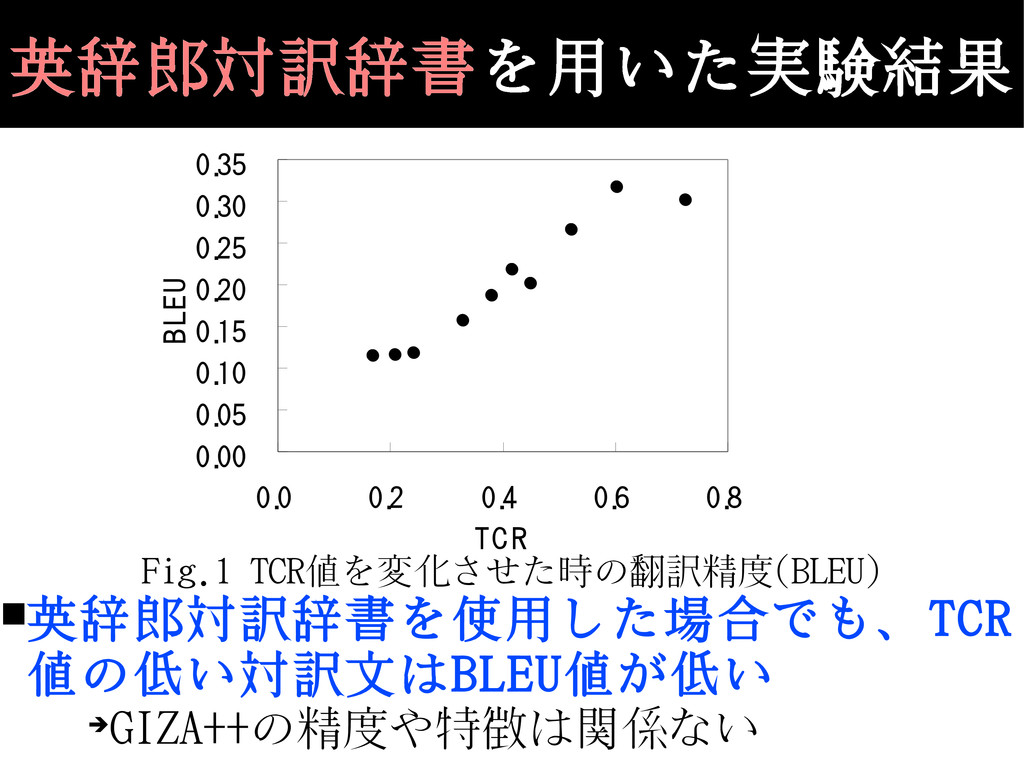
英辞郎対訳辞書を ▪推定対訳辞書を用いた実験結果は GIZA++の特徴が表れていた? 英辞郎対訳辞書を用いて再実験 ▪評価用データの作成 26,095対訳をテストセットに使用 TCR値でソートし、2,610対訳ごとに分割
各2,610対訳からテストセット1,000対訳 を抽出
▪翻訳モデルの構築 テストセットを除いた359,431対訳を使用 して翻訳モデルを構築 ▪言語モデルの構築 対訳コーパスの目的言語を使用 テストセットは除いている
5-gramまで 用いた実験方法
0. 00 0. 05 0. 10 0. 15 0. 20
0. 25 0. 30 0. 35 0. 0 0. 2 0. 4 0. 6 0. 8 TC R BLEU ▪英辞郎対訳辞書を使用した場合でも、TCR 値の低い対訳文はBLEU値が低い ➔ GIZA++の精度や特徴は関係ない Fig.1 TCR値を変化させた時の翻訳精度(BLEU) 英辞郎対訳辞書を用いた実験結果
コーパスサイズを変化させて実験 ▪翻訳モデル構築方法の違いによる影響 を3種類の翻訳モデルによって確認 全体モデル ➔ 全対訳文(360,000対訳)から構築 直訳モデル ➔
TCR値の高い方から30,000対訳ずつ増やして 構築(11個のモデルを構築) 意訳モデル ➔ TCR値の低い方から30,000対訳ずつ増やして 構築(11個のモデルを構築)
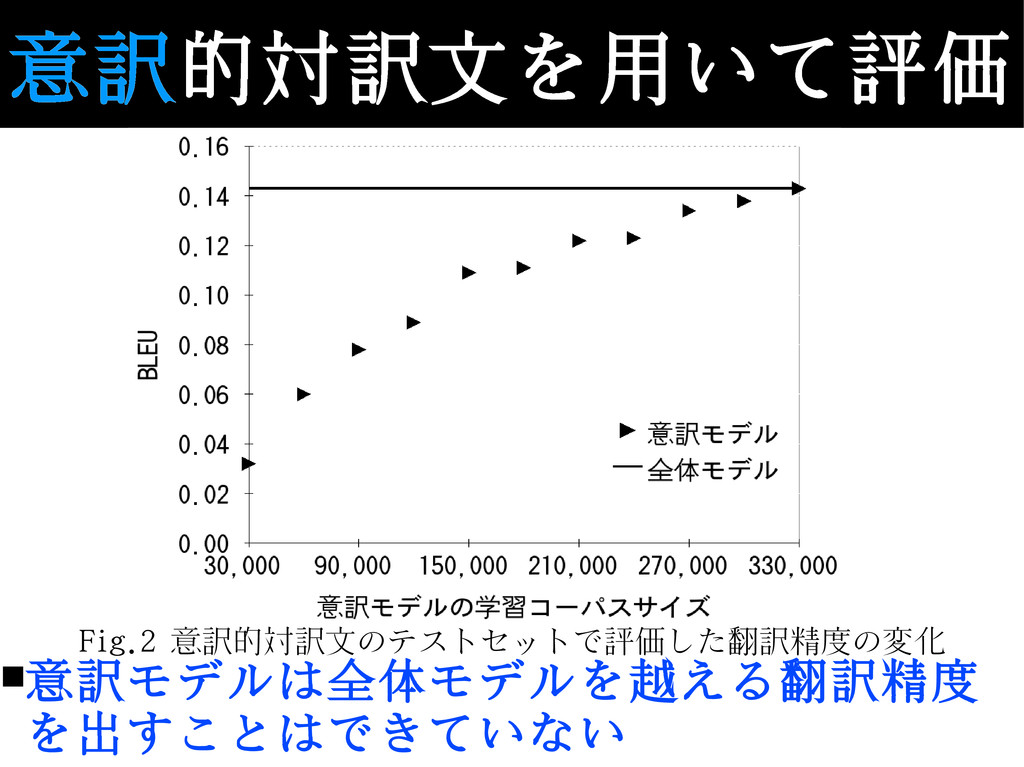
意訳的対訳文を用いて評価 Fig.2 意訳的対訳文のテストセットで評価した翻訳精度の変化 ▪意訳モデルは全体モデルを越える翻訳精度 を出すことはできていない
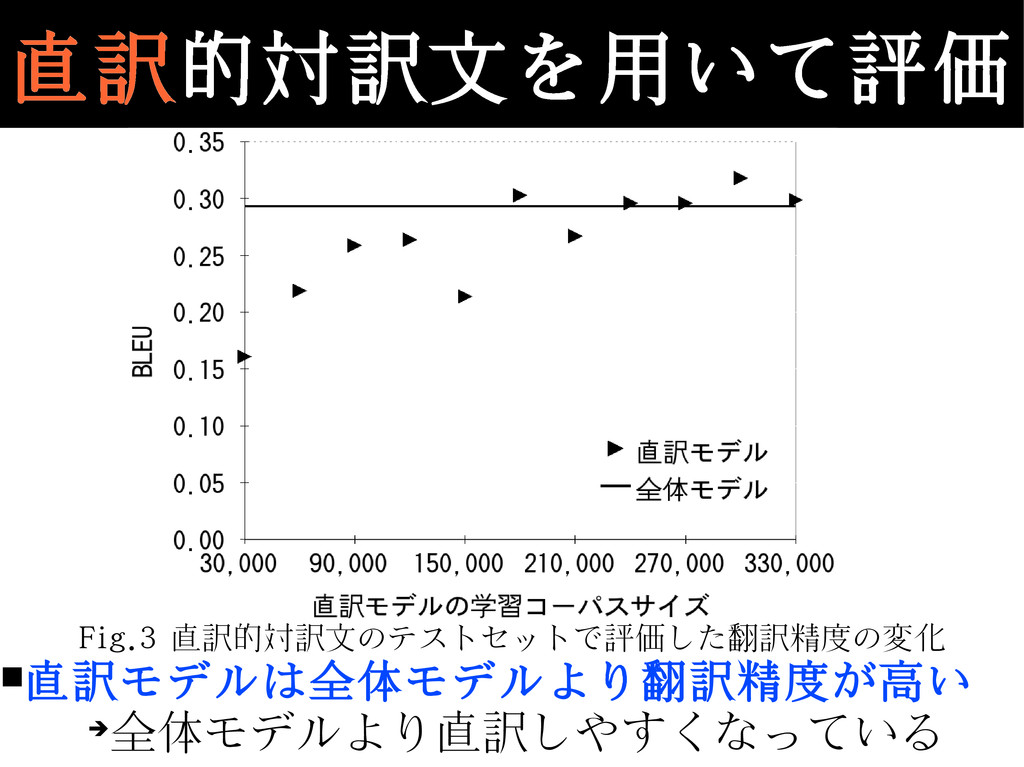
Fig.3 直訳的対訳文のテストセットで評価した翻訳精度の変化 ▪直訳モデルは全体モデルより翻訳精度が高い ➔ 全体モデルより直訳しやすくなっている 直訳的対訳文を用いて評価
実験ツール&言語資源 ▪実験ツール Moses : デコーダ GIZA++ : アライメント推定ツール
IRSTLM : 言語モデル構築ツール Chasen : 日本語形態素解析器 TreeTagger : 英語形態素解析器 ▪言語資源 日英対訳コーパス :374,085対訳 日英推定対訳辞書 :748,258対訳 日英英辞郎対訳辞書 :153,067対訳
TCRの計算方法 TCR = 2 ×対訳辞書中に対訳としてある数 [L ] 対訳辞書中にある原文の単語数 [Ts ]+
対訳辞書中にある翻訳結果の単語数 [Tt ] 丸囲み単語の個数がTs及びTt、直線の数がLに値する
英辞郎対訳辞書を用いた実験 ▪評価用データの作成方法 辞書Bは辞書Aに比べ対訳数が1/5と少ない TCR値の信頼度を上げるために、以下の式 を満たす対訳文だけをテストセットとする 対訳辞書中にある原文の単語数 [Ts ]+
対訳辞書中にある翻訳結果の単語数 [Tt ] 原言語の単語数 [Ws ]+目的言語の単語数 [Wt ] ≥0.9
{kind=link}
{kind=link}
![関連研究 ▪直訳性を利用した機械翻訳知識の自 動構築[今村 04] 日英対訳コーパス TCR 英語 日本語 1.00 --a--](https://files.speakerdeck.com/presentations/25ce8d00c60501306b9616ef2e465d1f/slide_2.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![TCRの計算方法 TCR = 2 ×対訳辞書中に対訳としてある数 [L ] 対訳辞書中にある原文の単語数 [Ts ]+](https://files.speakerdeck.com/presentations/25ce8d00c60501306b9616ef2e465d1f/slide_13.jpg){kind=link}
![英辞郎対訳辞書を用いた実験 ▪評価用データの作成方法 辞書Bは辞書Aに比べ対訳数が1/5と少ない TCR値の信頼度を上げるために、以下の式 を満たす対訳文だけをテストセットとする 対訳辞書中にある原文の単語数 [Ts ]+](https://files.speakerdeck.com/presentations/25ce8d00c60501306b9616ef2e465d1f/slide_14.jpg){kind=link}