データ量の不足 ▪ 学習によりドメインに順応する単語データを作成 → 取得したいドメインの書き込みを学習 W s :意見文で単語 W i が出現する確率 P p P n :意見文以外で単語 W i が出現する確率 W s w i = P p w i P p w i P n w i
新出の単語 → 単語データのすべての単語の平均値を付与 S s= ∑ i W s w i Average W s :単語スコア Average :単語データの平均値を 単語数分与えた時の総和 入力文 意見文スコア 静かなのも手伝って、スピード感が殆んどないです。 2.009 ペイントシーラントいいですねぇ 1.924 今あるストックを提示して貰えば話が早そうですね 1.120 0.816 それともステレオとの組み合わせで決まるのですか?
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
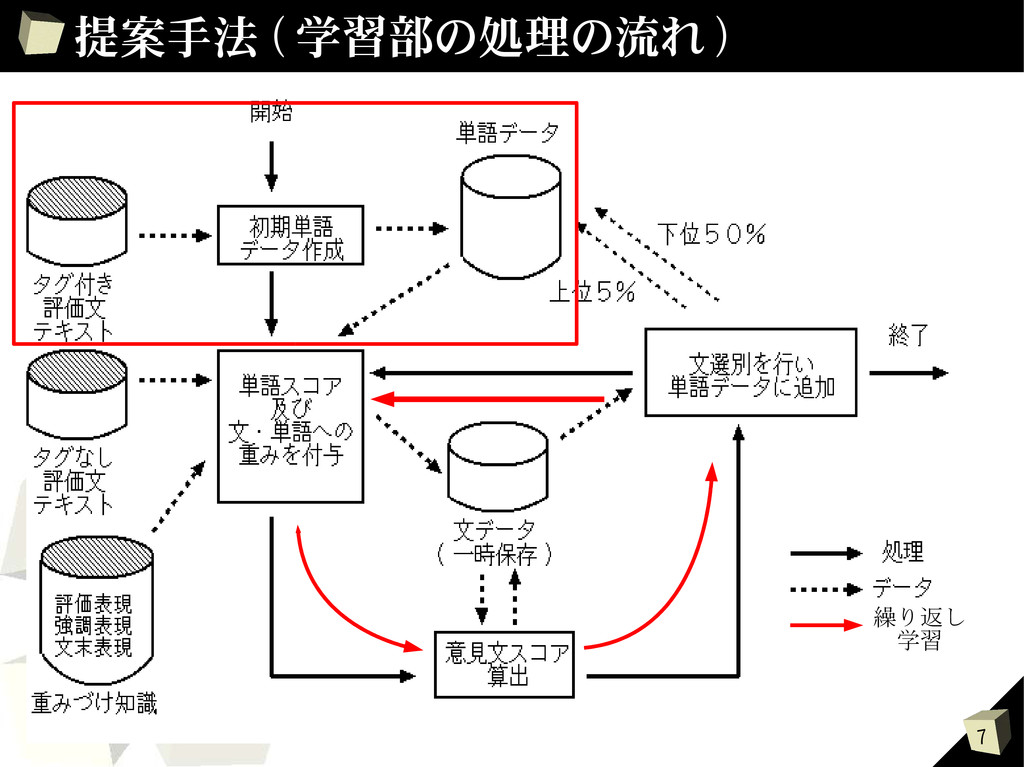{kind=link}
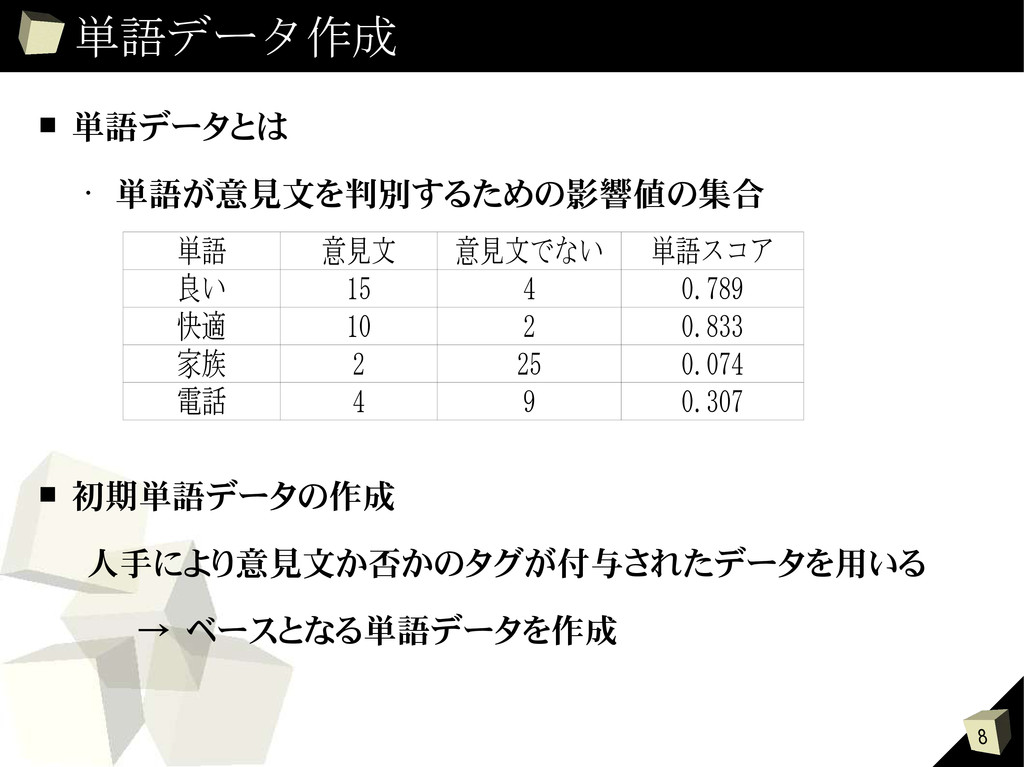{kind=link}
{kind=link}
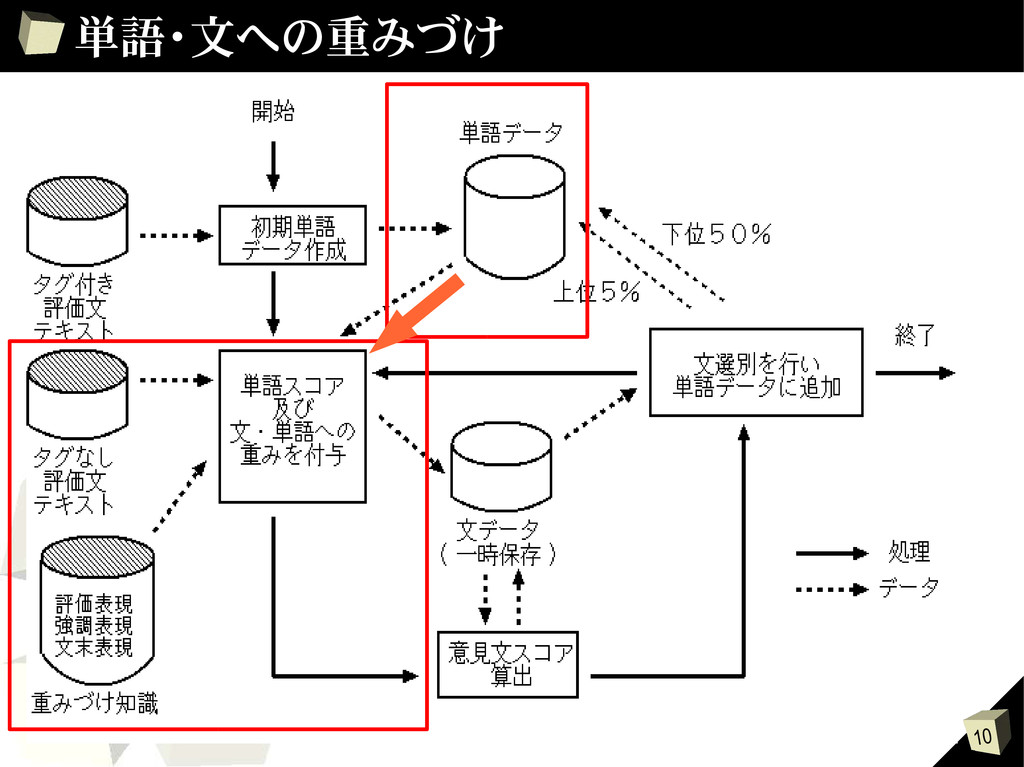{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
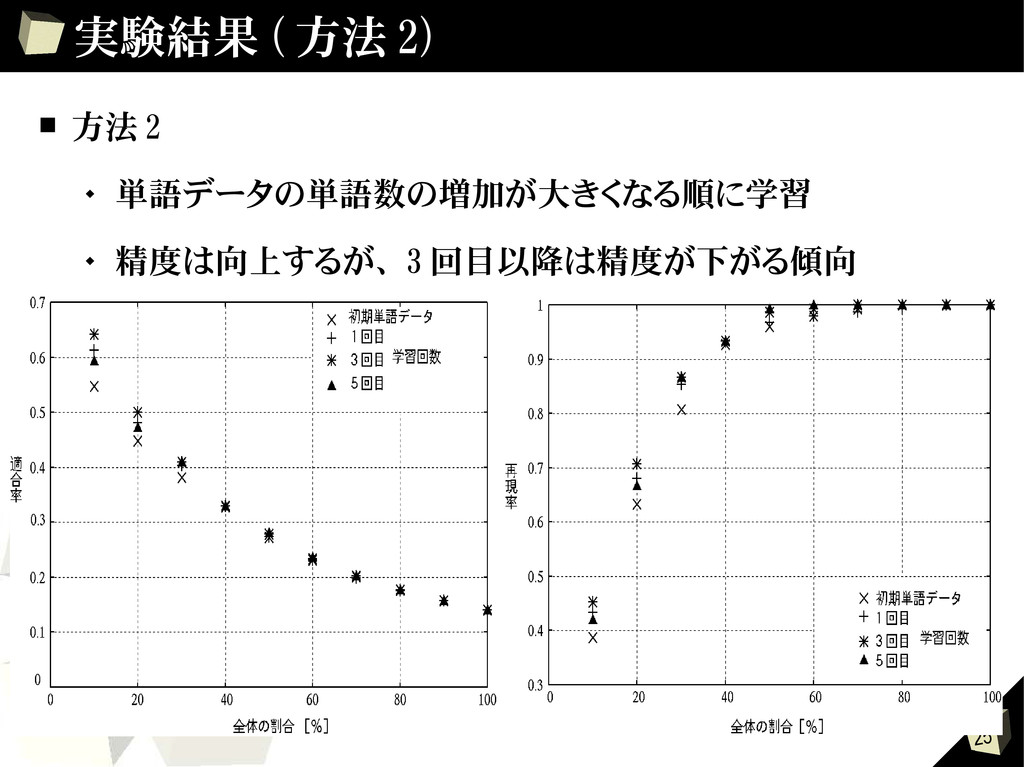{kind=link}
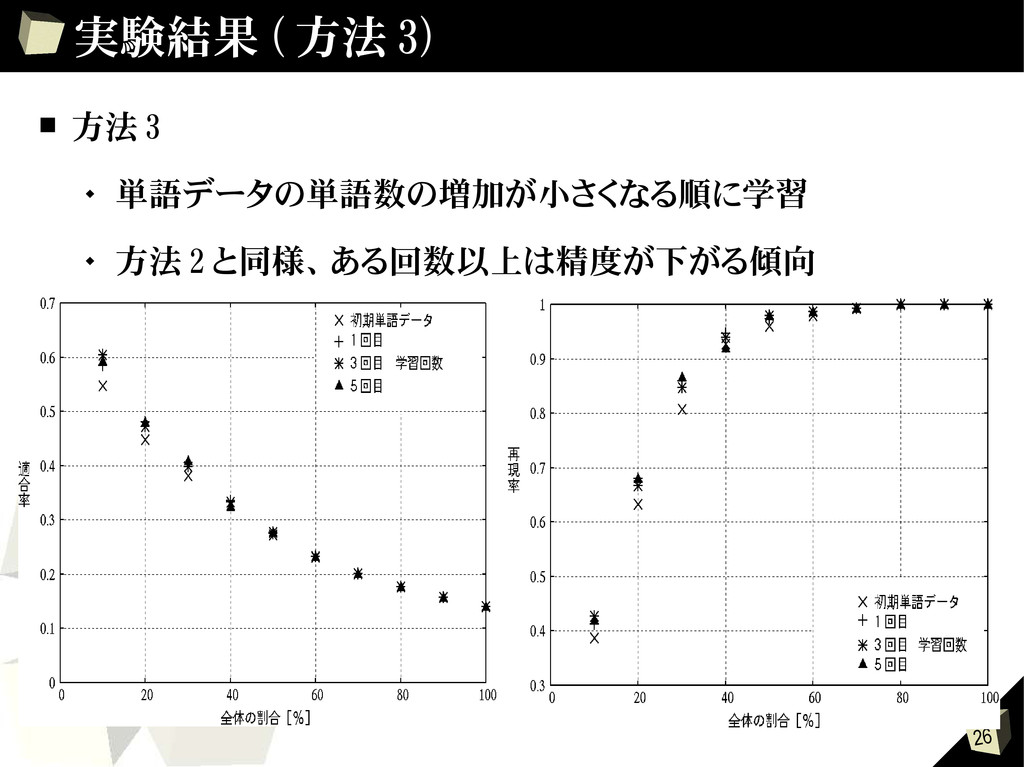{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}